
Martin FowlerжңҖиҝ‘зҡ„дёҖзҜҮж–Үз« пјҡLMAXжһ¶жһ„гҖӮ
LMAXжҳҜдёҖз§Қж–°еһӢйӣ¶е”®йҮ‘иһҚдәӨжҳ“е№іеҸ°пјҢе®ғиғҪеӨҹд»ҘеҫҲдҪҺзҡ„延иҝҹ(latency)дә§з”ҹеӨ§йҮҸдәӨжҳ“(еҗһеҗҗйҮҸ). иҝҷдёӘзі»з»ҹжҳҜе»әз«ӢеңЁJVMе№іеҸ°дёҠпјҢж ёеҝғжҳҜдёҖдёӘдёҡеҠЎйҖ»иҫ‘еӨ„зҗҶеҷЁпјҢе®ғиғҪеӨҹеңЁдёҖдёӘзәҝзЁӢйҮҢжҜҸз§’еӨ„зҗҶ6зҷҫдёҮи®ўеҚ•. дёҡеҠЎйҖ»иҫ‘еӨ„зҗҶеҷЁе®Ңе…ЁжҳҜиҝҗиЎҢеңЁеҶ…еӯҳдёӯ(in-memory)пјҢдҪҝз”ЁдәӢ件жәҗй©ұеҠЁж–№ејҸ(event sourcing). дёҡеҠЎйҖ»иҫ‘еӨ„зҗҶеҷЁзҡ„ж ёеҝғжҳҜDisruptorsпјҢиҝҷжҳҜдёҖдёӘ并еҸ‘组件пјҢиғҪеӨҹеңЁж— й”Ғзҡ„жғ…еҶөдёӢе®һзҺ°зҪ‘з»ңзҡ„Queue并еҸ‘ж“ҚдҪңгҖӮ他们зҡ„з ”з©¶иЎЁжҳҺпјҢзҺ°еңЁзҡ„жүҖи°“й«ҳжҖ§иғҪз ”з©¶ж–№еҗ‘дјјд№Һе’ҢзҺ°д»ЈCPUи®ҫи®ЎжҳҜзӣёе·Ұзҡ„гҖӮ(и§ҒеҸҰеӨ–дёҖзҜҮж–Үз« пјҡJVMдјӘе…ұдә«)
иҝҮ еҺ»еҮ е№ҙжҲ‘们дёҚж–ӯжҸҗдҫӣиҝҷж ·еЈ°йҹіпјҡе…Қиҙ№еҚҲйӨҗе·Із»Ҹз»“жқҹгҖӮжҲ‘们дёҚеҶҚиғҪжңҹжңӣеңЁеҚ•дёӘCPUдёҠиҺ·еҫ—жӣҙеҝ«зҡ„жҖ§иғҪпјҢеӣ жӯӨжҲ‘们йңҖиҰҒеҶҷдҪҝз”ЁеӨҡж ёеӨ„зҗҶзҡ„并еҸ‘иҪҜ件пјҢдёҚе№ёзҡ„жҳҜпјҢ зј–еҶҷ并еҸ‘иҪҜ件жҳҜеҫҲйҡҫзҡ„пјҢй”Ғе’ҢдҝЎеҸ·йҮҸжҳҜеҫҲйҡҫзҗҶи§Јзҡ„е’Ңйҡҫд»ҘжөӢиҜ•пјҢиҝҷж„Ҹе‘ізқҖжҲ‘们иҰҒиҠұжӣҙеӨҡж—¶й—ҙеңЁи®Ўз®—жңәдёҠпјҢиҖҢдёҚжҳҜжҲ‘们зҡ„йўҶеҹҹй—®йўҳпјҢеҗ„з§Қ并еҸ‘жЁЎеһӢпјҢеҰӮActors е’ҢиҪҜдәӢеҠЎSTM(Software Transactional Memory), зӣ®зҡ„жҳҜжӣҙеҠ е®№жҳ“дҪҝз”ЁпјҢдҪҶжҳҜжҢүдёӢи‘«иҠҰйЈҳиө·з“ўпјҢиҝҳжҳҜеёҰжқҘдәҶbugsе’ҢеӨҚжқӮжҖ§.
жҲ‘ еҫҲжғҠ讶еҗ¬еҲ°еҺ»е№ҙ3жңҲQConдёҠдёҖдёӘжј”и®ІпјҢ LMAXжҳҜдёҖз§Қж–°зҡ„йӣ¶е”®зҡ„йҮ‘иһҚдәӨжҳ“е№іеҸ°гҖӮе®ғзҡ„дёҡеҠЎеҲӣж–° - е…Ғи®ёд»»дҪ•дәәеңЁдёҖзі»еҲ—зҡ„йҮ‘иһҚиЎҚз”ҹдә§е“ҒдәӨжҳ“гҖӮиҝҷе°ұйңҖиҰҒйқһеёёдҪҺзҡ„延иҝҹпјҢйқһеёёеҝ«йҖҹзҡ„еӨ„зҗҶпјҢеӣ дёәеёӮеңәеҸҳеҢ–еҫҲеҝ«пјҢиҝҷдёӘйӣ¶е”®е№іеҸ°еӣ дёәжңүеҫҲеӨҡдәәеҗҢж—¶ж“ҚдҪңиҮӘ然具еӨҮдәҶеӨҚжқӮжҖ§пјҢ з”ЁжҲ·и¶ҠеӨҡпјҢдәӨжҳ“йҮҸи¶ҠеӨ§пјҢдёҚж–ӯеҝ«йҖҹеўһй•ҝгҖӮ
йүҙдәҺеӨҡж ёеҝғжҖқжғізҡ„иҪ¬еҸҳпјҢиҝҷз§ҚиӢӣеҲ»зҡ„жҖ§иғҪиҮӘ然дјҡжҸҗеҮәдёҖдёӘжҳҺзЎ®зҡ„并иЎҢзј–зЁӢжЁЎеһӢ пјҢдҪҶжҳҜ他们еҚҙжҸҗеҮәз”ЁдёҖдёӘзәҝзЁӢеӨ„зҗҶ6зҷҫдёҮи®ўеҚ•пјҢиҖҢдё”жҳҜжҜҸз§’пјҢеңЁйҖҡз”Ёзҡ„硬件дёҠгҖӮ
йҖҡиҝҮдҪҺ延иҝҹеӨ„зҗҶеӨ§йҮҸдәӨжҳ“пјҢеҸ–еҫ—дҪҺ延иҝҹе’Ңй«ҳеҗһеҗҗйҮҸпјҢиҖҢдё”жІЎжңү并еҸ‘д»Јз Ғзҡ„еӨҚжқӮжҖ§пјҢ他们жҳҜжҖҺд№ҲеҒҡеҲ°е‘ўпјҹзҺ°еңЁLMAXе·Із»Ҹдә§е“ҒеҢ–дёҖж®өж—¶й—ҙдәҶпјҢзҺ°еңЁеә”иҜҘеҸҜд»ҘжҸӯејҖе…¶зҘһз§ҳиҖҢиҝ·дәәзҡ„йқўзәұдәҶгҖӮ
з»“жһ„еҰӮеӣҫпјҡ
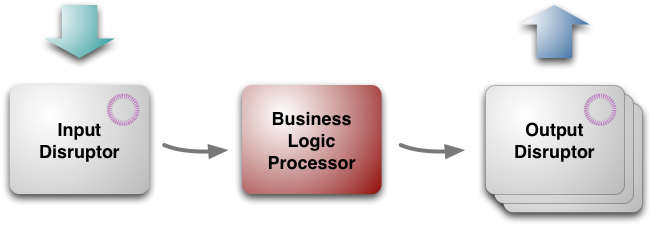
д»ҺжңҖй«ҳеұӮж¬ЎзңӢпјҢжһ¶жһ„жңүдёүдёӘйғЁеҲҶпјҡ
дёҡеҠЎйҖ»иҫ‘еӨ„зҗҶеҷЁbusiness logic processor[5]
иҫ“е…Ҙinput disruptor
иҫ“еҮәoutput disruptors
дёҡеҠЎйҖ»иҫ‘еӨ„зҗҶеҷЁеӨ„зҗҶжүҖжңүзҡ„еә”з”ЁзЁӢеәҸзҡ„дёҡеҠЎйҖ»иҫ‘пјҢиҝҷжҳҜдёҖдёӘеҚ•зәҝзЁӢзҡ„JavaзЁӢеәҸпјҢзәҜзІ№зҡ„ж–№жі•и°ғз”ЁпјҢ并иҝ”еӣһиҫ“еҮәгҖӮдёҚйңҖиҰҒд»»дҪ•е№іеҸ°жЎҶжһ¶пјҢиҝҗиЎҢеңЁJVMйҮҢпјҢиҝҷе°ұдҝқиҜҒе…¶еҫҲе®№жҳ“иҝҗиЎҢжөӢиҜ•зҺҜеўғгҖӮ
дёҡеҠЎйҖ»иҫ‘еӨ„зҗҶеҷЁ
е…ЁйғЁй©»з•ҷеңЁеҶ…еӯҳдёӯ
дёҡеҠЎйҖ»иҫ‘еӨ„зҗҶеҷЁжңүж¬ЎеәҸең°еҸ–еҮәж¶ҲжҒҜпјҢ然еҗҺиҝҗиЎҢе…¶дёӯзҡ„дёҡеҠЎйҖ»иҫ‘пјҢ然еҗҺдә§з”ҹиҫ“еҮәдәӢ件пјҢж•ҙдёӘж“ҚдҪңйғҪжҳҜеңЁеҶ…еӯҳдёӯпјҢжІЎжңүж•°жҚ®еә“жҲ–е…¶д»–жҢҒд№…еӯҳеӮЁгҖӮе°ҶжүҖжңүж•°жҚ®й©»з•ҷеңЁеҶ…еӯҳдёӯжңүдёӨдёӘйҮҚиҰҒеҘҪеӨ„пјҡйҰ–е…ҲжҳҜеҝ«пјҢжІЎжңүIOпјҢд№ҹжІЎжңүдәӢеҠЎпјҢе…¶ж¬ЎжҳҜз®ҖеҢ–зј–зЁӢпјҢжІЎжңүеҜ№иұЎ/е…ізі»ж•°жҚ®еә“зҡ„жҳ е°„пјҢжүҖжңүд»Јз ҒйғҪжҳҜдҪҝз”ЁJavaеҜ№иұЎжЁЎеһӢ(е№ҝе‘ҠпјҡејҖжәҗжЎҶжһ¶Jdonframeworkе’ҢJiveJdonд№ҹжҳҜе…ЁйғЁеҹәдәҺеҶ…еӯҳе’ҢдәӢ件жәҗпјҢеҶ…еӯҳйўҶеҹҹеҜ№иұЎ+дәӢ件й©ұеҠЁпјҢзңӢжқҘиҝҷжқЎи·Ҝзҡ„ж–№еҗ‘жҳҜеҜ№зҡ„)гҖӮ
дҪҝз”ЁеҹәдәҺеҶ…еӯҳзҡ„жЁЎеһӢжңүдёҖдёӘйҮҚиҰҒй—®йўҳпјҡдёҮдёҖеҙ©жәғжҖҺд№ҲеҠһпјҹз”өжәҗжҺүз”өд№ҹжҳҜеҸҜиғҪеҸ‘з”ҹзҡ„пјҢвҖңдәӢ件вҖқ(Event Sourcing )жҰӮеҝөжҳҜй—®йўҳи§ЈеҶізҡ„ж ёеҝғпјҢдёҡеҠЎйҖ»иҫ‘еӨ„зҗҶеҷЁзҡ„зҠ¶жҖҒжҳҜз”ұиҫ“е…ҘдәӢ件й©ұеҠЁзҡ„пјҢеҸӘиҰҒиҝҷдәӣиҫ“е…ҘдәӢ件被жҢҒд№…еҢ–дҝқеӯҳиө·жқҘпјҢдҪ е°ұжҖ»жҳҜиғҪеӨҹеңЁеҙ©жәғжғ…еҶөдёӢпјҢж №жҚ®дәӢ件йҮҚжј”йҮҚж–°иҺ·еҫ—еҪ“еүҚзҠ¶жҖҒгҖӮ(NOSQLеӯҳеӮЁзҡ„еҹәдәҺдәӢ件зҡ„дәӢеҠЎе®һзҺ°)
иҰҒеҫҲеҘҪзҗҶи§ЈиҝҷзӮ№еҸҜд»ҘйҖҡиҝҮзүҲжң¬жҺ§еҲ¶зі»з»ҹжқҘзҗҶи§ЈпјҢзүҲжң¬жҺ§еҲ¶зі»з»ҹжҸҗдәӨзҡ„еәҸеҲ—пјҢеңЁд»»дҪ•ж—¶еҖҷпјҢдҪ еҸҜд»Ҙе»әз«Ӣз”ұз”іиҜ·иҖ…жҸҗдәӨдёҖдёӘе·ҘдҪңжӢ·иҙқпјҢзүҲжң¬жҺ§еҲ¶зі»з»ҹжҳҜдёҖдёӘеӨҚжқӮзҡ„е•ҶдёҡйҖ»иҫ‘еӨ„зҗҶеҷЁпјҢиҖҢиҝҷйҮҢзҡ„дёҡеҠЎйҖ»иҫ‘еӨ„зҗҶеҸӘжҳҜдёҖдёӘз®ҖеҚ•зҡ„еәҸеҲ—гҖӮ
еӣ жӯӨпјҢд»ҺзҗҶи®әдёҠи®ІпјҢдҪ жҖ»жҳҜеҸҜд»ҘйҖҡиҝҮеҗҺеӨ„зҗҶзҡ„жүҖжңүдәӢ件зҡ„е•ҶдёҡйҖ»иҫ‘еӨ„зҗҶеҷЁйҮҚе»әзҡ„зҠ¶жҖҒпјҢдҪҶжҳҜе®һи·өдёӯйҮҚе»әжүҖжңүдәӢ件жҳҜиҖ—ж—¶зҡ„пјҢйңҖиҰҒеҲҮеҲҶпјҢLMAXжҸҗдҫӣдёҡеҠЎйҖ»иҫ‘еӨ„зҗҶзҡ„еҝ«з…§пјҢд»Һеҝ«з…§иҝҳеҺҹпјҢжҜҸеӨ©жҷҡдёҠзі»з»ҹдёҚз№Ғеҝҷж—¶жһ„е»әеҝ«з…§пјҢйҮҚж–°еҗҜеҠЁе•ҶдёҡйҖ»иҫ‘еӨ„зҗҶеҷЁзҡ„йҖҹеәҰеҫҲеҝ«пјҢдёҖдёӘе®Ңж•ҙзҡ„йҮҚж–°еҗҜеҠЁ - еҢ…жӢ¬йҮҚж–°еҗҜеҠЁJVMеҠ иҪҪжңҖиҝ‘зҡ„еҝ«з…§пјҢе’ҢйҮҚж”ҫдёҖеӨ©дәӢ件 - дёҚеҲ°дёҖеҲҶй’ҹгҖӮ
еҝ«з…§иҷҪ然дҪҝеҗҜеҠЁдёҖдёӘж–°зҡ„дёҡеҠЎйҖ»иҫ‘еӨ„зҗҶеҷЁзҡ„йҖҹеәҰпјҢдҪҶйҖҹеәҰиҝҳдёҚеӨҹеҝ«пјҢдёҡеҠЎйҖ»иҫ‘еӨ„зҗҶеҷЁеңЁдёӢеҚҲ2ж—¶е°ұйқһеёёз№Ғеҝҷз”ҡиҮіеҙ©жәғпјҢLMAXе°ұдҝқжҢҒеӨҡдёӘдёҡеҠЎйҖ»иҫ‘еӨ„зҗҶеҷЁеҗҢж—¶иҝҗиЎҢпјҢжҜҸдёӘиҫ“е…ҘдәӢ件з”ұеӨҡдёӘеӨ„зҗҶеҷЁеӨ„зҗҶпјҢеҸӘжңүдёҖдёӘеӨ„зҗҶеҷЁиҫ“еҮәжңүж•ҲпјҢе…¶д»–еҝҪз•ҘпјҢеҰӮжһңдёҖдёӘеӨ„зҗҶеҷЁеӨұиҙҘпјҢеҲҮжҚўеҲ°еҸҰеӨ–дёҖдёӘпјҢиҝҷз§Қж•…йҡңиҪ¬з§»еӨұиҙҘжҒўеӨҚжҳҜдәӢ件жәҗй©ұеҠЁ(Event Sourcing)зҡ„еҸҰеӨ–дёҖдёӘеҘҪеӨ„гҖӮ
йҖҡиҝҮдәӢ件й©ұеҠЁ(event sourcing)他们д№ҹеҸҜд»ҘеңЁеӨ„зҗҶеҷЁд№Ӣй—ҙд»Ҙеҫ®з§’йҖҹеәҰеҲҮжҚўпјҢжҜҸжҷҡеҲӣе»әеҝ«з…§пјҢжҜҸжҷҡйҮҚеҗҜдёҡеҠЎйҖ»иҫ‘еӨ„зҗҶеҷЁпјҢ иҝҷз§ҚеӨҚеҲ¶ж–№ејҸиғҪеӨҹдҝқиҜҒ他们没жңүеҪ“жңәж—¶й—ҙпјҢе®һзҺ°24/7.
дәӢ件方ејҸжҳҜжңүд»·еҖјзҡ„еӣ дёәе®ғе…Ғи®ёеӨ„зҗҶеҷЁеҸҜд»Ҙе®Ңе…ЁеңЁеҶ…еӯҳдёӯиҝҗиЎҢпјҢдҪҶе®ғжңүеҸҰдёҖз§Қз”ЁдәҺиҜҠж–ӯзӣёеҪ“еӨ§зҡ„дјҳеҠҝпјҡеҰӮжһңеҮәзҺ°дёҖдәӣж„ҸжғідёҚеҲ°зҡ„иЎҢдёәпјҢдәӢ件еүҜжң¬д»¬иғҪеӨҹ让他们еңЁејҖеҸ‘зҺҜеўғйҮҚж”ҫз”ҹдә§зҺҜеўғзҡ„дәӢ件пјҢиҝҷе°ұе®№жҳ“дҪҝ他们иғҪеӨҹз ”з©¶е’ҢеҸ‘зҺ°еҮәеңЁз”ҹдә§зҺҜеўғеҲ°еә•еҸ‘з”ҹдәҶд»Җд№ҲдәӢгҖӮ
иҝҷ з§ҚиҜҠж–ӯиғҪеҠӣ延伸еҲ°дёҡеҠЎиҜҠж–ӯгҖӮжңүдёҖдәӣдјҒдёҡзҡ„д»»еҠЎпјҢеҰӮеңЁйЈҺйҷ©з®ЎзҗҶпјҢйңҖиҰҒеӨ§йҮҸзҡ„и®Ўз®—пјҢдҪҶжҳҜдёҚеӨ„зҗҶи®ўеҚ•гҖӮдёҖдёӘдҫӢеӯҗжҳҜж №жҚ®е…¶зӣ®еүҚзҡ„дәӨжҳ“еӨҙеҜёзҡ„йЈҺйҷ©зҠ¶еҶөжҺ’еҗҚеүҚ20дҪҚе®ў жҲ·еҗҚеҚ•пјҢ他们е°ұеҸҜд»ҘеҲҮеҲҶеҲ°еӨҚеҲ¶еҘҪзҡ„йўҶеҹҹжЁЎеһӢдёӯиҝӣиЎҢи®Ўз®—пјҢиҖҢдёҚжҳҜеңЁз”ҹдә§зҺҜеўғдёӯжӯЈеңЁиҝҗиЎҢзҡ„йўҶеҹҹжЁЎеһӢпјҢдёҚеҗҢжҖ§иҙЁзҡ„йўҶеҹҹжЁЎеһӢдҝқеӯҳеңЁдёҚеҗҢжңәеҷЁзҡ„еҶ…еӯҳдёӯпјҢеҪјжӯӨдёҚеҪұе“ҚгҖӮ
жҖ§иғҪдјҳеҢ–
жӯЈеҰӮжҲ‘и§ЈйҮҠпјҢдёҡеҠЎйҖ»иҫ‘еӨ„зҗҶеҷЁзҡ„жҖ§иғҪе…ій”®жҳҜжҢүйЎәеәҸең°еҒҡдәӢ(е…¶е®һ并дёҚж„ҡи ў 并иЎҢеҒҡе°ұиҒӘжҳҺеҗ—пјҹ)пјҢиҝҷеҸҜд»Ҙи®©жҷ®йҖҡејҖеҸ‘иҖ…еҶҷзҡ„д»Јз ҒеӨ„зҗҶ10K TPS. еҰӮжһңиғҪзІҫз®Җд»Јз ҒиғҪеӨҹеёҰжқҘ100K TPSжҸҗеҚҮ. иҝҷйңҖиҰҒиүҜеҘҪзҡ„д»Јз Ғе’Ңе°Ҹж–№жі•пјҢеҪ“然пјҢJVM Hotspotзҡ„зј“еӯҳеҫ®и°ғпјҢи®©е…¶жӣҙеҠ дјҳеҢ–д№ҹжҳҜеҝ…йЎ»зҡ„гҖӮ
д»ҘдёӢзңҒеҺ»дёӨж®ө.......и°ғиҜ•ж–№йқўгҖӮ
зј–зЁӢжЁЎеһӢ
д»Ҙ дёҖдёӘз®ҖеҚ•зҡ„йқһLMAXзҡ„дҫӢеӯҗжқҘиҜҙжҳҺгҖӮжғіиұЎдёҖдёӢпјҢдҪ жӯЈеңЁдёәзі–иұҶдҪҝз”ЁдҝЎз”ЁеҚЎдёӢи®ўеҚ•гҖӮдёҖдёӘз®ҖеҚ•зҡ„йӣ¶е”®зі»з»ҹе°ҶиҺ·еҸ–жӮЁзҡ„и®ўеҚ•дҝЎжҒҜпјҢдҪҝз”ЁдҝЎз”ЁеҚЎйӘҢиҜҒжңҚеҠЎпјҢд»ҘжЈҖжҹҘжӮЁзҡ„дҝЎ з”ЁеҚЎеҸ·з ҒпјҢ然еҗҺзЎ®и®ӨжӮЁзҡ„и®ўеҚ• - жүҖжңүиҝҷдәӣйғҪеңЁдёҖдёӘеҚ•дёҖиҝҮзЁӢдёӯж“ҚдҪңгҖӮеҪ“иҝӣиЎҢдҝЎз”ЁеҚЎжңүж•ҲжҖ§жЈҖжҹҘж—¶пјҢжңҚеҠЎеҷЁиҝҷиҫ№зҡ„зәҝзЁӢдјҡйҳ»еЎһзӯүеҫ…пјҢеҪ“然иҝҷдёӘеҜ№дәҺз”ЁжҲ·жқҘиҜҙеҒңйЎҝдёҚдјҡеӨӘй•ҝгҖӮ
еңЁMAXжһ¶жһ„дёӯпјҢдҪ е°ҶжӯӨеҚ•дёҖж“ҚдҪңиҝҮзЁӢеҲҶдёәдёӨдёӘпјҢ第дёҖйғЁеҲҶе°ҶиҺ·еҸ–и®ўеҚ•дҝЎжҒҜпјҢ然еҗҺиҫ“еҮәдәӢ件(иҜ·жұӮдҝЎз”ЁеҚЎжЈҖжҹҘжңүж•ҲжҖ§зҡ„иҜ·жұӮдәӢ件)з»ҷдҝЎз”ЁеҚЎе…¬еҸё. дёҡеҠЎйҖ»иҫ‘еӨ„зҗҶеҷЁе°Ҷ继з»ӯеӨ„зҗҶе…¶д»–е®ўжҲ·зҡ„и®ўеҚ•пјҢзӣҙиҮіе®ғеңЁиҫ“е…ҘдәӢ件дёӯеҸ‘зҺ°дәҶдҝЎз”ЁеҚЎе·Із»ҸжЈҖжҹҘжңүж•Ҳзҡ„дәӢ件пјҢ然еҗҺиҺ·еҸ–иҜҘдәӢ件жқҘзЎ®и®ӨиҜҘи®ўеҚ•жңүж•ҲгҖӮ
иҝҷз§ҚејӮжӯҘдәӢ件й©ұеҠЁж–№ејҸзЎ®е®һдёҚеҜ»еёёпјҢиҷҪ然дҪҝз”ЁејӮжӯҘжҸҗй«ҳеә”з”ЁзЁӢеәҸзҡ„е“Қеә”жҳҜдёҖдёӘзҶҹжӮүзҡ„жҠҖжңҜгҖӮе®ғиҝҳеҸҜд»Ҙеё®еҠ©дёҡеҠЎжөҒзЁӢжӣҙеј№жҖ§пјҢеӣ дёәдҪ еҝ…йЎ»иҰҒжӣҙжҳҺзЎ®зҡ„жҖқиҖғдёҺиҝңзЁӢеә”з”ЁзЁӢеәҸжү“дәӨйҒ“зҡ„дёҚеҗҢд№ӢеӨ„гҖӮ
иҝҷдёӘзј–зЁӢжЁЎеһӢ第дәҢдёӘзү№зӮ№еңЁдәҺй”ҷиҜҜеӨ„зҗҶгҖӮдј з»ҹжЁЎејҸдёӢдјҡиҜқе’Ңж•°жҚ®еә“дәӢеҠЎжҸҗдҫӣдәҶдёҖдёӘжңүз”Ёзҡ„й”ҷиҜҜеӨ„зҗҶиғҪеҠӣгҖӮеҰӮжһңжңүд»Җд№ҲеҮәй”ҷпјҢеҫҲе®№жҳ“жҠӣеҮәд»»дҪ•дёңиҘҝпјҢиҝҷдёӘдјҡиҜқиғҪеӨҹиў«дёўејғгҖӮеҰӮжһңдёҖдёӘй”ҷиҜҜеҸ‘з”ҹеңЁж•°жҚ®еә“з«ҜпјҢдҪ еҸҜд»Ҙеӣһж»ҡдәӢеҠЎгҖӮ
LMAXзҡ„еҶ…еӯҳжЁЎејҸ(in-memory structures)еңЁдәҺжҢҒд№…еҢ–иҫ“е…ҘдәӢ件пјҢеҰӮжһңжңүй”ҷиҜҜеҸ‘з”ҹд№ҹдёҚдјҡд»ҺеҶ…еӯҳдёӯзҰ»ејҖйҖ жҲҗдёҚдёҖиҮҙзҡ„зҠ¶жҖҒгҖӮдҪҶжҳҜеӣ дёәжІЎжңүеӣһж»ҡжңәеҲ¶пјҢLMAXжҠ•е…ҘдәҶжӣҙеӨҡзІҫеҠӣпјҢзЎ®дҝқиҫ“е…ҘдәӢ件еңЁе®һж–Ҫд»»дҪ•еҶ…еӯҳзҠ¶жҖҒеҪұе“ҚеүҚжңүж•Ҳең°жҢҒд№…еҢ–пјҢ他们еҸ‘зҺ°иҝҷдёӘе…ій”®жҳҜжөӢиҜ•пјҢеңЁиҝӣе…Ҙз”ҹдә§зҺҜеўғд№ӢеүҚе°ҪеҸҜиғҪеҸ‘зҺ°еҗ„з§Қй—®йўҳпјҢзЎ®дҝқжҢҒд№…еҢ–жңүж•ҲгҖӮ
иҪ¬пјҡhttp://www.jdon.com/42452



зӣёе…іжҺЁиҚҗ
Martin FowlerеңЁиҮӘе·ұзҪ‘з«ҷдёҠеҶҷдәҶдёҖзҜҮLMAXжһ¶жһ„зҡ„ж–Үз« пјҢеңЁж–Үз« дёӯд»–д»Ӣз»ҚдәҶLMAXжҳҜдёҖз§Қж–°еһӢйӣ¶е”®йҮ‘иһҚдәӨжҳ“е№іеҸ°пјҢе®ғиғҪеӨҹд»ҘеҫҲдҪҺзҡ„延иҝҹдә§з”ҹеӨ§йҮҸдәӨжҳ“гҖӮиҝҷдёӘзі»з»ҹжҳҜе»әз«ӢеңЁJVMе№іеҸ°дёҠпјҢе…¶ж ёеҝғжҳҜдёҖдёӘдёҡеҠЎйҖ»иҫ‘еӨ„зҗҶеҷЁпјҢе®ғиғҪеӨҹеңЁдёҖдёӘзәҝзЁӢ...
Martin FowlerеңЁиҮӘе·ұзҪ‘з«ҷдёҠеҶҷдәҶдёҖзҜҮLMAXжһ¶жһ„зҡ„ж–Үз« пјҢеңЁж–Үз« дёӯд»–д»Ӣз»ҚдәҶLMAXжҳҜдёҖз§Қж–°еһӢйӣ¶е”®йҮ‘иһҚдәӨжҳ“е№іеҸ°пјҢе®ғиғҪеӨҹд»ҘеҫҲдҪҺзҡ„延иҝҹдә§з”ҹеӨ§йҮҸдәӨжҳ“гҖӮиҝҷдёӘзі»з»ҹжҳҜе»әз«ӢеңЁJVMе№іеҸ°дёҠпјҢе…¶ж ёеҝғжҳҜдёҖдёӘдёҡеҠЎйҖ»иҫ‘еӨ„зҗҶеҷЁпјҢе®ғиғҪеӨҹеңЁдёҖдёӘзәҝзЁӢ...
LmaxжүҖжңүдә§е“Ғзҡ„жҳҺз»Ҷиө„ж–ҷпјҢдёҠдј иҖ…дәІиҮӘеҲ¶дҪңпјҢзӢ¬жӯӨдёҖ家еҲ«ж— еҲҶеҸ·гҖӮ
LMAXCollections, LMAXйӣҶеҗҲ LMAXйӣҶеҗҲй«ҳжҖ§иғҪйӣҶеҗҲеә“з»ҙжҠӨиҖ…еҗҲ并зҺҜзј“еҶІпјҡ[Nick Zeeb] ( https://github.com/nickzeeb )жҳҜд»Җд№ҲпјҹиҜ·еҸӮи§Ғ http://nickzeeb.wordpress.com/2013/03/07/t
DisruptorжЎҶжһ¶жҳҜз”ұLMAXе…¬еҸёејҖеҸ‘зҡ„дёҖж¬ҫй«ҳж•Ҳзҡ„ж— й”ҒеҶ…еӯҳйҳҹеҲ—гҖӮдҪҝз”Ёж— й”Ғзҡ„ж–№ејҸе®һзҺ°дәҶдёҖдёӘзҺҜеҪўйҳҹеҲ—гҖӮжҚ®е®ҳж–№жҸҸиҝ°пјҢе…¶жҖ§иғҪиҰҒжҜ”BlockingQueueиҮіе°‘й«ҳдёҖдёӘж•°йҮҸзә§гҖӮж №жҚ®GitHubдёҠзҡ„жңҖж–°зүҲжң¬жәҗз Ғжү“еҮәзҡ„еҢ…пјҢеёҢжңӣеҜ№еӨ§е®¶жңүеё®еҠ©гҖӮ
жңҖж–°lmaxеңЁзәҝејҖжҲ·жіЁеҶҢжҢҮеҚ—收йӣҶ.pdf
并еҸ‘жЎҶжһ¶Disruptorд»Ӣз»ҚMartin FowlerеңЁиҮӘе·ұзҪ‘з«ҷдёҠеҶҷдәҶдёҖзҜҮLMAXжһ¶жһ„зҡ„ж–Үз« пјҢеңЁж–Үз« дёӯд»–д»Ӣз»ҚдәҶLMAXжҳҜдёҖз§Қж–°еһӢйӣ¶е”®йҮ‘иһҚдәӨжҳ“е№іеҸ°пјҢе®ғиғҪеӨҹд»ҘеҫҲдҪҺзҡ„延иҝҹдә§з”ҹеӨ§йҮҸдәӨжҳ“гҖӮиҝҷдёӘзі»з»ҹжҳҜе»әз«ӢеңЁJVMе№іеҸ°дёҠпјҢе…¶ж ёеҝғжҳҜдёҖдёӘдёҡеҠЎйҖ»иҫ‘...
LMAXжҳҜдёҖз§Қж–°еһӢйӣ¶е”®йҮ‘иһҚдәӨ жҳ“е№іеҸ°пјҢе®ғиғҪеӨҹд»ҘеҫҲдҪҺзҡ„延иҝҹдә§з”ҹеӨ§йҮҸдәӨжҳ“гҖӮиҝҷдёӘзі»з»ҹжҳҜе»әз«ӢеңЁJVMе№іеҸ°дёҠпјҢе…¶ж ёеҝғжҳҜдёҖдёӘдёҡеҠЎйҖ»иҫ‘еӨ„зҗҶ еҷЁпјҢе®ғиғҪеӨҹеңЁдёҖдёӘзәҝзЁӢйҮҢжҜҸз§’еӨ„зҗҶ6зҷҫдёҮи®ўеҚ•гҖӮдёҡеҠЎйҖ»иҫ‘еӨ„зҗҶеҷЁе®Ңе…ЁжҳҜиҝҗиЎҢеңЁеҶ…еӯҳдёӯпјҢдҪҝз”ЁдәӢ件...
LMAX е®ўжҲ·з«Ҝ , еңЁзәҝе•ҶеҹҺзі»з»ҹзҡ„е®ўжҲ·з«ҜжҺҘеҸЈеҢ…иЈ…пјҢйҮҮз”Ёе…ЁејӮжӯҘжЁЎејҸ
LMAX Disruptor жңҖж–°зүҲжң¬ жәҗз Ғ+API+й©ұеҠЁеҢ…
ж–°lmaxеңЁзәҝејҖжҲ·жіЁеҶҢжҢҮеҚ—еҲҶдә«.pdf
match-tradeи¶…й«ҳж•Ҳзҡ„дәӨжҳ“жүҖж’®еҗҲеј•ж“ҺпјҢйҮҮз”ЁдјҰж•ҰеӨ–жұҮдәӨжҳ“жүҖLMAXејҖжәҗзҡ„DisruptorжЎҶжһ¶пјҢеҲҶеёғејҸеҶ…еӯҳеӯҳеҸ–пјҢд»ҘеҸҠеҺҹеӯҗжҖ§ж“ҚдҪңгҖӮдҪҝз”Ёж•°жҚ®жөҒзҡ„ж–№ејҸиҝӣиЎҢи®Ўз®—ж’®еҗҲеәҸеҲ—пјҢжүҚз”Ёд»·ж јж°ҙе№ізӢ¬з«Ӣж’®еҗҲйҖ»иҫ‘пјҢе®һзҺ°й«ҳж•ҲеӨ§ж•°жҚ®ж’®еҗҲ
find the local maximum of the data, and filter high frequency signal.
дёҖдёӘе…Қиҙ№зҡ„ејҖжәҗе®ўжҲ·з«Ҝеә”з”ЁзЁӢеәҸпјҢз”ЁдәҺйҖҡиҝҮLMAX Webservice / APIиҝӣиЎҢе®һж—¶еӣҫиЎЁз»ҳеҲ¶е’Ңжңүйҷҗзҡ„дәӨжҳ“жү§иЎҢгҖӮ
жңҖж–°lmaxеңЁзәҝејҖжҲ·жіЁеҶҢжҢҮеҚ—.pdf