
下图是 hive 系统的整体结构图
![]()
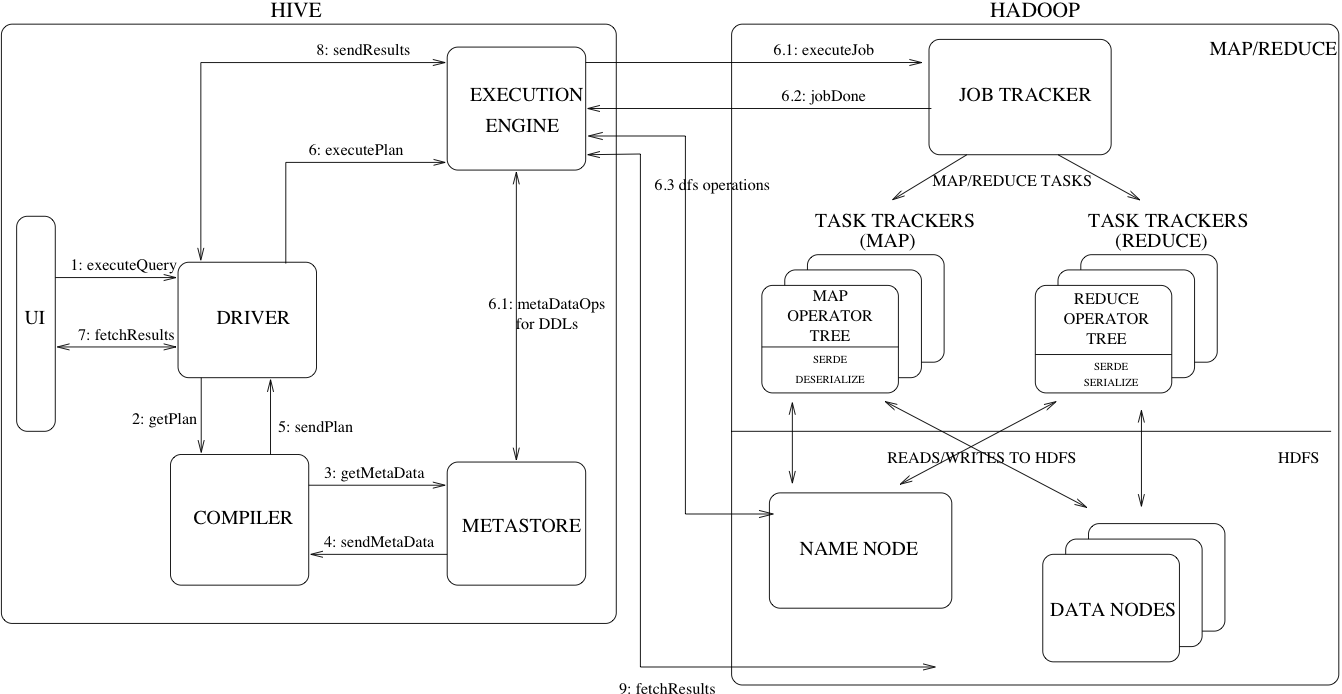
Hive 体系结构
上图显示了 Hive 的主要组件以及 Hive 跟 Hadoop 的交互过程,这些组件分别是:
UI:用户提交查询和其他操作到系统的用户接口。
Driver:接收查询的组件,负责 session 管理,提供基于 JDBC/ODBC 接口的执行和数据拉取 API。
Compiler:解析查询,对查询的不同部分做语法分析,生成执行计划。
Metastore:存储数据仓库中所有数据的结构信息,包括列名和列的类型信息;也负责数据读写的序列化和反序列化,以及定位数据对应的 HDFS 文件。
Execution Engine - 执行具体的执行计划。执行计划是一个状态的有向无环图(DAG),执行引擎管理图中状态的依赖关系,并进行调度。
Hive 数据模型
Hive 把数据组织成如下三级结构:
- Tables
- Partitions
- Buckets
Hive 除了支持基础类型之外,还支持数组、maps 和用户自定义类型。Hive 中用户是通过实现自己的对象 inspector 接口来自定义列类型以及他们的序列化逻辑。
元数据存储
Metastore 提供了两个非常重要但常常被忽略的特性:数据抽象和数据发现。数据抽象使得对数据的解释在表创建的时候就已经提供好了,之后每次查询都可以复用。
元数据对象
- Database
- Table
- Partition
元数据实现方案
Metastore 有两种实现方案:基于数据库的和基于文件的。
- 基于数据库的方案使用 DataNucleus 实现,该方案的好处是可以查询元数据,坏处是会有元数据同步和扩展的问题。
- 基于文件的方案的问题是没有一个很好的实现方法。
所以最终选择了基于关系数据库的 metastore 方案。
metastore 的访问有嵌入式和远程调用两种方式,远程调用是通过 Thrift 服务实现的,这样可以兼容非 Java 客户端;对于 Java 客户端可以直接使用嵌入方式。
Hive 查询语言
HiveQL 是一种类 SQL 查询语言,它在建表、加载数据和查询上大量模仿 SQL 语法。
HiveQL 支持嵌入用户自定义的 map-reduce 脚本,通过这些脚本可以在标准输入中按行读取数据再按行输出数据到标准输出。
另一个 HiveQL 的特性是多表插入,如果多个查询访问的是相同数据,只需要做一次数据扫描操作。
编译器
编译组件由下面四部分组成:
- Parser
- Semantic Analyser
这步中会做类型检查和类型的隐式转换;
对于涉及到划分的表,这里会收集所有的表达式,为后面的划分剪枝做准备;
这个步骤也会收集查询的指定采样。
- Logical Plan Generator
逻辑计划中的操作大体分为两类,一类是关系代数操作(filter、join 等),一类是 Hive 特有的操作(像 reduceSink 操作),这类特有的操作后续会被转换成 map-reduce 任务。
这个步骤中还会做一些查询优化的事情,比如:
- 把一系列 join 操作转换成一个单独的 multi-way join 操作
- 为 group by 执行一个 map-side 偏序聚合
- 把 group by 切分成两阶段来消除 reducer 的性能瓶颈问题
- Query Plan Generator
这个步骤中遍历逻辑计划树,把操作逐个分解成可以提交给 Hadoop 集群 map-reduce 框架的任务。查询计划也包括必要的采用和划分任务,最终这个计划被序列化到一个文件中。
翻译自:https://cwiki.apache.org/confluence/display/Hive/Design#



相关推荐
hive旅游-hive旅游系统-hive旅游系统源码-hive旅游管理系统-hive旅游管理系统java代码-hive旅游系统设计与实现-基于springboot的hive旅游系统-基于Web的hive旅游系统设计与实现-hive旅游网站-hive旅游网站代码-hive...
hive旅游-hive旅游系统-hive旅游系统源码-hive旅游管理系统-hive旅游管理系统java代码-hive旅游系统设计与实现-基于springboot的hive旅游系统-基于Web的hive旅游系统设计与实现-hive旅游网站-hive旅游网站代码-hive...
接着详细介绍了Hive的系统架构,包括基本组成模块、工作原理和几种外部访问方式,描述了Hive的具体应用及Hive HA原理;同时,介绍了新一代开源大数据分析引擎Impala及其与Hive的比较分析;最后,以单词统计为例,...
Adam Muise是Hortonworks的解决方案工程师,他在多伦多举办的HUG上做了一个关于如何调优Hive的演讲,长达91页的PPT干货十足,从Hive的基本架构、Hive如何存取数据讲起,到如何调优的基本知识,最后介绍了个叫Stinger...
1.1HIVE 架构 Hive 的结构可以分为以下几部分: 用户接口:包括 CLI, Client, WUI 元数据存储。通常是存储在关系数据库如 mysql, derby 中 6 解释器、编译器、优化器、执行器 Hadoop:用 HDFS 进行存储,利用 ...
本书介绍了Apache Hive,它是基于Hadoop的数据仓库架构。通过本书,读者可以很快学会如何使用Hive的SQL方言——HiveQL来汇总、查询和分析存储在Hadoop分布式文件系统上的大型数据集。 本书以实际案例为主线,详细...
本书介绍了Apache Hive,它是基于Hadoop的数据仓库架构。通过本书,读者可以很快学会如何使用Hive的SQL方言——HiveQL来汇总、查询和分析存储在Hadoop分布式文件系统上的大型数据集。 本书以实际案例为主线,详细...
Hive简介,包括Hive的来源,系统的架构 Hive基础语法,包括 Hive各种函数 Hive编程,导入、导出、建表、分区、自定义函数
-IDEA搭建及实战.pdf4.Spark运行架构.pdf5.Hive(上)--Hive介绍及部署.pdf5.Hive(下)--Hive实战.pdf6.SparkSQL(上)--SparkSQL简介.pdf6.SparkSQL(下)--Spark实战应用.pdf6.SparkSQL(中)--深入了解运行计划...
14.1 概述 14.2 Hive系统架构 14.3 Hive工作原理 14.4 Hive HA基本原理 14.5 Impala 14.6 Hive编程实践
2.1_HDFS概述及应用场景-HDFS系统架构 2.2_关键特性介绍 3.1_MapReduce和Yarn基本介绍-MapReduce和Yarn功能与架构 3.2_Yarn的资源管理和任务调度-增强特性 4.1_Spark概述-Spark原理与架构 4.2_Spark原理与架构-Spark...
│ │ 04--数据仓库基础理论--OLTP、OLAP系统.avi │ │ 05--数据仓库基础理论--数据仓库、数据库区别.avi │ │ 06--数据仓库基础理论--数据仓库、数据集市区别.avi │ │ 07--数据仓库基础理论--数仓分层...
价值过亿的架构师训练营课面试题和答案.pptx 架构师职责 听课总结 – 第一课 架构视图,设计文档 – 第二课 编程的本质与未来 第三课 听课总结 框架设计、设计原则、设计...系统架构 消息队列 负载均衡 数据库备份 第
赵伟首先介绍了他们的TDW核心架构,HIVE,MapReduce,HDFS及PostgreSQL构成。赵伟分享了最核心的HIVE模块在TDW中的实践经验;HIVE是一个在Hadoop上构建数据仓库的软件,它支持通过类SQL的HQL语言对结构化数据进行...
通过对Hadoop分布式计算平台最核心的分布式文件系统HDFS、MapReduce处理过程,以及数据仓库工具Hive和分布式数据库Hbase的介绍,基本涵盖了Hadoop分布式平台的所有技术核心。通过这一阶段的调研总结,从内部机理的...
2.1_HDFS概述及应用场景-HDFS系统架构 2.2_关键特性介绍 第三章 MapReduce分布式离线批处理和Yarn资源协调 3.1_MapReduce和Yarn基本介绍-MapReduce和Yarn功能与架构 3.2_Yarn的资源管理和任务调度-增强特性 第四...
实验目的: 学习Hive基本知识;2)提高Linux操作技能...4)了解Hive架构与相关组件。 实验内容: 1)配置伪分布式Hadoop3系统;2)配置并运行Hive服务HiveServer2;3)以beeline连接HiveServer2,可以运行初级查询命令。
在LINUX虚拟机中搭建 HADOOP+HIVE大数据平台,完善伪...Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
1.Spark及其生态圈简介.pdf 2.Spark编译与部署(上)--基础环境搭建.pdf 2.Spark编译与部署(下)--Spark编译安装.pdf 2.Spark编译与部署(中)--Hadoop编译安装.pdf...10.分布式内存文件系统Tachyon介绍及安装部署.pdf
8.1 概述 8.2 Hive系统架构 8.3 Hive工作原理 8.6 Hive编程实践 8.1 概述 8.1.1 数据仓库概念 8.1.2 传统数据仓库面临