
首先本地将kafka的docker容器镜像下载到本地并运行:
docker search kafka
docker pull spotify/kafka
docker run --name kafka3 spotify/kafka
docker ps命令,查看tcp端口号:

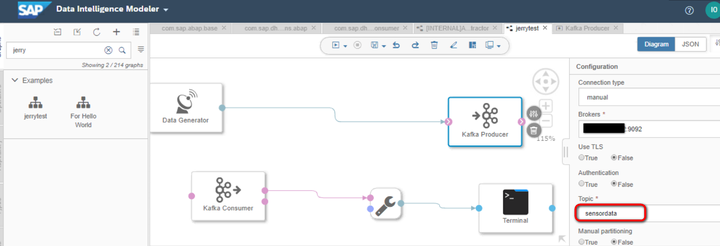
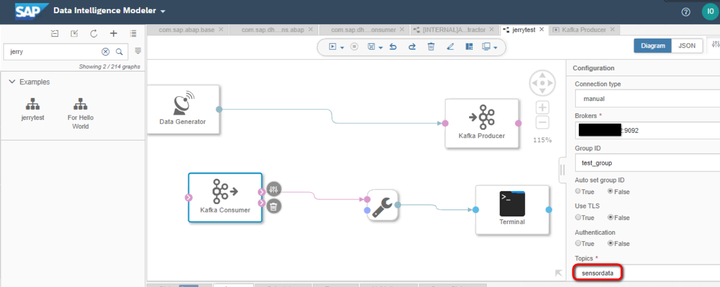
新建一个graph,使用典型的生产者-消费者模型:将Data Generator生成的数据交给kafka Producer operator;
而Kafka Consumer从kafka producer里读取出data Generator生成的数据,通过ToString converter,输出到Terminal Operator上。

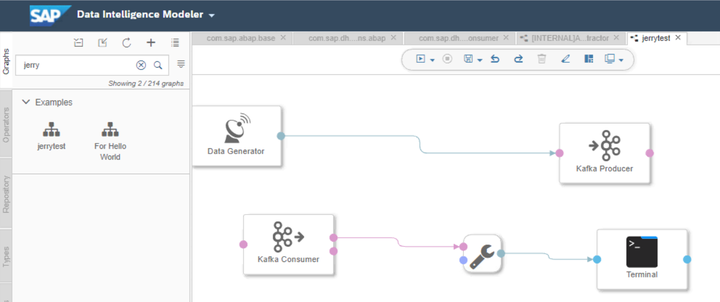
kafka producer和consumer使用的broker和topic必须一致:
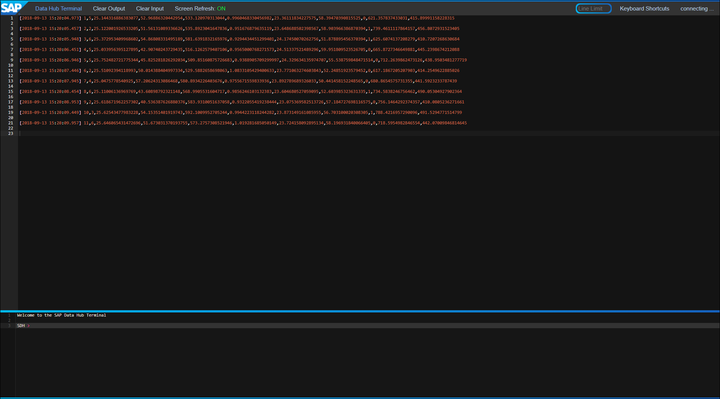
运行graph,可以看到
要获取更多Jerry的原创文章,请关注公众号"汪子熙":



相关推荐
Kafka Producer机制优化-提高发送消息可靠性
主要介绍了Springboot集成Kafka实现producer和consumer的示例代码,详细的介绍了什么是Kafka和安装Kafka以及在springboot项目中集成kafka收发message,感兴趣的小伙伴们可以参考一下
kettle kafka 生产者插件,在plugins 下新建steps文件夹,把zip文件解压放到里面。
带有Rest URL的Kafka Producer和Consumer API的Spring Boot应用程序 生产者:将数据或消息发送到kafka服务器的应用程序 消息:一小段数据,即kafka的字节数组 使用者:数据的接收者,即从kafka服务器读取数据 Kafka...
kafka集群搭建,开启sasl认证,并通过Python调用Producer和Consumer
第12单元 Kafka producer拦截器与Kafka Streams1
Simple application demonstrate kafka java springboot
kettle kafka 消费者插件,在plugins 下新建steps文件夹,把zip文件解压放到里面。
kafka_hdfs_consumer实现
kafka_client_producer_consumer
这是使用java操作kafka consumer api的一个demo,欢迎下载交流,博客地址:https://blog.csdn.net/qq_26803795
Go-consumergroup:采用golang编写的kafka consumer库
kettle7.1版本整合kafka,kafka插件包含生产者、消费者。直接在kettle安装目录plugins下创建steps目录,并解压下载文件到kettle/plugins/steps目录。具体可查看我博文。
使用场景:生产环境海量数据,用kafka-console-consumer 消费kafka某时间段消息用于分析问题,生产环境海量数据,用kafka-console-consumer.sh只能消费全量,文件巨大,无法grep。 代码来源于博主:BillowX_ ,感谢...
3、Druid的load data 示例(实时kafka数据和离线-本地或hdfs数据) 网页地址:https://blog.csdn.net/chenwewi520feng/article/details/130801752 本文介绍了Druid摄取离线与实时数据的过程,离线数据包括本地文件和...
jmeter连接kafka需要的连接器,可用于将静态测试数据通过jemter模拟高并发数据流发送到kafka中,可作为Kafka的生产者。
Kafka 目前支持SSL、SASL/Kerberos、SASL/PLAIN三种认证机制 ,我拿第三种进行了 配置 。你可以直接下载 运行并测试
kettle kafka 消息者生产插件,用于集成到kettle,生产Kafka消息。亲测试可用。
研究了一段时间后,根据网上的例子,做大量的削减及根据需要做出的最简化使用实例,并且加入了获取kafka的server端的状态信息,根据状态信息配置启动时读写位置