
1ŃĆüõ║īÕÅēµĀæńÜäµ”éÕ┐Ą
õ║īÕÅēµĀæ’╝łBinary Tree’╝ēµś»õĖ¬µ£ēķÖÉÕģāń┤ĀńÜäķøåÕÉł’╝īĶ»źķøåÕÉłµł¢ĶĆģõĖ║ń®║ŃĆüµł¢ĶĆģńö▒õĖĆõĖ¬ń¦░õĖ║µĀ╣(root)ńÜäÕģāń┤ĀÕÅŖõĖżõĖ¬õĖŹńøĖõ║żńÜäŃĆüĶó½ÕłåÕł½ń¦░õĖ║ÕĘ”ÕŁÉµĀæÕÆīÕÅ│ÕŁÉµĀæńÜäõ║īÕÅēµĀæń╗䵳ÉŃĆéÕĮōķøåÕÉłõĖ║ń®║µŚČ’╝īń¦░Ķ»źõ║īÕÅēµĀæõĖ║ń®║õ║īÕÅēµĀæŃĆéÕ£©õ║īÕÅēµĀæõĖŁ’╝īõĖĆõĖ¬Õģāń┤Āõ╣¤ń¦░õĮ£õĖĆõĖ¬ń╗ōńé╣ŃĆé
’╝ł1’╝ēń╗ōńé╣ńÜäÕ║”ŃĆéń╗ōńé╣µēƵŗźµ£ēńÜäÕŁÉµĀæńÜäõĖ¬µĢ░ń¦░õĖ║Ķ»źń╗ōńé╣ńÜäÕ║”ŃĆé
’╝ł2’╝ēÕÅČń╗ōńé╣ŃĆéÕ║”õĖ║0ńÜäń╗ōńé╣ń¦░õĖ║ÕÅČń╗ōńé╣’╝īµł¢ĶĆģń¦░õĖ║ń╗łń½»ń╗ōńé╣ŃĆé
’╝ł3’╝ēÕłåµ×Øń╗ōńé╣ŃĆéÕ║”õĖŹõĖ║0ńÜäń╗ōńé╣ń¦░õĖ║Õłåµö»ń╗ōńé╣’╝īµł¢ĶĆģń¦░õĖ║ķØ×ń╗łń½»ń╗ōńé╣ŃĆéõĖƵŻĄµĀæńÜäń╗ōńé╣ķÖżÕÅČń╗ōńé╣Õż¢’╝īÕģČõĮÖńÜäķāĮµś»Õłåµö»ń╗ōńé╣ŃĆé
’╝ł4’╝ēÕĘ”ÕŁ®ÕŁÉŃĆüÕÅ│ÕŁ®ÕŁÉŃĆüÕÅīõ║▓ŃĆéµĀæõĖŁõĖĆõĖ¬ń╗ōńé╣ńÜäÕŁÉµĀæńÜäµĀ╣ń╗ōńé╣ń¦░õĖ║Ķ┐ÖõĖ¬ń╗ōńé╣ńÜäÕŁ®ÕŁÉŃĆéĶ┐ÖõĖ¬ń╗ōńé╣ń¦░õĖ║Õ«āÕŁ®ÕŁÉń╗ōńé╣ńÜäÕÅīõ║▓ŃĆéÕģʵ£ēÕÉīõĖĆõĖ¬ÕÅīõ║▓ńÜäÕŁ®ÕŁÉń╗ōńé╣õ║Æń¦░õĖ║ÕģäÕ╝¤ŃĆé
’╝ł5’╝ēĶĘ»ÕŠäŃĆüĶĘ»ÕŠäķĢ┐Õ║”ŃĆéÕ”éµ×£õĖƵŻĄµĀæńÜäõĖĆõĖ▓ń╗ōńé╣n1,n2,ŌĆ”,nkµ£ēÕ”éõĖŗÕģ│ń│╗’╝Üń╗ōńé╣niµś»ni+1ńÜäńłČń╗ōńé╣’╝ł1Ōēżi<k’╝ē,Õ░▒µŖŖn1,n2,ŌĆ”,nkń¦░õĖ║õĖƵØĪńö▒n1Ķć│nkńÜäĶĘ»ÕŠäŃĆéĶ┐ÖµØĪĶĘ»ÕŠäńÜäķĢ┐Õ║”µś»k-1ŃĆé
┬Ā
’╝ł6’╝ēńź¢ÕģłŃĆüÕŁÉÕŁÖŃĆéÕ£©µĀæõĖŁ’╝īÕ”éµ×£µ£ēõĖƵØĪĶĘ»ÕŠäõ╗Äń╗ōńé╣MÕł░ń╗ōńé╣N’╝īķéŻõ╣łMÕ░▒ń¦░õĖ║NńÜäńź¢Õģł’╝īĶĆīNń¦░õĖ║MńÜäÕŁÉÕŁÖŃĆé
’╝ł7’╝ēń╗ōńé╣ńÜäÕ▒éµĢ░ŃĆéĶ¦äիܵĀæńÜäµĀ╣ń╗ōńé╣ńÜäÕ▒éµĢ░õĖ║1’╝īÕģČõĮÖń╗ōńé╣ńÜäÕ▒éµĢ░ńŁēõ║ÄÕ«āńÜäÕÅīõ║▓ń╗ōńé╣ńÜäÕ▒éµĢ░ÕŖĀ1ŃĆé
’╝ł8’╝ēµĀæńÜäµĘ▒Õ║”ŃĆéµĀæõĖŁµēƵ£ēń╗ōńé╣ńÜäµ£ĆÕż¦Õ▒éµĢ░ń¦░õĖ║µĀæńÜäµĘ▒Õ║”ŃĆé
’╝ł9’╝ēµĀæńÜäÕ║”ŃĆéµĀæõĖŁÕÉäń╗ōńé╣Õ║”ńÜäµ£ĆÕż¦ÕĆ╝ń¦░õĖ║Ķ»źµĀæńÜäÕ║”ŃĆé
’╝ł10’╝ēµ╗Īõ║īÕÅēµĀæ
┬Ā ┬Ā ┬Ā ┬Ā ┬ĀÕ£©õĖƵŻĄõ║īÕÅēµĀæõĖŁ’╝īÕ”éµ×£µēƵ£ēÕłåµö»ń╗ōńé╣ķāĮÕŁśÕ£©ÕĘ”ÕŁÉµĀæÕÆīÕÅ│ÕŁÉµĀæ’╝īÕ╣ČõĖöµēƵ£ēÕÅČÕŁÉń╗ōńé╣ķāĮÕ£©ÕÉīõĖĆÕ▒éõĖŖ’╝īĶ┐ÖµĀĘńÜäõĖƵŻĄõ║īÕÅēµĀæń¦░õĮ£µ╗Īõ║īÕÅēµĀæŃĆé
11’╝ēÕ«īÕģ©õ║īÕÅēµĀæŃĆé
┬Ā
┬Ā┬Ā┬Ā┬ĀõĖƵŻĄµĘ▒Õ║”õĖ║kńÜäµ£ēnõĖ¬ń╗ōńé╣ńÜäõ║īÕÅēµĀæ’╝īÕ»╣µĀæõĖŁńÜäń╗ōńé╣µīēõ╗ÄõĖŖĶć│õĖŗŃĆüõ╗ÄÕĘ”Õł░ÕÅ│ńÜäķĪ║Õ║ÅĶ┐øĶĪīń╝¢ÕÅĘ’╝īÕ”éµ×£ń╝¢ÕÅĘõĖ║i’╝ł1ŌēżiŌēżn’╝ēńÜäń╗ōńé╣õĖĵ╗Īõ║īÕÅēµĀæõĖŁń╝¢ÕÅĘõĖ║ińÜäń╗ōńé╣Õ£©õ║īÕÅēµĀæõĖŁńÜäõĮŹńĮ«ńøĖÕÉī’╝īÕłÖĶ┐ÖµŻĄõ║īÕÅēµĀæń¦░õĖ║Õ«īÕģ©õ║īÕÅēµĀæŃĆéÕ«īÕģ©õ║īÕÅēµĀæńÜäńē╣ńé╣µś»’╝ÜÕÅČÕŁÉń╗ōńé╣ÕŬĶāĮÕć║ńÄ░Õ£©µ£ĆõĖŗÕ▒éÕÆīµ¼ĪõĖŗÕ▒é’╝īõĖöµ£ĆõĖŗÕ▒éńÜäÕÅČÕŁÉń╗ōńé╣ķøåõĖŁÕ£©µĀæńÜäÕĘ”ķā©ŃĆ鵜ŠńäČ’╝īõĖƵŻĄµ╗Īõ║īÕÅēµĀæÕ┐ģիܵś»õĖƵŻĄÕ«īÕģ©õ║īÕÅēµĀæ’╝īĶĆīÕ«īÕģ©õ║īÕÅēµĀæµ£¬Õ┐ģµś»µ╗Īõ║īÕÅēµĀæŃĆé
õ║īÕÅēµĀæńÜäõĖ╗Ķ”üµĆ¦Ķ┤©
µĆ¦Ķ┤©1┬Ā┬ĀõĖƵŻĄķØ×ń®║õ║īÕÅēµĀæńÜäń¼¼iÕ▒éõĖŖµ£ĆÕżÜµ£ē2i-1õĖ¬ń╗ōńé╣’╝łiŌēź1’╝ēŃĆé
µĆ¦Ķ┤©2┬Ā┬ĀõĖƵŻĄµĘ▒Õ║”õĖ║kńÜäõ║īÕÅēµĀæõĖŁ’╝īµ£ĆÕżÜÕģʵ£ē2k’╝Ź1õĖ¬ń╗ōńé╣ŃĆé
µĆ¦Ķ┤©3┬Ā┬ĀÕ»╣õ║ÄõĖƵŻĄķØ×ń®║ńÜäõ║īÕÅēµĀæ’╝īÕ”éµ×£ÕÅČÕŁÉń╗ōńé╣µĢ░õĖ║n0’╝īÕ║”µĢ░õĖ║2ńÜäń╗ōńé╣µĢ░õĖ║n2’╝īÕłÖµ£ē:┬Ā n0’╝Øn2’╝ŗ1ŃĆé
µĆ¦Ķ┤©4┬Ā┬ĀÕģʵ£ēnõĖ¬ń╗ōńé╣ńÜäÕ«īÕģ©õ║īÕÅēµĀæńÜäµĘ▒Õ║”kõĖ║[log2n]+1ŃĆé
┬ĀµĆ¦Ķ┤©5┬Ā┬ĀÕ»╣õ║ÄÕģʵ£ēnõĖ¬ń╗ōńé╣ńÜäÕ«īÕģ©õ║īÕÅēµĀæ’╝īÕ”éµ×£µīēńģ¦õ╗ÄõĖŖĶć│õĖŗÕÆīõ╗ÄÕĘ”Õł░ÕÅ│ńÜäķĪ║Õ║ÅÕ»╣õ║īÕÅēµĀæõĖŁńÜäµēƵ£ēń╗ōńé╣õ╗Ä1Õ╝ĆÕ¦ŗķĪ║Õ║Åń╝¢ÕÅĘ’╝īÕłÖÕ»╣õ║Äõ╗╗µäÅńÜäÕ║ÅÕÅĘõĖ║ińÜäń╗ōńé╣’╝īµ£ē’╝Ü
’╝ł1’╝ēÕ”éµ×£i>1’╝īÕłÖÕ║ÅÕÅĘõĖ║ińÜäń╗ōńé╣ńÜäÕÅīõ║▓ń╗ōńé╣ńÜäÕ║ÅÕÅĘõĖ║i/2(ŌĆ£/ŌĆØĶĪ©ńż║µĢ┤ķÖż)’╝øÕ”éµ×£i’╝Ø1’╝īÕłÖÕ║ÅÕÅĘõĖ║ińÜäń╗ōńé╣µś»µĀ╣ń╗ōńé╣’╝īµŚĀÕÅīõ║▓ń╗ōńé╣ŃĆé
’╝ł2’╝ēÕ”éµ×£2iŌēżn’╝īÕłÖÕ║ÅÕÅĘõĖ║ińÜäń╗ōńé╣ńÜäÕĘ”ÕŁ®ÕŁÉń╗ōńé╣ńÜäÕ║ÅÕÅĘõĖ║2i’╝øÕ”éµ×£2i>n’╝īÕłÖÕ║ÅÕÅĘõĖ║ińÜäń╗ōńé╣µŚĀÕĘ”ÕŁ®ÕŁÉŃĆé
’╝ł3’╝ēÕ”éµ×£2i’╝ŗ1Ōēżn’╝īÕłÖÕ║ÅÕÅĘõĖ║ińÜäń╗ōńé╣ńÜäÕÅ│ÕŁ®ÕŁÉń╗ōńé╣ńÜäÕ║ÅÕÅĘõĖ║2i’╝ŗ1’╝øÕ”éµ×£2i’╝ŗ1>n’╝īÕłÖÕ║ÅÕÅĘõĖ║ińÜäń╗ōńé╣µŚĀÕÅ│ÕŁ®ÕŁÉ
õ║īÕÅēµĀæńÜäķüŹÕÄå
õ║īÕÅēµĀæńÜäķüŹÕÄåµś»µīćµīēńģ¦µ¤Éń¦ŹķĪ║Õ║ÅĶ«┐ķŚ«õ║īÕÅēµĀæõĖŁńÜäµ»ÅõĖ¬ń╗ōńé╣’╝īõĮ┐µ»ÅõĖ¬ń╗ōńé╣Ķó½Ķ«┐ķŚ«õĖƵ¼ĪõĖöõ╗ģĶó½Ķ«┐ķŚ«õĖƵ¼ĪŃĆé
1’╝ēÕģłÕ║ÅķüŹÕÄå
µĀ╣--->ÕĘ”ÕŁÉµĀæ--->ÕÅ│ÕŁÉµĀæ
ÕģłÕ║ÅķüŹÕÄåõ║īÕÅēµĀæńÜäķĆÆÕĮÆń«Śµ│ĢÕ”éõĖŗ’╝Ü
void PreOrder’╝łBiTree bt’╝ē
{/*ÕģłÕ║ÅķüŹÕÄåõ║īÕÅēµĀæbt*/
┬Ā┬Āif (bt==NULL) return;┬Ā┬Ā┬Ā┬Ā┬Ā/*ķĆÆÕĮÆĶ░āńö©ńÜäń╗ōµØ¤µØĪõ╗Č*/
┬Ā┬ĀVisite’╝łbt->data’╝ē;┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā/*Ķ«┐ķŚ«ń╗ōńé╣ńÜäµĢ░µŹ«Õ¤¤*/
┬Ā┬ĀPreOrder’╝łbt->lchild’╝ē;┬Ā┬Ā┬Ā/*ÕģłÕ║ÅķĆÆÕĮÆķüŹÕÄåbtńÜäÕĘ”ÕŁÉµĀæ*/
┬Ā┬ĀPreOrder’╝łbt->rchild’╝ē;┬Ā┬Ā┬Ā/*ÕģłÕ║ÅķĆÆÕĮÆķüŹÕÄåbtńÜäÕÅ│ÕŁÉµĀæ*/┬Ā┬Ā
}
2’╝ēõĖŁÕ║ÅķüŹÕÄå
ÕĘ”ÕŁÉµĀæ--->µĀ╣---->ÕÅ│ÕŁÉµĀæ
õĖŁÕ║ÅķüŹÕÄåõ║īÕÅēµĀæńÜäķĆÆÕĮÆń«Śµ│ĢÕ”éõĖŗ’╝Ü
void InOrder’╝łBiTree bt’╝ē
{/*õĖŁÕ║ÅķüŹÕÄåõ║īÕÅēµĀæbt*/
┬Ā┬Āif (bt==NULL) return;┬Ā┬Ā┬Ā┬Ā┬Ā/*ķĆÆÕĮÆĶ░āńö©ńÜäń╗ōµØ¤µØĪõ╗Č*/
┬Ā┬ĀInOrder’╝łbt->lchild’╝ē;┬Ā┬Ā┬Ā┬Ā/*õĖŁÕ║ÅķĆÆÕĮÆķüŹÕÄåbtńÜäÕĘ”ÕŁÉµĀæ*/
┬Ā┬ĀVisite’╝łbt->data’╝ē;┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā/*Ķ«┐ķŚ«ń╗ōńé╣ńÜäµĢ░µŹ«Õ¤¤*/
┬Ā┬ĀInOrder’╝łbt->rchild’╝ē;┬Ā┬Ā┬Ā┬Ā/*õĖŁÕ║ÅķĆÆÕĮÆķüŹÕÄåbtńÜäÕÅ│ÕŁÉµĀæ*/┬Ā┬Ā
}
3’╝ēÕÉÄÕ║ÅķüŹÕÄå
ÕĘ”ÕŁÉµĀæ--->ÕÅ│ÕŁÉµĀæ--->µĀ╣
ÕÉÄÕ║ÅķüŹÕÄåõ║īÕÅēµĀæńÜäķĆÆÕĮÆń«Śµ│ĢÕ”éõĖŗ’╝Ü
void PostOrder’╝łBiTree bt’╝ē
{/*ÕÉÄÕ║ÅķüŹÕÄåõ║īÕÅēµĀæbt*/
┬Ā┬Āif (bt==NULL) return;┬Ā┬Ā┬Ā┬Ā┬Ā/*ķĆÆÕĮÆĶ░āńö©ńÜäń╗ōµØ¤µØĪõ╗Č*/
┬Ā┬ĀPostOrder’╝łbt->lchild’╝ē;┬Ā┬Ā┬Ā/*ÕÉÄÕ║ÅķĆÆÕĮÆķüŹÕÄåbtńÜäÕĘ”ÕŁÉµĀæ*/
┬Ā┬ĀPostOrder’╝łbt->rchild’╝ē;┬Ā┬Ā┬Ā/*ÕÉÄÕ║ÅķĆÆÕĮÆķüŹÕÄåbtńÜäÕÅ│ÕŁÉµĀæ*/┬Ā┬Ā
┬Ā┬ĀVisite’╝łbt->data’╝ē;┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā/*Ķ«┐ķŚ«ń╗ōńé╣ńÜäµĢ░µŹ«Õ¤¤*/
}
Õ▒éµ¼ĪķüŹÕÄå
µēĆĶ░ōõ║īÕÅēµĀæńÜäÕ▒éµ¼ĪķüŹÕÄå’╝īµś»µīćõ╗Äõ║īÕÅēµĀæńÜäń¼¼õĖĆÕ▒é’╝łµĀ╣ń╗ōńé╣’╝ēÕ╝ĆÕ¦ŗ’╝īõ╗ÄõĖŖĶć│õĖŗķĆÉÕ▒éķüŹÕÄå’╝īÕ£©ÕÉīõĖĆÕ▒éõĖŁ’╝īÕłÖµīēõ╗ÄÕĘ”Õł░ÕÅ│ńÜäķĪ║Õ║ÅÕ»╣ń╗ōńé╣ķĆÉõĖ¬Ķ«┐ķŚ«ŃĆé
Õ£©Ķ┐øĶĪīÕ▒éµ¼ĪķüŹÕÄåµŚČ’╝īÕÅ»Ķ«ŠńĮ«õĖĆõĖ¬ķś¤ÕłŚń╗ōµ×ä’╝īķüŹÕÄåõ╗Äõ║īÕÅēµĀæńÜäµĀ╣ń╗ōńé╣Õ╝ĆÕ¦ŗ’╝īķ”¢ÕģłÕ░åµĀ╣ń╗ōńé╣µīćķÆłÕģźķś¤ÕłŚ’╝īńäČÕÉÄõ╗ÄÕ»╣Õż┤ÕÅ¢Õć║õĖĆõĖ¬Õģāń┤Ā’╝īµ»ÅÕÅ¢õĖĆõĖ¬Õģāń┤Ā’╝īµē¦ĶĪīõĖŗķØóõĖżõĖ¬µōŹõĮ£’╝Ü
’╝ł1’╝ēĶ«┐ķŚ«Ķ»źÕģāń┤ĀµēƵīćń╗ōńé╣’╝ø
’╝ł2’╝ēĶŗźĶ»źÕģāń┤ĀµēƵīćń╗ōńé╣ńÜäÕĘ”ŃĆüÕÅ│ÕŁ®ÕŁÉń╗ōńé╣ķØ×ń®║’╝īÕłÖÕ░åĶ»źÕģāń┤ĀµēƵīćń╗ōńé╣ńÜäÕĘ”ÕŁ®ÕŁÉµīćķÆłÕÆīÕÅ│ÕŁ®ÕŁÉµīćķÆłķĪ║Õ║ÅÕģźķś¤ŃĆé
┬Ā
µŁżĶ┐ćń©ŗõĖŹµ¢ŁĶ┐øĶĪī’╝īÕĮōķś¤ÕłŚõĖ║ń®║µŚČ’╝īõ║īÕÅēµĀæńÜäÕ▒éµ¼ĪķüŹÕÄåń╗ōµØ¤ŃĆé
┬Ā
2.ÕōłÕż½µø╝µĀæHaffmanµĀæ
µ£Ćõ╝śõ║īÕÅēµĀæ’╝īµś»ÕĖ”µØāĶĘ»ÕŠäµ£Ćń¤ŁńÜäµĀæ
ÕüćĶ«Šµ£ēnõĖ¬µØāÕĆ╝{w1,w2,w3,...,wn} ,µś»µ×äķĆĀõĖĆķóŚµ£ēnõĖ¬ÕÅČÕŁÉĶŖéńé╣ńÜäõ║īÕÅēµĀæ’╝īµ»ÅõĖ¬ÕÅČÕŁÉĶŖéńé╣ńÜäµØāÕĆ╝õĖ║wi,ÕłÖÕģČõĖŁÕĖ”µØāĶĘ»ÕŠäķĢ┐Õ║”WPLµ£ĆÕ░ÅńÜäõ║īÕÅēµĀæń¦░õĖ║HaffmanµĀæŃĆéńö©õ║ĵĢ░µŹ«ÕÄŗń╝®’╝īµ×äÕ╗║Haffmanń╝¢ńĀüŃĆé
┬Ā
3.ÕøŠ
’╝ł1’╝ēµ£ēÕÉæÕøŠŃĆüµŚĀÕÉæÕøŠŃĆüÕ«īÕģ©ÕøŠŃĆüÕ║”ŃĆüµĘ▒Õ║”ķüŹÕÄåŃĆüÕ╣┐Õ║”ķüŹÕÄåŃĆé
’╝ł2’╝ēµŚĀÕÉæÕøŠĶ┐×ķĆܵƦ’╝īµ£ēÕÉæÕøŠńÜäĶ┐×ķĆܵƦ’╝īÕ╝║Ķ┐×ķĆÜÕłåķćÅ’╝ī’╝ē
’╝ł3’╝ēµ£ĆÕ░Åńö¤µłÉµĀæ
┬ĀPrimń«Śµ│Ģ’╝Üõ╗ÄõĖĆõĖ¬ķĪČńé╣µīēµ£ĆÕ░ÅĶŠ╣Ķ┐׵ğķé╗µÄźńé╣’╝īńø┤Õł░µēƵ£ēńÜäńé╣ķāĮĶ┐×ķĆÜŃĆé
Kruskalń«Śµ│Ģ’╝Üõ╗ĵēƵ£ēńÜäĶ┐×ķĆÜĶŠ╣õĖŁµīæÕć║µ£ĆÕ░ÅńÜäĶŠ╣’╝īõŠØµ¼ĪµīæķĆēµ¼ĪÕ░ÅńÜäĶŠ╣’╝īõ╗źµŁżń▒╗µÄ©’╝īńø┤Õł░µēƵ£ēķĪČńé╣ķāĮĶ┐×ķĆÜŃĆé
┬Ā’╝ł4’╝ēÕŹĢÕģāµ£Ćń¤ŁĶĘ»ÕŠä
õĖĆ.µ£Ćń¤ŁĶĘ»ÕŠäńÜäµ£Ćõ╝śÕŁÉń╗ōµ×äµĆ¦Ķ┤©
┬Ā┬Ā Ķ»źµĆ¦Ķ┤©µÅÅĶ┐░õĖ║’╝ÜÕ”éµ×£P(i,j)={Vi....Vk..Vs...Vj}µś»õ╗ÄķĪČńé╣iÕł░jńÜäµ£Ćń¤ŁĶĘ»ÕŠä’╝īkÕÆīsµś»Ķ┐ÖµØĪĶĘ»ÕŠäõĖŖńÜäõĖĆõĖ¬õĖŁķŚ┤ķĪČńé╣’╝īķéŻõ╣łP(k,s)Õ┐ģիܵś»õ╗ÄkÕł░sńÜäµ£Ćń¤ŁĶĘ»ÕŠäŃĆéõĖŗķØóĶ»üµśÄĶ»źµĆ¦Ķ┤©ńÜ䵣ŻńĪ«µĆ¦ŃĆé
┬Ā┬Ā ÕüćĶ«ŠP(i,j)={Vi....Vk..Vs...Vj}µś»õ╗ÄķĪČńé╣iÕł░jńÜäµ£Ćń¤ŁĶĘ»ÕŠä’╝īÕłÖµ£ēP(i,j)=P(i,k)+P(k,s)+P(s,j)ŃĆéĶĆīP(k,s)õĖŹµś»õ╗ÄkÕł░sńÜäµ£Ćń¤ŁĶĘØń”╗’╝īķéŻõ╣łÕ┐ģÕ«ÜÕŁśÕ£©ÕÅ”õĖƵØĪõ╗ÄkÕł░sńÜäµ£Ćń¤ŁĶĘ»ÕŠäP'(k,s)’╝īķéŻõ╣łP'(i,j)=P(i,k)+P'(k,s)+P(s,j)<P(i,j)ŃĆéÕłÖõĖÄP(i,j)µś»õ╗ÄiÕł░jńÜäµ£Ćń¤ŁĶĘ»ÕŠäńøĖń¤øńøŠŃĆéÕøĀµŁżĶ»źµĆ¦Ķ┤©ÕŠŚĶ»üŃĆé
õ║ī.Dijkstrań«Śµ│Ģ
┬Ā┬Ā ńö▒õĖŖĶ┐░µĆ¦Ķ┤©ÕÅ»ń¤ź’╝īÕ”éµ×£ÕŁśÕ£©õĖƵØĪõ╗ÄiÕł░jńÜäµ£Ćń¤ŁĶĘ»ÕŠä(Vi.....Vk,Vj)’╝īVkµś»VjÕēŹķØóńÜäõĖĆķĪČńé╣ŃĆéķéŻõ╣ł(Vi...Vk)õ╣¤Õ┐ģիܵś»õ╗ÄiÕł░kńÜäµ£Ćń¤ŁĶĘ»ÕŠäŃĆéõĖ║õ║åµ▒éÕć║µ£Ćń¤ŁĶĘ»ÕŠä’╝īDijkstraÕ░▒µÅÉÕć║õ║åõ╗źµ£Ćń¤ŁĶĘ»ÕŠäķĢ┐Õ║”ķĆÆÕó×’╝īķĆɵ¼Īńö¤µłÉµ£Ćń¤ŁĶĘ»ÕŠäńÜäń«Śµ│ĢŃĆéĶŁ¼Õ”éÕ»╣õ║ĵ║ÉķĪČńé╣V0’╝īķ”¢ÕģłķĆēµŗ®ÕģČńø┤µÄźńøĖķé╗ńÜäķĪČńé╣õĖŁķĢ┐Õ║”µ£Ćń¤ŁńÜäķĪČńé╣Vi’╝īķéŻõ╣łÕĮōÕēŹÕĘ▓ń¤źÕŻՊŚõ╗ÄV0Õł░ĶŠŠVjķĪČńé╣ńÜäµ£Ćń¤ŁĶĘØń”╗dist[j]=min{dist[j],dist[i]+matrix[i][j]}ŃĆéµĀ╣µŹ«Ķ┐Öń¦ŹµĆØĶĘ»’╝ī
ÕüćĶ«ŠÕŁśÕ£©G=<V,E>’╝īµ║ÉķĪČńé╣õĖ║V0’╝īU={V0},dist[i]Ķ«░ÕĮĢV0Õł░ińÜäµ£Ćń¤ŁĶĘØń”╗’╝īpath[i]Ķ«░ÕĮĢõ╗ÄV0Õł░iĶĘ»ÕŠäõĖŖńÜäiÕēŹķØóńÜäõĖĆõĖ¬ķĪČńé╣ŃĆé
1.õ╗ÄV-UõĖŁķĆēµŗ®õĮ┐dist[i]ÕĆ╝µ£ĆÕ░ÅńÜäķĪČńé╣i’╝īÕ░åiÕŖĀÕģźÕł░UõĖŁ’╝ø
2.µø┤µ¢░õĖÄińø┤µÄźńøĖķé╗ķĪČńé╣ńÜädistÕĆ╝ŃĆé(dist[j]=min{dist[j],dist[i]+matrix[i][j]})
3.ń¤źķüōU=V’╝īÕü£µŁóŃĆé
3.Õģ½Õż¦µÄÆÕ║Åń«Śµ│Ģ
’╝ł1’╝ēńø┤µÄźµÅÆÕģźµÄÆÕ║Å
Õ¤║µ£¼µĆصā│:
Õ░åõĖĆõĖ¬Ķ«░ÕĮĢµÅÆÕģźÕł░ÕĘ▓µÄÆÕ║ÅÕźĮńÜäµ£ēÕ║ÅĶĪ©õĖŁ’╝īõ╗ÄĶĆīÕŠŚÕł░õĖĆõĖ¬µ¢░’╝īĶ«░ÕĮĢµĢ░Õó×1ńÜäµ£ēÕ║ÅĶĪ©ŃĆéÕŹ│’╝ÜÕģłÕ░åÕ║ÅÕłŚńÜäń¼¼1õĖ¬Ķ«░ÕĮĢń£ŗµłÉµś»õĖĆõĖ¬µ£ēÕ║ÅńÜäÕŁÉÕ║ÅÕłŚ’╝īńäČÕÉÄõ╗Äń¼¼2õĖ¬Ķ«░ÕĮĢķĆÉõĖ¬Ķ┐øĶĪīµÅÆÕģź’╝īńø┤Ķć│µĢ┤õĖ¬Õ║ÅÕłŚµ£ēÕ║ÅõĖ║µŁóŃĆé
Ķ”üńé╣’╝ÜĶ«Šń½ŗÕō©ÕģĄ’╝īõĮ£õĖ║õĖ┤µŚČÕŁśÕé©ÕÆīÕłżµ¢ŁµĢ░ń╗äĶŠ╣ńĢīõ╣ŗńö©ŃĆé
µÅÆÕģźµÄÆÕ║Åń«Śµ│Ģµś»ń©│Õ«ÜńÜä’╝łµÄÆÕ║ÅÕēŹÕÉÄńøĖÕÉīÕģāń┤ĀķĪ║Õ║ÅõĖŹÕÅś’╝ē
µĢłńÄć’╝Ü
µŚČķŚ┤ÕżŹµØéÕ║”’╝ÜO’╝łn^2’╝ēń©│Õ«Ü.
’╝ł2’╝ēõ║żµŹóµÄÆÕ║Å-ÕåƵ│ĪµÄÆÕ║Å
Õ¤║µ£¼µĆصā│’╝Ü
Õ£©Ķ”üµÄÆÕ║ÅńÜäõĖĆń╗äµĢ░õĖŁ’╝īÕ»╣ÕĮōÕēŹĶ┐śµ£¬µÄÆÕźĮÕ║ÅńÜäĶīāÕø┤ÕåģńÜäÕģ©ķā©µĢ░’╝īĶć¬õĖŖĶĆīõĖŗÕ»╣ńøĖķé╗ńÜäõĖżõĖ¬µĢ░õŠØµ¼ĪĶ┐øĶĪīµ»öĶŠāÕÆīĶ░āµĢ┤’╝īĶ«®ĶŠāÕż¦ńÜäµĢ░ÕŠĆõĖŗµ▓ē’╝īĶŠāÕ░ÅńÜäÕŠĆõĖŖÕåÆŃĆéÕŹ│’╝ܵ»ÅÕĮōõĖżńøĖķé╗ńÜäµĢ░µ»öĶŠāÕÉÄÕÅæńÄ░Õ«āõ╗¼ńÜäµÄÆÕ║ÅõĖĵÄÆÕ║ÅĶ”üµ▒éńøĖÕÅŹµŚČ’╝īÕ░▒Õ░åÕ«āõ╗¼õ║ƵŹóŃĆé
ÕåƵ│ĪµÄÆÕ║Åń«Śµ│ĢńÜäµö╣Ķ┐ø
Õ»╣ÕåƵ│ĪµÄÆÕ║ÅÕĖĖĶ¦üńÜäµö╣Ķ┐øµ¢╣µ│Ģµś»ÕŖĀÕģźõĖƵĀćÕ┐ŚµĆ¦ÕÅśķćÅexchange’╝īńö©õ║ĵĀćÕ┐Śµ¤ÉõĖĆĶȤµÄÆÕ║ÅĶ┐ćń©ŗõĖŁµś»ÕÉ”µ£ēµĢ░µŹ«õ║żµŹó’╝īÕ”éµ×£Ķ┐øĶĪīµ¤ÉõĖĆĶȤµÄÆÕ║ŵŚČÕ╣ȵ▓Īµ£ēĶ┐øĶĪīµĢ░µŹ«õ║żµŹó’╝īÕłÖĶ»┤µśÄµĢ░µŹ«ÕĘ▓ń╗ŵīēĶ”üµ▒éµÄÆÕłŚÕźĮ’╝īÕÅ»ń½ŗÕŹ│ń╗ōµØ¤µÄÆÕ║Å’╝īķü┐ÕģŹõĖŹÕ┐ģĶ”üńÜäµ»öĶŠāĶ┐ćń©ŗŃĆé
µ£¼µ¢ćÕåŹµÅÉõŠøõ╗źõĖŗõĖżń¦Źµö╣Ķ┐øń«Śµ│Ģ’╝Ü
┬Ā
1’╝ÄĶ«ŠńĮ«õĖƵĀćÕ┐ŚµĆ¦ÕÅśķćÅpos,ńö©õ║ÄĶ«░ÕĮĢµ»ÅĶȤµÄÆÕ║ÅõĖŁµ£ĆÕÉÄõĖƵ¼ĪĶ┐øĶĪīõ║żµŹóńÜäõĮŹńĮ«ŃĆéńö▒õ║ÄposõĮŹńĮ«õ╣ŗÕÉÄńÜäĶ«░ÕĮĢÕØćÕĘ▓õ║żµŹóÕł░õĮŹ,µĢģÕ£©Ķ┐øĶĪīõĖŗõĖĆĶȤµÄÆÕ║ŵŚČÕŬĶ”üµē½µÅÅÕł░posõĮŹńĮ«ÕŹ│ÕÅ»ŃĆé
2’╝Äõ╝Āń╗¤ÕåƵ│ĪµÄÆÕ║ÅõĖŁµ»ÅõĖĆĶȤµÄÆÕ║ŵōŹõĮ£ÕŬĶāĮµēŠÕł░õĖĆõĖ¬µ£ĆÕż¦ÕĆ╝µł¢µ£ĆÕ░ÅÕĆ╝,µłæõ╗¼ĶĆāĶÖæÕł®ńö©Õ£©µ»ÅĶȤµÄÆÕ║ÅõĖŁĶ┐øĶĪīµŁŻÕÉæÕÆīÕÅŹÕÉæõĖżķüŹÕåƵ│ĪńÜäµ¢╣µ│ĢõĖƵ¼ĪÕÅ»õ╗źÕŠŚÕł░õĖżõĖ¬µ£Ćń╗łÕĆ╝(µ£ĆÕż¦ĶĆģÕÆīµ£ĆÕ░ÅĶĆģ) ,┬Āõ╗ÄĶĆīõĮ┐µÄÆÕ║ÅĶȤµĢ░ÕćĀõ╣ÄÕćÅÕ░æõ║åõĖĆÕŹŖŃĆé
µĢłńÄć’╝Ü
µŚČķŚ┤ÕżŹµØéÕ║”’╝ÜO’╝łn^2’╝ē’╝īń©│Õ«Ü.
’╝ł3’╝ēķĆēµŗ®µÄÆÕ║Å-ń«ĆÕŹĢķĆēµŗ®µÄÆÕ║Å
Õ¤║µ£¼µĆصā│’╝Ü
Õ£©Ķ”üµÄÆÕ║ÅńÜäõĖĆń╗äµĢ░õĖŁ’╝īķĆēÕć║µ£ĆÕ░Å’╝łµł¢ĶĆģµ£ĆÕż¦’╝ēńÜäõĖĆõĖ¬µĢ░õĖÄń¼¼1õĖ¬õĮŹńĮ«ńÜäµĢ░õ║żµŹó’╝øńäČÕÉÄÕ£©Õē®õĖŗńÜäµĢ░ÕĮōõĖŁÕåŹµēŠµ£ĆÕ░Å’╝łµł¢ĶĆģµ£ĆÕż¦’╝ēńÜäõĖÄń¼¼2õĖ¬õĮŹńĮ«ńÜäµĢ░õ║żµŹó’╝īõŠØµ¼Īń▒╗µÄ©’╝īńø┤Õł░ń¼¼n-1õĖ¬Õģāń┤Ā’╝łÕĆƵĢ░ń¼¼õ║īõĖ¬µĢ░’╝ēÕÆīń¼¼nõĖ¬Õģāń┤Ā’╝łµ£ĆÕÉÄõĖĆõĖ¬µĢ░’╝ēµ»öĶŠāõĖ║µŁóŃĆé
µōŹõĮ£µ¢╣µ│Ģ’╝Ü
ń¼¼õĖĆĶȤ’╝īõ╗Än õĖ¬Ķ«░ÕĮĢõĖŁµēŠÕć║Õģ│ķö«ńĀüµ£ĆÕ░ÅńÜäĶ«░ÕĮĢõĖÄń¼¼õĖĆõĖ¬Ķ«░ÕĮĢõ║żµŹó’╝ø
ń¼¼õ║īĶȤ’╝īõ╗Äń¼¼õ║īõĖ¬Ķ«░ÕĮĢÕ╝ĆÕ¦ŗńÜän-1 õĖ¬Ķ«░ÕĮĢõĖŁÕåŹķĆēÕć║Õģ│ķö«ńĀüµ£ĆÕ░ÅńÜäĶ«░ÕĮĢõĖÄń¼¼õ║īõĖ¬Ķ«░ÕĮĢõ║żµŹó’╝ø
õ╗źµŁżń▒╗µÄ©.....
ń¼¼i ĶȤ’╝īÕłÖõ╗Äń¼¼i õĖ¬Ķ«░ÕĮĢÕ╝ĆÕ¦ŗńÜän-i+1 õĖ¬Ķ«░ÕĮĢõĖŁķĆēÕć║Õģ│ķö«ńĀüµ£ĆÕ░ÅńÜäĶ«░ÕĮĢõĖÄń¼¼i õĖ¬Ķ«░ÕĮĢõ║żµŹó’╝ī
┬Ā
ńø┤Õł░µĢ┤õĖ¬Õ║ÅÕłŚµīēÕģ│ķö«ńĀüµ£ēÕ║ÅŃĆé
┬Āń«ĆÕŹĢķĆēµŗ®µÄÆÕ║ÅńÜäµö╣Ķ┐øŌĆöŌĆöõ║īÕģāķĆēµŗ®µÄÆÕ║Å
ń«ĆÕŹĢķĆēµŗ®µÄÆÕ║Å’╝īµ»ÅĶČ¤ÕŠ¬ńÄ»ÕŬĶāĮńĪ«Õ«ÜõĖĆõĖ¬Õģāń┤ĀµÄÆÕ║ÅÕÉÄńÜäÕ«ÜõĮŹŃĆ鵳æõ╗¼ÕÅ»õ╗źĶĆāĶÖæµö╣Ķ┐øõĖ║µ»ÅĶČ¤ÕŠ¬ńÄ»ńĪ«Õ«ÜõĖżõĖ¬Õģāń┤Ā’╝łÕĮōÕēŹĶȤµ£ĆÕż¦ÕÆīµ£ĆÕ░ÅĶ«░ÕĮĢ’╝ēńÜäõĮŹńĮ«,õ╗ÄĶĆīÕćÅÕ░æµÄÆÕ║ŵēĆķ£ĆńÜäÕŠ¬ńÄ»µ¼ĪµĢ░ŃĆéµö╣Ķ┐øÕÉÄÕ»╣nõĖ¬µĢ░µŹ«Ķ┐øĶĪīµÄÆÕ║Å’╝īµ£ĆÕżÜÕŬķ£ĆĶ┐øĶĪī[n/2]ĶČ¤ÕŠ¬ńÄ»ÕŹ│ÕÅ»ŃĆé
µĢłńÄć’╝Ü
µŚČķŚ┤ÕżŹµØéÕ║”’╝ÜO’╝łn^2’╝ēõĮåµś» õĖŹń©│Õ«Ü.
’╝ł4’╝ēķĆēµŗ®µÄÆÕ║Å-ÕĀåµÄÆÕ║Å
ÕĀåµÄÆÕ║ŵś»õĖĆń¦ŹµĀæÕĮóķĆēµŗ®µÄÆÕ║Å’╝īµś»Õ»╣ńø┤µÄźķĆēµŗ®µÄÆÕ║ÅńÜäµ£ēµĢłµö╣Ķ┐øŃĆé
ÕĀåńÜäÕ«Üõ╣ēÕ”éõĖŗ’╝ÜÕģʵ£ēnõĖ¬Õģāń┤ĀńÜäÕ║ÅÕłŚ’╝łk1,k2,...,kn),ÕĮōõĖöõ╗ģÕĮōµ╗ĪĶČ│
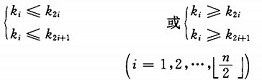
µŚČń¦░õ╣ŗõĖ║ÕĀåŃĆéńö▒ÕĀåńÜäÕ«Üõ╣ēÕÅ»õ╗źń£ŗÕć║’╝īÕĀåķĪČÕģāń┤Ā’╝łÕŹ│ń¼¼õĖĆõĖ¬Õģāń┤Ā’╝ēÕ┐ģõĖ║µ£ĆÕ░ÅķĪ╣’╝łÕ░ÅķĪČÕĀå’╝ēŃĆé
Ķŗźõ╗źõĖĆń╗┤µĢ░ń╗äÕŁśÕé©õĖĆõĖ¬ÕĀå’╝īÕłÖÕĀåÕ»╣Õ║öõĖƵŻĄÕ«īÕģ©õ║īÕÅēµĀæ’╝īõĖöµēƵ£ēķØ×ÕÅČń╗ōńé╣ńÜäÕĆ╝ÕØćõĖŹÕż¦õ║Ä(µł¢õĖŹÕ░Åõ║Ä)ÕģČÕŁÉÕź│ńÜäÕĆ╝’╝īµĀ╣ń╗ōńé╣’╝łÕĀåķĪČÕģāń┤Ā’╝ēńÜäÕĆ╝µś»µ£ĆÕ░Å(µł¢µ£ĆÕż¦)ńÜäŃĆé
ÕłØÕ¦ŗµŚČµŖŖĶ”üµÄÆÕ║ÅńÜänõĖ¬µĢ░ńÜäÕ║ÅÕłŚń£ŗõĮ£µś»õĖƵŻĄķĪ║Õ║ÅÕŁśÕé©ńÜäõ║īÕÅēµĀæ’╝łõĖĆń╗┤µĢ░ń╗äÕŁśÕé©õ║īÕÅēµĀæ’╝ē’╝īĶ░āµĢ┤Õ«āõ╗¼ńÜäÕŁśÕé©Õ║Å’╝īõĮ┐õ╣ŗµłÉõĖ║õĖĆõĖ¬ÕĀå’╝īÕ░åÕĀåķĪČÕģāń┤ĀĶŠōÕć║’╝īÕŠŚÕł░n õĖ¬Õģāń┤ĀõĖŁµ£ĆÕ░Å(µł¢µ£ĆÕż¦)ńÜäÕģāń┤Ā’╝īĶ┐ÖµŚČÕĀåńÜäµĀ╣ĶŖéńé╣ńÜäµĢ░µ£ĆÕ░Å’╝łµł¢ĶĆģµ£ĆÕż¦’╝ēŃĆéńäČÕÉÄÕ»╣ÕēŹķØó(n-1)õĖ¬Õģāń┤Āķ揵¢░Ķ░āµĢ┤õĮ┐õ╣ŗµłÉõĖ║ÕĀå’╝īĶŠōÕć║ÕĀåķĪČÕģāń┤Ā’╝īÕŠŚÕł░n õĖ¬Õģāń┤ĀõĖŁµ¼ĪÕ░Å(µł¢µ¼ĪÕż¦)ńÜäÕģāń┤ĀŃĆéõŠØµŁżń▒╗µÄ©’╝īńø┤Õł░ÕŬµ£ēõĖżõĖ¬ĶŖéńé╣ńÜäÕĀå’╝īÕ╣ČÕ»╣Õ«āõ╗¼õĮ£õ║żµŹó’╝īµ£ĆÕÉÄÕŠŚÕł░µ£ēnõĖ¬ĶŖéńé╣ńÜäµ£ēÕ║ÅÕ║ÅÕłŚŃĆéń¦░Ķ┐ÖõĖ¬Ķ┐ćń©ŗõĖ║ÕĀåµÄÆÕ║ÅŃĆé
ÕøĀµŁż’╝īÕ«×ńÄ░ÕĀåµÄÆÕ║Åķ£ĆĶ¦ŻÕå│õĖżõĖ¬ķŚ«ķóś’╝Ü
1. Õ”éõĮĢÕ░ån õĖ¬ÕŠģµÄÆÕ║ÅńÜäµĢ░Õ╗║µłÉÕĀå’╝ø
2. ĶŠōÕć║ÕĀåķĪČÕģāń┤ĀÕÉÄ’╝īµĆĵĀĘĶ░āµĢ┤Õē®õĮÖn-1 õĖ¬Õģāń┤Ā’╝īõĮ┐ÕģȵłÉõĖ║õĖĆõĖ¬µ¢░ÕĀåŃĆé
ń«Śµ│ĢõĖŹń©│Õ«Ü’╝īõĖöµĢłńÄćõĖ║O(nlogn)
’╝ł5’╝ēÕ┐½ķƤµÄÆÕ║Å
Õ¤║µ£¼µĆصā│’╝Ü
1’╝ēķĆēµŗ®õĖĆõĖ¬Õ¤║ÕćåÕģāń┤Ā,ķĆÜÕĖĖķĆēµŗ®ń¼¼õĖĆõĖ¬Õģāń┤Āµł¢ĶĆģµ£ĆÕÉÄõĖĆõĖ¬Õģāń┤Ā,
2’╝ēķĆÜĶ┐ćõĖĆĶȤµÄÆÕ║ÅĶ«▓ÕŠģµÄÆÕ║ÅńÜäĶ«░ÕĮĢÕłåÕē▓µłÉńŗ¼ń½ŗńÜäõĖżķā©Õłå’╝īÕģČõĖŁõĖĆķā©ÕłåĶ«░ÕĮĢńÜäÕģāń┤ĀÕĆ╝ÕØćµ»öÕ¤║ÕćåÕģāń┤ĀÕĆ╝Õ░ÅŃĆéÕÅ”õĖĆķā©ÕłåĶ«░ÕĮĢńÜä┬ĀÕģāń┤ĀÕĆ╝µ»öÕ¤║ÕćåÕĆ╝Õż¦ŃĆé
3’╝ēµŁżµŚČÕ¤║ÕćåÕģāń┤ĀÕ£©ÕģȵÄÆÕźĮÕ║ÅÕÉÄńÜ䵣ŻńĪ«õĮŹńĮ«
4’╝ēńäČÕÉÄÕłåÕł½Õ»╣Ķ┐ÖõĖżķā©ÕłåĶ«░ÕĮĢńö©ÕÉīµĀĘńÜäµ¢╣µ│Ģń╗¦ń╗ŁĶ┐øĶĪīµÄÆÕ║Å’╝īńø┤Õł░µĢ┤õĖ¬Õ║ÅÕłŚµ£ēÕ║ÅŃĆé
Õłåµ×É’╝Ü
Õ┐½ķƤµÄÆÕ║ŵś»ķĆÜÕĖĖĶó½Ķ«żõĖ║Õ£©ÕÉīµĢ░ķćÅń║¦’╝łO(nlog2n)’╝ēńÜäµÄÆÕ║ŵ¢╣µ│ĢõĖŁÕ╣│ÕØćµĆ¦ĶāĮµ£ĆÕźĮńÜäŃĆéõĮåĶŗźÕłØÕ¦ŗÕ║ÅÕłŚµīēÕģ│ķö«ńĀüµ£ēÕ║ŵł¢Õ¤║µ£¼µ£ēÕ║ŵŚČ’╝īÕ┐½µÄÆÕ║ÅÕÅŹĶĆīĶ£ĢÕī¢õĖ║ÕåƵ│ĪµÄÆÕ║ÅŃĆéõĖ║µö╣Ķ┐øõ╣ŗ’╝īķĆÜÕĖĖõ╗źŌĆ£õĖēĶĆģÕÅ¢õĖŁµ│ĢŌĆØµØźķĆēÕÅ¢Õ¤║ÕćåĶ«░ÕĮĢ’╝īÕŹ│Õ░åµÄÆÕ║ÅÕī║ķŚ┤ńÜäõĖżõĖ¬ń½»ńé╣õĖÄõĖŁńé╣õĖēõĖ¬Ķ«░ÕĮĢÕģ│ķö«ńĀüÕ▒ģõĖŁńÜäĶ░āµĢ┤õĖ║µö»ńé╣Ķ«░ÕĮĢŃĆéÕ┐½ķƤµÄÆÕ║ŵś»õĖĆõĖ¬õĖŹń©│Õ«ÜńÜäµÄÆÕ║ŵ¢╣µ│ĢŃĆé
’╝ł6’╝ēÕĖīÕ░öµÄÆÕ║Å
ÕĖīÕ░öµÄÆÕ║ÅÕÅłÕŽń╝®Õ░ÅÕó×ķćŵÄÆÕ║Å
Õ¤║µ£¼µĆصā│’╝Ü
ÕģłÕ░åµĢ┤õĖ¬ÕŠģµÄÆÕ║ÅńÜäĶ«░ÕĮĢÕ║ÅÕłŚÕłåÕē▓µłÉõĖ║ĶŗźÕ╣▓ÕŁÉÕ║ÅÕłŚÕłåÕł½Ķ┐øĶĪīńø┤µÄźµÅÆÕģźµÄÆÕ║Å’╝īÕŠģµĢ┤õĖ¬Õ║ÅÕłŚõĖŁńÜäĶ«░ÕĮĢŌĆ£Õ¤║µ£¼µ£ēÕ║ÅŌĆصŚČ’╝īÕåŹÕ»╣Õģ©õĮōĶ«░ÕĮĢĶ┐øĶĪīõŠØµ¼Īńø┤µÄźµÅÆÕģźµÄÆÕ║ÅŃĆé
µōŹõĮ£µ¢╣µ│Ģ’╝Ü
- ķĆēµŗ®õĖĆõĖ¬Õó×ķćÅÕ║ÅÕłŚt1’╝īt2’╝īŌĆ”’╝ītk’╝īÕģČõĖŁti>tj’╝ītk=1’╝ø┬Ā
- µīēÕó×ķćÅÕ║ÅÕłŚõĖ¬µĢ░k’╝īÕ»╣Õ║ÅÕłŚĶ┐øĶĪīk ĶȤµÄÆÕ║Å’╝ø┬Ā
- µ»ÅĶȤµÄÆÕ║Å’╝īµĀ╣µŹ«Õ»╣Õ║öńÜäÕó×ķćÅti’╝īÕ░åÕŠģµÄÆÕ║ÅÕłŚÕłåÕē▓µłÉĶŗźÕ╣▓ķĢ┐Õ║”õĖ║m ńÜäÕŁÉÕ║ÅÕłŚ’╝īÕłåÕł½Õ»╣ÕÉäÕŁÉĶĪ©Ķ┐øĶĪīńø┤µÄźµÅÆÕģźµÄÆÕ║ÅŃĆéõ╗ģÕó×ķćÅÕøĀÕŁÉõĖ║1 µŚČ’╝īµĢ┤õĖ¬Õ║ÅÕłŚõĮ£õĖ║õĖĆõĖ¬ĶĪ©µØźÕżäńÉå’╝īĶĪ©ķĢ┐Õ║”ÕŹ│õĖ║µĢ┤õĖ¬Õ║ÅÕłŚńÜäķĢ┐Õ║”ŃĆé
- ń«Śµ│ĢÕ«×ńÄ░’╝ܵłæõ╗¼ń«ĆÕŹĢÕżäńÉåÕó×ķćÅÕ║ÅÕłŚ’╝ÜÕó×ķćÅÕ║ÅÕłŚd = {n/2 ,n/4, n/8 .....1}┬ĀnõĖ║Ķ”üµÄÆÕ║ŵĢ░ńÜäõĖ¬µĢ░ ’╝īÕŹ│’╝ÜÕģłÕ░åĶ”üµÄÆÕ║ÅńÜäõĖĆń╗äĶ«░ÕĮĢµīēµ¤ÉõĖ¬Õó×ķćÅd’╝łn/2,nõĖ║Ķ”üµÄÆÕ║ŵĢ░ńÜäõĖ¬µĢ░’╝ēÕłåµłÉĶŗźÕ╣▓ń╗äÕŁÉÕ║ÅÕłŚ’╝īµ»Åń╗äõĖŁĶ«░ÕĮĢńÜäõĖŗµĀćńøĖÕĘ«d.Õ»╣µ»Åń╗äõĖŁÕģ©ķā©Õģāń┤ĀĶ┐øĶĪīńø┤µÄźµÅÆÕģźµÄÆÕ║Å’╝īńäČÕÉÄÕåŹńö©õĖĆõĖ¬ĶŠāÕ░ÅńÜäÕó×ķćÅ’╝łd/2’╝ēÕ»╣Õ«āĶ┐øĶĪīÕłåń╗ä’╝īÕ£©µ»Åń╗äõĖŁÕåŹĶ┐øĶĪīńø┤µÄźµÅÆÕģźµÄÆÕ║ÅŃĆéń╗¦ń╗ŁõĖŹµ¢Łń╝®Õ░ÅÕó×ķćÅńø┤Ķć│õĖ║1’╝īµ£ĆÕÉÄõĮ┐ńö©ńø┤µÄźµÅÆÕģźµÄÆÕ║ÅÕ«īµłÉµÄÆÕ║ÅŃĆé
- ń«Śµ│ĢõĖŹń©│Õ«Ü’╝īõĖöµĢłńÄćõĖ║O(n1.3)
’╝ł7’╝ēÕĮÆÕ╣ȵÄÆÕ║Å
Õ¤║µ£¼µĆصā│’╝Ü
┬Ā
ÕĮÆÕ╣Č’╝łMerge’╝ēµÄÆÕ║ŵ│Ģµś»Õ░åõĖżõĖ¬’╝łµł¢õĖżõĖ¬õ╗źõĖŖ’╝ēµ£ēÕ║ÅĶĪ©ÕÉłÕ╣ȵłÉõĖĆõĖ¬µ¢░ńÜäµ£ēÕ║ÅĶĪ©’╝īÕŹ│µŖŖÕŠģµÄÆÕ║ÅÕ║ÅÕłŚÕłåõĖ║ĶŗźÕ╣▓õĖ¬ÕŁÉÕ║ÅÕłŚ’╝īµ»ÅõĖ¬ÕŁÉÕ║ÅÕłŚµś»µ£ēÕ║ÅńÜäŃĆéńäČÕÉÄÕåŹµŖŖµ£ēÕ║ÅÕŁÉÕ║ÅÕłŚÕÉłÕ╣ČõĖ║µĢ┤õĮōµ£ēÕ║ÅÕ║ÅÕłŚŃĆéń«Śµ│Ģń©│Õ«Ü’╝īõĖöµĢłńÄćõĖ║O(nlogn)
’╝ł8’╝ēÕ¤║µĢ░µÄÆÕ║Å
Õ¤║µ£¼µĆصā│’╝ܵś»Õ░åķśĄÕłŚÕłåÕł░µ£ēķÖɵĢ░ķćÅńÜäµĪČÕŁÉķćīŃĆéµ»ÅõĖ¬µĪČÕŁÉÕåŹõĖ¬Õł½µÄÆÕ║Å’╝łµ£ēÕÅ»ĶāĮÕåŹõĮ┐ńö©Õł½ńÜäµÄÆÕ║Åń«Śµ│Ģµł¢µś»õ╗źķĆÆÕø×µ¢╣Õ╝Åń╗¦ń╗ŁõĮ┐ńö©µĪȵÄÆÕ║ÅĶ┐øĶĪīµÄÆÕ║Å’╝ēŃĆéµĪȵÄÆÕ║ŵś»ķĖĮÕĘóµÄÆÕ║ÅńÜäõĖĆń¦ŹÕĮÆń║│ń╗ōµ×£ŃĆéÕĮōĶ”üĶó½µÄÆÕ║ÅńÜäķśĄÕłŚÕåģńÜäµĢ░ÕĆ╝µś»ÕØćÕīĆÕłåķģŹńÜ䵌ČÕĆÖ’╝īµĪȵÄÆÕ║ÅõĮ┐ńö©ń║┐µĆ¦µŚČķŚ┤’╝ł╬ś’╝łn’╝ē’╝ēŃĆéń«Śµ│Ģń©│Õ«Ü’╝īõĖöµĢłńÄćõĖ║O(n+r).
┬Ā4.µ¤źµēŠń«Śµ│Ģ
ķĪ║Õ║ŵ¤źµēŠŃĆüõ║īÕłåµ¤źµēŠŃĆüõ║īÕÅēµĀ浤źµēŠŃĆüń┤óÕ╝Ģµ¤źµēŠŃĆüÕ╝ƵöŠÕ£░ÕØĆhashµ¤źµēŠŃĆüµŗēķōŠÕÅæhashµ¤źµēŠ



ńøĖÕģ│µÄ©ĶŹÉ
ÕŠłÕģ©ńÜäµĢ░µŹ«ń╗ōµ×äÕżŹõ╣ĀĶĄäµ¢Ö Õɽµ©Īµŗ¤ķóśõ╗źÕÅŖńŁöµĪł
õ╗ģõŠøµĢ░µŹ«ń╗ōµ×äÕżŹõ╣ĀõĮ┐ńö©’╝īõŠŗÕ”éń¤źĶ»åńé╣ 1.µĢ░µŹ«Õģāń┤Āµś»µĢ░µŹ«ńÜäÕ¤║µ£¼ÕŹĢõĮŹŃĆé 2.µĢ░µŹ«ķĪ╣µś»ń╗䵳ɵĢ░µŹ«Õģāń┤ĀńÜäŃĆüµ£ēńŗ¼ń½ŗÕɽõ╣ēńÜäŃĆüõĖŹÕÅ»ÕłåÕē▓ńÜäµ£ĆÕ░ÅÕŹĢõĮŹŃĆé 3.µĢ░µŹ«ń╗ōµ×䵜»ńøĖõ║Æõ╣ŗķŚ┤ÕŁśÕ£©õĖĆń¦Źµł¢ÕżÜń¦Źńē╣Õ«ÜÕģ│ń│╗ńÜäµĢ░µŹ«Õģāń┤ĀńÜäķøåÕÉłŃĆéÕ«āÕīģµŗ¼ķĆ╗ĶŠæń╗ōµ×äÕÆī...
µĢ░µŹ«ń╗ōµ×äÕżŹõ╣ĀĶĄäµ¢ÖÕÅŖĶ»ĢÕŹĘ’╝łc++ńēł’╝ē’╝īµ£ēÕżŹõ╣ĀĶĄäµ¢ÖÕÆīÕŹüÕźŚĶ»ĢÕŹĘÕÅŖńŁöµĪł’╝īĶĮ»õ╗ČÕĘźń©ŗõĖōõĖÜÕÆīĶ«Īń«Śµ£║õĖōõĖÜńÜäń”ÅÕł®µØźõ║åŃĆé
Õż¦ÕŁ”ńö¤µĢ░µŹ«ń╗ōµ×äÕżŹõ╣ĀķóśÕŹüÕźŚÕŹĘ(ÕɽńŁöµĪł)
µĢ░µŹ«ń╗ōµ×äÕżŹõ╣ĀÕż¦ń║▓ µĢ░µŹ«ń╗ōµ×äĶĆāĶ»ĢÕż¦ń║▓ ’╝łõŠøĶĆāĶ»ĢõĮ┐ńö©’╝ē
02331µĢ░µŹ«ń╗ōµ×äÕżŹõ╣ĀķóśÕÅŖńŁöµĪł ÕżŹõ╣ĀńÜäµŖōń┤¦’╝īÕżŹõ╣ĀńÜäµŖōń┤¦’╝īÕżŹõ╣ĀńÜäµŖōń┤¦’╝īÕżŹõ╣ĀńÜäµŖōń┤¦
µĢ░µŹ«ń╗ōµ×äÕżŹõ╣ĀµĢ░µŹ«ń╗ōµ×äÕżŹõ╣ĀµĢ░µŹ«ń╗ōµ×äÕżŹõ╣ĀµĢ░µŹ«ń╗ōµ×äÕżŹõ╣Ā
µĢ░µŹ«ń╗ōµ×äÕżŹõ╣ĀĶĄäµ¢Ö’╝īµĢ┤ńÉåõ║åÕżÜń»ćµ¢ćµĪŻ’╝īķøåÕÉłõ║åÕŠłÕżÜõ║║ńÜäµÖ║µģ¦ŃĆé
µĢ░µŹ«ń╗ōµ×äÕżŹõ╣Āppt ÕŹÄõĖŁń¦æµŖĆÕż¦ÕŁ”Ķ«Īń«Śµ£║ÕŁ”ķÖó
µĢ░µŹ«ń╗ōµ×äÕżŹõ╣ĀĶĄäµ¢Ö µĢ░µŹ«ń╗ōµ×äÕżŹõ╣ĀĶĄäµ¢Ö µĢ░µŹ«ń╗ōµ×äÕżŹõ╣ĀµĆ╗ĶĄäµ¢Ö
µĢ░µŹ«ń╗ōµ×äÕżŹõ╣Āń¼öĶ«░-ÕøŠńÜäµĢ░ń╗ä(ķé╗µÄźń¤®ķśĄ)ÕŁśÕé©ĶĪ©ńż║ÕÅŖķćŹĶ”üńÜäÕ¤║µ£¼µōŹõĮ£
µĢ░µŹ«ń╗ōµ×äÕżŹõ╣ĀķóśµĢ┤ńÉå’╝łķÖäńŁöµĪł’╝ē.doc
µĢ░µŹ«ń╗ōµ×äÕżŹõ╣ĀķćŹńé╣ÕĮÆń║│ń¼öĶ«░[µĖģÕŹÄõĖźĶöܵĢÅńēł]
µĢ░µŹ«ń╗ōµ×äÕżŹõ╣ĀõĮ£õĖÜÕÅŖńŁöµĪł’╝īõŠøµ£¤µ£½ĶĆāĶ»ĢÕżŹõ╣ĀõĮ┐ńö©ŃĆéµĢ░µŹ«ń╗ōµ×äÕżŹõ╣ĀõĮ£õĖÜÕÅŖńŁöµĪł’╝īõŠøµ£¤µ£½ĶĆāĶ»ĢÕżŹõ╣ĀõĮ┐ńö©ŃĆéµĢ░µŹ«ń╗ōµ×äÕżŹõ╣ĀõĮ£õĖÜÕÅŖńŁöµĪł’╝īõŠøµ£¤µ£½ĶĆāĶ»ĢÕżŹõ╣ĀõĮ┐ńö©ŃĆé
µĢ░µŹ«ń╗ōµ×äÕżŹõ╣ĀµĢ░µŹ«ń╗ōµ×äÕżŹõ╣ĀµĢ░µŹ«ń╗ōµ×äÕżŹõ╣ĀµĢ░µŹ«ń╗ōµ×äÕżŹõ╣Ā
µĢ░µŹ«ń╗ōµ×äÕżŹõ╣ĀĶ”üńé╣(µĢ┤ńÉåńēł).pdf
µĢ░µŹ«ń╗ōµ×äÕżŹõ╣ĀķćŹńé╣ÕĮÆń║│ń¼öĶ«░[µĖģÕŹÄõĖźĶöܵĢÅńēł].doc
µĖģÕŹÄĶ«Īń«Śµ£║ĶĆāńĀöµĢ░µŹ«ń╗ōµ×äÕżŹõ╣ĀµÅÉĶ”ü’╝īµ£ēÕŖ®õ║ÄÕĖ«ÕŖ®ÕżŹõ╣Ā’╝īńÉåµĖģµĆØĶĘ»’╝īÕż¦Õ«ČÕģ▒ÕÉīÕŁ”õ╣Ā
µĢ░µŹ«ń╗ōµ×äÕżŹõ╣Āķóś’╝īÕØćõĖ║ĶĆāĶ»ĢķóśÕ×ŗ,ÕīģÕɽń«ĆµśōńÜäńŁöµĪł’╝īCĶ»ŁĶ©Ćµ×äķĆĀõĮōń│╗Õī¢’╝īµĀ╝Õ╝ÅĶ”üµ▒éõĖźµĀ╝ŃĆé