在各种基于关系数据库的应用系统开发中,我们往往需要存储树型结构的数据,目前有很多流行的方法,如邻接列表模型(The Adjacency List Model),在此基础上也有很多人针对不同的需求做了相应的改进,但总是在某些方面存在的各种各样的缺陷。
那么理想中的树型结构应具备哪些特点呢?数据存储冗余小、直观性强;方便返回整个树型结构数据;可以很轻松的返回某一子树(方便分层加载);快整获以某节
点的祖谱路径;插入、删除、移动节点效率高等等。带着这些需求我查找了很多资料,发现了一种理想的树型结构数据存储及操作算法,改进的前序遍历树模型
(The Nested Set Model)。
一、数据
在本文中,举一个在线食品店树形图的例子。这个食品店通过类别、颜色和品种来组织食品。树形图如下:
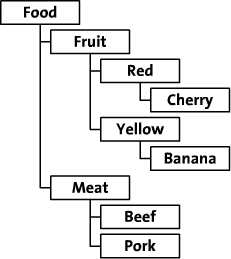
二、邻接列表模型(The Adjacency List Model)
在这种模型下,上述数据在关系数据库的表结构数据通常如下图所示:
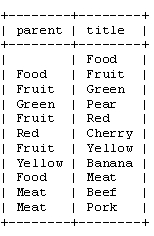
由于该模型比较简单,在此不再详细介绍其算法,下面列出它的一些不足:
在大多数编程语言中,他运行很慢,效率很差。这主要是“递归”造成的。我们每次查询节点都要访问数据库。每次数据库查询都要花费一些时间,这让函数处理庞
大的树时会十分慢。造成这个函数不是太快的第二个原因可能是你使用的语言。不像Lisp这类语言,大多数语言不是针对递归函数设计的。对于每个节点造成这
个函数不是太快的第二个原因可能是你使用的语言。不像Lisp这类语言,大多数语言不是针对递归函数设计的。对于每个节点,函数都要调用他自己,产生新的
实例。这样,对于一个4层的树,你可能同时要运行4个函数副本。对于每个函数都要占用一块内存并且需要一定的时间初始化,这样处理大树时递归就很慢了。
三、改进的前序遍历树模型(The Nested Set Model)
原理:
我们先把树按照水平方式摆开。从根节点开始(“Food”),然后他的左边写上1。然后按照树的顺序(从上到下)给“Fruit”的左边写上2。这样,你
沿着树的边界走啊走(这就是“遍历”),然后同时在每个节点的左边和右边写上数字。最后,我们回到了根节点“Food”在右边写上18。下面是标上了数字
的树,同时把遍历的顺序用箭头标出来了。
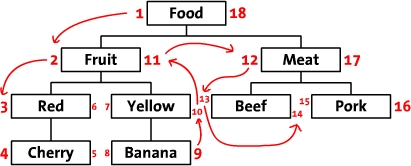
我们称这些数字为左值和右值(如,“Food”的左值是1,右值是18)。正如你所见,这些数字按时了每个节点之间的关系。因为“Red”有3和6两个
值,所以,它是有拥有1-18值的“Food”节点的后续。同样的,我们可以推断所有左值大于2并且右值小于11的节点,都是有2-11的“Fruit”
节点的后续。这样,树的结构就通过左值和右值储存下来了。这种数遍整棵树算节点的方法叫做“改进前序遍历树”算法。
表结构设计:
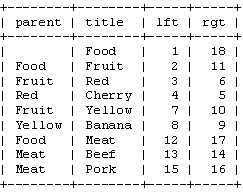
常用的操作:
下面列出一些常用操作的SQL语句
返回完整的树(Retrieving a Full Tree)
SELECT
node.name
FROM
nested_category node, nested_category parent
WHERE
node.lft
BETWEEN
parent.lft
AND
parent.rgt
AND
parent.name
=
'
electronics
'
ORDER
BY
node.lft
返回某结点的子树(Find the Immediate Subordinates of a Node)
SELECT
V.
*
FROM
(
SELECT
node.name,
(
COUNT
(parent.name)
-
(
AVG
(sub_tree.depth)
+
1
)) depth
FROM
nested_category node,
nested_category parent,
nested_category sub_parent,
(
SELECT
V.
*
FROM
(
SELECT
node.name, (
COUNT
(parent.name)
-
1
) depth
FROM
nested_category node, nested_category parent
WHERE
node.lft
BETWEEN
parent.lft
AND
parent.rgt
AND
node.name
=
'
portable electronics
'
GROUP
BY
node.name) V,
nested_category T
WHERE
V.name
=
T.name
ORDER
BY
T.lft) sub_tree
WHERE
node.lft
BETWEEN
parent.lft
AND
parent.rgt
AND
node.lft
BETWEEN
sub_parent.lft
AND
sub_parent.rgt
AND
sub_parent.name
=
sub_tree.name
GROUP
BY
node.name) V,
nested_category T
WHERE
V.name
=
T.name
and
V.depth
<=
1
and
V.depth
>
0
ORDER
BY
T.Lft
返回某结点的祖谱路径(Retrieving a Single Path)
SELECT
parent.name
FROM
nested_category node, nested_category parent
WHERE
node.lft
BETWEEN
parent.lft
AND
parent.rgt
AND
node.name
=
'
flash
'
ORDER
BY
node.lft
返回所有节点的深度(Finding the Depth of the Nodes)
SELECT
V.
*
FROM
(
SELECT
node.name, (
COUNT
(parent.name)
-
1
) depth
FROM
nested_category node, nested_category parent
WHERE
node.lft
BETWEEN
parent.lft
AND
parent.rgt
GROUP
BY
node.name) V,
nested_category T
WHERE
V.name
=
T.name
ORDER
BY
T.Lft
返回子树的深度(Depth of a Sub-Tree)
SELECT
V.
*
FROM
(
SELECT
node.name,
(
COUNT
(parent.name)
-
(
AVG
(sub_tree.depth)
+
1
)) depth
FROM
nested_category node,
nested_category parent,
nested_category sub_parent,
(
SELECT
V.
*
FROM
(
SELECT
node.name, (
COUNT
(parent.name)
-
1
) depth
FROM
nested_category node, nested_category parent
WHERE
node.lft
BETWEEN
parent.lft
AND
parent.rgt
AND
node.name
=
'
portable electronics
'
GROUP
BY
node.name) V,
nested_category T
WHERE
V.name
=
T.name
ORDER
BY
T.lft) sub_tree
WHERE
node.lft
BETWEEN
parent.lft
AND
parent.rgt
AND
node.lft
BETWEEN
sub_parent.lft
AND
sub_parent.rgt
AND
sub_parent.name
=
sub_tree.name
GROUP
BY
node.name) V,
nested_category T
WHERE
V.name
=
T.name
ORDER
BY
T.Lft
返回所有的叶子节点(Finding all the Leaf Nodes)
SELECT
name
FROM
nested_category
WHERE
rgt
=
lft
+
1
插入节点(Adding New Nodes)
LOCK
TABLE
nested_category WRITE;
SELECT
@myRight
:
=
rgt
FROM
nested_category
WHERE
name
=
'
TELEVISIONS
'
;
UPDATE
nested_category
SET
rgt
=
rgt
+
2
WHERE
rgt
>
@myRight
;
UPDATE
nested_category
SET
lft
=
lft
+
2
WHERE
lft
>
@myRight
;
INSERT
INTO
nested_category
(name, lft, rgt)
VALUES
(
'
GAME CONSOLES
'
,
@myRight
+
1
,
@myRight
+
2
);
UNLOCK TABLES;
删除节点(Deleting Nodes)
LOCK
TABLE
nested_category WRITE;
SELECT
@myLeft
:
=
lft,
@myRight
:
=
rgt,
@myWidth
:
=
rgt
-
lft
+
1
FROM
nested_category
WHERE
name
=
'
GAME CONSOLES
'
;
DELETE
FROM
nested_category
WHERE
lft
BETWEEN
@myLeft
AND
@myRight
;
UPDATE
nested_category
SET
rgt
=
rgt
-
@myWidth
WHERE
rgt
>
@myRight
;
UPDATE
nested_category
SET
lft
=
lft
-
@myWidth
WHERE
lft
>
@myRight
;
UNLOCK TABLES;
[
参考资料]
http://dev.mysql.com/tech-resources/articles/hierarchical-data.html
http://www.nirvanastudio.org/php/hierarchical-data-database.html
分享到:





相关推荐
注:非网上流传的“一种理想的在关系数据库中存储树型结构数据的方法”。 该存储算法对查询,插入,移动,删除均显得高效,当然也有一定的局限性,读者自己分析。
针对现有映射方法对XML文档格式要求过严等不足,在模型映射方法基础上提出一种XML文档映射关系数据库的新方法。通过给XML文档树做标志,将映射算法转换后的数据放到两张预先定义结构的表进行存储。给出了逻辑数据模型...
树型结构对于构建和搜索数据很理想,但对于报告,就不是很理想了。XML方法很适合于报告,但是对于整个应用程序的实现,该方法还有很多不便,并会降低性能。因为数据集的大小是可管理的。如果数据集的大小合适,那么...
摘要:简要介绍了一种通用的,动态树型结构的实现方案,该方案基于AsynchronousJavaScriptandXML,结合Struts框架设计实现了结构清晰、扩展性良好的多层架构,数据存储于数据库,结合XML描述树的节点信息,使得任何按...
其缺陷是:(数据冗余性 数据不一致性 数据联系弱)3、数据库阶段的特点:采用复杂的数据模型表示数据结构,有较高的数据独立性(数据结构分成用户的逻辑结构、整体逻辑结构和物理结构三级),数据库系统为用户提供方便的...
针对SaaS 模式的云服务,本文提出一种树型云数据库,该数据库以树的形式组织、检索数据,树中节点的类型不仅可以是数值、字符、文本,也可以是二维表、文件等,其最差情况下的搜索时间复杂度为O[log
数据模型中的__________是对数据系统的静态特征描述,包括数据结构和数据间联系的描述,__________是对数据库系统的动态特征描述,是一组定义在数据上的操作,包括操作的涵义、操作符、运算规则及其语言等。...
JGRAPH中对图和顶点与边的定义与存储结构是非常简洁与实用的,利用数据库或者是GXL文件中的这些数据可以非常简单的处理一个复杂的流程图........... 该工具经过修改后,也可以实现一个实时监控界面和其它的适合于...
空间数据库中反向最近邻查询在低维查询时一般利用基于R-Tree的改进树作为索引结构,由于树型索引结构...针对这个问题,提出了一种基于VARdnn-Tree的索引结构,采用量化压缩的方法存储数据,能够有效地支持高维查询。
第 一种映像使得数据库物理结构改变时逻辑结构不变,因而相应的程序也不变,这就是数 据库的物理独立性;第二种映像使得逻辑结构改变时,用户结构不变,应用程序也不用 改变,这就是数据和程序的逻辑独立性。 32....
想到最后,我决定还是借鉴XML的树型标签形式,来实现一种二进制的存储结构,即BinXML:) 关于src包 对于BinXML-src里面的例子,数据的结构类似于: BinXML-src.zip包括两部分,一部分是vc的工程,一部分是java的...
本文主要做了以下几点工作: ...并将接收到的数据存储到数据库的表中,方便用户对历史数据的查 询。并提供了报警功能,根据设置的相关物理量报警门限及时的给出报警信息, 方便管理者及时作出相应的决策。
23.如果要把C盘某个文件夹中的一些文件复制到C盘的另外一个文件央中,在选定文件后,若采用拖放操作,可以用___B___目标的方法。 A、直接拖至 B、Ctrl十拖至 C、Alt十拖至 D、单击 24.Windows98中的磁盘的根文件夹是...
SA法是面向数据流,建立在数据封闭原则上的需求分析方法。(√) 3. HIPO法既是需求分析方法,又是软件设计方法。(√) 4. 在面向对象的需求分析方法中,建立动态模型是最主要的任务。(×) 5. 加工小说明是对系统...
与树型结构相比,Hash表对数据的精确查找具有更高的效率,但是范围查找的效率比较低.针对这种情况,提出了一种改进的可用于范围查询的数据桶划分算法.为了能够更好地对算法进行描述,首先提出了可用于范围查询的Hash存储...
数据流程图是一种能全面地描述信息系统逻辑模型的主要工具,它可以用少数几种符号综合地反映出信息在系统中的流动、处理和存储情况。 37.把数据项分成若干组,每一区间代表一个组,码中数字的值和位置都代表一定的...
后台数据库使用的是SQL Server 2000,前台使用了.NET的静态绑定技术,和新一代的ADO.NET数据存储机制,与.NET2005添加的一些新的功能配合使用,添加了一些集成控件,如集成了树型控件,登陆控件等,利用这些技术将...