
http://blog.csdn.net/historyasamirror/article/details/6244893(转)
ParallelGC
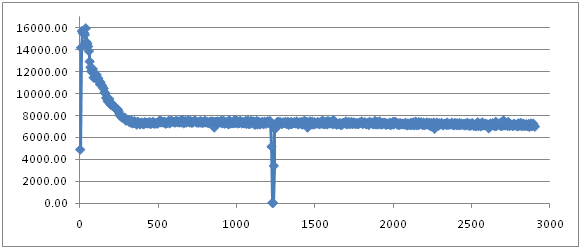
再来看看parallelGC的结果。
截取其中一段放大如下:
JVM参数如下:
Java -jar -Xms10g -Xmx15g -XX:+UseParallelGC -XX:ParallelGCThreads=8 -XX:NewSize=6g -XX:MaxNewSize=6g -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -Xloggc:./log/gc.log Slaver.jar
XX:ParallelGCThreads是用来设置GC并行线程的数量,由于我的测试服务器是8个core,所以这里也设置成了8;
和上一篇中SerialGC的实验结果图相比,有了很大的差别:
首先是整条throughput曲线的抖动明显下降了,并且,更重要的是,整个系统的平均throughput提高了。SerialGC中的曲线在6000左右抖动,而这的实验结果图中,throughput基本上在7000以上。这说明MinorGC对系统造成的影响变小了,为了确认这一点,可以随意看一条Minor GC的log:
1020.911: [GC [PSYoungGen: 6252096K->22304K(6260544K)] 9744749K->3537437K(10454848K), 0.0831140 secs] [Times: user=0.62 sys=0.06, real=0.09 secs ]
从log中读出,一个minor GC在0.09秒内就完成了,相当于只阻塞了application 0.09秒的时间,和SerialGC相比,大概缩短为它的几分之一。正是因为minor GC的时间变短,所以系统受到的影响变小,整体性能也显著提高。
实际上,在Sun的官方文档中,ParallelGC也是被推荐为“能够最大化系统的throughput”。而且,在服务器一级的机器上,ParallelGC是被设置为默认的GC collector,也就是说,如果JVM参数什么没有,那么就是采用Parallel GC。
有一个需要注意的是,虽然real time是0.09秒,但是user time是real time的好几倍,正好说明在执行minor GC的时候是由多个thread共同完成的。
不过,和SerialGC一样,它也有一个大峡谷,和SerialGC一样,这也是Full GC发生的地方:
1239.230: [Full GC [PSYoungGen: 22048K->17780K(6268352K)] [PSOldGen: 4190181K->4194303K(9437184K)] 4212229K->4212084K(15705536K) [PSPermGen: 11049K->11049K(22400K)], 14.1572170 secs] [Times: user=14.15 sys=0.01, real=14.16 secs ]
整个Full GC持续了14.16秒,这段时间系统的throughput下降为0。这点上,ParallelGC和SerialGC相比并没有任何优势。并且,user time和real time值差不多,说明也是由单线程完成的Full GC的工作。
最后需要指出的是,采用ParallelGC的实验发生Full GC的时间和Seral GC相比要更早一些。这主要是因为平均的throughput要比前者更好,所以插入数据的速度更快,所以tenured generation更早的就被数据填满了。
ParallelOldGC
JVM参数如下:
java -jar -Xms10g -Xmx15g -XX:+UseParallelOldGC -XX:ParallelGCThreads=8 -XX:NewSize=6g -XX:MaxNewSize=6g -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintHeapAtGC -Xloggc:./log/gc.log Slaver.jar
实验结果:
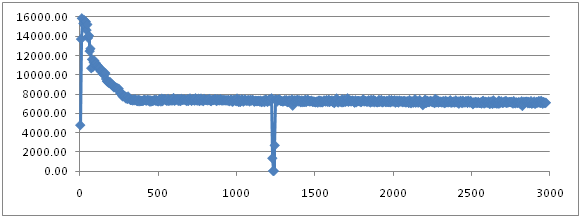
实验结果几乎和ParallelGC一模一样。
它的minor GC的机制和ParallelGC是一样的,所以就不多说了。
但是在Full GC的时候还是有一些差别:
1248.458: [Full GC [PSYoungGen: 22176K->0K(6268224K)] [ParOldGen: 4179368K->4166292K(9437184K)] 4201544K->4166292K(15705408K) [PSPermGen: 11047K->11032K(22400K)], 17.1588660 secs] [Times:user=124.85 sys=0.53, real=17.16 secs ]
老实说,这个结果有些出乎意料。因为按照文档,ParallelOldGC在执行FullGC的时候是多线程工作的,我原以为Full GC的时间就会相应的缩短很多。但是,至少在我的实验中,两者的Full GC的时间差不多(14.16 vs 17.16)。唯一让我确定ParallelOldGC确实是采用多线程工作的是,user time相比real time委实大了好几倍。但是貌似多线程的Full GC在我这里没有起到作用。
(CMS collector比较麻烦,下篇再说)
补充一下,前一篇中各种collector的示意图摘自:



相关推荐
### 马士兵JVM调优笔记知识点梳理 #### 一、Java内存结构 Java程序运行时,其内存被划分为几个不同的区域,包括堆内存(Heap)、方法区(Method Area)、栈(Stack)、程序计数器(Program Counter Register)以及...
《深入解析JVM调优与监控》 在Java开发领域,JVM(Java Virtual Machine)是运行Java程序的核心,它的性能直接影响着应用的效率和稳定性。JVM调优是优化Java应用程序性能的关键环节,而"jvm-monitor"则提供了一种...
"Java面试题-内存+GC+类加载器+JVM调优" 在 Java 面试中,内存、GC、类加载器和 JVM 调优是非常重要的知识点,本文将对这些知识点进行详细的解释和分析。 一、Java 内存模型 在 Java 中,内存主要分为两部分:堆...
### jvm调优建议文档知识点解析 #### 一、JVM基本概念及组成部分 - **JVM内存区域划分**:JVM内存分为新生代、老年代以及元空间(Metaspace)三大区域。其中,新生代负责存放新创建的对象,经过多次垃圾回收后存活的...
理解不同类型的GC工作原理、触发条件以及如何选择合适的GC策略对于减少系统停顿时间至关重要。 3. **内存分配与GC调优**:包括对象的分配策略、新生代与老年代的划分、内存大小调整、存活对象的判断算法(如Mark-...
### JVM_GC调优详解 #### 一、JVM体系结构概览 Java虚拟机(JVM)作为Java程序的运行环境,其内部结构复杂且高效。为了更好地理解JVM_GC调优,我们首先来了解一下JVM的基本组成部分。 1. **类装载器子系统(Class ...
- **选择合适的垃圾回收器**:根据应用的特点选择不同的GC策略,如CMS、G1等。 - **监控工具**:利用VisualVM、JConsole等工具监控JVM的运行状态,分析GC行为。 - **GC日志分析**:通过配置日志参数(`-XX:+...
一个PPT包含 java内存模型,class运行机制。 java jvm垃圾回收算法 java jvm gc常见垃圾回收算法分析 java jvm调优
"用于测试jvm gc调优-share-jvm-gc.zip"这个压缩包文件很可能包含了一些工具、脚本或教程,用于帮助我们了解和实践JVM的垃圾收集优化。 首先,我们需要理解JVM GC的基本原理。垃圾收集器的主要任务是识别并回收不再...
其次,选择合适的垃圾收集器(Garbage Collector,简称GC)对性能影响很大。不同类型的GC适用于不同的应用场景。例如,Serial Collector适合单线程环境,Parallel Collector适用于多CPU环境,可以提高并行收集的效率...
每种算法在不同场景下有不同的性能表现,需要根据应用需求选择合适的GC。 2. **内存分配策略**:调整新生代、老年代、永久代(或元空间)的大小,以平衡吞吐量和响应时间。过大可能导致内存浪费,过小可能导致频繁...
2. **选择合适的垃圾收集器**:考虑系统资源和应用特点,如响应时间优先或吞吐量优先。 3. **监控和分析GC日志**:通过`-XX:+PrintGCDetails`等选项输出GC日志,分析垃圾回收行为。 4. **减少Full GC**:优化对象...
### 2024年Java面试题:JVM性能调优面试题第二部分 #### 内存模型及分区 在Java虚拟机(JVM)中,内存主要被划分为以下几个区域: 1. **堆区(Heap)**:堆区是用于存储初始化的对象、成员变量等数据的地方。所有对象...
选择合适的GC策略至关重要,如低延迟场景下通常使用CMS或G1。 - **GC日志**:开启-XX:+PrintGCDetails和-XX:+PrintGCDateStamps,以便分析和优化。 3. **类加载机制** - **类加载器**:Bootstrap、Extension、...
5. **JVM调优**:通过调整JVM参数,可以控制GC的行为,例如设置堆大小、新生代和老年代的比例、GC策略等。常用的JVM参数有`-Xms`, `-Xmx`, `-Xmn`, `-XX:NewRatio`, `-XX:SurvivorRatio`, `-XX:+UseConcMarkSweepGC`...
JVM性能调优监控工具jps、jstack、jmap、jhat、jstat使用详解 本文将对一些常用的 JVM 性能调优监控工具进行介绍,包括 jps、jstack、jmap、jhat、jstat 等工具的使用详解。这些工具对于 Java 程序员来说是必备的,...
JVM调优还包括对垃圾收集器(Garbage Collector,GC)的选择和参数调整。不同类型的GC有不同的性能特征,如Serial GC适合轻量级应用,Parallel GC和Concurrent Mark Sweep (CMS) GC适用于高并发场景,G1 GC则试图...
在Java世界中,Java虚拟机(JVM)是运行所有Java应用程序的核心。JVM内存设置与调优是提升应用性能的...理解内存结构、选择合适的垃圾收集器、合理设置参数,并结合监控工具进行调优,是优化Java应用性能的关键步骤。
选择合适的算法和调整算法的参数是性能调优的重点。 在JDK 5版本中,垃圾回收器进行了较大改进。其中包括了对新生代(Young Generation)和老年代(Tenured Generation)垃圾回收的优化。新生代负责快速创建对象,...