超大型数据库的大小常常达到数百GB,有时甚至要用TB来计算。而单表的数据量往往会达到上亿的记录,并且记录数会随着时间而增长。这不但影响着数据库的运行效率,也增大数据库的维护难度。除了表的数据量外,对表不同的访问模式也可能会影响性能和可用性。这些问题都可以通过对大表进行合理分区得到很大的改善。当表和索引变得非常大时,分区可以将数据分为更小、更容易管理的部分来提高系统的运行效率。如果系统有多个CPU或是多个磁盘子系统,可以通过并行操作获得更好的性能。所以对大表进行分区是处理海量数据的一种十分高效的方法。本文通过一个具体实例,介绍如何创建和修改分区表,以及如何查看分区表。
1 SQL Server 2005
SQL Server 2005是微软在推出SQL Server 2000后时隔五年推出的一个数据库平台,它的数据库引擎为关系型数据和结构化数据提供了更安全可靠的存储功能,使用户可以构建和管理用于业务的高可用和高性能的数据应用程序。此外SQL Server 2005结合了分析、报表、集成和通知功能。这使企业可以构建和部署经济有效的BI解决方案,帮助团队通过记分卡、Dashboard、Web Services和移动设备将数据应用推向业务的各个领域。无论是开发人员、数据库管理员、信息工作者还是决策者,SQL Server 2005都可以提供出创新的解决方案,并可从数据中获得更多的益处。
它所带来的新特性,如T-SQL的增强、数据分区、服务代理和与.Net Framework的集成等,在易管理性、可用性、可伸缩性和安全性等方面都有很大的增强。
2 表分区的具体实现方法
表分区分为水平分区和垂直分区。水平分区将表分为多个表。每个表包含的列数相同,但是行更少。例如,可以将一个包含十亿行的表水平分区成 12 个表,每个小表表示特定年份内一个月的数据。任何需要特定月份数据的查询只需引用相应月份的表。而垂直分区则是将原始表分成多个只包含较少列的表。水平分区是最常用分区方式,本文以水平分区来介绍具体实现方法。
水平分区常用的方法是根据时期和使用对数据进行水平分区。例如本文例子,一个短信发送记录表包含最近一年的数据,但是只定期访问本季度的数据。在这种情况下,可考虑将数据分成四个区,每个区只包含一个季度的数据。
2.1 创建文件组
建立分区表先要创建文件组,而创建多个文件组主要是为了获得好的 I/O 平衡。一般情况下,文件组数最好与分区数相同,并且这些文件组通常位于不同的磁盘上。每个文件组可以由一个或多个文件构成,而每个分区必须映射到一个文件组。一个文件组可以由多个分区使用。为了更好地管理数据(例如,为了获得更精确的备份控制),对分区表应进行设计,以便只有相关数据或逻辑分组的数据位于同一个文件组中。使用 ALTER DATABASE,添加逻辑文件组名:
ALTER DATABASE [DeanDB] ADD FILEGROUP [FG1]
DeanDB为数据库名称,FG1文件组名。创建文件组后,再使用 ALTER DATABASE 将文件添加到该文件组中:
ALTER DATABASE [DeanDB] ADD FILE ( NAME = N'FG1', FILENAME = N'C:\DeanData\FG1.ndf' , SIZE = 3072KB , FILEGROWTH = 1024KB ) TO FILEGROUP [FG1]
类似的建立四个文件和文件组,并把每一个存储数据的文件放在不同的磁盘驱动器里。
2.2 创建分区函数
创建分区表必须先确定分区的功能机制,表进行分区的标准是通过分区函数来决定的。创建数据分区函数有RANGE “LEFT | / RIGHT”两种选择。代表每个边界值在局部的哪一边。例如存在四个分区,则定义三个边界点值,并指定每个值是第一个分区的上边界 (LEFT) 还是第二个分区的下边界 (RIGHT)[1]。代码如下:
CREATE PARTITION FUNCTION [SendSMSPF](datetime) AS RANGE RIGHT FOR VALUES ('20070401', '20070701', '20071001')
2.3 创建分区方案
创建分区函数后,必须将其与分区方案相关联,以便将分区指向至特定的文件组。就是定义实际存放数据的媒体与各数据块的对应关系。多个数据表可以共用相同的数据分区函数,一般不共用相同的数据分区方案。可以通过不同的分区方案,使用相同的分区函数,使不同的数据表有相同的分区条件,但存放在不同的媒介上。创建分区方案的代码如下:
CREATE PARTITION SCHEME [SendSMSPS] AS PARTITION [SendSMSPF] TO ([FG1], [FG2], [FG3], [FG4])
2.4 创建分区表
建立好分区函数和分区方案后,就可以创建分区表了。分区表是通过定义分区键值和分区方案相联系的。插入记录时,SQL SERVER会根据分区键值的不同,通过分区函数的定义将数据放到相应的分区。从而把分区函数、分区方案和分区表三者有机的结合起来。创建分区表的代码如下:
CREATE TABLE SendSMSLog
([ID] [int] IDENTITY(1,1) NOT NULL,
[IDNum] [nvarchar](50) NULL,
[SendContent] [text] NULL
[SendDate] [datetime] NOT NULL,
) ON SendSMSPS(SendDate)
2.5 查看分区表信息
系统运行一段时间或者把以前的数据导入分区表后,我们需要查看数据的具体存储情况,即每个分区存取的记录数,那些记录存取在那个分区等。我们可以通过$partition.SendSMSPF来查看,代码如下:
SELECT $partition.SendSMSPF(o.SendDate)
AS [Partition Number]
, min(o.SendDate) AS [Min SendDate]
, max(o.SendDate) AS [Max SendDate]
, count(*) AS [Rows In Partition]
FROM dbo.SendSMSLog AS o
GROUP BY $partition.SendSMSPF(o.SendDate)
ORDER BY [Partition Number]
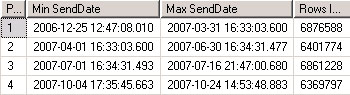
在查询分析器里执行以上脚本,结果如图1所示:
图1 分区表信息
2.6 维护分区
分区的维护主要设计分区的添加、减少、合并和在分区间转换。可以通过ALTER PARTITION FUNCTION的选项SPLIT,MERGE和ALTER TABLE的选项SWITCH来实现。SPLIT会多增加一个分区,而MEGRE会合并或者减少分区,SWITCH则是逻辑地在组间转换分区。
3 性能对比
我们对2650万数据,存储空间占用约<chmetcnv w:st="on" unitname="g" sourcevalue="4" hasspace="False" negative="False" numbertype="1" tcsc="0"><span>4G</span></chmetcnv>的单表进行性能对比,测试环境为IBM365,CPU 至强<chmetcnv w:st="on" unitname="g" sourcevalue="2.7" hasspace="False" negative="False" numbertype="1" tcsc="0"><span>2.7G</span></chmetcnv>*2、内存 <chmetcnv w:st="on" unitname="g" sourcevalue="16" hasspace="False" negative="False" numbertype="1" tcsc="0">16G</chmetcnv>、硬盘 <chmetcnv w:st="on" unitname="g" sourcevalue="136" hasspace="False" negative="False" numbertype="1" tcsc="0">136G</chmetcnv>*2,系统平台为Windows 2003 SP1+SQL Server 2005 SP1。测试结果如表1:
表1:分区和未分区性能对比表(单位:毫秒)
|
测试项目 分区 未分区
|
|
1 16546 61466
|
|
2 13 33
|
|
3 20140 61546
|
|
4 17140 61000
|
说明:
1:根据时间检索某一天记录所耗时间
2:单条记录插入所耗时间
3:根据时间删除某一天记录所耗时间
4:统计每月的记录数所需时间
从表1可以看出,对分区表进行操作比未分区的表要快,这是因为对分区表的操作采用了CPU和I/O的并行操作,检索数据的数据量也变小了,定位数据所耗时间变短。
4 结束语
对海量数据的处理一直是一个令人头痛的问题。分离的技术是所有设计者们首先考虑的问题,不管是分离应用程序功能还是分离数据访问,如果加以了合理规划,都能十分有效的解决大数据表的运行效率低和维护成本高等问题。SQL Server 2005新增的表分区功能,可以对数据进行合理分区,当用户在访问部分数据时,SQL Server最佳化引擎可以根据数据的实体存放,找出最佳的执行方案,而不至于大海捞针。
分享到:





相关推荐
乌燕鸥优化算法(Seagull Optimization Algorithm, SOA)是一种新兴的自然启发式优化算法,源于生物界乌燕鸥的觅食行为。在自然界中,乌燕鸥以灵活的飞行技巧和敏锐的感知能力寻找食物,这一特性被借鉴到解决复杂的...
《初三语文说明文阅读练习题(三)精选》是一篇以北极燕鸥为主题的说明文,主要探讨了这种鸟类的特性及其引人注目的生活习性。 北极燕鸥是一种令人敬畏的鸟类,它们拥有多种显著的特点。首先,它们以其非凡的飞行...
乌燕鸥优化算法STOA-野狗优化算法DOA-海鸥优化算法TSO-金枪鱼优化算法TSO-斑点鬣狗优化算法SHO【单目标优化算法】在23个测试函数上对比(Matlab代码实现) 乌燕鸥优化算法STOA-野狗优化算法DOA-海鸥优化算法TSO-...
乌燕鸥优化算法(Seagull Optimization Algorithm, STOA)是一种新型的全局优化算法,灵感来源于乌燕鸥在海面上捕食的行为。这种算法在解决复杂优化问题时展现出优秀的搜索性能,尤其对于多模态、非线性以及高维度的...
- 北极燕鸥的迁徙:展示了动物对季节变化的适应,以及不同迁徙路线的选择。 6. 地质地貌和河流演变: - 河流阶地的形成:揭示了河流侵蚀、侧蚀和堆积过程,以及堰塞湖的影响。 7. 地理观测和天文现象: - 观测...
2. **生态学**:北极的生态系统独特且脆弱,包括独特的动植物种群,如北极熊、驯鹿、海豹和北极燕鸥等。研究人员会研究这些物种的生存状态、繁殖模式以及它们如何适应快速变化的环境。 3. **遗传资源**:描述中的...
- 北极燕鸥的迁徙路线展示了它们如何追逐夏季,这涉及地球的昼夜变化和季节更替。燕鸥的迁徙路径选择可能考虑节省能量,利用风向等因素。 6. **航海与地理知识应用**: - 荷兰学生乘坐帆船从加勒比海返回时,可能...
【优化求解】基于乌燕鸥算法STOA求解最优目标matlab代码.zip是一个压缩包,其中包含了一篇关于利用乌燕鸥算法(Seagull Optimization Algorithm, STOA)进行最优目标求解的Matlab代码实现。乌燕鸥算法是一种自然启发...
- 北极则有北极熊、海豹、北极狐、驯鹿以及多种鸟类,如北极燕鸥和雪鹅。 5. **科学考察的重要性**: - 极地地区的科学研究对于理解地球气候变化、生态系统、地质构造等方面具有重要意义。 - 极地是全球气候变化...
### 中海地产中海会「燕鸥行动」夏令营活动关键知识点 #### 一、活动背景及目的 - **背景**:2011年7月,中海地产中海会组织了一次名为「燕鸥行动」的夏令营活动。此次活动的主要参与者是由中海业主和中海会会员的...
北极燕鸥迁徙:北极燕鸥的迁徙路径利用了盛行风和洋流,使得飞行更为顺利;在迁徙过程中,它们可以通过沿岸地区获取淡水补充。 以上是对试卷中涉及的地理知识点的详细解析,涵盖了气候、自然带、交通建设、城市...
- 北极燕鸥的迁徙路径:可能利用盛行风和洋流进行长途迁徙,以节省能量。 5. 大气现象与光学效应: - 海市蜃楼的成因:与大气密度的垂直分布有关,"上现蜃景"发生在密度低的空气层在上,"下现蜃景"反之。 6. ...
燕鸥-SQL Fan的迁移者Tern是PostgreSQL独立迁移工具。 它包括传统的迁移以及用于管理数据库代码(例如功能和视图)的单独的可选工作流程。特征多平台独立二进制内置SSH隧道支持数据变量插值到迁移中安装go get -u ...
北极燕鸥选择"S"形线路可能是为了沿着盛行风的方向飞行,节省能量。大圆航线可能距离较短,但并不一定是最节能的路径。 10. **关于北极燕鸥的描述**: 北极燕鸥的迁徙距离远超过3万千米;靠近陆地迁徙可能是为了...
3. 气候与动物迁徙:北极燕鸥是动物界著名的迁徙者,每年在北极和南极之间长途迁徙。它们的迁徙路径与地球上的气候和季节变化密切相关,例如,利用盛行风、洋流等自然现象节省能量。在迁徙过程中,北极燕鸥适应低温...
这篇文档是关于高中教师暑期培训后学员的感言总结,以自然界的四种生命现象——依米花、沙漠玫瑰、胡杨树和北极燕鸥为引,寓言性地阐述了培训带给教师们的深刻启示和教育理念。 首先,依米花象征着坚韧与执着的精神...
8. **气候与洋流**:钦查群岛的环境特征与生物群落,特别是北极燕鸥的迁徙,涉及到气候类型、洋流及其对生物分布的影响。 9. **地理环境与建筑**:穿堂风与民居设计,这体现了地理环境对人类生活的影响,以及如何...
11. 北极燕鸥迁徙规律:北极燕鸥的迁徙路线,甲可能表示向北迁徙去繁殖,乙可能表示向南迁徙去越冬,它们根据季节变化追逐适合生存的环境。 12. 沿岸共同的自然景观:西非海岸和南美洲东岸都具有热带雨林这一自然...
- **腾讯地图**:2013年更名为腾讯地图,以“怀抱梦想,勇于探索”为口号,以北极燕鸥为品牌标识。其提供了矩形地图、卫星地图和街景地图等功能,还推出了如路宝盒子、零流量地图、骑行导航等一系列创新服务。 - *...
基于遗传乌燕鸥算法的同步优化特征选择.docx