- 浏览: 48824 次
- 性别:

- 来自: 武汉
-

文章分类
- 全部博客 (49)
- java基础 (9)
- mysql (1)
- oracle (1)
- linux (6)
- struts (0)
- spring (0)
- hibernate (0)
- struts2 (1)
- javascript (1)
- jquery (1)
- extjs (0)
- css (0)
- 架构 (6)
- 版本控制(svn、git) (1)
- resin (0)
- jboss (0)
- nginx (0)
- 模板技术(freemarker、velocity ) (0)
- android (0)
- 搜索(lucene、solr) (0)
- 工作流jbpm (0)
- webservice (4)
- ejb3 (6)
- java图表技术 (3)
- 构建与部署(ant 、maven) (0)
- 生活感悟 (1)
- 开发资源 (1)
- java分布式 (7)
最新评论
-
daunty:
其实不一定的,闲的时候可以关掉多余的服务器就好了哦,水平架构不 ...
由12306.cn谈谈网站性能技术 -
iamicebergs:
写得很好,有见解~
由12306.cn谈谈网站性能技术
hadoop集群环境搭建
- 博客分类:
- java分布式
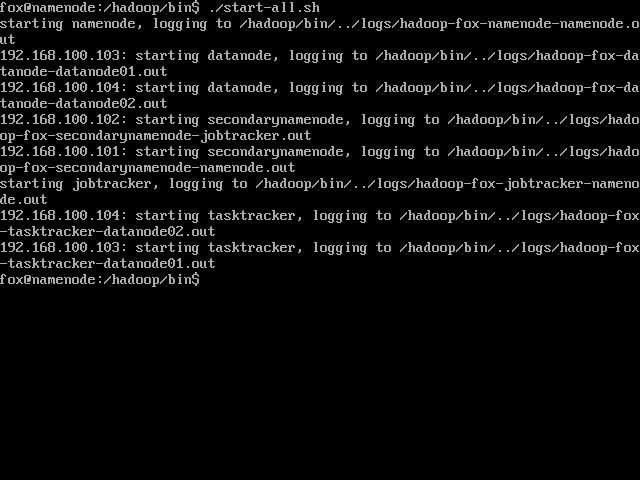
听说Hadoop很久了,今天开始尝试自己搭建一个集群来玩玩,同时学习下Linux各种操作。 主要参考资料当然是官方文档了: Hadoop 集群搭建:http://hadoop.apache.org/common/docs/r0.19.2/cn/cluster_setup.html Hadoop 快速入门:http://hadoop.apache.org/common/docs/r0.19.2/cn/quickstart.html 采用的操作系统是 Ubuntu 11.04.03 64-bit Server。 通过VMware 来创建虚拟网络,这也是现实问题,没有那么多机器啊 预计的设计是这样,4台虚拟机:NameServer, JobTracker, DataNode01, DataNode02。 主机为Win7。 首先安装系统,这个没有什么好说的,VMware有Easy Install,中间偶尔干涉一下,就完事了。 然后安装必须的软件,第一个就是JAVA,Hadoop推荐使用Sun公司的Java, 但是用apt-get install java, 只有openjdk之类的。于是上网搜了半天,找到一篇文章(http://blog.csdn.net/ansomray/article/details/5825096),根据其说明,添加apt source,再重新安装,命令如下: 然后设置JAVA_HOME: 在Win7中下载下来后,问题就来了,怎么从Ubuntu Server中访问Win7的东西,这玩意儿只有命令行啊。继续搜索,发现是通过mount 的方式来处理: 先在mnt下建立一个目录,然后把Win7中共享的文件mount 到那个目录上,这样就可以访问了。命令如下: 最后当然是建立Hadoop目录,解压弄下来的文件,我下载的是.tar.gz文件,所以命令如下: 这样,基本的软件准备就搞定了,下面就是拷贝装好的第一台虚拟机,再复制三台出来,分别按照预定各自命名,然后就是组建网络了。 软件准备好了,开始搭建网络。 我用的是VMware WorkStation 6.5,而VMware提供了三种网络支持:Bridge, Nat, Host Only。 关于VMware的网络概念,我严重参考了这篇文章:深入理解VMware虚拟网络(http://wangchunhai.blog.51cto.com/225186/381225) 简单来说,我需要这4台虚拟机能上网(Internet),同时相互能互联,并且能够与主机互联。拓扑结构可以参考那篇文章,只是其中的一个子集而已(所有虚拟机在一个子网中)。 这个目标我选择使用NAT虚拟网络来实现,这好像也是VMware装机时默认的网络配置。不过在默认情况下,好像只有一台机器可以通过NAT上网,这时就需要手动配置网络了。 首先寻找NAT的网段等信息,先启动一台虚拟机,假设就是NameNode。 使用下面命令来查看: 再看看网关: 得到了默认的网关是192.168.100.2。这里比较奇怪的是我在Win7的网络适配器中看到VmNet8的IP是192.168.100.1,难道网关不是它吗?不过我同时也发现VmNet8也是被禁用了的,很晕。 好了,现在得到了足够的信息,开始进行网络配置: 按照同样的方法来配置其余3台虚拟机即可。这里要注意的是不知道是不是由于我是直接拷贝虚拟机文件的原因,在剩下的三台虚拟机中,eth0不见了,只有eth1,第一次用ifconfig时也只是显示出lo来,后来使用 ifconfig -a才发现有个eth1的。那么在之前的网络配置/etc/network/interfaces 中,就需要添加为eth1的。 网络配好了后,可以通过ssh或ping来检测是否可以相互联通。 接下来就是配置各个服务器了。 本来以为网络搭建好了就可以了,没有想到还有ssh这个东西需要配置免密码访问,这个东西应该也算是软件上互联吧。 ssh免密码本来是很简单的一件事情,不过我折腾了2天 经过无数次的尝试,终于拼出了一条正确的道路: 1. 首先在本地生成空密码的公钥和私钥: 2. 配置本地访问不需要密码: 3. 执行下面的命令来测试本地访问 这里要注意,一定要执行exit来退出ssh,否则这样嵌套执行会搞晕人的。我就这么晕了半天,不知道是在ssh上干活还是直接登录干活。后来在直接操作时把目录切换到了~/.ssh下,这样使用ssh后命令提示符就不一样了。呵呵,菜鸟就是需要多搞一点提示。 4. 把本地的公钥复制到另外的机器(比如192.168.100.102)上: 这个会要求输入102的密码,照提示输入即可。 这里就是折腾了我2天的罪魁祸首,在配置从NameNode(192.168.100.101免密码ssh访问)JobTracker(192.168.100.102)时,一定要在NameNode上执行这个命令。虽然我不知道为什么,但是多次尝试下来,就只有这样才能成功。或许还有其它办法,以后有机会了再研究研究。 5. 在另外一台机器上JobTracker(192.168.100.102),把刚刚拷贝过来的公钥导入authorized_keys 至此就算配置好了ssh从其中一台到另外一台的免密码访问了,把这个操作在各个机器上两两执行,就可以让任意一台机器免密码访问另外任意一台机器了。 如果配置过程中有失误,想要重新来,可以删除.ssh下的所有东西,从头来过。 顺便提一下,我用的是VMware文件拷贝生成的虚拟机,故而所有虚拟机的机器名都是一致的,不知道会有什么问题,所以我在执行上述操作时更改了机器名。 改机器名要改两个地方: /etc/hostname 里面的字符串就是机器名,这个要重启后才能生效。Ubuntu下才是这样的,其它Linux貌似不是这个文件。 /etc/hosts 里面应该是用于访问网络时的一个DNS式的东西,把所有出现原机器名的地方都替换成新的机器名即可。 改好后重启,可以用hostname命令来查看是否成功。 好了,暂时就到这里,明天再研究真正的Hadoop配置文件。 实际配置这部分时,才发现在(一)当中提到的那两个官网文档已经过时了,现在我实际下载的版本是 0.20.203,也即那个stable版本。于是只好找到相应版本的文档来参考了:http://hadoop.apache.org/common/docs/stable/cluster_setup.html 关于Hadoop的配置,按照我的理解,应该有六个文件需要修改,它们都在Hadoop的conf文件夹下,分别是: masters/slavers:配置masters和slavers的机器IP hadoop-env.sh :Hadoop 运行时的环境变量,比如JAVA_HOME,LOG之类的 core-site.xml :Hadoop 的核心配置文件,对应并覆盖core-default.xml 中的配置项 hdfs-site.xml :HDFS 的配置文件,对应并覆盖hdfs-default.xml 中的配置项 mapred-site.xml :Map/Reduce的配置文件,对应并覆盖mapred-default.xml 中的配置项 上面提到的三个*-default.xml 是Hadoop的默认配置项,理论上都是只读的,如果要修改,就通过对应的用户配置文件来覆盖其设置。 1、先配置masters/slavers,NameNode和JobTracker是master, DataNode01和DataNode02是salvers Masters: Slavers: 2、先配置hadoop-env.sh,这里最重要的是配置JAVA_HOME,在我的机器上是这样的: 5、配置mapred-site.xml, 这里配置的东西有很多,都是跟Map-Reduce相关的,不过暂时先配置如下几项: 这些配置都可以在一台机器上搞定,由于Hadoop所有机器是使用同样的配置,所以可以通过scp命令将conf下的内容拷贝复制到各个机器上: 启动 然后,激动人心的时刻到了,所有配置都搞定了,我们可以启动了! 不过还有一件事情必须要先做, 格式化名称空间。 在NameNode上,执行如下命令: 然后就可以执行最后一个命令了: 如果要关闭的话,可以执行 
在其中添加
再来就是获取Hadoop的发行版,这个可以从这里获取稳定发行版。
这里本来是查到的用smbfs,结果Ubuntu说这个好像将从2.6.27内核中删除,不推荐使用,于是采用了cifs。同时好像必须要同时提供username和password,不然就会说writen-protected,mount不上去。
这时,应该会有两个网络设备,eth0和lo,不去管lo,eth0的IP地址是192.168.100.138,这个是通过DHCP自动获取的,由此我们可以得到网段是192.168.100.*。
将eth0相关的内容修改为如下配置:
然后再重启网络服务:
最后再用ifconfig和route来看看是更改过来了,再ping一下sina,看看Internet是否可用:

 ,这就是菜鸟的必经过程了,我算是觉悟了。
,这就是菜鸟的必经过程了,我算是觉悟了。
在网上看到有些使用rsa,不过在Hadoop网站上写的是dsa,就使用dsa吧,生成的密钥文件放在当前用户的.ssh目录下,据我观察,貌似ssh所需要的用户配置文件都存放在这里。执行命令后应该会有 id_dsa, id_dsa.pub两个文件。
其实就是把生成的公钥导入到authorized_keys中,估计ssh 会使用这个文件来进行验证。
如果之前没有使用过ssh连接localhost, 那么会有提示添加localhost到knowhosts中去,然后要求输入密码。第二次及以后的连接就不需要密码了。
6. 从101上连接102:
同样第一次连接的话会询问是否添加机器以及要求输入密码,第二次就不用了。
其余的可以考虑配置日志文件路径:
3、配置core-site.xml,通过文档可以知道这里一般是配置NameNode的地址,即机器名或IP:
4、配置hdfs-site.xml,这里一般配置文件存放路径以及文件权限:
只复制conf是由于我拷贝虚拟机时就已经把JAVA,Hadoop 都安装好后才拷贝的,这样可以保证所有文件在同一目录。
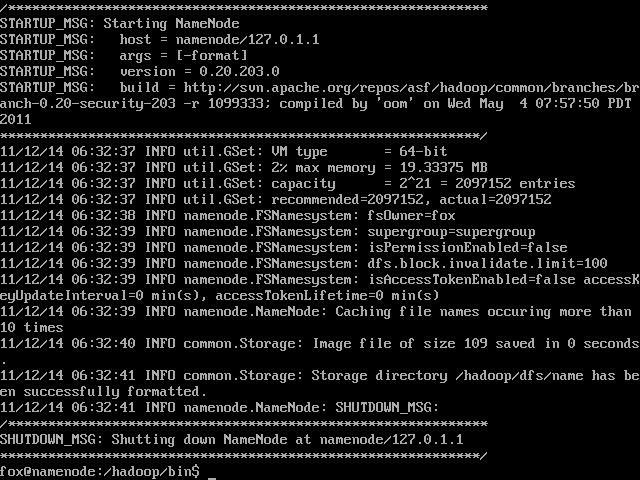
如果一切顺利的话,应该就成功了:


发表评论

-
jms 学习笔记3
2011-09-16 17:25 912Lingo 是一个Spring的子项目,是一种基于Spri ... -
jms 学习笔记2
2011-09-16 17:23 744JMS 异步消息传输,客户端将消息发给消息中介,可以保证消息被 ... -
jms 学习笔记1
2011-09-16 17:22 634今天有学习一下JMS,从一个简单例子开始 名词概念: 消息中 ... -
cxf2.3.3中jaxb-api.jar、jaxws-api.jar与jdk1.6.0_02不兼容问题
2011-09-01 10:29 1019低版本jdk6与cxf中的jaxb-api.jar、j ... -
spring rmi入门示例
2011-08-31 11:18 714一 前言 (转载自http://www.itey ... -
rmi入门实例
2011-08-31 10:15 6581.定义业务接口 package cn.rmi; im ...
相关推荐
Hadoop集群环境搭建
基于Centos7下的hadoop2.7集群的搭建。(在vmware中的2台虚拟机。)
hadoop集群环境的搭建
Hadoop集群环境搭建,实战篇
在一台虚拟机上安装多台linux服务机,并搭建Hadoop集群环境
Linux Info: Ubuntu 16.10 x64 Docker 本身就是基于 Linux 的,所以首先以我的一台服务器做实验。虽然最后跑 wordcount 已经由于内存不足而崩掉,但是之前的过程还是可以参考的。 连接服务器 使用 ssh 命令连接远程...
HADOOP快速入门及搭建集群环境,可以进行搭建试试,文档比较详细
此文档在hadoop集群搭建完毕之后,在集群之外搭建一个hadoop集群的开发环境,用于编写hadoop实际处理程序,还包括了如何提交任务等。整体非常详细,如需要其他hadoop集群搭建资源可以联系我,免费给q:1487954071
脚本搭建hadoop集群 可以自定义主机名和IP地址 可以自定义安装jdk和hadoop(格式为*tar.gz) 注意事项 1、安装完jdk和hadoop请手动source /etc/profile 刷新环境变量 2测试脚本环境为centOS6,其他操作系统会有些...
Hadoop集群架构搭建分析
全程跟着安装配置的一般不会出现问题,jdk版本尽量选择和Hadoop版本相容的,Hadoop版本可以选择较低版本,2.7版本较为稳定,Linux系统版本没有多大要求,一般将Hadoop和jdk版本选择好就行,这个作业较为简单,在安装...
要想深入的学习Hadoop数据分析技术,首要的任务是必须要将hadoop集群环境搭建起来,可以将hadoop简化地想象成一个小软件,通过在各个物理节点上安装这个小软件,然后将其运行起来,就是一个hadoop分布式集群了。...
!
!
hadoop 全套环境搭建指南,三台虚拟机环境准备 linux基础及shell增强 大数据集群环境准备 zookeeper介绍及集群操作 网络编程
3.1 生成密匙 3.2 免密登录 3.3 验证免密登录 3.1 下载并解压 3.2 配置环境变量 3.3 修改配置 3.4 分发程序 3.5 初始化 3.6
大数据技术基础实验报告-Linux环境下hadoop集群的搭建与基本配置