一、算法设计
1、设rand(s,t)返回[s,t]之间的随机小数,利用该函数在一个半径为R的圆内找随机n个点,并给出时间复杂度分析。
思路:这个使用数学中的极坐标来解决,先调用[s1,t1]随机产生一个数r,归一化后乘以半径,得到R*(r-s1)/(t1-s1),然后在调用[s2,t2]随机产生一个数a,归一化后得到角度:360*(a-s2)/(t2-s2)
2、为分析用户行为,系统常需存储用户的一些query,但因query非常多,故系统不能全存,设系统每天只存m个query,现设计一个算法,对用户请求的query进行随机选择m个,请给一个方案,使得每个query被抽中的概率相等,并分析之,注意:不到最后一刻,并不知用户的总请求量。
思路:如果用户查询的数量小于m,那么直接就存起来。如果用户查询的数量大于m,假设为m+i,那么在1-----m+i之间随机产生一个数,如果选择的是前面m条查询进行存取,那么概率为m/(m+i),如果选择的是后面i条记录中的查询,那么用这个记录来替换前面m条查询记录的概率为m/(m+i)*(1-1/m)=(m-1)/(m+i),当查询记录量很大的时候,m/(m+i)== (m-1)/(m+i),所以每个query被抽中的概率是相等的。
3、C++ STL中vector的相关问题:
(1)、调用push_back时,其内部的内存分配是如何进行的?
(2)、调用clear时,内部是如何具体实现的?若想将其内存释放,该如何操作?
vector的工作原理是系统预先分配一块CAPACITY大小的空间,当插入的数据超过这个空间的时候,这块空间会让某种方式扩展,但是你删除数据的时候,它却不会缩小。
vector为了防止大量分配连续内存的开销,保持一块默认的尺寸的内存,clear只是清数据了,未清内存,因为vector的capacity容量未变化,系统维护一个的默认值。
有什么方法可以释放掉vector中占用的全部内存呢?
标准的解决方法如下
template < class T >
void ClearVector( vector< T >& vt )
{
vector< T > vtTemp;
veTemp.swap( vt );
}
事实上,vector根本就不管内存,它只是负责向内存管理框架acquire/release内存,内存管理框架如果发现内存不够了,就malloc,但是当vector释放资源的时候(比如destruct), stl根本就不调用free以减少内存,因为内存分配在stl的底层:stl假定如果你需要更多的资源就代表你以后也可能需要这么多资源(你的list, hashmap也是用这些内存),所以就没必要不停地malloc/free。如果是这个逻辑的话这可能是个trade-off
一般的STL内存管理器allocator都是用内存池来管理内存的,所以某个容器申请内存或释放内存都只是影响到内存池的剩余内存量,而不是真的把内存归还给系统。这样做一是为了避免内存碎片,二是提高了内存申请和释放的效率——不用每次都在系统内存里寻找一番。
二、系统设计
正常用户端每分钟最多发一个请求至服务端,服务端需做一个异常客户端行为的过滤系统,设服务器在某一刻收到客户端A的一个请求,则1分钟内的客户端任何其它请求都需要被过滤,现知每一客户端都有一个IPv6地址可作为其ID,客户端个数太多,以至于无法全部放到单台服务器的内存hash表中,现需简单设计一个系统,使用支持高效的过滤,可使用多台机器,但要求使用的机器越少越好,请将关键的设计和思想用图表和代码表现出来。
三、求一个全排列函数:
如p([1,2,3])输出:
[123]、[132]、[213]、[231]、[321]、[312]
求一个组合函数。
方法1:依次从字符串中取出一个字符作为最终排列的第一个字符,对剩余字符组成的字符串生成全排列,最终结果为取出的字符和剩余子串全排列的组合。
#include <iostream>
#include <string>
using namespace std;
void permute1(string prefix, string str)
{
if(str.length() == 0)
cout << prefix << endl;
else
{
for(int i = 0; i < str.length(); i++)
permute1(prefix+str[i], str.substr(0,i)+str.substr(i+1,str.length()));
}
}
void permute1(string s)
{
permute1("",s);
}
int main(void)
{
//method1, unable to remove duplicate permutations.
permute1("abc");
return 0;
}
优点:该方法易于理解,但无法移除重复的排列,如:s="ABA",会生成两个“AAB”。
方法2:利用交换的思想,具体见实例,但该方法不如方法1容易理解。
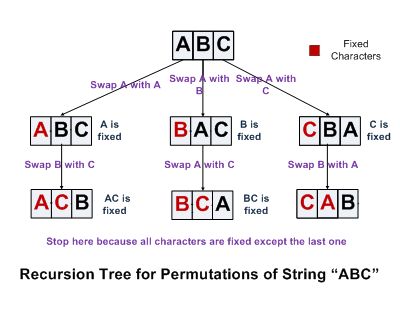
我们以三个字符abc为例来分析一下求字符串排列的过程。首先我们固定第一个字符a,求后面两个字符bc的排列。当两个字符bc的排列求好之后,我们把第一个字符a和后面的b交换,得到bac,接着我们固定第一个字符b,求后面两个字符ac的排列。现在是把c放到第一位置的时候了。记住前面我们已经把原先的第一个字符a和后面的b做了交换,为了保证这次c仍然是和原先处在第一位置的a交换,我们在拿c和第一个字符交换之前,先要把b和a交换回来。在交换b和a之后,再拿c和处在第一位置的a进行交换,得到cba。我们再次固定第一个字符c,求后面两个字符b、a的排列。
既然我们已经知道怎么求三个字符的排列,那么固定第一个字符之后求后面两个字符的排列,就是典型的递归思路了。
基于前面的分析,我们可以得到如下的参考代码:
void Permutation(char* pStr, char* pBegin)
{
assert(pStr && pBegin);
//if(!pStr || !pBegin)
//return ;
if(*pBegin == '\0')
printf("%s\n",pStr);
else
{
char temp;
for(char* pCh = pBegin; *pCh != '\0'; pCh++)
{
if(pCh != pBegin && *pCh == *pBegin) //为避免生成重复排列,当不同位置的字符相同时不再交换
continue;
temp = *pCh;
*pCh = *pBegin;
*pBegin = temp;
Permutation(pStr, pBegin+1);
temp = *pCh;
*pCh = *pBegin;
*pBegin = temp;
}
}
}
int main(void)
{
char str[] = "aba";
Permutation(str,str);
return 0;
}
如p([1,2,3])输出:
[1]、[2]、[3]、[1,2]、[2,3]、[1,3]、[1,2,3]
这两问可以用伪代码。
分享到:





相关推荐
天然气汽车供气系统减压装置毕业设计(cad+设计方案)
PHP+SQL考勤系统安全性实现(源代码+论文+答辩PPT+指导书)
NumPy 的用途是什么
毕业设计 基于javaweb的在线答题平台
基于MATLAB的pca人脸识别.zip
课设毕设基于SSM的系统源码可运行
JAVAWML信息查询与后端信息发布系统实现——WML信息查询设计(源代码+LW)
毕业设计[整站程序]情感家园站 v3.0 For 个人版_qgweb30fp.zip
可以自动刷课,执行重复的脚本工作,内有详细操作教程。支持WIN7---WIN10系统。
Java项目之实验室计算机故障报修系统(源码) 开发语言:Java 框架:ssm 技术:JSP JDK版本:JDK1.8 服务器:tomcat7 数据库:mysql 5.7(一定要5.7版本) 数据库工具:Navicat11 开发软件:eclipse/myeclipse/idea Maven包:Maven3.3.9
协同过滤算法(Collaborative Filtering)是一种经典的推荐算法,其基本原理是“协同大家的反馈、评价和意见,一起对海量的信息进行过滤,从中筛选出用户可能感兴趣的信息”。它主要依赖于用户和物品之间的行为关系进行推荐。 协同过滤算法主要分为两类: 基于物品的协同过滤算法:给用户推荐与他之前喜欢的物品相似的物品。 基于用户的协同过滤算法:给用户推荐与他兴趣相似的用户喜欢的物品。 协同过滤算法的优点包括: 无需事先对商品或用户进行分类或标注,适用于各种类型的数据。 算法简单易懂,容易实现和部署。 推荐结果准确性较高,能够为用户提供个性化的推荐服务。 然而,协同过滤算法也存在一些缺点: 对数据量和数据质量要求较高,需要大量的历史数据和较高的数据质量。 容易受到“冷启动”问题的影响,即对新用户或新商品的推荐效果较差。 存在“同质化”问题,即推荐结果容易出现重复或相似的情况。 协同过滤算法在多个场景中有广泛的应用,如电商推荐系统、社交网络推荐和视频推荐系统等。在这些场景中,协同过滤算法可以根据用户的历史行为数据,推荐与用户兴趣相似的商品、用户或内容,从而提高用户的购买转化率、活跃度和社交体验。 未来,协同过滤算法的发展方向可能是结合其他推荐算法形成混合推荐系统,以充分发挥各算法的优势。
JAVAWEB校园二手平台项目,基本功能包括:个人信息、商品管理;交易商品板块管理等。本系统结构如下: (1)本月推荐交易板块: 电脑及配件:实现对该类商品的查询、用户留言功能 通讯器材:实现对该类商品的查询、用户留言功能 视听设备:实现对该类商品的查询、用户留言功能 书籍报刊:实现对该类商品的查询、用户留言功能 生活服务:实现对该类商品的查询、用户留言功能 房屋信息:实现对该类商品的查询、用户留言功能 交通工具:实现对该类商品的查询、用户留言功能 其他商品:实现对该类商品的查询、用户留言功能 (2)载入个人用户: 用户登陆 用户注册 (3)个人平台: 信息管理:实现对商品的删除、修改、查询功能 添加二手信息:实现对新商品的添加 修改个人资料:实现对用户个人信息的修改 注销
协同过滤算法(Collaborative Filtering)是一种经典的推荐算法,其基本原理是“协同大家的反馈、评价和意见,一起对海量的信息进行过滤,从中筛选出用户可能感兴趣的信息”。它主要依赖于用户和物品之间的行为关系进行推荐。 协同过滤算法主要分为两类: 基于物品的协同过滤算法:给用户推荐与他之前喜欢的物品相似的物品。 基于用户的协同过滤算法:给用户推荐与他兴趣相似的用户喜欢的物品。 协同过滤算法的优点包括: 无需事先对商品或用户进行分类或标注,适用于各种类型的数据。 算法简单易懂,容易实现和部署。 推荐结果准确性较高,能够为用户提供个性化的推荐服务。 然而,协同过滤算法也存在一些缺点: 对数据量和数据质量要求较高,需要大量的历史数据和较高的数据质量。 容易受到“冷启动”问题的影响,即对新用户或新商品的推荐效果较差。 存在“同质化”问题,即推荐结果容易出现重复或相似的情况。 协同过滤算法在多个场景中有广泛的应用,如电商推荐系统、社交网络推荐和视频推荐系统等。在这些场景中,协同过滤算法可以根据用户的历史行为数据,推荐与用户兴趣相似的商品、用户或内容,从而提高用户的购买转化率、活跃度和社交体验。 未来,协同过滤算法的发展方向可能是结合其他推荐算法形成混合推荐系统,以充分发挥各算法的优势。
Java游戏设计打飞机程序(源代码+LW)
Matlab实现CoMP多用户注水算法在最最基础的注水算法的基础上,实现了在功率受限速率受限的情况下CoMP多用户的功率分配.zip
自己写代码实现 Eigenface 人脸识别的训练与识别过程,纯手工实现 假设每张人脸图像只有一张人脸,且两只眼睛位置已知(即可人工标注给出)。每张图像的眼睛位置存在相应目录下的一个与图像文件名相同但后缀名为 txt 的文本文件里,文本文件中用一行、以空格分隔的 4 个数字表示,分别对应于两只眼睛中心在图像中的位置; 实现两个程序过程(两个执行文件),分别对应训练与识别; 自己构建一个人脸库(至少 40 人,包括自己),课程主页提供一个人脸库可选用; 不能直接调用 OpenCV 里面与 Eigenface 相关的一些函数,特征值与特征向量求解函数可以调用;只能用 C/C++/Python,不能用其他编程语言;GUI 只能用 OpenCV 自带的 HighGUI,不能用 QT 或其他的;平台可以用 Win/Linux/MacOS,建议 Win 优先;
有源电力滤波器的控制在MATLAB下的发展。三相电源电压是基于hysterezis正弦电流调节器.zip
BCH码的MATLAB程序源代码.zip
基于java的一个简单的即时通讯工具的设计与开发(源代码+LW)
参加比赛的一些心得:感觉把比赛得那一门语言基础学会,输入输出([我写的python输入输出](https://blog.csdn.net/qq_41392228/article/details/123614298)),([C++的STL](https://blog.csdn.net/qq_41392228/article/details/124825895)),熟练里面的数据结构,如数组,map等,==主要还是基础==。熟悉了后,可以在刷一下基础题,巩固哈学了的基础知识。把基础学好了,拿个奖是没问题的,正常发挥即可。想那个好的名词,就要看看相关的算法了,主要就是暴力的+优化,BFS,DFS,比较难的就是动态规划,得找转换方程。 python版本的可见:https://blog.csdn.net/qq_41392228/article/details/123616441