
主题是什么?
我写这个系列的博客主要目的是解析Disruptor是如何工作的,并深入了解下为什么这样工作。理论上,我应该从可能准备使用disruptor的开发人员的角度来写,以便在代码和技术论文[Disruptor-1.0.pdf]之间搭建一座桥梁。这篇文章提及到了内存屏障,我想弄清楚它们到底是什么,以及它们是如何应用于实践中的。
什么是内存屏障?
它是一个CPU指令。没错,又一次,我们在讨论CPU级别的东西,以便获得我们想要的性能(Martin著名的Mechanical Sympathy理论)。基本上,它是这样一条指令: a)确保一些特定操作执行的顺序; b)影响一些数据的可见性(可能是某些指令执行后的结果)。
编译器和CPU可以在保证输出结果一样的情况下对指令重排序,使性能得到优化。插入一个内存屏障,相当于告诉CPU和编译器先于这个命令的必须先执行,后于这个命令的必须后执行。正如去拉斯维加斯旅途中各个站点的先后顺序在你心中都一清二楚。
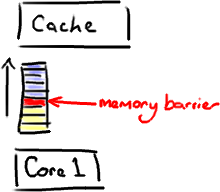
内存屏障另一个作用是强制更新一次不同CPU的缓存。例如,一个写屏障会把这个屏障前写入的数据刷新到缓存,这样任何试图读取该数据的线程将得到最新值,而不用考虑到底是被哪个cpu核心或者哪颗CPU执行的。
和Java有什么关系?
现在我知道你在想什么——这不是汇编程序。它是Java。
这里有个神奇咒语叫volatile(我觉得这个词在Java规范中从未被解释清楚)。如果你的字段是volatile,Java内存模型将在写操作后插入一个写屏障指令,在读操作前插入一个读屏障指令。
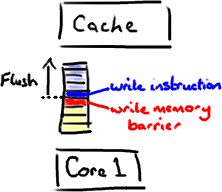
这意味着如果你对一个volatile字段进行写操作,你必须知道:
1、一旦你完成写入,任何访问这个字段的线程将会得到最新的值。
2、在你写入前,会保证所有之前发生的事已经发生,并且任何更新过的数据值也是可见的,因为内存屏障会把之前的写入值都刷新到缓存。
举个例子呗!
很高兴你这样说了。又是时候让我来画几个甜甜圈了。
RingBuffer的指针(cursor)(译注:指向队尾元素)属于一个神奇的volatile变量,同时也是我们能够不用锁操作就能实现Disruptor的原因之一。
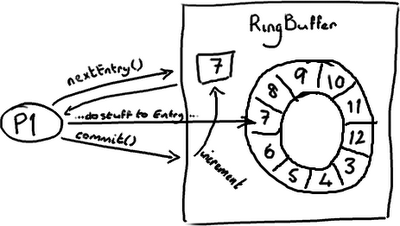
生产者将会取得下一个Entry(或者是一批),并可对它(们)作任意改动, 把它(们)更新为任何想要的值。如你所知,在所有改动都完成后,生产者对ring buffer调用commit方法来更新序列号(译注:把cursor更新为该Entry的序列号)。对volatile字段(cursor)的写操作创建了一个内存屏障,这个屏障将刷新所有缓存里的值(或者至少相应地使得缓存失效)。
这时候,消费者们能获得最新的序列号码(8),并且因为内存屏障保证了它之前执行的指令的顺序,消费者们可以确信生产者对7号Entry所作的改动已经可用。
…那么消费者那边会发生什么?
消费者中的序列号是volatile类型的,会被若干个外部对象读取——其他的下游消费者可能在跟踪这个消费者。ProducerBarrier/RingBuffer(取决于你看的是旧的还是新的代码)跟踪它以确保环没有出现重叠(wrap)的情况(译注:为了防止下游的消费者和上游的消费者对同一个Entry竞争消费,导致在环形队列中互相覆盖数据,下游消费者要对上游消费者的消费情况进行跟踪)。
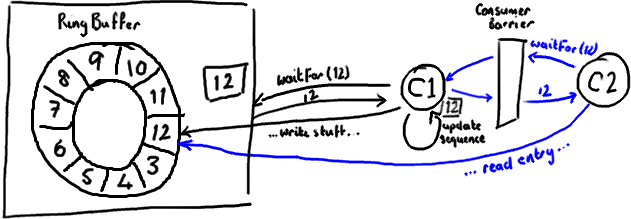
所以,如果你的下游消费者(C2)看见前一个消费者(C1)在消费号码为12的Entry,当C2的读取也到了12,它在更新序列号前将可以获得C1对该Entry的所作的更新。
基本来说就是,C1更新序列号前对ring buffer的所有操作(如上图黑色所示),必须先发生,待C2拿到C1更新过的序列号之后,C2才可以为所欲为(如上图蓝色所示)。
对性能的影响
内存屏障作为另一个CPU级的指令,没有锁那样大的开销。内核并没有在多个线程间干涉和调度。但凡事都是有代价的。内存屏障的确是有开销的——编译器/cpu不能重排序指令,导致不可以尽可能地高效利用CPU,另外刷新缓存亦会有开销。所以不要以为用volatile代替锁操作就一点事都没。
你会注意到Disruptor的实现对序列号的读写频率尽量降到最低。对volatile字段的每次读或写都是相对高成本的操作。但是,也应该认识到在批量的情况下可以获得很好的表现。如果你知道不应对序列号频繁读写,那么很合理的想到,先获得一整批Entries,并在更新序列号前处理它们。这个技巧对生产者和消费者都适用。以下的例子来自BatchConsumer:
01 |
long nextSequence = sequence + 1;
|
02 |
while (running)
|
03 |
{
|
04 |
try
|
05 |
{
|
06 |
final long availableSequence = consumerBarrier.waitFor(nextSequence);
|
07 |
while (nextSequence <= availableSequence)
|
08 |
{
|
09 |
entry = consumerBarrier.getEntry(nextSequence);
|
10 |
handler.onAvailable(entry);
|
11 |
nextSequence++;
|
12 |
}
|
13 |
handler.onEndOfBatch();
|
14 |
sequence = entry.getSequence();
|
15 |
}
|
16 |
…
|
17 |
catch (final Exception ex)
|
18 |
{
|
19 |
exceptionHandler.handle(ex, entry);
|
20 |
sequence = entry.getSequence();
|
21 |
nextSequence = entry.getSequence() + 1;
|
22 |
}
|
23 |
}
|
(你会注意到,这是个旧式的代码和命名习惯,因为这是摘自我以前的博客文章,我认为如果直接转换为新式的代码和命名习惯会让人有点混乱)
在上面的代码中,我们在消费者处理entries的循环中用一个局部变量(nextSequence)来递增。这表明我们想尽可能地减少对volatile类型的序列号的进行读写。
总结
内存屏障是CPU指令,它允许你对数据什么时候对其他进程可见作出假设。在Java里,你使用volatile关键字来实现内存屏障。使用volatile意味着你不用被迫选择加锁,并且还能让你获得性能的提升。
但是,你需要对你的设计进行一些更细致的思考,特别是你对volatile字段的使用有多频繁,以及对它们的读写有多频繁。



相关推荐
这种性能提升使得Disruptor成为异步事件驱动架构的理想选择,LMAX公司已经在订单匹配引擎、实时风险管理和内存事务处理系统等多个关键项目中成功应用了Disruptor,实现了前所未有的性能水平。 Disruptor并非仅限于...
在LMAX公司的实际应用中,例如顺序匹配引擎、实时风险管理系统和内存事务处理系统,都基于Disruptor实现了卓越的性能提升,打破了行业标准。 Disruptor的主要特点包括: 1. **减少写入争用**:通过避免在生产者和...
深入研究和对计算机科学的理解,特别是考虑到现代CPU的工作原理——我们称之为“机械同情”(mechanical sympathy),即通过良好的设计原则来区分不同的关注点,开发团队提出了名为Disruptor的数据结构和使用模式。...
2017 Conversant Disruptor - 仍然是世界上最快的入门运行 maven build 来构建和使用包。 $ mvn -U clean package Conversant Disruptor 在 Maven Central 上对于 Java 9 及更高版本: <dependency> <groupId>...
Disruptor利用内存屏障来保证在无锁设计中,数据的可见性和一致性,从而避免了竞态条件的发生。 #### 三、Disruptor的工作机制 ##### 2.1 Ring Buffer的特别之处 Ring Buffer是Disruptor的核心组件,它是一个固定...
- **Ring Buffer**:Disruptor的核心数据结构是一个环形缓冲区,它避免了锁和内存屏障带来的性能开销,通过固定大小的缓存块进行数据交换。 - **Sequencer**:负责为生产者和消费者分配唯一的序列号,确保数据的...
赠送jar包:disruptor-3.3.0.jar; 赠送原API文档:disruptor-3.3.0-javadoc.jar; 赠送源代码:disruptor-3.3.0-sources.jar; 赠送Maven依赖信息文件:disruptor-3.3.0.pom; 包含翻译后的API文档:disruptor-...
赠送jar包:disruptor-3.3.0.jar; 赠送原API文档:disruptor-3.3.0-javadoc.jar; 赠送源代码:disruptor-3.3.0-sources.jar; 赠送Maven依赖信息文件:disruptor-3.3.0.pom; 包含翻译后的API文档:disruptor-...
它避免了传统的锁机制,采用了序列化和依赖于内存屏障的机制,从而减少了线程间的同步开销。tiny_disruptor项目保留了这一核心思想,但可能对其进行了更直观、更易于理解的封装。 在tiny_disruptor中,开发者可以...
Disruptor的高效性能得益于其无锁设计和避免了传统的内存屏障。此外,其采用的序列号机制确保了数据的一致性,而无需使用传统的锁或volatile变量。在实际应用中,Disruptor通常与其他并发工具如ExecutorService结合...
《Spring Boot Starter Disruptor深度解析》 在现代软件开发中,高性能和低延迟往往是系统设计的关键要素。Spring Boot作为Java领域最受欢迎的微服务框架,提供了丰富的启动器(starters)来简化开发工作。"spring-...
三、序列号与屏障 序列号是Disruptor中的关键概念,每个生产者和消费者都有自己的独立序列号,用来跟踪它们在环形缓冲区中的位置。屏障(Barrier)则是协调生产者和消费者之间工作关系的关键,它包括生产者屏障和...
Disruptor的设计理念是避免传统的锁机制,转而采用一种称为“环形缓冲区”的数据结构,以及基于事件的处理模型,从而实现低延迟、高吞吐量的并发编程。 在"Disruptor demo"中,我们可以看到如何使用Disruptor来实现...
在C++实现中,环形缓冲区通常使用原子操作和内存屏障来保证在多线程环境下的正确性,避免了锁竞争导致的性能瓶颈。此外,C++实现中的动态环缓冲区允许在运行时调整其大小,以适应不断变化的系统负载。 Disruptor的...
在使用Disruptor过程中,开发者可能会遇到`FatalExceptionHandler`的错误,这通常是由于处理流程中的异常没有被正确处理,导致Disruptor内部的默认异常处理器介入。下面将详细解析这个问题,并提供解决方案。 首先...
赠送jar包:disruptor-3.3.7.jar; 赠送原API文档:disruptor-3.3.7-javadoc.jar; 赠送源代码:disruptor-3.3.7-sources.jar; 赠送Maven依赖信息文件:disruptor-3.3.7.pom; 包含翻译后的API文档:disruptor-...
Disruptor会自动管理事件的传递顺序,确保每个事件处理器只处理已发布的事件。 4. 处理器协作:Disruptor的等待策略(WaitStrategy)可以灵活调整,如使用忙等、多路复用或者阻塞等待,以适应不同的系统需求和资源...
2. **零拷贝**:Disruptor的环形缓冲区直接在内存中操作,避免了数据复制,进一步提升了性能。 3. **多生产者与多消费者**:Disruptor支持多个生产者和消费者并发操作,通过序列号的同步机制,保证了数据的一致性。...
1. **环形缓冲区**:Disruptor使用一个固定大小的环形数组作为缓冲区,避免了数组增长导致的内存分配和拷贝开销。在环形缓冲区中,生产者和消费者通过独立的序列号进行操作,使得它们可以并行工作而不会相互阻塞。 ...