
这个练习会使用SAP HANA Express Edition的文本语义分析引擎对JSON格式的documents进行语义分析。
首先创建一个column table,对其index开启fuzzy text search(模糊搜索)功能。
上述描述的操作可以用下面的SQL语句来完成:
create column table food_analysis
(
name nvarchar(64),
description text FAST PREPROCESS ON FUZZY SEARCH INDEX ON
);
其中description字段开启了模糊搜索功能。
将存储于名为doc_store的document store collection里的json key-value键值对拷贝到刚刚创建的数据库表里:
insert into food_analysis with doc_store as (select "name", "description" from food_collection) select doc_store."name" as name, doc_store."description" as description from doc_store;
执行上述的sql语句,确保数据全部拷贝到数据库表food_analysis中:
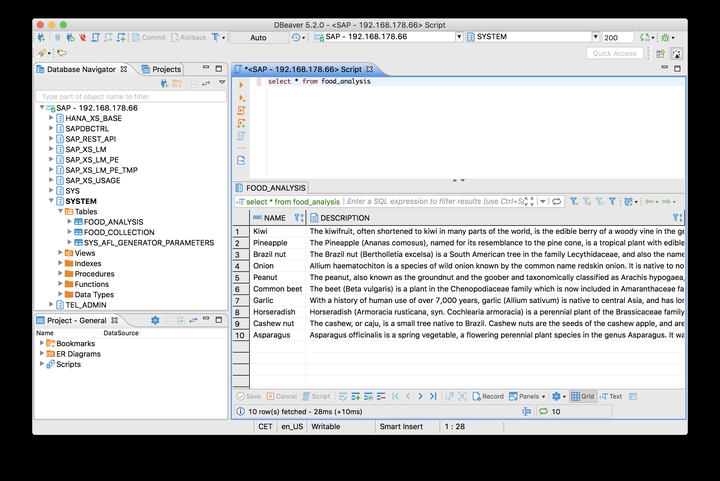
使用下列的sql语句对description字段进行模糊搜索:
select name, score() as similarity, TO_VARCHAR(description) from food_analysis where contains(description, 'nuts', fuzzy(0.5,'textsearch=compare')) order by similarity desc
执行结果:
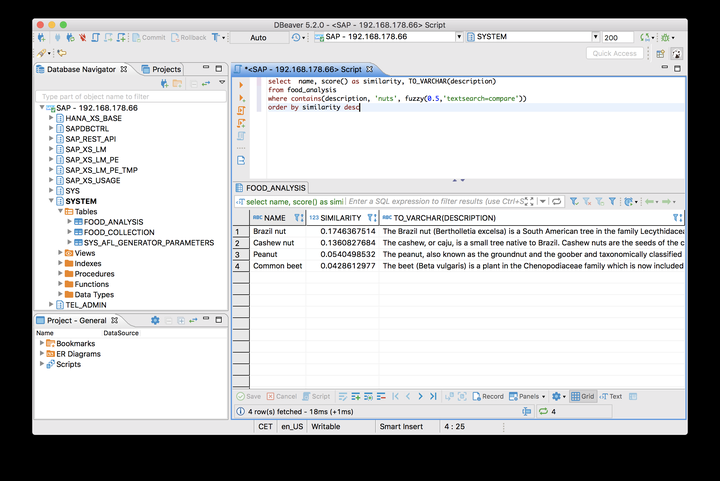
HANA Express Edition里的linguistic 文本分析步骤也比较简单。
首先还是创建一个数据库表:
create column table food_sentiment ( name nvarchar(64) primary key, description nvarchar(2048) );
将document store里的json数据拷贝到数据库表里:
insert into food_sentiment with doc_store as (select "name", "description" from food_collection) select doc_store."name" as name, doc_store."description" as description from doc_store;
针对description字段创建一个新的index:
CREATE FULLTEXT INDEX FOOD_SENTIMENT_INDEX ON "FOOD_SENTIMENT" ("DESCRIPTION") CONFIGURATION 'GRAMMATICAL_ROLE_ANALYSIS' LANGUAGE DETECTION ('EN') SEARCH ONLY OFF FAST PREPROCESS OFF TEXT MINING OFF TOKEN SEPARATORS '' TEXT ANALYSIS ON;
上述SQL语句会自动创建一个名为$TA_FOOD_SENTIMENT_INDEX的文本分析表:
该表里的内容:
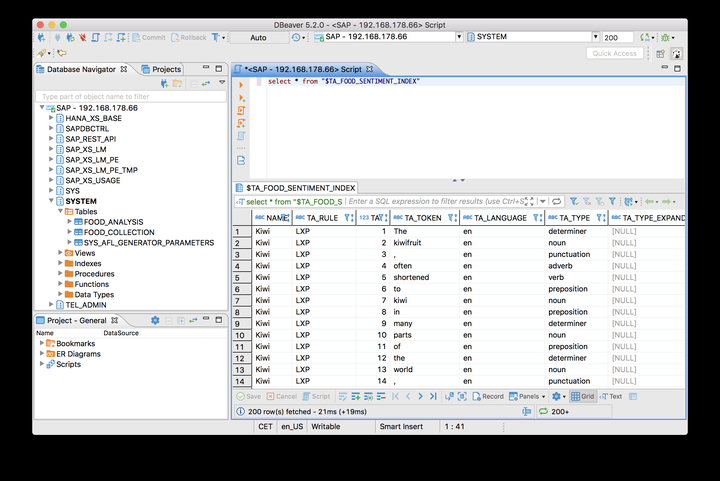
由此可以发现,之前我们导入到数据库表里的英文句子,被HANA text engine拆解成单词,并且每个单词的词性也自动被HANA解析出来了。



相关推荐
SAP HANA Developer Quick Start Guide For SAP HANA XS Classic Model SAP HANA Platform 2.0 SPS 00 Document Version: 1.0 – 2016-11-30 from: ...
SAP HANA SR(System Replication)配置手册、 SAP HANA数据库HA配置、 SAP HANA 管理维护、 官方手册,详细讲解SAP HANA SR的配置。
本书详细讲述SAPHANA平台的各种技术以及在SAPHANA平台上的软件开发过程。主要内容包括:SAPHANA的各个特性;SAPHANAStudio;属性视图;分析视图;图形化计算视图;用SQLScript创建计算视图;SAPHANA系统的授权机制;...
SAP HANA运维工具 自动化脚本 备份工具 SAP HANA运维工具 自动化脚本 备份工具
java连接saphana的jdbc驱动,驱动类:com.sap.db.jdbc.Driver,连接URL:jdbc:sap://${ip}:${port}/${example}?reconnect=true
HXEDownloadManager_win.EXE WINDOWS版本 sap HANA express 下载工具
sap hana studio SAP HANA 数据库连接工具 及安装方式
SAP HANA 数据库 2.8.22 含 ODBC
SAP Note 1969700包含有用的SQL语句的集合,用于监视和分析SAP HANA数据库。文件HANA_Security_MiniChecks.txt中包含的语句执行所有 本文档中列出的基于SQL的检查。 针对数据库用户,角色和特权的建议[第7页] 有关...
SAP的hana操作手册用于 内容比较繁琐请大家仔细查看内容
SAP HANA Training Materials SAP HANA Training Materials SAP HANA Training Materials
SAP HANA SELECT语法(带参数) SAP HANA SELECT语法(带参数)
SAP HANA_STUDIO 安装包,有需要的朋友可以下载
本文档为用户提供了SAP HANA Client和Studio的安装步骤
该详细介绍了关于SAP HANA 数据库内存使用的分析,可直接通过SQL 语句进行分析,适合SAP 技术顾问或 Basis相关人员,
SAP HANA 中调试存储过程 SAP HANA 中调试存储过程 SAP HANA 中调试存储过程
SAP HANA Developer Guide For SAP HANA Web Workbench PUBLIC SAP HANA Platform 2.0 SPS 03 Document Version: 1.1 – 2018-10-31 from: ...
《SAP HANA 故障处理与性能分析指南》 使用 SAP HANA,您可以以令人难以置信的速度分析数据,例如,每个核心每秒扫描 10 亿行,每秒连接 1000 万行。然而,这样的结果只有在系统受到监控并且性能问题保持在最低限度...
SAP HANA studio window版本2.4.126