
https://lobin.iteye.com/admin/blogs/2520928
-
C: 数据类型及定义 https://www.iteye.com/blog/lobin-2510952
-
C: 复杂数据类型 https://www.iteye.com/blog/lobin-2516920
-
C: 字符串 https://www.iteye.com/blog/lobin-2518051
-
C: 指针 https://www.iteye.com/blog/lobin-2518894
-
C: 第5章 指向数组的指针 https://www.iteye.com/blog/lobin-2518895
-
C: 第6章 不完全类型 https://www.iteye.com/blog/lobin-2518897
-
C: 类型转换 https://www.iteye.com/blog/lobin-2537964
-
C: 第7章 修饰符 https://www.iteye.com/blog/lobin-2517064
-
C: 第8章 预处理 https://www.iteye.com/blog/lobin-2326350
-
C: 第9章 变量 https://www.iteye.com/blog/lobin-2517041
-
C: 运算符 https://www.iteye.com/blog/lobin-2369324
-
C: 表达式 https://www.iteye.com/blog/lobin-2520626
-
C: lvalue & rvalue https://www.iteye.com/blog/lobin-2537962
-
C: 表达式求值 https://www.iteye.com/blog/lobin-2537955
-
C: 语句 https://www.iteye.com/blog/lobin-2537957
-
C: 第14章 函数 https://www.iteye.com/blog/lobin-2516445
-
C: 内联函数 https://www.iteye.com/blog/lobin-2517042
-
C: 嵌套函数 https://www.iteye.com/blog/lobin-2327679
-
C: 入口函数 https://www.iteye.com/blog/lobin-2516873
-
C: 第40章 setjmp/longjmp https://www.iteye.com/blog/lobin-2518038
-
C: 第101章 编译链接 https://www.iteye.com/blog/lobin-2516875
-
C: 第102章 程序依赖的链接库 https://www.iteye.com/blog/lobin-2516939
-
C: 第103章 在main函数执行之前后执行初始化和销毁操作 https://www.iteye.com/blog/lobin-2517021
-
C 第1000章:内存对齐 https://www.iteye.com/blog/lobin-2364160
-
C 第1500章: 动态内存申请和释放 https://www.iteye.com/blog/lobin-2337380
-
C 第2000章: 文件 https://www.iteye.com/blog/lobin-2516962
-
C 第2050章: 输入输出 https://www.iteye.com/blog/lobin-2517063
-
C 第2100章: 标准输入输出 https://www.iteye.com/blog/lobin-2517062
-
C 第2500章: 内嵌汇编 https://www.iteye.com/blog/lobin-1585647
-
C 第10000章:GCC https://www.iteye.com/blog/lobin-2516874
-
C 第10001章:LOG https://www.iteye.com/blog/lobin-2517845
-
C 第10001章:LOG(2) https://www.iteye.com/blog/lobin-2518416
-
C: 第10002章 文字处理 https://www.iteye.com/blog/lobin-2518273
-
C: 第10003章 相似度 https://www.iteye.com/blog/lobin-2518301
-
C 第100000000000000000000000000000000000章:内存布局 https://www.iteye.com/blog/lobin-2327707
-
C: 标准库 https://www.iteye.com/blog/lobin-2537959
-
C: 运行库 https://www.iteye.com/blog/lobin-2508566
-
C: Linux C 编程 https://www.iteye.com/blog/lobin-667823
-
C: Linux C 编程 - 图像处理 https://www.iteye.com/blog/lobin-2516443
-
C: Linux C 编程 - FFmpeg多媒体 https://www.iteye.com/blog/lobin-2346290
-
C: Windows编程 https://www.iteye.com/blog/lobin-1663268
- ... ...
数据表示形式
这里数据的表示形式是我们习惯的表示形式,比如1,2,3,123,2.14,3.1,3.14,3.14159265,-3.1,-3.14,-3.14159265,a, abcdefg,还有大数字1.6225927682921336339157801028813e+32,甚至还有1970-01-01,1970-01-01 23:59,1970-01-01 23:59:59,以及你的名字,你写的文章,日志,你发的邮件,你拍的照片,录制的声音(音频)和视频等。
除了数据自身表现的形式,它应该还有类型
在日常生活中,我们并不关心数据是什么类型,但,在计算机中是要确定数据是什么类型,不然,计算机怎么知道要怎么处理数据?
除了类型,它应该还有大小
不然,你要计算机怎么保存和存储你的数据。你要在电脑上保存一部1G的电影,你总得要有至少1G的硬盘吧?
除了类型,大小,它应该还有它表示的意义
数据总应该有它的意义吧?不然这个歌数据表示的是什么?有什么用?表示什么意思?
数据在C语言中的表示和定义
光谈数据,它是一个很抽象的概念。上面的数据的类型,大小,还有意义什么的都是我们对它的一些具体化认识,那么在C语言中是怎么表示和定义这个数据的?
数据在计算机中的表现形式
原码
反码
补码
移码
数据在计算机是以补码形式表示的。
比如数字1在计算机中的表示为0000 0001。其原码,反码,补码为:
原码:0000 0001
反码:0000 0001
补码:0000 0001
数据在计算机中是怎么存储的
C支持这么多数据类型,那么这些不同类型的数据在计算机中是怎么存储的?
在计算机中,不管是什么数据,在计算机中都是以2进制的形式表示和存储的。如0000 1000,1000 1101等。但这样一些0和1的数字表示什么意思呢?我们看着它都是一些0和1的数字,在计算机中的表示是有其特定意义的。2进制数据0000 1000它表示数字8,或者数字8对应的什么东西,如ASCII码中8对应的一个字符。1000 1101它可能表示数字141,或者-13或者其他的什么东西。
在没有指定数据时什么类型,比如1、123,-1,-123,3.1, 3.14,3.14159265,-3.1,-3.14,-3.14159265,a, abcdefg,还有大数字1.6225927682921336339157801028813e+32是怎么存储的?这个数字是2的107次方的科学计算表示。
先看简单的数字,数字有正数,负数,整数,小数,所以看着简单的数字在计算机中的表示和存储一点都不简单,甚至很复杂。
可以从简单的正的整数开始,比如上面的1和123:
程序结构
in units called source files, (or preprocessing files) in this International Standard.
translation unit
translation unit是程序预处理后的叫法。在程序预处理之前,还有一种preprocessing translation unit的叫法。在ISO/IEC 9899:TC2标准中,即WG14/N1124,translation unit被定义为:
directive #include is known as a preprocessing translation unit. After preprocessing, a
preprocessing translation unit is called a translation unit.
在ANSI/ISO 9899-1990中,即American National Standard for Programming Languages - C中,translation unit被定义为:

标识符
词法单元

其中keyword、identifier被认为是词法单元很好理解。
在词法分析阶段,需要注意的是:
1、第4个string-literal,如在对strtok("<!DOCTYPE html><html lang=\"en\"> <head> <title>Sample page</title> </head> <body> <h1>Sample page</h1> <p>This is a <a href=\"demo.html\">simple</a> sample.</p> <!-- this is a comment --> </body></html>", "<>! \"/=");这条语句进行词法分析的时候,其中的两个字符串常量"<!DOCTYPE html><html lang=\"en\"> <head> <title>Sample page</title> </head> <body> <h1>Sample page</h1> <p>This is a <a href=\"demo.html\">simple</a> sample.</p> <!-- this is a comment --> </body></html>"以及"<>! \"/="分别是一个词法单元。
2、第5个punctuator,以下标点符号也都是词法单元。在上面的例子中,左小括号“(”、逗号“,”、右小括号“)”,以及分号“;”都是词法单元。

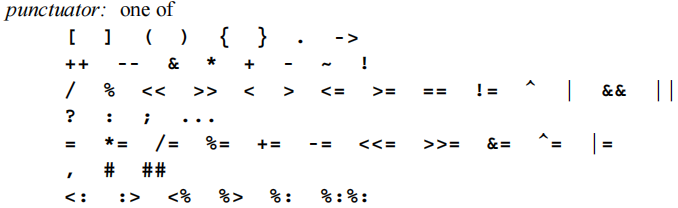
语法
编程语言C采用类似文法的形式来描述语法,这是一种形式化语言的描述方式。在一般情况下,语法和文法这两个概念可以是一个意思。
采用这种形式化语言来描述语法在理解的时候并不太容易,如以下赋值表达式(assignment-expression)定义:

对于第1种情况来说,为什么赋值表达式可以是一个条件表达式(conditional-expression)?对于第2种情况来说,赋值操作符(assignment-operator)左边为什么是一个一元表达式(unary-expression)?为什么不是一个左值(lvalue)表达式?还有为什么赋值操作符右边又是一个赋值表达式(assignment-expression)?
C语言
1、C是一种系统编程语言
2、C是一种低级语言
3、C是一种高级语言
4、C属于编译型语言
5、C是一种静态类型的语言
5、C是现代众语言之母
C虽然是一种静态类型的语言,但C语言的类型具有非常大的灵活性。虽然是静态类型,变量的声明和定义需要显式指定类型,变量必须具有某种类型,但C语言的不同类型,变量之间都可以很灵活的进行转换。
C语言的安全性
C语言给了编程时所有的能力,却牺牲了安全性。C语言的安全性牺牲主要表现在内存的操作上,以及类型安全上。
C语言通过指针操作变量或内存。
在使用C语言编写程序时,经常会遇到各种各样的问题,类似“warning: assignment from incompatible pointer type”,遇到这种问题时必须要警惕,除非你确定这样的赋值是你需要的,这样的赋值是安全的。
Algol-derived语言
ALGOL语言
即ALGOrithmic Language,算法(Algorithm)语言
操作变量
操作指针
int a = 100;
printf("@=%p, @=%p, @=%p, @=%p, @=%p, @=%p, @=%p, @=%p, @=%p, @=%p, "
"@=%p, @=%p, @=%p, @=%p, @=%p, @=%p, @=%p, @=%p, @=%p, @=%p\n",
&a,
&(*(&a)),
&(*(&(*(&a)))),
&(*(&(*(&(*(&a)))))),
&(*(&(*(&(*(&(*(&a)))))))),
&(*(&(*(&(*(&(*(&(*(&a)))))))))),
&(*(&(*(&(*(&(*(&(*(&(*(&a)))))))))))),
&(*(&(*(&(*(&(*(&(*(&(*(&(*(&a)))))))))))))),
&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&a)))))))))))))))),
&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&a)))))))))))))))))),
&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&a)))))))))))))))))))),
&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&a)))))))))))))))))))))),
&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&a)))))))))))))))))))))))),
&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&a)))))))))))))))))))))))))),
&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&a)))))))))))))))))))))))))))),
&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&a)))))))))))))))))))))))))))))),
&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&a)))))))))))))))))))))))))))))))),
&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&a)))))))))))))))))))))))))))))))))),
&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&a)))))))))))))))))))))))))))))))))))),
&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&(*(&a)))))))))))))))))))))))))))))))))))))));
常量
这里的常量指的是const限定的变量。C中的常量也一般指的是const修饰的变量。
常量的定义
const int C = 1;
C还可以预处理指令定义一个常量:
#define C 1
这跟上面的const是有本质的区别。
关于常量和变量,从内存的角度看是不存在所谓的常量和变量,因为内存本身是可以修改的。
真正称得上“常量”是字面量,比如数字1。
字面量
字面量(literal)
字面量并不一定就是一个常量。
复合字面量
复合字面量(Compound Literals)定义如下:
复合字面量是一个后缀表达式。
复合字面量不是常量。
https://gcc.gnu.org/onlinedocs/gcc/Compound-Literals.html
如下给struct foo变量f赋值的{a, {'a', 0}}就是一个复合字面量(Compound Literals)。
struct foo
{
int i;
char b[2];
};
int a = 11;
struct foo f = {a, {'a', 0}};
定义
初始化
声明
什么是声明
声明这个概念在C语言中并不是那么容易理解。声明的意思就是“已经定义了”
声明在C语言标准中称为“Declaration”,这个词在标准中经常出现。在C语言课堂教学中,也经常反复提起强调声明,以至于甚至在C语言开发中都潜意识的看是否已经声明,要先去声明。这是一种良好的习惯,通常我们也会去先声明再去使用。

看下这段代码:
char* mark;
for (char *p = input, mark = p; *p; p++) ...
这段代码是标准C不允许的,不过自C99之后,for语句中新增了一种语法形式,括号中的第1部分可以是一个声明。然而这段代码还是错误的,在这段代码中,也许你的本意是先定义了一个char类型指针的mark变量,然后在for语句中又定义一个char类型指针的p变量并初始化,然后再将p赋值给mark,但是,括号中的第1部分被解释为一个声明,在这个声明中,声明并定义了一个char类型指针的p变量并初始化,然后又声明并定义了一个char类型的mark变量,这时其实是定义了两个mark变量,一个是char*类型,一个是char类型,但它们的作用域不一样,这个是允许的。但是后面又将p赋值给mark,这就有问题了,因为p是char类型的指针,而这时候的mark是char类型。注意这通常还不会报错,只是会有一个告警提示。
声明包括显式声明和隐式声明。
显式声明
隐式声明
所谓的隐式声明包括两层意思, 一个是定义在使用之前,那么定义也隐式的含有声明的意思。另一种就是使用之前并没有声明,编译器会有一个隐式的声明,如函数的隐式声明,不过这种规则自C99之后,确切的说自WG14/N1124之后,或者对应的自ISO/IEC 9899:TC2之后,支持隐式的函数声明,这个特性被移除(remove implicit function declaration)。
之后这个特性被移除(remove implicit function declaration)
我们去声明,指的是显式声明。为什么要先声明呀?我们有时候忘记了声明,也没有出现错误,程序也可以正常的运行。有些情况,声明也可以不需要。这种情况还是挺多的。
是否先声明,不同的编译器在编译的时候反应也不一样。这点也跟编译器有关。
声明指的是对变量或函数进行声明,对于变量和函数,是否声明对于程序差别很大,尤其是函数声明,有时候可以不先声明,有时候必须先声明。
变量声明
函数声明
声明和定义的区别
很多时候,我们经常难以区分声明和定义,如下一个变量i,为什么会有两个i?到底哪个是声明哪个是定义?
int i;
int main()
{
printf("i: %d, addr: %u\n", i, &i);
return 0;
}
int i;
声明和定义通常说的是声明或者定义一个变量或者函数。不过,还有类型,比如C支持复合数据类型。我们是说“定义一种类型”呢?还是“声明一种类型”?尽管我们说定义一种类型通常也没什么问题。不过从语法上开看,它是声明的一种,我们更应该理解成“声明一种类型”。
如下,我们声明一个point类型的结构体:
struct point
{
double x, y;
};
还有关键字typedef从字面意思上很容易让人理解成“定义一个类型”,尽管这种理解也没有什么问题。不过从语法上来看,它是一种“storage-class-specifier”,是在声明的时候用到的一个关键字。
作用域
作用域指的是变量,函数的可见范围,也就是可见性。这个变量或函数是有它的作用域的,不在定义的作用域内是不能使用或调用的。
所谓可见性指的是是否能访问到对应内存,以及对应内存的变化是否能感知到。这个比较模糊不太好理解,可参考另一篇专门讲解可见性的文章。
文件域
变量的定义
变量的初始化
变量的声明
递归
尾递归
提升规则
即promotion rules
warning: ‘float’ is promoted to ‘double’ when passed through ‘...’
默认提升类型(default promotion types)
整型提升规则(integer promotion rules)
整型提升(integer promotions)
参数提升(argument promotions)
内存
C程序的内存区域包括代码区,栈,全局数据区。全局数据区还分为静态全局区和动态全局区。这些内存区域除了代码区,其他的区域都是用于存放运行时需要的数据,比如我们定义的变量,以及动态开辟的内存空间,都是用来存放我们的数据。
内存模型
运行时数据区
内存地址
内存地址存在逻辑地址和物理地址之分。
逻辑地址
相对系统来说,我们在应用层面操作的都是内存的逻辑地址。
分配内存
分配内存并不只是通过malloc和realloc函数这种申请动态内存的情况,这只是一种堆上分配,是一种动态分配内存方式。内存的分配还包括非动态分配方式,包括栈上分配已经在全局数据区上进行的静态分配。
静态分配
静态分配是一种编译器在编译的时候就已经确定好了为变量分配内存空间的方式。
void main()
{
char *s = "abcdefg";
printf("%s\n", s);
memcpy(s + 1, s, 3);
s = "abcdefg";
printf("%s\n", s);
}
静态分配也包括栈上分配。
栈上分配
在函数内部定义变量(非静态)是直接在栈上分配的。 在栈上给变量分配的内存空间和从堆上申请内存空间不一样,不需要调用malloc这样的分配内存的函数去主动分配内存。编译器在编译的时候就已经确定好了为变量分配内存空间。
内存操作
对变量进行操作就是对内存进行操作。包括通过指针来访问内存以及操作内存的相关函数,如memset,memcpy,memmove,strcpy,strncpy等。
初始化内存
通常我们会通过memset来初始化一块内存。
memset
函数原型
void * memset ( void * ptr, int value, size_t num );
int a = 0;
memset(&a, 1, sizeof(a));
printf("%d(%#x)\n", a, a);
对大块内存初始化
char *area = (char *) malloc(UINT_MAX);
printf("%u\n", UINT_MAX);
memset(area, 1, UINT_MAX);
在对大块内存初始化时会报错,程序会挂掉,产生core文件。
操作内存
memcpy
void main()
{
char *s = "abcdefg";
printf("%s\n", s);
memcpy(s + 1, s, 3);
printf("%s\n", s);
}
memmove
void main()
{
char *s = "abcdefg";
printf("%s\n", s);
memmove(s + 1, s, 3);
printf("%s\n", s);
}
源文件
头文件
多文件
输入输出
这里主要将的IO部分。
文件读写
网络IO读写
内存对齐
在上面讲结构体等复杂数据类型的时候,我们讲到结构体在内存中的布局,以及结构体的大小问题。很好笑的是,在前面讨论的时候,按照前面涉及的知识点,我们都没有什么根据来计算出结构体的大小。只能通过sizeof来得到结构体的大小到底是多少?
• no hole may occur at the beginning.
• members occupy increasing storage addresses.
• if necessary, a hole is placed on the end to make the structure big enough to pack tightly into arrays and maintain proper alignment.
内嵌汇编
有关C/C++:内嵌汇编可参考这篇文章:https://lobin.iteye.com/blog/1585647。
C
The Standard
Note: Prices quoted here are current as of the date each was written but are not guaranteed to remain unchanged.
The international standard which defines the C programming language is ISO/IEC 9899 a joint effort of ISO and IEC and the participating countries via their national body's all of which make the standard available via whatever publishing arrangement(s) each makes, many of which are available via the web for easy purchasing. Each participating country adopts the standard into their own standards system (some use the same document number) though in some cases changes are made to the document -- the technical content should (and really must) remain the same.
The working group (WG14) makes some of the drafts, the rationale by which they made their decisions (The Rationale) and issues raised against the standard (Defect Reports) available for free from their web site, see Web_resources#Secondary_materials for the links.
The latest freely available working paper (draft) by WG14 is n2596 (aka C2x).
C18
The current standard is ISO/IEC 9899:2018 (aka C17 and C18) -- this version addresses many defects reported for C11. It incorporates TCs (Technical Corrigenda) and does not introduce new language features.
Sites that make one or more of these (standards) documents available are:
ISO:
CHF 198 - https://www.iso.org/standard/74528.html -- same price for PDF download or PDF shipped on a CD.
IEC:
CHF 198 - https://webstore.iec.ch/publication/63478 -- same price for PDF download or PDF shipped on a CD.
The latest freely available draft is c17_updated_proposed_fdis.pdf.
C11
The older standard was ISO/IEC 9899:2011 -- (aka C11 and until it was adopted C1x) will soon be unavailable from official sources due to the adoption of C17.
Sites that make one or more of these (standards) documents available are:
ISO:
CHF 238 - http://www.iso.org/iso/iso_catalogue/catalogue_tc/catalogue_detail.htm?csnumber=57853 -- same price for PDF download or PDF shipped on a CD.
ISO/IEC 9899/Cor1:2012: http://www.iso.org/iso/home/store/catalogue_tc/catalogue_detail.htm?csnumber=61717 -- PDF download
USA INCITS (née ANSI) -- essentially identical to the ISO/IEC document:
USD 60 - INCITS/ISO/IEC 9899:2012 http://webstore.ansi.org/RecordDetail.aspx?sku=INCITS%2FISO%2FIEC+9899-2012 -- PDF download.
ISO/IEC 9899/Cor1:2012: http://webstore.ansi.org/RecordDetail.aspx?sku=ISO%2fIEC+9899%2fCor1%3a2012 -- PDF download
The latest freely available draft is N1570.
The latest defect report summary for C11 is available at n2244.htm.
C99
The next older standard was ISO/IEC 9899:1999 (aka C99 and C9x) likely unavailable from any official sources, due to the ISO adoption of C11.
The British Standards Institute (BSI) has published C99, TC1 and The Rationale in a bound book, see Books#References for the link.
Sites that make one or more of the documents available are:
USA INCITS (née ANSI) -- PDF format download only:
USD 30 - INCITS/ISO/IEC 9899:1999 http://webstore.ansi.org/RecordDetail.aspx?sku=INCITS%2fISO%2fIEC+9899-1999+(R2005)
Techstreet -- PDF format free download, USD 12 for printed edition:
ISO/IEC 9899/Cor1:2001: http://www.techstreet.com/standards/iso_iec/9899_cor1_2001?product_id=1035925
ISO/IEC 9899/Cor2:2004: http://www.techstreet.com/standards/iso_iec/9899_cor2_2004?product_id=1205982
ISO/IEC 9899/Cor3:2007: http://www.techstreet.com/standards/iso_iec/9899_cor3_2007?product_id=1527765
This is also effectively available for free as N1256.
C89 / C90 / C95
The older standards -- ANSI X3.159-1989 (aka C89), ISO/IEC 9899:1990 (aka C90), ISO/IEC 9899:1990/AMD 1:1995 (aka AMD1 or C95) -- are no longer available from official sources, so your best source is a printed book. C89 and C90 are identical except for the frontmatter and section numbering.
AS 3955-1991 (C90) is still available from two sources:
SAI-Global, the exclusive publisher for Standards Australia:
AUD 224.76 - PDF or hard copy (printed): http://infostore.saiglobal.com/store/Details.aspx?ProductID=306911
USA ANSI/INCITS:
USD 229 - PDF only: http://webstore.ansi.org/ansidocstore/product.asp?sku=AS+3955%2D1991
AMD1 (which transforms C90 into C95) can be ordered from IHS (née Global Engineering Documents):
USD 65 for PDF and USD 82 for hard copy (printed): enormous product url hidden
Many standards can be ordered from good technical booksellers, such as Opamp.
Note: Implementations which conform with C89/C90 are more widely available than those which conform with any later revision(s).
https://www.gnu.org/software/gnu-c-manual/gnu-c-manual.pdf
C编译器
https://clang.llvm.org/docs/UsersManual.html
无运行库及标准库环境下的C语言编程
开发C运行库及标准库
错误和警告
编译阶段错误和警告
这里其实还包括编译前阶段的错误和警告提示
warning: backslash and newline separated by space
出现这个告警信息一般无关紧要。
链接阶段错误和警告
运行阶段错误和警告
模块化编程
声明和定义分离
这遵循接口和实现分离原则。
函数、类型以及变量在头文件中声明,在源程序文件中定义实现。头文件即.h(在C++中通常是.hpp)文件,源程序文件即.c(在C++中通常是.cpp)文件。
头文件和源程序文件的关系
通常,每个源程序文件都对应一个头文件,既一对一,这是最简单的方式。但源程序文件主要用于函数定义实现,和头文件中的函数声明关系不大,只要源程序文件中使用到的函数、类型和变量在使用之前有声明就行。头文件其实和使用其中的函数,类型以及变量声明的源程序文件有关。所以源程序文件和头文件并不应该是简单的一对一关系。
头文件和源程序文件的模块组织
头文件中主要包含函数、类型,变量声明。以及一些定义,如宏定义等。
源程序文件主要包括函数及变量定义。
头文件和源程序文件都可以分别按模块进行组织。源程序文件和头文件按模块进行组织划分依赖关系。一个源程序文件通常依赖一个或多个头文件,一个头文件也通常被多个源程序文件依赖包含。
全局访问控制的函数和变量
模块内访问控制的函数和变量
源程序文件虽然只是一个普通的文件,本质上和其他文件没什么区别,但在C语言中,在程序组织上以及函数或变量的作用域或者叫访问控制范围上是有其语义的。通常来说,函数或变量其作用域是从其定义的地方开始的,也就是说只有在其定义以后才有效,才能去使用。
C语言提供了一个static用于将一个函数或变量声明为静态函数或变量,这种函数或变量的作用域为单个源程序文件模块,即在当前这个源程序文件中都可以使用这个静态函数或变量。
由函数提供的通过函数参数传递的局部静态变量
这个怎么理解?
就是编写C程序代码时不在任何函数以外定义变量,甚至连函数声明都没有。所有可能会在函数外部或者模块其他地方,甚至全局其他任何地方会访问的变量都通过一个局部静态变量并由函数返回提供,并通过参数传递的方式提供。
这个最初的想法是讨厌在程序中定义太多的全局变量,甚至是静态变量。有时候在程序中定义了超过2个这样的全局变量都觉得讨厌。尤其是在程序代码非常庞大的时候。
这种思路的目的就是没有全局变量定义,甚至连声明都没有。即便是在变量出现的最初的地方,有个局部静态变量的定义,但本意是“offer”,即通过一个叫“Offer Function”的函数提供我们需要的变量访问,这个函数本意是一个“Offer Function”,或"Function Producer";而且,由于这个变量是在函数内部定义,虽然声明为静态,从语言的角度来看,还是可以将它当作局部变量对待。
函数指针
结构体中使用函数指针
处理空指针
内存保护
智能指针
实现自动内存资源的申请和释放管理
内存管理
GC
回调函数
封装
C程序OO编程风格(COO风格)
OO范畴。
设计模式
设计模式,尤其是GOF,感觉都是讲烂了,认为有用的将之奉为工程至宝,认为没用的就想把它扔进垃圾桶。很多人对待它的态度更是觉得“食之无味,弃之可惜”。
设计模式其实是一种很好的工程实践,同时也可以作为在设计思想上的参考。
其他语言提供的一些机制也可以借鉴
有利于模块化编程的,如上面提到的COO本质上就是借鉴的面向对象的OO,以及闭包等。不只是其他语言上的,像在工程中采用的模块化思想也可以借鉴。
这里介绍一些实际有利于模块化编程的思想和实践。
组件
面向组件的编程是一种非常有效的模块化编程实践。这在其他编程语言领域,尤其是在商业领域或者工业领域中,应用的非常广泛。
链接库
链接库就是一种编译型语言实现组件编程最直接的方式。包括动态链接库和静态链接库。
动态链接库
静态链接库
移植性
平台无关
标准
POSIX等
标准库
平台有关
系统调用。
条件判断
可以在预处理阶段通过条件判断根据当前的编译环境和系统环境等配置编译出符合系统的程序,使程序具备更好的移植性,
编程日志
编程中的错误处理
在编程时,在调用函数时,函数可能会返回错误,函数通常通过返回值来判断函数调用是否成功,比如成功返回0,出错返回-1或者一个错误代码。也有通过一个errno错误代码来返回的。对于出错的返回省事倒是省事,但对于出错的处理就是件麻烦事,尽管很多语言提供了相应的错误处理机制,比如C++的错误的捕获,以及Java的异常处理机制,但在错误的处理上还是很麻烦,更何况C本身并没有这样的机制。
错误处理
程序返回错误很简单,不管是通过返回-1或者一个错误代码,或者通过一个errno错误代码返回,还是C++,Java这种提供错误处理机制的语言,通过throw将错误或异常抛出。在错误处理方面,C程序需要程序员自行处理程序运行中的各种出错的情况。当然也有系统提供的一些简单的错误处理,以及一些非标准库提供的错误处理。
程序中错误处理之所以麻烦点很多,主要表现在:
错误的定义不确定,模糊不清。
这里还包括故障,异常,例外,陷阱(trap),中断
还有些,比如断言,崩溃(crash),瘫痪,程序宕掉。
错误代码定义混乱。
函数(包括程序、外设等)的一些行为上的隐晦,特别对于一些边界临界点,例外的行为不确定,它也不给你说明。



相关推荐
内含:C参考手册.chm(最全的一个) 、C函数查询.chm 、C语言库函数速查手册.chm 、C语言100例.chm、C语言标准库函数大全.chm、C语言库函数使用大全CHM版.chm、 这6个是我找了好久才找到的,各有各的好处,3个互补十分...
c8051F系列单片机开发与C语言编程 c8051F系列单片机开发与C语言编程 c8051F系列单片机开发与C语言编程
qt调用c语言代码(c语言的代码写在c文件中)
基于C语言的神庙逃亡游戏,优秀C程序设计,计算机新手必看! 基于C语言的神庙逃亡游戏,优秀C程序设计,计算机新手必看! 基于C语言的神庙逃亡游戏,优秀C程序设计,计算机新手必看! 基于C语言的神庙逃亡游戏,优秀...
数字滤波器的C语言实现,包括高通、低通、带通滤波器( Digital filter C language, including high pass, low pass, band pass filter )
C8051的C语言学习应用,教你如何快速学习掌握C8051的知识。
(0积分)C语言标准(c89,c99,c11,c17,c2x)
C8051F 系列单片机开发与C语言编程是, C8051F的C语言示例,掌握C8051F的基本用法
C语言规则检查工具C Checker C语言规则检查工具C Checker C语言规则检查工具C Checker
c4.5算法实现 用c语言实现 经过调试 可直接使用 在vc下运行
里面的数据来自UCI库,机器学习C4.5算法完全采用C语言实现
C.Programming.FAQs_C语言常见问题集C.Programming.FAQs_C语言常见问题集C.Programming.FAQs_C语言常见问题集C.Programming.FAQs_C语言常见问题集C.Programming.FAQs_C语言常见问题集C.Programming.FAQs_C语言常见...
c.STL 学习c语言的必看 c.STL 学习c语言的必看
C语言主要知识点巩固(学习Objective-C 的前提),PPT格式。
c语言中.C文件与.h头文件的关系,这个对于c程序的编写至关重要,与其对于文件相互包含,有独到见解。
c语言标准库,包含c语言标准库中的函数的介绍
PLL 锁相环 仿真 C代码实现,经过验证的锁相环仿真与C语言实现,对电力电子初学者非常有用,希望对您有帮助。 PLL 锁相环 仿真 C代码实现,经过验证的锁相环仿真与C语言实现,对电力电子初学者非常有用,希望对您有...
c语言Turbo C下写的俄罗斯方块 c语言UDP传输系统源码 c语言万年历源码 c语言五子棋源码 c语言俄罗斯方块 c语言做的一个任务管理器 c语言做的播放器源码 c语言做的绘图板系统 c语言别踩白块儿(双人版)源码 c语言力学...
C语言 C++ 异同 浅析C语言与C_的异同
C高级编程 基于模块化设计思想的C语言开发 高清 带书签