信息论中的熵借鉴与物理学里的概念,物理学里熵来自于热力学第二定律,描述了功与热的转化,公式上是温度(不是温度变化值)除热量变化值所得的商,标志热量转化为功的程度,物质微观热运动时,混乱程度的标志。看得出来在封闭的系统中是一个熵是增加的。
熵是混乱和无序的度量 。熵值越大,混乱无序的程度越大。生命是高度的有序,智慧是高度的有序,局部的有序是可能的,但必须以其他地方的更大无序为代价,生命和智慧算作负熵。更多详细的内容,百度百科 上说的挺不错的。
信息论首先定义信息就是消除不确定性的东西,一系列的概念及所能表现的性质相当完备和一致,不得不佩服这些开创者的洞察力和跨域的综合能力。
任意随机事件的自信息量定义为该事件发生概率的对数的负值。设I(xi)=-log p(xi) 事件xi 的概率为p(xi),对于离散符号集合,定义熵为
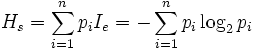
首先,熵值是对应于一个系统或符号集合而言,并不是求对一个符号的熵,当所有的符号出现概率相同的时候,对应的熵值最大,因为我们对下一个将出现什么符号的不确定程度越大。
对于离散随机变量x和任意函数f, 我们有H(f(x))<=H(x),即对原始信号的任何处理都不能增加熵(也就是信息量)。另外,任意改变事件的标记,不会影响这组符号的熵,因为熵只与每个符号的出现概率有关,而与符号本身无关。
我们记P(f(x))为f(x)出现的概率,那么H(f(x))= E[log1/p(f(x))], H(x) = E[log1/p(x)];
其中p(f(x))>= p(x),f(x)的离散值数目<=x,所以H(f(x)) <= H(x).
而对于连续的随机变量的情况,上述不一定成立,因为f(x)后的积分值很可能会发生变化,所以最后的熵值往往是不同的,因为f(x)与x是一一对应的,如果因此而说f(x)和x具有不同的内在无序性是没有意义的,除非加入某些随机性后,比如函数映射时随机改变映射之间的位置。
实际应用中,相对熵和熵之间的差值对我们来说更加重要。
相对熵,用经常使用的比值来定义
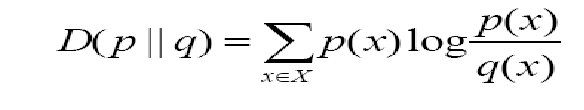 ,还有一个形式是E q(x)log q(x)/p(x).
,还有一个形式是E q(x)log q(x)/p(x).
那么交叉熵就是H(X, q) = H(X) + D(p||q) = - E p(x) log q(x), 其中X~p(x), q(X)用于近似p(x)的概率分布,它的概念用来衡量估值模型与真实概率分布间差异情况。
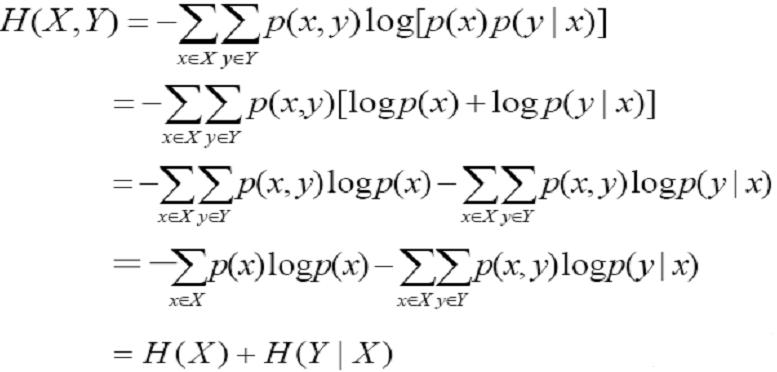
这时候互传信息量为 I(X;Y) = H(X) - H(X|Y),展开式子又可得下式。
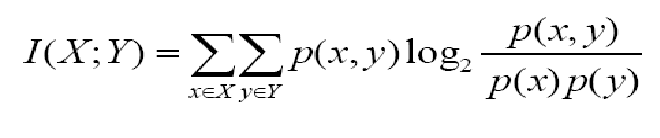
可以认为它就是联合概率分布与各自概率乘积之间的相对熵,衡量的是x,y的分布于统计独立的差别程度。
注意上面的交叉熵和互传信息量都不服从全部度量性质,联合熵总是比单独的熵要大,显然不确定性越大。
-----------------------
后记一些关于熵的内容(Added at 2009-09-28)
热力学第二定律是一个经验公式,当前还没有观察到违反它的现象发生。熵的概念最早来自描述能量在空间中分布的均匀程度,能量分布得越均匀,熵就越大,当然其过程来自于对热力学过程的研究。
虽然热力学第一定律描述能量守恒,但第二定律表明内能不如机械能,电能好用,它只能部分用于做功,表明能量的品质是在降级,这就是能量的耗散与退化。熵就被引入来描述能量耗散过程。
比较不均匀的状态是比较有序的状态,从微观的角度来讲,热传递过程也是从比较有序的状态变成比较无序的状态,例如,温度高的物体说明其分子运动比较剧烈,这是一种秩序,达到热平衡后两者温度一致,热运动没有区别了,变成无序。所以说熵是表征系统无序程度的物理量。
熵作为一个数学物理量,当然有正负之分,只不过在孤立系统中其总是大于等于0,特别是物理上。例如生命就可以说是靠负熵维持的。顺带附上一片有趣的日志,别人理解描述的深刻的多。
http://buguang.spaces.live.com/blog/cns!846EA6D78FBE7773!1330.entry
分享到:





相关推荐
信息论与编码--熵值的计算------------------C++实现的啊
行业分类-设备装置-信息熵保持解码方法与装置.zip
打包Matlab博士论文关于垃圾邮件分类-基于信息熵和决策分类技术的邮件识别研究.pdf 改进的贝叶斯分类对垃圾邮件识别探讨.pdf 基于NP的垃圾邮件分析系统的设计与实现.pdf ...
读书笔记 -读懂任正非华为管理哲学的核心框架《熵减:华为活力之源》.pdf
论文研究-熵-信息理论与系统工程方法论的有效性分析.pdf,
论文研究-基于集成预测的均值-方差-熵的模糊投资组合选择.pdf, 通过基于集成预测的方法构建模糊投资组合, 代表性地选择了遗传神经网络模型、 多因素SVM回归模型和ARIMA...
使用MATLAB实现信息熵的计算
针对AdaBoost算法不能有效提高RVM分类性能的问题,提出一种基于信息熵的RVM与AdaBoost组合分类器。依据RVM输出的后验概率来定义样本的信息熵,信息熵越高的样本越容易错分。提出使用自适应信息熵阈值对数据进行筛选...
基于信息熵-动态可增减SOM图的机器人路径规划,阮晓钢,高静欣,针对传统方法建立环境地图需要大量环境信息从而造成的存储搜索困难的问题,本文基于自组织特征映射图SOM提出了一种动态可增减自组
用matlab绘制二进制信息熵,word内附原代码,运行截图等
详解交叉熵损失函数及Softmax激活函数Sigmoid激活函数在深度学习二分类/多分类任务中的应用
在提取问题特征时,通过把信息熵算法和医院本体概念模型结合在一起,进行问题的特征模型计算,在此基础上使用支持向量机方法进行中文问题分类。在城域医院问答系统的中文问题集上进行实验,证明了该方法的有效性,大...
这是一个样本的实验,现将振动信号进行CEEMD分解,得到imf分量,在求imf分量的相关系数啦筛选分量,并求一个样本的信息熵特征,构造一个特征向量矩阵,然后自己选择类器进行分类。
最大信息熵原理已被成功地应用于各种自然语言处理领域,如机器翻译、语音识别和文本自动分类等,提出了将其应用于互联网异常流量的分类。由于最大信息熵模型利用二值特征函数来表达和处理符号特征,而KDD99数据集中...
基于MATLAB的图像信息熵计算,内含原始图像和结果图像
为了提高传统CURE(clustering using representatives)聚类算法的质量,引入信息熵对其进行改进。该算法使用K-means算法对样本数据集进行预聚类;采用基于信息熵的相似性度量,利用簇中元素提供的信息度量不同簇...
尽管热力学第二定律表明我们的宇宙是由趋向无序的趋势驱动的,但生物似乎... 因此,我们证明生命蓝图的形成可能最初是通过信息熵通过具有更高信息熵含量的材料的去复合作用而衍生出来的,从而导致原始遗传分子的形成。
使用C++读取图像中的信息熵以便于更好的理解
输入彩色图像,转化为灰度图像后,进行图像信息熵(一维和二维)、互信息等计算和对比分析。