netli
- ŠÁĆŔžł: 74642 ŠČí
- ŠÇžňłź:

- ŠŁąŔç¬: ňîŚń║Č
-

Šľçšźáňłćš▒╗
- ňůĘÚâĘňŹÜň«ó (37)
- python (3)
- j2se (3)
- Struts 2 (1)
- HTTP (1)
- memcached (4)
- šŻĹšźÖŠ×Š×ä (6)
- ŠôŹńŻťš│╗š╗č (2)
- lighttpd (1)
- ŠÁőŔ»Ľ (1)
- ň║öšöĘŠťŹňŐíňÖĘ (1)
- Ŕ»╗ń╣Ž (3)
- Grails (1)
- webň돚ź» (0)
- Beetle (1)
- LDAP (0)
- GWT (1)
- hudson (1)
- ň╝Çň┐â (0)
- RoR (1)
- ant&mvn (0)
- ASM (1)
- robocode (1)
- JAAS Jboss Ŕ«ĄŔ»ü (0)
šĄżňî║šëłňŁŚ
- ŠłĹšÜäŔÁäŔ«» ( 0)
- ŠłĹšÜäŔ«║ňŁŤ ( 1)
- ŠłĹšÜäÚŚ«šşö ( 0)
ňşśŠíúňłćš▒╗
- 2012-11 ( 1)
- 2012-08 ( 2)
- 2011-09 ( 1)
- ŠŤ┤ňĄÜňşśŠíú...
ŠťÇŠľ░Ŕ»äŔ«║
-
rmn190´╝Ü
ňĄÜŔ░óŠą╝ńŞ╗Ŕ┐Öń╣łŔ»Žš╗ćšÜäŔ«▓Ŕžú´╝ü
šöĘnmonšŤĹŠÄžLinuxš│╗š╗čŔÁäŠ║É -
669098238´╝Ü
   good
struts2ŠÇ╗š╗ôń╣ő OGNLŔíĘŔżżň╝Ć -
javantsky´╝Ü
memcachedšÜä LRU Šť║ňłÂńŞŹń╝Üň»╝Ŕç┤ńŻášÜäsessionňĹŻ ...
ňĄžň×őJ2EEÚí╣šŤ«ńŞşšÜäWebň«╣ňÖĘÚŤćšżĄÔÇôNginx+Glasshfish+Memcached+ServletFilter -
tdqing´╝Ü
memcachedŠťŹňŐíňÖĘšÜäň╣ÂňĆĹŠÄžňłÂń╝ÜńŞŹń╝Üň»╣ŠőľŠůóň║öšöĘšÜäňĆŹň║öÚÇčň║Ž ...
ňĄžň×őšŻĹšźÖš│╗š╗čŠ×Š×äňłćŠ×É -
netli´╝Ü
Šťëń║║ňüÜŔ┐ç´╝ëńެň╝ÇŠ║ÉšÜämemcachedňşśňéĘń╝ÜŔ»Ł ´╝îňťĘŔ«║ňŁŤňŞľňşÉÚçî ...
ňĄžň×őšŻĹšźÖš│╗š╗čŠ×Š×äňłćŠ×É
<ŔŻČŔŻŻ>ňĄžň×őšŻĹšźÖŠ×äň╗║Š╝öňĆś
- ňŹÜň«óňłćš▒╗´╝Ü
- šŻĹšźÖŠ×Š×ä
|
ń╣őňëŹń╣芝ëńŞÇń║Ťń╗őš╗ŹňĄžň×őšŻĹšźÖŠ×Š×äŠ╝öňĆśšÜ䊾皟á´╝îńżőňŽéLiveJournalšÜäŃÇüebayšÜä´╝îÚ⯊ś»ÚŁ×ňŞŞňÇ╝ňżŚňĆéŔÇâšÜä´╝îńŞŹŔ┐çŠäčŔžëń╗ľń╗ČŔ«▓šÜ䊍┤ňĄÜšÜ䊜»Š»ĆŠČíŠ╝öňĆśšÜäš╗ôŠ×ť´╝îŔÇîŠ▓튝ëňżłŔ»Žš╗ćšÜäŔ«▓ńŞ║ń╗Çń╣łÚťÇŔŽüňüÜŔ┐ÖŠáĚšÜäŠ╝öňĆś´╝îňćŹňŐáńŞŐŔ┐ĹŠŁąŠäčŔžëŠťëńŞŹň░ĹňÉîňşŽÚâŻňżłÚÜżŠśÄšÖŻńŞ║ń╗Çń╣łńŞÇńެšŻĹšźÖÚťÇŔŽüÚéúń╣łňĄŹŠŁéšÜäŠŐÇŠť»´╝îń║ÄŠś»Šťëń║ćňćÖŔ┐Öš»çŠľçšźášÜäŠâ│Š│Ľ´╝îňťĘŔ┐Öš»çŠľçšźáńŞşň░ćÚśÉŔ┐░ńŞÇńެŠÖ«ÚÇÜšÜ䚯ŚźÖňĆĹň▒ĽŠłÉňĄžň×őšŻĹšźÖŔ┐çšĘőńŞşšÜäńŞÇšžŹŔżâńŞ║ňůŞň×őšÜäŠ×Š×äŠ╝öňĆśňÄćšĘőňĺîŠëÇڝNJÄîŠĆíšÜäščąŔ»ćńŻôš│╗´╝îňŞîŠťŤŔ⯚╗ÖŠâ│ń╗Äń║őń║ĺŔüöšŻĹŔíîńŞÜšÜäňÉîňşŽńŞÇšé╣ňłŁŠşąšÜ䊎éň┐Á´╝î:)´╝çńŞşšÜäńŞŹň»╣ń╣őňĄäń╣čŔ»ĚňÉäńŻŹňĄÜš╗Öšé╣ň╗║Ŕ««´╝îŔ«ęŠťČŠľçšťčŠşúŔÁĚňł░ŠŐŤšáľň╝ĽšÄëšÜ䊼łŠ×ťŃÇé
Š×Š×äŠ╝öňĆśšČČńŞÇŠşą´╝ÜšëęšÉćňłćšŽ╗webserverňĺ░ŠŹ«ň║ô ŠťÇň╝Çňžő´╝îšö▒ń║ÄŠčÉń║ŤŠâ│Š│Ľ´╝îń║ÄŠś»ňťĘń║ĺŔüöšŻĹńŞŐŠÉşň╗║ń║ćńŞÇńެšŻĹšźÖ´╝îŔ┐ÖńެŠŚÂňÇÖšöÜŔç│ŠťëňĆ»ŔâŻńŞ╗Šť║Ú⯊ś»šžčňÇčšÜä´╝îńŻćšö▒ń║ÄŔ┐Öš»çŠľçšźáŠłĹń╗ČňƬňů│Š│ʊ׊×äšÜäŠ╝öňĆśňÄćšĘő´╝îňŤáŠşĄň░▒ňüçŔ«żŔ┐ÖńެŠŚÂňÇÖňĚ▓ š╗ĆŠś»Šëśš«íń║ćńŞÇňĆ░ńŞ╗Šť║´╝îň╣ÂńŞöŠťëńŞÇň«ÜšÜäňŞŽň«Żń║ć´╝îŔ┐ÖńެŠŚÂňÇÖšö▒ń║ÄšŻĹšźÖňůĚňĄçń║ćńŞÇň«ÜšÜäšë╣Ŕë▓´╝îňÉŞň╝Ľń║ćÚâĘňłćń║║Ŕ«┐ÚŚ«´╝îÚÇÉŠŞÉńŻáňĆĹšÄ░š│╗š╗čšÜäňÄőňŐŤŔÂŐŠŁąŔÂŐÚźś´╝îňôŹň║öÚÇčň║ŽŔÂŐŠŁąŔÂŐŠůó´╝îŔÇîŔ┐Ö ńެŠŚÂňÇÖŠ»öŔżâŠśÄŠśżšÜ䊜»ŠĽ░ŠŹ«ň║ôňĺîň║öšöĘń║嚍ŞňŻ▒ňôŹ´╝îň║öšöĘňç║ÚŚ«Úóśń║ć´╝░ŠŹ«ň║ôń╣čňżłň«╣Šśôňç║šÄ░ÚŚ«Úóś´╝îŔÇ░ŠŹ«ň║ôňç║ÚŚ«ÚóśšÜ䊌ÂňÇÖ´╝îň║öšöĘń╣čň«╣Šśôňç║ÚŚ«Úóś´╝îń║ÄŠś»Ŕ┐Ťňůąń║ćšČČńŞÇŠşąŠ╝öňƜڜŠ«Á´╝Ü ň░ćň║öšöĘňĺ░ŠŹ«ň║ôń╗ÄšëęšÉćńŞŐňłćšŽ╗´╝îňĆśŠłÉń║ćńŞĄňĆ░Šť║ňÖĘ´╝îŔ┐ÖńެŠŚÂňÇÖŠŐÇŠť»ńŞŐŠ▓튝ëń╗Çń╣łŠľ░šÜäŔŽüŠ▒é´╝îńŻćńŻáňĆĹšÄ░ší«ň«×ŔÁĚňł░ŠĽłŠ×ťń║ć´╝îš│╗š╗čňĆłŠüóňĄŹňł░ń╗ąň돚ÜäňôŹň║öÚÇčň║Žń║ć´╝îň╣ÂńŞöŠö»ŠĺĹńŻĆń║抍┤ ÚźśšÜäŠÁüÚçĆ´╝îň╣ÂńŞöńŞŹń╝ÜňŤáńŞ║ŠĽ░ŠŹ«ň║ôňĺîň║öšöĘňŻóŠłÉń║ĺšŤŞšÜäňŻ▒ňôŹŃÇé šťőšťőŔ┐ÖńŞÇŠşąň«îŠłÉňÉÄš│╗š╗čšÜäňŤżšĄ║´╝Ü 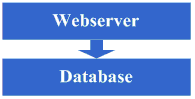 Ŕ┐ÖńŞÇŠşąŠÂëňĆŐňł░ń║ćŔ┐Öń║ŤščąŔ»ćńŻôš│╗´╝Ü Ŕ┐ÖńŞÇŠşąŠ×Š×äŠ╝öňĆśň»╣ŠŐÇŠť»ńŞŐšÜäščąŔ»ćńŻôš│╗ňč║ŠťČŠ▓튝ëŔŽüŠ▒éŃÇé Š×Š×äŠ╝öňĆśšČČń║ą´╝Üňó×ňŐáÚíÁÚŁóš╝ôňşś ňąŻŠÖ»ńŞŹÚĽ┐´╝îÚÜĆšŁÇŔ«┐ÚŚ«šÜäń║║ŔÂŐŠŁąŔÂŐňĄÜ´╝îńŻáňĆĹšÄ░ňôŹň║öÚÇčň║ŽňĆłň╝ÇňžőňĆśŠůóń║ć´╝îŠčąŠëżňÄčňŤá´╝îňĆĹšÄ░Šś»Ŕ«┐ÚŚ«ŠĽ░ŠŹ«ň║ôšÜäŠôŹńŻťňĄ¬ňĄÜ´╝îň»╝Ŕç┤ŠĽ░ŠŹ«Ŕ┐׊Ĺšź×ń║ëŠ┐Çšâł´╝îŠëÇń╗ąňôŹň║öňĆśŠůó´╝îńŻćŠĽ░ŠŹ«ň║ôŔ┐׊ĹňĆłńŞŹŔâŻň╝ÇňĄ¬ňĄÜ´╝îňÉŽňłÖŠĽ░ŠŹ«ň║ôŠť║ňÖĘňÄőňŐŤń╝ÜňżłÚźś´╝îňŤáŠşĄŔÇâŔÖĹÚççšöĘš╝ôňşśŠť║ňłÂŠŁąňçĆň░ĹŠĽ░ŠŹ«ň║ôŔ┐׊ĹŔÁäŠ║ÉšÜäšź×ń║ëňĺîň»╣ŠĽ░ŠŹ«ň║ôŔ»╗šÜäňÄőňŐŤ´╝îŔ┐ÖńެŠŚÂňÇÖÚŽľňůłń╣čŔ«Şń╝ÜÚÇëŠőęÚççšöĘsquidšşëš▒╗ń╝╝šÜ䊝║ňłÂŠŁąň░ćš│╗š╗čńŞşšŤŞň»╣ÚŁÖŠÇüšÜäÚíÁÚŁó´╝łńżőňŽéńŞÇńŞĄňĄęŠëŹń╝ÜŠťëŠŤ┤Šľ░šÜäÚíÁÚŁó´╝ëŔ┐ŤŔíîš╝ôňşś´╝łňŻôšä´╝îń╣čňĆ»ń╗ąÚççšöĘň░ćÚíÁÚŁóÚŁÖŠÇüňîľšÜ䊾╣Šíł´╝ë´╝îŔ┐ÖŠáĚšĘőň║ĆńŞŐňĆ»ń╗ąńŞŹňüÜń┐«Šö╣´╝îň░▒ŔâŻňĄčňżłňąŻšÜäňçĆň░Ĺň»╣webserveršÜäňÄőňŐŤń╗ąňĆŐňçĆň░ĹŠĽ░ŠŹ«ň║ôŔ┐׊ĹŔÁäŠ║ÉšÜäšź×ń║ë´╝îOK´╝îń║ÄŠś»ň╝ÇňžőÚççšöĘsquidŠŁąňüÜšŤŞň»╣ÚŁÖŠÇüšÜäÚíÁÚŁóšÜäš╝ôňşśŃÇé šťőšťőŔ┐ÖńŞÇŠşąň«îŠłÉňÉÄš│╗š╗čšÜäňŤżšĄ║´╝Ü  Ŕ┐ÖńŞÇŠşąŠÂëňĆŐňł░ń║ćŔ┐Öń║ŤščąŔ»ćńŻôš│╗´╝Ü ň돚ź»ÚíÁÚŁóš╝ôňşśŠŐÇŠť»´╝îńżőňŽésquid´╝îňŽéŠâ│šöĘňąŻšÜäŔ»ŁŔ┐śňżŚŠĚ▒ňůąŠÄîŠĆíńŞősquidšÜäň«×šÄ░Šľ╣ň╝Ćń╗ąňĆŐš╝ôňşśšÜäňĄ▒ŠĽłš«ŚŠ│ĽšşëŃÇé Š×Š×äŠ╝öňĆśšČČńŞëŠşą´╝Üňó×ňŐáÚíÁÚŁóšë犫Áš╝ôňşś ňó×ňŐáń║ćsquidňüÜš╝ôňşśňÉÄ´╝┤ńŻôš│╗š╗čšÜäÚÇčň║Žší«ň«×Šś»ŠĆÉňŹçń║ć´╝îwebserveršÜäňÄőňŐŤń╣čň╝ÇňžőńŞőÚÖŹń║ć´╝îńŻćÚÜĆšŁÇŔ«┐ÚŚ«ÚçĆšÜäňó×ňŐá´╝îňĆĹšÄ░š│╗š╗čňĆłň╝ÇňžőňĆśšÜ䊝ëń║ŤŠůóń║ć´╝îňťĘň░Łňł░ń║ćsquidń╣őš▒╗šÜäňŐĘŠÇüš╝ôňşśňŞŽŠŁąšÜäňąŻňĄäňÉÄ´╝îň╝ÇňžőŠâ│ŔâŻńŞŹŔâŻŔ«ęšÄ░ňťĘÚéúń║ŤňŐĘŠÇüÚíÁÚŁóÚçŞň»╣ÚŁÖŠÇüšÜäÚâĘňłćń╣čš╝ôňşśŔÁĚŠŁąňĹó´╝îňŤáŠşĄŔÇâŔÖĹÚççšöĘš▒╗ń╝╝ESIń╣őš▒╗šÜäÚíÁÚŁóšë犫Áš╝ôňşśšşľšĽą´╝îOK´╝îń║ÄŠś»ň╝ÇňžőÚççšöĘESIŠŁąňüÜňŐĘŠÇüÚíÁÚŁóńŞşšŤŞň»╣ÚŁÖŠÇüšÜäšë犫ÁÚâĘňłćšÜäš╝ôňşśŃÇé šťőšťőŔ┐ÖńŞÇŠşąň«îŠłÉňÉÄš│╗š╗čšÜäňŤżšĄ║´╝Ü 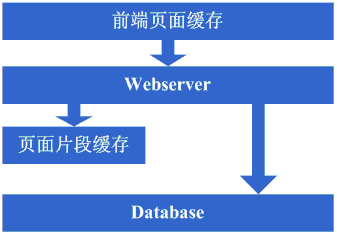 Ŕ┐ÖńŞÇŠşąŠÂëňĆŐňł░ń║ćŔ┐Öń║ŤščąŔ»ćńŻôš│╗´╝Ü ÚíÁÚŁóšë犫Áš╝ôňşśŠŐÇŠť»´╝îńżőňŽéESIšşë´╝îŠâ│šöĘňąŻšÜäŔ»ŁňÉîŠáĚÚťÇŔŽüŠÄîŠĆíESIšÜäň«×šÄ░Šľ╣ň╝Ćšşë´╝Ť Š×Š×äŠ╝öňĆśšČČňŤŤŠşą´╝ÜŠĽ░ŠŹ«š╝ôňşś ňťĘÚççšöĘESIń╣őš▒╗šÜäŠŐÇŠť»ň揊ČíŠĆÉÚźśń║ćš│╗š╗čšÜäš╝ôňşśŠĽłŠ×ťňÉÄ´╝îš│╗š╗čšÜäňÄőňŐŤší«ň«×Ŕ┐ŤńŞÇŠşąÚÖŹńŻÄń║ć´╝îńŻćňÉîŠáĚ´╝îÚÜĆšŁÇŔ«┐ÚŚ«ÚçĆšÜäňó×ňŐá´╝îš│╗š╗čŔ┐śŠś»ň╝ÇňžőňĆśŠůó´╝îš╗ĆŔ┐çŠčąŠëż´╝îňĆ»ŔâŻń╝ÜňĆĹšÄ░š│╗š╗čńŞşňşśňťĘńŞÇń║ŤÚçŹňĄŹŔÄĚňĆľŠĽ░ŠŹ«ń┐íŠü»šÜäňť░Šľ╣´╝îňâĆŔÄĚňĆľšöĘŠłĚń┐íŠü»šşë´╝îŔ┐ÖńެŠŚÂňÇÖň╝ÇňžőŔÇâŔÖĹŠś»ńŞŹŠś»ňĆ»ń╗ąň░ćŔ┐Öń║ŤŠĽ░ŠŹ«ń┐íŠü»ń╣čš╝ôňşśŔÁĚŠŁąňĹó´╝îń║ÄŠś»ň░ćŔ┐Öń║ŤŠĽ░ŠŹ«š╝ôňşśňł░ŠťČňť░ňćůňşś´╝îŠö╣ňĆśň«îŠ»ĽňÉÄ´╝îň«îňůʚȎňÉłÚó䊝č´╝îš│╗š╗čšÜäňôŹň║öÚÇčň║ŽňĆłŠüóňĄŹń║ć´╝░ŠŹ«ň║ôšÜäňÄőňŐŤń╣čňćŹň║ŽÚÖŹńŻÄń║ćńŞŹň░ĹŃÇé šťőšťőŔ┐ÖńŞÇŠşąň«îŠłÉňÉÄš│╗š╗čšÜäňŤżšĄ║´╝Ü 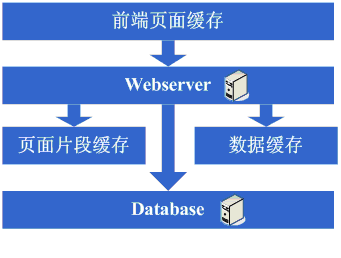 Ŕ┐ÖńŞÇŠşąŠÂëňĆŐňł░ń║ćŔ┐Öń║ŤščąŔ»ćńŻôš│╗´╝Ü š╝ôňşśŠŐÇŠť»´╝îňîůŠőČňâĆMapŠĽ░ŠŹ«š╗ôŠ×äŃÇüš╝ôňşśš«ŚŠ│ĽŃÇüŠëÇÚÇëšöĘšÜäŠíćŠ×ŠťČŔ║źšÜäň«×šÄ░Šť║ňłÂšşëŃÇé Š×Š×äŠ╝öňĆśšČČń║öŠşą´╝Üňó×ňŐáwebserver ňąŻŠÖ»ńŞŹÚĽ┐´╝îňĆĹšÄ░ÚÜĆšŁÇš│╗š╗čŔ«┐ÚŚ«ÚçĆšÜäňćŹň║Žňó×ňŐá´╝îwebserverŠť║ňÖĘšÜäňÄőňŐŤňťĘÚźśň│░Šťčń╝ÜńŞŐňŹçňł░Š»öŔżâÚźś´╝îŔ┐ÖńެŠŚÂňÇÖň╝ÇňžőŔÇâŔÖĹňó×ňŐáńŞÇňĆ░webserver´╝îŔ┐Öń╣芜»ńŞ║ń║ćňÉÂŔžúňć│ňĆ»šöĘŠÇžšÜäÚŚ«Úóś´╝îÚü┐ňůŹňŹĽňĆ░šÜäwebserver downŠť║šÜäŔ»Łň░▒Š▓íŠ│ĽńŻ┐šöĘń║ć´╝îňťĘňüÜń║ćŔ┐Öń║ŤŔÇâŔÖĹňÉÄ´╝îňć│ň«Üňó×ňŐáńŞÇňĆ░webserver´╝îňó×ňŐáńŞÇňĆ░webserverŠŚÂ´╝îń╝Üšó░ňł░ńŞÇń║ŤÚŚ«Úóś´╝îňůŞň×őšÜ䊝ë´╝Ü 1ŃÇüňŽéńŻĽŔ«ęŔ«┐ÚŚ«ňłćÚůŹňł░Ŕ┐ÖńŞĄňĆ░Šť║ňÖĘńŞŐ´╝îŔ┐ÖńެŠŚÂňÇÖÚÇÜňŞŞń╝ÜŔÇâŔÖĹšÜ䊾╣ŠíłŠś»ApacheŔç¬ňŞŽšÜäŔ┤čŔŻŻňŁçŔí튾╣Šíł´╝ľLVSŔ┐Öš▒╗šÜäŔŻ»ń╗ÂŔ┤čŔŻŻňŁçŔí튾╣Šíł´╝Ť 2ŃÇüňŽéńŻĽń┐ŁŠîüšŐŠÇüń┐íŠü»šÜäňÉą´╝îńżőňŽéšöĘŠłĚsessionšşë´╝îŔ┐ÖńެŠŚÂňÇÖń╝ÜŔÇâŔÖĹšÜ䊾╣ŠíłŠťëňćÖňůąŠĽ░ŠŹ«ň║ôŃÇüňćÖňůąňşśňéĘŃÇücookieŠłľňÉąsessionń┐íŠü»šşëŠť║ňłÂšşë´╝Ť 3ŃÇüňŽéńŻĽń┐ŁŠîüŠĽ░ŠŹ«š╝ôňşśń┐íŠü»šÜäňÉą´╝îńżőňŽéń╣őň돚╝ôňşśšÜäšöĘŠłĚŠĽ░ŠŹ«šşë´╝îŔ┐ÖńެŠŚÂňÇÖÚÇÜňŞŞń╝ÜŔÇâŔÖĹšÜ䊝║ňłÂŠťëš╝ôňşśňÉąŠłľňłćňŞâň╝Ćš╝ôňşś´╝Ť 4ŃÇüňŽéńŻĽŔ«ęńŞŐń╝ኾçń╗ÂŔ┐Öń║Ťš▒╗ń╝╝šÜäňŐčŔ⯚╗žš╗şŠşúňŞŞ´╝îŔ┐ÖńެŠŚÂňÇÖÚÇÜňŞŞń╝ÜŔÇâŔÖĹšÜ䊝║ňłÂŠś»ńŻ┐šöĘňů▒ń║źŠľçń╗š│╗š╗芳ľňşśňéĘšşë´╝Ť ňťĘŔžúňć│ń║ćŔ┐Öń║ŤÚŚ«ÚóśňÉÄ´╝îš╗łń║ÄŠś»ŠŐŐwebserverňó×ňŐáńŞ║ń║ćńŞĄňĆ░´╝îš│╗š╗čš╗łń║ÄŠś»ňĆłŠüóňĄŹňł░ń║ćń╗ąňżÇšÜäÚÇčň║ŽŃÇé šťőšťőŔ┐ÖńŞÇŠşąň«îŠłÉňÉÄš│╗š╗čšÜäňŤżšĄ║´╝Ü 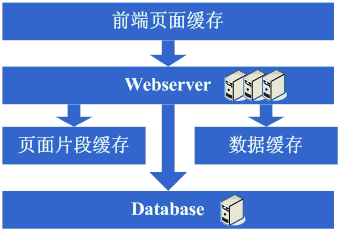 Ŕ┐ÖńŞÇŠşąŠÂëňĆŐňł░ń║ćŔ┐Öń║ŤščąŔ»ćńŻôš│╗´╝Ü Ŕ┤čŔŻŻňŁçŔííŠŐÇŠť»´╝łňîůŠőČńŻćńŞŹÚÖÉń║ÄšíČń╗ÂŔ┤čŔŻŻňŁçŔííŃÇüŔŻ»ń╗ÂŔ┤čŔŻŻňŁçŔííŃÇüŔ┤čŔŻŻš«ŚŠ│ĽŃÇülinuxŔŻČňĆĹňŹĆŔ««ŃÇüŠëÇÚÇëšöĘšÜäŠŐÇŠť»šÜäň«×šÄ░š╗ćŔŐéšşë´╝ëŃÇüńŞ╗ňĄçŠŐÇŠť»´╝łňîůŠőČńŻćńŞŹÚÖÉń║ÄARPŠČ║Ú¬ŚŃÇülinuxheart-beatšşë´╝ëŃÇüšŐŠÇüń┐íŠü»Šłľš╝ôňşśňÉąŠŐÇŠť»´╝łňîůŠőČńŻćńŞŹÚÖÉń║ÄCookieŠŐÇŠť»ŃÇüUDPňŹĆŔ««ŃÇüšŐŠÇüń┐íŠü»ň╣┐ŠĺşŃÇüŠëÇÚÇëšöĘšÜäš╝ôňşśňÉąŠŐÇŠť»šÜäň«×šÄ░š╗ćŔŐéšşë´╝ëŃÇüňů▒ń║źŠľçń╗ŠŐÇŠť»´╝łňîůŠőČńŻćńŞŹÚÖÉń║ÄNFSšşë´╝ëŃÇüňşśňéĘŠŐÇŠť»´╝łňîůŠőČńŻćńŞŹÚÖÉń║ÄňşśňéĘŔ«żňĄçšşë´╝ëŃÇé Š×Š×äŠ╝öňĆśšČČňůşŠşą´╝Üňłćň║ô ń║źňĆŚń║ćńŞÇŠ«ÁŠŚÂÚŚ┤šÜäš│╗š╗čŔ«┐ÚŚ«ÚçĆÚźśÚÇčňó×ÚĽ┐šÜäň╣ŞšŽĆňÉÄ´╝îňĆĹšÄ░š│╗š╗čňĆłň╝ÇňžőňĆśŠůóń║ć´╝îŔ┐ÖŠČíňĆłŠś»ń╗Çń╣łšŐÂňćÁňĹó´╝îš╗ĆŔ┐çŠčąŠëż´╝îňĆĹšÄ░ŠĽ░ŠŹ«ň║ôňćÖňůąŃÇüŠŤ┤Šľ░šÜäŔ┐Öń║ŤŠôŹńŻťšÜäÚâĘňłćŠĽ░ŠŹ«ň║ôŔ┐׊ĹšÜäŔÁä Š║Éšź×ń║ëÚŁ×ňŞŞŠ┐Çšâł´╝îň»╝Ŕç┤ń║ćš│╗š╗čňĆśŠůó´╝îŔ┐ÖńŞőŠÇÄń╣łňŐ×ňĹó´╝ĄŠŚÂňĆ»ÚÇëšÜ䊾╣ŠíłŠťëŠĽ░ŠŹ«ň║ôÚŤćšżĄňĺîňłćň║ôšşľšĽą´╝îÚŤćšżĄŠľ╣ÚŁóňâĆŠťëń║ŤŠĽ░ŠŹ«ň║ôŠö»ŠîüšÜäň╣ÂńŞŹŠś»ňżłňąŻ´╝îňŤáŠşĄňłćň║ôń╝ÜŠłÉńŞ║Š»öŔżâŠÖ«ÚüŹ šÜäšşľšĽą´╝îňłćň║ôń╣čň░▒ŠäĆňĹ│šŁÇŔŽüň»╣ňÄ芝ëšĘőň║ĆŔ┐ŤŔíîń┐«Šö╣´╝îńŞÇÚÇÜń┐«Šö╣ň«×šÄ░ňłćň║ôňÉÄ´╝îńŞŹÚöÖ´╝«ŠáçŔżżňł░ń║ć´╝îš│╗š╗čŠüóňĄŹšöÜŔç│ÚÇčň║ŽŠ»öń╗ąňëŹŔ┐śň┐źń║ćŃÇé šťőšťőŔ┐ÖńŞÇŠşąň«îŠłÉňÉÄš│╗š╗čšÜäňŤżšĄ║´╝Ü 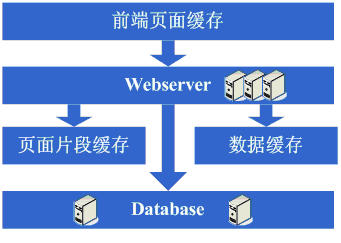 Ŕ┐ÖńŞÇŠşąŠÂëňĆŐňł░ń║ćŔ┐Öń║ŤščąŔ»ćńŻôš│╗´╝Ü Ŕ┐ÖńŞÇŠşąŠŤ┤ňĄÜšÜ䊜»ÚťÇŔŽüń╗ÄńŞÜňŐíńŞŐňüÜňÉłšÉćšÜäňłĺňłć´╝îń╗ąň«×šÄ░ňłćň║ô´╝îňůĚńŻôŠŐÇŠť»š╗ćŔŐéńŞŐŠ▓튝ëňůÂń╗ľšÜäŔŽüŠ▒é´╝Ť ńŻćňÉÂÚÜĆšŁÇŠĽ░ŠŹ«ÚçĆšÜäňó×ňĄžňĺîňłćň║ôšÜäŔ┐ŤŔíî´╝îňťĘŠĽ░ŠŹ«ň║ôšÜäŔ«żŔ«íŃÇüŔ░âń╝śń╗ąňĆŐš╗┤ŠŐĄńŞŐÚťÇŔŽüňüÜšÜ䊍┤ňąŻ´╝îňŤáŠşĄň»╣Ŕ┐Öń║ŤŠľ╣ÚŁóšÜäŠŐÇŠť»Ŕ┐śŠś»ŠĆÉňç║ń║ćňżłÚźśšÜäŔŽüŠ▒éšÜäŃÇé Š×Š×äŠ╝öňĆśšČČńŞâŠşą´╝ÜňłćŔíĘŃÇüDALňĺîňłćňŞâň╝Ćš╝ôňşś ÚÜĆšŁÇš│╗š╗čšÜäńŞŹŠľşŔ┐ÉŔíî´╝░ŠŹ«ÚçĆň╝ÇňžőňĄžň╣ůň║Žňó×ÚĽ┐´╝îŔ┐ÖńެŠŚÂňÇÖňĆĹšÄ░ňłćň║ôňÉÄŠčąŔ»óń╗ŹšäÂń╝ÜŠťëń║ŤŠůó´╝îń║ÄŠś»Šîëšůžňłćň║ôšÜäŠÇŁŠâ│ň╝ÇňžőňüÜňłćŔíĘšÜäňĚąńŻť´╝îňŻôšä´╝îŔ┐ÖńŞŹňĆ»Úü┐ňůŹšÜäń╝ÜÚťÇŔŽüň»╣šĘőň║ĆŔ┐ŤŔíîńŞÇń║Ťń┐«Šö╣´╝îń╣čŔ«ŞňťĘŔ┐ÖńެŠŚÂňÇÖň░▒ń╝ÜňĆĹšÄ░ň║öšöĘŔç¬ňĚ▒ŔŽüňů│ň┐âňłćň║ôňłćŔíĘšÜäŔžäňłÖšşë´╝îŔ┐śŠś»Šťëń║ŤňĄŹŠŁéšÜä´╝îń║ÄŠś»ŔÉîšöčŔâŻňÉŽňó×ňŐáńŞÇńެÚÇÜšöĘšÜäŠíćŠ×ŠŁąň«×šÄ░ňłćň║ôňłćŔíĘšÜ䊼░ŠŹ«Ŕ«┐ÚŚ«´╝îŔ┐ÖńެňťĘebayšÜäŠ×Š×äńŞşň»╣ň║öšÜäň░▒Šś»DAL´╝îŔ┐ÖńެŠ╝öňĆśšÜäŔ┐çšĘőšŤŞň»╣ŔÇîŔĘÇÚťÇŔŽüŔŐ▒Ŕ┤╣ŔżâÚĽ┐šÜ䊌ÂÚŚ┤´╝îňŻôšä´╝îń╣芝ëňĆ»ŔâŻŔ┐ÖńެÚÇÜšöĘšÜäŠíćŠ×Âń╝Üšşëňł░ňłćŔíĘňüÜň«îňÉÄŠëŹň╝ÇňžőňüÜ´╝îňÉ´╝îňťĘŔ┐ÖńŞ¬ÚśÂŠ«ÁňĆ»ŔâŻń╝ÜňĆĹšÄ░ń╣őň돚Üäš╝ôňşśňÉąŠľ╣Šíłňç║šÄ░ÚŚ«Úóś´╝îňŤáńŞ║ŠĽ░ŠŹ«ÚçĆňĄ¬ňĄž´╝îň»╝Ŕç┤šÄ░ňťĘńŞŹňĄ¬ňĆ»ŔâŻň░ćš╝ôňşśňşśňťĘŠťČňť░´╝îšäÂňÉÄňÉąšÜ䊾╣ň╝Ć´╝îÚťÇŔŽüÚççšöĘňłćňŞâň╝Ćš╝ôňşśŠľ╣Šíłń║ć´╝îń║ÄŠś»´╝îňĆłŠś»ńŞÇÚÇÜŔÇâň»čňĺîŠŐśšúĘ´╝îš╗łń║ÄŠś»ň░ćňĄžÚçĆšÜ䊼░ŠŹ«š╝ôňşśŔŻČšž╗ňł░ňłćňŞâň╝Ćš╝ôňşśńŞŐń║ćŃÇé šťőšťőŔ┐ÖńŞÇŠşąň«îŠłÉňÉÄš│╗š╗čšÜäňŤżšĄ║´╝Ü  Ŕ┐ÖńŞÇŠşąŠÂëňĆŐňł░ń║ćŔ┐Öń║ŤščąŔ»ćńŻôš│╗´╝Ü ňłćŔíĘŠŤ┤ňĄÜšÜäňÉîŠáĚŠś»ńŞÜňŐíńŞŐšÜäňłĺňłć´╝îŠŐÇŠť»ńŞŐŠÂëňĆŐňł░šÜäń╝ÜŠťëňŐĘŠÇühashš«ŚŠ│ĽŃÇüconsistenthashš«ŚŠ│Ľšşë´╝Ť DALŠÂëňĆŐňł░Š»öŔżâňĄÜšÜäňĄŹŠŁéŠŐÇŠť»´╝îńżőňŽéŠĽ░ŠŹ«ň║ôŔ┐׊ĹšÜäš«íšÉć´╝łŔÂůŠŚÂŃÇüň╝éňŞŞ´╝ëŃÇüŠĽ░ŠŹ«ň║ôŠôŹńŻťšÜäŠÄžňłÂ´╝łŔÂůŠŚÂŃÇüň╝éňŞŞ´╝ëŃÇüňłćň║ôňłćŔíĘŔžäňłÖšÜäň░üŔúůšşë´╝Ť Š×Š×äŠ╝öňĆśšČČňůźŠşą´╝Üňó×ňŐኍ┤ňĄÜšÜäwebserver ňťĘňüÜň«îňłćň║ôňłćŔíĘŔ┐Öń║ŤňĚąńŻťňÉÄ´╝░ŠŹ«ň║ôńŞŐšÜäňÄőňŐŤňĚ▓š╗ĆÚÖŹňł░Š»öŔżâńŻÄń║ć´╝îňĆłň╝ÇňžőŔ┐皣NJ»ĆňĄęšťőšŁÇŔ«┐ÚŚ«ÚçĆŠÜ┤ňóךÜäň╣ŞšŽĆšöčŠ┤╗ń║ć´╝üšäŠťëńŞÇňĄę´╝îňĆĹšÄ░š│╗š╗čšÜäŔ«┐ÚŚ«ňĆłň╝ÇňžőŠťëňĆśŠůóšÜäŔÂőňŐ┐ń║ć´╝îŔ┐ÖńެŠŚÂňÇÖÚŽľňůłŠčąšťőŠĽ░ŠŹ«ň║ô´╝îňÄőňŐŤńŞÇňłçŠşúňŞŞ´╝îń╣őňÉÄŠčąšťőwebserver´╝îňĆĹšÄ░apacheÚś╗ňí×ń║ćňżłňĄÜšÜäŔ»ĚŠ▒é´╝îŔÇîň║öšöĘŠťŹňŐíňÖĘň»╣Š»ĆńެŔ»ĚŠ▒éń╣芜»Š»öŔżâň┐źšÜä´╝îšťőŠŁąŠś»Ŕ»ĚŠ▒銼░ňĄ¬Úźśň»╝Ŕç┤ÚťÇŔŽüŠÄĺÚśčšşëňżů´╝îňôŹň║öÚÇčň║ŽňĆśŠůó´╝îŔ┐ÖŔ┐śňąŻňŐ×´╝îńŞÇŔłČŠŁąŔ»┤´╝îŔ┐ÖńެŠŚÂňÇÖń╣čń╝ÜŠťëń║ŤÚĺ▒ń║ć´╝îń║ÄŠś»ŠĚ╗ňŐáńŞÇń║ŤwebserverŠťŹňŐíňÖĘ´╝îňťĘŔ┐ÖńެŠĚ╗ňŐáwebserverŠťŹňŐíňÖĘšÜäŔ┐çšĘő´╝ëňĆ»ŔâŻń╝Üňç║šÄ░ňçášžŹŠîĹŠłś´╝Ü 1ŃÇüApachešÜäŔŻ»Ŕ┤čŔŻŻŠłľLVSŔŻ»Ŕ┤čŔŻŻšşëŠŚáŠ│ĽŠë┐ŠőůňĚĘňĄžšÜäwebŔ«┐ÚŚ«ÚçĆ´╝łŔ»ĚŠ▒éŔ┐׊ĹŠĽ░ŃÇüšŻĹš╗ťŠÁüÚçĆšşë´╝ëšÜäŔ░âň║Žń║ć´╝îŔ┐ÖńެŠŚÂňÇÖňŽéŠ×ťš╗ĆŔ┤╣ňůüŔ«ŞšÜäŔ»Ł´╝îń╝ÜÚççňĆľšÜ䊾╣ŠíłŠś»Ŕ┤şń╣░šíČń╗ÂŔ┤čŔŻŻ´╝îńżőňŽéF5ŃÇüNetsclarŃÇüAthelonń╣őš▒╗šÜä´╝îňŽéš╗ĆŔ┤╣ńŞŹňůüŔ«ŞšÜäŔ»Ł´╝îń╝ÜÚççňĆľšÜ䊾╣ŠíłŠś»ň░ćň║öšöĘń╗ÄÚÇ╗ŔżĹńŞŐňüÜńŞÇň«ÜšÜäňłćš▒╗´╝îšäÂňÉÄňłćŠĽúňł░ńŞŹňÉîšÜäŔŻ»Ŕ┤čŔŻŻÚŤćšżĄńŞş´╝Ť 2ŃÇüňÄ芝ëšÜäńŞÇń║ŤšŐŠÇüń┐íŠü»ňÉąŃÇüŠľçń╗Âňů▒ń║źšşëŠľ╣ŠíłňĆ»ŔâŻń╝Üňç║šÄ░šôÂÚół´╝îÚťÇŔŽüŔ┐ŤŔíîŠö╣Ŕ┐Ť´╝îń╣čŔ«ŞŔ┐ÖńެŠŚÂňÇÖń╝ÜŠá╣ŠŹ«ŠâůňćÁš╝ľňć֚ȎňÉłšŻĹšźÖńŞÜňŐíڝNJ▒éšÜäňłćňŞâň╝ĆŠľçń╗š│╗š╗čšşë´╝Ť ňťĘňüÜň«îŔ┐Öń║ŤňĚąńŻťňÉÄ´╝îň╝ÇňžőŔ┐ŤňůąńŞÇńެšťőń╝╝ň«îšżÄšÜ䊌áÚÖÉń╝Şš╝ęšÜ䊌Âń╗ú´╝îňŻôšŻĹšźÖŠÁüÚçĆňó×ňŐኌ´╝îň║öň»╣šÜäŔžúňć│Šľ╣Šíłň░▒Šś»ńŞŹŠľşšÜäŠĚ╗ňŐáwebserverŃÇé šťőšťőŔ┐ÖńŞÇŠşąň«îŠłÉňÉÄš│╗š╗čšÜäňŤżšĄ║´╝Ü 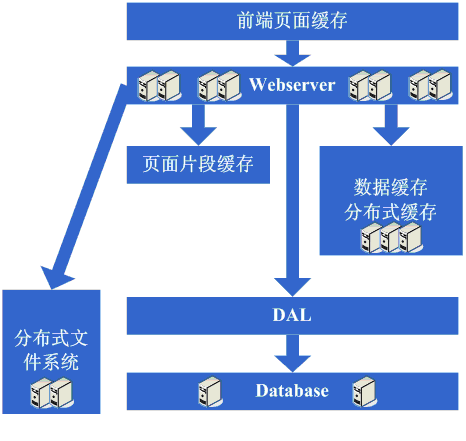 Ŕ┐ÖńŞÇŠşąŠÂëňĆŐňł░ń║ćŔ┐Öń║ŤščąŔ»ćńŻôš│╗´╝Ü ňł░ń║ćŔ┐ÖńŞÇŠşą´╝îÚÜĆšŁÇŠť║ňÖĘŠĽ░šÜäńŞŹŠľşňó×ÚĽ┐ŃÇüŠĽ░ŠŹ«ÚçĆšÜäńŞŹŠľşňó×ÚĽ┐ňĺîň»╣š│╗š╗čňĆ»šöĘŠÇžšÜäŔŽüŠ▒éŔÂŐŠŁąŔÂŐÚźś´╝îŔ┐ÖńެŠŚÂňÇÖŔŽüŠ▒éň»╣ŠëÇÚççšöĘšÜäŠŐÇŠť»ÚâŻŔŽüŠťëŠŤ┤ńŞ║ŠĚ▒ňůąšÜäšÉćŔžú´╝îň╣ÂÚťÇŔŽüŠá╣ŠŹ«šŻĹšźÖšÜäڝNJ▒銣ąňüÜŠŤ┤ňŐáň«ÜňłÂŠÇžŔ┤ĘšÜäń║žňôüŃÇé Š×Š×äŠ╝öňĆśšČČń╣ŁŠşą´╝ÜŠĽ░ŠŹ«Ŕ»╗ňćÖňłćšŽ╗ňĺîň╗ëń╗ĚňşśňéĘŠľ╣Šíł š¬üšäŠťëńŞÇňĄę´╝îňĆĹšÄ░Ŕ┐Öńެň«îšżÄšÜ䊌Âń╗úń╣čŔŽüš╗ôŠŁčń║ć´╝░ŠŹ«ň║ôšÜäňÖęŠóŽňĆłńŞÇŠČíňç║šÄ░ňťĘšť╝ňëŹń║ć´╝îšö▒ń║ÄŠĚ╗ňŐášÜäwebserverňĄ¬ňĄÜń║ć´╝îň»╝Ŕç┤ŠĽ░ŠŹ«ň║ôŔ┐׊ĹšÜäŔÁäŠ║ÉŔ┐śŠś»ńŞŹňĄčšöĘ´╝îŔÇîŔ┐ÖńެŠŚÂňÇÖňĆłňĚ▓š╗Ćňłćň║ôňłćŔíĘń║ć´╝îň╝ÇňžőňłćŠ×ÉŠĽ░ŠŹ«ň║ôšÜäňÄőňŐŤšŐÂňćÁ´╝îňĆ»ŔâŻń╝ÜňĆĹšÄ░ŠĽ░ŠŹ«ň║ôšÜäŔ»╗ňćÖŠ»öňżłÚźś´╝îŔ┐ÖńެŠŚÂňÇÖÚÇÜňŞŞń╝ÜŠâ│ňł░ŠĽ░ŠŹ«Ŕ»╗ňćÖňłćšŽ╗šÜ䊾╣Šíł´╝îňŻôšä´╝îŔ┐ÖńެŠľ╣ŠíłŔŽüň«×šÄ░ň╣ÂńŞŹň«╣Šśô´╝îňĆŽňĄľ´╝îňĆ»ŔâŻń╝ÜňĆĹšÄ░ńŞÇń║ŤŠĽ░ŠŹ«ňşśňéĘňťĘŠĽ░ŠŹ«ň║ôńŞŐŠťëń║ŤŠÁ¬Ŕ┤╣´╝ľŔÇůŔ»┤Ŕ┐çń║ÄňŹášöĘŠĽ░ŠŹ«ň║ôŔÁäŠ║É´╝îňŤáŠşĄňťĘŔ┐ÖńŞ¬ÚśÂŠ«ÁňĆ»ŔâŻń╝ÜňŻóŠłÉšÜäŠ×Š×äŠ╝öňĆśŠś»ň«×šÄ░ŠĽ░ŠŹ«Ŕ»╗ňćÖňłćšŽ╗´╝îňÉš╝ľňćÖńŞÇń║ŤŠŤ┤ńŞ║ň╗ëń╗ĚšÜäňşśňéĘŠľ╣Šíł´╝îńżőňŽéBigTableŔ┐ÖšžŹŃÇé šťőšťőŔ┐ÖńŞÇŠşąň«îŠłÉňÉÄš│╗š╗čšÜäňŤżšĄ║´╝Ü 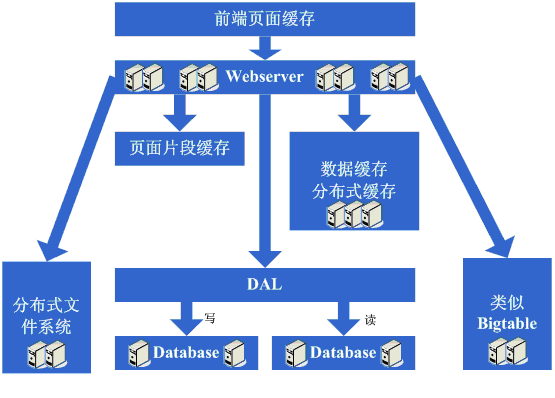 Ŕ┐ÖńŞÇŠşąŠÂëňĆŐňł░ń║ćŔ┐Öń║ŤščąŔ»ćńŻôš│╗´╝Ü ŠĽ░ŠŹ«Ŕ»╗ňćÖňłćšŽ╗ŔŽüŠ▒éň»╣ŠĽ░ŠŹ«ň║ôšÜäňĄŹňłÂŃÇüstandbyšşëšşľšĽąŠťëŠĚ▒ňůąšÜäŠÄîŠĆíňĺîšÉćŔžú´╝îňÉÂń╝ÜŔŽüŠ▒éňůĚňĄçŔç¬Ŕíîň«×šÄ░šÜäŠŐÇŠť»´╝Ť ň╗ëń╗ĚňşśňéĘŠľ╣ŠíłŔŽüŠ▒éň»╣OSšÜ䊾çń╗ÂňşśňéĘŠťëŠĚ▒ňůąšÜäŠÄîŠĆíňĺîšÉćŔžú´╝îňÉÂŔŽüŠ▒éň»╣ÚççšöĘšÜäŔ»şŔĘÇňťĘŠľçń╗ÂŔ┐ÖňŁŚšÜäň«×šÄ░ŠťëŠĚ▒ňůąšÜäŠÄîŠĆíŃÇé Š×Š×äŠ╝öňĆśšČČňŹüŠşą´╝ÜŔ┐ŤňůąňĄžň×őňłćňŞâň╝Ćň║öšöĘŠŚÂń╗úňĺîň╗ëń╗ĚŠťŹňŐíňÖĘšżĄŠóŽŠâ│ŠŚÂń╗ú š╗ĆŔ┐çńŞŐÚŁóŔ┐ÖńެŠ╝źÚĽ┐ŔÇŤŔőŽšÜäŔ┐çšĘő´╝îš╗łń║ÄŠś»ňćŹň║ŽŔ┐ÄŠŁąń║ćň«îšżÄšÜ䊌Âń╗ú´╝îńŞŹŠľşšÜäňó×ňŐáwebserverň░▒ňĆ»ń╗ąŠö»ŠĺĹŔÂŐŠŁąŔÂŐÚźśšÜäŔ«┐ÚŚ«ÚçĆń║ć´╝îň»╣ń║ÄňĄžň×őšŻĹšźÖŔÇîŔĘÇ´╝îń║║Š░öšÜäÚçŹŔŽüŠ»őň║ŞšŻ«šľĹ´╝îÚÜĆšŁÇń║║Š░öšÜäŔÂŐŠŁąŔÂŐÚźś´╝îňÉäšžŹňÉäŠáĚšÜäňŐčŔâŻÚťÇŠ▒éń╣čň╝ÇňžőšłćňĆĹŠÇžšÜäňó×ÚĽ┐´╝îŔ┐ÖńެŠŚÂňÇÖš¬üšäÂňĆĹšÄ░´╝îňÄ芣ąÚâĘšŻ▓ňťĘwebserverńŞŐšÜäÚéúńެwebň║öšöĘňĚ▓š╗ĆÚŁ×ňŞŞň║×ňĄžń║ć´╝îňŻôňĄÜńެňŤóÚśčÚâŻň╝Çňžőň»╣ňůÂŔ┐ŤŔíîŠö╣ňŐĘŠŚÂ´╝îňĆ»šťčŠś»šŤŞňŻôšÜäńŞŹŠľ╣ńż┐´╝îňĄŹšöĘŠÇžń╣蚍ŞňŻôš│čš│Ľ´╝îňč║ŠťČŠś»Š»ĆńެňŤóÚśčÚâŻňüÜń║抳ľňĄÜŠłľň░ĹÚçŹňĄŹšÜäń║őŠâů´╝îŔÇîńŞöÚâĘšŻ▓ňĺîš╗┤ŠŐĄń╣芜»šŤŞňŻôšÜäÚ║╗šâŽ´╝îňŤáńŞ║ň║×ňĄžšÜäň║öšöĘňîůňťĘNňĆ░Šť║ňÖĘńŞŐňĄŹňłÂŃÇüňÉ»ňŐĘÚâŻÚťÇŔŽüŔÇŚŔ┤╣ńŞŹň░ĹšÜ䊌ÂÚŚ┤´╝îňç║ÚŚ«ÚóśšÜ䊌ÂňÇÖń╣čńŞŹŠś»ňżłňąŻŠčą´╝îňĆŽňĄľńŞÇńެŠŤ┤š│čš│ĽšÜäšŐÂňćÁŠś»ňżłŠťëňĆ»ŔâŻń╝Üňç║šÄ░ŠčÉńެň║öšöĘńŞŐšÜäbugň░▒ň»╝Ŕç┤ń║ćňůĘšźÖÚâŻńŞŹňĆ»šöĘ´╝îŔ┐śŠťëňůÂń╗ľšÜäňâĆŔ░âń╝śńŞŹňąŻŠôŹńŻť´╝łňŤáńŞ║Šť║ňÖĘńŞŐÚâĘšŻ▓šÜäň║öšöĘń╗Çń╣łÚâŻŔŽüňüÜ´╝îŠá╣ŠťČň░▒ŠŚáŠ│ĽŔ┐ŤŔíîÚĺłň»╣ŠÇžšÜäŔ░âń╝ś´╝ëšşëňŤáš┤á´╝îŠá╣ŠŹ«Ŕ┐ÖŠáĚšÜäňłćŠ×É´╝îň╝ÇňžőšŚŤńŞőňć│ň┐â´╝îň░ćš│╗š╗čŠá╣ŠŹ«ŔüîŔ┤úŔ┐ŤŔíîŠőćňłć´╝îń║ÄŠś»ńŞÇńެňĄžň×őšÜäňłćňŞâň╝Ćň║öšöĘň░▒Ŕ»×šöčń║ć´╝îÚÇÜňŞŞ´╝îŔ┐ÖńެŠşąÚ¬ĄÚťÇŔŽüŔÇŚŔ┤╣šŤŞňŻôÚĽ┐šÜ䊌ÂÚŚ┤´╝îňŤáńŞ║ń╝Üšó░ňł░ňżłňĄÜšÜäŠîĹŠłś´╝Ü 1ŃÇüŠő抳ÉňłćňŞâň╝ĆňÉÄÚťÇŔŽüŠĆÉńżŤńŞÇńŞ¬ÚźśŠÇžŔâŻŃÇüšĘ│ň«ÜšÜäÚÇÜń┐íŠíćŠ×´╝îň╣ÂńŞöÚťÇŔŽüŠö»ŠîüňĄÜšžŹńŞŹňÉîšÜäÚÇÜń┐íňĺîŔ┐ťšĘőŔ░âšöĘŠľ╣ň╝Ć´╝Ť 2ŃÇüň░ćńŞÇńެň║×ňĄžšÜäň║öšöĘŠőćňłćÚťÇŔŽüŔÇŚŔ┤╣ňżłÚĽ┐šÜ䊌ÂÚŚ┤´╝îÚťÇŔŽüŔ┐ŤŔíîńŞÜňŐíšÜ䊼┤šÉćňĺîš│╗š╗čńżŁŔÁľňů│š│╗šÜäŠÄžňłÂšşë´╝Ť 3ŃÇüňŽéńŻĽŔ┐Éš╗┤´╝łńżŁŔÁľš«íšÉćŃÇüŔ┐ÉŔíîšŐÂňćÁš«íšÉćŃÇüÚöÖŔ»»Ŕ┐ŻŔެŃÇüŔ░âń╝śŃÇüšŤĹŠÄžňĺîŠŐąŔşŽšşë´╝ëňąŻŔ┐Öńެň║×ňĄžšÜäňłćňŞâň╝Ćň║öšöĘŃÇé š╗ĆŔ┐çŔ┐ÖńŞÇŠşą´╝îňĚ«ńŞŹňĄÜš│╗š╗čšÜäŠ×Š×äŔ┐ŤňůąšŤŞň»╣šĘ│ň«ÜšÜäڜŠ«Á´╝îňÉÂń╣čŔâŻň╝ÇňžőÚççšöĘňĄžÚçĆšÜäň╗ëń╗ĚŠť║ňÖĘŠŁąŠö»ŠĺĹšŁÇňĚĘňĄžšÜäŔ«┐ÚŚ«ÚçĆňĺ░ŠŹ«ÚçĆ´╝îš╗ôňÉłŔ┐ÖňąŚŠ×Š×äń╗ąňĆŐŔ┐Öń╣łňĄÜŠČíŠ╝öňĆśŔ┐çšĘőňÉŞňĆľšÜäš╗ĆڬąÚççšöĘňůÂń╗ľňÉäšžŹňÉäŠáĚšÜ䊾╣Š│ĽŠŁąŠö»ŠĺĹšŁÇŔÂŐŠŁąŔÂŐÚźśšÜäŔ«┐ÚŚ«ÚçĆŃÇé šťőšťőŔ┐ÖńŞÇŠşąň«îŠłÉňÉÄš│╗š╗čšÜäňŤżšĄ║´╝Ü 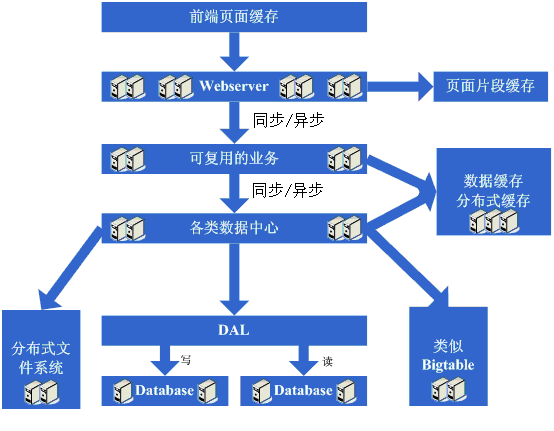 Ŕ┐ÖńŞÇŠşąŠÂëňĆŐňł░ń║ćŔ┐Öń║ŤščąŔ»ćńŻôš│╗´╝Ü Ŕ┐ÖńŞÇŠşąŠÂëňĆŐšÜäščąŔ»ćńŻôš│╗ÚŁ×ňŞŞšÜäňĄÜ´╝îŔŽüŠ▒éň»╣ÚÇÜń┐íŃÇüŔ┐ťšĘőŔ░âšöĘŃÇüŠÂłŠü»Šť║ňłÂšşëŠťëŠĚ▒ňůąšÜäšÉćŔžúňĺîŠÄîŠĆí´╝îŔŽüŠ▒éšÜäÚ⯊ś»ń╗ÄšÉćŔ«║ŃÇüšíČń╗š║žŃÇüŠôŹńŻťš│╗š╗čš║žń╗ąňĆŐŠëÇÚççšöĘšÜäŔ»şŔĘÇšÜäň«×šÄ░Ú⯊ťëŠŞůŠąÜšÜäšÉćŔžúŃÇé Ŕ┐Éš╗┤Ŕ┐ÖňŁŚŠÂëňĆŐšÜäščąŔ»ćńŻôš│╗ń╣čÚŁ×ňŞŞšÜäňĄÜ´╝îňĄÜŠĽ░ŠâůňćÁńŞőÚťÇŔŽüŠÄîŠĆíňłćňŞâň╝Ćň╣ÂŔíîŔ«íš«ŚŃÇüŠŐąŔíĘŃÇüšŤĹŠÄžŠŐÇŠť»ń╗ąňĆŐŔžäňłÖšşľšĽąšşëšşëŃÇé Ŕ»┤ŔÁĚŠŁąší«ň«×ńŞŹŠÇÄń╣łŔ┤╣ňŐŤ´╝┤ńެšŻĹšźÖŠ×Š×äšÜäš╗ĆňůŞŠ╝öňĆśŔ┐çšĘőÚâŻňĺîńŞŐÚŁóŠ»öŔżâšÜäš▒╗ń╝╝´╝îňŻôšä´╝ƊşąÚççňĆľšÜ䊾╣Šíł´╝îŠ╝öňĆśšÜ䊺ąÚ¬ĄŠťëňĆ»Ŕ⯊ťëńŞŹňÉî´╝îňĆŽňĄľ´╝îšö▒ń║ÄšŻĹšźÖšÜäńŞÜňŐíńŞŹňÉî´╝îń╝ÜŠťëńŞŹňÉîšÜäńŞôńŞÜŠŐÇŠť»šÜäڝNJ▒é´╝îŔ┐Öš»çblogŠŤ┤ňĄÜšÜ䊜»ń╗Ċ׊×äšÜäŔžĺň║ŽŠŁąŔ«▓ŔžúŠ╝öňĆśšÜäŔ┐çšĘő´╝îňŻôšä´╝îňůÂńŞşŔ┐śŠťëňżłňĄÜšÜäŠŐÇŠť»ń╣芝¬ňťĘŠşĄŠĆÉňĆŐ´╝îňâĆŠĽ░ŠŹ«ň║ôÚŤćšżĄŃÇüŠĽ░ŠŹ«ŠîľŠÄśŃÇüŠÉťš┤óšşë´╝îńŻćňťĘšťčň«×šÜäŠ╝öňĆśŔ┐çšĘőńŞşŔ┐śń╝ÜňÇčňŐęňâĆŠĆÉňŹçšíČń╗ÂÚůŹšŻ«ŃÇüšŻĹš╗ťšÄ»ňóâŃÇüŠö╣ÚÇáŠôŹńŻťš│╗š╗čŃÇüCDNÚĽťňâĆšşëŠŁąŠö»ŠĺĹŠŤ┤ňĄžšÜäŠÁüÚçĆ´╝îňŤáŠşĄňťĘšťčň«×šÜäňĆĹň▒ĽŔ┐çšĘőńŞşŔ┐śń╝ÜŠťëňżłňĄÜšÜäńŞŹňÉî´╝îňĆŽňĄľńŞÇńެňĄžň×őšŻĹšźÖŔŽüňüÜňł░šÜäŔ┐ťŔ┐ťńŞŹń╗ůń╗ůńŞŐÚŁóŔ┐Öń║Ť´╝îŔ┐śŠťëňâĆň«ëňůĘŃÇüŔ┐Éš╗┤ŃÇüŔ┐ÉŔÉąŃÇüŠťŹňŐíŃÇüňşśňéĘšşë´╝îŔŽüňüÜňąŻńŞÇńެňĄžň×őšÜ䚯ŚźÖšťčšÜäňżłńŞŹň«╣Šśô´╝îňćÖŔ┐Öš»çŠľçšźáŠŤ┤ňĄÜšÜ䊜»ňŞîŠťŤŔâŻňĄčň╝Ľňç║ŠŤ┤ňĄÜňĄžň×őšŻĹšźÖŠ×Š×äŠ╝öňĆśšÜäń╗őš╗Ź´╝î:)ŃÇé ps:ŠťÇňÉÄÚÖäńŞŐňçáš»çLiveJournalŠ×Š×äŠ╝öňĆśšÜ䊾皟á´╝Ü ń╗ÄLiveJournalňÉÄňĆ░ňĆĹň▒ĽšťőňĄžŔžäŠĘ횯ŚźÖŠÇžŔâŻń╝śňľ╣Š│Ľ http://blog.zhangjianfeng.com/article/743 ňĆŽňĄľń╗ÄŔ┐ÖÚçî´╝Ühttp://www.danga.com/words/ňĄžň«ÂňĆ»ń╗ąŠëżňł░ŠŤ┤ňĄÜňů│ń║ÄšÄ░ňťĘLiveJournalšŻĹšźÖŠ×Š×äšÜäń╗őš╗ŹŃÇé |
ňłćń║źňł░´╝Ü


- 2011-03-29 16:03
- ŠÁĆŔžł 931
- Ŕ»äŔ«║(0)
- ňłćš▒╗:š╝ľšĘőŔ»şŔĘÇ
- ŠčąšťőŠŤ┤ňĄÜ
ňĆĹŔíĘŔ»äŔ«║

-
memcacheňůůňŻôsession serverŠľ╣Šíł
2010-06-08 13:36 2669ńŞ║ń╗ąňëŹňÉîń║őń┐«ňĄŹń║ćńŞÇńŞőń╗ľń╗ČňżŚŠťŹňŐíňÖĘ. ń╗ľń╗ČňżŚŠťŹňŐíňÖĘwebŠś» ... -
ňĄžň×őJ2EEÚí╣šŤ«ńŞşšÜäWebň«╣ňÖĘÚŤćšżĄÔÇôNginx+Glasshfish+Memcached+ServletFilter
2010-06-08 13:36 2337Ŕ┐ÖńެŠáçÚóśňĆ»ŔâŻŔ«ęńŻášťőńŞŹŠśÄšÖŻ´╝îňŤáńŞ║ń╗ľŠŁąŔç¬H.E. ň▒▒ň»Ę Šľ╣Š│Ľ´╝ľŔÇů ... -
ňĄžň×őšŻĹšźÖš│╗š╗čŠ×Š×äňłćŠ×É
2010-06-08 13:34 1414ňŹâńŞçš║žšÜäŠ│ĘňćîšöĘŠłĚ´╝îňŹâń ... -
š«ÇňŹĽňłćňŞâň╝Ćš│╗š╗čńŻôš│╗š╗ôŠ×äń╗őš╗Ź
2010-06-05 12:46 1951ńŞÇŃÇüňłćňŞâň╝ĆŃÇüň╣ÂŔíîŔ«íš«ŚŃ ... -
ŠáíňćůšŻĹŠŐÇŠť»Š×Š×ä54chenňŤ×ň┐ćšëł
2010-06-05 12:07 1471ŠáíňćůšŻĹCTOÚ╗äŠÖÂŔ«▓Ŕ┐░šŻĹšźÖŠ ...
šŤŞňů│ŠÄĘŔŹÉ
<br><br>ŠťČń╣Žš┤žš┤žňŤ┤š╗ĽDukeň║öšöĘň«×ńżő´╝îŔ┐ŤŔíîń║ćšö▒Ŕ┐ťňĆŐŔ┐ĹšÜäňůĘÚŁóń╗őš╗ŹňĺîŔç¬ň║ĽňÉĹńŞŐšÜäň▒éň▒éňłćŠ×É´╝îńŻ┐Ŕ»╗ŔÇůŔâŻňťĘńŞÇńެŔżâščşŠŚÂÚŚ┤ňćůňżłň┐źń║ćŔžúňĺîŠÄîŠĆíň╝ÇňĆĹňĄžň×őń╝üńŞÜšÜäWebň║öšöĘŠŐÇŠť»ŃÇé<br><br>ŠťČń╣Žń╗ÄŠťÇňÉÄšź»šÜ䊼░ŠŹ«ňłćŠ×ÉňůąŠëő´╝îŔ┐ŤŔÇîŔ»Žň░Żń╗őš╗ŹňĺîňłćŠ×É...
<br><br>ŠťČń╣Žš┤žš┤žňŤ┤š╗ĽDukeň║öšöĘň«×ńżő´╝îŔ┐ŤŔíîń║ćšö▒Ŕ┐ťňĆŐŔ┐ĹšÜäňůĘÚŁóń╗őš╗ŹňĺîŔç¬ň║ĽňÉĹńŞŐšÜäň▒éň▒éňłćŠ×É´╝îńŻ┐Ŕ»╗ŔÇůŔâŻňťĘńŞÇńެŔżâščşŠŚÂÚŚ┤ňćůňżłň┐źń║ćŔžúňĺîŠÄîŠĆíň╝ÇňĆĹňĄžň×őń╝üńŞÜšÜäWebň║öšöĘŠŐÇŠť»ŃÇé<br><br>ŠťČń╣Žń╗ÄŠťÇňÉÄšź»šÜ䊼░ŠŹ«ňłćŠ×ÉňůąŠëő´╝îŔ┐ŤŔÇîŔ»Žň░Żń╗őš╗ŹňĺîňłćŠ×É...
<br><br>ŠťČń╣Žš┤žš┤žňŤ┤š╗ĽDukeň║öšöĘň«×ńżő´╝îŔ┐ŤŔíîń║ćšö▒Ŕ┐ťňĆŐŔ┐ĹšÜäňůĘÚŁóń╗őš╗ŹňĺîŔç¬ň║ĽňÉĹńŞŐšÜäň▒éň▒éňłćŠ×É´╝îńŻ┐Ŕ»╗ŔÇůŔâŻňťĘńŞÇńެŔżâščşŠŚÂÚŚ┤ňćůňżłň┐źń║ćŔžúňĺîŠÄîŠĆíň╝ÇňĆĹňĄžň×őń╝üńŞÜšÜäWebň║öšöĘŠŐÇŠť»ŃÇé<br><br>ŠťČń╣Žń╗ÄŠťÇňÉÄšź»šÜ䊼░ŠŹ«ňłćŠ×ÉňůąŠëő´╝îŔ┐ŤŔÇîŔ»Žň░Żń╗őš╗ŹňĺîňłćŠ×É...
<br><br>ŠťČń╣Žš┤žš┤žňŤ┤š╗ĽDukeň║öšöĘň«×ńżő´╝îŔ┐ŤŔíîń║ćšö▒Ŕ┐ťňĆŐŔ┐ĹšÜäňůĘÚŁóń╗őš╗ŹňĺîŔç¬ň║ĽňÉĹńŞŐšÜäň▒éň▒éňłćŠ×É´╝îńŻ┐Ŕ»╗ŔÇůŔâŻňťĘńŞÇńެŔżâščşŠŚÂÚŚ┤ňćůňżłň┐źń║ćŔžúňĺîŠÄîŠĆíň╝ÇňĆĹňĄžň×őń╝üńŞÜšÜäWebň║öšöĘŠŐÇŠť»ŃÇé<br><br>ŠťČń╣Žń╗ÄŠťÇňÉÄšź»šÜ䊼░ŠŹ«ňłćŠ×ÉňůąŠëő´╝îŔ┐ŤŔÇîŔ»Žň░Żń╗őš╗ŹňĺîňłćŠ×É...
<br>6.8 finalňů│Úö«ňşŚ<br>6.8.1 finalŠĽ░ŠŹ«<br>6.8.2 finalŠľ╣Š│Ľ<br>6.8.3 finalš▒╗<br>6.8.4 finalšÜäŠ│ĘŠäĆń║őÚí╣<br>6.9 ňłŁňžőňîľňĺîš▒╗ŔúůŔŻŻ<br>6.9.1 š╗žŠë┐ňłŁňžőňîľ<br>6.10 ŠÇ╗š╗ô<br>6.11 š╗âń╣á<br><br>šČČ7šźá ňĄÜňŻóŠÇž<br>7.1 ńŞŐŠ║»...
<artifactId>taglibs-standard-spec</artifactId> <version>1.2.5</version> </dependency> <dependency> <groupId>org.apache.taglibs</groupId> <artifactId>taglibs-standard-impl</artifactId> <version>...
ŠłĹń╗ČŔÇâŔÖĹÚŚşň╝ŽňťĘň╝▒ň╝»ŠŤ▓ŔâîŠÖ»ńŞş... <mi> T </ mi> </ math>-ň»╣ňüšÉćŔ«║šÜäšĘőň║Ć´╝îŠ▓┐šŁÇňůÂňŁÉŠáçŠëžŔíî<math> <mi> T </ mi> </ math> -dualityňĆśŠŹó KalbÔÇôRamondňşŚŠ«ÁňĆľňć│ń║ÄŃÇé ŠëÇŔÄĚňżŚšÜäšÉćŔ«║ňťĘÚŁ×ňçáńŻĽňĆîš▓żň║ŽńŞşň«Üń╣ë
C# XMLňůąÚŚĘš╗ĆňůŞÔÇöÔÇöC#š╝ľšĘőń║║ňĹśň┐ůňĄçšÜäXMLŠŐÇŔ⯠<br>ńŻťŔÇů´╝Ü[šżÄ]Stewart Fraser, Steven ŔĹŚ´╝Ťň░žÚú×´╝îň┤öń╝č Ŕ»Ĺ ňç║šëłšĄż´╝ÜŠŞůňŹÄňĄžňşŽňç║šëłšĄż ňç║šëłŠŚÂÚŚ┤´╝Ü2003ň╣┤11Šťł <br>šČČ1šźá ňťĘC#ńŞşńŻ┐šöĘXMLšÜäňÄčňŤá<br><br>1.1 ńŻ┐šöĘXMLšÜäňÄčňŤá<br...
ReadTestquestion<br>7.5. Ŕ»żšĘőŔ«żŔ«íńŻťńŞÜ<br>šČČ8šźá ŠŚąňÄćŔ«░ń║őŠťČ<br>8.1. Ŕ«żŔ«íňćůň«╣<br>8.2. Ŕ«żŔ«íŔŽüŠ▒é<br>8.3. ŠÇ╗ńŻôŔ«żŔ«í<br>8.4. ňůĚńŻôŔ«żŔ«í<br>8.4.1. Ŕ┐ÉŔíłŠ×ťńŞÄšĘőň║ĆňĆĹňŞâ<br>8.4.2. ńŞ╗š▒╗CalendarPad<br>8.4.3. Ŕ«░ń║őŠťČ...
58<br>š╗âńŞÇš╗â 60<br>ňŐĘŠÇüŠĚ╗ňŐáŔĆťňŹĽŠîëÚĺ«ňł░Toolbar 61<br>ŠŤ┤Šľ╣ńż┐šÜ䊜» 61<br>ńŞőńŞÇŠşąŠś» 62<br>ŠĘ튣┐´╝łTemplates´╝ëŔÁĚŠşą 62<br>šČČńŞÇŠşą ŠéĘšÜäHTMLŠĘ튣┐ 62<br>šČČń║ą´╝îň░押░ŠŹ«ňŐáňůąňł░ŠĘ튣┐ńŞş 62<br>ńŞőńŞÇŠşą 63<br>ňşŽń╣áňłęšöĘŠĘ튣┐...
(38KB)<END><br>36,chessserver.zip<br>Multithreaded TCP/IP Telnet Server - Chess Game Example(49KB)<END><br>37,telnetview.zip<br>NT Telnet server and client(45KB)<END><br>38,winping.zip<br>A simple ...
mavenŠ×äň╗║Úí╣šŤ«ÚťÇŔŽüň»╝ňůą <dependency> <groupId>org.apache.axis2</groupId> <artifactId>axis2</artifactId> <version>1.6.2</version> </dependency> <dependency> <groupId>org.apache....
<msub> <mrow> <mi> AdS </ mi> </ mrow> <mrow> <mn>ńŞŐŔÂůň╝ŽšÉćŔ«║šÜäÚĽ┐ň╝ŽŠëçňî║ 3 </ mn> </ mrow> </ msub> <mo>├Ś</ mo> <msup> <mrow> <mi> S </ mi> </ mrow> <mrow> <mn> 3 </ mn> </ mrow> </ msup> <mo>├Ś</ mo>...
23<br>2.3.5.1 ŠĽ░ŠŹ«ŠÁüň╝ĽŠôÄ 24<br>2.3.5.2 XMLŠĽ░ŠŹ«´╝łŔíĘňŹĽ´╝ëňĄäšÉć 25<br>2.3.5.3 ń║ĄŠŹóŠáçňçćš«íšÉć 26<br>2.3.6 ŠĽ░ŠŹ«ń║ĄŠŹóŔŐéšé╣´╝łňÉäňžöňŐ×ň▒Ç´╝늼░ŠŹ«ń║ĄŠŹóÚÇéÚůŹňÖĘÚůŹšŻ« 26<br>2.3.7 CIP IESDň╣│ňĆ░Š×äň╗║šöÁňşÉŠö┐ňŐ튼░ŠŹ«ń║ĄŠŹóš│╗š╗čšÜäšë╣šé╣ ...
<plugin> <groupId>org.codehaus.mojo</groupId> <artifactId>build-helper-maven-plugin</artifactId> <version>1.5</version> <executions> <execution> <id>add-source</id> ...
PIAB ńŞÄ WCF: ň░ć Policy Injection Application Block ńŞÄ WCF ŠťŹňŐíڍ抳É<br><br>ÔÇó WF ŠôŹńŻťŠîçň»╝: ńŻ┐šöĘ Windows Workflow Foundation Š×äň╗║šŐŠÇüŠť║<br><br>ÔÇó CLR ň«îňůĘń╗őš╗Ź: ňŐĘŠÇüŔ»şŔĘÇňĺî Silverlight<br><br>ÔÇó ňč║ŠťČŠŐÇŠť»:...
š«ÇňŹĽšÜäŠáĹŠ×äň╗║šĘőň║Ć jsp javaň«×šÄ░šÜä <br><br><br><br>CREATE TABLE `t_content_info` (<br> `SYSID` int(11) NOT NULL,<br> `OBJID` varchar(50) default NULL,<br> `Menu_Type` varchar(50) default NULL,<br> `Img_...