
话说腾讯的笔试题和百度笔试题不太一样,腾讯的有很多技术的题,还有一些组合数学的问题,组合数学的题我怕自己弄错,就用二维数组穷举求解的,浪费了很多时间,最后的加试题的那个其实很easy,只不过当时没有时间了,对于当时的我来说很久没有看技术的细节东西了,备受打击。百度的题完全是从思维、设计的角度出发,技术题只有一个就是c语言和c++里面动态分配内存的区别,还好我记得。其实对我自己满有信息了,毕竟偏思维的自己答的还不错,百度的面试官说我笔试的分数挺高的,最后百度过了三面,腾讯一面就over了,哎,归根结底都是自己没准备好,希望秋季校招的时候把自己的水泵展现出来吧。下面就是腾讯今年的笔试题,我转贴过来的,我会对一些必要的做一些分析。
A、3 B、4 C、5 D、6
有些同学认为:第一次乘法:x^2 第二次乘法:x^4=x^2 * x^2 第三次乘法:x^2 * (x^4+4x^2+2x)+x+1每一项系数用加法实现。答案A
误区:x^2,x^4,x^3,x^6 每一项都通过乘法求出2、给定3个int类型的正整数x,y,z,对如下4组表达式判断正确的选项()
Int a1=x+y-z; int b1=x*y/z;
Int a2=x-z+y; int b2=x/z*y;
Int c1=x<<y>>z; int d1=x&y|z; //<< ( 左移) >>(右移) &(按位与,清零时,取某些位) |(按位或)
Int c2=x>>z<<y; int d2=x|z&y;
A、a1一定等于a2 // x=65535 y>=1 则发生溢出
B、b1一定定于b2 //溢出
C、c1一定等于c2 //有效值移走,导致结果不准确
D、d1一定等于d2
A、死代码删除指的是编译过程直接抛弃掉被注释的代码;//编译器可以判断出某些代码根本不影响输出,所以编译器会消除这些代码。也可以使用优化作用进行消除。(永远不执行的代码叫死代码)
B、函数内联可以避免函数调用中压栈和退栈的开销
C、For循环的循环控制变量通常很适合调度到寄存器访问
D、强度削弱是指执行时间较短的指令等价的替代执行时间较长的指令
4、 如下关于进程的描述不正确的是()
A、进程在退出时会自动关闭自己打开的所有文件
B、进程在退出时会自动关闭自己打开的网络链接
C、进程在退出时会自动销毁自己创建的所有线程
D、进程在退出时会自动销毁自己打开的共享内存//共享内存用来进程之间通信
5、 在如下8*6的矩阵中,请计算从A移动到B一共有多少种走法?要求每次只能向上或着向右移动一格,并且不能经过P;
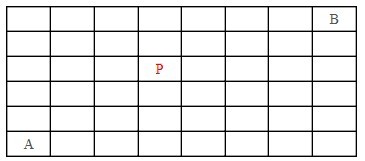
A、492
B、494
C、496
D、498
解答:
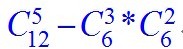
从A到B总共12步,向上可以走5步,向右可以走7步。注意,必须向上走5步,向右走7步
只需要考虑上和右依次在哪里出现,所以不难得出答案
6、SQL语言中删除一个表的指令是()
A、DROP TABLE
B、DELETE TABLE
C、DESTROY TABLE
D、REMOVE TABLE
7、某产品团队由美术组、产品组、client程序组和server程序组4个小组构成,每次构建一套完整的版本时,需要各个组发布如下资源。美术组想客户端提供图像资源(需要10分钟),产品组向client组合server提供文字内容资源(同时进行,10分钟),server和client源代码放置在不同工作站上,其完整编译时间均为10分钟且编译过程不依赖于任何资源,client程序(不包含任何资源)在编译完毕后还需要完成对程序的统一加密过程(10分钟)。可以请问,从要完成一次版本构建(client与server的版本代码与资源齐备),至少需要多少时间()
A、60分钟
B、40分钟
C、30分钟
D、20分钟
这道题主要考察进程同步问题,关于操作系统方面。美术 10
产品 10
client 10 10(加密)
server 10
误区:记住client跟server 与美术跟产品 可以同时进行
8、如下关于编译链接的说法错误的是()
A、编译优化会使得编译速度变慢
B、预编译头文件可以优化程序的性能
C、静态链接会使得可执行文件偏大
D、动态链接库会使进程启动速度偏慢 //程序启动 跟程序运行的区别,启动的时候不用加载动态链接库,运行的时候需要查找动态链接库中函数
9、如下关于链接的说法错误的是()
A、一个静态库中不能包含两个同名全局函数的定义 //编译器保证没有同名函数
B、一个动态库中不能包含两个同名全局函数的定义
C、如果两个静态库都包含一个同名全局函数,他们不能同时被链接 //编译完成后,会在不同类库,同名函数上加上一些参数或者其他特定信息,从而在调用时区别
D、如果两个动态库都包含一个同名全局函数,他们不能同时被链接
//全局函数是定义在类外的函数,成员函数就是定义在类中的函数
10、排序算法的稳定是指,关键码相同的记录排序前后相对位置不发生改变,下面哪种排序算法是不稳定的()//考研几乎是必考的题
A、插入排序 //扩展为希尔排序,(间距)
B、冒泡排序
C、快速排序 //冒泡的改进 轴左边小,右边大
D、归并排序
11、下列说法中错误的是:()
A、插入排序某些情况下复杂度为O(n)
B、排序二叉树元素查找的复杂度可能为O(n)
C、对于有序列表的排序最快的是快速排序 //由于要选轴,每次都是选最大或最小的,导致快速排序最慢
D、在有序列表中通过二分查找的复杂度一定是O(n log2n)//不要见到”一定“就排除
12、在程序设计中,要对两个16K×16K的多精度浮点数二维数组进行矩阵求和时,行优先读取和列优先读取的区别是()
A、没区别
B、行优先快
C、列优先快
D、2种读取方式速度为随机值,无法判断
内存中数据可以“随机存取”:当存储器中的消息被读取或写入时,所需要的时间与这段信息所在的位置无关。相对的,读取或写入顺序访问(Sequential Access)存储设备中的信息时,其所需要的时间与位置就会有关系(如磁带)
数组在磁盘中的存放规则:

本题关键是考抖动问题,如果按列访问就需要跳过很大一串内存地址 这样可能需求的内存地址不在当前页中 需要页置换 则需要硬盘IO 则较慢
13、字符串www.qq.com所有非空子串(两个子串如果内容相同则只算一个)个数是()
A、1024
B、1018
C、55
D、50
14、TCP的关闭过程,说法正确的是()
A、TIME_WAIT状态称为MSL(Maximum Segment Lifetime)等待状态 //TIME_WAIT 是TCP链接断开时必定出现的状态,
//TCP下每条连接都有一个属性叫做max segment lifetime,就是说该连接关闭后,要经过2*max segment lifetime的时间,才算是真正的被关闭,才能被重新建立,以防止这条链路上还有东西在传输
//停留在TIME_WAIT状态的持续时间是最长分节生命周期(MSL)的两倍,有时候称之为2MSLB、对一个established状态的TCP连接,在调用shutdown函数之前调用close接口,可以让主动调用的一方进入半关闭状态
C、主动发送FIN消息的连接端,收到对方回应ack之前不能发只能收,在收到对方回复ack之后不能发也不能收,进入CLOSING状态
D、在已经成功建立连接的TCP连接上,如果一端收到RST消息可以让TCP的连接端绕过半关闭状态并允许丢失数据。
15、操作系统的一些特别端口要为特定的服务做预留,必须要root权限才能打开的端口描述正确的是()
A、端口号在64512-65535之间的端口
B、所有小于1024的每个端口
C、RFC标准文档中已经声明特定服务的相关端口,例如http服务的80端口,8080端口等
D、所有端口都可以不受权限限制打开
16、图书馆有6人排队,其中3人要还同一本书,书名为《面试宝典》,另外3人要借。问求能保证另外3人借到的种类。
Catalan数 C(2n , n)/( n+1 ) C(6,3)/4 = 5
5*3!*3! = 180
17、ack(3 , 3)的执行结果是多少?
[cpp] view plaincopy
int ack(int m,int n)
{
if(m == 0)
return n + 1;
else if(n == 0)
return ack(m-1,1);
else
return ack(m - 1 , ack(m , n-1));
}
这个题目可以找规律的。。
18、如下SQL语句是需要列出一个论坛版面第一页(每页显示20个)的帖子(post)标题(title),并按照发布(create_time)降序排列:
SELECT title FROM post( )create_time DESC( )0,20 order by limit
19、为了某项目需要,我们准备构造了一种面向对象的脚本语言,例如,对所有的整数,我们都通过Integer类型的对象来描述。在计算“1+2”时,这里的“1”,“2”和结果“3”分别为一个Integer对象。为了降低设计复杂度,我们决定让Integer对象都是只读对象,也即在计算a=a+b后,对象a引用的是一个新的对象,而非改a所指对象的值。考虑到性能问题,我们又引入两种优化方案:(1)对于数值相等的Integer对象,我们不会重复创建。例如,计算“1+1”,这里两个“1”的引用的是同一个对象——这种设计模式叫做();(2)脚本语言解析器启动时,默认创建数值范围[1,32]的32个Integer对象。现在,假设我们要计算表达式“1+2+3+…+40”,在计算过程需要创建的Integer对象个数是()。
享元模式
20、甲、乙两个人在玩猜数字游戏,甲随机写了一个数字,在[1,100]区间之内,将这个数字写在了一张纸上,然后乙来猜。
如果乙猜的数字偏小的话,甲会提示:“数字偏小”
一旦乙猜的数字偏大的话,甲以后就再也不会提示了,只会回答“猜对 或 猜错”
问: 乙至少猜 多少次 猜可以准确猜出这个数字,在这种策略下, 乙猜的第一个数字是多少???
答案:猜测序列是14,、27、39、50、60、69、77、84、90、95、99
因为无论第几次猜大了,最终的总次数总是14。 这个题目类似于一道Google面试题 : 扔玻璃球求最高楼层。。
一道关于动态规划的面试题——Google面试题:扔玻璃珠
某幢大楼有100层。你手里有两颗一模一样的玻璃珠。当你拿着玻璃珠在某一层往下扔的时候,一定会有两个结果,玻璃珠碎了或者没碎。这幢大楼有个临界楼层。低于它的楼层,往下扔玻璃珠,玻璃珠不会碎,等于或高于它的楼层,扔下玻璃珠,玻璃珠一定会碎。玻璃珠碎了就不能再扔。现在让你设计一种方式,使得在该方式下,最坏的情况扔的次数比其他任何方式最坏的次数都少。也就是设计一种最有效的方式。
首先,为了保存下一颗玻璃珠自己玩,就采用最笨的办法吧:从第一层开始试,每次增加一层,当哪一层扔下玻璃珠后碎掉了,也就知道了。不过最坏的情况扔的次数可能为100。
当然,为了这一颗玻璃珠代价也高了点,还是采取另外一种办法吧。随便挑一层,假如为N层,扔下去后,如果碎了,那就只能从第一层开始试了,最坏的情况可能为N。假如没碎,就一次增加一层继续扔吧,这时最坏的情况为100-N。也就是说,采用这种办法,最坏的情况为max{N, 100-N+1}。之所以要加一,是因为第一次是从第N层开始扔。
不过还是觉得不够好,运气好的话,挑到的N可能刚好是临界楼层,运气不好的话,要扔的次数还是很多。不过回过头看看第二种方式,有没有什么发现。假如没摔的话,不如不要一次增加一层继续扔吧,而是采取另外一种方式:把问题转换为100-N,在这里面找临界楼层,这样不就把问题转换成用递归的方式来解决吗?看下面:
假如结果都保存在F[101]这个数组里面,那么:
F[N]=100-N,
F[100]=min(max(1,1+F[N-1]),max(2,1+F[N-2]),……,max(N-1,1+F[1]));
看出来了没有,其实最终就是利用动态规划来解决这个问题。
下面是自己随便写的C++代码:
[cpp] view plaincopy
#include<iostream>
using namespace std;
int dp[101] = { 0 };
void solve()
{
int i , j , k;
for(i = 2 ; i < 101 ; ++i)
{
dp[i] = i;
for(j = 1 ; j < i ; ++j)
{
k = (j>=(1 + dp[i-j])) ? j : (1 + dp[i-j]);
if(dp[i] > k)
dp[i] = k;
}
}
}
int main(void)
{
dp[0] = 0 , dp[1] = 1;
solve();
printf("%d\n",dp[100]);
return 0;
}
输出结果为14。也就是说,最好的方式只要试14次就能够得出结果了。
答案是先从14楼开始抛第一次;如果没碎,再从27楼抛第二次;如果还没碎,再从39楼抛第三次;如果还没碎,再从50楼抛第四次;如此,每次间隔的楼层少一层。这样,任何一次抛棋子碎时,都能确保最多抛14次可以找出临界楼层。
证明如下:
1、第一次抛棋子的楼层:最优的选择必然是间隔最大的楼层。比如,第一次如果在m层抛下棋子,以后再抛棋子时两次楼层的间隔必然不大于m层(大家可以自己用反证法简单证明)
2、从第二次抛棋子的间隔楼层最优的选择必然比第一次间隔少一层,第三次的楼层间隔比第二次间隔少一层,如此,以后每次抛棋子楼层间隔比上一次间隔少一层。(大家不妨自己证明一下)
3、所以,设n是第一次抛棋子的最佳楼层,则n即为满足下列不等式的最小自然数:
不等式如下: 1+2+3+...+(n-1)+n >= 100
由上式可得出n=14
即最优的策略是先从第14层抛下,最多抛14次肯定能找出临界楼层。
21、给定一个数组a[N],我们希望构造数组b[N],其中b[i]=a[0]*a[1]*...*a[N-1]/a[i]。在构造过程:
不允许使用除法;
要求O(1)空间复杂度和O(n)时间复杂度;
除遍历计数器与a[N] b[N]外,不可使用新的变量(包括栈临时变量、对空间和全局静态变量等);
请用程序实现并简单描述。
[cpp] view plaincopy
/*
思路:进行3趟扫描
第一趟从左到右对A进行累乘,结果保存在B数组中,b[i] = b[i-1]*a[i-1];
第二趟从右到左对A进行累乘,结果写入A中,a[i]=a[i+1]*a[i];
第三趟从左到右,然后B数组对应位置的元素等于其前一个位置的元素与A中其后一个位置的元素的乘积。b[i] = a[i+1] * b[i-1]
*/
void makeArray(int a[],int b[],int len)
{
int i;
b[0] = 1;
for(i = 1 ; i < len ; ++i)
b[i] = b[i-1] * a[i-1]; // b[0] = 1 , b[i] = a[0]*a[1]*...*a[i-1]
a[len - 1] = a[len - 1]^a[len - 2]; //不使用中间变量,通过位运算来交换两个变量
a[len - 2] = a[len - 1]^a[len - 2];
a[len - 1] = a[len - 1]^a[len - 2];
for(i = len - 3 ; i >= 0 ; --i)
{
a[len - 1] = a[i + 1] * a[len - 1];
a[i] = a[i]^a[len - 1]; //交换两个变量
a[len - 1] = a[i]^a[len - 1];
a[i] = a[i]^a[len - 1];
}
a[len - 1 ] = 1; //a[len - 1 ] = 1 , a[i] = a[i+1]*a[i+2]*...*a[len-1]
for(i = 0 ; i < len ; ++i)
b[i] = a[i] * b[i];
}
方法二:
[cpp] view plaincopy
//方法二,保持a数组不变
void makeArray(int a[],int b[],int len)
{
int i;
b[0] = 1;
for(i = 1 ; i < len ; ++i)
{
b[0] *= a[i-1];
b[i] = b[0]; // b[i] = a[0]*a[1]*...*a[i-1]
}
b[0] = 1;
for(i = len - 2 ; i > 0 ; --i)
{
b[0] *= a[i+1]; // b[0] = a[i+1]*a[i+2]...*a[len-1]
b[i] *= b[0]; // b[i] = a[0]*a[1]*...*a[i-1]*a[i+1]*...*a[len-1]
}
b[0] *= a[1];
}
方法三:
[cpp] view plaincopy
void makeArray(int a[],int b[],int len)
{
int i;
b[0] = 1;
for(i = 1 ; i < len ; ++i)
{
b[i] = b[i-1] * a[i-1]; // b[i] = a[0]*a[1]*...*a[i-1]
}
b[0] = a[len - 1];
for(i = len - 2 ; i > 0 ; --i)
{
b[i] *= b[0]; // b[i] = a[0]*a[1]*...*a[i-1]*a[i+1]*...*a[len-1]
b[0] *= a[i]; // b[0] = a[i+1]*a[i+2]...*a[len-1]
}
}
22、20世纪60年代,美国心理学家米尔格兰姆设计了一个连锁信件实验。米尔格兰姆把信随即发送给住在美国各城市的一部分居民,信中写有一个波士顿股票经纪人的名字,并要求每名收信人把这封信寄给自己认为是比较接近这名股票经纪人的朋友。这位朋友收到信后再把信寄给他认为更接近这名股票经纪人的朋友。最终,大部分信件都寄到了这名股票经纪人手中,每封信平均经受6.2词到达。于是,米尔格兰姆提出六度分割理论,认为世界上任意两个人之间建立联系最多只需要6个人。
假设QQ号大概有10亿个注册用户,存储在一千台机器上的关系数据库中,每台机器存储一百万个用户及其的好友信息,假设用户的平均好友个数大约为25人左右。
第一问:请你设计一个方案,尽可能快的计算存储任意两个QQ号之间是否六度(好友是1度)可达,并得出这两位用户六度可达的话,最短是几度可达。
第二问:我们希望得到平均每个用户的n度好友个数,以增加对用户更多的了解,现在如果每台机器一秒钟可以返回一千条查询结果,那么在10天的时间内,利用给出的硬件条件,可以统计出用户的最多几度好友个数?如果希望得到更高的平均n度好友个数,可以怎样改进方案?
23、段页式虚拟存储管理方案的特点。
答:空间浪费小、存储共享容易、存储保护容易、能动态连接。
段页式管理是段式管理和页式管理结合而成,兼有段式和页式管理的优点,每一段分成若干页,再按页式管理,页间不要求连续(能动态连接);用分段方法分配管理作业,用分页方法分配管理内存(空间浪费小)。
段页式管理采用二维地址空间,如段号(S)、页号(P)和页内单元号(D);系统建两张表格每一作业一张段表,每一段建立一张页表,段表指出该段的页表在内存中的位置;地址变换机构类似页式机制,只是前面增加一项段号。所以存储共享容易、存储保护容易。



相关推荐
腾讯 2012 实习生 技术类 笔试题
腾讯2012实习生笔试题, 腾讯2012实习生笔试题
腾讯2012实习生笔试题+答案,要的赶紧下载哦.
腾讯历年实习生招聘笔试真题,大部分有答案。
腾讯校园实习生笔试题,有答案,大家好好看吧
腾讯实习生测试类笔试题,对于想要进入腾讯实习的朋友会有很大的作用的。
腾讯2013实习生招聘笔试试题,2013年4月13日刚刚出炉的,相比2012年简单一些。
腾讯2012实习生笔试题+答案解析,内容详细,欢迎下载。
2012年腾讯实习生技术运营试题
腾讯公司2010年校园招聘实习生技术类笔试题
2012 腾讯实习生笔试题,这是真题,文档清晰
hadoop2面试题 -2012年腾讯招聘实习生笔试题.pdf
腾讯百度笔试题腾讯百度笔试题腾讯百度笔试题腾讯百度笔试题腾讯百度笔试题腾讯百度笔试题
腾讯产品策划运营类职位笔试题和参考答案腾讯产品策划运营类职位笔试题和参考答案腾讯产品策划运营类职位笔试题和参考答案腾讯产品策划运营类职位笔试题和参考答案腾讯产品策划运营类职位笔试题和参考答案腾讯产品...
腾讯校园实习招聘笔试完整版,具有很好的参考价值哦。。
2019腾讯产品暑期实习提前批笔试题.pdf
2019腾讯产品暑期实习提前批笔试题(1).pdf
腾讯2012年实习生招聘笔试题,4月7日笔试题,题目类型:1.选择题(20*3’) 2.填空题(10*4’)3.附加题
为便于大家做练习,整理的word版 答案网上很多 自己找
2009校园招聘2008年10月11日腾讯软件开发笔试[nightelf] 2011腾讯技术类校园招聘笔试试题 腾讯2012实习生技术类笔试题201204