
õĖĆŃĆüÕ”éõĮĢÕø×µöČ’╝¤
1.1 Õ×āÕ£ŠµöČķøåń«Śµ│Ģ:
’╝ł1’╝ēµĀćĶ«░-µĖģķÖż’╝łMark-Sweep’╝ēń«Śµ│Ģ
Ķ┐Öµś»µ£ĆÕ¤║ńĪĆńÜäń«Śµ│Ģ’╝īÕ░▒ÕāÅÕ«āÕÉŹÕŁŚõĖƵĀĘ’╝īń«Śµ│ĢÕłåõĖ║ŌĆ£µĀćĶ«░ŌĆØÕÆīŌĆ£µĖģķÖżŌĆØõĖżõĖ¬ķśČµ«Ą’╝Üķ”¢ÕģłµĀćĶ«░ÕżäµēƵ£ēķ£ĆĶ”üÕø×µöČńÜäÕ»╣Ķ▒Ī’╝łÕ”éÕō¬õ║øÕåģÕŁśķ£ĆĶ”üÕø×µöȵēƵÅÅĶ┐░ńÜäÕ»╣Ķ▒Ī’╝ē’╝īÕ»╣µĀćĶ«░Õ«īµłÉÕÉÄń╗¤õĖĆÕø×µöȵēƵ£ēĶó½µĀćĶ«░ńÜäÕ»╣Ķ▒Ī’╝īÕ”éõĖŗÕøŠµēĆńż║’╝Ü
 ┬Ā
┬Ā
ń╝║ńé╣’╝ÜõĖĆõĖ¬µś»µĢłńÄćķŚ«ķóś’╝īµĀćĶ«░ÕÆīµĖģķÖżõĖżõĖ¬Ķ┐ćń©ŗńÜäµĢłńÄćķāĮõĖŹķ½ś’╝øÕÅ”õĖĆõĖ¬µś»ń®║ķŚ┤ķŚ«ķóś’╝īµĀćĶ«░µĖģķÖżÕÉĵéöõ║¦ńö¤Õż¦ķćÅńÜäõĖŹĶ┐×ń╗ŁńÜäÕåģÕŁśńóÄńēć’╝īÕÅ»ĶāĮõ╝ÜÕ»╝Ķć┤ÕÉÄń╗ŁµŚĀµ│ĢÕłåķģŹÕż¦Õ»╣Ķ▒ĪĶĆīÕ»╝Ķć┤ÕåŹõĖƵ¼ĪĶ¦”ÕÅæÕ×āÕ£ŠµöČķøåÕŖ©õĮ£ŃĆé
’╝ł2’╝ēÕżŹÕłČń«Śµ│Ģ
õĖ║õ║åķÆłÕ»╣µĀćĶ«░-µĖģķÖżń«Śµ│ĢńÜäõĖŹĶČ│’╝īÕżŹÕłČń«Śµ│ĢÕ░åÕÅ»ńö©ÕåģÕŁśÕ«╣ķćÅÕłÆÕłåõĖ║Õż¦Õ░ÅńøĖńŁēńÜäõĖżÕØŚ’╝īµ»Åµ¼ĪÕŬõĮ┐ńö©õĖĆÕØŚŃĆéÕĮōõĖĆÕØŚńÜäÕåģÕŁśńö©Õ«īõ║å’╝īÕ░▒Õ░åĶ┐śÕŁśµ┤╗ńÜäÕ»╣Ķ▒ĪÕżŹÕłČÕł░ÕÅ”õĖĆÕØŚõĖŖķØóÕÄ╗ŃĆéńäČÕÉĵŖŖÕĘ▓õĮ┐ńö©Ķ┐ćńÜäÕåģÕŁśń®║ķŚ┤õĖƵ¼ĪµĖģńÉåµÄē’╝īÕ”éõĖŗÕøŠµēĆńż║’╝Ü
 ┬Ā
┬Ā
ń╝║ńé╣’╝ÜõĮ┐ńö©ÕåģÕŁśµ»öÕĤµØźń╝®Õ░Åõ║åõĖĆÕŹŖŃĆé
ńÄ░Õ£©ńÜäÕĢåõĖÜĶÖܵŗ¤µ£║ķāĮķććńö©Ķ┐Öń¦ŹµöČķøåń«Śµ│ĢµØźÕø×µöȵ¢░ńö¤õ╗Ż’╝īµ£ēõ╝üõĖÜÕłåµ×ÉńÜäÕŠŚÕć║ÕģČÕ«×Õ╣ČõĖŹķ£Ćµ▒éÕ░åÕåģÕŁśµīē1:1ńÜäµ»öõŠŗÕłÆÕłå’╝īÕøĀõĖ║µ¢░ńö¤õ╗ŻõĖŁńÜäÕ»╣Ķ▒ĪÕż¦ķā©ÕłåķāĮµś»ŌĆ£µ£Øńö¤ÕżĢµŁ╗ŌĆØńÜäŃĆéµēĆõ╗ź’╝īHotSpotĶÖܵŗ¤µ£║ķ╗śĶ«żńÜäEdenÕÆīSurvivorńÜäÕż¦Õ░ŵ»öõŠŗµś»8:1ŃĆéõĖĆÕØŚEdenÕÆīõĖżÕØŚSurvivor’╝īµ»Åµ¼ĪõĮ┐ńö©õĖĆÕØŚEdenÕÆīõĖĆÕØŚSurvivor’╝īõ╣¤Õ░▒µś»Ķ»┤ÕŬµ£ē10%µś»µĄ¬Ķ┤╣ńÜäŃĆéÕ”éµ×£ÕÅ”õĖĆÕØŚSurvivorķāĮµŚĀµ│ĢÕŁśµöŠõĖŖµ¼ĪÕ×āÕ£ŠÕø×µöČńÜäÕ»╣Ķ▒ĪµŚČ’╝īķéŻĶ┐Öõ║øÕ»╣Ķ▒ĪÕ░åķĆÜĶ┐ćŌĆ£µŗģõ┐ص£║ÕłČŌĆØĶ┐øÕģźĶĆüÕ╣┤õ╗Żõ║åŃĆé
’╝ł3’╝ēµĀćĶ«░-µĢ┤ńÉå’╝łMark-Compact’╝ēń«Śµ│Ģ
ÕżŹÕłČń«Śµ│ĢõĖĆĶł¼µś»Õ»╣Õ»╣Ķ▒ĪÕŁśµ┤╗ńÄćĶŠāõĮÄńÜäõĖĆń¦ŹÕø×µöȵōŹõĮ£’╝īõĮåÕ»╣õ║ÄÕ»╣Ķ▒ĪÕŁśµ┤╗ńÄćĶŠāķ½śńÜäÕåģÕŁśÕī║Õ¤¤’╝łĶĆüÕ╣┤õ╗Ż’╝ēµØźĶ»┤’╝īµĢłµ×£Õ░▒õĖŹµś»ķéŻõ╣łńÉåµā│õ║å’╝īµĀćĶ«░-µĢ┤ńÉåń«Śµ│ĢÕøĀµŁżĶ»×ńö¤õ║åŃĆéµĀćĶ«░-µĢ┤ńÉåń«Śµ│ĢÕÆīµĀćĶ«░-µĖģķÖżń«Śµ│ĢÕĘ«õĖŹÕżÜ’╝īķāĮµś»õĖĆÕ╝ĆÕ¦ŗÕ»╣Õø×µöČÕ»╣Ķ▒ĪĶ┐øĶĪīµĀćĶ«░’╝īõĮåÕÉÄń╗ŁõĖŹµś»ńø┤µÄźÕ»╣Õ»╣Ķ▒ĪµĖģńÉå’╝īĶĆīµś»Ķ«®µēƵ£ēÕŁśµ┤╗ńÜäÕ»╣Ķ▒ĪķāĮÕÉæõĖĆń½»ń¦╗ÕŖ©’╝īńäČÕÉÄńø┤µÄźµĖģńÉåµÄēń½»ĶŠ╣ńĢīõ╗źÕż¢ńÜäÕåģÕŁś’╝īÕ”éõĖŗÕøŠµēĆńż║’╝Ü
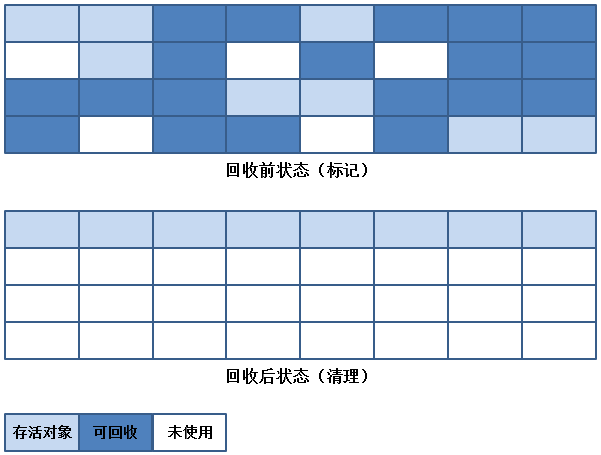 ┬Ā
┬Ā
’╝ł4’╝ēÕłåõ╗ŻµöČķøåń«Śµ│Ģ
Õłåõ╗ŻµöČķøåń«Śµ│Ģµś»ńø«ÕēŹÕż¦ķā©ÕłåJVMńÜäÕ×āÕ£ŠµöČķøåÕÖ©ķććńö©ńÜäń«Śµ│ĢŃĆéÕ«āńÜäµĀĖÕ┐āµĆصā│µś»µĀ╣µŹ«Õ»╣Ķ▒ĪÕŁśµ┤╗ńÜäńö¤ÕæĮÕ橵£¤Õ░åÕåģÕŁśÕłÆÕłåõĖ║ĶŗźÕ╣▓õĖ¬õĖŹÕÉīńÜäÕī║Õ¤¤ŃĆéõĖĆĶł¼µāģÕåĄõĖŗÕ░åÕĀåÕī║ÕłÆÕłåõĖ║ĶĆüÕ╣┤õ╗Ż’╝łTenured Generation’╝ēÕÆīµ¢░ńö¤õ╗Ż’╝łYoung Generation’╝ē’╝īĶĆüÕ╣┤õ╗ŻńÜäńē╣ńé╣µś»µ»Åµ¼ĪÕ×āÕ£ŠµöČķøåµŚČÕŬµ£ēÕ░æķćÅÕ»╣Ķ▒Īķ£ĆĶ”üĶó½Õø×µöČ’╝īĶĆīµ¢░ńö¤õ╗ŻńÜäńē╣ńé╣µś»µ»Åµ¼ĪÕ×āÕ£ŠÕø×µöȵŚČķāĮµ£ēÕż¦ķćÅńÜäÕ»╣Ķ▒Īķ£ĆĶ”üĶó½Õø×µöČ’╝īķéŻõ╣łÕ░▒ÕÅ»õ╗źµĀ╣µŹ«õĖŹÕÉīõ╗ŻńÜäńē╣ńé╣ķććÕÅ¢µ£ĆķĆéÕÉłńÜäµöČķøåń«Śµ│ĢŃĆé
1.2 Õ×āÕ£ŠµöČķøåÕÖ©’╝Ü
’╝ł1’╝ēõĖāń¦ŹÕ×āÕ£ŠµöČķøåÕÖ©:
- Serial’╝łõĖ▓ĶĪīGC’╝ē-ÕżŹÕłČ
- ParNew’╝łÕ╣ČĶĪīGC’╝ē-ÕżŹÕłČ
- Parallel Scavenge’╝łÕ╣ČĶĪīÕø×µöČGC’╝ē-ÕżŹÕłČ
- Serial Old’╝łMSC’╝ē’╝łõĖ▓ĶĪīGC’╝ē-µĀćĶ«░-µĢ┤ńÉå
- CMS’╝łÕ╣ČÕÅæGC’╝ē-µĀćĶ«░-µĖģķÖż
- Parallel Old’╝łÕ╣ČĶĪīGC’╝ē--µĀćĶ«░-µĢ┤ńÉå
- G1’╝łJDK1.7update14µēŹÕÅ»õ╗źµŁŻÕ╝ÅÕĢåńö©’╝ē
Ķ»┤µśÄ’╝Ü
- 1~3ńö©õ║ÄÕ╣┤ĶĮ╗õ╗ŻÕ×āÕ£ŠÕø×µöČ’╝ÜÕ╣┤ĶĮ╗õ╗ŻńÜäÕ×āÕ£ŠÕø×µöČń¦░õĖ║minor GC
- 4~6ńö©õ║ÄÕ╣┤ĶĆüõ╗ŻÕ×āÕ£ŠÕø×µöČ’╝łÕĮōńäČõ╣¤ÕÅ»õ╗źńö©õ║ĵ¢╣µ│ĢÕī║ńÜäÕø×µöČ’╝ē’╝ÜÕ╣┤ĶĆüõ╗ŻńÜäÕ×āÕ£ŠÕø×µöČń¦░õĖ║full GC
- G1ńŗ¼ń½ŗÕ«īµłÉ"Õłåõ╗ŻÕ×āÕ£ŠÕø×µöČ"
- ParNew Parallel ScavengeõĖżĶĆģķāĮµś»ÕżŹÕłČń«Śµ│Ģ’╝īķāĮµś»Õ╣ČĶĪīÕżäńÉå’╝īõĮåµś»õĖŹÕÉīńÜ䵜»’╝īparalel scavenge ÕÅ»õ╗źĶ«ŠńĮ«µ£ĆÕż¦gcÕü£ķĪ┐µŚČķŚ┤’╝ł-XX:MaxGCPauseMills’╝ēõ╗źÕÅŖgcµŚČķŚ┤ÕŹĀµ»ö(-XX:GCTimeRatio)
µ│©µäÅ’╝ÜÕ╣ČĶĪīõĖÄÕ╣ČÕÅæ
- Õ╣ČĶĪī’╝ÜÕżÜµØĪÕ×āÕ£ŠÕø×µöČń║┐ń©ŗÕÉīµŚČµōŹõĮ£
- Õ╣ČÕÅæ’╝ÜÕ×āÕ£ŠÕø×µöČń║┐ń©ŗõĖÄńö©µłĘń║┐ń©ŗõĖĆĶĄĘµōŹõĮ£
(2)ÕĖĖńö©õ║öń¦Źń╗äÕÉł:
- Serial/Serial Old
- ParNew/Serial Old’╝ÜõĖÄõĖŖĶŠ╣ńøĖµ»ö’╝īÕŬµś»µ»öÕ╣┤ĶĮ╗õ╗ŻÕżÜõ║åÕżÜń║┐ń©ŗÕ×āÕ£ŠÕø×µöČĶĆīÕĘ▓
- ParNew/CMS’╝ÜÕĮōõĖŗµ»öĶŠāķ½śµĢłńÜäń╗äÕÉł
- Parallel Scavenge/Parallel Old’╝ÜĶć¬ÕŖ©ń«ĪńÉåńÜäń╗äÕÉł
- G1’╝ܵ£ĆÕģłĶ┐øńÜäµöČķøåÕÖ©’╝īõĮåµś»ķ£ĆĶ”üJDK1.7update14õ╗źõĖŖ
(2.1)Serial/Serial Old’╝Ü
┬Ā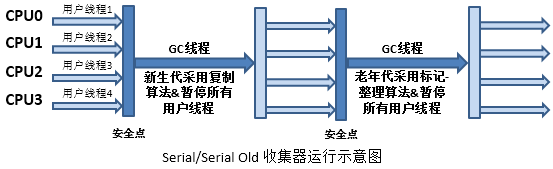
ńē╣ńé╣’╝Ü
- Õ╣┤ĶĮ╗õ╗ŻSerialµöČķøåÕÖ©ķććńö©ÕŹĢõĖ¬GCń║┐ń©ŗÕ«×ńÄ░"ÕżŹÕłČ"ń«Śµ│Ģ’╝łÕīģµŗ¼µē½µÅÅŃĆüÕżŹÕłČ’╝ē
- Õ╣┤ĶĆüõ╗ŻSerial OldµöČķøåÕÖ©ķććńö©ÕŹĢõĖ¬GCń║┐ń©ŗÕ«×ńÄ░"µĀćĶ«░-µĢ┤ńÉå"ń«Śµ│Ģ
- SerialõĖÄSerial OldķāĮõ╝ܵÜéÕü£µēƵ£ēńö©µłĘń║┐ń©ŗ’╝łÕŹ│STW’╝ē
Ķ»┤µśÄ’╝Ü
STW’╝łstop the world’╝ē’╝Üń╝¢Ķ»æõ╗ŻńĀüµŚČõĖ║µ»ÅõĖĆõĖ¬µ¢╣µ│Ģµ│©Õģźsafepoint’╝łµ¢╣µ│ĢõĖŁÕŠ¬ńÄ»ń╗ōµØ¤ńÜäńé╣ŃĆüµ¢╣µ│Ģµē¦ĶĪīń╗ōµØ¤ńÜäńé╣’╝ē’╝īÕ£©µÜéÕü£Õ║öńö©µŚČ’╝īķ£ĆĶ”üńŁēÕŠģµēƵ£ēńÜäńö©µłĘń║┐ń©ŗĶ┐øÕģźsafepoint’╝īõ╣ŗÕÉĵÜéÕü£µēƵ£ēń║┐ń©ŗ’╝īńäČÕÉÄĶ┐øĶĪīÕ×āÕ£ŠÕø×µöČŃĆé
ķĆéńö©Õ£║ÕÉł’╝Ü
- CPUµĀĖµĢ░<2’╝īńē®ńÉåÕåģÕŁś<2GńÜäµ£║ÕÖ©’╝łń«ĆÕŹĢµØźĶ«▓’╝īÕŹĢCPU’╝īµ¢░ńö¤õ╗Żń®║ķŚ┤ĶŠāÕ░ÅõĖöÕ»╣STWµŚČķŚ┤Ķ”üµ▒éõĖŹķ½śńÜäµāģÕåĄõĖŗõĮ┐ńö©’╝ē
- -XX:UseSerialGC’╝ÜÕ╝║ÕłČõĮ┐ńö©Ķ»źGCń╗äÕÉł
- -XX:PrintGCApplicationStoppedTime’╝ܵ¤źń£ŗSTWµŚČķŚ┤
- ńö▒õ║ÄÕ«āÕ«×ńÄ░ńøĖÕ»╣ń«ĆÕŹĢ’╝īµ▓Īµ£ēń║┐ń©ŗńøĖÕģ│ńÜäķóØÕż¢Õ╝ĆķöĆ’╝łõĖ╗Ķ”üµīćń║┐ń©ŗÕłćµŹóõĖÄÕÉīµŁź’╝ē’╝īÕøĀµŁżķØ×ÕĖĖķĆéÕÉłĶ┐ÉĶĪīõ║ÄÕ«óµłĘń½»PCńÜäÕ░ÅÕ×ŗÕ║öńö©ń©ŗÕ║Å’╝īµł¢ĶĆģµĪīķØóÕ║öńö©ń©ŗÕ║Å’╝łµ»öÕ”éswingń╝¢ÕåÖńÜäńö©µłĘńĢīķØóń©ŗÕ║Å’╝ē’╝īõ╗źÕÅŖµłæõ╗¼Õ╣│µŚČńÜäÕ╝ĆÕÅæŃĆüĶ░āĶ»ĢŃĆüµĄŗĶ»ĢńŁēŃĆé
(2.2)ParNew/Serial Old’╝Ü
┬Ā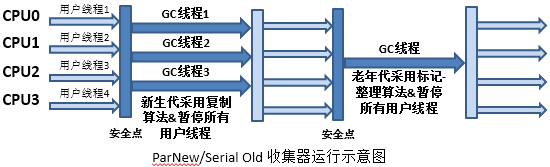
Ķ»┤µśÄ’╝Ü
ParNewķÖżõ║åķććńö©ÕżÜGCń║┐ń©ŗµØźÕ«×ńÄ░ÕżŹÕłČń«Śµ│Ģõ╗źÕż¢’╝īÕģČõ╗¢ķāĮõĖÄSerialõĖƵĀĘ’╝īõĮåµś»µŁżń╗äÕÉłõĖŁńÜäSerial OldÕÅłµś»õĖĆõĖ¬ÕŹĢGCń║┐ń©ŗ’╝īµēĆõ╗źĶ»źń╗äÕÉłµś»õĖĆõĖ¬µ»öĶŠāÕ░┤Õ░¼ńÜäń╗äÕÉł’╝īÕ£©ÕŹĢCPUµāģÕåĄõĖŗµ▓Īµ£ēSerial/Serial OldķƤÕ║”Õ┐½’╝łÕøĀõĖ║ParNewÕżÜń║┐ń©ŗķ£ĆĶ”üÕłćµŹó’╝ē’╝īÕ£©ÕżÜCPUµāģÕåĄõĖŗÕÅłµ▓Īµ£ēõ╣ŗÕÉÄńÜäõĖēń¦Źń╗äÕÉłÕ┐½’╝łÕøĀõĖ║Serial Oldµś»ÕŹĢGCń║┐ń©ŗ’╝ē’╝īµēĆõ╗źõĮ┐ńö©ÕģČÕ«×õĖŹÕżÜŃĆé
-XX:ParallelGCThreads’╝ܵīćÕ«ÜParNew GCń║┐ń©ŗńÜäµĢ░ķćÅ’╝īķ╗śĶ«żõĖÄCPUµĀĖµĢ░ńøĖÕÉī’╝īĶ»źÕÅéµĢ░Õ£©õ║ÄCMS GCń╗äÕÉłµŚČ’╝īõ╣¤ÕÅ»ĶāĮõ╝Üńö©Õł░
(2.3)Parallel Scavenge/Parallel Old’╝Ü
┬Ā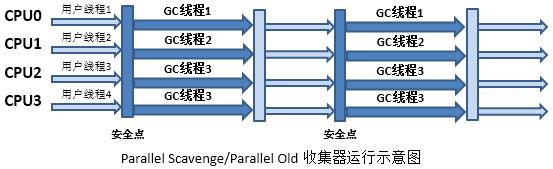
ńē╣ńé╣’╝Ü
- Õ╣┤ĶĮ╗õ╗ŻParallel ScavengeµöČķøåÕÖ©ķććńö©ÕżÜõĖ¬GCń║┐ń©ŗÕ«×ńÄ░"ÕżŹÕłČ"ń«Śµ│Ģ’╝łÕīģµŗ¼µē½µÅÅŃĆüÕżŹÕłČ’╝ē
- Õ╣┤ĶĆüõ╗ŻParallel OldµöČķøåÕÖ©ķććńö©ÕżÜõĖ¬GCń║┐ń©ŗÕ«×ńÄ░"µĀćĶ«░-µĢ┤ńÉå"ń«Śµ│Ģ
- Parallel ScavengeõĖÄParallel OldķāĮõ╝ܵÜéÕü£µēƵ£ēńö©µłĘń║┐ń©ŗ’╝łÕŹ│STW’╝ē
Ķ»┤µśÄ’╝Ü
- ÕÉ×ÕÉÉķćÅ’╝ÜCPUĶ┐ÉĶĪīõ╗ŻńĀüµŚČķŚ┤/(CPUĶ┐ÉĶĪīõ╗ŻńĀüµŚČķŚ┤+GCµŚČķŚ┤)
- CMSõĖ╗Ķ”üµ│©ķćŹSTWńÜäń╝®ń¤Ł’╝łĶ»źµŚČķŚ┤ĶČŖń¤Ł’╝īńö©µłĘõĮōķ¬īĶČŖÕźĮ’╝īµēĆõ╗źõĖ╗Ķ”üńö©õ║ÄÕżäńÉåÕŠłÕżÜńÜäõ║żõ║Æõ╗╗ÕŖĪńÜäµāģÕåĄ’╝ē
- Parallel Scavenge/Parallel OldõĖ╗Ķ”üµ│©ķćŹÕÉ×ÕÉÉķćÅ’╝łÕÉ×ÕÉÉķćÅĶČŖÕż¦’╝īĶ»┤µśÄCPUÕł®ńö©ńÄćĶČŖķ½ś’╝īµēĆõ╗źõĖ╗Ķ”üńö©õ║ÄÕżäńÉåÕŠłÕżÜńÜäCPUĶ«Īń«Śõ╗╗ÕŖĪĶĆīńö©µłĘõ║żõ║Æõ╗╗ÕŖĪĶŠāÕ░æńÜäµāģÕåĄ’╝ē
ÕÅéµĢ░Ķ«ŠńĮ«’╝Ü
- -XX:+UseParallelOldGC’╝ÜõĮ┐ńö©Ķ»źGCń╗äÕÉł
- -XX:GCTimeRatio’╝Üńø┤µÄźĶ«ŠńĮ«ÕÉ×ÕÉÉķćÅÕż¦Õ░Å’╝īÕüćĶ«ŠĶ«ŠõĖ║19’╝īÕłÖÕģüĶ«ĖńÜäµ£ĆÕż¦GCµŚČķŚ┤ÕŹĀµĆ╗µŚČķŚ┤ńÜä1/(1 +19)’╝īķ╗śĶ«żÕĆ╝õĖ║99’╝īÕŹ│1/(1+99)
- -XX:MaxGCPauseMillis’╝ܵ£ĆÕż¦GCÕü£ķĪ┐µŚČķŚ┤’╝īĶ»źÕÅéµĢ░Õ╣ČķØ×ĶČŖÕ░ÅĶČŖÕźĮ
- -XX:+UseAdaptiveSizePolicy’╝ÜÕ╝ĆÕÉ»Ķ»źÕÅéµĢ░’╝ī-Xmn/-XX:SurvivorRatio/-XX:PretenureSizeThresholdĶ┐Öõ║øÕÅéµĢ░Õ░▒õĖŹĶĄĘõĮ£ńö©õ║å’╝īĶÖܵŗ¤µ£║õ╝ÜĶć¬ÕŖ©µöČķøåńøæµÄ¦õ┐Īµü»’╝īÕŖ©µĆüĶ░āµĢ┤Ķ┐Öõ║øÕÅéµĢ░õ╗źµÅÉõŠøµ£ĆÕÉłķĆéńÜäńÜäÕü£ķĪ┐µŚČķŚ┤µł¢ĶĆģµ£ĆÕż¦ńÜäÕÉ×ÕÉÉķćÅ’╝łGCĶć¬ķĆéÕ║öĶ░āĶŖéńŁ¢ńĢź’╝ē’╝īĶĆīµłæõ╗¼ķ£ĆĶ”üĶ«ŠńĮ«ńÜäÕ░▒µś»-Xmx’╝ī-XX:+UseParallelOldGCµł¢-XX:GCTimeRatioõĖżõĖ¬ÕÅéµĢ░Õ░▒ÕźĮ’╝łÕĮōńäČ-Xmsõ╣¤µīćÕ«ÜõĖŖõĖÄ-XmxńøĖÕÉīÕ░▒ÕźĮ’╝ē
ķĆéńö©Õ£║ÕÉł’╝Ü
- ÕŠłÕżÜńÜäCPUĶ«Īń«Śõ╗╗ÕŖĪĶĆīńö©µłĘõ║żõ║Æõ╗╗ÕŖĪĶŠāÕ░æńÜäµāģÕåĄ
- õĖŹµā│Ķć¬ÕĘ▒ÕÄ╗Ķ┐ćÕżÜńÜäÕģ│µ│©GCÕÅéµĢ░’╝īµā│Ķ«®ĶÖܵŗ¤µ£║Ķć¬ÕĘ▒Ķ┐øĶĪīĶ░āõ╝śÕĘźõĮ£
- Õ»╣ÕÉ×ÕÉÉķćÅĶ”üµ▒éĶŠāķ½ś’╝īµł¢ķ£ĆĶ”üĶŠŠÕł░õĖĆÕ«ÜńÜäķćÅŃĆé
(2.4)ParNew/CMS’╝Ü
┬Ā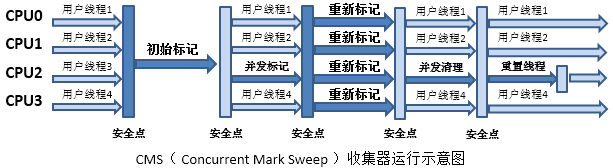
Ķ»┤µśÄ’╝Ü
- õ╗źõĖŖÕŬµś»Õ╣┤ĶĆüõ╗ŻCMSµöČķøåńÜäĶ┐ćń©ŗ’╝īÕ╣┤ĶĮ╗õ╗ŻParNewń£ŗ"2.2ŃĆüParNew/Serial Old"Õ░▒ÕźĮ
- CMSµś»ÕżÜÕø×µöČń║┐ń©ŗńÜä’╝īõĖŹĶ”üĶó½õĖŖÕøŠĶ»»Õ»╝’╝īķ╗śĶ«żńÜäń║┐ń©ŗµĢ░’╝Ü(CPUµĢ░ķćÅ+3)/4
- CMSõĖ╗Ķ”üµ│©ķćŹSTWńÜäń╝®ń¤Ł’╝łĶ»źµŚČķŚ┤ĶČŖń¤Ł’╝īńö©µłĘõĮōķ¬īĶČŖÕźĮ’╝īµēĆõ╗źõĖ╗Ķ”üńö©õ║ÄÕżäńÉåÕŠłÕżÜńÜäõ║żõ║Æõ╗╗ÕŖĪńÜäµāģÕåĄ’╝ē
ńē╣ńé╣’╝Ü
1.Õ╣┤ĶĮ╗õ╗ŻParNewµöČķøåÕÖ©ķććńö©ÕżÜõĖ¬GCń║┐ń©ŗÕ«×ńÄ░"ÕżŹÕłČ"ń«Śµ│Ģ’╝łÕīģµŗ¼µē½µÅÅŃĆüÕżŹÕłČ’╝ē
2.Õ╣┤ĶĆüõ╗ŻCMSµöČķøåÕÖ©ķććńö©ÕżÜń║┐ń©ŗÕ«×ńÄ░"µĀćĶ«░-µĖģķÖż"ń«Śµ│Ģ
- ÕłØÕ¦ŗµĀćĶ«░’╝ܵĀćĶ«░õĖĵĀ╣ķøåÕÉłĶŖéńé╣ńø┤µÄźÕģ│ĶüöńÜäĶŖéńé╣ŃĆ鵌ČķŚ┤ķØ×ÕĖĖń¤Ł’╝īķ£ĆĶ”üSTW
- Õ╣ČÕÅæµĀćĶ«░’╝ÜķüŹÕÄåõ╣ŗÕēŹµĀćĶ«░Õł░ńÜäÕģ│ĶüöĶŖéńé╣’╝īń╗¦ń╗ŁÕÉæõĖŗµĀćĶ«░µēƵ£ēÕŁśµ┤╗ĶŖéńé╣ŃĆ鵌ČķŚ┤ĶŠāķĢ┐ŃĆé
- ķ揵¢░µĀćĶ«░’╝Üķ揵¢░ķüŹÕÄåtraceÕ╣ČÕÅæµ£¤ķŚ┤õ┐«µö╣Ķ┐ćńÜäÕ╝Ģńö©Õģ│ń│╗Õ»╣Ķ▒ĪŃĆ鵌ČķŚ┤õ╗ŗõ║ÄÕłØÕ¦ŗµĀćĶ«░õĖÄÕ╣ČÕÅæµĀćĶ«░õ╣ŗķŚ┤’╝īķĆÜÕĖĖõĖŹõ╝ÜÕŠłķĢ┐ŃĆéķ£ĆĶ”üSTW
- Õ╣ČÕÅæµĖģńÉå’╝Üńø┤µÄźµĖģķÖżķØ×ÕŁśµ┤╗Õ»╣Ķ▒Ī’╝īµĖģńÉåõ╣ŗÕÉÄ’╝īÕ░åĶ»źń║┐ń©ŗÕŹĀńö©ńÜäCPUÕłćµŹóń╗Öńö©µłĘń║┐ń©ŗ
3.ÕłØÕ¦ŗµĀćĶ«░õĖÄķ揵¢░µĀćĶ«░ķāĮõ╝ܵÜéÕü£µēƵ£ēńö©µłĘń║┐ń©ŗ’╝łÕŹ│STW’╝ē’╝īõĮåµś»µŚČķŚ┤ĶŠāń¤Ł’╝øÕ╣ČÕÅæµĀćĶ«░õĖÄÕ╣ČÕÅæµĖģńÉåµŚČķŚ┤ĶŠāķĢ┐’╝īõĮåµś»õĖŹķ£ĆĶ”üSTW
Õģ│õ║ÄÕ╣ČÕÅæµĀćĶ«░µ£¤ķŚ┤µĆĵĀĘĶ«░ÕĮĢÕÅæńö¤ÕÅśÕŖ©ńÜäÕ╝Ģńö©Õģ│ń│╗Õ»╣Ķ▒Ī’╝īÕ£©ķ揵¢░µĀćĶ«░µ£¤ķŚ┤µĆĵĀʵē½µÅÅĶ┐Öõ║øÕ»╣Ķ▒Ī
ń╝║ńé╣’╝Ü
- Õ╣ČÕÅæµĀćĶ«░õĖÄÕ╣ČÕÅæµĖģńÉå’╝ܵīēńģ¦Ķ»┤µśÄńÜäń¼¼õ║īńé╣µØźĶ«▓’╝īÕüćĶ«Šµ£ē2õĖ¬CPU’╝īķéŻõ╣łÕģČõĖŁµ£ēõĖĆõĖ¬CPUõ╝Üńö©õ║ÄÕ×āÕ£ŠÕø×µöČ’╝īĶĆīÕÅ”õĖĆõĖ¬ńö©õ║Äńö©µłĘń║┐ń©ŗ’╝īĶ┐ÖµĀĘńÜäĶ»Ø’╝īõ╣ŗÕēŹµś»õĖżCPUĶ┐ÉĶĪīńö©µłĘń║┐ń©ŗ’╝īńÄ░Õ£©µś»õĖĆõĖ¬’╝īķéŻõ╣łµĢłńÄćÕ░▒õ╝ܵƟÕē¦õĖŗķÖŹŃĆéõ╣¤Õ░▒µś»Ķ»┤’╝īķÖŹõĮÄõ║åÕÉ×ÕÉÉķćÅ’╝łÕŹ│ķÖŹõĮÄõ║åCPUõĮ┐ńö©ńÄć’╝ēŃĆé
- Õ╣ČÕÅæµĖģńÉå’╝ÜÕ£©Ķ┐ÖõĖĆĶ┐ćń©ŗõĖŁ’╝īõ║¦ńö¤ńÜäÕ×āÕ£ŠµŚĀµ│ĢĶó½µĖģńÉå’╝łÕøĀõĖ║ÕÅæńö¤Õ£©ķ揵¢░µĀćĶ«░õ╣ŗÕÉÄ’╝ē
- Õ╣ČÕÅæµĀćĶ«░õĖÄÕ╣ČÕÅæµĖģńÉå’╝Üńö▒õ║ĵś»õĖÄńö©µłĘń║┐ń©ŗÕ╣ČÕÅæńÜä’╝īµēĆõ╗źńö©µłĘń║┐ń©ŗÕÅ»ĶāĮõ╝ÜÕłåķģŹÕ»╣Ķ▒Ī’╝īĶ┐ÖµĀʵŚóÕÅ»ĶāĮÕ»╣Ķ▒Īńø┤µÄźĶ┐øÕģźÕ╣┤ĶĆüõ╗Ż’╝łõŠŗÕ”é’╝īÕż¦Õ»╣Ķ▒Ī’╝ē’╝īõ╣¤ÕÅ»ĶāĮĶ┐øÕģźÕ╣┤ĶĮ╗õ╗ŻÕÉÄ’╝īÕ╣┤ĶĮ╗õ╗ŻÕÅæńö¤minor GC’╝īĶ┐ÖµĀĘńÜäĶ»Ø’╝īÕ«×ķÖģõĖŖĶ”üµ▒鵳æõ╗¼ńÜäÕ╣┤ĶĆüõ╗Żķ£ĆĶ”üķóäńĢÖõĖĆÕ«Üń®║ķŚ┤’╝īõ╣¤Õ░▒µś»Ķ»┤Ķ”üÕ£©Õ╣┤ĶĆüõ╗ŻĶ┐śµ£ēõĖĆÕ«Üń®║ķŚ┤ńÜäµāģÕåĄõĖŗÕ░▒Ķ”üĶ┐øĶĪīÕ×āÕ£ŠÕø×µöČ’╝īńĢÖÕć║õĖĆÕ«ÜÕåģÕŁśń®║ķŚ┤µØźõŠøÕģČõ╗¢ń║┐ń©ŗõĮ┐ńö©’╝īĶĆīõĖŹĶāĮńŁēÕł░Õ╣┤ĶĆüõ╗ŻÕ┐½ńłåµ╗Īõ║åµēŹĶ┐øĶĪīÕ×āÕ£ŠÕø×µöČ’╝īķĆÜĶ┐ć-XX:CMSInitiatingOccupancyFractionµØźµīćÕ«ÜÕĮōÕ╣┤ĶĆüõ╗Żń®║ķŚ┤µ╗Īõ║åÕżÜÕ░æÕÉÄĶ┐øĶĪīÕ×āÕ£ŠÕø×µöČ
- µĀćĶ«░-µĖģńÉåń«Śµ│Ģ’╝Üõ╝Üõ║¦ńö¤ÕåģÕŁśńóÄńēć’╝īńö▒õ║ĵś»Õ£©ĶĆüÕ╣┤õ╗Ż’╝īÕÅ»ĶāĮõ╝ܵÅÉÕēŹĶ¦”ÕÅæFull GC’╝łĶ┐ÖµŁŻµś»µłæõ╗¼Ķ”üÕ░ĮķćÅÕćÅÕ░æńÜä’╝ē
ÕÅéµĢ░Ķ«ŠńĮ«’╝Ü
- -XX:+UseConcMarkSweepGC’╝ÜõĮ┐ńö©Ķ»źGCń╗äÕÉł
- -XX:CMSInitiatingOccupancyFraction’╝ܵīćÕ«ÜÕĮōÕ╣┤ĶĆüõ╗Żń®║ķŚ┤µ╗Īõ║åÕżÜÕ░æÕÉÄĶ┐øĶĪīÕ×āÕ£ŠÕø×µöČ
- -XX:+UseCMSCompactAtFullCollection’╝Ü’╝łķ╗śĶ«żµś»Õ╝ĆÕÉ»ńÜä’╝ēÕ£©CMSµöČķøåÕÖ©ķĪČõĖŹõĮÅĶ”üĶ┐øĶĪīFullGCµŚČÕ╝ĆÕÉ»ÕåģÕŁśńóÄńēćµĢ┤ńÉåĶ┐ćń©ŗ’╝īĶ»źĶ┐ćń©ŗķ£ĆĶ”üSTW
- -XX:CMSFullGCsBeforeCompaction’╝ܵīćÕ«ÜÕżÜÕ░æµ¼ĪFullGCÕÉĵēŹĶ┐øĶĪīµĢ┤ńÉå
- -XX:ParallelCMSThreads’╝ܵīćÕ«ÜCMSÕø×µöČń║┐ń©ŗńÜäµĢ░ķćÅ’╝īķ╗śĶ«żõĖ║’╝Ü(CPUµĢ░ķćÅ+3)/4
ķĆéńö©Õ£║ÕÉł’╝Ü
ńö©õ║ÄÕżäńÉåÕŠłÕżÜńÜäõ║żõ║Æõ╗╗ÕŖĪńÜäµāģÕåĄ
µ¢╣µ│ĢÕī║ńÜäÕø×µöČõĖĆĶł¼õĮ┐ńö©CMS’╝īķģŹńĮ«õĖżõĖ¬ÕÅéµĢ░’╝Ü-XX:+CMSPermGenSweepingEnabledõĖÄ-XX:+CMSClassUnloadingEnabled
ķĆéńö©õ║ÄõĖĆõ║øķ£ĆĶ”üķĢ┐µ£¤Ķ┐ÉĶĪīõĖöÕ»╣ńøĖÕ║öµŚČķŚ┤µ£ēõĖĆÕ«ÜĶ”üµ▒éńÜäÕÉÄÕÅ░ń©ŗÕ║Å
(2.5)G1
┬Ā
Ķ»┤µśÄ’╝Ü
- õ╗ÄõĖŖÕøŠµØźń£ŗ’╝īG1õĖÄCMSńøĖµ»ö’╝īõ╗ģÕ£©µ£ĆÕÉÄńÜä"ńŁøķĆēÕø×µöČ"ķā©ÕłåõĖŹÕÉī’╝łCMSµś»Õ╣ČÕÅæµĖģķÖż’╝ē’╝īÕ«×ķÖģõĖŖG1Õø×µöČÕÖ©ńÜäµĢ┤õĖ¬ÕĀåÕåģÕŁśńÜäÕłÆÕłåķāĮõĖÄÕģČõ╗¢µöČķøåÕÖ©õĖŹÕÉīŃĆé
- CMSķ£ĆĶ”üķģŹÕÉłParNew’╝īG1ÕÅ»ÕŹĢńŗ¼Õø×µöȵĢ┤õĖ¬ń®║ķŚ┤
ÕĤńÉå’╝Ü
- G1µöČķøåÕÖ©Õ░åµĢ┤õĖ¬ÕĀåÕłÆÕłåõĖ║ÕżÜõĖ¬Õż¦Õ░ÅńøĖńŁēńÜäRegion
- G1ĶʤĶĖ¬ÕÉäõĖ¬regionķćīķØóńÜäÕ×āÕ£ŠÕĀåń¦»ńÜäõ╗ĘÕĆ╝’╝łÕø×µöČÕÉĵēĆĶÄĘÕŠŚńÜäń®║ķŚ┤Õż¦Õ░Åõ╗źÕÅŖÕø×µöȵēĆķ£ĆµŚČķŚ┤ķĢ┐ń¤ŁńÜäń╗Åķ¬īÕĆ╝’╝ē’╝īÕ£©ÕÉÄÕÅ░ń╗┤µŖżõĖĆÕ╝Āõ╝śÕģłÕłŚĶĪ©’╝īµ»Åµ¼ĪµĀ╣µŹ«ÕģüĶ«ĖńÜäµöČķøåµŚČķŚ┤’╝īõ╝śÕģłÕø×µöČõ╗ĘÕĆ╝µ£ĆÕż¦ńÜäregion’╝īĶ┐Öń¦ŹµĆØĶĘ»’╝ÜÕ£©µīćÕ«ÜńÜ䵌ČķŚ┤Õåģ’╝īµē½µÅÅķā©Õłåµ£Ćµ£ēõ╗ĘÕĆ╝ńÜäregion’╝łĶĆīõĖŹµś»µē½µÅŵĢ┤õĖ¬ÕĀåÕåģÕŁś’╝ē’╝īÕ╣ČÕø×µöČ’╝īÕüÜÕł░Õ░ĮÕÅ»ĶāĮńÜäÕ£©µ£ēķÖÉńÜ䵌ČķŚ┤ÕåģĶÄĘÕÅ¢Õ░ĮÕÅ»ĶāĮķ½śńÜäµöČķøåµĢłńÄćŃĆé
Ķ┐ÉõĮ£µĄüń©ŗ’╝Ü
- ÕłØÕ¦ŗµĀćĶ«░’╝ܵĀćĶ«░Õć║µēƵ£ēõĖĵĀ╣ĶŖéńé╣ńø┤µÄźÕģ│ĶüöÕ╝Ģńö©Õ»╣Ķ▒ĪŃĆéķ£ĆĶ”üSTW
- Õ╣ČÕÅæµĀćĶ«░’╝ÜķüŹÕÄåõ╣ŗÕēŹµĀćĶ«░Õł░ńÜäÕģ│ĶüöĶŖéńé╣’╝īń╗¦ń╗ŁÕÉæõĖŗµĀćĶ«░µēƵ£ēÕŁśµ┤╗ĶŖéńé╣ŃĆéÕ£©µŁżµ£¤ķŚ┤µēƵ£ēÕÅśÕī¢Õ╝Ģńö©Õģ│ń│╗ńÜäÕ»╣Ķ▒Ī’╝īķāĮõ╝ÜĶó½Ķ«░ÕĮĢÕ£©Remember Set LogsõĖŁ
- µ£Ćń╗łµĀćĶ«░’╝ܵĀćĶ«░Õ£©Õ╣ČÕÅæµĀćĶ«░µ£¤ķŚ┤’╝īµ¢░õ║¦ńö¤ńÜäÕ×āÕ£ŠŃĆéķ£ĆĶ”üSTW
- ńŁøķĆēÕø×µöČ’╝ܵĀ╣µŹ«ńö©µłĘµīćÕ«ÜńÜäµ£¤µ£øÕø×µöȵŚČķŚ┤Õø×µöČõ╗ĘÕĆ╝ĶŠāÕż¦ńÜäÕ»╣Ķ▒Ī’╝łń£ŗ"ÕĤńÉå"ń¼¼õ║īµØĪ’╝ēŃĆéķ£ĆĶ”üSTW
õ╝śńé╣’╝Ü
- Õü£ķĪ┐µŚČķŚ┤ÕÅ»õ╗źķó䵥ŗ’╝ܵłæõ╗¼µīćիܵŚČķŚ┤’╝īÕ£©µīćիܵŚČķŚ┤ÕåģÕŬÕø×µöČķā©Õłåõ╗ĘÕĆ╝µ£ĆÕż¦ńÜäń®║ķŚ┤’╝īĶĆīCMSķ£ĆĶ”üµē½µÅŵĢ┤õĖ¬Õ╣┤ĶĆüõ╗Ż’╝īµŚĀµ│Ģķó䵥ŗÕü£ķĪ┐µŚČķŚ┤
- µŚĀÕåģÕŁśńóÄńēć’╝ÜÕ×āÕ£ŠÕø×µöČÕÉÄõ╝ܵĢ┤ÕÉłń®║ķŚ┤’╝īCMSķććńö©"µĀćĶ«░-µĖģńÉå"ń«Śµ│Ģ’╝īÕŁśÕ£©ÕåģÕŁśńóÄńēć
- ńŁøķĆēÕø×µöČķśČµ«Ą’╝Ü
- ńö▒õ║ÄÕŬÕø×µöČķā©Õłåregion’╝īµēĆõ╗źSTWµŚČķŚ┤µłæõ╗¼ÕÅ»µÄ¦’╝īµēĆõ╗źõĖŹķ£ĆĶ”üõĖÄńö©µłĘń║┐ń©ŗÕ╣ČÕÅæõ║ēµŖóCPUĶĄäµ║É’╝īĶĆīCMSÕ╣ČÕÅæµĖģńÉåķ£ĆĶ”üÕŹĀµŹ«õĖĆķā©ÕłåńÜäCPU’╝īõ╝ÜķÖŹõĮÄÕÉ×ÕÉÉķćÅŃĆé
- ńö▒õ║ÄSTW’╝īµēĆõ╗źõĖŹõ╝Üõ║¦ńö¤"µĄ«ÕŖ©Õ×āÕ£Š"’╝łÕŹ│CMSÕ£©Õ╣ČÕÅæµĖģńÉåķśČµ«Ąõ║¦ńö¤ńÜ䵌Āµ│ĢÕø×µöČńÜäÕ×āÕ£Š’╝ē
ķĆéńö©ĶīāÕø┤’╝Ü
- Ķ┐Įµ▒éSTWń¤Ł’╝ÜĶŗźParNew/CMSńö©ńÜäµī║ÕźĮ’╝īÕ░▒ńö©Ķ┐ÖõĖ¬’╝øĶŗźõĖŹń¼”ÕÉł’╝īńö©G1
- Ķ┐Įµ▒éÕÉ×ÕÉÉķćÅ’╝Üńö©Parallel Scavenge/Parallel Old’╝īĶĆīG1Õ£©ÕÉ×ÕÉÉķćŵ¢╣ķØóµ▓Īµ£ēõ╝śÕŖ┐



ńøĖÕģ│µÄ©ĶŹÉ
ÕøøÕż¦Õ×āÕ£ŠÕø×µöČń«Śµ│Ģ’╝ÜÕżŹÕłČń«Śµ│ĢŃĆüµĀćĶ«░-µĖģķÖżń«Śµ│ĢŃĆüµĀćĶ«░-µĢ┤ńÉåń«Śµ│ĢŃĆüÕłåõ╗ŻµöČķøåń«Śµ│Ģ õĖāÕż¦Õ×āÕ£ŠÕø×µöČÕÖ©’╝ÜSerialŃĆüSerial OldŃĆüParNewŃĆüCMSŃĆüParallelŃĆüParallel OldŃĆüG1 JVMĶ░āõ╝ś’╝ÜÕæĮõ╗żĶĪīµīćõ╗ż’╝īĶ«ŠńĮ«ÕĀåÕåģÕŁśÕż¦Õ░ÅńÜäÕÅéµĢ░
Õ×āÕ£ŠÕø×µöČń«Śµ│ĢµĆ╗ń╗ō Õ╝Ģńö©Ķ«ĪµĢ░ń«Śµ│Ģ õ╝śńé╣’╝Ü’╝ł1’╝ēÕåģÕŁśń«ĪńÉåÕ╝ĆķöĆÕłåÕĖāÕ╣│µ╗æ’╝īµŚĀķ£ĆµīéĶĄĘ’╝ø’╝ł2’╝ēÕ║¤Õ╝āÕŹ│Õø×µöČ ń╝║ńé╣’╝Ü’╝ł1’╝ēµ»Åµ¼ĪÕ£©Õ»╣Ķ▒ĪÕłøÕ╗║µł¢ĶĆģķćŖµöŠµŚČ’╝īķāĮĶ”üĶ«Īń«ŚÕ╝Ģńö©Ķ«ĪµĢ░ÕĆ╝’╝īĶ┐Öõ╝ÜÕ╝ĢĶĄĘķóØÕż¢ńÜäÕ╝ĆķöĆ’╝ł2’╝ēõ╗śÕć║ķóØÕż¢ń®║ķŚ┤ÕŁśµöŠÕ╝Ģńö©Ķ«ĪµĢ░’╝ł3’╝ē...
ń¼¼ÕøøĶŖé’╝ÜÕ×āÕ£ŠÕø×µöČń«Śµ│Ģ 1.1µĀćĶ«░µĖģķÖżń«Śµ│Ģ 1.2ÕżŹÕłČń«Śµ│Ģ 1.3 µĀćĶ«░µĢ┤ńÉå’╝łµĀćĶ«░ÕÄŗń╝®’╝ēń«Śµ│Ģ ń¼¼õ║öĶŖé’╝ÜÕ×āÕ£ŠÕø×µöČÕÖ© 1.1Serial/Serial OldµöČķøåÕÖ© 1.2 ParNewµöČķøåÕÖ© 1.3Parallel ScavengeµöČķøåÕÖ© 1.4Parallel OldµöČķøåÕÖ© 1.5CMS...
Ķ»źĶĄäµ║ÉķĆÜĶ┐ćÕøŠÕāÅÕÅŖµ¢ćÕŁŚĶ»”ń╗åÕłåµ×ÉÕø×ńŁöõ║åJVMÕ×āÕ£Š...ÕøŠńö╗Ķ»”ń╗åõ╗ŗń╗ŹÕĖĖĶ¦üńÜäõĖēń¦ŹÕ×āÕ£ŠÕø×µöČń«Śµ│Ģ’╝īÕīģµŗ¼µĀćĶ«░-µĖģķÖżń«Śµ│ĢŃĆüµĀćĶ«░-µĢ┤ńÉåń«Śµ│ĢÕÆīµĀćĶ«░-ÕżŹÕłČń«Śµ│ĢŃĆé 3.Õ×āÕ£ŠÕø×µöČńÜäÕģĘõĮōµĄüń©ŗµś»µĆĵĀĘńÜä’╝¤ ÕøŠńö╗Õłåµ×Éõ╗ŗń╗ŹÕ×āÕ£ŠÕø×µöȵ£║ÕłČķóØÕłåÕī║ÕÆīń«Śµ│ĢĶ┐ćń©ŗ
ÕĄīÕģźÕ╝ÅJavaĶÖܵŗ¤µ£║ńÜäÕ×āÕ£ŠÕø×µöČń«Śµ│ĢńÜäńĀöń®Č’╝īÕłśÕüźÕ¤╣’╝ī’╝īÕ£©ÕĄīÕģźÕ╝Åń│╗ń╗¤õĖŁ’╝īķ£ĆĶ”üÕłåµ×Éõ╗Ćõ╣łµĀĘńÜäÕ×āÕ£ŠÕø×µöȵ£║ÕłČĶāĮÕż¤ķĆéÕ║öÕĄīÕģźÕ╝Åń│╗ń╗¤ńÜäńē╣ńé╣’╝īµ╗ĪĶČ│ń│╗ń╗¤Õ»╣õ║Äń©│Õ«ÜµĆ¦ÕÆīµĆ¦ĶāĮńÜäĶ”üµ▒éŃĆéµ£¼µ¢ćķśÉĶ┐░õ║åÕĄīÕģźÕ╝ÅJav
ķćŹĶ”üµĆ¦’╝ÜÕ×āÕ£ŠÕø×µöȵś»JavaÕ×āÕ£ŠÕø×µöČÕÖ©ńÜäµĀĖÕ┐āÕŖ¤ĶāĮ’╝īÕ»╣µĆ¦ĶāĮÕÆīÕåģÕŁśń«ĪńÉåĶć│Õģ│ķćŹĶ”üŃĆéÕćåńĪ«ńÉåĶ¦ŻÕ×āÕ£ŠÕø×µöČńÜäÕĤńÉåÕÆīµ£║ÕłČ’╝īõ╗źÕÅŖĶāĮÕż¤õ╝śÕī¢ÕÆīĶ░āõ╝śÕ×āÕ£ŠÕø×µöČĶ┐ćń©ŗńÜäĶāĮÕŖø’╝īµś»õĖĆõĖ¬JavaÕ╝ĆÕÅæĶĆģÕ┐ģÕżćńÜäÕ¤║µ£¼µŖĆĶāĮŃĆé ķØóĶ»ĢõĖŁÕÅ»ĶāĮõ╝ÜķŚ«Õł░ńÜäÕ×āÕ£ŠÕø×µöČ...
ńĮæõĖŖµöČķøåµĢ┤ńÉåńÜäõĖżń»ćÕģ│õ║ÄjavalÕ×āÕ£ŠÕø×µöȵ£║ÕłČńÜäõĖĆõ║øµ¢ćµĪŻŃĆé
µĘ▒ÕģźńÉåĶ¦ŻJVMÕ×āÕ£ŠµöČķøåń«Śµ│ĢõĖÄÕ×āÕ£ŠµöČķøåÕÖ©
õĖĆ’╝ī Õ×āÕ£ŠÕø×µöȵ£║ÕłČ Õ£©ń│╗ń╗¤Ķ┐ÉĶĪīĶ┐ćń©ŗõĖŁõ╝Üõ║¦ńö¤õĖĆõ║øµŚĀńö©ńÜäÕ»╣Ķ▒Ī,Ķ┐Öõ║øÕ»╣Ķ▒ĪõĖĆńø┤ÕŹĀńö©ÕåģÕŁś,õĖŹµĖģńÉåĶ┐Öõ║øµŚĀńö©ńÜäÕ»╣Ķ▒ĪÕÅ»ĶāĮõ╝ÜÕ»╝Ķć┤ÕåģÕŁśĶĆŚÕ░Į,µēƵ£ēÕ×āÕ£ŠÕø×µöȵ£║ÕłČńÜ䵜»ÕåģÕŁś. Õ×āÕ£ŠµöČķøåńÜäÕĤńÉåÕÆīµ”éÕ┐Ą Õ»╣õ║ÄÕ»╣Ķ▒ĪÕ«×õŠŗµöČķøå.õĖ╗Ķ”üµ£ēõĖżń¦ŹÕ¤║µ£¼ń«Śµ│Ģ,...
JVMńÜäÕåģÕ«╣Õłåõ║½’╝īÕīģÕɽJVMńÜäõ╝śÕī¢ńø«µĀćŃĆüõ╝śÕī¢ÕÄ¤ÕłÖŃĆüJVMń╗䵳ÉŃĆüÕåģÕŁśÕī║Õ¤¤ÕłÆÕłåŃĆüÕ×āÕ£ŠÕø×µöČń«Śµ│ĢŃĆüÕ×āÕ£ŠÕø×µöČÕÖ©ŃĆüFullGCĶ¦”ÕÅæµŚČµ£║ŃĆüÕ»╣Ķ▒ĪÕĖāÕ▒ĆŃĆüÕģāń®║ķŚ┤ÕŁśÕé©ŃĆüGCĶ░āõ╝ś
GCńÜäÕēŹõĖ¢õĖÄõ╗Ŗńö¤ õ╗Ćõ╣łµś»GC õĖĆŃĆüMark-Compact µĀćĶ«░ÕÄŗń╝®ń«Śµ│Ģ õ║īŃĆü Generational Õłåõ╗Żń«Śµ│Ģ õĖēŃĆüFinalization QueueÕÆīFreachable Queue µēśń«ĪĶĄäµ║É and ķØ×µēśń«ĪĶĄäµ║É’╝Ü .NETńÜäGCµ£║ÕłČµ£ēĶ┐ÖµĀĘõĖżõĖ¬ķŚ«ķóś. GC 10õĖ¬µ│©µäÅõ║ŗķĪ╣’╝Ü
Õģ│õ║ÄJavaÕ×āÕ£ŠÕø×µöȵ£║ÕłČ Õ×āÕ£ŠµöČķøåńÜäń«Śµ│ĢÕłåµ×É Õ×āÕ£ŠÕø×µöČńÜäÕćĀõĖ¬ńē╣ńé╣
JAVAÕĀåńÜäń«ĪńÉå-Õ×āÕ£ŠÕø×µöȵ£║ÕłČńÜäń«Śµ│ĢÕłåµ×ÉõĖÄńĀöń®Č
CĶ»ŁĶ©Ć’╝īÕ¤║õ║Ämark-sweepń«Śµ│ĢÕ«×ńÄ░ńÜäÕ×āÕ£ŠÕø×µöȵ£║ÕłČ
JavaÕ×āÕ£ŠÕø×µöȵ£║ÕłČµĆ╗ń╗ō
µłæõ╗¼ń¤źķüōńø«ÕēŹńÜäJVMńÜäÕ×āÕ£ŠÕø×µöČÕÖ©ķāĮµś»ķććńö©┬ĀÕÅ»ĶŠŠµĆ¦Õłåµ×Éń«Śµ│Ģ┬ĀµĀćĶ«░ÕŁśµ┤╗Õ»╣Ķ▒Ī’╝īĶ»źń«Śµ│Ģķ”¢Õģłķ£ĆĶ”üµēŠÕł░GC Roots’╝īńäČÕÉÄķĆÜĶ┐ćĶ┐Öõ║øµĀ╣ĶŖéńé╣ÕÉæõĖŗµÉ£ń┤ó’╝īĶāĮµÉ£ń┤óÕł░ńÜäÕ░▒µĀćĶ«░õĖ║ÕŁśµ┤╗Õ»╣Ķ▒Ī’╝īµ£¬Ķó½µĀćĶ«░ńÜäµ£ĆÕÉÄÕ░▒õ╝ÜĶó½Õ×āÕ£ŠÕø×µöČÕÖ©Õø×µöČŃĆéķéŻõĮĀµś»ÕÉ”µā│...
JVM’╝Üń╗䵳Éķā©ÕłåŃĆüÕ×āÕ£ŠÕø×µöȵ£║ÕłČÕÆīń«Śµ│ĢŃĆüÕ»╣ÕåģÕŁśńÜäń«ĪńÉåÕŖ×µ│ĢŃĆé
Javaµś»õĖĆń¦Źķ½śµĆ¦ĶāĮŃĆüĶĘ©Õ╣│ÕÅ░ńÜäķØóÕÉæ...Ķć¬ÕŖ©ÕåģÕŁśń«ĪńÉå’╝łÕ×āÕ£ŠÕø×µöČ’╝ē’╝Ü JavaÕģʵ£ēĶć¬ÕŖ©ÕåģÕŁśń«ĪńÉåµ£║ÕłČ’╝īķĆÜĶ┐ćÕ×āÕ£ŠÕø×µöČÕÖ©Ķć¬ÕŖ©Õø×µöČõĖŹÕåŹõĮ┐ńö©ńÜäÕ»╣Ķ▒Ī’╝īõĮ┐ÕŠŚÕ╝ĆÕÅæĶĆģõĖŹķ£ĆĶ”üµēŗÕŖ©ń«ĪńÉåÕåģÕŁś’╝īÕćÅĶĮ╗õ║åń©ŗÕ║ÅÕæśńÜäĶ┤¤µŗģ’╝īÕÉīµŚČõ╣¤ÕćÅÕ░æõ║åÕåģÕŁśµ│äµ╝ÅńÜäķŻÄķÖ®ŃĆé
JVMńÜäÕ×āÕ£ŠÕø×µöȵ£║ÕłČĶ»”Ķ¦ŻÕÆīĶ░āõ╝ś,gcÕŹ│Õ×āÕ£ŠµöČķøåµ£║ÕłČµś»µīćjvmńö©õ║ÄķćŖµöŠķéŻõ║øõĖŹÕåŹõĮ┐ńö©ńÜäÕ»╣Ķ▒ĪµēĆÕŹĀńö©ńÜäÕåģÕŁśŃĆéjavaĶ»ŁĶ©ĆÕ╣ČõĖŹĶ”üµ▒éjvmµ£ēgc’╝īõ╣¤µ▓Īµ£ēĶ¦äÕ«ÜgcÕ”éõĮĢÕĘźõĮ£ŃĆéõĖŹĶ┐ćÕĖĖńö©ńÜäjvmķāĮµ£ēgc’╝īĶĆīõĖöÕż¦ÕżÜµĢ░gcķāĮõĮ┐ńö©ń▒╗õ╝╝ńÜäń«Śµ│Ģń«ĪńÉåÕåģÕŁśÕÆī...
JavaÕåģÕŁśń╗ōµ×äõĖÄÕ×āÕ£ŠÕø×µöȵ£║ÕłČń«Śµ│ĢÕłåµ×É