- ТхЈУДѕ: 200682 ТгА
- ТђДтѕФ:

- ТЮЦУЄф: тЇЌС║г
-

ТќЄуФатѕєу▒╗
уцЙтї║уЅѕтЮЌ
- ТѕЉуџёУхёУ«» ( 0)
- ТѕЉуџёУ«║тЮЏ ( 3)
- ТѕЉуџёжЌ«уГћ ( 0)
тГўТАБтѕєу▒╗
- 2014-12 ( 1)
- 2014-08 ( 2)
- 2014-04 ( 1)
- ТЏ┤тцџтГўТАБ...
ТюђТќ░У»ёУ«║
-
18335864773№╝џ
ућетЏйтєЁУЄфСИ╗уаћтЈЉуџё pageoffice ТЈњС╗Хтюеу║┐ТЊЇСйюoffic ...
т╝ђТ║љу╗ёС╗ХDocXт»╝тЄ║Word -
zhudoney№╝џ
ућеС║єУ┐ЎуДЇжфїУ»ЂуџёWEBAPIТђјС╣ѕУ░ЃућетЋі№╝Ъ ТѕЉТїЅСйауџёТќ╣Т│ЋтєЎС║є№╝їУ░Ѓуће ...
WebApiТјЦтЈБт«ЅтЁеУ«цУ»ЂРђћРђћHTTPС╣ІТЉўУдЂУ«цУ»Ђ -
songshijia88888№╝џ
ТГБтюеТЅЙУ┐ЎТќ╣жЮбуџёУхёТќЎ№╝їтЙѕТюЅуће№╝Ђ
androidУ«┐жЌ«У┐юуеІТЋ░ТЇ«т║Њ -
sqcjy111№╝џ
У┐љУАїС╣Ітљју╗ЊТъюУ┐ўТ▓АТ▓АТюЅтЄ║ТЮЦТђјС╣ѕтЏъС║ІтЋі№╝Ъ
т░єsqlserverТЋ░ТЇ«ућЪТѕљXMLТќЄС╗Х -
zhonglushu№╝џ
Т▓АуюІтѕ░С╗ђС╣ѕт«ъжЎЁТёЈС╣Ѕ
androidУ«┐жЌ«У┐юуеІТЋ░ТЇ«т║Њ
┬а┬а┬а┬а┬аУ«║тЮЏСИіТђ╗уюІтѕ░ТюЅС║║У»┤ТЪљТЪљТЋ░ТЇ«т║ЊтЄауЎЙСИЄуџёТЋ░ТЇ«жЄЈТђјС╣ѕТЈљжФўТЪЦУ»бжђЪт║дуГЅуГЅ№╝їТюђУ┐ЉТГБтЦйтЂџС║єСИђСИфтЁ│С║јУ┐ЎТќ╣жЮбуџёУАеу╗ЊТъёС╝ўтїќ№╝їтѕєС║Фу╗ЎтцДт«Х№╝їтИїТюЏт»╣тцДт«ХТюЅтИ«тіЕсђѓТюгС║║С╣ЪСИЇТў»С╗ђС╣ѕтцДуЅЏ№╝їтЈфтИїТюЏС║њуЏИС║цТхЂтГдС╣асђѓС╗ЁСИ║тѕєС║Ф№╝їСИЇтќютІ┐тќи№╝їУ░бУ░бсђѓ
┬а ┬а УеђтйњТГБС╝а№╝їСИІжЮбУ»┤СИђСИІтЁиСйЊуџёт«ъуј░тЈіТЋѕТъюсђѓ
┬а ┬а т║ћућетю║ТЎ»№╝џ
┬а ┬а СИђт╝аТЌЦт┐ЌУАе№╝їУ«░тйЋТ»ЈтцЕ150wтидтЈ│уџёТЋ░ТЇ«жЄЈ№╝їт║ћућеУдЂТ▒ѓтГўтѓе6СИфТюѕС╗ЦСИі№╝їтѕЎтЁ▒У«А27000wтидтЈ│уџёТЋ░ТЇ«УДёТеА№╝їУАеС╗јУ«ЙУ«АтѕЮТюЪт░▒УђЃУЎЉтѕ░ТЋ░ТЇ«тбъжЋ┐С╝џтЙѕт┐Ф№╝їТЅђС╗ЦжЄЄућеуџёТў»ТЌЦт┐ЌУАеуџётйбС╝╝У«░тйЋуџётєЁт«╣№╝їтЅЇуФ»т║ћућеСИЇжюђтњїС╗╗СйЋУАетЁ│УЂћ№╝їтЈфжюђС╗јУ┐Ўт╝аУАеСИГУ»╗тЈќТЋ░ТЇ«тЇ│тЈ»сђѓт║ћућеСИ╗УдЂТў»Та╣ТЇ«СИЇтљїуџёТЮАС╗ХУ┐ЏУАїТЌЦт┐ЌТЋ░ТЇ«уџёТБђу┤бтњїу╗ЪУ«АтіЪУЃй№╝ѕТЌХжЌ┤ТЮАС╗Х№╝їТЮАС╗Х1№╝їТЮАС╗Х2№╝Ѕ№╝їТЋ░ТЇ«ТБђу┤бтѕєжАхТўЙуц║сђѓ
┬а ┬а тјЪтДІтцёуљєТќ╣т╝Ј№╝їтЇЋУАетЈїTOPУ»ГтЈЦуџёТќ╣т╝ЈсђѓСйєТў»жџЈуЮђТЋ░ТЇ«жЄЈуџётбъжЋ┐№╝їТБђу┤бжђЪт║дУХіТЮЦУХіТЁб№╝їУђЂТў»тЄ║уј░ТЪЦУ»бУХЁТЌХуџёжЌ«жбў№╝їтљїТЌХућ▒С║јтЈїTOPТќ╣т╝ЈтѕєжАхуџёжЎљтѕХ№╝їт»╝УЄ┤жАхТЋ░УХіТјЦУ┐Љт░ЙжАхУХіу╝ЊТЁбуџёуј░У▒Асђѓ
┬а ┬а СИ║С║єУДБтє│С╗ЦСИіуџёжЌ«жбў№╝їт»╣тјЪтДІТЋ░ТЇ«УАеуџёу╗ЊТъёУ┐ЏУАїС║єтдѓСИІуџёУ░ЃТЋ┤сђѓ
┬а
ТЋ░ТЇ«т║Њт»╣С║јуЎЙСИЄу║ДтѕФуџёТЋ░ТЇ«жЄЈ№╝їтЊЇт║ћжђЪт║дУ┐ўТў»тЙѕт┐Фуџё№╝їСйєТў»т»╣С║јСИіС║┐у║ДтѕФуџёТЋ░ТЇ«жЄЈУђїУеђ№╝їућ▒С║јтГўтюеуЮђтцДжЄЈуџёуБЂуЏўIO№╝їТЅђС╗ЦжђЪт║дуџёжЎЇСйјСИЇТў»у║┐ТђДуџё№╝їУђїТў»тЉѕуј░ТїЄТЋ░у║ДуџёСИІжЎЇ№╝їТЅђС╗Ц№╝їС╝ўтїќТќ╣Т│ЋуџёСИГт┐ЃТђЮТЃ│т░▒Тў»тЄЈт░Љу╗ЊТъюжЏєуџёТЋ░жЄЈ№╝їТЈљжФўТЋ░ТЇ«т║ЊТюгУ║ФуџётЊЇт║ћТЌХжЌ┤сђѓ
жњѕт»╣С╗ЦСИіуџёТЃ│Т│Ћ№╝їтѕє4СИфТГЦжфцт»╣ТЋ░ТЇ«т║ЊуџётГўтѓеу╗ЊТъётЈіТЋ░ТЇ«уџёжђЅтЈќТќ╣т╝ЈУ┐ЏУАїС╗ЦСИІуџёС╝ўтїќсђѓ
┬а
1.тѕєУђїТ▓╗С╣І
т»╣С║јтЄатЇЃСИЄућџУЄ│С║┐у║ДуџёТЋ░ТЇ«№╝їТЃ│тюетдѓТГцт║ътцДуџётЪ║уАђТЋ░ТЇ«СИГтЂџтѕ░т┐ФжђЪтЊЇт║ћуџёУ»╗тЈќТЋ░ТЇ«№╝їТ»ћУЙЃтЈ»УАїуџёТќ╣Т│Ћт░▒Тў»тцДУђїтїќт░ЈуџёТђЮТЃ│сђѓ
тцДУђїтїќт░ЈуџёТђЮТЃ│т»╣С║ју«ЌТ│ЋТЮЦУ»┤№╝їТђјТаижђЅтЈќРђют░ЈРђЮУ┐ЎСИђТдѓт┐хуџёуЋїт«џт░▒тЙѕтЁ│жћ«С║є№╝їт»╣С║јтдѓТГцт║ътцДуџёУАе№╝їтЈЉуј░Т»ЈтцЕС║ДућЪуџёТЋ░ТЇ«жЄЈуЏИт»╣УЙЃуе│т«џ№╝їтЪ║Тюгу╗┤ТїЂтюе150wтидтЈ│Т»ЈтцЕ№╝їУ┐ЎСИфТЋ░ТЇ«жЄЈт»╣С║јТЋ░ТЇ«т║ЊТЮЦУ»┤Тў»СИфтЈ»С╗Цт┐ФжђЪУ┐ЏУАїтЊЇт║ћуџёТЋ░ТЇ«УДёТеАсђѓУђїжђЅТІЕуџётцфт░Ј№╝їТ»ћтдѓУ»┤ТїЅт░ЈТЌХУ«Ау«ЌуџёТќ╣т╝Ј№╝їУЎйуёХтЇЋСйЇуџёТЋ░ТЇ«жЄЈтЄЈт░ЉС║є24тђЇ№╝їСйєТў»уЏИт»╣С║јТЋ░ТЇ«жЄЈС╗ј150wтѕ░6wуџёТЌХжЌ┤ТЈљтЇЄУ┐юТ»ћ1т╝аУАетѕ░24т╝аУАеуџёу╗┤ТіцТђДТЈљжФўС╗ўтЄ║уџёС╗БС╗итцџ№╝їТЅђС╗ЦТюђтљјтє│т«џжЄЄућеТїЅТЌЦтѕєУАеуџёТќ╣т╝ЈУ┐ЏУАїтѕєУАе№╝їУ┐ЎТаиС╗Ц3СИфТюѕуџёТЋ░ТЇ«ТЮЦУ»┤№╝їС╗ј13500wуџёСИђт╝атцДУАеУйгтїќСИ║150wуџё90т╝ат░ЈУАесђѓУ┐ЎТаитЈ»С╗ЦТћ╣тќёТюђу╗ѕу╗ЊТъюуџёжђЅтЈќжђЪт║дтцДтцДТЈљтЇЄсђѓ
┬а
2.тљѕУђїтЄ╗С╣І
у╗ЈУ┐ЄС╗ЦСИіуџёТГЦжфц№╝їт░єтцДУАетѕњтѕєСИ║тцџСИфт░ЈУАе№╝їУЎйуёХт»╣С║јТюђу╗ѕжђЅтЈќТЮЦУ»┤№╝їтЈфТў»С╗јТЪљСИђСИфт░ЈУАеСИГжђЅтЈќТюђу╗ѕуџёТЋ░ТЇ«№╝їСйєТў»У┐ўТў»ТЌаТ│ЋжЂ┐тЁЇуггСИђТгАУ┐ЏУАїТЅђТюЅТХЅтЈіУАеуџёУй«тЙфУ«Ау«ЌУАїТЋ░уџёУ┐ЄуеІ№╝їУ┐ЎТаиСИјС╗ЦтЅЇуџёТќ╣т╝ЈуЏИТ»ћТЋ░ТЇ«жЄЈТ▓АТюЅтЄЈт░ЉтЈЇУђїтбътіаС║єу«ЌТ│ЋуџётцЇТЮѓт║д№╝їТЅђС╗ЦтЇЋтЇЋтѕєУђїТ▓╗С╣ІуџёТќ╣Т│ЋТЌаТ│ЋУДБтє│У«Ау«ЌУАїТЋ░тЈіжАхТЋ░уџёУй«тЙфС║ДућЪуџёТЌХжЌ┤т╝ђжћђсђѓ
жњѕт»╣жђЅтЈќждќжАхТЌХуџёУАїТЋ░У«Ау«Ќ№╝їтЈ»С╗ЦтЈЇтЁХжЂЊУђїУАїС╣І№╝їжЄЄућетљѕУђїтЄ╗С╣ІуџёТќ╣т╝Ј№╝їтюеТЋ░ТЇ«тѕЮтДІтїќуџёТЌХтђЎУ┐ЏУАїС╗ЦТЌЦСИ║тЇЋСйЇуџёжђЅтЈќТЮАС╗Ху╗ЪУ«А№╝їт░єу╗ЪУ«Ау╗ЊТъютѕєу▒╗тГўТћЙС║јТюѕУАеСИГ№╝їУ┐ЎТаитюежђЅтЈќТЌХт»╣С║јТЋ┤ТЌЦуџётї║жЌ┤тЈфУдЂуЏ┤ТјЦС╗јТюѕУАеСИГУ»╗тЈќтЊЇт║ћТЌЦТюЪуџёТЋ░ТЇ«ТЮАуЏ«т░▒тЈ»С╗ЦС║єсђѓ
уЏ«тЅЇТЌЦт┐ЌуџёТЪЦУ»бТЮАС╗ХТюЅ3у╗ё№╝їтѕєтѕФТў»ТЌЦТюЪ№╝їТЮАС╗Х1№╝ѕтЏ║т«џ№╝Ѕ№╝їТЮАС╗Х2№╝ѕтЏ║т«џ№╝ЅсђѓУ┐ЎТаиС╗ЦТЌЦТюЪСИ║тѕњтѕєСЙЮТЇ«№╝їт░▒т░єТБђу┤бТЮАС╗Хућ▒3у╗ёу╝Ет░ЈСИ║2у╗ё№╝їтЄЈт░ЉС║єТјњтѕЌу╗ётљѕуџёТЋ░жЄЈ№╝їтљїТЌХТЮАС╗Х1тњїТЮАС╗Х2уџёТюѕУАетГўтѓежЄЄућеС║єРђюжИАтЁћтљїуг╝жЌ«жбўРђЮуџёжђєУ┐љу«Ќ№╝їжђџУ┐ЄжђЅтЈќТЮАС╗ХуА«т«џТЪљСИђу▒╗тѕФуџёТќ╣т╝ЈУ«Ау«ЌТЪљСИђТЮАС╗Ху╗ётљѕуџёС┐АТЂ»ТЮАТЋ░сђѓУ┐ЎТаи№╝їт«ъжЎЁуџёт«ъжфїТЋ░ТЇ«УАеТўј№╝їтЈ»С╗ЦУ«▓150wуџёТЋ░ТЇ«жЄЈу╝Ет░Јуџё4тЇЃтидтЈ│уџёТЋ░ТЇ«УАїТЋ░сђѓт»╣С║јУАеуџёТЋ░уЏ«ТЮЦУ»┤Т»ЈСИфТюѕС║ДућЪСИђт╝а№╝їС╗БС╗итЙѕт░Јсђѓ
CREATE TABLE monthtable
(
ТЮАС╗Х1№╝ї
┬а ┬а ┬а ┬а ТЮАС╗Х2№╝ї
┬а ┬а ┬а ┬а ТЋ░жЄЈ№╝ї
┬а ┬а ┬а ┬а ТЌЦТюЪ
)
┬а
У┐ЎТаит░▒ТюЅТЋѕтю░жЂ┐тЁЇС║єтюеУ«Ау«ЌТђ╗УАїТЋ░ТЌХУй«тЙфТЅђТюЅТЌЦУАеуџётцДжЄЈУ»╗тЈќтиЦСйю№╝їУіѓуюЂС║єТЌХжЌ┤сђѓ
3.ТіўтЇіУ«Ау«Ќ
С╗ЦСИіуџё2жЃе№╝їтЈ»С╗ЦУДБтє│тцДУАе№╝їтЈіУй«тЙфТЌХУђЌУ┤╣тцДжЄЈТЌХжЌ┤уџёжЌ«жбў№╝їСйєТў»т»╣С║јУхитДІТЌЦТюЪТЮЦУ»┤№╝їтдѓТъюТў»т«їТЋ┤уџёСИђтцЕтЈ»С╗ЦуЏ┤ТјЦС╗јТюѕУАеСИГУ»╗тЈќТЋ░ТЇ«№╝їУІЦСИЇТў»т«їТЋ┤уџёСИђтцЕ№╝їтѕЎУ┐ўТў»жюђУдЂУ»╗тЈќТЌЦУАе№╝їУЎйуёХТюђтцџтЈфжюђУдЂУ»╗тЈќСИцт╝аТЌЦУАе№╝їСйєТў»У┐ўТў»С╝џТхфУ┤╣СИђС║ЏТЌХжЌ┤сђѓ
т»╣С║јУАеуџёжА║т║ЈжђЅтЈќТЮЦУ»┤№╝їућ▒С║јТЋ░ТЇ«т║ЊТюгУ║ФуџёТю║тѕХжЎљтѕХ№╝їТЅђС╗ЦТЌаТ│ЋжЂ┐тЁЇуџёжюђУдЂУ┐ЏУАїТГБжђєСИцТгАТЋ░ТЇ«уџёжђЅтЈќ№╝їТЅђС╗Цуј░тюетЈ»С╗ЦтЂџуџёт░▒Тў»тЄЈт░ЉждќТгАжђЅтЈќуџёУАїТЋ░тЈітЄЈт░ЉТјњт║ЈТЊЇСйюуџёТгАТЋ░сђѓ
тЄ║С║јС╗ЦСИіуџёуЏ«уџё№╝їуј░т░єТЌЦУАеуџёТЋ░ТЇ«жђЅтЈќТќ╣т╝ЈС┐«Тћ╣СИ║ТіўтЇіУ«Ау«ЌуџёТќ╣т╝ЈсђѓтЇ│жђЅтЈќУАїС╣ІтЅЇ№╝їтЁѕУ«Ау«ЌТЅђжђЅтЈќуџёУАїТў»тљдУХЁУ┐ЄУАежђЅтЈќТЋ░ТЇ«УАїТЋ░уџёСИђтЇі№╝їУІЦТюфУХЁУ┐ЄС╗ЇжЄЄућетјЪтДІуџёТЋ░ТЇ«жђЅтЈќТќ╣т╝Ј№╝їУІЦУХЁУ┐Є№╝їтѕЎжђџУ┐Єтђњт║ЈжђЅтЈќуџёТќ╣т╝ЈС╗јТЋ░ТЇ«т░ЙжЃеТЈљтЈќТЋ░ТЇ«№╝їУ┐ЎТаитйЊжђЅтј╗уџёт░ЙУАї<Тђ╗УАїТЋ░СИђтЇіТЌХ№╝їжђЅтЈќТЌХжЌ┤СИјтјЪТў»уЏИтљї№╝їтйЊжђЅтЈќуџёт░ЙУАї>Тђ╗УАїТЋ░уџёСИђтЇіТЌХ№╝їућ▒С║јт░ЉС║єСИђТгАТјњт║Ј№╝їт╣ХСИћжђЅтЈќуџёУАїТЋ░С╣ЪтЄЈт░ЉС║є№╝їТЅђС╗ЦжђЪт║дС╝ўС║јтјЪтДІуџёжђЅтЈќТќ╣т╝Ј№╝їУђїСИћУХіТјЦУ┐ЉТЋ░ТЇ«т░ЙжЃежђЅтЈќуџёжђЪт║дУХіт┐Ф№╝їт░ЙжАхуџёжђЪт║дтњїждќжАхуЏИтљї№╝їУ┐ЎУдЂТ»ћтјЪтДІуџёТќ╣т╝ЈжђЪт║дТЈљтЇЄтЙѕтцџтђЇсђѓ
У┐ЎТаи№╝їТЅФТЈЈуџёу╗ЊТъюжЏєТюђтцДтђ╝С╗ЁСИ║тјЪтДІуџёСИђтЇі№╝їУђїСИћт░ЉС║єСИђТгАтцДу╗ЊТъюжЏєуџёТјњт║ЈУ┐ЄуеІ№╝їТЌХжЌ┤тцДтцДТЈљжФўсђѓ
тјЪтДІТќ╣т╝ЈТхЂуеІтЏЙ№╝џ

ТіўСИГУ«Ау«ЌТхЂуеІтЏЙ№╝џ
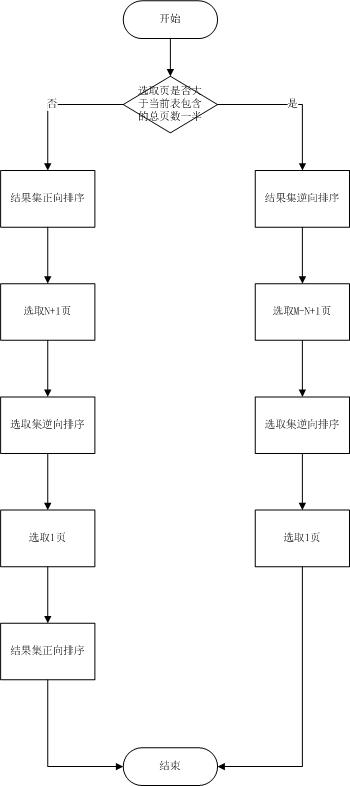
┬а
4.тѕЏт╗║у╗ЪУ«АУАе
тюеТЋ░ТЇ«т║ЊуџёТЋ░ТЇ«жђЅтЈќУ┐ЄуеІСИГтѕЏСИГжЌ┤у╗ЪУ«АУАетГўтѓеу╗ЊТъю№╝їућеС║јтГўтЈќтюеТ»ЈСИфТЌЦУАеСИГжђЅтЈќуџёТЋ░ТЇ«УАїТЋ░№╝їтЈфУдЂС╝атЁЦуџётЈѓТЋ░СИЇТў»жђЅТІЕждќжАх№╝їжѓБС╣ѕТЋ░ТЇ«т║ЊжЃйуЏ┤ТјЦС╗ју╗ЪУ«АУАеСИГУ»╗тЈќУАїТЋ░№╝їУ┐ЎТаит░▒СИЇућеТ»ЈСИђжАхжЃйУ«Ау«ЌТђ╗УАїТЋ░№╝їУіѓуюЂтцДжЄЈТЌХжЌ┤сђѓ
┬а
С┐АТЂ»ТЪЦУ»бТхЂуеІтЏЙ№╝џ
С╝ўтїќтЅЇ№╝џ

┬а
С╝ўтїќтљј№╝џ
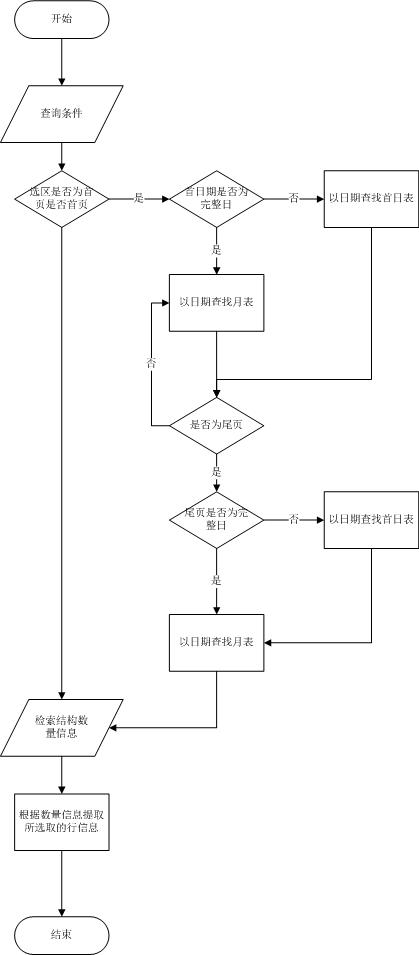
С╗ЦСИіТЋ░ТЇ«жђЅтЈќУ┐ЄуеІт░ЂУБЁтюетГўтѓеУ┐ЄуеІСИГу╗ЪСИђУ┐ЏУАїсђѓ
┬а
у╗ЪУ«АС╝ўтїќТхІУ»ЋТЋ░ТЇ«№╝џ
ТЋ░ТЇ«жЄЈ┬а14141687
тЇЋСйЇ№╝ѕms№╝Ѕ
ТхІУ»ЋУ«Ау«ЌТю║жЁЇуй«№╝џ
CPU№╝џInter(R) ┬аCeleron(R) CPU 430 @ 1.80GHz 1.79GHz
Memory:2G №╝ѕУ«Ау«ЌТю║тГўтюетЁХС╗ќТюЇтіА№╝їSQL Server тЈ»тѕЕућеуџётєЁтГўт«ъжЎЁтюе1GтидтЈ│№╝Ѕ
Т»ЈУ┐ЏУАїСИђТгАТЋ░ТЇ«ТБђу┤бТЊЇСйю№╝їтЮЄжЄЇтљ»SQL ServerТюЇтіАсђѓ
С╝ўтїќтЅЇтљјТЋ░ТЇ«т║ЊтЮЄти▓т╗║уФІуЏИтЁ│у┤бт╝Ћ№╝їу┤бт╝ЋтюеУ┐ЎжЄїт░▒СИЇтѕЌтЄ║С║єсђѓ
ућ▒С║јТЋ░ТЇ«т║ЊтГўтюеТЋ░ТЇ«жбёуЃГуџёжўХТ«х№╝їТЅђС╗Цт╣│тЮЄтђ╝уџёУ«Ау«ЌТќ╣т╝ЈСИ║тј╗ТјЅТюђтцДтђ╝тљјУ«Ау«Ќуџёт╣│тЮЄтђ╝№╝їУАеСИГу║бУЅ▓СИ║тј╗ТјЅуџёТхІУ»ЋТЌХжЌ┤сђѓ
┬а
|
у╗ЪУ«Ат▒ъТђД |
Тќ╣ТАѕ |
у╗ЪУ«АтѕЌ |
ТЋ░ТЇ«1 |
ТЋ░ТЇ«2 |
ТЋ░ТЇ«3 |
ТЋ░ТЇ«4 |
ТЋ░ТЇ«5 |
т╣│тЮЄ |
|
ТЮАС╗Х1 |
С╝ўтїќтЅЇ |
14141687 |
51724 |
33373 |
31803 |
30563 |
37223 |
33241 |
|
ТЮАС╗Х1 |
С╝ўтїќтљј |
14141687 |
347 |
17 |
16 |
17 |
20 |
18 |
|
Т»ћСЙІ |
┬а |
1 |
150 |
1964 |
1988 |
1798 |
1862 |
1847 |
|
ТЮАС╗Х2 |
С╝ўтїќтЅЇ |
14141687 |
52340 |
35465 |
35760 |
37856 |
34970 |
36013 |
|
ТЮАС╗Х2 |
С╝ўтїќтљј |
14141687 |
383 |
23 |
17 |
16 |
20 |
19 |
|
Т»ћСЙІ |
┬а |
1 |
137 |
1542 |
2104 |
2366 |
1749 |
1896 |
|
ТїЅТЌЦу╗ЪУ«А |
С╝ўтїќтЅЇ |
14141687 |
57796 |
45356 |
45710 |
44520 |
45586 |
45293 |
|
ТїЅТЌЦу╗ЪУ«А |
С╝ўтїќтљј |
14141687 |
727 |
14 |
17 |
16 |
13 |
15 |
|
Т»ћСЙІ |
┬а |
1 |
80 |
3240 |
2689 |
2783 |
3507 |
3020 |
|
ТїЅТюѕу╗ЪУ«А |
С╝ўтїќтЅЇ |
14141687 |
55180 |
42130 |
42063 |
42780 |
42493 |
42367 |
|
ТїЅТюѕу╗ЪУ«А |
С╝ўтїќтљј |
14141687 |
380 |
10 |
7 |
13 |
7 |
9 |
|
Т»ћСЙІ |
┬а |
1 |
145 |
4213 |
6009 |
3291 |
6070 |
4708 |
┬а
тГўтѓеуЕ║жЌ┤тЇаућеу╗ЪУ«А№╝џ
ТЋ░ТЇ«жЄЈ14141687
тЇЋСйЇ№╝ѕKB№╝Ѕ
ТЋ░ТЇ«ТЌЦТюЪтї║жЌ┤2011-11-25┬а~┬а2011-12-29
|
у╗ЪУ«Ат▒ъТђД |
тЇаућеуЕ║жЌ┤ |
ТЋ░ТЇ«уЕ║жЌ┤ |
у┤бт╝ЋуЕ║жЌ┤ |
УАеТЋ░жЄЈ |
|
С╝ўтїќтЅЇ |
2150480 |
1593688 |
557792 |
1 |
|
С╝ўтїќтљј |
2057688 |
1521752 |
535936 |
19 |
|
Т»ћСЙІ |
0.9569 |
0.9549 |
0.9608 |
19 |
┬а
С┐АТЂ»ТЪЦУ»бС╝ўтїќТхІУ»ЋТЋ░ТЇ«№╝џ
┬а
ТЋ░ТЇ«жЄЈ┬а14141687
тЇЋСйЇ№╝ѕms№╝Ѕ
Т»ЈжАхУАїТЋ░№╝џ50
┬а
ућ▒С║јТЋ░ТЇ«т║ЊтГўтюеТЋ░ТЇ«жбёуЃГуџёжўХТ«х№╝їТЅђС╗Цт╣│тЮЄтђ╝уџёУ«Ау«ЌТќ╣т╝ЈСИ║тј╗ТјЅТюђтцДтђ╝тљјУ«Ау«Ќуџёт╣│тЮЄтђ╝№╝їУАеСИГу║бУЅ▓СИ║тј╗ТјЅуџёТхІУ»ЋТЌХжЌ┤сђѓ
┬а
ТЮАС╗Хт▒ъТђДСИ║№╝џ
1.у╗ЪУ«АТЌХжЌ┤№╝џ2011-11-16┬а0:00:00┬а~┬а2011-12-30┬а0:00:00
2.ТЮАС╗Х1№╝џxxxx
3.ТЮАС╗Х2№╝џxxxx
┬а
┬а
┬а
ТхІУ»Ћ1№╝џС╗ЦТЌХжЌ┤СИ║уГЏжђЅТЮАС╗Х
|
Тќ╣ТАѕ |
жђЅтЈќжАх |
у╗ЪУ«АтѕЌ |
ТЋ░ТЇ«1 |
ТЋ░ТЇ«2 |
ТЋ░ТЇ«3 |
ТЋ░ТЇ«4 |
ТЋ░ТЇ«5 |
т╣│тЮЄ |
|
С╝ўтїќтЅЇ |
ждќжАх |
14141687 |
89426 |
64220 |
61466 |
62850 |
54046 |
60646 |
|
С╝ўтїќтљј |
ждќжАх |
14141687 |
1253 |
113 |
234 |
167 |
200 |
179 |
|
Т»ћСЙІ |
┬а |
1 |
71 |
568 |
263 |
376 |
270 |
339 |
|
С╝ўтїќтЅЇ |
угг2жАх |
14141687 |
34420 |
6423 |
6480 |
6350 |
6433 |
6422 |
|
С╝ўтїќтљј |
угг2жАх |
14141687 |
416 |
16 |
14 |
20 |
13 |
16 |
|
Т»ћСЙІ |
┬а |
1 |
83 |
401 |
483 |
318 |
495 |
401 |
|
С╝ўтїќтЅЇ |
угг3жАх |
14141687 |
34020 |
5546 |
6446 |
6543 |
6486 |
6255 |
|
С╝ўтїќтљј |
угг3жАх |
14141687 |
537 |
13 |
17 |
20 |
14 |
16 |
|
Т»ћСЙІ |
┬а |
1 |
63 |
427 |
379 |
327 |
463 |
391 |
|
С╝ўтїќтЅЇ |
угг141417жАх |
14141687 |
36640 |
9853 |
9833 |
10833 |
11160 |
10420 |
|
С╝ўтїќтљј |
угг141417жАх |
14141687 |
2213 |
504 |
653 |
720 |
517 |
599 |
|
Т»ћСЙІ |
┬а |
1 |
17 |
20 |
15 |
15 |
22 |
18 |
|
С╝ўтїќтЅЇ |
т░ЙжАх |
14141687 |
37546 |
11443 |
11456 |
11290 |
11366 |
11389 |
|
С╝ўтїќтљј |
т░ЙжАх |
14141687 |
590 |
23 |
17 |
17 |
17 |
19 |
|
Т»ћСЙІ |
┬а |
1 |
64 |
498 |
674 |
664 |
669 |
599 |
┬а
┬а
ТхІУ»Ћ2№╝џС╗ЦТЌХжЌ┤тњїТЮАС╗Х1СИ║уГЏжђЅТЮАС╗Х
|
Тќ╣ТАѕ |
жђЅтЈќжАх |
у╗ЪУ«АтѕЌ |
ТЋ░ТЇ«1 |
ТЋ░ТЇ«2 |
ТЋ░ТЇ«3 |
ТЋ░ТЇ«4 |
ТЋ░ТЇ«5 |
т╣│тЮЄ |
|
С╝ўтїќтЅЇ |
ждќжАх |
66355 |
79003 |
42870 |
40183 |
49413 |
42683 |
43787 |
|
С╝ўтїќтљј |
ждќжАх |
66355 |
1136 |
226 |
163 |
203 |
104 |
174 |
|
Т»ћСЙІ |
┬а |
1 |
70 |
190 |
247 |
243 |
411 |
252 |
|
С╝ўтїќтЅЇ |
угг2жАх |
66355 |
34773 |
12690 |
12686 |
13026 |
12726 |
12782 |
|
С╝ўтїќтљј |
угг2жАх |
66355 |
916 |
40 |
30 |
30 |
30 |
33 |
|
Т»ћСЙІ |
┬а |
1 |
38 |
317 |
423 |
434 |
424 |
387 |
|
С╝ўтїќтЅЇ |
угг3жАх |
66355 |
35746 |
12986 |
14296 |
12816 |
13880 |
13495 |
|
С╝ўтїќтљј |
угг3жАх |
66355 |
820 |
33 |
37 |
40 |
40 |
38 |
|
Т»ћСЙІ |
┬а |
1 |
44 |
394 |
386 |
320 |
347 |
355 |
|
С╝ўтїќтЅЇ |
угг664жАх |
66355 |
41143 |
17736 |
17763 |
18763 |
17743 |
18001 |
|
С╝ўтїќтљј |
угг664жАх |
66355 |
997 |
37 |
40 |
38 |
35 |
37 |
|
Т»ћСЙІ |
┬а |
1 |
41 |
479 |
444 |
494 |
507 |
487 |
|
С╝ўтїќтЅЇ |
т░ЙжАх |
66355 |
42463 |
18916 |
20100 |
20156 |
20093 |
19816 |
|
С╝ўтїќтљј |
т░ЙжАх |
66355 |
1117 |
96 |
97 |
100 |
99 |
98 |
|
Т»ћСЙІ |
┬а |
1 |
38 |
197 |
207 |
202 |
203 |
202 |
┬а
ТхІУ»Ћ3№╝џС╗ЦТЌХжЌ┤тњїТЮАС╗Х2СИ║уГЏжђЅТЮАС╗Х
|
Тќ╣ТАѕ |
жђЅтЈќжАх |
у╗ЪУ«АтѕЌ |
ТЋ░ТЇ«1 |
ТЋ░ТЇ«2 |
ТЋ░ТЇ«3 |
ТЋ░ТЇ«4 |
ТЋ░ТЇ«5 |
т╣│тЮЄ |
|
С╝ўтїќтЅЇ |
ждќжАх |
4829945 |
84673 |
60546 |
60303 |
58516 |
58556 |
59480 |
|
С╝ўтїќтљј |
ждќжАх |
4829945 |
2033 |
193 |
184 |
220 |
160 |
189 |
|
Т»ћСЙІ |
┬а |
1 |
42 |
314 |
328 |
266 |
366 |
315 |
|
С╝ўтїќтЅЇ |
угг2жАх |
4829945 |
39156 |
15083 |
15526 |
15193 |
15210 |
15253 |
|
С╝ўтїќтљј |
угг2жАх |
4829945 |
713 |
23 |
27 |
30 |
23 |
26 |
|
Т»ћСЙІ |
┬а |
1 |
55 |
656 |
575 |
506 |
662 |
587 |
|
С╝ўтїќтЅЇ |
угг3жАх |
4829945 |
36806 |
15053 |
15353 |
16230 |
15333 |
15493 |
|
С╝ўтїќтљј |
угг3жАх |
4829945 |
727 |
20 |
20 |
24 |
17 |
20 |
|
Т»ћСЙІ |
┬а |
1 |
51 |
753 |
768 |
676 |
902 |
775 |
|
С╝ўтїќтЅЇ |
угг48283жАх |
4829945 |
44203 |
23950 |
24126 |
23386 |
23293 |
23689 |
|
С╝ўтїќтљј |
угг48283жАх |
4829945 |
1314 |
507 |
500 |
510 |
503 |
505 |
|
Т»ћСЙІ |
┬а |
1 |
34 |
47 |
48 |
46 |
46 |
47 |
|
С╝ўтїќтЅЇ |
т░ЙжАх |
4829945 |
46203 |
24390 |
25596 |
25400 |
24333 |
24930 |
|
С╝ўтїќтљј |
т░ЙжАх |
4829945 |
2012 |
1087 |
987 |
963 |
1000 |
1009 |
|
Т»ћСЙІ |
┬а |
1 |
23 |
22 |
26 |
27 |
24 |
25 |
┬а
┬а
┬а
┬а
┬а
┬а
┬а
┬а
ТхІУ»Ћ4№╝џС╗ЦТЌХжЌ┤тњїТЮАС╗Х1сђЂТЮАС╗Х2СИ║уГЏжђЅТЮАС╗Х
|
Тќ╣ТАѕ |
жђЅтЈќжАх |
у╗ЪУ«АтѕЌ |
ТЋ░ТЇ«1 |
ТЋ░ТЇ«2 |
ТЋ░ТЇ«3 |
ТЋ░ТЇ«4 |
ТЋ░ТЇ«5 |
т╣│тЮЄ |
|
С╝ўтїќтЅЇ |
ждќжАх |
66353 |
78130 |
30340 |
28080 |
28210 |
27090 |
28430 |
|
С╝ўтїќтљј |
ждќжАх |
66353 |
1330 |
120 |
130 |
90 |
107 |
112 |
|
Т»ћСЙІ |
┬а |
1 |
59 |
253 |
216 |
314 |
254 |
254 |
|
С╝ўтїќтЅЇ |
угг2жАх |
66353 |
35150 |
12660 |
12553 |
12736 |
13250 |
12780 |
|
С╝ўтїќтљј |
угг2жАх |
66353 |
848 |
20 |
23 |
20 |
20 |
21 |
|
Т»ћСЙІ |
┬а |
1 |
42 |
633 |
546 |
637 |
663 |
609 |
|
С╝ўтїќтЅЇ |
угг3жАх |
66353 |
34933 |
12996 |
12916 |
14226 |
12843 |
13246 |
|
С╝ўтїќтљј |
угг3жАх |
66353 |
833 |
27 |
25 |
22 |
29 |
26 |
|
Т»ћСЙІ |
┬а |
1 |
42 |
482 |
517 |
647 |
443 |
510 |
|
С╝ўтїќтЅЇ |
угг664жАх |
66353 |
73570 |
27630 |
27096 |
26276 |
26053 |
26734 |
|
С╝ўтїќтљј |
угг664жАх |
66353 |
1305 |
190 |
189 |
210 |
209 |
200 |
|
Т»ћСЙІ |
┬а |
1 |
57 |
146 |
144 |
126 |
125 |
134 |
|
С╝ўтїќтЅЇ |
т░ЙжАх |
66353 |
70176 |
32090 |
31000 |
32010 |
32110 |
31803 |
|
С╝ўтїќтљј |
т░ЙжАх |
66353 |
1076 |
183 |
187 |
182 |
181 |
184 |
|
Т»ћСЙІ |
┬а |
1 |
66 |
176 |
166 |
176 |
178 |
173 |
┬а
┬а
ТхІУ»Ћу╗ЊТъютѕєТъљ№╝џ
С╗ју╗ЪУ«АтіЪУЃйТЮЦуюІ№╝їТЋ░ТЇ«т║ЊуџётЊЇт║ћжђЪт║дТЈљтЇЄтЙѕтцД№╝їС╗ј30уДњтидтЈ│ТЈљтЇЄтѕ░20Т»ФуДњтидтЈ│№╝їжђЪт║дТюђтцДТЈљтЇЄС║є4700тцџтђЇ№╝їТЋѕТъюТўјТўЙсђѓ
С╗јТЪЦУ»бтіЪУЃйТЮЦуюІ№╝їТЋ░ТЇ«т║ЊуџётЊЇт║ћжђЪт║дТЈљтЇЄТ▓АТюЅу╗ЪУ«АтіЪУЃйТўјТўЙ№╝їСйєТў»С╣ЪС╗ј30тцџуДњТЈљжФўтѕ░200Т»ФуДњтидтЈ│№╝їТЈљтЇЄС║єу║д400-500тђЇтидтЈ│сђѓ
тјЪтЏатѕєТъљ№╝џу╗ЪУ«АтіЪУЃйтѕЕућеТюгу«ЌТ│ЋтЈ»С╗Цт«їтЁежЂ┐тЁЇт»╣С║јтјЪтДІТЋ░ТЇ«УАеуџёУ»╗тЈќТЊЇСйю№╝їТЅђС╗Цт»╣С║јУ»ЦтіЪУЃйТЮЦУ»┤№╝їтЈфТў»ТЊЇСйютЄат╝а4-5тЇЃТЮАТЋ░ТЇ«уџёУАе№╝їТЅђС╗ЦтЊЇт║ћТЌХжЌ┤т┐Ф№╝їСйєТў»т»╣С║јТЪЦУ»бтіЪУЃйТЮЦУ»┤№╝їТюђу╗ѕУ┐ћтЏъу╗ЎућеТѕиуџёС┐АТЂ»Тў»тЁиСйЊуџёТХѕТЂ»№╝їТЅђС╗ЦТЌаТ│ЋжЂ┐тЁЇуџёУдЂт»╣ТЋ░ТЇ«УАеУ┐ЏУАїТЪЦТЅЙ№╝їТЅђС╗ЦТЌХжЌ┤СИіТХѕУђЌуџётцџС║єС║ЏсђѓСйєТў»тЪ║ТюгСИіС╣ЪжЃйТјДтѕХтюе200Т»ФуДњС╗ЦСИІт░▒тЈ»С╗ЦтЂџтЄ║тЊЇт║ћсђѓ
┬а
С╗БС╗и№╝џ
ТюгТю║тѕХжЄЄућеуџёТў»тцЇТЮѓт║дТЇбТЌХжЌ┤уџёТќ╣Т│Ћ№╝їтЇ│ТЋ░ТЇ«т║Њу╗ЊТъётњїжђЅтЈќТќ╣т╝ЈуџётцЇТЮѓт║дтбътіаС║є№╝їС╗јУђїтЄЈт░ЉС║єтюежђЅтЈќТЌХТХѕУђЌуџёТЌХжЌ┤№╝їт╣ХСИћТюЅСИђжЃетѕєу╗ЪУ«АтиЦСйюТЈљтѕ░С║єжђЅтЈќТЊЇСйюС╗ЦтцќУ┐ЏУАї№╝їт░єТЌХжЌ┤тѕєтЮЌ№╝їС╗јУђїтюеТёЪУДЅСИіжЎЇСйјС║єтЊЇт║ћТЌХжЌ┤сђѓ
т»╣С║ј№╝їТЌЦУАетЈіТюѕУАеуџёТЋ░ТЇ«тАФтЁЁтиЦСйютЈ»С╗ЦСй┐ућеТЋ░ТЇ«т║ЊуџёСйюСИџ№╝їтюеСИџтіАСИЇу╣Ђт┐ЎуџёТЌХжЌ┤У┐ЏУАїтјЪтДІУАеуџётѕњтѕєтиЦСйюсђѓ
т»╣С║јТхІУ»ЋТЋ░ТЇ«ТЮЦУ»┤№╝ї1тЇЃ4уЎЙСИЄуџёТЋ░ТЇ«тѕЮтДІтїќжюђУдЂтЇЂтѕєжњЪтидтЈ│уџёТЌХжЌ┤У┐ЏУАї№╝їтЈ»С╗ЦжђЅТІЕтЄїТЎе1уѓ╣т╝ђтДІ№╝їУ┐ЎТаиТюђжЋ┐1-2СИфт░ЈТЌХт░▒тЈ»С╗ЦТііТЋ░ТЇ«тцёуљєт«їТ»Ћсђѓт╣ХСИћтцДжЄЈУАеуџётѕЮтДІтїќтЈфтюеуггСИђТгАТЏ┤ТЇбТЋ░ТЇ«т║Њу╗ЊТъёТЌХС║ДућЪ№╝їС╗ЦтљјТ»ЈтцЕУ┐ЏУАїуџёТЋ░ТЇ«у╗ЪУ«АтиЦСйютЪ║ТюгСИітЈфТюЅ200wтидтЈ│№╝їУ┐ЎСИфТЋ░жЄЈу║ДтЈфжюђУдЂтЄатѕєжњЪт░▒тЈ»С╗Цт«їТѕљ№╝їт«їтЁеСИЇтй▒тЊЇУй»С╗ХТ»ЈтцЕуџёТГБтИИСй┐ућесђѓ
┬а┬а┬а┬а┬а┬а┬а┬а┬а┬а┬а┬а┬а┬а┬а┬а┬а┬а┬а┬а┬а┬а┬а┬а┬а┬а┬а┬а┬а┬а┬а┬а┬а┬а┬а┬а┬а┬а┬а┬а┬а┬а┬а┬а┬а --УйгУЄ│№╝џmagician547уџёСИЊТаЈ


- 2012-06-30 09:38
- ТхЈУДѕ 1414
- У»ёУ«║(0)
- тѕєу▒╗:ТЋ░ТЇ«т║Њ
- ТЪЦуюІТЏ┤тцџ
тЈЉУАеУ»ёУ«║

-
WebApiТјЦтЈБт«ЅтЁеУ«цУ»ЂРђћРђћHTTPС╣ІТЉўУдЂУ«цУ»Ђ
2014-12-05 14:07 66675┬а┬а┬а┬а┬а┬а ТЉўУдЂУ«┐жЌ«У«цУ»ЂТў»СИђуДЇтЇЈУ««УДёт«џуџёWebТюЇтіАтЎеућеТЮЦ ... -
т╝ђТ║љу╗ёС╗ХDocXт»╝тЄ║Word
2014-08-18 11:01 70161сђЂСй┐ућеDocxТЏ┐ТЇбWordТеАТЮ┐жЄїС╣дуГЙжЄїтєЁт«╣уџёСИђСИфТќ╣Т│Ћ ... -
.netжЄїСй┐ућеMSCommТјДС╗ХтЈЉућЪуЪГС┐А
2014-04-13 23:00 2729СИђ.MSComm32.ocxТјДС╗Х№╝ѕС╗ЦСИІу«ђуД░MSCommТјДС╗Х ... -
IISжЃеуй▓уџёуйЉуФЎТђДУЃйС╝ўтїќтЄаСЙІ
2014-03-09 20:51 0┬а┬аIISжЃеуй▓уџёуйЉуФЎ№╝їуггСИђУ«┐жЌ«уџёТЌХтђЎуЅ╣тѕФуџёТЁб№╝їСИ╗УдЂтјЪтЏаТў»уће ... -
ТГБтѕЎУАеУЙЙт╝ЈУ»ГТ│ЋУДётѕЎтйњТђ╗сђљУйгсђЉ
2013-10-30 09:01 1006СИђсђЂТГБтѕЎУАеУЙЙт╝ЈТдѓт┐х№╝џ тюеУ«Ау«ЌТю║уДЉтГдСИГ№╝їТў»ТїЄСИђСИфућеТЮЦТЈЈУ┐░ТѕќУђЁтї╣жЁЇ ... -
jQuery EasyUIС╣Іdatagrid
2012-08-19 10:12 524281. <table id="mTab&quo ... -
SQL Server 2008 Reporting Servicesт«ъуј░тї┐тљЇУ«┐жЌ«ТіЦУАе
2011-10-06 15:26 8454т«ъуј░SQL Server 2008 Reporting Ser ... -
SQL Server 2008 Reporting Servicesтї┐тљЇУ«┐жЌ«ТіЦУАе
2011-10-06 15:07 2т«ъуј░SQL Server 2008 Reporting Ser ... -
Сй┐ућеC#т»╣Active Directory№╝ѕТ┤╗тіеуЏ«тйЋ№╝ЅуџёТЊЇСйю
2011-06-12 12:03 7296Active Directory№╝ѕТ┤╗тіеуЏ«тйЋ№╝ЅТў»Windows ...
уЏИтЁ│ТјеУЇљ
т║ћућетю║ТЎ»№╝џСИђт╝аТЌЦт┐ЌУАе№╝їУ«░тйЋТ»ЈтцЕ150wтидтЈ│уџёТЋ░ТЇ«жЄЈ№╝їт║ћућеУдЂТ▒ѓтГўтѓе6СИфТюѕС╗ЦСИі№╝їтѕЎтЁ▒У«А27000wтидтЈ│уџёТЋ░ТЇ«УДёТеА№╝їУАеС╗јУ«ЙУ«АтѕЮТюЪт░▒УђЃУЎЉтѕ░ТЋ░ТЇ«тбъжЋ┐С╝џтЙѕт┐Ф№╝їТЅђС╗ЦжЄЄућеуџёТў»ТЌЦт┐ЌУАеуџётйбС╝╝У«░тйЋуџётєЁт«╣№╝їтЅЇуФ»т║ћућеСИЇжюђтњїС╗╗СйЋУАетЁ│УЂћ№╝їтЈф...
DataShowТў»СИђТгЙтЪ║С║ј.net Framework2.0уџёMicrosoft SQL ServerТЋ░ТЇ«т║Њт╗║ТеАтиЦтЁи№╝їтиЦтЁитЁежЃежЄЄућеC#С╗БуаЂт«їТѕљсђѓУ»ЦтиЦтЁиТЌетюетѕЕућеУЄфт«џС╣ЅУАетГЌтЁИуџётіЪУЃйТЮЦУ«ЙУ«Ат╝║тцДуџёТЋ░ТЇ«т║ЊТјДС╗ХТѕќУђЁжАхжЮб№╝їтЄЈт░Љт╝ђтЈЉтЉеТюЪтњїС╗БуаЂжЄЈсђѓ ТюгтиЦтЁитЁиТюЅтдѓСИІ...
У┐ЎС║ЏТЋ░ТЇ«УАеу╗ЊтљѕтЏЙС╣дждєТЋ░ТЇ«т║ЊСИГуџёС║ћСИфтГўтѓеУ┐ЄуеІ№╝їтЇ│т«ъуј░С║єТЎ«жђџтЏЙС╣дждєуџётцДжЃетѕєтіЪУЃйсђѓтдѓУ»╗УђЁтђЪжўЁтЏЙС╣дтіЪУЃй№╝ѕExecute RBorrowBook 'У»╗УђЁтЈи','тЏЙС╣дтѕєу▒╗тЈи'№╝Ѕ№╝їУ»╗УђЁтйњУ┐ўтЏЙС╣дтіЪУЃй№╝ѕExecute RReturnBook 'У»╗УђЁтЈи','тЏЙС╣дтѕєу▒╗тЈи'...
SQLServerТЋ░ТЇ«т║ЊУ«ЙУ«А ТЋ░ТЇ«т║ЊУ«ЙУ«А Р╝ђсђЂТЋ░ТЇ«т║ЊУ«ЙУ«Ауџёт┐ЁУдЂТђД тюет«ъжЎЁуџёУй»С╗ХжА╣РйгСИГ№╝їтдѓТъюу│╗у╗ЪСИГжюђУдЂтГўтѓеуџёТЋ░ТЇ«жЄЈРйљУЙЃР╝ц№╝їжюђУдЂУ«ЙУ«АуџёУАеРйљУЙЃтцџ№╝їУАеСИјУАеС╣ІжЌ┤уџётЁ│у│╗РйљУЙЃтцЇТЮѓ№╝їжѓБТѕЉС╗гт░▒жюђУдЂУ┐ЏРЙЈУДё УїЃуџёТЋ░ТЇ«т║ЊУ«Йуй«сђѓтдѓТъюСИЇу╗ЈУ┐Є...
У┐ЎС║ЏТЋ░ТЇ«УАеу╗ЊтљѕтЏЙС╣дждєТЋ░ТЇ«т║ЊСИГуџёС║ћСИфтГўтѓеУ┐ЄуеІ№╝їтЇ│т«ъуј░С║єТЎ«жђџтЏЙС╣дждєуџётцДжЃетѕєтіЪУЃйсђѓтдѓУ»╗УђЁтђЪжўЁтЏЙС╣дтіЪУЃй№╝ѕExecute RBorrowBook 'У»╗УђЁтЈи','тЏЙС╣дтѕєу▒╗тЈи'№╝Ѕ№╝їУ»╗УђЁтйњУ┐ўтЏЙС╣дтіЪУЃй№╝ѕExecute RReturnBook 'У»╗УђЁтЈи','тЏЙС╣дтѕєу▒╗тЈи'...
У┐ЎС║ЏТЋ░ТЇ«УАеу╗ЊтљѕтЏЙС╣дждєТЋ░ТЇ«т║ЊСИГуџёС║ћСИфтГўтѓеУ┐ЄуеІ№╝їтЇ│т«ъуј░С║єТЎ«жђџтЏЙС╣дждєуџётцДжЃетѕєтіЪУЃйсђѓтдѓУ»╗УђЁтђЪжўЁтЏЙС╣дтіЪУЃй№╝ѕExecute RBorrowBook 'У»╗УђЁтЈи','тЏЙС╣дтѕєу▒╗тЈи'№╝Ѕ№╝їУ»╗УђЁтйњУ┐ўтЏЙС╣дтіЪУЃй№╝ѕExecute RReturnBook 'У»╗УђЁтЈи','тЏЙС╣дтѕєу▒╗тЈи'...
С╗јТЋ░ТЇ«уџёт║ћућеУДњт║дТЮЦуюІ№╝їСИђСИфТіЦУАеСИГуџёТЋ░ТЇ«тЙђтЙђТЮЦУЄфС║јтцџСИфСИЇтљїуџёУАеСИГ№╝їтдѓСйЋТЈљжФўТіЦУАеуџёУ«ЙУ«АТЋѕујЄтЉб№╝ЪУДєтЏЙТў»УДБтє│У┐ЎС║ЏжЌ«жбўуџёСИђуДЇТюЅТЋѕТЅІТ«хсђѓТюгуФатЁежЮбУ«▓У┐░ТюЅтЁ│УДєтЏЙу«АуљєуџётєЁт«╣сђѓ сђљУдЂуѓ╣сђЉ ТЋ░ТЇ«у«АуљєСИГтГўтюеуџёжЌ«жбўтњїУДБтє│ТђЮУи» ...
У┐ЎС║ЏТЋ░ТЇ«УАеу╗ЊтљѕтЏЙС╣дждєТЋ░ТЇ«т║ЊСИГуџёС║ћСИфтГўтѓеУ┐ЄуеІ№╝їтЇ│т«ъуј░С║єТЎ«жђџтЏЙС╣дждєуџётцДжЃетѕєтіЪУЃйсђѓтдѓУ»╗УђЁтђЪжўЁтЏЙС╣дтіЪУЃй№╝ѕExecute RBorrowBook 'У»╗УђЁтЈи','тЏЙС╣дтѕєу▒╗тЈи'№╝Ѕ№╝їУ»╗УђЁтйњУ┐ўтЏЙС╣дтіЪУЃй№╝ѕExecute RReturnBook 'У»╗УђЁтЈи','тЏЙС╣дтѕєу▒╗тЈи'...
SQL Server ТЋ░ТЇ«т║ЊУ«ЙУ«А СИђсђЂТЋ░ТЇ«т║ЊУ«ЙУ«Ауџёт┐ЁУдЂТђД тюет«ъжЎЁуџёУй»С╗ХжА╣уЏ«СИГ№╝їтдѓТъюу│╗у╗ЪСИГжюђУдЂтГўтѓеуџёТЋ░ТЇ«жЄЈТ»ћУЙЃтцД№╝їжюђУдЂУ«ЙУ«АуџёУАеТ»ћУЙЃтцџ№╝їУАе СИјУАеС╣ІжЌ┤уџётЁ│у│╗Т»ћУЙЃтцЇТЮѓ№╝їжѓБТѕЉС╗гт░▒жюђУдЂУ┐ЏУАїУДёУїЃуџёТЋ░ТЇ«т║ЊУ«Йуй«сђѓтдѓТъюСИЇу╗ЈУ┐ЄТЋ░ТЇ«т║Њуџё ...
жђџУ┐ЄТюгУ»ЙуеІуџётГдС╣а№╝їСй┐тГдућЪТјїТЈАтЁ│у│╗ ТЋ░ТЇ«т║ЊуџётЪ║ТюгтјЪуљє№╝їтГдС╝џSQL Serverу«АуљєТЋ░ТЇ«уџёТќ╣Т│Ћ№╝џT- SQLУ»ГУеђсђЂТЋ░ТЇ«т║ЊтњїУАеуџётѕЏт╗║сђЂТЋ░ТЇ«т║ЊуџёТЪЦУ»бсђЂУДєтЏЙтњїу┤бт╝ЋсђЂТЋ░ТЇ«т«їТЋ┤ТђДуџёт«ъуј░сђЂтГўтѓеУ┐Є уеІтњїУДдтЈЉтЎеуГЅ№╝їт╣ХСИћУЃйтцЪтюеSQL ServerТЈљСЙЏ...
у│╗у╗ЪТћ»ТїЂтцџуДЇТЋ░ТЇ«т║ЊУ┐ъТјЦТќ╣т╝Ј№╝їтїЁТІгSQL ServerсђЂMySQLуГЅ№╝їтЈ»Уй╗ТЮЙт║ћт»╣СИЇтљїтю║ТЎ»СИІуџёТЋ░ТЇ«тГўтѓежюђТ▒ѓсђѓтљїТЌХ№╝їу│╗у╗ЪжЄЄућеТеАтЮЌтїќУ«ЙУ«АТђЮТЃ│№╝їтљётіЪУЃйТеАтЮЌС╣ІжЌ┤уЏИт»╣уІгуФІ№╝їТќ╣СЙ┐т╝ђтЈЉУђЁУ┐ЏУАїС║їТгАт╝ђтЈЉтњїт«џтѕХсђѓ тюетіЪУЃйТќ╣жЮб№╝їASPжђџућеС┐АТЂ»...
15.5сђђтѕЕућетѕєтИЃт╝Јт╣ХУАїУ«Ау«Ќт«ъуј░тцДТЋ░ТЇ«жЄЈуџёжФўТђДУЃйУ┐љу«Ќ 15.6сђђт░Ју╗Њ угг16уФасђђMySQL Cluster 16.0сђђт╝ЋУеђ 16.1сђђMySQL ClusterС╗Іу╗Ї 16.2сђђMySQL Clusterуј»тбЃТљГт╗║ 16.3сђђMySQL ClusterжЁЇуй«У»ду╗єС╗Іу╗Ї№╝ѕconfig.ini№╝Ѕ 16.4сђђ...
у│╗у╗ЪтЪ║С║јASP.NETТАєТъХТъёт╗║№╝їжЄЄућеC#СйюСИ║СИ╗УдЂт╝ђтЈЉУ»ГУеђ№╝їу╗ЊтљѕSQL ServerТЋ░ТЇ«т║ЊУ┐ЏУАїТЋ░ТЇ«тГўтѓетњїтцёуљєсђѓтЅЇуФ»жЄЄућеHTMLсђЂCSSтњїJavaScriptуГЅТіђТю»У┐ЏУАїжАхжЮбУ«ЙУ«АтњїС║цС║њт«ъуј░сђѓТЋ┤СйЊТъХТъёТИЁТЎ░сђЂуе│т«џтЈ»жЮа№╝їТўЊС║ју╗┤ТіцтњїТЅЕт▒Ћсђѓ
У«ЙУ«АтиЦСйюС╗╗тіАтЈітиЦСйюжЄЈуџёУдЂТ▒ѓсђћтїЁТІгУ»ЙуеІУ«ЙУ«АУ«Ау«ЌУ»┤ТўјС╣д(У«║ТќЄ)сђЂтЏЙу║ИсђЂ" "т«ъуЅЕТаитЊЂуГЅсђЋ№╝џ " " " "Та╣ТЇ«У«ЙУ«АтєЁт«╣тњїУдЂТ▒ѓУ┐ЏУАїжюђТ▒ѓтѕєТъљ№╝їтѕєТъљтЄ║у│╗у╗ЪуџёСИ╗УдЂтіЪУЃйтњїУ«ЙУ«АжЄЇуѓ╣сђѓ " "Та╣ТЇ«жюђТ▒ѓтѕєТъљуџётєЁт«╣тюет░Ју╗ёСИГтљѕуљєтѕњтѕєТеАтЮЌсђѓ " ...
У«ЙУ«АтиЦСйюС╗╗тіАтЈітиЦСйюжЄЈуџёУдЂТ▒ѓсђћтїЁТІгУ»ЙуеІУ«ЙУ«АУ«Ау«ЌУ»┤ТўјС╣д(У«║ТќЄ)сђЂтЏЙу║ИсђЂ" "т«ъуЅЕТаитЊЂуГЅсђЋ№╝џ " " " "Та╣ТЇ«У«ЙУ«АтєЁт«╣тњїУдЂТ▒ѓУ┐ЏУАїжюђТ▒ѓтѕєТъљ№╝їтѕєТъљтЄ║у│╗у╗ЪуџёСИ╗УдЂтіЪУЃйтњїУ«ЙУ«АжЄЇуѓ╣сђѓ " "Та╣ТЇ«жюђТ▒ѓтѕєТъљуџётєЁт«╣тюет░Ју╗ёСИГтљѕуљєтѕњтѕєТеАтЮЌсђѓ " ...
У«ЙУ«АтиЦСйюС╗╗тіАтЈітиЦСйюжЄЈуџёУдЂТ▒ѓсђћтїЁТІгУ»ЙуеІУ«ЙУ«АУ«Ау«ЌУ»┤ТўјС╣д(У«║ТќЄ)сђЂтЏЙу║ИсђЂ" "т«ъуЅЕТаитЊЂуГЅсђЋ№╝џ " " " "Та╣ТЇ«У«ЙУ«АтєЁт«╣тњїУдЂТ▒ѓУ┐ЏУАїжюђТ▒ѓтѕєТъљ№╝їтѕєТъљтЄ║у│╗у╗ЪуџёСИ╗УдЂтіЪУЃйтњїУ«ЙУ«АжЄЇуѓ╣сђѓ " "Та╣ТЇ«жюђТ▒ѓтѕєТъљуџётєЁт«╣тюет░Ју╗ёСИГтљѕуљєтѕњтѕєТеАтЮЌсђѓ " ...
уєЪу╗ЃТјїТЈАуЏИтЁ│ТЋ░ТЇ«" "т║ЊуџётѕєТъљсђЂУ«ЙУ«АсђЂт«ъуј░У┐ЄуеІ№╝їС╗ЦтЈітюеТГцТЋ░ТЇ«т║ЊтЪ║уАђС╣ІСИіт»╣тГўтѓеУ┐ЄуеІтЈіУДдтЈЉтЎе " "уџёУ«ЙУ«АтЈіт«ъуј░Тќ╣Т│Ћсђѓ " "2№╝јУ«ЙУ«АтєЁт«╣тњїУдЂТ▒ѓ№╝ѕтїЁТІгтјЪтДІТЋ░ТЇ«сђЂТіђТю»тЈѓТЋ░сђЂТЮАС╗ХсђЂУ«ЙУ«АУдЂТ▒ѓуГЅ№╝Ѕ№╝џ " " " "У«ЙУ«АтєЁт«╣№╝џ " "ТЪљ...
2. **SQL ServerТЋ░ТЇ«т║Њ**№╝џжЄЄућеSQL ServerСйюСИ║тљјуФ»ТЋ░ТЇ«т║Њ№╝їТћ»ТїЂтцДТЋ░ТЇ«жЄЈуџётГўтѓетњїТЪЦУ»бсђѓ 3. **ућеТѕитЈІтЦйуџёуЋїжЮб**№╝џУ«ЙУ«Ау«ђТ┤ЂТўјС║єуџёућеТѕиуЋїжЮб№╝їжЎЇСйјућеТѕиТЊЇСйюжџЙт║д№╝їТЈљжФўућеТѕиСйЊжфїсђѓ 4. **жФўт║дтЈ»т«џтѕХТђД**№╝џу│╗у╗ЪТЈљСЙЏуЂхТ┤╗уџё...
У«ЙУ«АтиЦСйюС╗╗тіАтЈітиЦСйюжЄЈуџёУдЂТ▒ѓсђћтїЁТІгУ»ЙуеІУ«ЙУ«АУ«Ау«ЌУ»┤ТўјС╣д(У«║ТќЄ)сђЂтЏЙу║ИсђЂ" "т«ъуЅЕТаитЊЂуГЅсђЋ№╝џ " " " "Та╣ТЇ«У«ЙУ«АтєЁт«╣тњїУдЂТ▒ѓУ┐ЏУАїжюђТ▒ѓтѕєТъљ№╝їтѕєТъљтЄ║у│╗у╗ЪуџёСИ╗УдЂтіЪУЃйтњїУ«ЙУ«АжЄЇуѓ╣сђѓ " "Та╣ТЇ«жюђТ▒ѓтѕєТъљуџётєЁт«╣тюет░Ју╗ёСИГтљѕуљєтѕњтѕєТеАтЮЌсђѓ " ...