
kafka原理解析
//更多文章请访问主页:https://blog.csdn.net/yuyuyuxiaolei
Apache的Kafka™是一个分布式流平台(a distributed streaming platform)。这到底意味着什么?
我们认为,一个流处理平台应该具有三个关键能力:
- 它可以让你发布和订阅记录流。在这方面,它类似于一个消息队列或企业消息系统。
- 它可以让你持久化收到的记录流,从而具有容错能力。
- 它可以让你处理收到的记录流。
Kafka擅长哪些方面?
它被用于两大类应用:
- 建立实时流数据管道从而能够可靠地在系统或应用程序之间的共享数据
- 构建实时流应用程序,能够变换或者对数据
- 进行相应的处理。
想要了解Kafka如何具有这些能力,让我们从下往上深入探索Kafka的能力。
首先,明确几个概念:
- Kafka是运行在一个或多个服务器的集群(Cluster)上的。
- Kafka集群分类存储的记录流被称为主题(Topics)。
- 每个消息记录包含一个键,一个值和时间戳。
分布式消息系统kafka的提供了一个生产者、缓冲区、消费者的模型
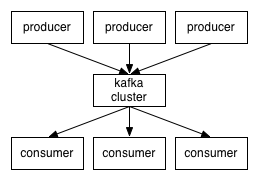
broker:中间的kafka cluster,存储消息,是由多个server组成的集群
topic:kafka给消息提供的分类方式。broker用来存储不同topic的消息数据
producer:往broker中某个topic里面生产数据
consumer:往broker中某个topic获取数据
设计思想
topic与消息
kafka将所有消息组织成多个topic的形式存储,而每个topic又可以拆分成多个partition,每个partition又由一个一个消息组成。每个消息都被标识了一个递增序列号代表其进来的先后顺序,并按顺序存储在partition中。

这样,消息就以一个个id的方式,组织起来。
producer选择一个topic,生产消息,消息会通过分配策略append到某个partition末尾
consumer选择一个topic,通过id指定从哪个位置开始消费消息。消费完成之后保留id,下次可以从这个位置开始继续消费,也可以从其他任意位置开始消费
这个id,在kafka中被称为offset
这种组织和处理策略提供了如下好处:
消费者可以根据需求,灵活指定offset消费
保证了消息不变性,为并发消费提供了线程安全的保证。每个consumer都保留自己的offset,互相之间不干扰,不存在线程安全问题
消息访问的并行高效性。每个topic中的消息被组织成多个partition,partition均匀分配到集群server中。生产、消费消息的时候,会被路由到指定partition,减少竞争,增加了程序的并行能力
增加消息系统的可伸缩性。每个topic中保留的消息可能非常庞大,通过partition将消息切分成多个子消息,并通过负责均衡策略将partition分配到不同server。这样当机器负载满的时候,通过扩容可以将消息重新均匀分配
保证消息可靠性。消息消费完成之后不会删除,可以通过重置offset重新消费,保证了消息不会丢失
灵活的持久化策略。可以通过指定时间段(如最近一天)来保存消息,节省broker存储空间
消息以partition为单位分配到多个server,并以partition为单位进行备份。备份策略为:1个leader和N个followers,leader接受读写请求,followers被动复制leader。leader和followers会在集群中打散,保证partition高可用
producer
producer生产消息需要如下参数:
topic:往哪个topic生产消息
partition:往哪个partition生产消息
key:根据该key将消息分区到不同partition
message:消息
根据kafka源码,可以根据不同参数灵活调整生产、分区策略
iftopic isNonethrowErrorp=NoneifpartitionNotNoneifpartition< 0Orpartition>= numPartitions throwErrorp=partitionelif key NotNonep=hash(key) % numPartitionselsep=round-robin() % numPartitionssend message to the partitionp
上面是我翻译的伪代码,其中round-robin就是简单轮询,hash采用的是murmurhash
consumer
传统消息系统有两种模式:
队列
发布订阅
kafka通过consumer group将两种模式统一处理

每个consumer将自己标记consumer group名称,之后系统会将consumer group按名称分组,将消息复制并分发给所有分组,每个分组只有一个consumer能消费这条消息。
于是推理出两个极端情况:
当所有consumer的consumer group相同时,系统变成队列模式
当每个consumer的consumer group都不相同时,系统变成发布订阅
多consumer并发消费消息时,容易导致消息乱序

通过限制消费者为同步,可以保证消息有序,但是这大大降低了程序的并发性。
kafka通过partition的概念,保证了partition内消息有序吗,缓解了上面的问题。partition内消息会复制分发给所有分组,每个分组只有一个consumer能消费这条消息。这个语义保证了某个分组消费某个分区的消息,是同步而非并发的。如果一个topic只有一个partition,那么这个topic并发消费有序,否则只是单个partition有序。
一般消息消息系统,consumer存在两种消费模型:
push:优势在于消息实时性高。劣势在于没有考虑consumer消费能力和饱和情况,容易导致producer压垮consumer
pull:优势在可以控制消费速度和消费数量,保证consumer不会出现饱和。劣势在于当没有数据,会出现空轮询,消耗cpu
kafka采用pull,并采用可配置化参数保证当存在数据并且数据量达到一定量的时候,consumer端才进行pull操作,否则一直处于block状态
kakfa采用整数值consumer position来记录单个分区的消费状态,并且单个分区单个消息只能被consumer group内的一个consumer消费,维护简单开销小。消费完成,broker收到确认,position指向下次消费的offset。由于消息不会删除,在完成消费,position更新之后,consumer依然可以重置offset重新消费历史消息



相关推荐
kafka原理解析 学习消息中间件的佳作。内容翔实,有丰富的实践代码(Kafka核心原理与实战 【整理人:北京海子】 )
本文是系列文章的第4篇,第一篇"第二篇第三篇第四篇第五篇第六篇《Kafka设计解析》系列上一篇《Kafka高性能架构之道——Kafka设计解析(六)》从宏观架构到具体实现分析了Kafka实现高性能的原理。本文介绍了Kafka...
针对kafka设计原理作了深入的解析,通过该文档可以了解kafka的设计理念和原理。
Kafka源码解析与实战,讲述了kafka的基本原理、架构及源码,并有实战项目
kafka架构原理 1、kafka架构原理简介 2、kafka架构原理深度解析 3、常见问题以及处理方案 4、各种消息中间件的对比 ps:可用于公司技术分享
《深入理解Kafka:核心设计与实践原理》从Kafka的基础...《深入理解Kafka:核心设计与实践原理》主要阐述了Kafka中生产者客户端、消费者客户端、主题与分区、日志存储、原理解析、监控管理、应用扩展及流式计算等内容
本文详细解析了Kafka的设计原理,重点介绍了Kafka作为一种高效的分布式消息系统的核心组件和机制。首先,文档解释了Kafka的总控制器(Controller)的作用,它负责管理集群中的分区和副本状态,并在必要时进行Leader...
由kafka作者书写的kafka的的指南书籍,全方位解析kafka内部原理
由kafka作者书写的kafka的的指南书籍,全方位解析kafka内部原理
本文档提供了对Kafka这一分布式消息系统的全面解析,从基本概念到实际应用,涵盖了其在日志收集、消息系统、用户活动跟踪等方面的使用场景。首先介绍了Kafka的核心概念,如Broker、Topic、Producer、Consumer等,...
1. 什么是kafka? 2. 消息队列介绍 3. 为什么使用消息队列? 4. kafka的特点 5. kafka的使用场景 6. kafka系统的架构基础(重点) 7. kafka的物理存储目录结构 ...20. kafka原理加强—日志分段条件 .....
业界大牛带你看kafka源码,图文解析kafka生产和消费模型,快速深入掌握kafka核心知识
strom zookeeper kafka 部署文档 原理解析
该代码包含kafka的生产者、消费者原理详解,各种参数解析,主题、分区、存储等的代码演示,可用于搭配博客学习
(1) 管理员设置策略以及用户(例如一个用户对一个hive数据库相关的权限)
亚马逊河 amazonriver是一个将postgresql的实时数据同步到es或kafka的服务版本支持Postgresql 9.4或更高版本Kafka 0.8或更高版本ElasticSearch 5.x架构图原理amazonriver利用pg内部的逻辑复制功能,通过在pg创建逻辑...
canal解析binlog的数据,由syncClient订阅,然后实时推送到kafka或者redis、elasticsearch、httpmq、ssdb;如果kafka、redis、es、httpmq服务异常,syncClient会回滚操作;canal、kafka、redis、es、httpmq的异常...
全套视频下载 离线部分课程主要包括:hadoop、hive、flume、azkban、hbase等以及项目实战 实时部分课程主要包括:storm、...内存计算部分课程主要包括:scala编程、spark原理、spark源码解析、机器学习以及项目实战
MySQL 小林coding图解 MySQL MySQL 常考题 MySQL数据库经典面试题解析 MySQL InnoDB MVCC 机制的原理及实现 为什么MySQL使用B+树做索引? 20 道 MySQL 面试题 看一遍就理解:order by 详解