
еҜјиҜ»пјҡеҰӮжғізӣҙжҺҘиҺ·зҹҘй…ҚзҪ®agentзҡ„ж–№жі•пјҢиҜ·йҳ…иҜ»Setting up an agentе°ҸиҠӮгҖӮ
В
Overview
жҰӮиҝ°
Apache FlumeжҳҜдёҖдёӘй«ҳеҸҜйқ гҖҒй«ҳеҸҜз”Ёзҡ„еҲҶеёғејҸзҡ„жө·йҮҸж—Ҙеҝ—收йӣҶгҖҒиҒҡеҗҲгҖҒдј иҫ“зі»з»ҹгҖӮе®ғеҸҜд»Ҙд»ҺдёҚеҗҢзҡ„ж—Ҙеҝ—жәҗйҮҮйӣҶж•°жҚ®е№¶йӣҶдёӯеӯҳеӮЁгҖӮ
В
Flumeд№ҹз®—жҳҜHadoopз”ҹжҖҒзі»з»ҹзҡ„дёҖйғЁеҲҶпјҢжәҗдәҺClouderaпјҢзӣ®еүҚжҳҜApacheеҹәйҮ‘дјҡзҡ„йЎ¶зә§йЎ№зӣ®д№ӢдёҖгҖӮFlumeжңүдёӨжқЎдә§е“ҒзәҝпјҢ0.9.xзүҲжң¬е’Ң1.xзүҲжң¬гҖӮжң¬ж–Үдё»иҰҒд»Ӣз»ҚFlume 1.3.0пјҢеҚі"NG"дә§е“ҒзәҝдёҠзҡ„жңҖж–°зЁіе®ҡзүҲгҖӮ(BTWпјҢFlumeжҳҜApache 2.0 В License)
В
Resource
иө„жәҗ
Architecutre
жһ¶жһ„
В
ж•°жҚ®жөҒжЁЎеһӢ
Flumeд»ҘagentдёәжңҖе°Ҹзҡ„зӢ¬з«ӢиҝҗиЎҢеҚ•дҪҚгҖӮдёҖдёӘagentе°ұжҳҜдёҖдёӘJVMгҖӮеҚ•agentз”ұSourceгҖҒSinkе’ҢChannelдёүеӨ§з»„件жһ„жҲҗпјҢеҰӮдёӢеӣҫ(еӣҫзүҮж‘ҳиҮӘFlumeе®ҳж–№зҪ‘з«ҷ)пјҡ
В

Flumeзҡ„ж•°жҚ®жөҒз”ұдәӢ件(Event)иҙҜз©ҝе§Ӣз»ҲгҖӮдәӢ件жҳҜFlumeзҡ„еҹәжң¬ж•°жҚ®еҚ•дҪҚпјҢе®ғжҗәеёҰж—Ҙеҝ—ж•°жҚ®(еӯ—иҠӮж•°з»„еҪўејҸ)并且жҗәеёҰжңүеӨҙдҝЎжҒҜпјҢиҝҷдәӣEventз”ұAgentеӨ–йғЁзҡ„SourceпјҢжҜ”еҰӮдёҠеӣҫдёӯзҡ„Web Serverз”ҹжҲҗгҖӮеҪ“SourceжҚ•иҺ·дәӢ件еҗҺдјҡиҝӣиЎҢзү№е®ҡзҡ„ж јејҸеҢ–пјҢ然еҗҺSourceдјҡжҠҠдәӢ件жҺЁе…Ҙ(еҚ•дёӘжҲ–еӨҡдёӘ)ChannelдёӯгҖӮдҪ еҸҜд»ҘжҠҠChannelзңӢдҪңжҳҜдёҖдёӘзј“еҶІеҢәпјҢе®ғе°ҶдҝқеӯҳдәӢ件зӣҙеҲ°SinkеӨ„зҗҶе®ҢиҜҘдәӢ件гҖӮSinkиҙҹиҙЈжҢҒд№…еҢ–ж—Ҙеҝ—жҲ–иҖ…жҠҠдәӢ件жҺЁеҗ‘еҸҰдёҖдёӘSourceгҖӮ
В
еҫҲзӣҙзҷҪзҡ„и®ҫи®ЎпјҢе…¶дёӯеҖјеҫ—жіЁж„Ҹзҡ„жҳҜпјҢFlumeжҸҗдҫӣдәҶеӨ§йҮҸеҶ…зҪ®зҡ„SourceгҖҒChannelе’ҢSinkзұ»еһӢгҖӮдёҚеҗҢзұ»еһӢзҡ„Source,Channelе’ҢSinkеҸҜд»ҘиҮӘз”ұз»„еҗҲгҖӮз»„еҗҲж–№ејҸеҹәдәҺз”ЁжҲ·и®ҫзҪ®зҡ„й…ҚзҪ®ж–Ү件пјҢйқһеёёзҒөжҙ»гҖӮжҜ”еҰӮпјҡChannelеҸҜд»ҘжҠҠдәӢ件жҡӮеӯҳеңЁеҶ…еӯҳйҮҢпјҢд№ҹеҸҜд»ҘжҢҒд№…еҢ–еҲ°жң¬ең°зЎ¬зӣҳдёҠгҖӮSinkеҸҜд»ҘжҠҠж—Ҙеҝ—еҶҷе…ҘHDFS, HBaseпјҢз”ҡиҮіжҳҜеҸҰеӨ–дёҖдёӘSourceзӯүзӯүгҖӮ
В
еҰӮжһңдҪ д»ҘдёәFlumeе°ұиҝҷдәӣиғҪиҖҗйӮЈе°ұеӨ§й”ҷзү№й”ҷдәҶгҖӮFlumeж”ҜжҢҒз”ЁжҲ·е»әз«ӢеӨҡзә§жөҒпјҢд№ҹе°ұжҳҜиҜҙпјҢеӨҡдёӘagentеҸҜд»ҘеҚҸеҗҢе·ҘдҪңпјҢ并且ж”ҜжҢҒFan-inгҖҒFan-outгҖҒContextual RoutingгҖҒBackup RoutesгҖӮ
В
й«ҳеҸҜйқ жҖ§
дҪңдёәз”ҹдә§зҺҜеўғиҝҗиЎҢзҡ„иҪҜ件пјҢй«ҳеҸҜйқ жҖ§жҳҜеҝ…йЎ»зҡ„гҖӮ
д»ҺеҚ•agentжқҘзңӢпјҢFlumeдҪҝз”ЁеҹәдәҺдәӢеҠЎзҡ„ж•°жҚ®дј йҖ’ж–№ејҸжқҘдҝқиҜҒдәӢд»¶дј йҖ’зҡ„еҸҜйқ жҖ§гҖӮSourceе’ҢSinkиў«е°ҒиЈ…иҝӣдёҖдёӘдәӢеҠЎгҖӮдәӢ件被еӯҳж”ҫеңЁChannelдёӯзӣҙеҲ°иҜҘдәӢ件被еӨ„зҗҶпјҢChannelдёӯзҡ„дәӢ件жүҚдјҡ被移йҷӨгҖӮиҝҷжҳҜFlumeжҸҗдҫӣзҡ„зӮ№еҲ°зӮ№зҡ„еҸҜйқ жңәеҲ¶гҖӮ
В
д»ҺеӨҡзә§жөҒжқҘзңӢпјҢеүҚдёҖдёӘagentзҡ„sinkе’ҢеҗҺдёҖдёӘagentзҡ„sourceеҗҢж ·жңүе®ғ们зҡ„дәӢеҠЎжқҘдҝқйҡңж•°жҚ®зҡ„еҸҜйқ жҖ§гҖӮ
В
еҸҜжҒўеӨҚжҖ§
В иҝҳжҳҜйқ ChannelгҖӮжҺЁиҚҗдҪҝз”ЁFileChannelпјҢдәӢ件жҢҒд№…еҢ–еңЁжң¬ең°ж–Ү件系з»ҹйҮҢ(жҖ§иғҪиҫғе·®)гҖӮ
В
жҰӮеҝөеҲ°жӯӨдёәжӯўпјҢдёӢйқўејҖе§Ӣе®һжҲҳгҖӮ
В
В
Setting up an agent
AgentйңҖиҰҒзҹҘйҒ“е“Әдәӣ组件е°Ҷиў«еҗҜз”ЁпјҢ组件еҰӮдҪ•иҝһжҺҘжқҘжһ„жҲҗж•°жҚ®жөҒгҖӮз”ЁжҲ·еҸӘйңҖиҰҒз®ҖеҚ•ең°жҸҗдҫӣдёҖдёӘй…ҚзҪ®ж–Ү件жқҘе‘ҠиҜүagentиҜҘеҰӮдҪ•еҺ»еҒҡеҚіеҸҜгҖӮ
В
дҫӢеӯҗпјҡдәӢ件жәҗдәҺдёҖдёӘnetcat sourceпјҢдҪҝз”ЁеҶ…еӯҳChannelпјҢжңҖеҗҺдҪҝз”Ёlogger SinkжҠҠж—Ҙеҝ—иҫ“еҮәеҲ°жҺ§еҲ¶еҸ°дёҠгҖӮ(дҫӢеӯҗжәҗдәҺFlumeе®ҳж–№ж–ҮжЎЈпјҢиҜ·еҮҶеӨҮеҘҪLinuxзҺҜеўғ)
В
AgentжҳҜз”ЁдёҖдёӘеҗҚдёәflume-ngзҡ„и„ҡжң¬жқҘеҗҜеҠЁзҡ„пјҡ
Flume 1.3:
В
$ bin/flume-ng agent -n $agent_name -c conf -f $property_file_path
В
В
Flume 1.2е’Ңд№ӢеүҚзүҲжң¬:
В
$ bin/flume-ng node -c conf -f $property_file_path -n $agent_nameВ
В
$agent_name: В agentзҡ„еҗҚеӯ—пјҢйҡҸдҫҝз»ҷдёӘеҗҚеҗ§пјҢжіЁж„Ҹе’Ңpropertyж–Ү件йҮҢagentеҗҚдёҖиҮҙ
$property_file_path: й…ҚзҪ®ж–Ү件и·Ҝеҫ„гҖӮ
В
дёӢйқўз»ҷеҮәй…ҚзҪ®ж–Ү件гҖӮ(ж–°е»әдёҖдёӘж–Ү件example.confпјҢзІҳиҙҙд»ҘдёӢеҶ…е®№пјҢ并дҝқеӯҳ)
# example.conf: A single-node Flume configuration # Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 44444 # Describe the sink a1.sinks.k1.type = logger # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
В
иҜҘй…ҚзҪ®ж–Ү件дёӯagentзҡ„еҗҚеӯ—жҳҜa1пјҢжүҖд»Ҙдҝ®ж”№еҗҜеҠЁе‘Ҫд»Өпјҡ
$ bin/flume-ng agent --conf-file example.conf --name a1 -Dflume.root.logger=INFO,console
В 1.2еҸҠжӣҙдҪҺзүҲжң¬зҡ„з”ЁжҲ·пјҢиҜ·жҠҠе‘Ҫд»Өдёӯзҡ„agentж”№дёәnodeгҖӮ
В
В жҺҘзқҖйҖҹйҖҹеҗҜеҠЁFlume agentеҗ§гҖӮеҗҜеҠЁеүҚзЎ®дҝқ44444з«ҜеҸЈжІЎжңүиў«еҚ з”ЁгҖӮ
В
еҗҜеҠЁжҲҗеҠҹеҗҺпјҢдҪҝз”Ёtelnetеҗ‘AgentеҸ‘йҖҒж—Ҙеҝ—пјҡ
$ telnet localhost 44444
В дјҡзңӢеҲ°еҰӮдёӢж—Ҙеҝ—пјҡ
Trying 127.0.0.1... Connected to localhost.localdomain (127.0.0.1). Escape character is '^]'.
В иҫ“е…ҘдҪ зҡ„ж—Ҙеҝ—еҶ…е®№пјҢжҜ”еҰӮпјҡHello world!еӣһиҪҰеҸ‘йҖҒгҖӮ
В еҫ—еҲ°еҰӮдёӢж—Ҙеҝ—пјҢиҜҙжҳҺдҪ е·Із»ҸжҲҗеҠҹеҸ‘йҖҒж—Ҙеҝ—пјҡ
$ telnet localhost 44444 Trying 127.0.0.1... Connected to localhost.localdomain (127.0.0.1). Escape character is '^]'. Hello world! <ENTER> OK
В
еңЁFlume agentзҡ„жҺ§еҲ¶еҸ°йҮҢдҪ еҸҜд»ҘзңӢеҲ°еҰӮдёӢдҝЎжҒҜпјҡ
12/06/19 15:32:19 INFO source.NetcatSource: Source starting
12/06/19 15:32:19 INFO source.NetcatSource: Created serverSocket:sun.nio.ch.ServerSocketChannelImpl[/127.0.0.1:44444]
12/06/19 15:32:34 INFO sink.LoggerSink: Event: { headers:{} body: 48 65 6C 6C 6F 20 77 6F 72 6C 64 21 0D Hello world!. }
В
иҮіжӯӨпјҢжҒӯе–ңдҪ пјҒдёҖдёӘжңҖз®ҖеҚ•зҡ„Flume agentе·Із»ҸжӯЈеёёе·ҘдҪңдәҶпјҒ
В
В
Setting multi-agent flow
и®ҫзҪ®еӨҡagentзҡ„жөҒ
В
е…Ҳз»ҷеҮ еј е®ҳзҪ‘зҡ„еӣҫпјҡ

В
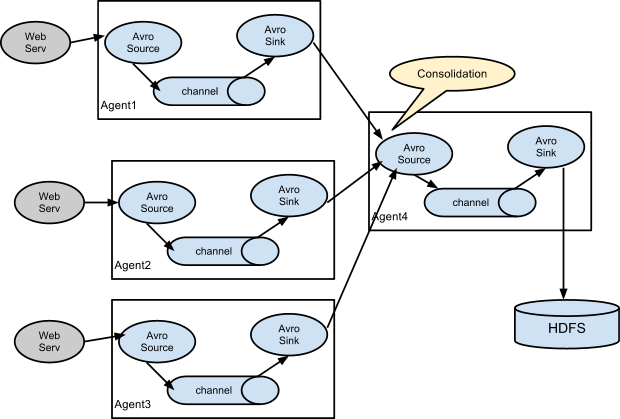
В
В еӨ§е®¶еҸҜд»ҘжҢүз…§е®ҳж–№з”ЁжҲ·жүӢеҶҢжқҘж·ұе…ҘеӯҰд№ гҖӮ
В
В
В
В



зӣёе…іжҺЁиҚҗ
Flume-NG е®үиЈ…дёҺй…ҚзҪ®жҢҮеҚ— Flume-NG жҳҜдёҖдёӘеҲҶеёғејҸж—Ҙеҝ—收йӣҶзі»з»ҹпјҢиғҪеӨҹд»Һеҗ„з§Қж•°жҚ®жәҗдёӯе®һж—¶йҮҮйӣҶж•°жҚ®пјҢ并е°Ҷе…¶дј иҫ“еҲ°йӣҶдёӯејҸеӯҳеӮЁзі»з»ҹдёӯгҖӮжң¬ж–Үе°ҶжҢҮеҜјжӮЁе®ҢжҲҗ Flume-NG зҡ„е®үиЈ…е’Ңеҹәжң¬й…ҚзҪ®гҖӮ е®үиЈ… Flume-NG 1. е…ҲеҶіжқЎд»¶пјҡ...
Flume1.6.0е…Ҙй—Ёпјҡе®үиЈ…гҖҒйғЁзҪІгҖҒеҸҠflumeзҡ„жЎҲдҫӢ
FlumeжҳҜClouderaжҸҗдҫӣзҡ„дёҖдёӘй«ҳеҸҜз”Ёзҡ„пјҢй«ҳеҸҜйқ зҡ„пјҢеҲҶеёғејҸзҡ„жө·йҮҸж—Ҙеҝ—йҮҮйӣҶгҖҒиҒҡеҗҲе’Ңдј иҫ“зҡ„зі»з»ҹпјҢFlumeж”ҜжҢҒеңЁж—Ҙеҝ—зі»з»ҹдёӯе®ҡеҲ¶еҗ„зұ»ж•°жҚ®еҸ‘йҖҒж–№пјҢз”ЁдәҺ收йӣҶж•°жҚ®пјӣеҗҢж—¶пјҢFlumeжҸҗдҫӣеҜ№ж•°жҚ®иҝӣиЎҢз®ҖеҚ•еӨ„зҗҶпјҢ并еҶҷеҲ°еҗ„з§Қж•°жҚ®жҺҘеҸ—ж–№пјҲеҸҜ...
FlumeжҳҜClouderaжҸҗдҫӣзҡ„дёҖдёӘй«ҳеҸҜз”Ёзҡ„пјҢй«ҳеҸҜйқ зҡ„пјҢеҲҶеёғејҸзҡ„жө·йҮҸж—Ҙеҝ—йҮҮйӣҶгҖҒиҒҡеҗҲе’Ңдј иҫ“зҡ„зі»з»ҹпјҢFlumeж”ҜжҢҒеңЁж—Ҙеҝ—зі»з»ҹдёӯе®ҡеҲ¶еҗ„зұ»ж•°жҚ®еҸ‘йҖҒж–№пјҢз”ЁдәҺ收йӣҶж•°жҚ®пјӣеҗҢж—¶пјҢFlumeжҸҗдҫӣеҜ№ж•°жҚ®иҝӣиЎҢз®ҖеҚ•еӨ„зҗҶпјҢ并еҶҷеҲ°еҗ„з§Қж•°жҚ®жҺҘеҸ—ж–№пјҲеҸҜ...
е°ҡзЎ…и°·еӨ§ж•°жҚ®жҠҖжңҜд№ӢFlume
и®©дҪ еҝ«йҖҹи®ӨиҜҶflumeеҸҠе®үиЈ…е’ҢдҪҝз”Ёflume1 5дј иҫ“ж•°жҚ® ж—Ҙеҝ— еҲ°hadoop2 2 дёӯж–Үж–ҮжЎЈ и®ӨиҜҶ flume 1 flume жҳҜд»Җд№Ҳ иҝҷйҮҢз®ҖеҚ•д»Ӣз»ҚдёҖдёӢ е®ғжҳҜ Cloudera зҡ„дёҖдёӘдә§е“Ғ 2 flume жҳҜе№Ід»Җд№Ҳзҡ„ 收йӣҶж—Ҙеҝ—зҡ„ 3 flume еҰӮдҪ•жҗңйӣҶж—Ҙеҝ— жҲ‘们жҠҠ...
flumeе®ҳзҪ‘дёӢиҪҪеӨӘж…ўпјҢиҜ·д»ҺиҝҷйҮҢдёӢиҪҪпјҢж¬Ўж–Ү件жҳҜе®ҳж–№зҪ‘з«ҷзҡ„1.8зүҲжң¬пјҢд№ҹе°ұжҳҜж”ҜжҢҒjdk1.8зҡ„пјҢдёҚж”ҜжҢҒjdk1.7пјҢеҰӮжһңиҰҒж”ҜжҢҒjdk1.7зҡ„пјҢиҜ·дёӢиҪҪжҲ‘зҡ„иө„жәҗйҮҢйқўд№ҹжңүпјҢflume1.7пјҢ
flumeйӣҶзҫӨзҺҜеўғжҗӯе»әпјҢиҜҰз»Ҷи®Іи§ЈпјҢеӣҫж–Ү并иҢӮпјҢеҢ…жӢ¬flumeдҝЎжҒҜзӣ‘жҺ§е’Ңдј—еӨҡж–Үз« й“ҫжҺҘ
flumeж”ҜжҢҒRabbitMQжҸ’件
flume1.9йҮҮйӣҶж•°жҚ®е…Ҙеӯҳе…Ҙelasticsearch6.2.4пјҢflume1.9жң¬иә«еҸӘж”ҜжҢҒдҪҺзүҲжң¬зҡ„elasticsearchпјҢеҹәдәҺapache-flume-1.9.0-srcзҡ„flume-ng-sinks/flume-ng-elasticsearch-sinkжәҗз Ғдҝ®ж”№пјҢж”ҜжҢҒes6.2.4пјҢжү“зҡ„еҢ…пјҢзӣҙжҺҘжӣҝжҚўflume/...
Apache Flume жҳҜдёҖдёӘеҲҶеёғејҸгҖҒй«ҳеҸҜйқ гҖҒй«ҳеҸҜз”Ёзҡ„з”ЁжқҘ收йӣҶгҖҒиҒҡеҗҲгҖҒиҪ¬з§»дёҚеҗҢжқҘжәҗзҡ„еӨ§йҮҸж—Ҙеҝ—ж•°жҚ®еҲ°дёӯеӨ®ж•°жҚ®д»“еә“зҡ„е·Ҙе…· Apache FlumeжҳҜApacheиҪҜ件еҹәйҮ‘дјҡпјҲASFпјүзҡ„йЎ¶зә§йЎ№зӣ® EventжҳҜFlumeе®ҡд№үзҡ„дёҖдёӘж•°жҚ®жөҒдј иҫ“зҡ„жңҖе°ҸеҚ•е…ғгҖӮ...
Flume+kafka+Stormж•ҙеҗҲ зӨәдҫӢз®Җд»Ӣпјҡ д»ҘдёӢдёәдёүдёӘз»„е»әж•ҙеҗҲпјҢиҝҷйҮҢеҸӘеҒҡж“ҚдҪңд№ҹжј”зӨәз»“жһңпјҢеҺҹзҗҶжҖ§ж–№йқўеӨ§е®¶еӨҡеӯҰд№ еҹәзЎҖгҖӮ жөҒзЁӢйЎәеәҸжҳҜflumeиҺ·еҸ–telnetж•°жҚ®пјҢе°ҶжҺҘ收еҲ°зҡ„ж•°жҚ®еҸ‘йҖҒиҮіkafakпјҢkafkaдҪңдёәStormзҡ„spoutпјҢStormиҝӣиЎҢжңүеҗ‘ж— ...
еҹәдәҺflume+kafka+е®һж—¶и®Ўз®—еј•ж“ҺпјҲstorm,spark,flinkпјүзҡ„е®һж—¶и®Ўз®—жЎҶжһ¶зӣ®еүҚжҳҜжҜ”иҫғзҒ«зҡ„дёҖдёӘеҲҶж”ҜпјҢеңЁе®һж—¶ж•°жҚ®йҮҮйӣҶ组件дёӯflumeжү®жј”зқҖжһҒдёәйҮҚиҰҒи§’иүІпјҢlogtashжҳҜELKзҡ„йҮҚиҰҒ组件йғЁеҲҶпјҢfilebeatд№ҹжҳҜдёҖдёӘе®һж—¶йҮҮйӣҶе·Ҙе…·пјӣ
Log4jзӣҙжҺҘеҸ‘йҖҒж•°жҚ®еҲ°Flume + Kafka (ж–№ејҸдёҖ) йҖҡиҝҮflume收йӣҶзі»з»ҹж—Ҙи®°, 收йӣҶзҡ„ж–№ејҸйҖҡеёёйҮҮз”Ёд»ҘдёӢ. зі»з»ҹlogsзӣҙжҺҘеҸ‘йҖҒз»ҷflumeзі»з»ҹ, жң¬ж–Үдё»иҰҒи®°еҪ•з§Қж–№ејҸиҝӣиЎҢиҜҙжҳҺ. ж–Үз« й“ҫжҺҘ,иҜ·зңӢ:...
з”ұдәҺflumeе®ҳ方并жңӘжҸҗдҫӣftpпјҢsourceзҡ„ж”ҜжҢҒпјӣ еӣ жӯӨжғідҪҝз”Ёftpж–Ү件жңҚеҠЎеҷЁзҡ„иө„жәҗдҪңдёәж•°жҚ®зҡ„жқҘжәҗе°ұйңҖиҰҒиҮӘе®ҡд№үftpsourceпјҢж №жҚ®githubпјҡhttps://github.com/keedio/flume-ftp-sourceпјҢжҸҗзӨәдёӢиҪҪзӣёе…іjarпјҢеҶҚжӯӨдҪңдёәи®°еҪ•гҖӮ
Flumeе®ҳж–№ж–ҮжЎЈдёӯж–Үзҝ»иҜ‘зүҲпјҢзҲ¬еҸ–зүҲпјҢPDFзүҲпјҢеҺҹж–Ү PDFгҖӮ
CDHзүҲжң¬зҡ„flume FlumeжҳҜClouderaжҸҗдҫӣзҡ„дёҖдёӘй«ҳеҸҜз”Ёзҡ„пјҢй«ҳеҸҜйқ ...еҪ“еүҚFlumeжңүдёӨдёӘзүҲжң¬Flume 0.9XзүҲжң¬зҡ„з»ҹз§°Flume-ogпјҢFlume1.XзүҲжң¬зҡ„з»ҹз§°Flume-ngгҖӮз”ұдәҺFlume-ngз»ҸиҝҮйҮҚеӨ§йҮҚжһ„пјҢдёҺFlume-ogжңүеҫҲеӨ§дёҚеҗҢпјҢдҪҝз”Ёж—¶иҜ·жіЁж„ҸеҢәеҲҶгҖӮ
Flume NGжҳҜClouderaжҸҗдҫӣзҡ„дёҖдёӘеҲҶеёғејҸгҖҒеҸҜйқ гҖҒеҸҜз”Ёзҡ„зі»з»ҹпјҢе®ғиғҪеӨҹе°ҶдёҚеҗҢж•°жҚ®жәҗзҡ„жө·йҮҸж—Ҙеҝ—ж•°жҚ®иҝӣиЎҢй«ҳж•Ҳ收йӣҶгҖҒиҒҡеҗҲгҖҒ移еҠЁпјҢжңҖеҗҺеӯҳеӮЁеҲ°дёҖдёӘдёӯеҝғеҢ–ж•°жҚ®еӯҳеӮЁзі»з»ҹдёӯгҖӮз”ұеҺҹжқҘзҡ„Flume OGеҲ°зҺ°еңЁзҡ„Flume NGпјҢиҝӣиЎҢдәҶжһ¶жһ„йҮҚжһ„пјҢ...
kafkaеҜ№жҺҘflumeпјҢflumeеҜ№жҺҘelasticSearchпјҢflumeй…ҚзҪ®ж ·дҫӢ
01_Flumeзҡ„д»Ӣз»ҚеҸҠе…¶жһ¶жһ„з»„жҲҗ 02_Flumeзҡ„е®үиЈ…йғЁзҪІ 03_Flumeзҡ„жөӢиҜ•иҝҗиЎҢ 04_Flumeдёӯй…ҚзҪ®дҪҝз”Ёfile channelеҸҠHDFS sink 05_Flumeдёӯй…ҚзҪ®HDFSж–Ү件з”ҹжҲҗеӨ§е°ҸеҸҠж—¶й—ҙеҲҶеҢә 06_Flumeдёӯй…ҚзҪ®Spooling Dirзҡ„дҪҝз”Ё 07_Flumeдёӯ...