
consistent hashing 算法早在 1997 年就在论文 Consistent hashing and random trees 中被提出,目前在 cache 系统中应用越来越广泛;
1 基本场景
比如你有 N 个 cache 服务器(后面简称 cache ),那么如何将一个对象 object 映射到 N 个 cache 上呢,你很可能会采用类似下面的通用方法计算 object 的 hash 值,然后均匀的映射到到 N 个 cache ;
hash(object)%N
一切都运行正常,再考虑如下的两种情况;
1 一个 cache 服务器 m down 掉了(在实际应用中必须要考虑这种情况),这样所有映射到 cache m 的对象都会失效,怎么办,需要把 cache m 从 cache 中移除,这时候 cache 是 N-1 台,映射公式变成了 hash(object)%(N-1) ;
2 由于访问加重,需要添加 cache ,这时候 cache 是 N+1 台,映射公式变成了 hash(object)%(N+1) ;
1 和 2 意味着什么?这意味着突然之间几乎所有的 cache 都失效了。对于服务器而言,这是一场灾难,洪水般的访问都会直接冲向后台服务器;
再来考虑第三个问题,由于硬件能力越来越强,你可能想让后面添加的节点多做点活,显然上面的 hash 算法也做不到。
有什么方法可以改变这个状况呢,这就是 consistent hashing...
2 hash 算法和单调性
Hash 算法的一个衡量指标是单调性( Monotonicity ),定义如下:
单调性是指如果已经有一些内容通过哈希分派到了相应的缓冲中,又有新的缓冲加入到系统中。哈希的结果应能够保证原有已分配的内容可以被映射到新的缓冲中去,而不会被映射到旧的缓冲集合中的其他缓冲区。
容易看到,上面的简单 hash 算法 hash(object)%N 难以满足单调性要求。
3 consistent hashing 算法的原理
consistent hashing 是一种 hash 算法,简单的说,在移除 / 添加一个 cache 时,它能够尽可能小的改变已存在 key 映射关系,尽可能的满足单调性的要求。
下面就来按照 5 个步骤简单讲讲 consistent hashing 算法的基本原理。
3.1 环形hash 空间
考虑通常的 hash 算法都是将 value 映射到一个 32 为的 key 值,也即是 0~2^32-1 次方的数值空间;我们可以将这个空间想象成一个首( 0 )尾( 2^32-1 )相接的圆环,如下面图 1 所示的那样。

图 1 环形 hash 空间
3.2 把对象映射到hash 空间
接下来考虑 4 个对象 object1~object4 ,通过 hash 函数计算出的 hash 值 key 在环上的分布如图 2 所示。
hash(object1) = key1;
… …
hash(object4) = key4;

图 2 4 个对象的 key 值分布
3.3 把cache 映射到hash 空间
Consistent hashing 的基本思想就是将对象和 cache 都映射到同一个 hash 数值空间中,并且使用相同的hash 算法。
假设当前有 A,B 和 C 共 3 台 cache ,那么其映射结果将如图 3 所示,他们在 hash 空间中,以对应的 hash值排列。
hash(cache A) = key A;
… …
hash(cache C) = key C;

图 3 cache 和对象的 key 值分布
说到这里,顺便提一下 cache 的 hash 计算,一般的方法可以使用 cache 机器的 IP 地址或者机器名作为hash 输入。
3.4 把对象映射到cache
现在 cache 和对象都已经通过同一个 hash 算法映射到 hash 数值空间中了,接下来要考虑的就是如何将对象映射到 cache 上面了。
在这个环形空间中,如果沿着顺时针方向从对象的 key 值出发,直到遇见一个 cache ,那么就将该对象存储在这个 cache 上,因为对象和 cache 的 hash 值是固定的,因此这个 cache 必然是唯一和确定的。这样不就找到了对象和 cache 的映射方法了吗?!
依然继续上面的例子(参见图 3 ),那么根据上面的方法,对象 object1 将被存储到 cache A 上; object2和 object3 对应到 cache C ; object4 对应到 cache B ;
3.5 考察cache 的变动
前面讲过,通过 hash 然后求余的方法带来的最大问题就在于不能满足单调性,当 cache 有所变动时,cache 会失效,进而对后台服务器造成巨大的冲击,现在就来分析分析 consistent hashing 算法。
3.5.1 移除 cache
考虑假设 cache B 挂掉了,根据上面讲到的映射方法,这时受影响的将仅是那些沿 cache B 逆时针遍历直到下一个 cache ( cache C )之间的对象,也即是本来映射到 cache B 上的那些对象。
因此这里仅需要变动对象 object4 ,将其重新映射到 cache C 上即可;参见图 4 。

图 4 Cache B 被移除后的 cache 映射
3.5.2 添加 cache
再考虑添加一台新的 cache D 的情况,假设在这个环形 hash 空间中, cache D 被映射在对象 object2 和object3 之间。这时受影响的将仅是那些沿 cache D 逆时针遍历直到下一个 cache ( cache B )之间的对象(它们是也本来映射到 cache C 上对象的一部分),将这些对象重新映射到 cache D 上即可。
因此这里仅需要变动对象 object2 ,将其重新映射到 cache D 上;参见图 5 。

图 5 添加 cache D 后的映射关系
4 虚拟节点
考量 Hash 算法的另一个指标是平衡性 (Balance) ,定义如下:
平衡性
平衡性是指哈希的结果能够尽可能分布到所有的缓冲中去,这样可以使得所有的缓冲空间都得到利用。
hash 算法并不是保证绝对的平衡,如果 cache 较少的话,对象并不能被均匀的映射到 cache 上,比如在上面的例子中,仅部署 cache A 和 cache C 的情况下,在 4 个对象中, cache A 仅存储了 object1 ,而 cache C 则存储了 object2 、 object3 和 object4 ;分布是很不均衡的。
为了解决这种情况, consistent hashing 引入了“虚拟节点”的概念,它可以如下定义:
“虚拟节点”( virtual node )是实际节点在 hash 空间的复制品( replica ),一实际个节点对应了若干个“虚拟节点”,这个对应个数也成为“复制个数”,“虚拟节点”在 hash 空间中以 hash 值排列。
仍以仅部署 cache A 和 cache C 的情况为例,在图 4 中我们已经看到, cache 分布并不均匀。现在我们引入虚拟节点,并设置“复制个数”为 2 ,这就意味着一共会存在 4 个“虚拟节点”, cache A1, cache A2 代表了 cache A ; cache C1, cache C2 代表了 cache C ;假设一种比较理想的情况,参见图 6 。

图 6 引入“虚拟节点”后的映射关系
此时,对象到“虚拟节点”的映射关系为:
objec1->cache A2 ; objec2->cache A1 ; objec3->cache C1 ; objec4->cache C2 ;
因此对象 object1 和 object2 都被映射到了 cache A 上,而 object3 和 object4 映射到了 cache C 上;平衡性有了很大提高。
引入“虚拟节点”后,映射关系就从 { 对象 -> 节点 } 转换到了 { 对象 -> 虚拟节点 } 。查询物体所在 cache时的映射关系如图 7 所示。
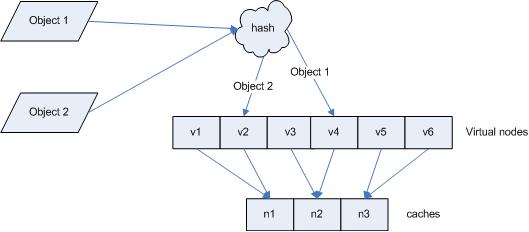
图 7 查询对象所在 cache
“虚拟节点”的 hash 计算可以采用对应节点的 IP 地址加数字后缀的方式。例如假设 cache A 的 IP 地址为202.168.14.241 。
引入“虚拟节点”前,计算 cache A 的 hash 值:
Hash(“202.168.14.241”);
引入“虚拟节点”后,计算“虚拟节”点 cache A1 和 cache A2 的 hash 值:
Hash(“202.168.14.241#1”); // cache A1
Hash(“202.168.14.241#2”); // cache A2
5 小结
Consistent hashing 的基本原理就是这些,具体的分布性等理论分析应该是很复杂的,不过一般也用不到。
http://weblogs.java.net/blog/2007/11/27/consistent-hashing 上面有一个 java 版本的例子,可以参考。
http://blog.csdn.net/mayongzhan/archive/2009/06/25/4298834.aspx 转载了一个 PHP 版的实现代码。
http://www.codeproject.com/KB/recipes/lib-conhash.aspx C语言版本
一些参考资料地址:
http://portal.acm.org/citation.cfm?id=258660
http://en.wikipedia.org/wiki/Consistent_hashing
http://www.spiteful.com/2008/03/17/programmers-toolbox-part-3-consistent-hashing/
http://weblogs.java.net/blog/2007/11/27/consistent-hashing
http://tech.idv2.com/2008/07/24/memcached-004/
http://blog.csdn.net/mayongzhan/archive/2009/06/25/4298834.aspx



相关推荐
宇宙人.zip
内容概要:本文介绍了基于CarSim和Simulink的ACC自适应巡航控制联合仿真模型。该模型由两部分组成:上层控制器采用ACC策略,负责根据车辆周围环境调整车速和跟车距离;下层控制器采用PID控制,确保车辆准确跟随上层指令。此外,还包含车辆逆动力学模型,用于模拟真实车辆的动态响应。文中详细解释了cpar文件的作用及其参数设置方法,并展示了如何在Simulink中搭建PID控制器。通过仿真,验证了模型在复杂道路环境下的有效性,展示了车辆能够根据前方车辆的速度和距离自动调整车速和跟车距离,保持安全行驶。 适合人群:从事自动驾驶技术研发的工程师和技术研究人员。 使用场景及目标:适用于需要对ACC系统进行深入研究和测试的场景,旨在帮助研发人员更好地理解和优化ACC策略,提高自动驾驶的安全性和可靠性。 其他说明:该模型为自动驾驶技术的研发提供了有效工具,有助于推动相关技术的进步和发展。
异业联盟红包拓客 2.12.2.zip
内容概要:本文详细介绍了Simulink锂离子电池模型的功能和技术解析。该模型主要用于模拟锂离子电池的充电和放电过程,能够设定功率进行充放电并实时监测电池的电压、电流、温度和SOC。它提供了数据输入与设置、实时监测与数据分析等功能,确保了模型的准确性和可靠性。通过该模型,工程师可以深入了解电池的性能特点,预测其在实际使用中的表现,从而为产品研发和优化提供依据。 适合人群:从事电动汽车、可再生能源以及储能系统研究和开发的工程师和技术人员。 使用场景及目标:①电动汽车研发:模拟电池性能,提升车辆性能和稳定性;②可再生能源领域:分析电池特性,促进能源开发和利用;③储能系统仿真:优化储能系统设计,提高电力系统效率。 其他说明:该模型不仅适用于特定领域的研究,还可扩展到其他需要模拟和分析电池性能特点的领域。
实训商业源码-飞飞CMS最新版本DC04电脑端网站模板-毕业设计.zip
内容概要:本文详细介绍了新能源电动汽车中VCU(车辆控制单元)和BMS(电池管理系统)的硬件在环(HIL)仿真技术及其重要性。文中阐述了VCU和BMS在电动汽车中的角色,解释了硬件在环仿真技术的概念及其在电动汽车研发中的应用。重点讨论了电动汽车整车建模的方法,涵盖驾驶员模块、仪表模块、BCU整车控制器模块、MCU电机模块、TCU变速箱模块、减速器模块、BMS电池管理模块等多个子系统的建模。此外,文章还探讨了HIL仿真的具体应用场景和优势,强调其在降低成本、提高效率和安全性方面的作用。 适合人群:从事新能源汽车研发的技术人员、研究人员及相关领域的学生。 使用场景及目标:适用于希望深入了解电动汽车VCU和BMS硬件在环仿真技术的研究人员和技术人员,旨在帮助他们掌握相关技术和工具,提升电动汽车的研发和测试能力。 其他说明:文章提供了详细的模块介绍和仿真技术的应用案例,有助于读者更好地理解和应用HIL仿真技术于实际项目中。
实训商业源码-手动安装视频教程-毕业设计.zip
内容概要:本文探讨了模型预测控制(MPC)在两相交错并联Boost变换器中的应用,特别是在Matlab/Simulink环境下对其快速响应、均流特性的仿真研究。文中介绍了MPC的基本概念,强调了它在应对电压跳变和负载突变时的优势。同时,还比较了纯MPC与PI+MPC两种控制方法的效果,指出后者在稳态误差和响应速度方面表现更优。 适合人群:从事电力电子、自动化控制领域的研究人员和技术工程师。 使用场景及目标:适用于需要深入了解MPC理论及其在具体硬件平台上的实施细节的人群;旨在提升电力转换设备的效率和可靠性。 其他说明:文章提供了详细的实验数据和图表支持,有助于读者直观理解不同控制策略下系统的动态行为。此外,文中提及的所有仿真均是在Matlab/Simulink平台上完成的,这为后续的实际工程应用打下了坚实的基础。
实训商业源码-炫酷恶趣强大的制作神器小程序源码_支持多种流量主模式-毕业设计.zip
内容概要:本文详细介绍了DSP28335芯片通过Bootloader和CAN通信实现在线固件升级的方法。首先解释了Bootloader的工作原理,即芯片上电后运行固化在Flash中的Bootloader程序,通过CAN接收新固件数据,擦除旧程序并写入新程序,最后跳转到用户程序执行。文中提供了具体的CAN初始化代码(如设置CCR配置位)以及上位机Python代码用于发送固件数据。还特别提到了版本校验的重要性,并给出了一种优化后的CRC32校验算法。此外,文档中提到一些常见问题及其解决方案,如CAN设备丢包问题和硬件干扰问题。 适合人群:嵌入式系统开发者、DSP芯片使用者、固件开发工程师。 使用场景及目标:适用于需要对DSP28335或其他类似DSP芯片进行固件升级的场景,帮助用户掌握Bootloader的应用和CAN通信的具体实现方法,确保固件升级的成功率。 其他说明:文档不仅提供理论讲解,还有详细的代码示例和操作步骤,甚至包括了一些实际操作中遇到的问题及解决方案,非常适合初学者和有一定经验的研发人员学习和参考。
实训商业源码-电影门户苹果CMS主题模板下载-毕业设计.zip
基于骨骼三维信息结合隐马尔科夫模型人体动作识别方法.pdf
内容概要:本文详细探讨了锂电池的SOC(荷电状态)与BMS(电池管理系统)的关系,重点介绍了2-RC模型及其在BMS中的应用。文中通过MATLAB Simulink进行仿真,展示了如何测试和验证SOC估算算法的精度,并讨论了提高算法精度的方法和技术。此外,还深入探讨了均衡模型的实现及其对电池组一致性的改善,最后介绍了BMS硬件电路PCB设计的关键步骤。 适合人群:从事电池管理系统的工程师、研究人员以及对锂电池技术和仿真有兴趣的技术爱好者。 使用场景及目标:适用于希望深入了解锂电池SOC估算、BMS系统设计、仿真测试及硬件电路设计的专业人士。目标是提升对锂电池管理和仿真的理解和技能。 其他说明:文章不仅涵盖了理论知识,还包括具体的代码示例和实际应用场景,有助于读者全面掌握相关技术并应用于实践中。
实训商业源码-小说系统-毕业设计.zip
内容概要:本文详细介绍了永磁同步电机(PMSM)转速环采用自抗扰控制(ADRC)进行仿真的方法和技术细节。首先解释了ADRC的核心组成部分:跟踪微分器(TD)、扩张状态观测器(ESO)和非线性反馈(NLSEF),并通过MATLAB代码展示了ESO的具体实现方式。接着给出了PMSM的机械运动方程及其Python代码实现,强调了负载转矩作为主要扰动源的影响。文中对比了ADRC与传统PID控制器在面对负载突变时的表现,指出ADRC能够更快地响应并稳定系统。最后提供了ADRC参数调整的经验技巧,如TD和ESO带宽的选择以及非线性因子α的限制条件。 适用人群:对永磁同步电机控制系统感兴趣的工程技术人员、研究人员及高校相关专业学生。 使用场景及目标:适用于需要提高永磁同步电机转速环鲁棒性和动态性能的应用场合,如工业自动化设备、电动汽车驱动系统等。目标是掌握ADRC的工作原理及其在PMSM控制中的具体应用方法。 其他说明:文中提供的代码片段和参数设定建议为实际项目实施提供了宝贵的参考资料,有助于缩短开发周期并提升系统的可靠性。
内容概要:本文详细介绍了利用CST Studio进行极化转换和非对称传输仿真的方法和技术要点。首先讲解了如何通过参数化建模构建用于极化转换的关键结构(如箭头型金属贴片),并强调了参数化设计的优势。接着讨论了边界条件和端口设置的具体步骤,确保仿真结果的准确性。随后提供了电场矢量图的后处理脚本,帮助直观判断极化转换的效果。最后探讨了非对称传输特性的验证方法,包括参数扫描和数据处理技巧。文中还分享了一些常见的仿真陷阱及其解决方案。 适合人群:从事微波工程、天线设计以及电磁兼容性研究的专业人士,尤其是有一定CST仿真经验的研究人员。 使用场景及目标:适用于需要深入理解和掌握CST仿真工具在极化转换和非对称传输领域的应用场合。目标是提高仿真精度,优化设计方案,缩短研发周期。 其他说明:文章不仅提供具体的技术细节,还包括实用的经验分享和避坑指南,有助于读者快速上手并解决实际问题。
运动步数宝步步换购小程序 V4.5.1.zip
数据集介绍:多类别农产品目标检测数据集 一、基础信息 数据集名称:多类别农产品目标检测数据集 图片数量: - 训练集:2,873张图片 - 验证集:738张图片 - 测试集:357张图片 总计:3,968张标注图片 分类类别: 覆盖36种常见农产品,包括: - 水果类:苹果、香蕉、蓝莓、樱桃、葡萄、猕猴桃、桃子、梨、菠萝、西瓜等 - 蔬菜类:朝鲜蓟、芦笋、甜菜、西兰花、卷心菜、胡萝卜、黄瓜、茄子、羽衣甘蓝、洋葱、南瓜、菠菜等 - 其他作物:玉米、马铃薯、红薯、西葫芦等 标注格式: YOLO格式,包含边界框和类别编号,支持主流目标检测框架直接调用。 数据特性: 覆盖农产品生长周期不同阶段的形态,包含复杂田间背景下的目标检测场景。 二、适用场景 农业自动化分拣系统: 支持开发果蔬分拣机器人视觉模块,实现多品类农产品的自动识别与定位。 智能农业监测系统: 用于田间作物生长监测,支持产量预估、成熟度判断等农业AI应用开发。 食品加工质检应用: 可训练模型检测农产品外观缺陷,适用于食品加工流水线质量控制系统。 农业学术研究: 为精准农业、农业机器人等研究方向提供标准化检测数据集。 农业教育工具: 适用于农业院校教学实验,帮助学生学习AI在农业场景的应用实践。 三、数据集优势 类别丰富性强: 涵盖36种全球主流农产品,包含水果、蔬菜、根茎作物等多品类目标,满足复杂农业场景需求。 标注专业度高: 采用YOLO标准格式标注,所有边界框均经过人工校验,确保遮挡目标、小目标标注准确性。 数据平衡性好: 各类别样本量经均衡处理,避免长尾分布问题,适合工业级模型训练。 应用扩展性强: 除目标检测外,支持扩展至产量统计、尺寸测量等农业计算机视觉任务。 实际价值突出: 数据采集自真实农业场景,包含不同光照条件、遮挡情况的样本,可直接部署于农业智能化应用。
内容概要:该数据集专注于课堂上学生的行为检测,特别是针对玩手机和睡觉两种不良行为。数据集由2388张图片组成,每张图片均配有Pascal VOC格式的xml文件和YOLO格式的txt文件作为标注文件,确保了数据的多样性和灵活性。数据集中共包含三种标注类别:“normal”(正常)、“play phone”(玩手机)和“sleep”(睡觉),对应的标注框数量分别为20238、10795和3763,总计34796个框。所有图片和标注均由labelImg工具完成,采用矩形框标注法。; 适合人群:计算机视觉领域研究人员、机器学习爱好者、高校教师及学生等。; 使用场景及目标:①可用于训练和评估课堂行为识别模型,提高课堂管理效率;②适用于研究和开发基于图像的学生行为监测系统,帮助教师及时发现并纠正不良行为。; 其他说明:数据集仅提供准确且合理的标注,不对由此训练出的模型或权重文件的精度作出任何保证。
实训商业源码-青苹果-毕业设计.zip