努力成为linux kernel hacker的人李万鹏原创作品,为梦而战。转载请标明出处
http://blog.csdn.net/woshixingaaa/archive/2011/05/14/6420100.aspx
目录项对象(dentry object):
存放目录项(也就是文件的特定名称)与对应文件进行连接的有关信息。每个磁盘文件系统都以自己特有的方式将该类信息存在磁盘上。
VFS把每个目录看作由若干子目录和文件组成的一个普通的文件。然而,一个目录项被读入内存,VFS就把它转换成基于dentry结构的一个目录项对象。对于进程查找的路径名中的每个分量,内核都为其创建一个目录项对象;目录项对象将每个分量与其对应的索引节点相联系,例如,在查找路径名/tmp/test时,内核为根目录“/”创建一个目录项对象,为根目录下的tmp项创建一个第二级目录项对象,为/tmp目录下的test项创建一个第三级目录项对象。
请注意,目录项对象在磁盘上并没有对应的镜像,因此dentry结构中不包含指出该对象已经修改的字段。目录项对象在磁盘上并没有对应的镜像,因此在dentry结构中不包含指出该对象已被修改的字段。目录项对象存放在名为dentry_cache的slab分配器高速缓存中。因此,目录项对象的创建和删除是通过调用kmem_cache_alloc()和kmem_cache_free()实现的。
每个目录项对象可以处于一下四种状态之一:
空闲状态(free):
处于该状态的目录项对象不包括有效的信息,而且还没有被VFS使用。对应的内存区由slab分配器进行处理。
未使用状态(unused):
处于该状态的目录项对象当前还没有被内核使用。该对象的引用计数器d_count的值为0,但其d_inode字段仍然指向关联的索引节点对象。该目录项对象包含有效的信息,但是为了在必要时回收内存,它的内容可能被丢弃。
正在使用状态(in use):
处于该状态的目录项对象当前正在被内核使用。该对象的引用计数器d_count的值为正数,其d_inode字段指向关联的索引节点对象。该目录项对象包含有效的信息,并且不能被丢弃。
负状态(negative):
与目录项关联的索引节点不复存在,那是因为相应的磁盘索引节点已被删除,或者因为目录项对象是通过解析一个不存在文件的路径名创建的。目录项对象的d_inode字段被置为NULL,但该对象仍然被保存在目录项高速缓存中,以便后续对同一文件目录名的查找操作能够快速完成。术语“负状态”容易使人误解,因为根本不涉及任何负值。
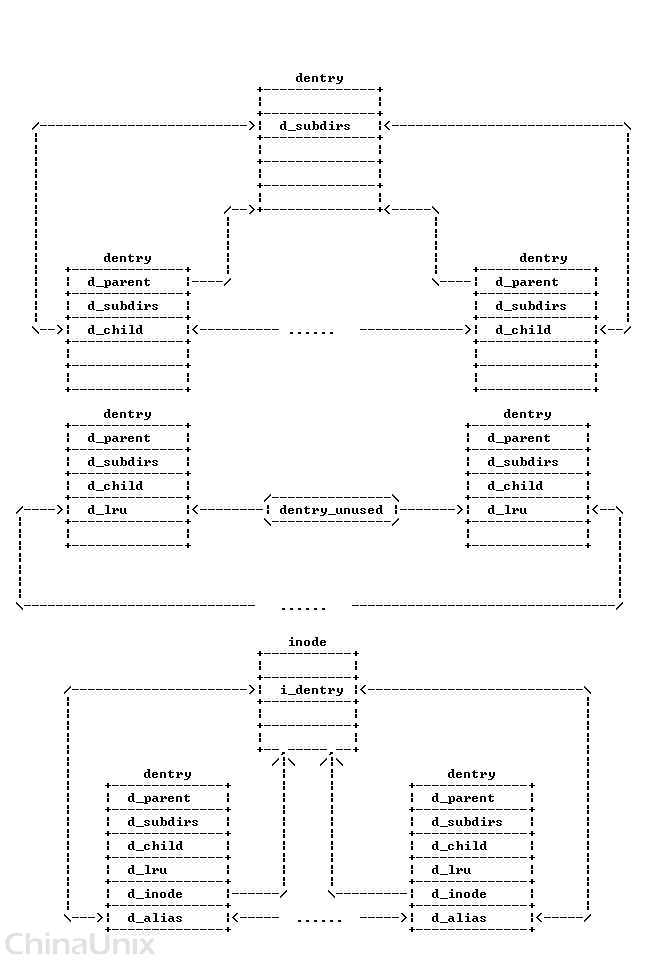
目录项高速缓存:
由于从磁盘读入一个目录项并构造相应的目录项对象需要花费大量时间,所以,在完成对目录项对象的操作后,可能后面还要使用它,因此仍在内存中保留它有重要的意义。
为了最大限度地提高处理这些目录项对象的效率,Linux使用目录项高速缓存,它由两种类型的数据结构组成:
1.一个处于正在使用,未使用或负状态的目录项对象的集合
2.一个散列表,从中能快速获取与给定的文件名和目录名对应的目录项对象。同样,如果访问的对象不再目录项高速缓存中,则散列函数返回一个空值。
目录项高速缓存的作用还相当于索引节点高速缓存的控制器(inode cache)的控制器。在内核内存中,并不丢弃与未用目录项相关的索引节点,这是由于目录项高速缓存仍在使用它们。因此,这些索引节点对象保存在RAM中,并且能够借助相应的目录项快速引用他们。
所有“未使用”目录项对象都存放在一个“最近最少使用(Least Recently used,LRU)”的双向链表中,该链表按照插入的时间排序。换句话说,最后释放的目录项对象放在链表的首部,所以最近最少使用的目录项对象总是靠近链表的尾部。一旦目录项高速缓存的空间开始变小,内核就从链表的尾部删除元素,使得最近最常用的对象得以保存。LRU链表的首元素和尾元素的地址存放在list_head类型的dentry_unused变量的next字段和prev字段中。目录项对象的d_lru字段包括指向链表中的相邻目录项的指针。
每个“正在使用”的目录项对象都被插入一个正在使用的双向链表中,该链表由相应索引节点对象的i_dentry字段所指向(由于每个索引节点可能与若干硬链接相关联,所以需要一个链表)。目录项对象的d_alias字段存放链表中相邻元素的地址。这两个字段的类型都是struct list_head。
当指向相应文件的最后一个硬链接被删除后,一个“正在使用”的目录项对象可能变成负状态。在这种情况下,该目录项对象被移到“未使用”目录项对象组成的LRU链表中。每当内核缩减目录项高速缓存时,“负状态”目录项对象就朝着LRU链表的尾部移动,这样一来,这些对象就逐渐被释放。
散列表是由dentry_hashtable数组实现的。数组中每个元素是一个指向链表的指针,这种链表就是把具有相同散列表值的目录项进行散列而形成的。
还有一个链表就是表示父子结构的链表。
文件对象(file object):
文件对象存放打开文件与进程之间进行交互的有关信息。这类信息仅当进程访问文件期间存在于内核内存中。文件对象是在文件被打开时创建的,由一个file结构组成。注意:文件对象在磁盘上没有对应的镜像,因此file结构中没有设置“脏”字段来表示文件是否已被修改。
存放在文件对象中的主要信息是文件指针,即文件中当前的位置,下一个操作将在该位置发生。由于几个进程可能同时访问同一个文件,因此文件指针必须存放在文件对象而不是索引节点对象中。
文件对象通过一个名为filp的slab高速缓存分配,filp描述符地址存放在filp_cachep变量中。由于分配的文件对象的数目是有限的,因此files_stat变量在其max_files字段中指定了可分配文件对象的最大数目。也就是系统可同时访问的最大文件数。
文件系统对象包含在由具体文件系统的超级块所确立的几个链表中。每个超级块对象把文件对象链表的头存放在s_files字段中;因此,属于不同文件系统的文件对象就包含在不同的链表中。链表中分别指向前一个元素和后一个元素的指针都存放在文件对象的f_list字段中。files_lock自旋锁保护超级块的s_files链表免受多处理器系统上的同时访问。
文件对象的f_count字段是一个引用计数器:它记录使用文件对象的进程数(记住,以CLONE_FILES标志创建的轻量级进程共享打开文件表,因此他们可以使用相同的文件对象)。当内核本身使用该文件对象时也要增加计数器的值——例如,把对象插入链表中或发出dup()系统调用时。
当VFS代表进程必须打开一个文件时,它调用get_empty_filp()函数来分配一个新的文件对象。该函数调用kmem_cache_alloc()从filp高速缓存中获得一个空闲的文件对象,然后初始化这个对象的字段。
每个文件系统都有其自己的文件操作集合,执行诸如读写文件这样的操作。当内核将一个索引节点从磁盘装入内存时,就会把指向这些文件操作的指针放在file_operations结构中,而该结构的地址存放在该索引节点对象的i_fop字段中。当进程打开这个文件时,VFS就用存放在索引节点中的这个地址初始化新文件对象的f_op字段,使得对文件操作的后续调用能够使用这些函数。如果需要,VFS随后也可以通过在f_op字段存放一个新值而修改文件操作的集合。
与进程相关的文件:

每个进程都有它自己的当前的工作目录和他自己的根目录。这仅仅是内核用来表示进程与文件系统相互作用所必须维护的数据中的两个例子。类型为fs_struct的整个数据结构就用于此目的,且每个进程的fs字段就指向进程的fs_struct结构。
现在再来看file_struct结构:
fd字段指向文件对象的指针数组,该数组的长度存放在max_fds字段中。通常,fd字段指向files_struct结构的fd_array字段,该字段包含32个文件对象的指针。如果进程打开文件的数目多于32个,内核就分配一个新的,更大的文件指针数组,并将其地址存放在fd字段中,内核同时也更新max_fds字段的值。
对于在fd数组中有元素的每个文件来说,数组的索引就是文件描述符(file descriptor)。通常,数组的第一个元素(索引为0)是进程的标准输入文件,数组的第二个元素(索引为1)是进程的标准输出文件,数组的第三个文件(索引为2)是进程的标准错误文件。
进程不能使用多于NR_OPEN_DEFAULT个文件描述符。内核也在进程描述符的signal->rlim[RLIMIT_NOFILE]结构上强制动态限制文件描述符的最大数;这个值通常为1024,但是如果进程具有超级用户特权,就可以增大这个值。
open_fds包含已打开文件的位图,max_fdset字段存放位图中的位数。由于fd_set数据结构有1024位,所以通常不需要扩大位图的大小。不过,如果确有必要的话,内核仍能动态增加位图的大小,这非常类似于文件对象的数组的情形。
当内核开始使用一个文件对象时,内核提供fget()函数以供调用。这个函数接受文件描述符fd作为参数,返回在current->files->fd[fd]中的地址,即对应的文件对象的地址,如果没有任何文件与fd对应,则返回NULL。在第一种情况下,fget()使文件对象引用计数器f_count的值增1。
当内核控制路径完成对文件对象的使用时,调用内核提供的fput()函数。该函数将文件对象的地址作为参数,并减少文件对象引用计数器f_count的值。另外,如果这个字段变为0,该函数就调用文件操作的release方法(如果已定义),减少索引节点对象的i_write_count字段的值(如果该文件是可写的),将文件对象从超级块链表中移走,释放文件对象给slab分配器,最后减少相关的文件系统描述符的目录项对象的引用计数值。
fget_light()和fput_light()函数是fget()和fput()的快速版本:内核要使用它们,前提是能够安全地假设当前进程已经拥有文件对象,即进程先前已经增加了文件对象引用计数器的值。例如,它们由接受一个文件描述符作为参考的系统调用服务例程使用,这是由于先前的open()系统调用已经增加了文件对象引用计数器的值。
总结一下:
1. super_block存在于两个链表中,一个是系统所有super_block的链表, 一个是对于特定的文件系统的super_block链表.
2. inode存在于两个双向链表中:
一个是inode所在文件系统的super block的 s_inodes 链表中
一个是根据inode的使用状态存在于以下三个链表中的某个链表中:
1. 未用的: inode_unused 链表
2. 正在使用的: inode_in_use 链表
3. 脏的: super block中的s_dirty 链表
3. dentry对象存在于三个双向链表中:
所有未用的目录项: dentry_unused 链表
正在使用的目录项: 对应inode的 i_dentry 链表
表示父子目录结构的链表
另外,还有一个重要的链表: inode_hashtable(这个暂不介绍).
4. 和进程相关的信息, 涉及到四个重要的数据结构:
file, fs_struct, files_struct 和 namespace
分享到:





相关推荐
虚拟文件系统(VFS) 虚拟文件系统(VFS)是由 Sun Microsystems 公司在定义网络文件系统(NFS)时创造的。它是一种用于网络环境的分布式文件系统,是允许和操作系统使用不同的文件系统实现的接口。 知识点: 1. ...
linux文件系统中的虚拟文件系统的数据结构,自己总结的,希望对大家有所帮助。
### Linux虚拟文件系统(VFS)的数据结构关系 Linux操作系统中的虚拟文件系统(VFS)是内核中的一个重要组成部分,它提供了统一的接口来处理不同类型的文件系统。VFS通过抽象出一套通用的数据结构来实现这一目标,...
VFS的主要组成部分包括:k结构、dentry结构、inode结构、super block结构等数据结构,这些数据结构组成了VFS与逻辑文件系统之间的接口,提供了VFS对逻辑文件系统的操作。 在Linux中,VFS是内核的一个子系统,其它子...
"VFS(虚拟文件系统)简介" 虚拟文件系统(VFS)是一种抽象的文件系统,它提供了一个通用的接口来访问不同的文件系统。VFS 作为一个中间层,位于操作系统的内核和文件系统之间,负责管理文件系统的元数据和文件的存储...
内容概要:本文介绍了Linux虚拟文件系统(Virtual File System,简称VFS)的原理、结构及操作流程,包括其主要对象如超级块、i节点、数据块、目录块和间接块的组成及其工作原理,并通过实验详述了如何实现一个简易的...
Linux虚拟文件系统的数据结构是操作系统中极为重要的一个组成部分。Linux操作系统支持多种不同的文件系统,为了能够兼容和管理这些文件系统,Linux内核中引入了虚拟文件系统(VFS)。VFS作为一个抽象层,对外提供...
Linux的虚拟文件系统(Virtual File System,简称VFS)是操作系统的核心组成部分,它为不同的文件系统提供了一个统一的接口,使得Linux可以支持多种文件系统,如EXT4、XFS、FAT32、NTFS等。VFS允许应用程序在不关心...
总的来说,虚拟文件系统 (VFS) 是 Linux 内核中的一项关键技术,它不仅为应用程序提供了统一的文件系统接口,还支持了多种文件系统的共存以及跨文件系统的文件操作。通过 VFS,Linux 实现了“一切皆文件”的哲学,并...
在C++环境下,我们可以创建一个简单的VFS实现,这通常涉及定义一些基本的数据结构,如文件描述符、文件节点和文件操作集。 在给定的文件中,`vfs.cpp`和`vfs.h`是实现虚拟文件系统的关键部分。`vfs.h`文件可能包含...
Linux文件系统可以分为三大块:上层文件系统的系统调用、虚拟文件系统VFS(Virtual Filesystem Switch)和挂载到VFS中的各实际文件系统,如ext2、jffs等。 1. VFS概述 VFS是一种软件机制,可以称为Linux的文件系统...
虚拟文件系统(Virtual File System,简称VFS)是一种在操作系统中用于实现不同文件系统兼容性的抽象层,它是Linux系统中的一项关键技术,为各种不同的文件系统提供统一的用户接口。Linux通过VFS能够在不同的文件...
虚拟文件系统(Virtual File System,VFS)是操作系统中的一个重要组成部分,它为应用程序提供了一个统一的接口来访问各种类型的文件存储设备,无论这些设备是硬盘、网络共享、内存中的文件系统还是其他形式。VFS的...
Linux内核分析与应用课件第8章(二)虚拟文件系统中的主要数据结构 在Linux内核中,虚拟文件系统(VFS)扮演着至关重要的角色,它提供了一个通用的文件系统接口来访问不同的文件系统。VFS的主要数据结构包括超级块...
Linux虚拟文件系统(VFS)是Linux操作系统中一个核心软件层,负责处理与标准文件系统相关的所有系统调用。它所隐含的思想是把表示很多不同种类文件系统的共同信息放入内核。对所调用的函数,内核都能把它们替换成...
为了支持这种通用模型,Linux内核设计了一套抽象的文件系统接口,即虚拟文件系统(Virtual File System, VFS)。 VFS提供了统一的接口来访问不同的文件系统,使得应用程序无需关心底层文件系统具体的实现细节。这种...
VFS的inode同样是一个抽象的数据结构,它可以映射到不同物理文件系统中的具体inode结构。 2. VFS对物理文件系统的管理: - VFS通过超级块和索引节点来管理物理文件系统。内存中的VFS超级块是物理文件系统超级块的...
在现代操作系统中,虚拟文件系统(VFS,Virtual File System)是操作系统内核中的一个关键组件,它为上层应用提供了一致的文件访问接口,同时允许底层支持多种不同的文件系统类型。本文将对VFS的基本概念、重要数据...