
Many batch processing problems can be solved with single threaded, single process jobs, so it is always a good idea to properly check if that meets your needs before thinking about more complex implementations. Measure the performance of a realistic job and see if the simplest implementation meets your needs first: you can read and write a file of several hundred megabytes in well under a minute, even with standard hardware.
When you are ready to start implementing a job with some parallel processing, Spring Batch offers a range of options, which are described in this chapter, although some features are covered elsewhere. At a high level there are two modes of parallel processing: single process, multi-threaded; and multi-process. These break down into categories as well, as follows:
-
Multi-threaded Step (single process)
-
Parallel Steps (single process)
-
Remote Chunking of Step (multi process)
-
Partitioning a Step (single or multi process)
Next we review the single-process options first, and then the multi-process options.
利用单线程、单进程作业可以解决许多批处理问题,因此在考虑更为复杂的部署之前最好检查一下这是否满足你的需求。首先,评估一个现实作业的性能,看一下最简单的部署能不能满足你的需求:即使使用标准硬件,你也可以在不到一分钟时间内读取和写入几百兆字节的文件。
当你准备用一些并行处理功能开始部署一项作业时,Spring Batch提供了一些选项;虽然部分特征在其他地方有所涉及,但是本文将对这些选项进行阐述。从高层面讲,有两种并行处理模式:单进程多线程,多进程。这些还可分为如下几类:
- 多线程step(单进程)
- 并行step(单进程)
- 远程Step结块(chunking)(多进程)
- Step分割(单进程或多进程)
下面,我们依次讨论单进程选项和多进程选项。
7.1. Multi-threaded Step
The simplest way to start parallel processing is to add a TaskExecutor to your Step configuration, e.g. as an attribute of the tasklet:
开启并行进程的最简单方法就是将TaskExecutor添加到你的Step配置中,比如作为tasklet的一个属性添加:
<step id="loading">
<tasklet task-executor="taskExecutor">...</tasklet>
</step>
In this example the taskExecutor is a reference to another bean definition, implementing the TaskExecutor interface. TaskExecutor is a standard Spring interface, so consult the Spring User Guide for details of available implementations. The simplest multi-threaded TaskExecutor is aSimpleAsyncTaskExecutor.
在该例子中,taskExecutor是对另一个bean定义的引用,且部署了TaskExecutor接口。TaskExecutor是个标准的Spring接口,因此可以阅读Spring用户手册获得更多部署信息。最简单的多线程TaskExecutor是SimpleAsyncTaskExecutor。
The result of the above configuration will be that the Step executes by reading, processing and writing each chunk of items (each commit interval) in a separate thread of execution. Note that this means there is no fixed order for the items to be processed, and a chunk might contain items that are non-consecutive compared to the single-threaded case. In addition to any limits placed by the task executor (e.g. if it is backed by a thread pool), there is a throttle limit in the tasklet configuration which defaults to 4. You may need to increase this to ensure that a thread pool is fully utilised, e.g.
上面配置的结果就是Step运行时是在另外一个线程执行中读取、处理、写入每块(chunk)项目(每个提交间隔)。请注意,这意味着项目处理时没有固定次序,且与单线程情况相比,项目块包括的项目可能是非连续的。除了任务执行程序施加的各种限制外(比如它有线程池支持时),tasklet配置还有一个节流(throttle)限制,且默认为4。你可能需要提高该数值以确保线程池得到充分利用,比如:
<step id="loading"> <tasklet
task-executor="taskExecutor"
throttle-limit="20">...</tasklet>
</step>
Note also that there may be limits placed on concurrency by any pooled resources used in your step, such as a DataSource. Be sure to make the pool in those resources at least as large as the desired number of concurrent threads in the step.
还请注意,在你的step中使用的入池资源可能会施加并发性约束,比如DataSource。一定要使这些资源的池至少要与step并行线程需要数量一样大。
There are some practical limitations of using multi-threaded Steps for some common Batch use cases. Many participants in a Step (e.g. readers and writers) are stateful, and if the state is not segregated by thread, then those components are not usable in a multi-threaded Step. In particular most of the off-the-shelf readers and writers from Spring Batch are not designed for multi-threaded use. It is, however, possible to work with stateless or thread safe readers and writers, and there is a sample (parallelJob) in the Spring Batch Samples that show the use of a process indicator (see Section 6.12, “Preventing State Persistence”) to keep track of items that have been processed in a database input table.
对部分常见的Batch使用情况,在实际使用多线程step时会遇到一些约束。Step的许多参与方(participant)(比如读取器和写入器)是有状态的,并且如果状态没有被线程分离,则这些组件无法用于多线程step。尤其地,Spring Batch大多数现成的读取器和写入器在设计时并没有考虑用于多线程。然而,利用无状态或线程安全性读取器和写入器还是有可能的,Spring Batch Samples中有一个例子(parallelJob)演示了如何使用进程指示器(见第6.12节,“Preventing State Persistence””防止状态持久性“),来跟踪数据库输入表中已经处理过的项目。
Spring Batch provides some implementations of ItemWriter and ItemReader. Usually they say in the Javadocs if they are thread safe or not, or what you have to do to avoid problems in a concurrent environment. If there is no information in Javadocs, you can check the implementation to see if there is any state. If a reader is not thread safe, it may still be efficient to use it in your own synchronizing delegator. You can synchronize the call to read() and as long as the processing and writing is the most expensive part of the chunk your step may still complete much faster than in a single threaded configuration.
Spring Batch提供了ItemWriter和ItemReader部分部署。他们经常在Javadocs中担心它们的线程安全性,或者提醒你必须要采取措施以避免并行环境出现问题。如果Javadocs没有提供相关信息,你可以检测部署情况,查看是否存在状态(state)。如果一个读取器不具有线程安全性,但是你仍然有可能将它高效地用于你的同步委派器(delegator)中。你可以把对read()的调用进行同步,只要处理和写入操作是项目块(chunk)成本最高的部分,你的step的完成时间就有可能远快于单线程配置情况。
7.2. Parallel Steps
As long as the application logic that needs to be parallelized can be split into distinct responsibilities, and assigned to individual steps then it can be parallelized in a single process. Parallel Step execution is easy to configure and use, for example, to execute steps (step1,step2) in parallel withstep3, you could configure a flow like this:
只要需要同步的应用逻辑可以分为多个任务并且分配给多个step,则它也就可以在单进程中并行化。并行step的配置和使用非常简单。例如,为了实现step (step1,step2) 与step3的并行执行,你可以按照如下方法配置一个flow:
<job id="job1">
<split id="split1" task-executor="taskExecutor" next="step4">
<flow>
<step id="step1" parent="s1" next="step2"/>
<step id="step2" parent="s2"/>
</flow>
<flow>
<step id="step3" parent="s3"/>
</flow>
</split>
<step id="step4" parent="s4"/>
</job>
<beans:bean id="taskExecutor" class="org.spr...SimpleAsyncTaskExecutor"/>
The configurable "task-executor" attribute is used to specify which TaskExecutor implementation should be used to execute the individual flows. The default is SyncTaskExecutor, but an asynchronous TaskExecutor is required to run the steps in parallel. Note that the job will ensure that every flow in the split completes before aggregating the exit statuses and transitioning.
See the section on Section 5.3.5, “Split Flows” for more detail.
使用了可配置的"task-executor"属性来指明应该使用哪个TaskExecutor部署来运行各个flow。默认的部署是SyncTaskExecutor,但是需要一个异步的TaskExecutor才能并行运行这些step。
请注意,作业将会确保split中的每个flow在聚集退出状态和转换(transitioning)前结束。
7.3. Remote Chunking
In Remote Chunking the Step processing is split across multiple processes, communicating with each other through some middleware. Here is a picture of the pattern in action:
对Remote Chunking(远程分块)中,step处理分为多个进程,互相之间通过中间件通信。下面是正在运行的一个模式:
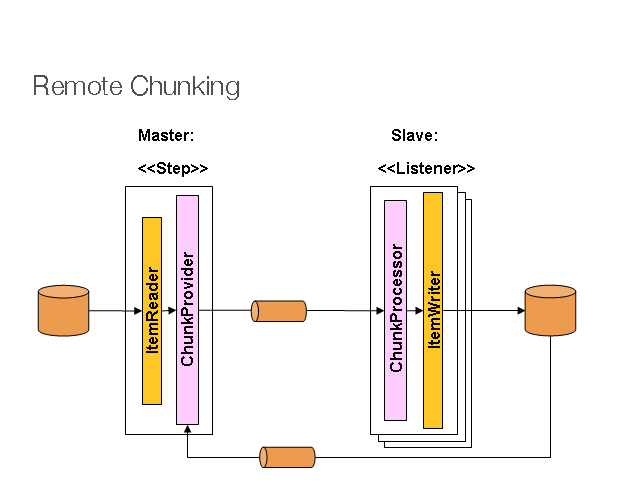
The Master component is a single process, and the Slaves are multiple remote processes. Clearly this pattern works best if the Master is not a bottleneck, so the processing must be more expensive than the reading of items (this is often the case in practice).
Master组件是个单进程,Slaves是远程多进程。很明显,如果Master不是一个瓶颈(bottleneck)的话,最利于该模式的运行。所以,处理的成本必须要高于项目读取成本(实际情况往往就是如此)。
The Master is just an implementation of a Spring Batch Step, with the ItemWriter replaced with a generic version that knows how to send chunks of items to the middleware as messages. The Slaves are standard listeners for whatever middleware is being used (e.g. with JMS they would beMesssageListeners), and their role is to process the chunks of items using a standard ItemWriter or ItemProcessor plus ItemWriter, through theChunkProcessor interface. One of the advantages of using this pattern is that the reader, processor and writer components are off-the-shelf (the same as would be used for a local execution of the step). The items are divided up dynamically and work is shared through the middleware, so if the listeners are all eager consumers, then load balancing is automatic.
Master只是Spring Batch Step的一个部署,替换掉ItemWriter的通用版本知道如何把项目块作为消息发送给中间件。Slaves是正在使用的中间件的标准收听器(listener)(比如有JMS时,它们就是MesssageListeners),它们的角色就是基于ChunkProcessor接口,使用标准的ItemWriter或ItemProcessor和ItemWriter来处理项目块。使用这种模式的一个优点就是读取器、处理器和读取器组件都是现成的(与用于step本地运行时是相同的)。项目被动态分配,通过中间件共享工作,因此如果收听器均是非常迫切的consumer,则负载均衡将实现自动化。
The middleware has to be durable, with guaranteed delivery and single consumer for each message. JMS is the obvious candidate, but other options exist in the grid computing and shared memory product space (e.g. Java Spaces).
中间件必须要持久耐用,每条消息的投递和单consumer性能有保证。很明显,JMS是不错的选择,网格计算和共享内存产品空间(比如Java Spaces)也提供了其他选择。
Spring Batch has a sister project Spring Batch Admin, which provides(amongst other things) implementations of various patterns like this one using Spring Integration. These are implemented in a module called Spring Batch Integration.
Spring Batch有一个姊妹项目Spring Batch Admin,提供了各种模式的部署(还提供了其他功能),比如这一个就使用了Spring Integration。这些都部署在称为Spring Batch Integration的模块中。
7.4. Partitioning
Spring Batch also provides an SPI for partitioning a Step execution and executing it remotely. In this case the remote participants are simply Step instances that could just as easily have been configured and used for local processing. Here is a picture of the pattern in action:
Spring Batch还提供了一个SPI,对Step运行过程进行分割并且远程运行。此时,远程参与方为step实例,并且这些实例用于本地处理时的配置同样很简单。下面是正在运行的一个模式:
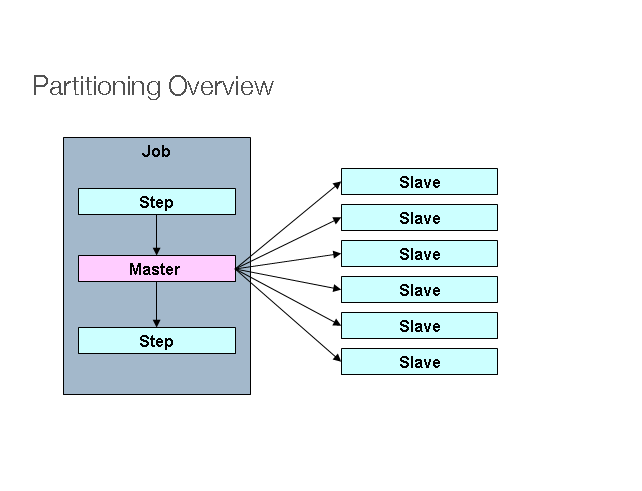
The Job is executing on the left hand side as a sequence of Steps, and one of the Steps is labelled as a Master. The Slaves in this picture are all identical instances of a Step, which could in fact take the place of the Master resulting in the same outcome for the Job. The Slaves are typically going to be remote services, but could also be local threads of execution. The messages sent by the Master to the Slaves in this pattern do not need to be durable, or have guaranteed delivery: Spring Batch meta-data in the JobRepository will ensure that each Slave is executed once and only once for each Job execution.
作业作为一个step序列在左手边运行,其中一个step标识为Master。该图中的Slaves均是Step的实例且完全相同,这些实例实际上可以取代Master进而生成相同的作业结果。一般而言,Slaves将是远程服务,也可能是运行过程的本地线程。Master在这种模式下发送给Slaves的消息不需要持久耐用或者具有较高的传递效果:JobRepository中的Spring Batch元数据将会确保每个Slave为每个作业只运行一次。
The SPI in Spring Batch consists of a special implementation of Step (the PartitionStep), and two strategy interfaces that need to be implemented for the specific environment. The strategy interfaces are PartitionHandler and StepExecutionSplitter, and their role is show in the sequence diagram below:
Spring Batch的SPI由Step的一个部署(PartitionStep)和两个策略接口构成;这两个策略接口需要针对具体的环境进行部署。策略接口为PartitionHandler和StepExecutionSplitter,它们的作用见如下序列图:
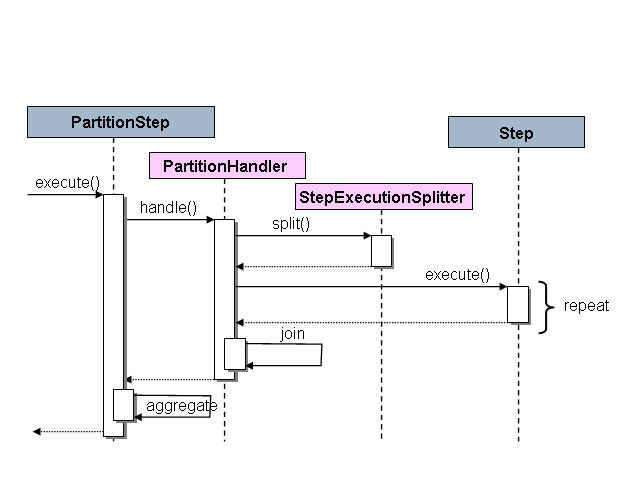
The Step on the right in this case is the "remote" Slave, so potentially there are many objects and or processes playing this role, and the PartitionStep is shown driving the execution. The PartitionStep configuration looks like this:
此时右边的Step为"remote"(远程) Slave,因此有可能有多个对象或进程扮演这个角色,图中可以看出PartitionStep对运行过程具有驱动作用。PartitionStep的配置如下:
<step id="step1.master">
<partition step="step1" partitioner="partitioner">
<handler grid-size="10" task-executor="taskExecutor"/>
</partition>
</step>
Similar to the multi-threaded step's throttle-limit attribute, the grid-size attribute prevents the task executor from being saturated with requests from a single step.
与多线程step的界限调节属性类似,网格大小属性可以防止任务执行程序由于单个step的申请太多而饱和。
There is a simple example which can be copied and extended in the unit test suite for Spring Batch Samples (see *PartitionJob.xmlconfiguration).
我们可以拷贝Spring Batch Samples (见*PartitionJob.xml配置)单元测试套件中的一个示例并且对其进行拓展。
Spring Batch creates step executions for the partitions called "step1:partition0", etc., so many people prefer to call the master step "step1:master" for consistency. With Spring 3.0 you can do this using an alias for the step (specifying the name attribute instead of the id).
Spring Batch为"step1:partition0"等分割创建step运行程序,许多人出于一致性考虑喜欢将master step称为"step1:master"。在Spring 3.0中,你此时可以使用step的别名(明确name属性而不是ID)。
7.4.1. PartitionHandler
The PartitionHandler is the component that knows about the fabric of the remoting or grid environment. It is able to send StepExecution requests to the remote Steps, wrapped in some fabric-specific format, like a DTO. It does not have to know how to split up the input data, or how to aggregate the result of multiple Step executions. Generally speaking it probably also doesn't need to know about resilience or failover, since those are features of the fabric in many cases, and anyway Spring Batch always provides restartability independent of the fabric: a failed Job can always be restarted and only the failed Steps will be re-executed.
PartitionHandler是个掌握了远程环境或网络环境结构(fabric)的组件。它可以向远程step发送用DTO等与结构相符的格式包装过的StepExecution请求。它不需要知道如何分割输入数据,也不需要知道如何聚集多个step执行程序的结果。总体来说,它很可能也不需要知道弹性或失效转移,因为这些特性是环境结构在其他许多情况下的特性,不管怎样,Spring Batch始终提供与环境结构无关的可重启性特征:发生故障的作业始终可以重启,只有发生故障的step将重新运行。
The PartitionHandler interface can have specialized implementations for a variety of fabric types: e.g. simple RMI remoting, EJB remoting, custom web service, JMS, Java Spaces, shared memory grids (like Terracotta or Coherence), grid execution fabrics (like GridGain). Spring Batch does not contain implementations for any proprietary grid or remoting fabrics.
PartitionHandler接口对不同的环境结构类型有不同的部署:比如,简单的RMI remoting,EJB remoting, 定制网络服务,JMS,Java Spaces,共享内存网格(比如Terracotta或Coherence),网格运行结构(比如GridGain)。Spring Batch不包含各种专有网络或remoting(远程)结构的部署。
Spring Batch does however provide a useful implementation of PartitionHandler that executes Steps locally in separate threads of execution, using the TaskExecutor strategy from Spring. The implementation is called TaskExecutorPartitionHandler, and it is the default for a step configured with the XML namespace as above. It can also be configured explicitly like this:
然而,Spring Batch提供了一种非常有用的部署,即PartitionHandler;它可以根据Spring的TaskExecutor策略,在单独的运行线程中本地化运行step。该部署称为TaskExecutorPartitionHandler,它是利用上文XML命名空间进行配置的step的默认设置。它也可以进行显式配置,如下文:
<step id="step1.master">
<partition step="step1" handler="handler"/>
</step>
<bean class="org.spr...TaskExecutorPartitionHandler">
<property name="taskExecutor" ref="taskExecutor"/>
<property name="step" ref="step1" />
<property name="gridSize" value="10" />
</bean>
The gridSize determines the number of separate step executions to create, so it can be matched to the size of the thread pool in the TaskExecutor, or else it can be set to be larger than the number of threads available, in which case the blocks of work are smaller.
gridSize决定了将要创建的各个step运行程序的数量,因此可以将它与TaskExecutor线程池的大小进行比较或者将它设置得大于可用线程数量,此时工作块(blocks of work)比较小。
The TaskExecutorPartitionHandler is quite useful for IO intensive Steps, like copying large numbers of files or replicating filesystems into content management systems. It can also be used for remote execution by providing a Step implementation that is a proxy for a remote invocation (e.g. using Spring Remoting).
TaskExecutorPartitionHandler对于向内容管理系统拷贝或复制大量文件等IO密集型step很有帮助。通过提供远程调用代理的step部署(比如使用Spring Remoting),它还可以用于远程运行程序。
The Partitioner has a simpler responsibility: to generate execution contexts as input parameters for new step executions only (no need to worry about restarts). It has a single method:
Partitioner的功能更为简单:生成只作为新的step运行程序的输入参数的运行上下文(不需担心重启)。它只有一个方法:
public interface Partitioner {
Map<String, ExecutionContext> partition(int gridSize);
}
The return value from this method associates a unique name for each step execution (the String), with input parameters in the form of anExecutionContext. The names show up later in the Batch meta data as the step name in the partitioned StepExecutions. The ExecutionContext is just a bag of name-value pairs, so it might contain a range of primary keys, or line numbers, or the location of an input file. The remote Step then normally binds to the context input using #{...} placeholders (late binding in step scope), as illustrated in the next section.
该方法返回的值为每个step运行程序(String)关联一个唯一标识符,输入参数的形式为ExecutionContext。Batch元数据中随后出现的名称是经过分割的StepExecutions的step名称。ExecutionContext就是一个装载了许多名称—数值对的包,因此它可能包含一系列主键,或者行号以及输入文件的位置。然后,一般情况下,远程step使用#{...}占位符与上下文输入绑定(step scope后期绑定),这点将在下节讨论。
The names of the step executions (the keys in the Map returned by Partitioner) need to be unique amongst the step executions of a Job, but do not have any other specific requirements. The easiest way to do this, and to make the names meaningful for users, is to use a prefix+suffix naming convention, where the prefix is the name of the step that is being executed (which itself is unique in the Job), and the suffix is just a counter. There is a SimplePartitioner in the framework that uses this convention.
对一个作业的多个step运行程序,其名称应该具有唯一性(Partitioner返回的Map键值),其他方面没有具体要求。实现名称唯一性以及使名称对用户来说带有一定含义的最早期方法是使用前缀+后缀命名规则,其中前缀是正在运行的step的名称(它在作业中本身就具有唯一性),后缀只是个计数器。框架中有SimplePartitioner接口使用该命名规则。
An optional interface PartitioneNameProvider can be used to provide the partition names separately from the partitions themselves. If a Partitionerimplements this interface then on a restart only the names will be queried. If partitioning is expensive this can be a useful optimisation. Obviously the names provided by the PartitioneNameProvider must match those provided by the Partitioner.
可以根据选择使用PartitioneNameProvider接口从partition(分区,分割)本身分别提供partition名称。如果Partitioner部署了这一接口,则在重启时只查询名称。如果分区成本很高,则这是个很有帮助的优化。很显然,PartitioneNameProvider提供的名称必须与Partitioner提供的名称相匹配。
It is very efficient for the steps that are executed by the PartitionHandler to have identical configuration, and for their input parameters to be bound at runtime from the ExecutionContext. This is easy to do with the StepScope feature of Spring Batch (covered in more detail in the section on Late Binding). For example if the Partitioner creates ExecutionContext instances with an attribute key fileName, pointing to a different file (or directory) for each step invocation, the Partitioner output might look like this:
如果PartitionHandler运行的step有相同的配置,并且它们的输入参数在运行期间从ExecutionContext实现绑定,则可以明显提高效率。利用Spring Batch的StepScope特征(见Late Binding节可以获得详细内容)可以很简单的实现这一点。例如,如果Partitioner创建带有属性键fileName的ExecutionContext实例,并且在每次step调用时属性键指向不同的文件或目录,则Partitioner的输出应该如下:
Table 7.1. Example step execution name to execution context provided by Partitioner targeting directory processing
| Step Execution Name (key) | ExecutionContext (value) |
| filecopy:partition0 | fileName=/home/data/one |
| filecopy:partition1 | fileName=/home/data/two |
| filecopy:partition2 | fileName=/home/data/three |
Then the file name can be bound to a step using late binding to the execution context:
然后,通过运行上下文后期绑定,可以将文件名称与step绑定。
<bean id="itemReader" scope="step"
class="org.spr...MultiResourceItemReader">
<property name="resource" value="#{stepExecutionContext[fileName]}/*"/>
</bean>



相关推荐
Chapter 7. Routine Maintenance Chapter 8. Database Benchmarking Chapter 9. Database Indexing Chapter 10. Query Optimization Chapter 11. Database Activity and Statistics Chapter 12. Monitoring and ...
Chapter 7. Routine Maintenance Chapter 8. Database Benchmarking Chapter 9. Database Indexing Chapter 10. Query Optimization Chapter 11. Database Activity and Statistics Chapter 12. Monitoring and ...
Addison.Wesley.Practices.for.Scaling.Lean.and.Agile.Development.Jan.2010.rar
High.Performance.Spark.Best.Practices.for.Scaling.and.Optimizing.Apache.Spark. High.Performance.Spark.Best.Practices.for.Scaling.and.Optimizing.Apache.Spark.
Hckers.Guide.Scaling.Python Hckers.Guide.Scaling.Python Hckers.Guide.Scaling.Python
Title: Scaling Big Data with Hadoop and Solr, 2nd Edition Author: Hrishikesh Vijay Karambelkar Length: 156 pages Edition: 1 Language: English Publisher: Packt Publishing Publication Date: 2015-03-31 ...
不说了,查找下载的人都很了解的,希望Programer 有用
If you are a developer who wants to learn how to get the most out of Solr in...Chapter 7. Faceting Chapter 8. Search Components Chapter 9. Integrating Solr Chapter 10. Scaling Solr Chapter 11. Deployment
If you are a developer who wants to learn how to get the most out of Solr in...Chapter 7. Faceting Chapter 8. Search Components Chapter 9. Integrating Solr Chapter 10. Scaling Solr Chapter 11. Deployment
The Nexus Framework for Scaling Scrum: Continuously Delivering an Integrated Product with Multiple Scrum Teams ...Chapter 7 The Nexus in Emergency Mode Chapter 8 Retrospective on the Nexus Journey
Summary Natural Language Processing in Action is your guide to creating machines that understand human language using the power of ... Scaling Up (Optimization, Parallelization, And Batch Processing)
Chapter 7. Complex Playbooks Chapter 8. Roles: Scaling Up Your Playbooks Chapter 9. Making Ansible Go Even Faster Chapter 10. Custom Modules Chapter 11. Vagrant Chapter 12. Amazon EC2 Chapter 13. ...
For Java applications, App Engine provides a J2EE standard servlet container with a complete Java 7 JVM and standard library. Because App Engine supports common Java API standards, your code stays ...
Chapter 7. Block Storage Chapter 8. Object Storage Chapter 9. Telemetry Chapter 10. Orchestration Chapter 11. Scaling Horizontally Chapter 12. Monitoring Chapter 13. Troubleshooting
Chapter 7. Event Sourcing Pattern Chapter 8. External Confguration Store Pattern Chapter 9. Federated Identity Pattern Chapter 10. Gatekeeper Pattern Chapter 11. Health Endpoint Monitoring Pattern ...
Focus on data usage and better design schemas with the help of MongoDB About This Book Create reliable, scalable data models ...Chapter 7. Scaling Chapter 8. Logging and Real-time Analytics with MongoDB
Chapter 7. Frequencies Chapter 8. Descriptive Statistics Chapter 9. Crosstabulation & χ2 Analyses Chapter 10. Means Procedure Chapter 11. Bivariate Correlation Chapter 12. t Test Procedure Chapter 13...
Early Release ...Chapter 7. Deployment Strategies Chapter 8. Building Reusable Components Chapter 9. Log Management Chapter 10. DNS with Route 53 Chapter 11. Monitoring Chapter 12. Backups
Following this, you'll get to grips with CloudFormation, auto scaling, bootstrap AWS EC2 instances, automation and deployment with Chef, and develop your knowledge of big data and Apache Hadoop on ...