- 浏览: 2513496 次
- 性别:

- 来自: 深圳
-

ÊñáÁ´ÝÂàÜÁ±ª
- 全部博客 (676)
- linux运维 (157)
- php (65)
- mysql (78)
- nginx (27)
- apche (18)
- framework (6)
- windows (9)
- IDE工具 (23)
- struts2 (7)
- java (13)
- 移动互联网 (14)
- memcache redis (23)
- shell基础/命令/语法 (37)
- shell (50)
- puppet (4)
- C (11)
- python (9)
- 产品经理 (27)
- Sphinx (4)
- svn (12)
- 设计构建 (12)
- 项目管理 (44)
- SEO (1)
- 网站架构 (26)
- 审时度势 (42)
- 网络 (14)
- 激发事业[书&视频] (81)
- 其它 (12)
- 摄影 (8)
- android (21)
社区版块
- 我的资讯 ( 0)
- 我的论坛 ( 14)
- 我的问答 ( 0)
存档分类
- 2015-05 ( 1)
- 2015-04 ( 4)
- 2015-03 ( 7)
- 更多存档...
最新评论
-
zhongmin2012Ôºö
原文的书在哪里
数据库水平切分的实现原理解析---分库,分表,主从,集群,负载均衡器 -
renzhengzhiÔºö
‰ΩÝ•ΩÔºåËØ∑ÈóƉ∏™ÈóÆÈ¢òԺ剪émasterÂêåÊ≠•Êï∞ÊçÆÂà∞slaveÁöÑÊó∂ÂÄôÔºås ...
数据库水平切分的实现原理解析---分库,分表,主从,集群,负载均衡器 -
ibc789Ôºö
‰ΩÝ•ΩÔºåÁúã‰∫܉ΩÝÁöÑÊñáÁ´ÝÔºåÊàëÊÉ≥ËØ∑Êïô‰∏™ÈóÆÈ¢òÔºå ÊàëÂú®Áî® redisÁöÑÊó∂ÂÄô ...
redis 的两种持久化方式及原理 -
iijjllÔºö
ÂÜôÂæóÈùûÂ∏∏Â•Ω¬Ý
数据库水平切分的实现原理解析---分库,分表,主从,集群,负载均衡器 -
iijjllÔºö
写得非常好
数据库水平切分的实现原理解析---分库,分表,主从,集群,负载均衡器
大型网站架构(转帖)--详细介绍阶段性需求和应对方法
- 博客分类:
- 网站架构
‰πãÂâç‰πüÊúâ‰∏ĉ∫õ‰ªãÁªç§ßÂûãÁΩëÁ´ôÊû∂ÊûÑʺîÂèòÁöÑÊñáÁ´ÝÔºå‰æã¶Ç
LiveJournalÁöÑ„ÄÅ
ebayÁöÑÔºåÈÉΩÊòØÈùûÂ∏∏ÂĺÂæóÂèÇËÄÉÁöÑÔºå‰∏çËøáÊÑüËß≪ñ‰ª¨ËÆ≤ÁöÑÊõ¥Â§öÁöÑÊòØÊØèʨ°ÊºîÂèòÁöÑÁªìÊûúÔºåËÄåÊ≤°ÊúâÂæàËضÁªÜÁöÑËÆ≤‰∏∫‰ªÄ‰πàÈúÄ˶ÅÂÅöËøôÊÝ∑ÁöÑʺîÂèòÔºåÂÜçÂä݉∏äËøëÊù•ÊÑüËßâÊúâ‰∏çÂ∞ëÂêåÂ≠¶ÈÉΩÂæàÈöæÊòéÁôΩ‰∏∫‰ªÄ‰πà‰∏ĉ∏™ÁΩëÁ´ôÈúÄ˶ÅÈÇ£‰πà§çÊùÇÁöÑÊäÄÊúØÔºå‰∫éÊòØÊúâ‰∫ÜÂÜôËøôÁØáÊñáÁ´ÝÁöÑÊÉ≥Ê≥ïÔºåÂú®ËøôÁØáÊñáÁ´Ý‰∏≠
将阐述一个普通的网站发展成大型网站过程中的一种较为典型的架构演变历程和所需掌握的知识体系,希望能给想从事互联网行业的同学一点初步的概念,
:)ÔºåÊñá‰∏≠Áöщ∏çÂØπ‰πã§щπüËØ∑ÂêщΩç§öÁªôÁÇπª∫ËÆÆÔºåËÆ©Êú¨ÊñáÁúüÊ≠£Ëµ∑Âà∞ÊäõÁÝñºïÁéâÁöÑÊïàÊûú„ÄÇ
<!--[if !supportLineBreakNewLine]-->
<!--[endif]-->
架构演变第一步:物理分离
webserver和数据库
ÊúĺÄÂßãÔºåÁ∫éÊüê‰∫õÊÉ≥Ê≥ïÔºå‰∫éÊòØÂú®‰∫íËÅîÁΩë‰∏äÊê≠ª∫‰∫܉∏ĉ∏™ÁΩëÁ´ôÔºåËøô‰∏™Êó∂ÂÄôÁîöËá≥ÊúâÂèØËÉΩ‰∏ªÊú∫ÈÉΩÊòØÁßüÂÄüÁöÑÔºå‰ΩÜÁ∫éËøôÁØáÊñáÁ´ÝÊà뉪¨Âè™ÂÖ≥Ê≥®Êû∂ÊûÑÁöÑʺîÂèòÂéÜÁ®ãÔºåÂõÝÊ≠§Â∞±ÂÅáËÆæËøô‰∏™Êó∂ÂÄô
Â∑≤ÁªèÊòØÊâòÁÆ°‰∫܉∏ÄÂè∞‰∏ªÊú∫ÔºåÂπ∂‰∏îÊúâ‰∏ÄÂÆöÁöÑÂ∏¶ÂÆΩ‰∫ÜÔºåËøô‰∏™Êó∂ÂÄôÁ∫éÁΩëÁ´ôÂÖ∑§á‰∫܉∏ÄÂÆöÁöÑÁâπËâ≤ÔºåÂê∏ºï‰∫ÜÈÉ®Âà܉∫∫ËÆøÈóÆÔºåÈÄêÊ∏ê‰ΩÝÂèëÁé∞Á≥ªÁªü
的压力越来越高,响应速度越来越慢,而这个时候比较明显的是数据
库和应用互相影响,应用出问题
了,
数据库也很容易出现问题,而数据库出问题的时候,应用也容易出问题,于是进入了第一步演变阶段:将应用和数据库从物理上分离,变成了两台机器,这个时候技
Êú؉∏äÊ≤°Êú≪ĉπàÊñ∞ÁöÑ˶ÅʱÇÔºå‰Ω܉ΩÝÂèëÁé∞Á°ÆÂÆû˵∑Âà∞ÊïàÊûú‰∫ÜÔºåÁ≥ªÁªüÂèàÊާçÂà∞‰ª•ÂâçÁöÑÂìçÂ∫îÈÄüÂ∫¶‰∫ÜÔºåÂπ∂‰∏îÊîØÊíë‰Ωè‰∫ÜÊõ¥È´òÁöÑʵÅÈáèÔºåÂπ∂‰∏î‰∏牺öÂõ݉∏∫Êï∞ÊçÆÂ∫ìÂíåÂ∫îÁî®ÂΩ¢Êàê‰∫íÁõ∏ÁöÑÂΩ±Âìç„ÄÇ
看看这一步完成后系统的图示:
<!--[if !vml]-->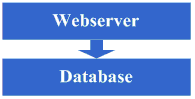
<!--[endif]-->
这一步涉及到了这些知识体系:
这一步架构演变对技术上的知识体系基本没有要求。
<!--[if !supportLineBreakNewLine]-->
<!--[endif]-->
Êû∂ÊûÑʺîÂèòÁ¨¨‰∫åÊ≠•Ôºö¢ûÂäÝÈ°µÈù¢ÁºìÂ≠ò
•ΩÊô؉∏çÈïøÔºåÈöèÁùÄËÆøÈóÆÁöщ∫∫Ë∂äÊù•Ë∂ä§öÔºå‰ΩÝÂèëÁé∞ÂìçÂ∫îÈÄüÂ∫¶ÂèàºÄÂßãÂèòÊÖ¢‰∫ÜÔºåÊü•ÊâæÂéüÂõÝÔºåÂèëÁé∞ÊòØËÆøÈóÆÊï∞ÊçÆÂ∫ìÁöÑÊìç‰Ωú§™Â§öÔºåÂغËá¥Êï∞ÊçÆËøûÊé•Á´û‰∫âÊøÄÁÉàÔºåÊâĉª•ÂìçÂ∫îÂèòÊÖ¢Ôºå‰ΩÜÊï∞ÊçÆÂ∫ìËøû
Êé•Âèà‰∏çËÉΩºÄ§™Â§öÔºåÂê¶ÂàôÊï∞ÊçÆÂ∫ìÊú∫Âô®ÂéãÂäõ‰ºöÂæàÈ´òÔºåÂõÝÊ≠§ËÄÉËôëÈááÁî®ÁºìÂ≠òÊú∫Âà∂Êù•ÂáèÂ∞ëÊï∞ÊçÆÂ∫ìËøûÊé•ËµÑÊ∫êÁöÑÁ´û‰∫âÂíåÂØπÊï∞ÊçÆÂ∫ìËتÁöÑÂéãÂäõÔºåËøô‰∏™Êó∂ÂÄôȶñÂÖà‰πüËÆ∏‰ºöÈÄâÊã©ÈááÁî®
squid Á≠âÁ±ª‰ººÁöÑÊú∫Âà∂Êù•Â∞ÜÁ≥ªÁªü‰∏≠Áõ∏ÂØπÈùôÊÄÅÁöÑÈ°µÈù¢Ôºà‰æã¶lj∏ĉ∏§Â§©Êâ牺öÊúâÊõ¥Êñ∞ÁöÑÈ°µÈù¢ÔºâËøõË°åÁºìÂ≠òÔºàÂΩìÁÑ∂Ôºå‰πüÂè؉ª•ÈááÁî®Â∞ÜÈ°µÈù¢ÈùôÊÄÅÂåñÁöÑÊñπÊ°àÔºâÔºåËøôÊÝ∑Á®ãÂ∫è‰∏äÂè؉ª•‰∏çÂÅö‰øÆÊîπÔºåÂ∞±ËÉΩ§ü
很好的减少对
webserver的压力以及减少数据库连接资源的竞争,
OK,于是开始采用
squid来做相对静态的页面的缓存。
看看这一步完成后系统的图示:
<!--[if !vml]-->
<!--[endif]-->
这一步涉及到了这些知识体系:
前端页面缓存技术,例如
squid,如想用好的话还得深入掌握下
squid的实现方式以及缓存的失效算法等。
Êû∂ÊûÑʺîÂèòÁ¨¨‰∏âÊ≠•Ôºö¢ûÂäÝÈ°µÈù¢ÁâáÊƵÁºìÂ≠ò
¢ûÂä݉∫Ü
squid做缓存后,整体系统的速度确实是提升了,
webserverÁöÑÂéãÂäõ‰πüºÄÂßã‰∏ãÈôç‰∫ÜÔºå‰ΩÜÈöèÁùÄËÆøÈóÆÈáèÁöÑ¢ûÂäÝÔºåÂèëÁé∞Á≥ªÁªüÂèàºÄÂßãÂèòÁöÑÊúâ‰∫õÊÖ¢‰∫ÜÔºåÂú®Â∞ù
到了
squid‰πãÁ±ªÁöÑÂä®ÊÄÅÁºìÂ≠òÂ∏¶Êù•ÁöÑ•Ω§ÑÂêéÔºåºÄÂßãÊÉ≥ËÉΩ‰∏çËÉΩËÆ©Áé∞Âú®ÈÇ£‰∫õÂä®ÊÄÅÈ°µÈù¢ÈáåÁõ∏ÂØπÈùôÊÄÅÁöÑÈÉ®Âà܉πüÁºìÂ≠ò˵∑Êù•Âë¢ÔºåÂõÝÊ≠§ËÄÉËôëÈááÁî®Á±ª‰ºº
ESI之类的页面片段缓存策略,
OK,于是开始采用
ESI来做动态页面中相对静态的片段部分的缓存。
看看这一步完成后系统的图示:
<!--[if !vml]-->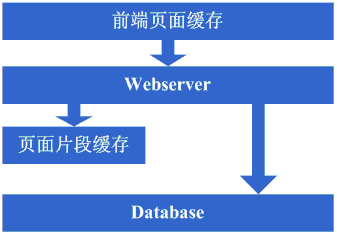
<!--[endif]-->
这一步涉及到了这些知识体系:
页面片段缓存技术,例如
ESIÁ≠âÔºåÊÉ≥Áî®Â•ΩÁöÑËØùÂêåÊÝ∑ÈúÄ˶ÅÊéåÊè°
ESI的实现方式等;
架构演变第四步:数据缓存
在采用
ESI‰πãÁ±ªÁöÑÊäÄÊúØÂÜçʨ°ÊèêÈ´ò‰∫ÜÁ≥ªÁªüÁöÑÁºìÂ≠òÊïàÊûúÂêéÔºåÁ≥ªÁªüÁöÑÂéãÂäõÁ°ÆÂÆûËøõ‰∏ÄÊ≠•Èôç‰Ωé‰∫ÜÔºå‰ΩÜÂêåÊÝ∑ÔºåÈöèÁùÄËÆøÈóÆÈáèÁöÑ¢ûÂäÝÔºåÁ≥ªÁªüËøòÊòغÄÂßãÂèòÊÖ¢ÔºåÁªèËøáÊü•ÊâæÔºåÂèØËÉΩ‰ºöÂèëÁé∞Á≥ª
统中存在一些重复获取数据信息的地方,像获取用户
信息等,这个时候开始考虑是不是可以将这些数据信息也缓存起来呢,于是将这些数据缓存到本地内存,改变完毕后,完全符合预期,系统的响应速度又恢复了,数据库的压力也再度降低了不少。
看看这一步完成后系统的图示:
<!--[if !vml]-->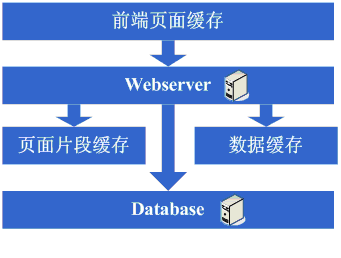
<!--[endif]-->
这一步涉及到了这些知识体系:
缓存技术,包括像
Map数据结构、缓存算法、所选用的框架
本身的实现机制等。
架构演变第五步:
¢ûÂäÝ
webserver
•ΩÊô؉∏çÈïøÔºåÂèëÁé∞ÈöèÁùÄÁ≥ªÁªüËÆøÈóÆÈáèÁöÑÂÜçÂ∫¶Â¢ûÂäÝÔºå
webserverÊú∫Âô®ÁöÑÂéãÂäõÂú®È´òÂ≥∞Êúü‰ºö‰∏äÂçáÂà∞ÊØîËæÉÈ´òÔºåËøô‰∏™Êó∂ÂÄôºÄÂßãËÄÉËôë¢ûÂä݉∏ÄÂè∞
webserver,这也是为了同时解决
可用性的问题,避免单台的
webserver downÊú∫ÁöÑËØùÂ∞±Ê≤°Ê≥ï‰ΩøÁ∫ÜÔºåÂú®ÂÅö‰∫ÜËøô‰∫õËÄÉËôëÂêéÔºåÂÜ≥ÂÆö¢ûÂä݉∏ÄÂè∞
webserverÔºå¢ûÂä݉∏ÄÂè∞
webserver时,会碰到一些问题,典型的有:
1、如何让访问分配到这两台机器上,这个时候通常会考虑的方案是
Apache自带的负载均衡方案,或
LVS这类的软件负载均衡方案;
2、如何保持状态信息的同步,例如用户
session
等,这个时候会考虑的方案有写入数据库、写入存储、
cookie或同步
session信息等机制等;
3、如何保持数据缓存信息的同步,例如之前缓存的用户数据等,这个时候通常会考虑的机制有缓存同步或分布式缓存;
4„ÄŶljΩïËÆ©‰∏䉺ÝÊñቪ∂
这些类似的功能
继续正常,这个时候通常会考虑的机制是使用共享文件系统或存储等;
在解决了这些问题后,终于是把
webserver¢ûÂä݉∏∫‰∫܉∏§Âè∞ÔºåÁ≥ªÁªüÁªà‰∫éÊòØÂèàÊާçÂà∞‰∫܉ª•ÂæÄÁöÑÈÄüÂ∫¶„ÄÇ
看看这一步完成后系统的图示:
<!--[if !vml]-->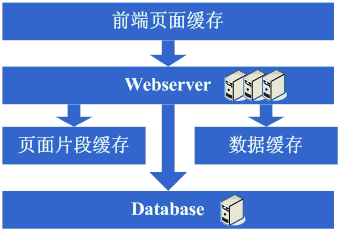
<!--[endif]-->
这一步涉及到了这些知识体系:
负载均衡技术(包括但不限于硬件负载均衡、软件负载均衡、负载算法、
linux
转发协议、所选用的技术的实现细节等)、主备技术(包括但不限于
ARP欺骗、
linux heart-beat等)、状态信息或缓存同步技术(包括但不限于
Cookie技术、
UDP协议、状态信息广播、所选用的缓存同步技术的实现细节等)、共享文件技术(包括但不限于
NFS等)、存储技术(包括但不限于存储设备等)。
架构演变第六步:分库
享受了一段时间的系统访问量高速增长的幸福后,发现系统又开始变慢了,这次又是什么状况呢,经过查找,发现数据库写入、更新的这些操作的部分数据库连接的
资
Ê∫êÁ´û‰∫âÈùûÂ∏∏ÊøÄÁÉàÔºåÂغË᥉∫ÜÁ≥ªÁªüÂèòÊÖ¢ÔºåËøô‰∏ãÊÄé‰πàÂäûÂë¢ÔºåÊ≠§Êó∂ÂèØÈÄâÁöÑÊñπÊ°àÊúâÊï∞ÊçÆÂ∫ìÈõÜÁæ§ÂíåÂàÜÂ∫ìÁ≠ñÁï•ÔºåÈõÜÁæ§ÊñπÈù¢ÂÉèÊúâ‰∫õÊï∞ÊçÆÂ∫ìÊîØÊåÅÁöÑÂπ∂‰∏çÊòØÂæà•ΩÔºåÂõÝÊ≠§ÂàÜÂ∫쉺öÊàê‰∏∫ÊØîËæÉÊôÆÈÅç
ÁöÑÁ≠ñÁï•ÔºåÂàÜÂ∫ì‰πüÂ∞±ÊÑèÂë≥ÁùÄ˶ÅÂØπÂéüÊúâÁ®ãÂ∫èËøõË°å‰øÆÊîπÔºå‰∏ÄÈÄö‰øÆÊîπÂÆûÁé∞ÂàÜÂ∫ìÂêéÔºå‰∏çÈîôÔºåÁõÆÊÝáËææÂà∞‰∫ÜÔºåÁ≥ªÁªüÊާçÁîöËá≥ÈÄüÂ∫¶ÊØ•ÂâçËøòÂø´‰∫Ü„ÄÇ
看看这一步完成后系统的图示:
<!--[if !vml]-->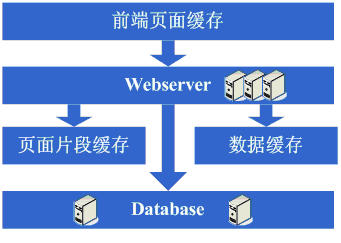
<!--[endif]-->
这一步涉及到了这些知识体系:
这一步更多的是需要从业务上做合理的划分,以实现分库,具体技术细节上没有其他的要求;
但同时随着数据量的增大和分库的进行,在数据库的设计
„ÄÅË∞ɉºò‰ª•ÂèäÁª¥Ê䧉∏äÈúÄ˶ÅÂÅöÁöÑÊõ¥Â•ΩÔºåÂõÝÊ≠§ÂØπËøô‰∫õÊñπÈù¢ÁöÑÊäÄÊúØËøòÊòØÊèêÂá∫‰∫ÜÂæàÈ´òÁöÑ˶ÅʱÇÁöÑ„ÄÇ
架构演变第七步:分表、
DAL和分布式缓存
随着系统的不断运行,数据量开始大幅度增长,这个时候发现分库后查询仍然会有些慢,于是按照分库的思想开始做分表的工作,当然,这不可避免的会需要对程序
ËøõË°å‰∏ĉ∫õ‰øÆÊîπÔºå‰πüËÆ∏Âú®Ëøô‰∏™Êó∂ÂÄôÂ∞±‰ºöÂèëÁé∞Â∫îÁî®Ëá™Â∑±Ë¶ÅÂÖ≥ÂøÉÂàÜÂ∫ìÂàÜË°®ÁöÑËßÑÂàôÁ≠âÔºåËøòÊòØÊúâ‰∫õ§çÊùÇÁöÑÔºå‰∫éÊòØËêåÁîüËÉΩÂê¶Â¢ûÂä݉∏ĉ∏™ÈÄöÁî®ÁöÑÊ°ÜÊû∂Êù•ÂÆûÁé∞ÂàÜÂ∫ìÂàÜË°®ÁöÑÊï∞ÊçÆËÆøÈóÆÔºåËøô‰∏™Âú®
ebay的架构中对应的就是
DAL,这个演变的过程相对而言需要花费较长的时间,当然,也有可能这个通用的框架会等到分表做完后才开始做,同时,在这个阶段可
ËÉΩ‰ºöÂèëÁé∞‰πãÂâçÁöÑÁºìÂ≠òÂêåÊ≠•ÊñπÊ°àÂá∫Áé∞ÈóÆÈ¢òÔºåÂõ݉∏∫Êï∞ÊçÆÈá觙§ßÔºåÂغËá¥Áé∞Âú®‰∏秙ÂèØËÉΩÂ∞ÜÁºìÂ≠òÂ≠òÂú®Êú¨Âú∞ÔºåÁÑ∂ÂêéÂêåÊ≠•ÁöÑÊñπºèÔºåÈúÄ˶ÅÈááÁî®ÂàÜÂ∏ɺèÁºìÂ≠òÊñπÊ°à‰∫ÜÔºå‰∫éÊòØÔºåÂèàÊò؉∏ÄÈÄöËÄÉÂØüÂíåÊäòÁ£®ÔºåÁªà‰∫éÊòØÂ∞ܧßÈáèÁöÑÊï∞ÊçÆÁºìÂ≠òËΩ¨ÁߪÂà∞ÂàÜÂ∏ɺèÁºìÂ≠ò‰∏ä‰∫Ü„ÄÇ
看看这一步完成后系统的图示:
<!--[if !vml]-->
<!--[endif]-->
这一步涉及到了这些知识体系:
ÂàÜË°®Êõ¥Â§öÁöÑÂêåÊÝ∑Êò؉∏öÂä°‰∏äÁöÑÂàíÂàÜÔºåÊäÄÊú؉∏äÊ∂âÂèäÂà∞ÁöщºöÊúâÂä®ÊÄÅ
hash算法、
consistent hash算法等;
DAL涉及到比较多的复杂技术,例如数据库连接的管理(超时、异常)、数据库操作的控制(超时、异常)、分库分表规则的封装等;
Êû∂ÊûÑʺîÂèòÁ¨¨ÂÖ´Ê≠•Ôºö¢ûÂäÝÊõ¥Â§öÁöÑ
webserver
在做完分库分表这些工作后,数据库上的压力已经降到比较低了,又开始过着每天看着访问量暴增的幸福生活了,突然有一天,发现系统的访问又开始有变慢的趋势
了,这个时候首先查看数据库,压力一切正常,之后查看
webserver,发现
apache
阻塞了很多的请求,而应用服务器对每个请求也是比较快的,看来
ÊòØËØ∑ʱÇÊï∞§™È´òÂغËá¥ÈúÄ˶ÅÊéíÈòüÁ≠âÂæÖÔºåÂìçÂ∫îÈÄüÂ∫¶ÂèòÊÖ¢ÔºåËøôËøò•ΩÂäûÔºå‰∏ÄËà¨Êù•ËØ¥ÔºåËøô‰∏™Êó∂ÂÄô‰πü‰ºöÊúâ‰∫õÈí±‰∫ÜÔºå‰∫éÊòØÊ∑ªÂä݉∏ĉ∫õ
webserverÊúçÂä°Âô®ÔºåÂú®Ëøô‰∏™Ê∑ªÂäÝ
webserverÊúçÂä°Âô®ÁöÑËøáÁ®ãÔºåÊúâÂèØËÉΩ‰ºöÂá∫Áé∞ÂáÝÁßçÊåëÊàòÔºö
1„ÄÅ
Apache的软负载或
LVSËΩØË¥üËΩΩÁ≠âÊóÝÊ≥ïÊâøÊãÖÂ∑®Â§ßÁöÑ
web访问量(请求连接数、网络流量等)的调度了,这个时候如果经费允许的话,会采取的方案是购
买硬件负载,例如
F5„ÄÅ
Netsclar„ÄÅ
Athelon之类的,如经费不允许的话,会采取的方案是将应用从逻辑上做一定的分类,然后分散到不同的软负载集群中;
2„ÄÅÂéüÊúâÁöщ∏ĉ∫õÁä∂ÊÄʼnø°ÊÅØÂêåÊ≠•„ÄÅÊñቪ∂ÂÖ±‰∫´Á≠âÊñπÊ°àÂèØËÉΩ‰ºöÂá∫Áé∞Áì∂È¢àÔºåÈúÄ˶ÅËøõË°åÊîπËøõÔºå‰πüËÆ∏Ëøô‰∏™Êó∂ÂÄô‰ºöÊÝπÊçÆÊÉÖÂܵÁºñÂÜôÁ¨¶ÂêàÁΩëÁ´ô‰∏öÂä°ÈúÄʱÇÁöÑÂàÜÂ∏ɺèÊñቪ∂Á≥ªÁªüÁ≠âÔºõ
Âú®ÂÅöÂÆåËøô‰∫õÂ∑•‰ΩúÂêéÔºåºÄÂßãËøõÂÖ•‰∏ĉ∏™Áú㉺ºÂÆåÁæéÁöÑÊóÝÈôꉺ∏Áº©ÁöÑÊó∂‰ª£ÔºåÂΩìÁΩëÁ´ôʵÅÈáè¢ûÂäÝÊó∂ÔºåÂ∫îÂØπÁöÑËߣÂÜ≥ÊñπÊ°àÂ∞±Êò؉∏çÊñ≠ÁöÑÊ∑ªÂäÝ
webserver„ÄÇ
看看这一步完成后系统的图示:
<!--[if !vml]-->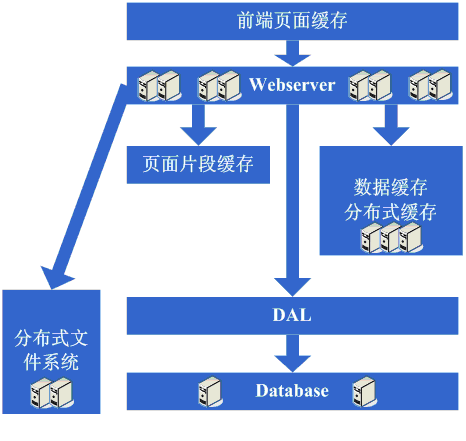
<!--[endif]-->
这一步涉及到了这些知识体系:
Âà∞‰∫ÜËøô‰∏ÄÊ≠•ÔºåÈöèÁùÄÊú∫Âô®Êï∞Áöщ∏çÊñ≠¢ûÈïø„ÄÅÊï∞ÊçÆÈáèÁöщ∏çÊñ≠¢ûÈïøÂíåÂØπÁ≥ªÁªüÂèØÁî®ÊÄßÁöÑ˶ÅʱÇË∂äÊù•Ë∂äÈ´òÔºåËøô‰∏™Êó∂ÂÄô˶ÅʱÇÂØπÊâÄÈááÁî®ÁöÑÊäÄÊúØÈÉΩ˶ÅÊúâÊõ¥‰∏∫Ê∑±ÂÖ•ÁöÑÁêÜËߣԺåÂπ∂ÈúÄ˶ÅÊÝπÊçÆÁΩëÁ´ôÁöÑÈúÄʱÇÊù•ÂÅöÊõ¥ÂäÝÂÆöÂà∂ÊÄßË¥®Áöщ∫ßÂìÅ„ÄÇ
架构演变第九步:数据读写分离和廉价存储方案
Á™ÅÁÑ∂Êúâ‰∏ħ©ÔºåÂèëÁé∞Ëøô‰∏™ÂÆåÁæéÁöÑÊó∂‰ª£‰πü˶ÅÁªìÊùü‰∫ÜÔºåÊï∞ÊçÆÂ∫ìÁöÑÂô©Ê¢¶Âèà‰∏Äʨ°Âá∫Áé∞Âú®ÁúºÂâç‰∫ÜÔºåÁ∫éÊ∑ªÂäÝÁöÑ
webserver太多了,导致数据库连接的资源还是不够用,而这个时候又已经分库分表了,开始分析数据库的压力状况,可能会发现数据库的读写比很高,这个时候通常会想到数据读写分离的方案,当然,这个方案要实现并不
ÂÆπÊòìÔºåÂè¶Â§ñÔºåÂèØËÉΩ‰ºöÂèëÁé∞‰∏ĉ∫õÊï∞ÊçÆÂ≠òÂÇ®Âú®Êï∞ÊçÆÂ∫ì‰∏äÊúâ‰∫õʵ™Ë¥πÔºåÊàñËÄÖËØ¥Ëøá‰∫éÂçÝÁî®Êï∞ÊçÆÂ∫ì˵ÑÊ∫êÔºåÂõÝÊ≠§Âú®Ëøô‰∏™Èò∂ÊƵÂèØËÉΩ‰ºöÂΩ¢ÊàêÁöÑÊû∂ÊûÑʺîÂèòÊòØÂÆûÁé∞Êï∞ÊçÆËتÂÜôÂàÜÁ¶ªÔºåÂêåÊó∂ÁºñÂÜô‰∏ĉ∫õÊõ¥‰∏∫ª≪∑ÁöÑÂ≠òÂÇ®ÊñπÊ°àÔºå‰æã¶Ç
BigTableËøôÁßç„ÄÇ
看看这一步完成后系统的图示:
<!--[if !vml]-->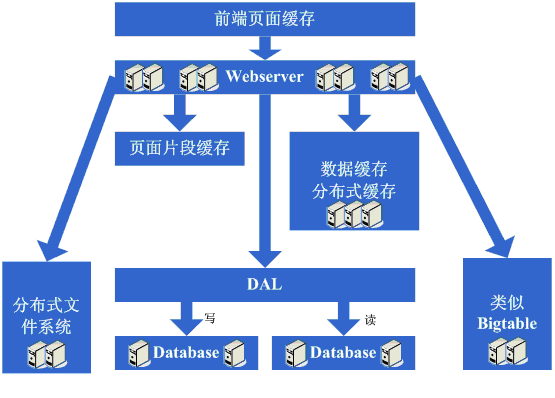
<!--[endif]-->
这一步涉及到了这些知识体系:
数据读写分离要求对数据库的复制、
standby等策略有深入的掌握和理解,同时会要求具备自行实现的技术;
廉价存储方案要求对
OS的文件存储有深入的掌握和理解,同时要求对采用的语言在文件这块的实现有深入的掌握。
架构演变第十步:进入大型分布式应用时代和廉价服务器群梦想时代
ÁªèËøá‰∏äÈù¢Ëøô‰∏™Êº´ÈïøËÄåÁóõËã¶ÁöÑËøáÁ®ãÔºåÁªà‰∫éÊòØÂÜçÂ∫¶ËøéÊù•‰∫ÜÂÆåÁæéÁöÑÊó∂‰ª£Ôºå‰∏çÊñ≠ÁöÑ¢ûÂäÝ
webserver就可以支撑越来越高的访问量了,对于大型网站而言,人气的重要毋
Â∫∏ÁΩÆÁñëÔºåÈöèÁùĉ∫∫Ê∞îÁöÑË∂äÊù•Ë∂äÈ´òÔºåÂêÑÁßçÂêÑÊÝ∑ÁöÑÂäüËÉΩÈúÄʱljπüºÄÂßãÁàÜÂèëÊÄßÁöÑ¢ûÈïøÔºåËøô‰∏™Êó∂ÂÄôÁ™ÅÁÑ∂ÂèëÁé∞ÔºåÂéüÊù•ÈÉ®ÁΩ≤Âú®
webserver上的那个
web应用已经非常庞大
了,当多个团队都开始对其进行改动时,可真是相当的不方便,复用性也相当糟糕,基本是每个团队都做了或多或少重复的事情,而且部署和维护也是相当的麻烦,
Âõ݉∏∫Â∫û§ßÁöÑÂ∫îÁî®ÂåÖÂú®
N台机器上复制、启动都需要耗费不少的时间,出问题的时候也不是很好查,另外一个更糟糕的状况是很有可能会出现某个应用上的
bug就导
Ë᥉∫ÜÂÖ®Á´ôÈÉΩ‰∏çÂèØÁî®ÔºåËøòÊúâÂÖ∂‰ªñÁöÑÂÉèË∞ɉºò‰∏ç•ΩÊìç‰ΩúÔºàÂõ݉∏∫Êú∫Âô®‰∏äÈÉ®ÁΩ≤ÁöÑÂ∫îÁªÄ‰πàÈÉΩ˶ÅÂÅöÔºåÊÝπÊú¨Â∞±ÊóÝÊ≥ïËøõË°åÈíàÂØπÊÄßÁöÑË∞ɉºòÔºâÁ≠âÂõÝÁ¥ÝÔºåÊÝπÊçÆËøôÊÝ∑ÁöÑÂàÜÊûêÔºåºÄÂßãÁóõ‰∏ãÂÜ≥ÂøÉÔºåÂ∞Ü
Á≥ªÁªüÊÝπÊçÆËÅåË¥£ËøõË°åÊãÜÂàÜÔºå‰∫éÊò؉∏ĉ∏™Â§ßÂûãÁöÑÂàÜÂ∏ɺèÂ∫îÁî®Â∞±ËØûÁîü‰∫ÜÔºåÈÄöÂ∏∏ÔºåËøô‰∏™Ê≠•È™§ÈúÄ˶ÅËÄóË¥πÁõ∏ÂΩìÈïøÁöÑÊó∂Èó¥ÔºåÂõ݉∏∫‰ºöÁ¢∞Âà∞Âæà§öÁöÑÊåëÊàòÔºö
1、拆成分布式后需要提供一个高性能、稳定的通信框架,并且需要支持多种不同的通信和远程调用方式;
2、将一个庞大的应用拆分需要耗费很长的时间,需要进行业务的整理和系统依赖关系的控制等;
3、如何运维(依赖管理、运行状况管理、错误
追踪、调优、监控和报警等)好这个庞大的分布式应用。
ÁªèËøáËøô‰∏ÄÊ≠•ÔºåÂ∑Ɖ∏ç§öÁ≥ªÁªüÁöÑÊû∂ÊûÑËøõÂÖ•Áõ∏ÂØπÁ®≥ÂÆöÁöÑÈò∂ÊƵԺåÂêåÊó∂‰πüËÉΩºÄÂßãÈááÁî®Â§ßÈáèÁöѪ≪∑Êú∫Âô®Êù•ÊîØÊíëÁùÄÂ∑®Â§ßÁöÑËÆøÈóÆÈáèÂíåÊï∞ÊçÆÈáèÔºåÁªìÂêàËøô•óÊû∂Êûщª•ÂèäËøô‰πà§öʨ°ÊºîÂèòËøáÁ®ãÂê∏ÂèñÁöÑÁªèÈ™åÊù•ÈááÁî®ÂÖ∂‰ªñÂêÑÁßçÂêÑÊÝ∑ÁöÑÊñπÊ≥ïÊù•ÊîØÊíëÁùÄË∂äÊù•Ë∂äÈ´òÁöÑËÆøÈóÆÈáè„ÄÇ
看看这一步完成后系统的图示:
<!--[if !vml]-->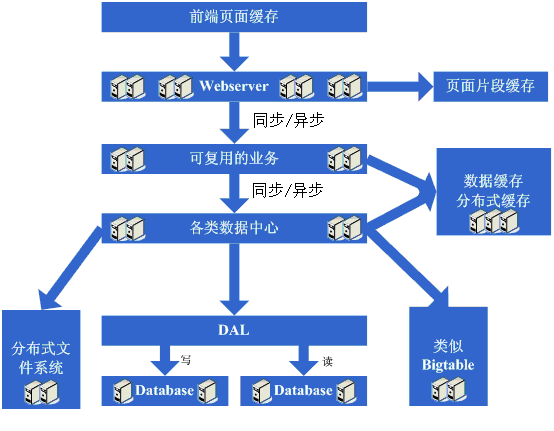
<!--[endif]-->
这一步涉及到了这些知识体系:
这一步涉及的知识体系非常的多,要求对通信、远程调用、消息机制等有深入的理解和掌握,要求的都是从理论、硬件级、操作系统级以及所采用的语言的实现都有清楚的理解。
运维这块涉及的知识体系也非常的多,多数情况下需要掌握分布式并行计算、报表、监控技术以及规则策略等等。
说起来确实不怎么费力,整个网站架构的经典演变过程都和上面比较的类似,当然,每步采取的方案,演变的步骤有可能有不同,另外,由于网站的业务不同,会有不同的专业技术的需求,这篇
blog更多的是从架构的角度来讲解演变的过程,当然,其中还有很多的技术也未在此提及,像数据库集群、数据挖掘、搜索
Á≠âÔºå‰ΩÜÂú®ÁúüÂÆûÁöÑʺîÂèòËøáÁ®ã‰∏≠Ëøò‰ºöÂÄüÂä©ÂÉèÊèêÂçáÁ°¨‰ª∂ÈÖçÁΩÆ„ÄÅÁΩëÁªúÁéØ¢ɄÄÅÊîπÈÄÝÊìç‰ΩúÁ≥ªÁªü„ÄÅ
CDNÈïúÂÉèÁ≠âÊù•ÊîØÊíëÊõ¥Â§ßÁöÑʵÅÈáèÔºåÂõÝÊ≠§Âú®ÁúüÂÆûÁöÑÂèë±ïËøáÁ®ã‰∏≠Ëøò‰ºöÊúâÂæà§öÁöщ∏çÂêåÔºåÂè¶Â§ñ‰∏ĉ∏™Â§ßÂûãÁΩëÁ´ô˶ÅÂÅöÂà∞ÁöÑËøúËøú‰∏牪։ªÖ‰∏äÈù¢Ëøô‰∫õÔºåËøòÊúâÂÉèÂÆâÂÖ®„ÄÅËøêÁª¥„ÄÅËøêËê•„ÄÅÊúçÂä°„ÄÅÂ≠òÂÇ®Á≠âÔºå˶ÅÂÅöÂ•Ω‰∏ĉ∏™Â§ßÂûãÁöÑÁΩëÁ´ôÁúüÁöÑÂæà‰∏çÂÆπÊòìÔºåÂÜôËøôÁØáÊñáÁ´ÝÊõ¥Â§öÁöÑÊòØÂ∏åÊúõËÉΩ§üºïÂá∫Êõ¥Â§ö§ßÂûãÁΩëÁ´ôÊû∂ÊûÑʺîÂèòÁöщªãÁªçÔºå
:)„ÄÇ
¬Ý
从LiveJournal后台 发展看大规模网站性能优化方法


- 2009-07-03 10:48
- 浏览 1802
- 评论(0)
- 查看更多
发表评论

-
haproxy 安装配置和负载实例
2015-03-27 11:49 11496一、环境说明实验环境 OS CentOS5.4 192.1 ... -
使用DNSPOD API实现域名动态解析
2015-03-17 11:13 13283http://www.williamsang.com/arc ... -
开发人员意识感悟
2014-10-30 16:02 01.将复杂的东西整理成 ... -
架构分布施工图
2012-04-17 14:37 1938Êû∂ÊûÑÂàÜÂ∏ÉÊñΩÂ∑•Âõæ ¬Ý ¬Ý ¬Ý ¬Ý ¬Ý ¬Ý ¬Ý ... -
juniper SSG550 防火墙
2011-11-11 13:47 1711¬Ý ¬Ý ¬Ý ¬Ý VPNÊîØÊåÅ ¬Ý ¬Ý Âü∫Êú¨ ... -
F5 BIG-IP
2011-11-11 13:43 3503¬Ý ¬Ý http://wenku.baidu.com/vi ... -
[转]架构师必须补充的能力
2011-07-19 18:12 1595http://xiammy.blog.51cto.co ... -
PHP搭建百万级网站架构技术揭秘:Poppen.de德国社交
2011-06-16 11:25 1932 在了解过世界最大的P ... -
[转]【拯救赵明】安全方案
2011-04-13 17:03 1673http://liuyu.blog.51cto.com/183 ... -
19个心得 明明白白说Linux下的负载均衡
2011-03-10 19:49 2369一、目前网站架构一般分成负载均衡层、web层和数据库层,我其实 ... -
大型网站运维探讨和心得
2011-03-10 19:33 2665ÁúãÂà∞‰∏ÄÁØá‰∏çÈîôÁöÑÂøÉÂæó‰Ω ... -
百万级PHP网站架构工具箱
2011-03-01 18:21 1740在了解过世界最大的PHP站点,Facebook的后台技术后,今 ... -
非常推荐:搭建一个大型网站架构的实验环境(FreeBsd+Nginx+Squid+Apache)
2009-09-10 15:23 2070http://blog.chinaunix.net/u1/55 ... -
网站架构收集
2009-09-10 14:13 2118来自sudone.com 服务器系统架构分析日志 ... -
使用MPICH构建一个四节点的集群系统
2009-09-09 14:01 3125http://selboo.com.cn/post/202/ ... -
网站架构--来自BAIDU百科
2009-08-15 20:55 1716网站架构   一:硬架构   ... -
推荐:大型网站架构设计系列--某人的总结
2009-08-15 20:45 3100大型网站架构设计系列-我的总结如下: 1、 数据结构和产品架 ... -
门户网站运维abc
2009-08-11 15:45 2314http://bbs3.chinaunix.net/threa ... -
„ÄêËΩ¨Ëá™phpchina„ÄëÊî؉ªòÂÆùÊû∂ÊûÑÂ∏àÂØπËØùËÖæËÆØÁÝîÂèëÊĪÁõë
2009-07-29 17:35 2104ÁéãÈÄüÁëúÔºåËÖæËÆØ R&DÁÝîÂèëÊĪÁõëԺ剪é‰∫ã‰∫ßÂìÅÁÝîÂèëÂíåÁÆ°ÁêÜÂ∑•‰ΩúÔºå ... -
【转自phpchina】内网CTO黄晶谈架构演变
2009-07-29 17:34 1381ËøôÊò؉∏Äʨ°ÂÖ¨Âè∏ÂÜÖÈÉ®Áöщ∫§ÊµÅ‰ºöÔºå‰∏ªÈ¢òÊòØÊÝ°ÂÜÖÁöÑÂèë±ïÂè≤ÂíåÊûÑÊû∂ËÆ≤ËߣԺå‰∏ªËÆ≤‰∫∫ ...
相关推荐
NULL 博文链接:https://juji1010.iteye.com/blog/1450311
经典---JAVA设计模式经典---JAVA设计模式
论坛转帖工具 .......... 纯HTML
在TI论坛看到的帖子,感觉挺好,就整理成word文档了,内容主要是运放datasheet常见参数的解释和分析。TI原帖地址“http://www.deyisupport.com/question_answer/analog/amplifiers/f/52/t/20214.aspx”。感谢原作者...
ÊØîÈÇ£‰∫õËΩ¨Â∏ñÁöÑÊñπÊ≥ï•ΩÁî®ÁöѧöÔºåÊåâÂÖ∂‰∏≠ÁöÑreadme ‰∏äÁöÑÊñπÊ≥ïÂè؉ª•ÂæàÊñπ‰æøÁöÑËߣÂÜ≥ÈóÆÈ¢òÔºåËá™Â∑±Á∫ÜÊÑüËßâ‰∏çÈîô‰ºÝ‰∏äÊù•ÈÄÝÁ¶è§ßÂÆ∂„ÄÇ
This is a document about float register on intel cpu.
一键转帖 一键8经验签到. 绿易贴吧工具3.7 11.11版.rar
H42131-转帖《关于用净值计算法计算收益》.doc
1分钟内抓到WPA握手包的方法!转帖的!!不是原创!!
编辑人员转帖去水印工具,很好用,直接选中水印区域后运行伪装即可!
转帖性能测试
转帖PLCDCSFCS三大控制系统的特点和差异.doc
UBB论坛转帖圣手.exeUBB论坛转帖圣手.exe
2.Êñ∞¢ûÊâπÈáèÊõøÊç¢ÂÖ≥ÈîÆËØç(ÂéüÊù•ÊòØÂçï‰∏™ËØçËØ≠ÊõøÊç¢,Âè؉ª•Âà©Áî®Ëøô‰∏™ÂäüËÉΩÂàÝÈô§‰∏ĉ∫õÁΩëÁ´ôÁöÑÈò≤ËΩ¨Â∏ñ‰ª£ÁÝÅ) 3.ÊâπÈáèÈöèÊú∫Êñ∞¢ûÊñáÂ≠ó(Êñ∞¢ûÂÜÖÂÆπÂèØËá™ÂÆö‰πâ,‰ªéËÄåÂÆûÁé∞‰º™ÂéüÂàõ) 4.cookieËÆ∞ÂΩïÊõøÊç¢ÂíåÊñ∞¢ûÂÖ≥ÈîÆËØç(ÈÅøÂÖçÊØèʨ°ÊâìºÄËΩ¨Â∏ñÂ∑•ÂÖ∑ÈÉΩ˶ÅËæìÂÖ•ÁπÅÁêêÁöÑ...
ÂÖ≥‰∫éadamsÂáΩÊï∞ÁöщΩøÁî®ÔºåÂπ∂‰∏îÊñቪ∂‰∏≠ËøòÊèê‰æõ‰∫܉∏ĉ∏™AdamsÁöÑÂ≠¶‰πÝÁΩëÁ´ô„ÄÇ
discuz X2转帖工具、采集工具,discuz论坛批量发帖,批量转帖工具
转帖图片提取工具可以对论坛...转帖图片提取工具使用方法: 将IP138上处理过的东西复制到上方的编辑框内,点击只要图片,下面的编辑框就出现结果,点击 复制结果 就可以把内容复制到剪切板中 转帖图片提取工具截图
这是一个世界编程大赛第一名写的程序,很好玩的,大家试试看。
共10个简单的网站Banner的flash源文件