
大数据时代,分布式缓存领域,大家可能较为熟悉Redis,当红一哥,还有经典老将Memcached, 以及新秀Apache Ignite, 当然还有Oracle的Coherence内存数据网格,今天我们主要关注投行金融领域的分布式缓存一哥Gemfire。
Gemfire的第一个商业版本由GemStone公司操刀正式发布于2002-2003年间,成为业界J2EE JCache -JSR107标准的中间件,兼容Java, C++, C#, 并在CEP(Complex Event Processing)处理领域一枝独秀。2008年借着金融危机之际凭着其实力击败老牌厂商Oracle, 大举进入华尔街金融领域,而其中Citi则是Gemfire的铁粉,据称全球2/3的Gemfire应用跑在Citi的服务器上,尤其是固定收益类交易系统的最爱,各位老友看到请自动点赞举牌。之后GemStone被Spring之父Rod Johnson在当时的VMare时慧眼识珠,2010年收购并入SpringSource部门作为进军Cloud以及大数据的入口,目前则与Spring一并成为Pivotal中重要的In-Memory Data Grid, 并于2015年其核心模块开源为Apache Geode核心项目。
Gemfire整体分布式架构
总体来说Gemfire提供了基于内存的海量数据实时处理平台,包括低延迟高吞吐,线性动态扩展(流行的话叫“弹性水平扩展”),HA,MapReduce,听起来很Hadoop, 这些是一切后SQL时代的分布式大数据产品入门款必备装备。

核心概念

Region
Region是Gemfire中一Map的分布式实现,同时具备了支持查询,事务。这个是Gemfire的核心中核心,一切的一切始于此。
Replicated Region: 一个Replicated Region保存所有分区的数据拷贝。
Partitioned Region: 只保存一部分分区的数据拷贝。
Shared-Nothing Persistence
支持非共享持久化,每一个peer持久化数据到本地磁盘,Gemfire持久化允许在磁盘维护一份配置的数据拷贝
Distributed
Distributed Member: Gemfire托管的集群中成员
Distributed Transaction: 跨节点,集群更新事务,分布式事务。
Distrbuted Lock: 分布式集群锁
Locator & Gateway
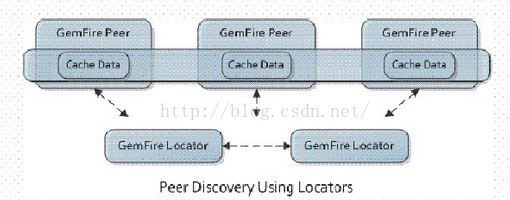
Gemfire的Locator类似ZooKeeper, 协调客户端与服务器成员,相互发现,以及简单负载均衡(非负荷均载)。
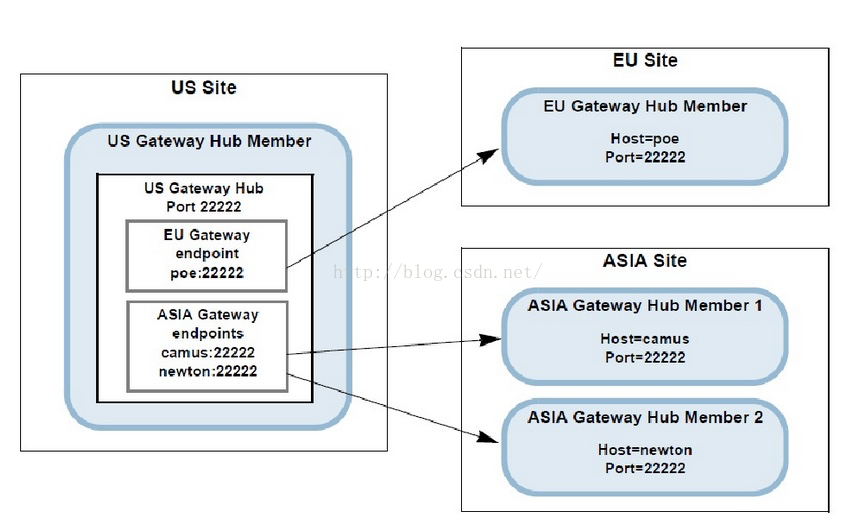
Gateway: 作为Gemfire跨WAN网同步数据,如HK, TK, NY等。
拓扑结构
1. Peer-to-Peer
缓存潜入应用,共享堆内存,适合小型缓存应用。
原以为这种架构在企业,金融机构无用武之地,殊不知一些大型金融机构的小型IT项目竟然采用此架构,没办法cowboy,今天需求明天生产。
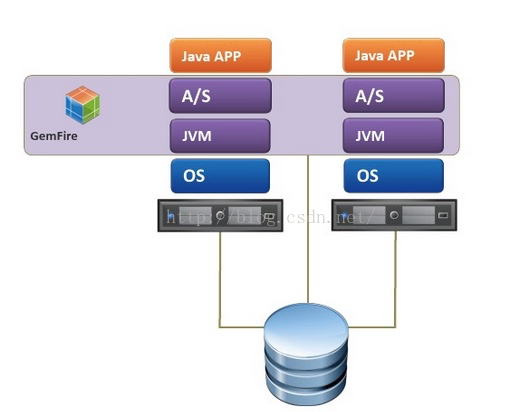
2. Client/Server结构
缓存层由分布式集群系统来组成,是多数中大型系统首选。
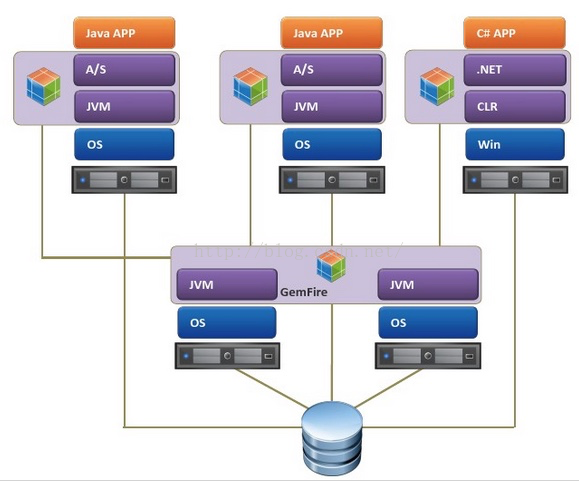
其中分布式引入Loactor来管理,结耦,离散,分布客户端与服务器端。
客户端服务器发现机制:
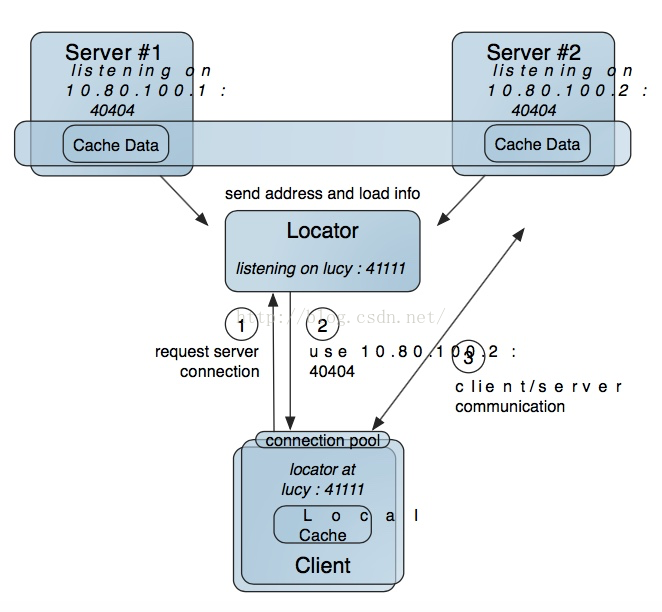
可以看出客户端与服务器通信要先透过Locator提供的发现机制,当然鉴于此所有的服务器端必须与Locator进行通信广播其生死状态,类似ZK。Locator通过JVM广播消息或者TCP实现通信定位。每个新加入或者离开的成员都会更新Loactor,并从Locator上发现目前可用成员列表。
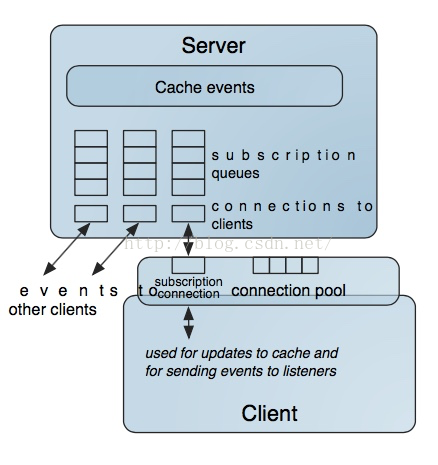
我们看一下客户端完整通信图:
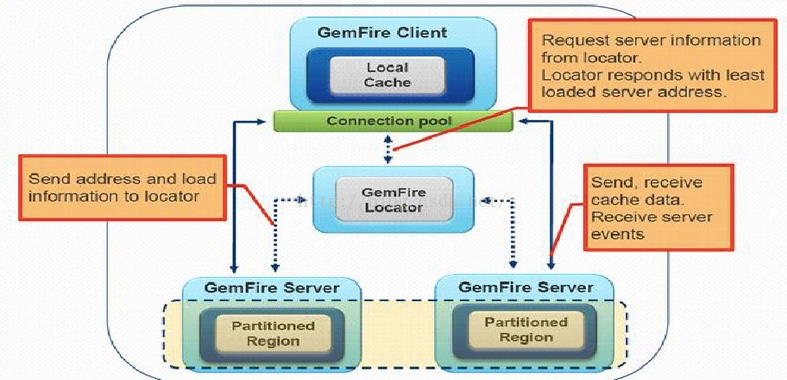
另外,Locator可以提供简单负载均衡,只是基于当前服务器是否有客户端连接而已。Gemfire提供了垮节点将键值对均匀分布到节点,以及一致性哈希算法等。
如果希望定制负载负荷均衡,Gemfire提供了Member Groups,可以把某些服务器分组,固定为某些客户/某类请求服务,再获得负荷均衡的优势同时也失去了全局分布式的优势,正所谓有利有弊。
Server内部提供了connection poor,queue以及subscription机制,以并行处理以CEP事件通知机制。同样,Gemfire客户端也提供了connection pool。
老司机看到这里肯定会说,全局就一个Locator一定会造成单点故障,当然分布式系统的必备。Gemfire也提供了启动多个Locator的能力。
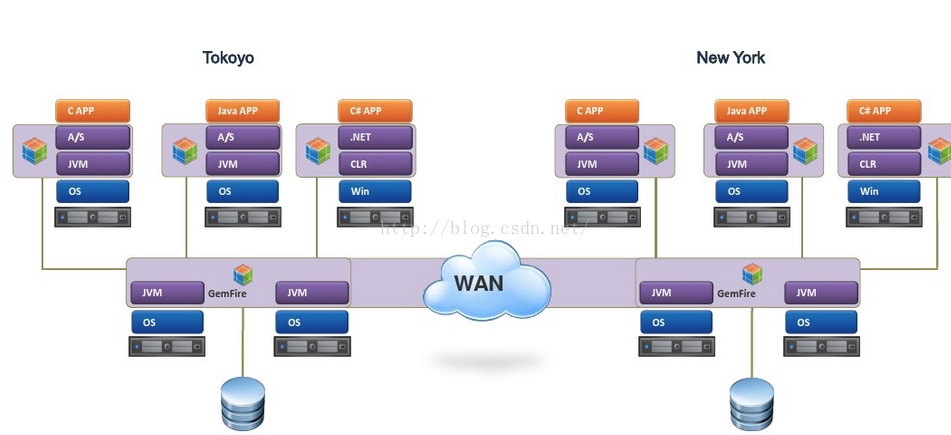
多地/多数据中心WAN部署
互联网世界比较流行,行话异地多活,全国甚至全球多地多数据中心部署。大型金融系统中也是不可或缺的,如全球多金融中心部署,NY, London, HK, TK等分布式多数据中心缓存。做的好的话,可以做到任意一个数据中心瘫痪,系统自动切换到其他数据中心运营,差的话就要人工干预了,不过至少不会完全瘫痪。
多数据中心的数据同步则是靠gateway来同步的,gateway receiver与gateway sender来发送接受数据中心的变化,如上图东京如果有缓存数据变化,新增或者变化,则会通过gateway发送给纽约的集群,通过gateway receiver来更新纽约的缓存,由于跨多地,网络,所以非实时同步更新,做到最终一致性。当然sender中必须提供了queue。

如下图定型的全球部署系统架构:
多数据中心支持多种拓扑结构,如Parallel则是每个数据中心均相互感知,当然其数据同步,通信也必然耗资源。
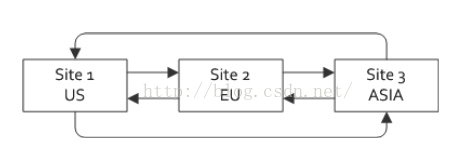
当然,还有其它多种网络拓扑,介于每个数据中心网络,带宽以及其它因素,最好与网络系统人员一起设计网络拓扑结构。
部署拓扑结构
新版的Gemfire 8.x支持多种部署拓扑结构:
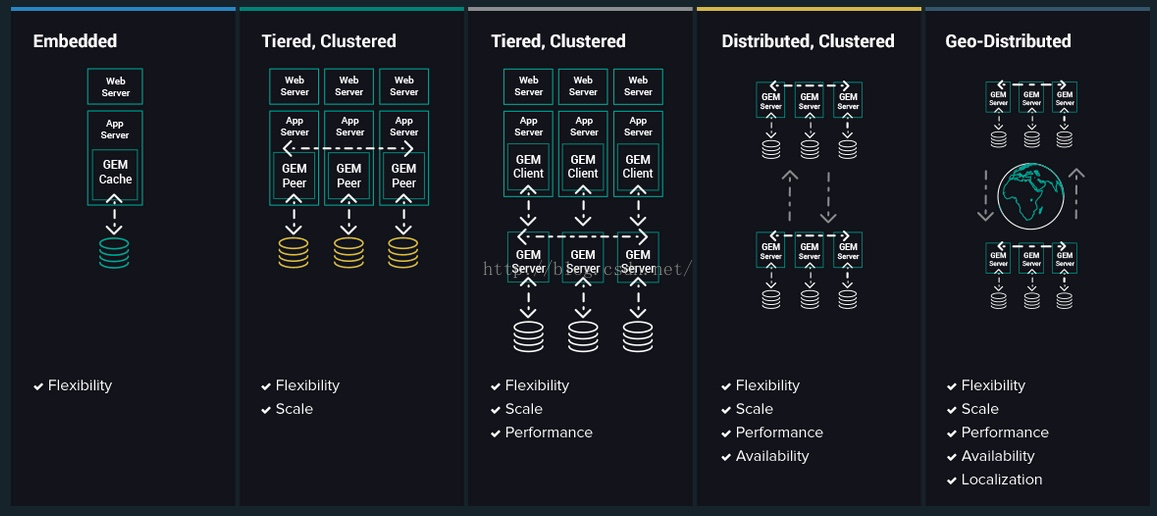
Pivotal细分和组合
5. Data Region
上文介绍过,Region是Gemfire中用来管理,存储数据的核心数据结构,本身实现了Map接口,类似于ConcurrentMap,同时支持分布式跨物理节点。
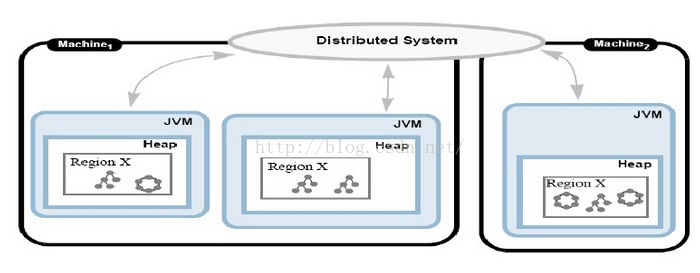
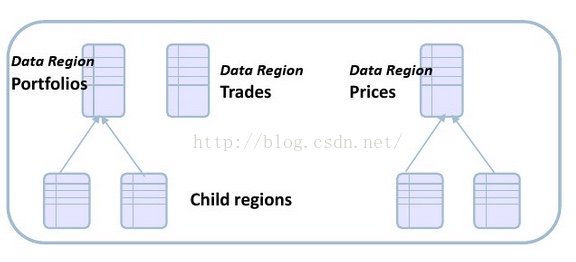
Gemfire的Data Region的读写操作支持同步读,同步写,异步写。
数据分布模型支持D-no-Ack, D-Ack, Global(锁)。
此外,Region还进行分布式支持以下高阶:
- 溢出至磁盘持久化(LRU)
- 持久化到磁盘
- 跨节点数据同步
- 外部数据源(数据库)延迟加载数据
- OQL
1Replicated Region
Replicated Region在每个Gemfire成员上都同步的保存一份完整的数据拷贝。Proxy:数据不存在本地缓存,Proxy成员提供了对Region的访问,需要其它成员配置Region的Non-Proxy拷贝用以存放数据。
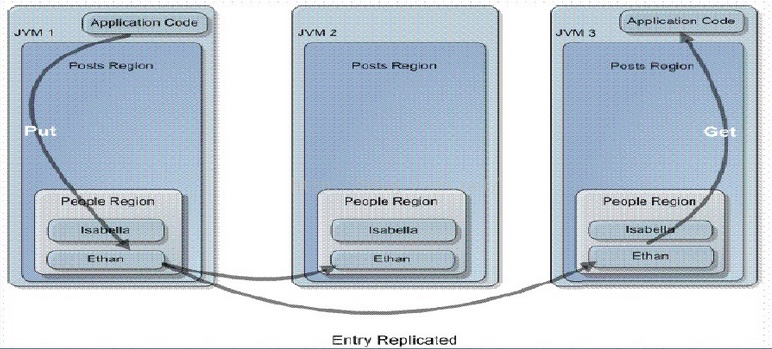
这是以空间换时间;这种Data Region适用于小型数据集并且读很频繁的操作;
2Partitioned Region
Partitioned Region顾名思义,将数据分散,每个成员近保存数据一部分,时间换空间;
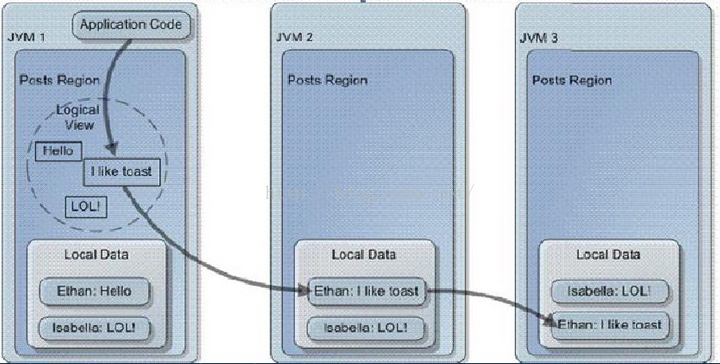
既然分区存储了,一定是适合大数据的数据集了,以及写/修改较多的数据集,并提供给了分布式并行查询,处理, MapReduce。
3OQL
Region提供类SQL, 基于SQL-92子集的OQL查询,注意可以跨分布式节点以及并行查询,这点是很多缓存不具备的,尽管简单。
SELECT, WHERE, DISTINCT, COUNT, IN, LIKE, 嵌套自查询,Map查询( p['key'] = '1.0' ),ORDER BY,。
注意,OQL仅支持COUNT, 不支持其它SUM, MIN, MAX。
另外,OQL支持Limit, 类似TOP:
SELECT * FROM /Region1 limit 100;
这里还提供高阶的Join, 大多数No-SQL都不支持,这里因为更类似二维表格,也提供了Join操作, 如下:
SELECT * FROM /Region1 r1, /Region2 r2 WHERE r1.status = r2.status;
可见,还是相对较熟悉,强大。当然这里的Join仅支持内连接,并不支持左右连接,毕竟没有那么强大。
既然可以提供OQL查询,支持Join, 那老司机又问是否可以做Index? 还真可以。
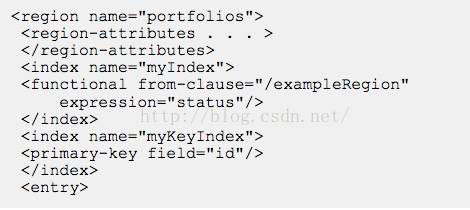
当然也支持代码动态创建了。当然,没有免费的午餐,与RDBMS类似,索引是把双刃剑,提供索引必然会降低修改,更新性能,提升查询性能。
用惯了Oracle了老鸟,这里居然也支持HINT,好吧。
当然,也不建议用过度负载的OQL,毕竟不是强大的RDBMS,况且考虑到兼容性,可移植性,以及没有那么强大的调试支持。
6. 事务支持
事务的操作首先作用在数据主拷贝节点,然后分布到其它成员。其中:
- 运行事务代码的成员被称作事务初始化器
- 管理事务和数据的成员被称为事务数据节点
Gemfire提供了分布式事务支持,难能可贵,在分布式世界里,提供分布式事务可比较重!所以尽量少用,开销太大,甚至可能全局死锁。
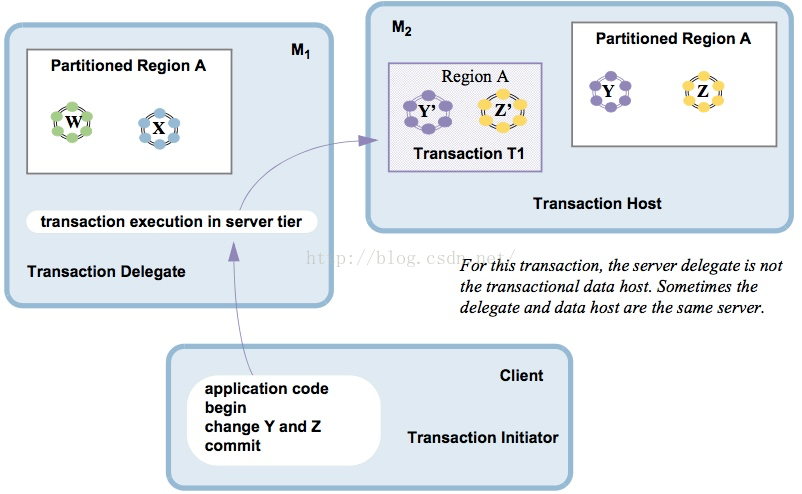
Gemfire同样提供了分布式锁支持,可以显示创建分布式锁, 在任何一个时间点,
工作原理:
在并发访问缓存的时候, 事务之间是隔离的。每一个事务都有自己的私有空间,包括已经读取的数据及其变更;当一个数据条目进入事务时,将在事务视图/空间生成一个数据状态的快照,此事务能保存数据的原始状态,快照的另一个作用则用于题解恢复写冲突。
当事务提交成功时,事务视图中的记录被合并到缓存上,如果提交失败或者回滚,则所有变更将放弃。提交事务时,Gemfire采用了两阶段提交协议, Two-Phase commit Protocol。
Gemfire甚至支持了JTA分布式事务;不建议使用分布式事务,因为会大大降低整体的性能,这与使用缓存的本意背驰。
7 分布式锁
Gemfire也提供了分布式锁支持,在任何一个时间节点,Gemfire系统保证只有一个线程可以用于该锁。另外线程将锁定整个服务,防止系统中其它线程锁定这个服务。可见其成本之高。
分布式锁分为隐式锁与显示锁。大多数情况下,系统自动利用隐式锁进行数据操作。锁服务从系统成员接受锁请求,并放入队列,按顺序授予锁。授予者负责运行锁服务。
当分布式锁服务创建时,分布式系统中某个成员通过选举成为分布式锁服务的授予者,授予者负责管理这个锁。当这个成员出现故障时,锁授予功能将被迁移到其它成员,且不丢失锁状态;这些细节处处可以看到分布式设计的目标及精髓。
8. Map Reduce
Gemfire与时俱进,提供了在分布式节点进行Map Reduce的操作函数。
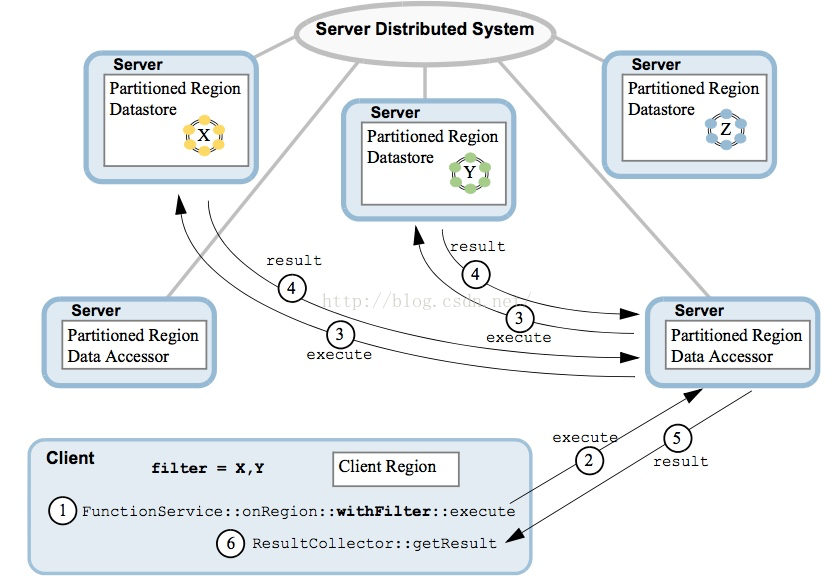
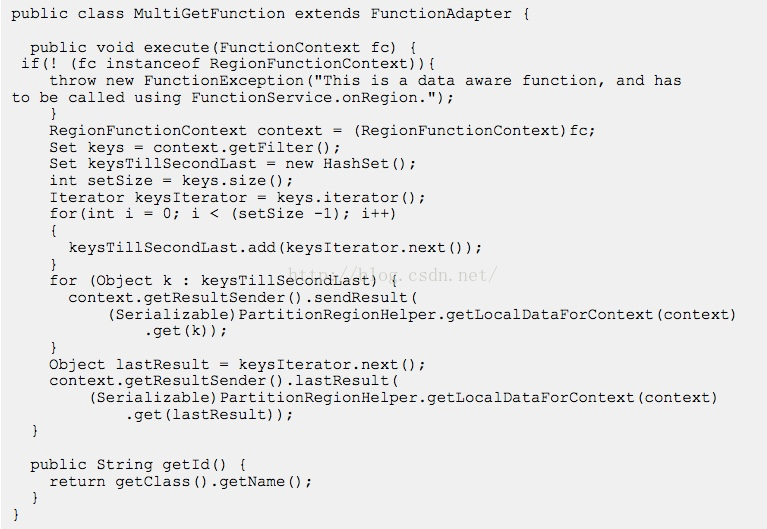
函数用Java自行编写,部署,运行。Gemfire支持两种形式的函数运行模式,方式1,提前注册并部署自定义函数到每个成员,运行时指定函数名字,显然不灵活,高耦合,每次改动函数都要全局部署;方式2,运行时动态ship函数,所谓ship function rather than data;更加现代的模式(从Gemfire 6.x开始支持)当然为了做到这种高效,必然要RPC + 序列化,所谓有利有弊,好处显然易见,首选推荐。
9. Management
分布式系统的Dev & Ops中的Ops也是重中之重,侧面反映一个分布式系统的成熟度。
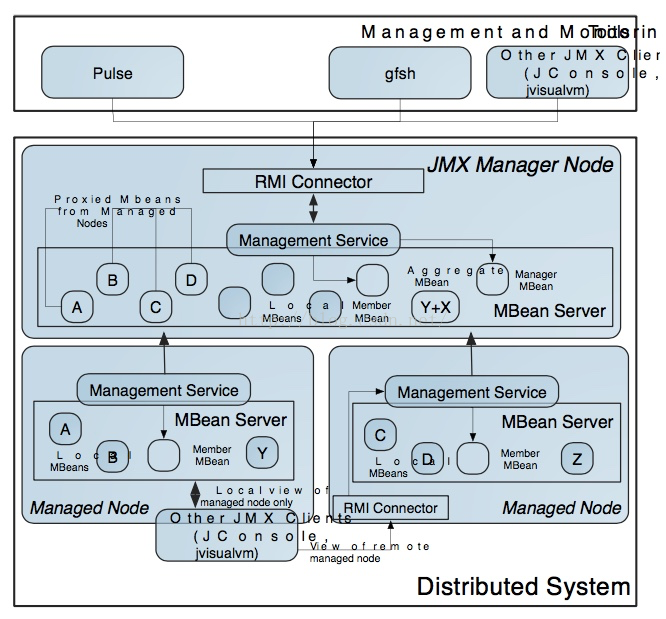
同时Gemfire支持JMX, Gemfire Pulse, Data Browser, VSD, JConsole/JVisualVM等。
Gemfire提供很多集成工具用来监控内存,磁盘,Region, 网络, 统计分析等等。
Cluster监控
Region View
Data Browser, 缓存当然需要一个即视的数据浏览器支持了。



相关推荐
Pivotal Gemfire 9.3 文档
gemfire开发文档gemfire开发文档gemfire开发文档gemfire开发文档gemfire开发文档gemfire开发文档gemfire开发文档gemfire开发文档gemfire开发文档gemfire开发文档gemfire开发文档gemfire开发文档gemfire开发文档...
Gemfire官网权威文档,内容涵盖全面,值得研究、参考。
GemFire是一个位于应用集群和后端数据源之间的高性能、分布式的操作数据(operational data)管理基础架构。它提供了低延迟、高吞吐量的数据共享和事件分发。GemFire充分利用网络中的内存和磁盘资源,形成一个实时的...
gemfire/geode从环境部署,搭建,到配置说明,全量的官方文档
1.安装 java se 1.8(jdk-8u111-windows-x64.exe) 2.命令行管理员运行 gfsh 3.按...成功后的REST文档 http://localhost:8080/gemfire-api/docs/index.html
解压缩文件并删除所有无关的项目(文档、示例代码等)(我们将目录Pivotal_GemFire_800_b48398_Linux_min ) 运行 tar 命令: tar -cf Pivotal_GemFire_800_b48398_Linux_min.tar Pivotal_GemFire_800_b48398_Linux...
Gemfire 是一个可扩展且健壮的内存数据网格。 Gemfire 进程分布在多个成员之间,并且可能容易受到一个或多个单个成员的网络和 JVM 问题的影响。 在解决此类问题时,应检查每个 Gemfire 流程中的工件。 该工具有助于...
Spring Data Gemfire - 缓存服务器模板 此模板演示了使用 Spring Data Gemfire 将缓存服务器创建为具有嵌入式缓存和单个区域的独立 Java 应用程序。... 如需帮助,请查看 Spring Data Gemfire 文档:
《Spring Data实战》从Spring Data背景知识、关系型数据库、NoSQL、快速应用开发、大数据、数据网格6个方面深度解析了数据访问技术,...文档数据库、图数据库、键/值存储、Hadoop以及GemFire数据结构等是最重要的内容...
Apache Geode是一个数据管理平台,可在广泛分布的云架构中实时,一致地访问数据密集型应用程序。 Apache Geode 和 Redis的比较: geode是java生态圈,目的是高性能高可用,除了缓存,更像数据库,可以sql查询,硬盘...
apace geode 是一个开源的分布式数据库,目前12306在用,国内资料比较少,翻译官网部分文档。
spring-boot-starter-data-gemfire spring-boot-starter-data-jpa spring-boot-starter-data-mongodb spring-boot-starter-data-rest spring-boot-starter-data-solr spring-boot-...
Gemfire iv. 29.4. Solr i. 29.4.1. 连接Solr ii. 29.4.2. Spring Data Solr仓库 v. 29.5. Elasticsearch i. 29.5.1. 连接Elasticsearch ii. 29.5.2. Spring Data Elasticseach仓库 ix. 30. 消息 i. 30.1. JMS i. ...