
摘要: 头疼的问题 MaxCompute 用户一个常见的问题是:同一个周期任务,为什么最近几天比之前慢了很多?或者为什么之前都能按时产出的作业最近经常破线? 通常来说,引起作业执行变慢的原因有:quota 组资源不足、输入数据量变动、数据分布情况变动、平台硬件故障引发重跑等。
头疼的问题
MaxCompute 用户一个常见的问题是:同一个周期任务,为什么最近几天比之前慢了很多?或者为什么之前都能按时产出的作业最近经常破线?
通常来说,引起作业执行变慢的原因有:quota 组资源不足、输入数据量变动、数据分布情况变动、平台硬件故障引发重跑等。本文主要针对数据变动引起的作业慢问题,介绍用户如何通过 MaxCompute Studio 的作业执行图及作业详情功能来自助定位问题。
MaxCompute Studio 登场
我们举个例子来说。 下面是同一个任务分别在5月7日,5月9日的执行情况,下面分别称为作业一、作业二:
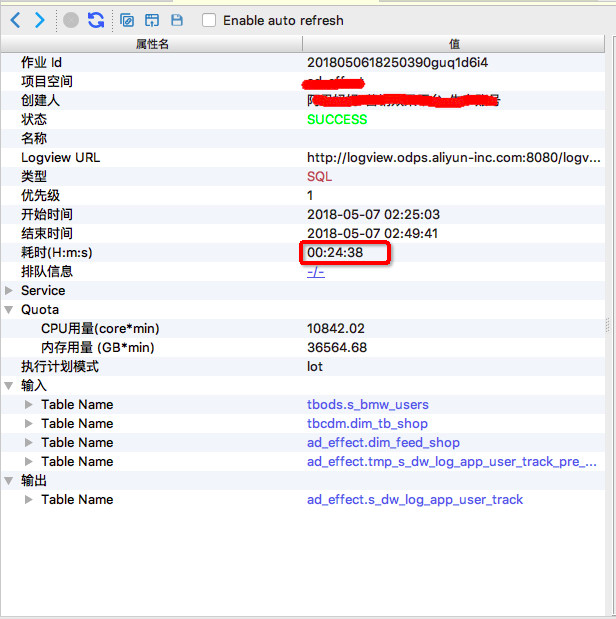
作业一,执行时长 24分38秒
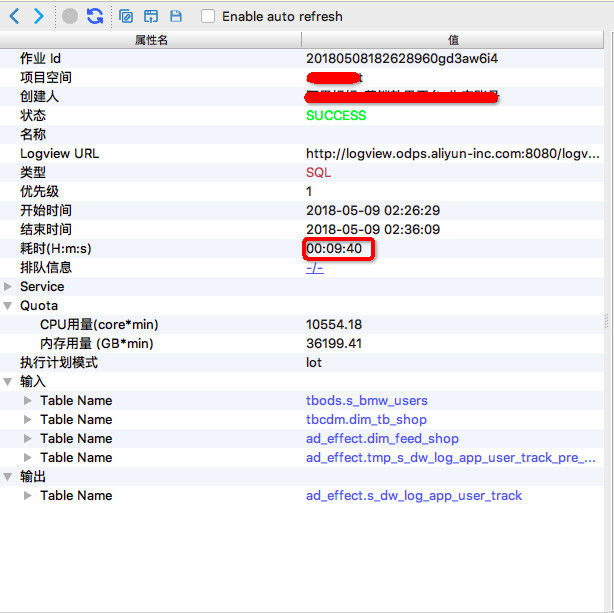
作业二,执行时长 9分40秒
先来,对比下 SQL 和执行计划
通常来说,进行两次执行对比前,要先对比一下两次执行的 SQL 脚本是否相同,如果在这之间用户改动过作业脚本,就需要先分析改动的部分造成的影响。如果脚本内容一致,随后还需要比较执行计划是否一致,可以通过 MaxCompute Studio 的作业执行计划图功能来分析(参看文档),可视化地看看两次执行的计划图长得一样不一样。 (作业对比的功能正在开发中,下个版本的 Studio 中就可以一键对比两个作业,标注出 SQL 脚本及其它部分的不同之处啦,敬请期待)
在上面这个例子中两个作业的 SQL 脚本及执行计划完全一致,出于数据安全考虑,此处不粘贴具体 SQL 的内容。
再来,对比数据量
第二步要看一下作业输入数据量有没有明显变化,有可能是某一天输入表或分区的数据量暴涨导致了作业执行变慢。作业输入数据在 Detail 页面左侧,那里列出了这个作业所有输入的数据表和最终输出的数据表。 展开 输入->Table Name 可以查看详细信息,包括是哪个 Fuxi 任务读取了这个表,读取了多少条记录以及读取的数据量大小。这些信息,也标注在作业执行计划图 graph 上,方便查看。如下图所示,
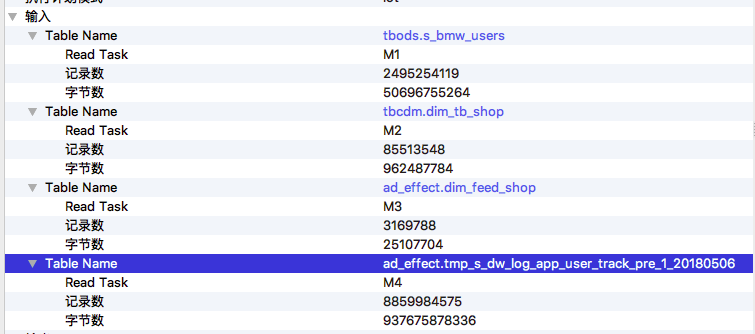
作业一的输入表及读取数据
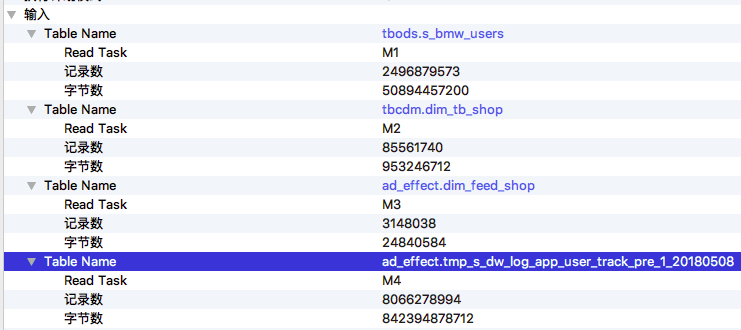
作业二的输入表及读取数据
也可以从graph上直接读取输入行数或者字节数(默认展示行数,可在边上右键切换为字节数):
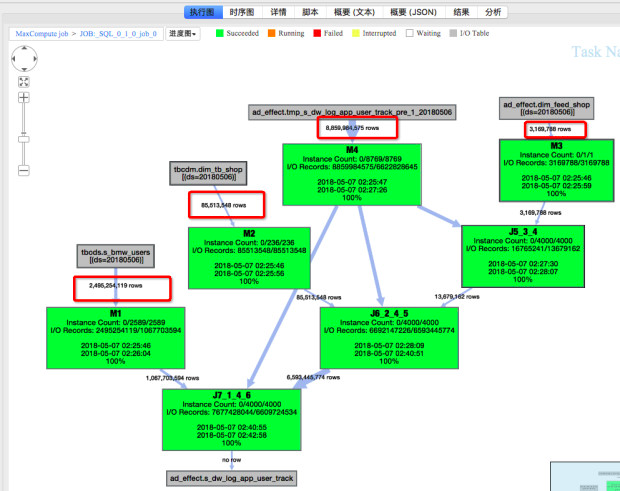
作业一 graph输入行数
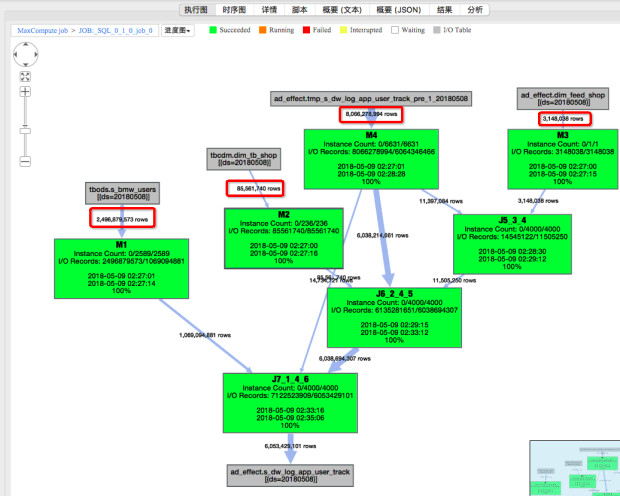
作业二 graph输入行数
在这个例子中,从输入数据量来看,两次执行的输入数据量差别不大。
作业回放是把利器
第三步,那到底作业运行情况是怎样的呢?运行那么长时间,或花费在哪儿了呢?不急,快快使用作业回放!
在 Studio 中作业执行计划图底部提供的作业回放工具条,允许用户在 30 秒内快速回放作业执行进度的全过程!这样我们就可以迅速地了解到底是哪个 Task 耗时最多,或者处理得数据最多,或者输出的数据最多等等。
通过回放重现作业执行过程,Studio 提供进度图以及热度图方便从不同维度进行作业分析。
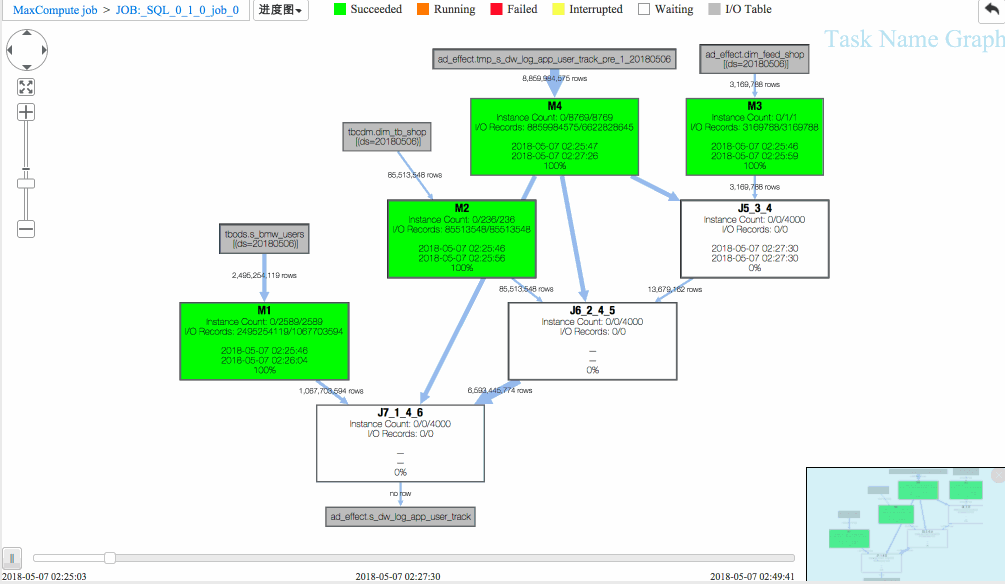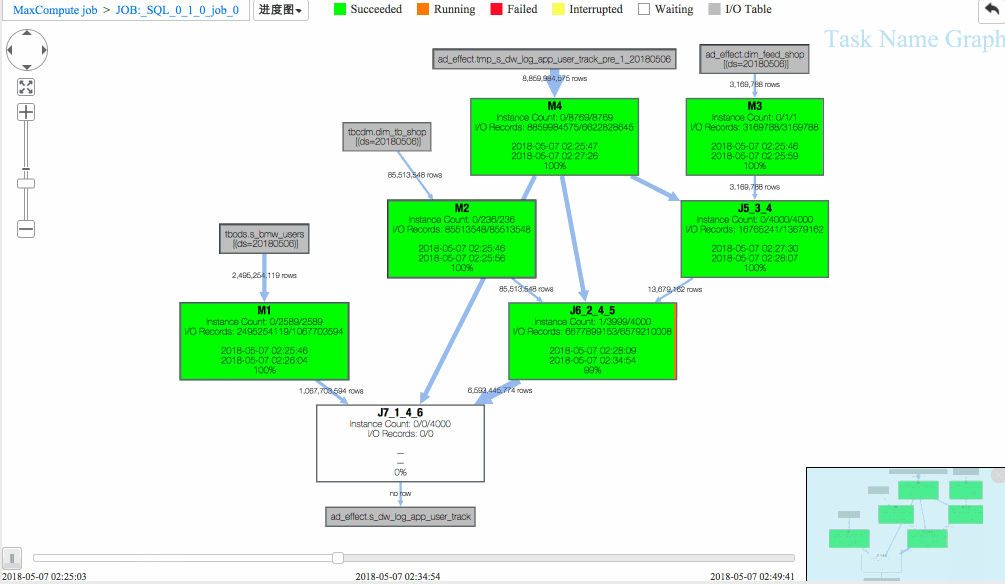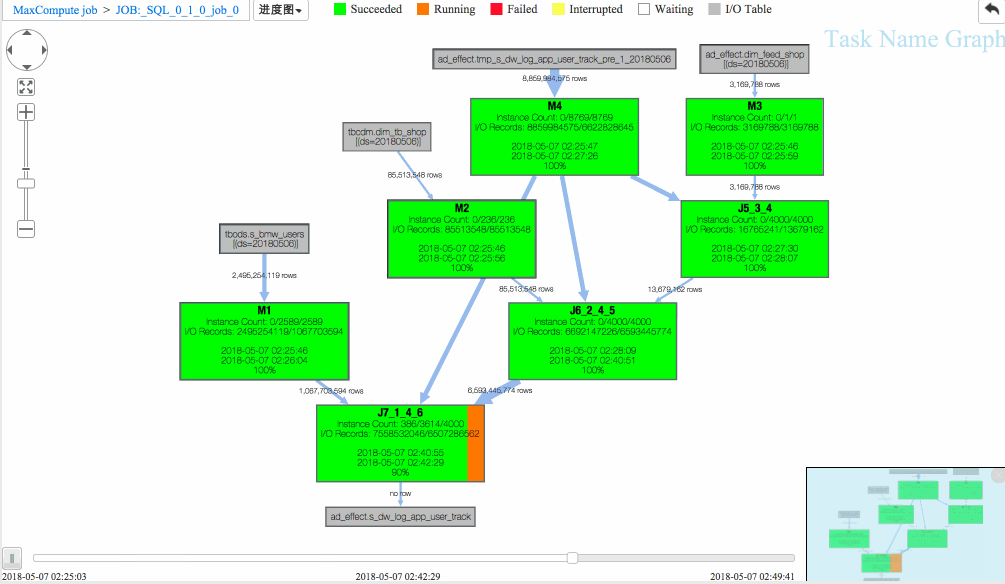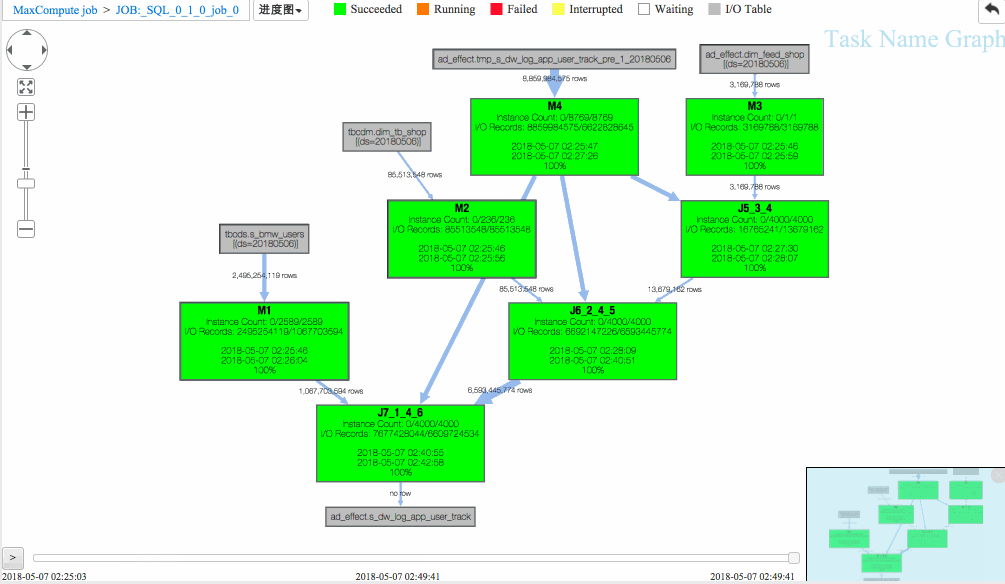
作业一 进度图回放
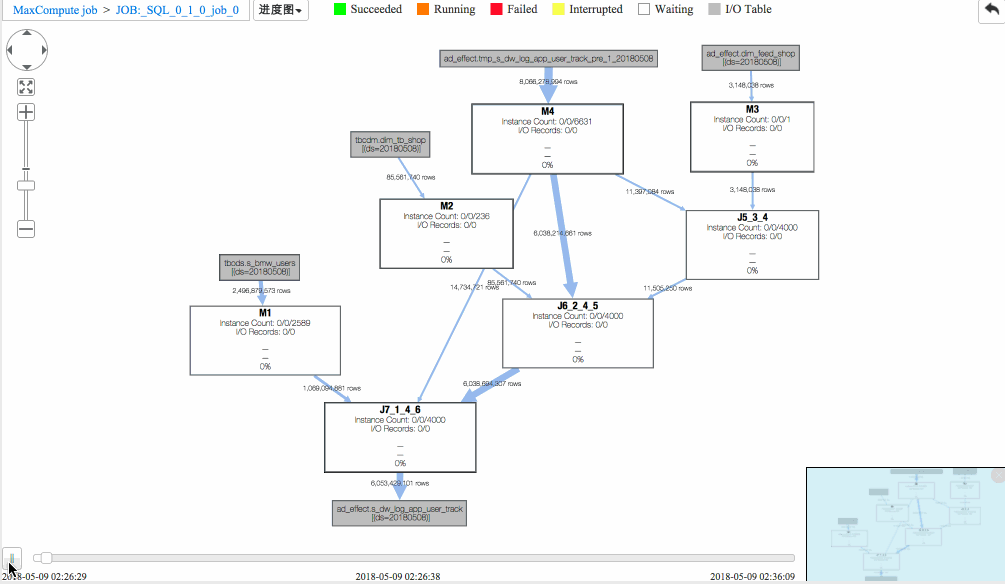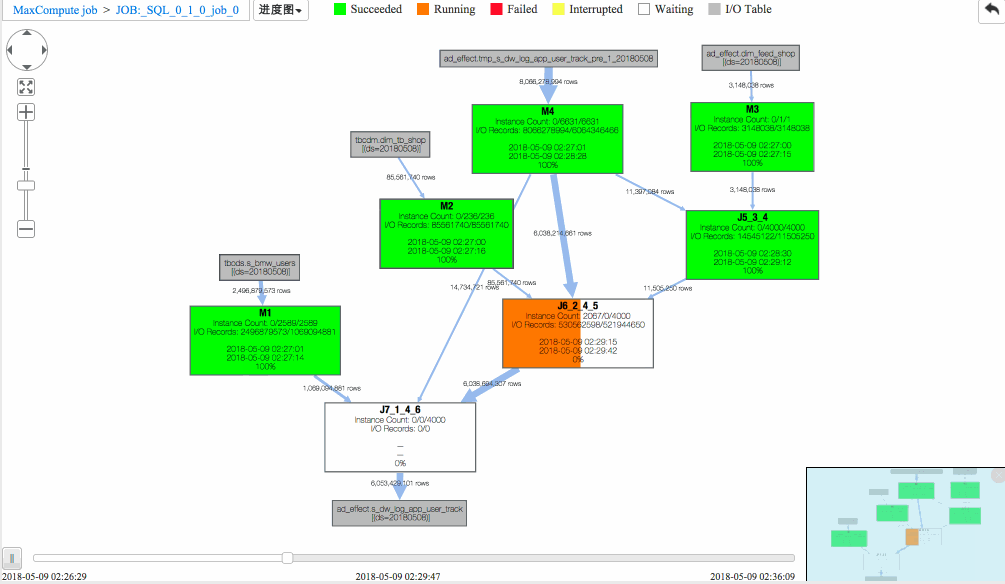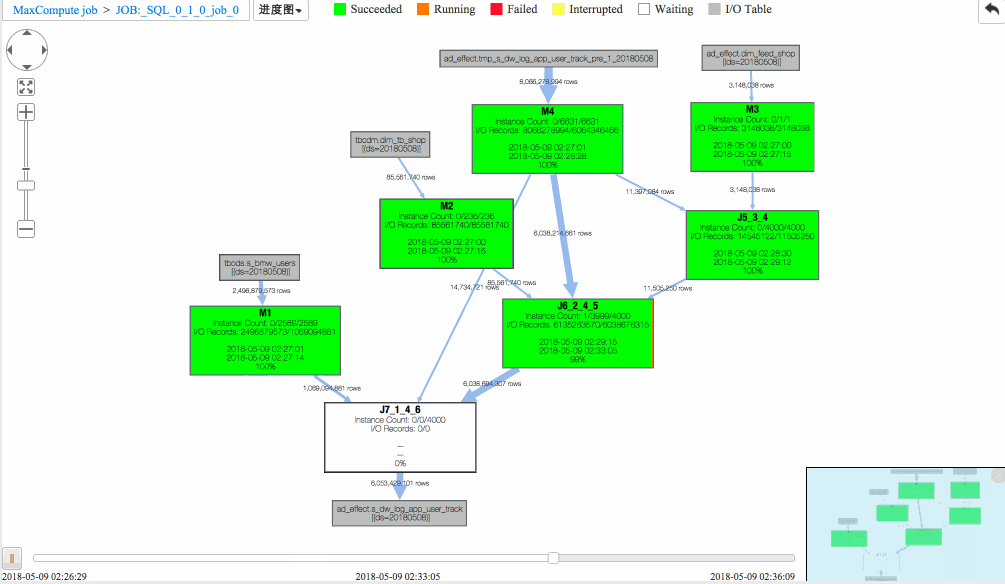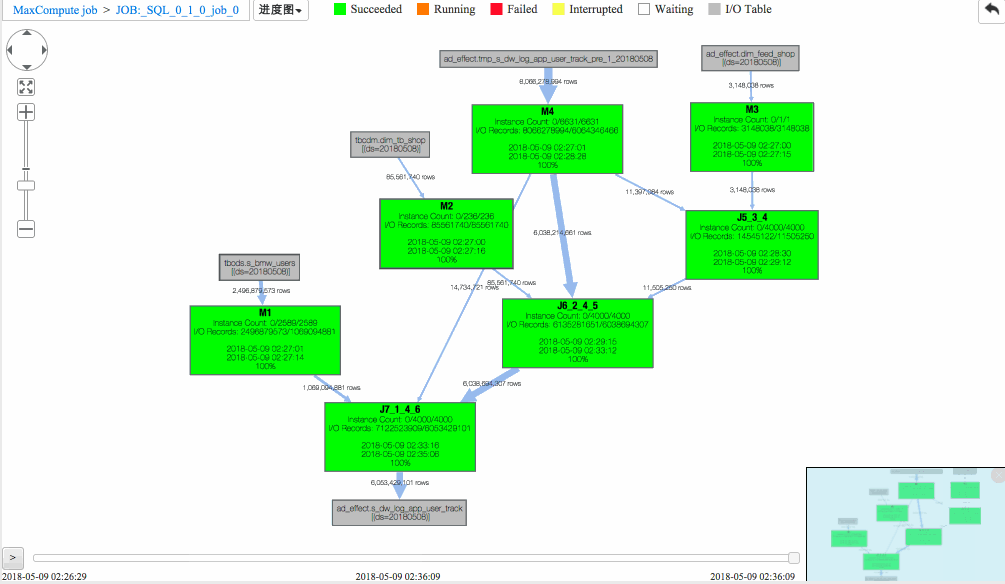
作业二 进度图回放
从回放中可以看出
(1)J6_2_4_5 task是整个作业瓶颈,时间消耗最多,从task热度图中也能发现该节点明显热于其它节点。(时间热度图上越红代表运行时间越长,数据热度图上越红代表处理数据越多)
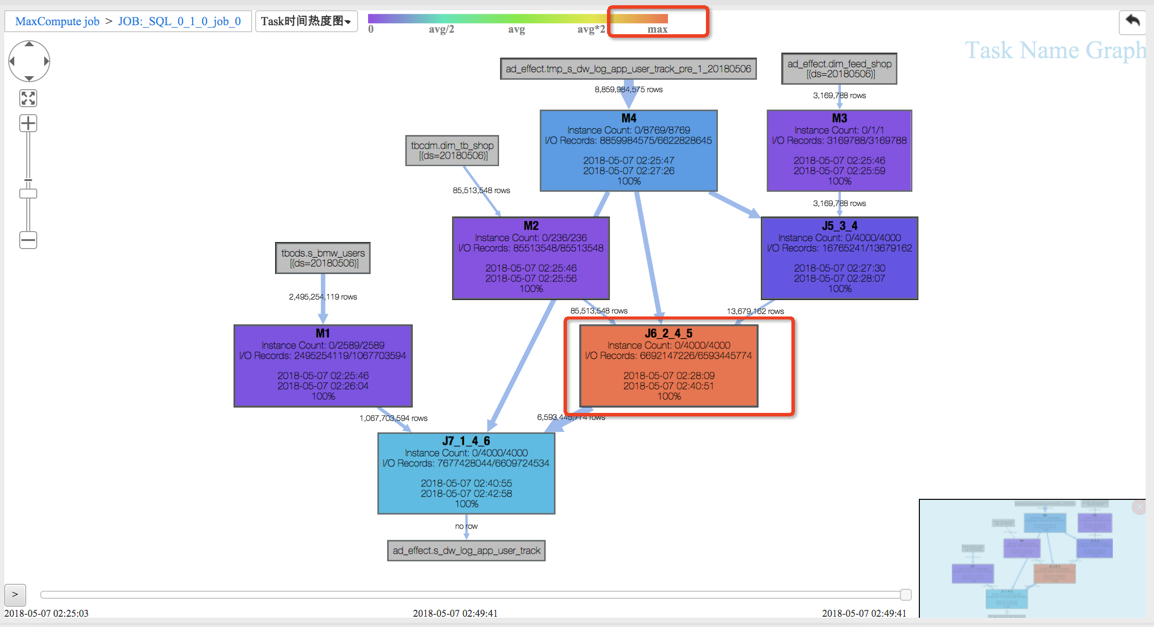
(2)同时对比两个作业的回放过程,能够比较明显地发现作业一在J6_2_4_5运行时长要大于作业二,说明作业一在J6_2_4_5阶段变慢了,初步怀疑有长尾节点产生。
接下来切换到时序图tab,比较两个作业的执行timeline:
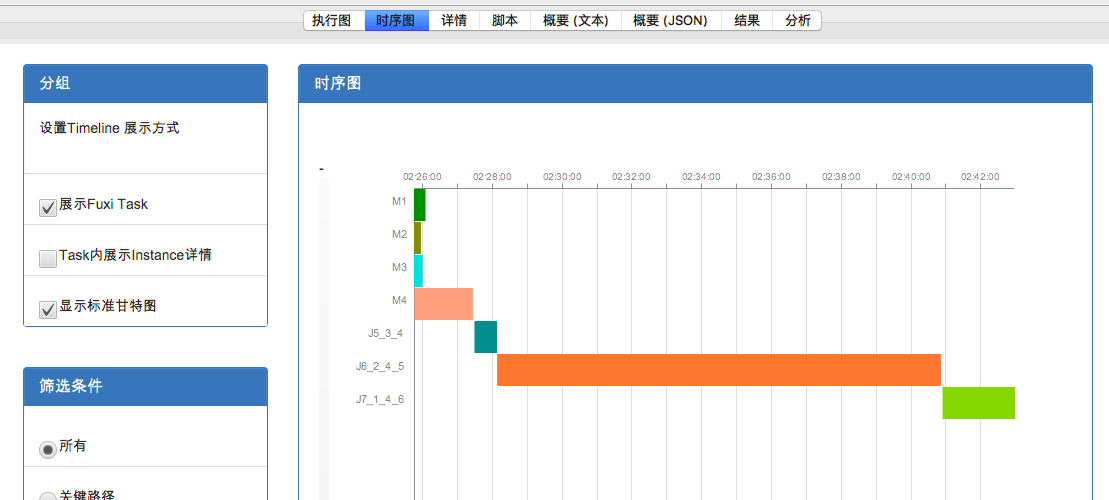
作业一 执行timeline
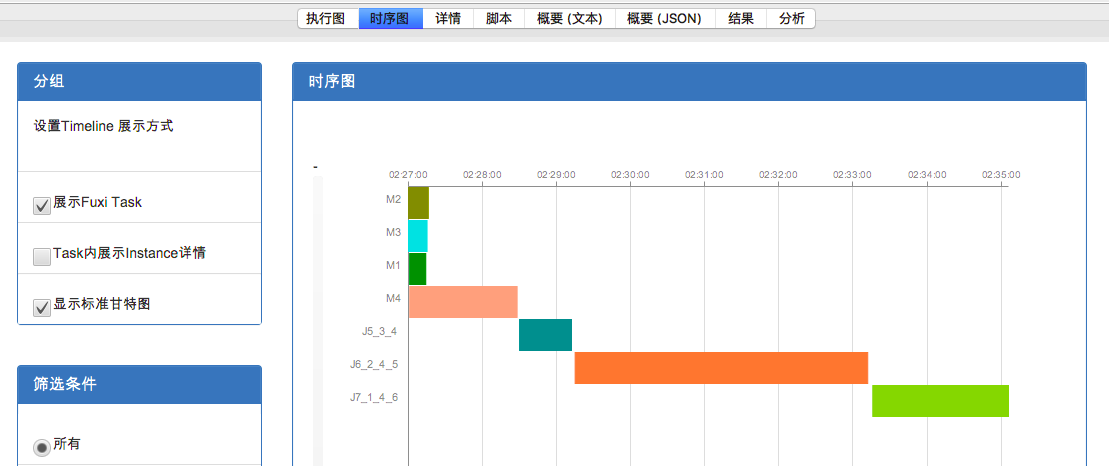
作业二 执行timeline
虽然两个作业timeline的时间尺度不同,但是可以明显看出,作业一中J6_2_4_5 占了更长的比例,由此可以断定是J6_2_4_5 在05-07执行(也就是作业一)发生可能长尾,导致整个作业执行变慢。
进入深水区
第四步,通过graph或detail tab 对比J6_2_4_5 的输入数据量
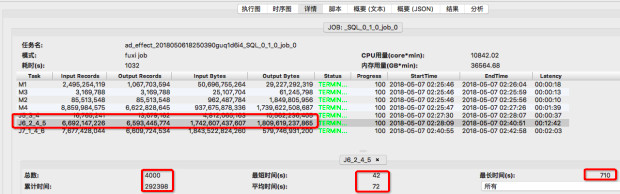
作业一 detail tab
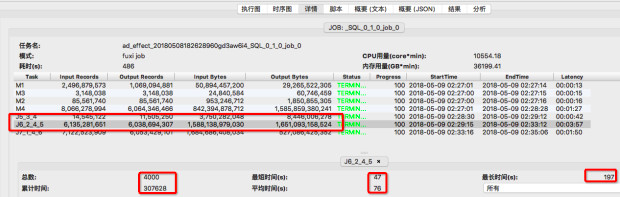
作业二 detail tab
关注上图中J6_2_4_5 输入数据量和统计信息,通过比较可看出,两次执行的J6_2_4_5 输入数据量基本相同,1.58万亿字节 vs 1.7万亿字节,从统计信息来看,累计执行时间及平均时间也基本相同:292398 vs 307628, 72s vs 76s 但作业一 fuxi instances中的最长执行时间为710s, 由此可以认定是某几个fuxi instance长尾导致了J6_2_4_5 这个fuxi task的长尾。
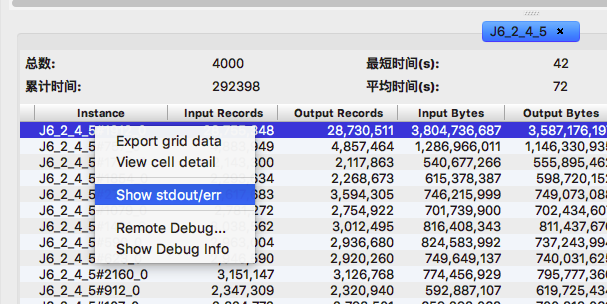
第五步,对两个 J6_2_4_5 fuxi instance 列表按照latency 排序:

作业一

作业二
或者转到分析tab下的长尾页面查找长尾节点:注意这个图中的比例尺是以等比而不是等差方式标定的,因此,上面突出的比较长的毛刺就很可能是长尾的实例了。可以通过浮动窗口中的具体信息来判断。 另外 Studio 也提供了诊断的页面,来自动找出超过平均实例执行时间两倍的长尾实例。
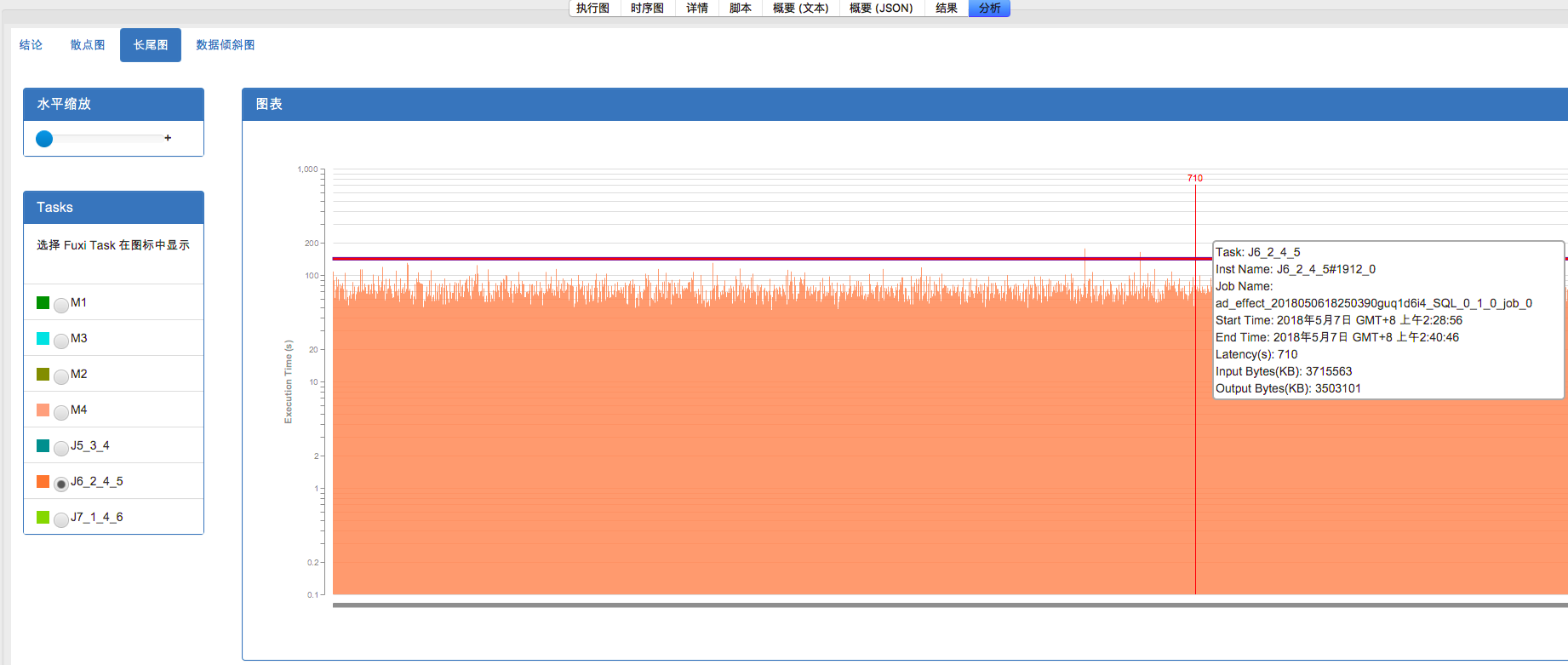
作业一
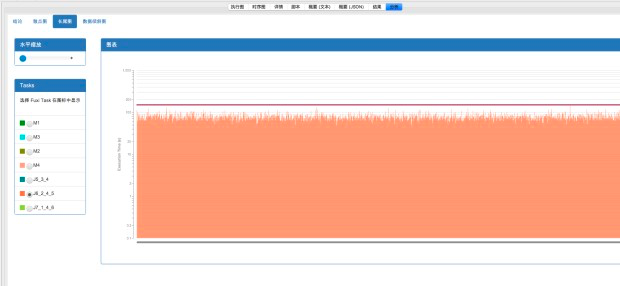
作业二
从上面fuxi instance 输入数据对比可以确定,因为J6_2_4_5#1912_0 这个instance 数据倾斜导致整个作业一长尾。即J6_2_4_5#1912_0 是latency排第二的输入数据量的7倍!
渐入佳境,刨根问底
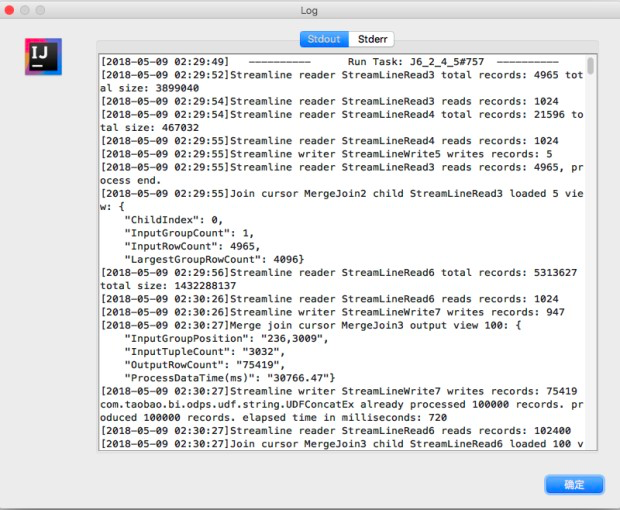
第六步,查看单个instance的执行日志,并通过job graph分析J6_2_4_5的具体执行计划,找到导致长尾的数据来源。
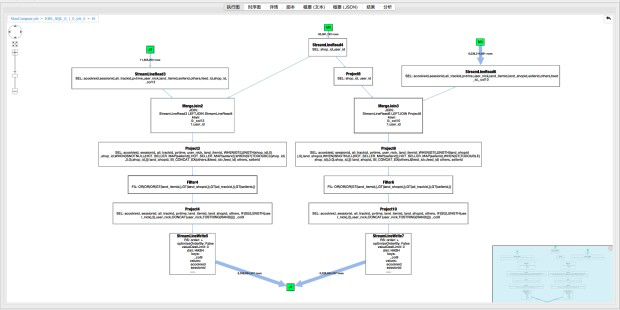
打开J6_2_4_5的operator graph, 可以看到有两个join:Merge Join2和Merge Join3,这里以Merge Join2为例展示如何查找数据来源。
从Merge Join2中可看到join key:_col13, user_id。 其中_col13 来自于J5, 点开J5后发现_col13来自IF(ISNULL(HOT_SELLER_MAP(sellerid)),sellerid,CONCAT(seller,TOSTRING(RAND()))) 说明_col13由seller决定,该seller来自于M4和M3。
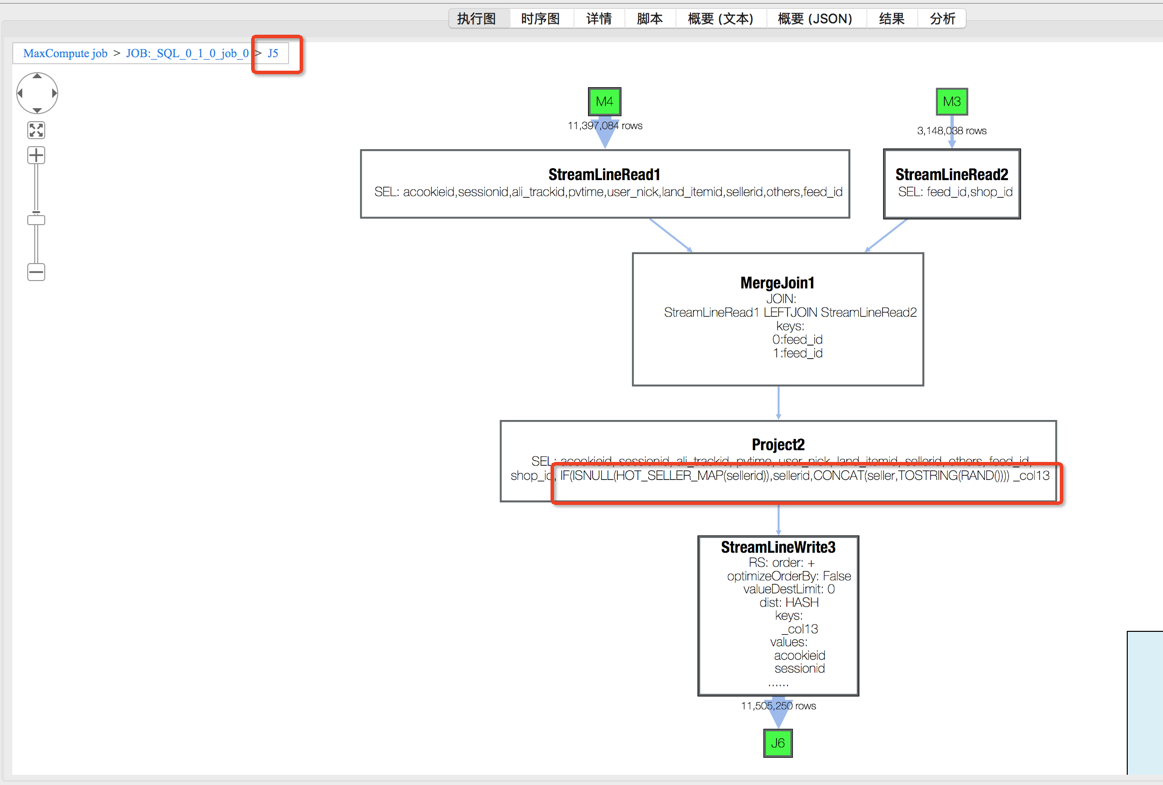
J5 operator详细信息
分别打开M4和M3的Operator详细信息,可以看到seller 分别来自tmp_s_dw_log_app_user_track_pre_1_20180508 和dim_feed_shop。
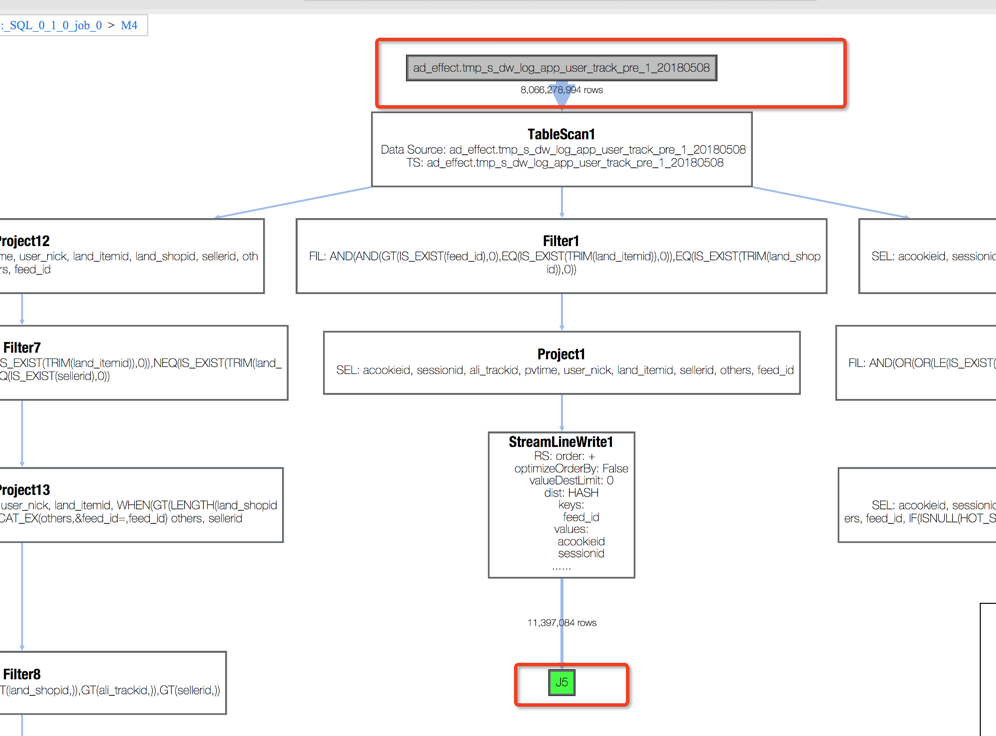
M4 Operator详细信息

M3 Operator详细信息
同理可以分析出Merge Join2 的user_id 来自于dim_tb_shop。
最后,通过写sql模拟产生对应的userid及_col13,比较这两个字段的数据量大小,在针对sql脚本进行优化即可。



相关推荐
拓展游戏:善用注意力.pdf
。。。
A1技术支持的学情分析作业1—学情分析方案道德与法治.pdf
人教部编版八年级上册政治同步练习:53善用法律.docx
(部编版)八年级道德与法治上册试卷:5.3善用法律.pdf
(部编版)八年级道德与法治上册试题:5.3善用法律.pdf
(部编版)八年级道德与法治上册试题:5.3善用法律.docx
(部编版)八年级道德与法治上册试卷:5.3善用法律.docx
(部编版)八年级道德与法治上册试题:5.3善用法律.docx
(部编版)八年级道德与法治上册试卷:5.3善用法律.docx
资源名称:善用GOOGLE--从入门到精通内容简介:一 GOOGLE简介 2 二 GOOGLE特色 2 三 基本搜寻: , -, OR 2 四 辅助搜寻:万用符号、大小写、句子、忽略字符以及强制搜寻 3 五 关键词搜寻技巧 4 六 进阶搜寻:...
我一直觉得编程某种意义上是一门...『Python工匠』这个系列文章,是我的一次小小尝试。它专注于分享Python编程中的一些偏『小』的东西。希望能够帮到每一位编程路上的匠人。 作为『Python工匠』系列文章的第一篇,
(部编版)八年级道德与法治上册试题:53善用法律.doc.pdf
(部编版)八年级道德与法治上册试题:53善用法律.doc.docx
不和谐表情符号录制机器人此Bot将于2020年底出售,由于我们要出售的人对我们有问题,因此Bot已被共享,他可能先共享了它,但不要忘记,他知道代码的所有者如有任何问题,请随时寻求帮助。
人教版2020-2021年八年级道德与法治上册教案:5.3善用法律.pdf
人民云充分利用僵尸网络的思想此页面上的文档始终在构建中 :warning_selector:目的与意图创建一个技术解决方案,以便具有计算能力的人可以与他人共享它。 在当前的迭代中,这是针对机器人制造商的,以便具有服务器的...
善用佳软:高效能人士的软件之道