
Spark Streaming运行原理
spark程序是使用一个spark应用实例一次性对一批历史数据进行处理,spark streaming是将持续不断输入的数据流转换成多个batch分片,使用一批spark应用实例进行处理。
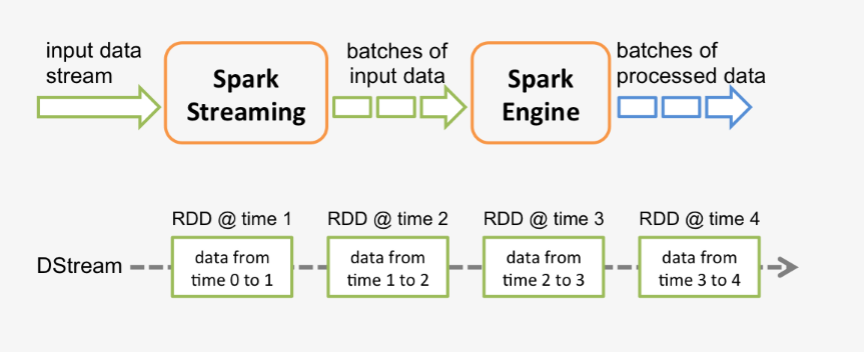
从原理上看,把传统的spark批处理程序变成streaming程序,spark需要构建什么?
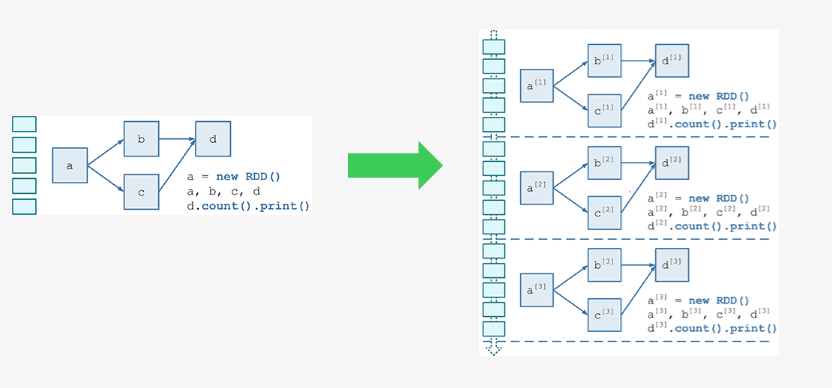
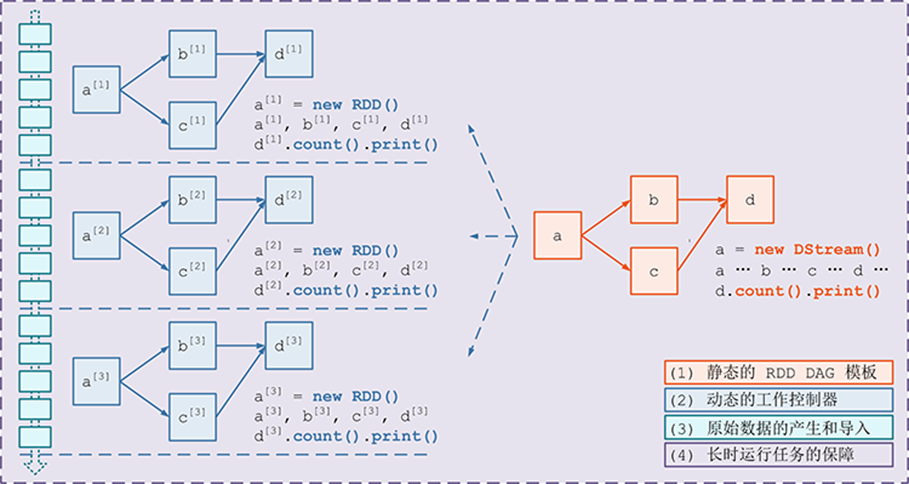
需要构建4个东西:
-
一个静态的 RDD DAG 的模板,来表示处理逻辑;
-
一个动态的工作控制器,将连续的 streaming data 切分数据片段,并按照模板复制出新的 RDD ;
-
DAG 的实例,对数据片段进行处理;
-
Receiver进行原始数据的产生和导入;Receiver将接收到的数据合并为数据块并存到内存或硬盘中,供后续batch RDD进行消费;
-
对长时运行任务的保障,包括输入数据的失效后的重构,处理任务的失败后的重调。
具体streaming的详细原理可以参考广点通出品的源码解析文章:
对于spark streaming需要注意以下三点:
- 尽量保证每个work节点中的数据不要落盘,以提升执行效率。
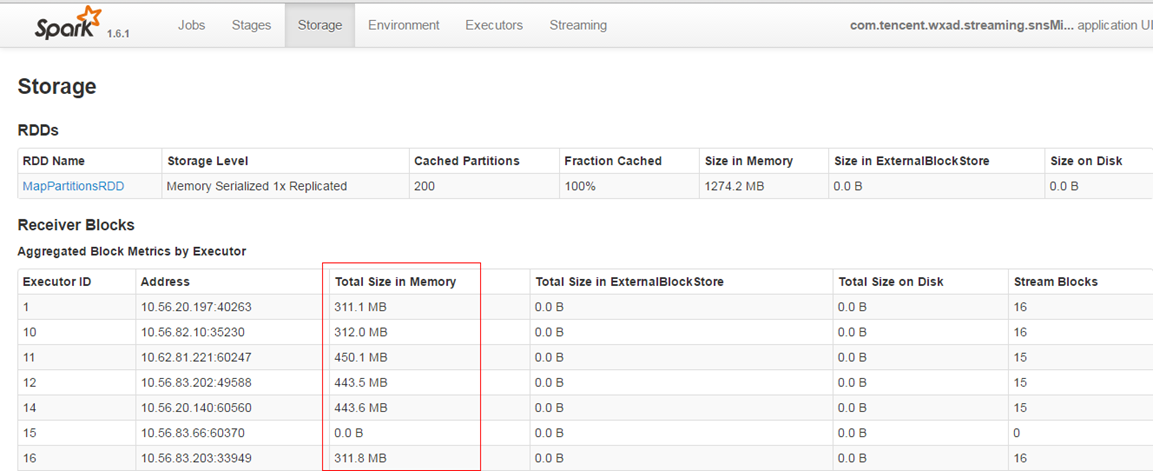
- 保证每个batch的数据能够在batch interval时间内处理完毕,以免造成数据堆积。
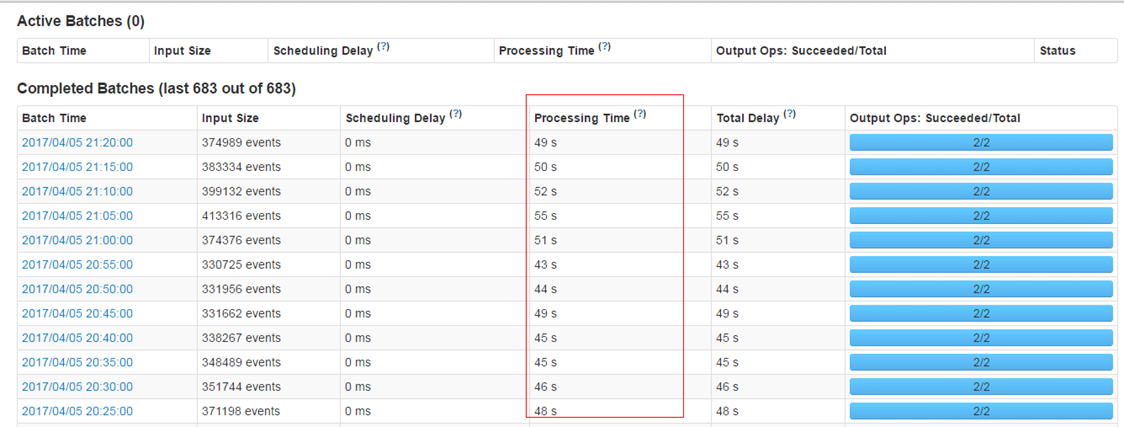
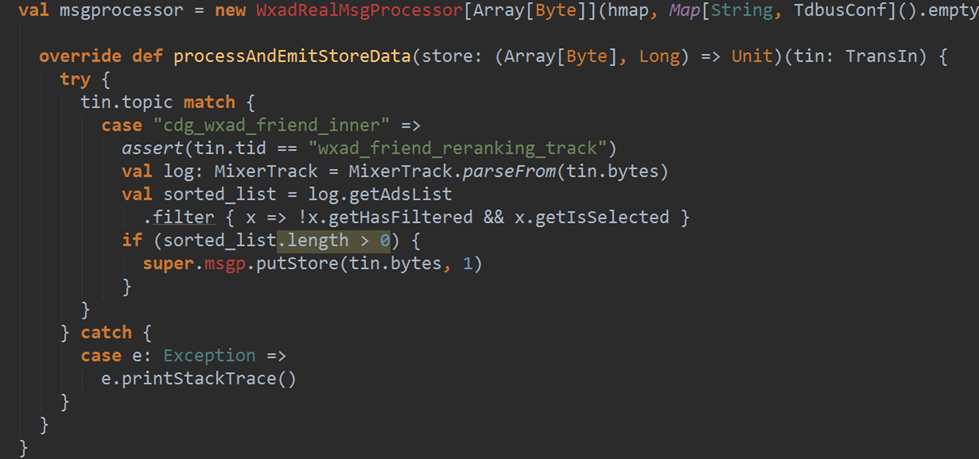
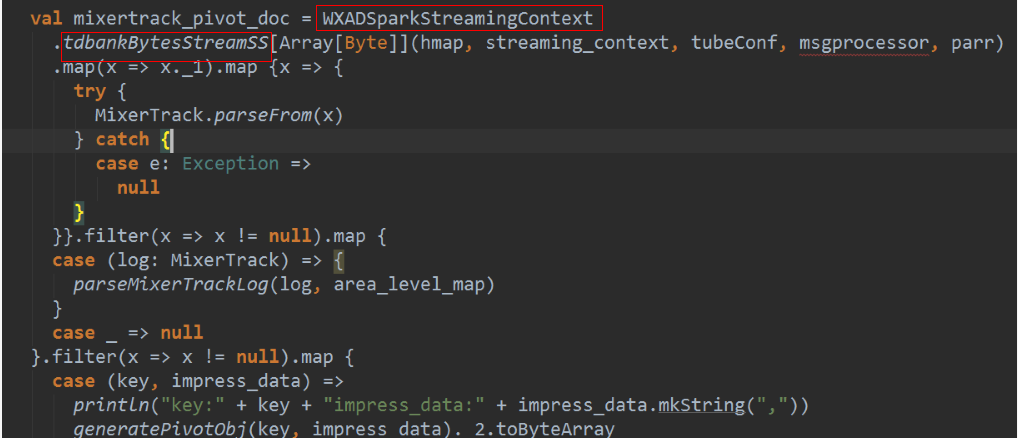
- 使用steven提供的框架进行数据接收时的预处理,减少不必要数据的存储和传输。从tdbank中接收后转储前进行过滤,而不是在task具体处理时才进行过滤。
Spark 资源调优
内存管理:
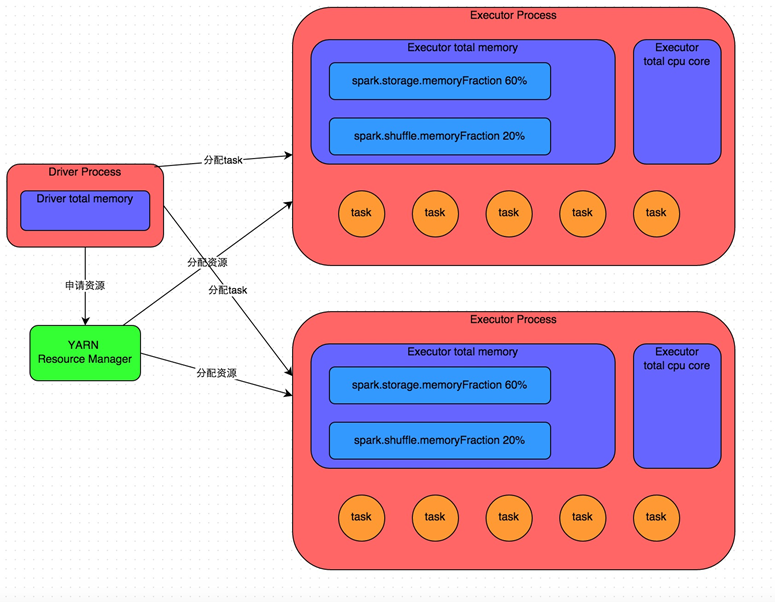
Executor的内存主要分为三块:
第一块是让task执行我们自己编写的代码时使用,默认是占Executor总内存的20%;
第二块是让task通过shuffle过程拉取了上一个stage的task的输出后,进行聚合等操作时使用,默认也是占Executor总内存的20%;
第三块是让RDD持久化时使用,默认占Executor总内存的60%。
每个task以及每个executor占用的内存需要分析一下。每个task处理一个partiiton的数据,分片太少,会造成内存不够。
其他资源配置:

具体调优可以参考美团点评出品的调优文章:
http://tech.meituan.com/spark-tuning-basic.html
http://tech.meituan.com/spark-tuning-pro.html
Spark 环境搭建
spark tdw以及tdbank api文档:
http://git.code.oa.com/tdw/tdw-spark-common/wikis/api
其他学习资料:
http://km.oa.com/group/2430/articles/show/257492
原文链接:https://www.qcloud.com/community/article/770164
https://www.cnblogs.com/liuliliuli2017/p/6809094.html



相关推荐
本文依次从spark生态,原理,基本概念,sparkstreaming原理及实践,还有spark调优以及环境搭建等方面进行介绍,希望对大家有所帮助。运行速度快Spark拥有DAG执行引擎,支持在内存中对数据进行迭代计
7.SparkStreaming(上)--SparkStreaming原理介绍.pdf 7.SparkStreaming(下)--SparkStreaming实战.pdf 8.SparkMLlib(上)--机器学习及SparkMLlib简介.pdf 8.SparkMLlib(下)--SparkMLlib实战.pdf 9.SparkGraphX...
Spark Streaming 是 Spark 核心 API 的一个扩展,可以实现高吞吐量的、具备容错机制的 实时流数据的处理。支持从多种数据源获取数据,包括 Kafk、Flume、Twitter、ZeroMQ、Kinesis 以及 TCP sockets,从数据源获取...
2、现场动手画图讲解Spark原理以及源码(绝对不是干讲源码和PPT); 3、覆盖Spark所有功能点(Spark RDD、Spark SQL、Spark Streaming,初级功能到高级特性,一个不少); 4、Scala全程案例实战讲解(近百个趣味性...
SparkStreaming是Spark核心API的一个扩展,可以实现高吞吐量的、具备容错机制的实时流数据的处理。支持从多种数据源获取数据,包括Kafk、Flume、Twitter、ZeroMQ、Kinesis以及TCPsockets,从数据源获取数据之后,...
本书以源码为基础,深入分析spark内核的设计理念和架构实现,系统讲解各个核心模块的实现,为性能调优、二次开发和系统运维提供理论支持,为更好地使用Spark Streaming、MLlib、Spark SQL和GraphX等奠定基础。
本书共分为四大部分:, 基础篇(1~10章)介绍了Spark的用途、扩展、安装、运行模式、程序开发、编程模型、工作原理,以及SparkSQL、SparkStreaming、MLlib、GraphX、Bagel等重要的扩展;, 实战篇(11~14)讲解了...
5.SparkStreaming工作原理 6.DStream及函数 7.集成Kafka 8.案例:百度搜索风云榜(实时ELT、窗口Window和状态State) 9.SparkStreaming Checkpoint 10.消费Kafka偏移量管理 第六章、StructuredStreaming模块 1....
, 扩展篇(第8~11章),主要讲解基于Spark核心的各种扩展及应用,包括SQL处理引擎、Hive处理、流式计算框架Spark Streaming、图计算框架GraphX、机器学习库MLlib等内容。通过阅读这部分内容,读者可以扩展实际项目...
通过学习Spark,我了解了其基本概念和核心组件,如RDD(弹性分布式数据集)、Spark SQL、Spark Streaming和MLlib等。我学会了使用Spark编写分布式的数据处理程序,并通过调优技巧提高了程序的性能。在实践过程中,我...
通过学习Spark,我了解了其基本概念和核心组件,如RDD(弹性分布式数据集)、Spark SQL、Spark Streaming和MLlib等。我学会了使用Spark编写分布式的数据处理程序,并通过调优技巧提高了程序的性能。在实践过程中,我...
第2章 Spark2.2技术及原理... 14 2.1 Spark 2.2综述... 14 2.1.1 连续应用程序... 14 2.1.2 新的API 15 2.2 Spark 2.2 Core. 16 2.2.1 第二代Tungsten引擎... 16 2.2.2 SparkSession. 16 2.2.3 累加器API 17 ...
本文将详细介绍SparkStreaming实时计算框架的原理与特点、适用场景。Spark是一个类似于MapReduce的分布式计算框架,其核心是弹性分布式数据集,提供了比MapReduce更丰富的模型,可以在快速在内存中对数据集进行多次...
本书以源码为基础,深入分析Spark内核的设计理念和架构实现,系统讲解各个核心模块的实现,为性能调优、二次开发和系统运维提供理论支持,为更好地使用Spark Streaming、MLlib、Spark SQL和GraphX等奠定基础。
, 扩展篇(第8~11章),主要讲解基于Spark核心的各种扩展及应用,包括SQL处理引擎、Hive处理、流式计算框架Spark Streaming、图计算框架GraphX、机器学习库MLlib等内容。通过阅读这部分内容,读者可以扩展实际项目...