
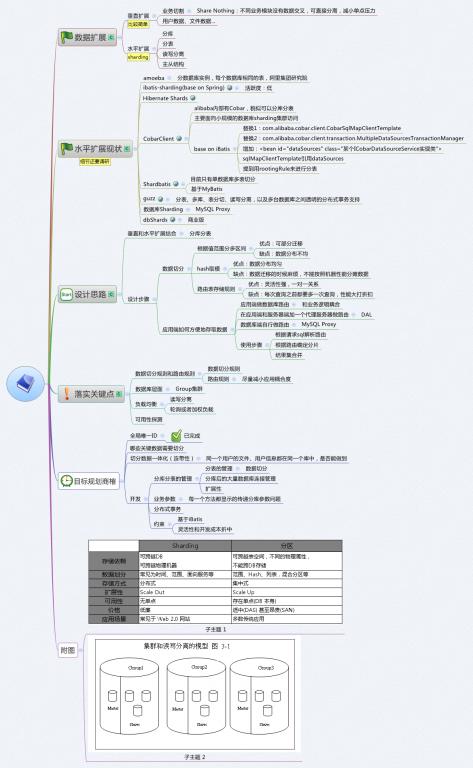
一、 背景介绍
1.大数据量的存储需要大量的数据库资源;
2.数据量的不断增长要求数据库存储具有可扩展性;
3.在保证大数据量的情况下,要保证性能、高可用性等质量要求;
4.现有框架中没有彻底解决大数据量的存储问题;
5.Oracle等海量存储方案价格不菲,采用MySQL进行分库分表节约IT成本。
二、 可行性分析
1. 风险评估
1) DBA数据库管理的资源和规范要求;
2. 业务数据量规模和变化的影响
1) 对于事先可规划的中等以上数据规模,采用单库分表(一个数据库实例,分多张表)、读写分离、或者多库多表(多个数据库实例,多张表)可以满足业务需求,且相应设计和实现相对简单,不易出错。
2) 对于初期数据规模不可准确预知,但随着业务发展数据规模不断增长的系统,要求数据存储具有可扩展性。这种可扩展性通过分库分表解决,要求分库分表在路由上具有极强的伸缩性,这也是分库分表的难点,本方案提出一个循序渐进的实现路线逐步解决这个问题。
3. 技术积累
1) 公司已有简单的分库分表方案
2) 这个方案缺乏扩展性
3) 本方案将提出短期实现一定扩展性、中长期高可扩展性的方案
4. 开源或产品
1) 商业版数据库Sharding:MySQL Proxy,提供MySQL协议接口(非JDBC),主从结构,可以负载平衡,读写分离,failover等,lua语法复杂,不支持大数据量的分库分表;
2) Amoeba,支持分数据库实例,每个数据相同的表,不支持事务;类似MySQL Proxy,设计上抛弃lua,更简单;
3) 阿里集团研究院开源的CobarClient,主要面向小规模的数据库sharding集群访问,基于ibatis,需要规划数据规模,缺乏扩展性;另外有Cobar,阿里集团内部的一个完整DAL层,实现完整JDBC代理;
4) HibernateShards,Hibernate提供的sharding,支持分数据库实例,比较复杂,事先规划数据规模,和框架不符;
5) guzz,多库(虚拟的数据库,实际数据库的路由规则仍然自定义)、表分切、读写分离,以及多台数据库之间透明的分布式事务支持,设计目标是支持大型在线生产应用;需完全替换ibatis;完全和框架不符。
6) TDDL,淘宝的DAL,很强的分库分表能力,仍然需要数据量实现规划,动态扩展有限。
7) 以上某些产品在一定程度上可以满足我们的需求,但不能彻底解决我们大数据量可扩展的问题。
三、 性能指标
1. 和没有引入分库分表时相比,每次操作最大延迟<1ms;
四、 特性列表和RoadMap
1. 垂直分库,不同业务数据使用不同数据库实例存储
2. 数据切分:
a) 根据切分字段Hash取模;
b) 确定需要切分的数据,尽量将可能进行关联的分片数据放在一个数据库实例中,例如同一用户的基本信息、好友信息或者文件信息等;
3. 短期:分库分表
a) 数据库实例编号递增
b) 每个数据库内分表序号从1递增,不全局编号
c) 基于数据源(ibatis基础上)拦截建立访问层,应用感知
d) 应用需在底层进行数据源、分布式事务考虑和管理等
e) 可扩展性:只支持向上扩展,不支持收缩
4. 长期:数据库访问层
a) 建立灵活的数据切分和路由规则
b) 支持MySQL集群
c) 读写分离和负载均衡
d) 可用性探测
e) 分布式事务
f) 对应用透明
附录:

单库单表
单库单表是最常见的数据库设计,例如,有一张用户(user)表放在数据库db中,所有的用户都可以在db库中的user表中查到。
单库多表
随着用户数量的增加,user表的数据量会越来越大,当数据量达到一定程度的时候对user表的查询会渐渐的变慢,从而影响整个DB的性能。如果使用mysql, 还有一个更严重的问题是,当需要添加一列的时候,mysql会锁表,期间所有的读写操作只能等待。
可以通过某种方式将user进行水平的切分,产生两个表结构完全一样的user_0000,user_0001等表,user_0000 + user_0001 + …的数据刚好是一份完整的数据。
多库多表
随着数据量增加也许单台DB的存储空间不够,随着查询量的增加单台数据库服务器已经没办法支撑。这个时候可以再对数据库进行水平区分。
分库分表规则
设计表的时候需要确定此表按照什么样的规则进行分库分表。例如,当有新用户时,程序得确定将此用户信息添加到哪个表中;同理,当登录的时候我们得通过用户的账号找到数据库中对应的记录,所有的这些都需要按照某一规则进行。
路由
通过分库分表规则查找到对应的表和库的过程。如分库分表的规则是user_id mod 4的方式,当用户新注册了一个账号,账号id的123,我们可以通过id mod 4的方式确定此账号应该保存到User_0003表中。当用户123登录的时候,我们通过123 mod 4后确定记录在User_0003中。
分库分表产生的问题,及注意事项
1. 分库分表维度的问题
假如用户购买了商品,需 要将交易记录保存取来,如果按照用户的纬度分表,则每个用户的交易记录都保存在同一表中,所以很快很方便的查找到某用户的购买情况,但是某商品被购买的情 况则很有可能分布在多张表中,查找起来比较麻烦。反之,按照商品维度分表,可以很方便的查找到此商品的购买情况,但要查找到买人的交易记录比较麻烦。
所以常见的解决方式有:
a.通过扫表的方式解决,此方法基本不可能,效率太低了。
b.记录两份数据,一份按照用户纬度分表,一份按照商品维度分表。
c.通过搜索引擎解决,但如果实时性要求很高,又得关系到实时搜索。
2. 联合查询的问题
联合查询基本不可能,因为关联的表有可能不在同一数据库中。
3. 避免跨库事务
避免在一个事务中修改db0中的表的时候同时修改db1中的表,一个是操作起来更复杂,效率也会有一定影响。
4. 尽量把同一组数据放到同一DB服务器上
例如将卖家a的商品和交易信息都放到db0中,当db1挂了的时候,卖家a相关的东西可以正常使用。也就是说避免数据库中的数据依赖另一数据库中的数据。
一主多备
在实际的应用中,绝大部分情况都是读远大于写。Mysql提供了读写分离的机制,所有的写操作都必须对应到Master,读操作可以在Master和Slave机器上进行,Slave与Master的结构完全一样,一个Master可以有多个Slave,甚至Slave下还可以挂Slave,通过此方式可以有效的提高DB集群的QPS.
所有的写操作都是先在Master上操作,然后同步更新到Slave上,所以从Master同步到Slave机器有一定的延迟,当系统很繁忙的时候,延迟问题会更加严重,Slave机器数量的增加也会使这个问题更加严重。
此外,可以看出Master是集群的瓶颈,当写操作过多,会严重影响到Master的稳定性,如果Master挂掉,整个集群都将不能正常工作。
所以,1. 当读压力很大的时候,可以考虑添加Slave机器的分式解决,但是当Slave机器达到一定的数量就得考虑分库了。 2. 当写压力很大的时候,就必须得进行分库操作。
另外,可能会因为种种原因,集群中的数据库硬件配置等会不一样,某些性能高,某些性能低,这个时候可以通过程序控制每台机器读写的比重,达到负载均衡。
转载:http://blog.csdn.net/doliu6/article/details/7321255
http://www.blogjava.net/happyenjoylife/archive/2011/05/13/350177.html



相关推荐
在IT行业中,数据库读写分离是一种常见的优化策略,主要用于提高系统的并发处理能力和数据读取效率。Redis作为一款高性能的键值存储系统,被广泛应用于缓存、消息队列等场景。在C#环境下,我们可以利用各种客户端库...
Oracle数据库的读写分离是一种优化策略,用于提升大型系统中数据处理能力,通过将读操作与写操作分离到不同的数据库实例上,实现高并发场景下的性能优化。在本配置文档中,我们将关注如何利用Mycat中间键实现Oracle ...
springboot结合mysql主从来实现读写分离 一、实现的功能 1、基于springboot框架,application.yml配置多个数据源,使用AOP以及AbstractRootingDataSource、ThreadLocal来实现多数据源切换,以实现读写分离。mysql...
本文介绍了MySQL与Mycat读写分离的基本概念及其实现过程,包括MySQL主从配置、表创建策略以及Mycat读写分离机制的启用方法。通过这种方式,不仅可以提高系统的整体性能,还可以增强系统的稳定性和可扩展性。在实际...
为了解决这一问题,引入读写分离机制便成了有效的解决方案之一。读写分离的核心思想是将数据的读操作和写操作分别由不同的服务器来承担,以此分散压力并提高数据库系统的整体性能。 读写分离工作原理是,主数据库...
读写分离就是对于一条SQL该选择哪一个数据库去执行,至于谁来做选择数据库这件事,有两个,要么使用中间件帮我们做,要么程序自己做。一般来说,读写分离有两种实现方式。第一种是依靠中间件MyCat,也就是说应用程序...
### MyBatis 实现读写分离 #### 一、读写分离的概念与优势 在数据库设计与应用领域,“读写分离”是一种常见的架构模式,它通过将数据读取操作和写入操作分配到不同的数据库服务器上来提高系统的整体性能。这种...
### MyCAT 读写分离优化详解 #### 一、前言 ##### 1.1 编写目的 本文档旨在探讨MyCAT读写分离模式下的智能优化方案,并分享实际应用场景中的经验教训。随着数据量的增长及业务复杂度的提升,单一数据库往往难以...
在企业级应用中,数据库的读写分离是一种常见的优化策略,它可以提高系统的并发处理能力,减轻主数据库的压力,确保数据的稳定性和可用性。Spring框架提供了对MySQL数据库读写分离的良好支持,使得开发者能够轻松地...
### 服务读写分离架构分析 #### 一、引言 在互联网架构设计中,针对高并发场景,读写分离是一种常见的策略。该策略旨在通过将读操作与写操作分离来提高系统的整体性能和可用性。然而,并非所有的场景都适合采用...
在数据库管理系统中,读写分离是一项重要技术,它能够提升数据库的处理能力,优化性能,尤其是对于高并发访问和大数据量处理的场景特别有效。本文将围绕如何基于Mycat实现Mysql主从复制以及读写分离进行详细介绍。...
在IT行业中,数据库读写分离是一种常见的优化策略,特别是在高并发场景下,它能有效提升系统的性能和稳定性。本文将详细讲解如何利用Spring Boot、MyBatis和AOP(面向切面编程)来实现这一技术。 首先,让我们理解...
在大型系统中,为了提高数据库系统的可用性和性能,通常会采用读写分离的策略。这是一种架构设计模式,用于减轻主数据库(写库)的压力,通过将读取操作分散到多个从库(读库)来实现。本项目——".NET Core基于SQL ...
.NET Core 实现分表分库、读写分离的通用 Repository 功能 .NET Core 实现分表分库、读写分离的通用 Repository 功能是指使用 FreeSql.Repository 库来实现通用的仓储层功能,实现了基础的仓储层(CURD),并且支持...
MySQL 双主 + Keepalived 读写分离解决方案 MySQL 双主 + Keepalived 读写分离是一种高可用性解决方案,旨在解决 MySQL 单点故障问题。该方案通过双主 MySQL 实现高可用性,并使用 Keepalived 实现虚拟 IP(VIP)...
MySQL 读写分离是数据库架构优化中的一个常见策略,它主要应用于高并发、大数据量的系统中,以提高数据库系统的性能和可用性。在这种架构下,数据库被分为两部分:主库(Master)负责处理所有的写操作(INSERT、...
Mybatis读写分离,支持n多的从库,简单的负载均衡。数据库是mysql,采用druid连接池。 读写分离采用插件的形式实现的,优点是不需要写源注解,不需要写分开的Mapper.xml。 如果只有主库的话,那么会创建两个地址相同...
### Oracle读写分离详解 #### 一、读写分离概念 **读写分离**是一种数据库设计模式,旨在通过将数据库的读操作与写操作分开,从而优化系统的整体性能。这种模式下,通常会有两个或多个数据库实例:一个主数据库...
在IT行业中,数据库读写分离是一种常见的优化策略,特别是在高并发和大数据量的场景下,以提高系统的性能和可用性。本教程将详细介绍如何利用SpringBoot框架实现MySQL的读写分离,以及涉及到的相关技术。 首先,...
在IT行业中,数据库读写分离是一种常见的优化策略,它能够有效地提高系统的并发处理能力和响应速度。Sharding-JDBC是阿里巴巴开源的一款轻量级Java框架,它可以在不改变业务代码的前提下,帮助我们快速实现数据库的...