
1.ÌÍ ËÌͤ
̘ͤÌÌ°:
ô Í´ÍñýÌͤÓiÌÀÒۯͧð¡ÙÌÍ Ëð¡ÌÀ̯Òۯͧÿ¥ÍƒÍ¯ÌͤÓi+1ÌÀÒۯͧÐ
ӿͨÌÓʤÿ¥Í₤ð£ËÓ¤Óý̯ӣÿ¥ÓÓˋ¤ÕÇÌËð§ð¡¤ÌÍ ËÓð¡ÙÕÇÍÕÐô
Ì¿Ò¢ÌÍ ËÕÀ¤Í¤ÿ¥ÍÎÌÍ´ÌÍ ËÒ¢Ó´ð¡ÙÍËÕÀ¤Í¤ÌË̃̿ð¡¤ÌÍÌË̃ÿ¥ÕÈð¿Í °ÕÛÍÙÓÌ₤̘҃À̯Í₤ð£ËÍͯÿ¥ÒۯͧÓÓϣʹ̘À̯ð¡ÍÐô
ՃͥÌÍ ËÌͤÿ¥ð¡Ó´Ì¯Ó£ÒÓ´ÕƒÒÀ´ÍÙʹ̯ÌÛÿ¥Í¯Ýð¡ÕÒÎÓϣʹ̯ÌÛÒð£ ð£ ÕÒÎÌ¿ÍՃͰÍ₤ð£ËÍÛÓ¯
ô
ÒÎÓ¿ÿ¥ÒÛƒÓ¨Í´Í çÿ¥ð§ð¡¤ð¡ÇÌÑÍÙÍ´ÍÍÊÌÙ̯ӣ҃¿Óð¿Ó´Ð
ô
ÓÇÌËÌÍ ËÌͤÓʤðƒÿ¥
ô
ô
ÍÎÌÓ¯ÒÏð¡ð¡ˆÍÌÍ ËÍ ÓÇ Ó¡ÓÙÓÿ¥ÕÈð¿ÌÍ ËÍ ÓÇ ÌÌ°ÌÍ ËÓÍ ÓÇ ÌƒÍ´Ó¡ÓÙÍ ÓÇ ÓÍÕÂÐÌð£Ëÿ¥Ó¡ÓÙÍ ÓÇ ÓÍÍÕÀ¤Í¤ÌýÀÌÌ¿Íÿ¥ð£ÍÌ Í¤Í¤ÍͤͣÓÕÀ¤Í¤Í¯ÝÌ₤ÌÍ˧ͤÍÓÕÀ¤Í¤ÿ¥Ìð£ËÌÍ ËÌͤÌ₤Ó´°ÍÛÓÐ
ô
2ÐÌÍ ËÌͤãͯ͡Ìͤ
̘ͤÌÌ°ÿ¥
Í Í¯ÌÇð¡ˆÍƒ ÌͤÓÒۯͧͤÍÍÍýÌð¡¤ÒËÍ¿ýÍÙͤÍÍͨҢÒÀÓÇÌËÌÍ ËÌͤÿ¥Íƒ ÌÇð¡ˆÍ¤Íð¡ÙÓÒۯͧã̘ͤÌͤãÌÑÿ¥ÍÍ₤¿Í ´ð§ÒۯͧҢÒÀðƒÌ˜ÀÓÇÌËÌÍ ËÌͤÐ
Ìð§Ì¿Ì°ÿ¥
- ÕÌˋð¡ð¡ˆÍÂÕͤÍt1ÿ¥t2ÿ¥ãÎÿ¥tkÿ¥Í Ñð¡Ùti>tjÿ¥tk=1ÿ¥
- ÌÍÂÕͤÍð¡ˆÌ¯kÿ¥Í₤¿Í¤ÍÒ¢ÒÀk ÒÑÌͤÿ¥
- Ì₤ÒÑÌͤÿ¥Ì ¿ÌÛÍ₤¿Í¤ÓÍÂÕtiÿ¥Í¯Íƒ ÌͤÍÍÍýÌÒËÍ¿ýբͤÎð¡¤m ÓÍÙͤÍÿ¥ÍͨÍ₤¿ÍÍÙÒÀ´Ò¢ÒÀÓÇÌËÌÍ ËÌͤÐð£ ÍÂÕÍ ÍÙð¡¤1 ÌÑÿ¥ÌÇð¡ˆÍ¤Íð§ð¡¤ð¡ð¡ˆÒÀ´ÌËÍÊÓÿ¥ÒÀ´Õ¢Í¤ÎÍ°ð¡¤ÌÇð¡ˆÍ¤ÍÓբͤÎÐ
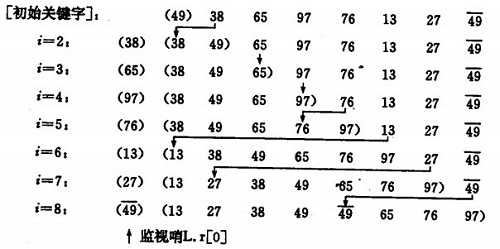
ͯ͡ÌͤÓÓʤðƒÿ¥
ô
ÓÛÌ°ÍÛÓ¯ÿ¥
Ìð£˜ÓÛÍÍÊÓÍÂÕͤÍÿ¥ÍÂÕͤÍd = {n/2 ,n/4, n/8 .....1}ô nð¡¤ÒÎÌ̯ͤÓð¡ˆÌ¯
Í°ÿ¥Í ͯÒÎÌͤÓð¡Ó£ÒۯͧÌÌð¡ˆÍÂÕdÿ¥n/2,nð¡¤ÒÎÌ̯ͤÓð¡ˆÌ¯ÿ¥ÍÌÒËÍ¿ýÓ£ÍÙͤÍÿ¥Ì₤Ó£ð¡ÙÒۯͧÓð¡Ì Ó¡ÍñÛd.Í₤¿Ì₤Ó£ð¡ÙÍ ´Õ´Í ÓÇ Ò¢ÒÀÓÇÌËÌÍ ËÌͤÿ¥ÓÑÍÍÓ´ð¡ð¡ˆÒƒÍ¯ÓÍÂÕÿ¥d/2ÿ¥Í₤¿ÍÛÒ¢ÒÀÍÓ£ÿ¥Í´Ì₤Ó£ð¡ÙÍÒ¢ÒÀÓÇÌËÌÍ ËÌͤÐÓ£ÏÓ£Ùð¡ÌÙÓ¥ˋͯÍÂÕÓÇÒ°ð¡¤1ÿ¥ÌÍð§¢Ó´ÓÇÌËÌÍ ËÌͤÍÛÌÌͤÐ
ô
3. ÕÌˋÌͤ
̘ͤÌÌ°ÿ¥
Í´ÒÎÌͤÓð¡Ó£Ì¯ð¡Ùÿ¥ÕͤÌͯÿ¥ÌÒ ÌÍÊÏÿ¥Óð¡ð¡ˆÌ¯ð¡Ó˜˜1ð¡ˆð§Ó§ÛÓ̯ð¤ÊÌÂÿ¥ÓÑÍÍ´Íˋð¡Ó̯ͧð¡ÙÍ̃Ìͯÿ¥ÌÒ ÌÍÊÏÿ¥Óð¡Ó˜˜2ð¡ˆð§Ó§ÛÓ̯ð¤ÊÌÂÿ¥ðƒÌ˜ÀÓݣ̴ÿ¥ÓÇͯӘ˜n-1ð¡ˆÍ ÓÇ ÿ¥Í̯Ә˜ð¤ð¡ˆÌ¯ÿ¥ÍÓ˜˜nð¡ˆÍ ÓÇ ÿ¥ÌÍð¡ð¡ˆÌ¯ÿ¥Ì₤Òƒð¡¤ÌÙÂÐ
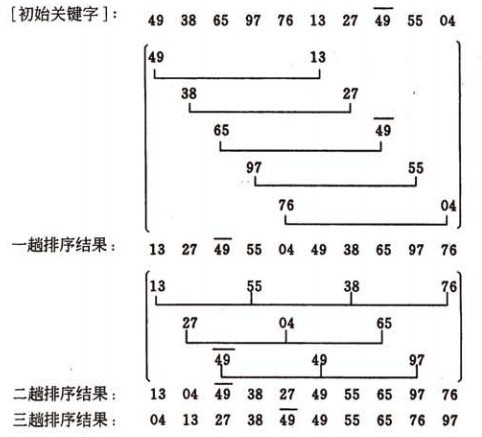
ÓÛÍÕÌˋÌͤÓÓʤðƒÿ¥
ô 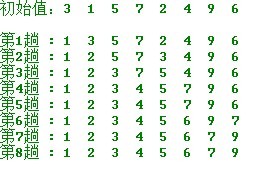
Ìð§Ì¿Ì°ÿ¥
Ó˜˜ð¡ÒÑÿ¥ð£n ð¡ˆÒۯͧð¡ÙÌƒÍ¤Í °ÕÛÓ ÌͯÓÒۯͧð¡Ó˜˜ð¡ð¡ˆÒۯͧð¤ÊÌÂÿ¥
Ó˜˜ð¤ÒÑÿ¥ð£Ó˜˜ð¤ð¡ˆÒۯͧͥÍÏÓn-1 ð¡ˆÒۯͧð¡ÙÍÕÍ¤Í °ÕÛÓ ÌͯÓÒۯͧð¡Ó˜˜ð¤ð¡ˆÒۯͧð¤ÊÌÂÿ¥
ð£ËÌÙÊÓݣ̴.....
Ó˜˜i ÒÑÿ¥Íð£Ó˜˜i ð¡ˆÒۯͧͥÍÏÓn-i+1 ð¡ˆÒۯͧð¡ÙÕÍ¤Í °ÕÛÓ ÌͯÓÒۯͧð¡Ó˜˜i ð¡ˆÒۯͧð¤ÊÌÂÿ¥
ÓÇͯÌÇð¡ˆÍ¤ÍÌÍ °ÕÛÓ ÌͤÐ
ô
4. ð¤ÊÌÂÌͤãÍÌ°ÀÌͤÿ¥Bubble Sortÿ¥
̘ͤÌÌ°ÿ¥
Í´ÒÎÌͤÓð¡Ó£Ì¯ð¡Ùÿ¥Í₤¿Í§ÍҢ̈ÌÍ˧ͤÓÒÍÇÍ ÓÍ ´Õ´Ì¯ÿ¥Òˆð¡Òð¡Í₤¿Ó¡Õ£Óð¡Êð¡ˆÌ¯ðƒÌ˜ÀÒ¢ÒÀÌ₤ÒƒÍÒ¯ÌÇÿ¥ÒÛˋÒƒÍÊÏÓ̯̓ð¡Ìýÿ¥ÒƒÍ¯Ó̓ð¡ÍÐÍ°ÿ¥Ì₤ͧð¡ÊÓ¡Õ£Ó̯Ì₤ÒƒÍÍÓ¯ÍÛð£˜ÓÌͤð¡ÌͤÒÎÌÝÓ¡ÍÌÑÿ¥Í¯ÝͯÍÛð£˜ð¤ÌÂÐ
ÍÌ°ÀÌͤÓÓʤðƒÿ¥
ô 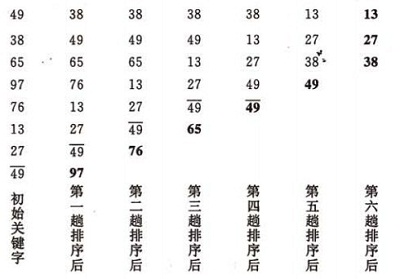
ô
ð£ÓÌ¿Ò¢ÓÛÌ°ÿ¥ Í¢¨ÕÌͤ
ÍÛÓ̘ͤÌÌ°Ì₤ÿ¥ÕÒ¢ð¡ÒÑÌͤͯÒÎÌͤÓ̯ÌÛÍÍýÌÓ˜Ó¨Óð¡ÊÕ´Íÿ¥Í Ñð¡Ùð¡Õ´ÍÓÌÌ̯ÌÛÕ§Ì₤ÍÎÍÊð¡Õ´ÍÓÌÌ̯ÌÛÕ§ÒÎͯÿ¥ÓÑÍÍÌÌÙÊÌ¿Ì°Í₤¿Ò¢ð¡ÊÕ´Í̯ÌÛÍͨҢÒÀÍ¢¨ÕÌͤÿ¥ÌÇð¡ˆÌͤҢӴÍ₤ð£ËÕͧҢÒÀÿ¥ð£ËÌÙÊÒƒƒÍ¯ÌÇð¡ˆÌ¯ÌÛÍÌÌͤͤÍÐ
ô
ӃͤÎÌͤÿ¥
http://baike.baidu.com/item/%E5%BF%AB%E9%80%9F%E6%8E%92%E5%BA%8F%E7%AE%97%E6%B3%95?fr=aladdin
ô
5ÐͧͿÑÌͤô
̘ͤÌÌ°
ͯð¡Êð¡ˆÌͤÓÍÒÀ´Í§Í¿ÑÌð¡ð¡ˆÌͤÍÒÀ´ÓÌ¿Ì°
ͧͿÑÌð§
ÓÛÌ°ÌÒ¢¯
6ÐÍ Ìͤô
̘ͤÌÌ°
Í ÍÛÒÇ´Ì₤Ì£ÀÒÑ°ÍÎð¡ÌÏÒÇ´ÓÍÛÍ ´ð¤ÍÌ ÿ¥Ì ð¡Ùð££ð¡ÕÍÑÒÓ¿ÓÍ °ÕÛÍÙð¡ÍÊÏð¤ÿ¥Ìð¡Í¯ð¤ÿ¥Í ÑÍñÎÍ°ÍÙˋÍÙÓ£Ó¿ÓÍ °ÕÛÍÙÐô
Ì ¿ÒÓ¿ÓÍ °ÕÛÍÙÌ₤Í ÕÌÌÒÓ¿Í °ÕÛÍÙð¡ÙÌÍ¯Ò ÓÍ Óϯð¡¤Í¯ÕÀÑÍ ÿ¥ Í Ì₤ð¡ÓÏÍÛÍ ´ð¤ÍÌ ÿ¥ð¡Ò˜ð§¢Ó´Ì¯Ó£ÌËÍÛÓ¯Ð
ô
ÓÛÌ°ÍÌ
Í¿°ÍÌÏÒ§
Í Ñð£ÌÏÒ§
7ÐÍÍʨ̥ÓÛÌ°
̘ͤÌÌ°ÿ¥
ÍÛÌ₤ÓÝnð¡ˆÍ¡ÎÌÍÑÍÙÓ£Ó¿ÌÌÓÌÌð¤ÍÌ ð¡ÙÍ¡ÎÌÒñ₤̓բͤÎÌÓÙÓð¤ÍÌ Ð
Í ð¡¤Ò¢ÓÏÌ ÌÌˋÓÝÍ̥ͥÿ¥Huffmanÿ¥Ó ÓˋÑÿ¥Ìð£ËÓϯð¡¤ÍÍ¥Ì¥Ì ÿ¥ÍͨÌð¥ð¤ÍÌ Ð
ô
ÍÍÊ¨Ì¥Ì ÍÍ£¤Ó´ð¤ð¡ÊÓÏÓÌ¿Ì°ÿ¥ð¡ÓÏÌ₤ͤð¤ÕÀ¤Í¤ÒÀ´ÿ¥ÍÎð¡ÓÏÌ₤ͤð¤ÌÍ¯Í Ð
ô
Í£¤Ó¨HuffmanÌ Ó̘ͤÌÒñ₤ÿ¥
Ó£ÍÛÌÌÕÓð¡Ó°£Í̯ÌÛÿ¥Í¡ÎÌÕÿ¥ÿ¥ð£ð¡ÙÌÕÌͯÌÕÓð¡Êð¡ˆÌ¯ÌÛÿ¥Ó£Ìð¡ÌÈçÌ ÿ¥ÍƒÍ¯ÓÓÑÒÓ¿ÍÌÍ Ë̯ͯÌÛÓ°£Íͧð¡ÙÐ
ô
8ÐÍÍʨ̥ÍÓ¥ˋÓÛÌ°
ÍÍʨ̥ÍÓ¥ˋÌÒñ₤
ÍÒÛƒð¡ÍÙÓ˜Îð¡ýÌ₤ÿ¥ãabcabcabcabcabcabcdddddddddãÿ¥Ó£ÒÛÀÍÍÙÓ˜ÎͤӯÓ̘À̯ÍÎð¡ÒÀ´Ð
ÍÙӘΠͤӯ̘À̯
a 6
b 6
c 6
d 9
ÌÓ Ïð¡Ì˜ÓÍÙÍ´Ì¿Ì°ÿ¥ð¡ð¡ˆÍÙÓ˜ÎÍ Ó´ð¡ð¡ˆÍÙÒÿ¥ÕÈð¿Í ÝÒÝÒÇ¿(6+6+6+9)*sizeof(char) = 27ÍÙÒÿ¥27ÍÙÒÓÀÛÍÛð¡ÓÛð£ð¿ÿ¥ð§Ì₤ÍÎÌÌ₤ÌçñÕ̯ÌÛÓÌÑÍÿ¥Í¯ÝÍ₤Ò§ÒÎÒÒÍÙÍ´Óˋ¤ÕÇÓÕÛÕÂð¤Ð
ô
ÌËÓÓÍÍʨ̥ÍÓ¥ˋÓÛÌ°Ì₤Ìð¿ÍÓÿ¥ÍÌ ñÌ₤ð¡ÕÂÓðƒÍÙÿ¥Ìð£˜Ò₤ÓÍ£¤Ó¨ÍÍÊ¨Ì¥Ì ÿ¥Í¤Ó¯Ó̘À̯ͯÝͧÍÌ₤ÌÕÿ¥Í¤Ó¯Ó̘À̯ÒÑÍÊÓÒ₤ÿ¥ÒÑÕ Ò¢Ì ¿ÒÓ¿ÿ¥ÕÈð¿Ó¥Ó ÒÑÓÙÿ¥ÍÎð¡Íƒÿ¥

ô
ð¤Ì₤ð¡ÕÂÓãabcabcabcabcabcabcdddddddddãÿ¥Í¯ÝÍ₤ð£ËÒ§˜Íð¡¤ã0001,1000,0110,0001,1000,0110,0001,1000,0110,1111,1111,1111,1111,11ãÿ¥Ì°´ÌÒ¢ÕÕÓ´ÓÌð§ÍÙÍ´Óÿ¥ð¿Í¯ÝÌ₤Ò₤Ç0Í1Õ§Ì₤ð§ÿ¥ÒÕcharÍÐÕÈð¿ð¿ÍÓ27ÍÙÒͯÝÒ¨Ìð£˜Ò§˜ÌÂÌð¤7ð¡ˆÍÙÒÿ¥7ÍÙÒð¡ÒÑ°ÿ¥ð¡ÒÑ°ÓÒ₤ͯÝÒÀËÕÑÿ¥ÿ¥ÒҢͯÝÒƒƒÍ¯ð¤ÍÓ¥ˋÓÌÌÐ
Ìð£ËÌ£Ó£ð¡ð¡ÿ¥ÍˋÓ´ÍÍÊ¨Ì¥Ì Ó¥Ó ÓÓ¿Ó¿ÿ¥ÌÕÒÑÍÊÏÒÑÕ Ò¢Ì ¿ÒÓ¿ÿ¥ÍƒÍ¯ÓÓ¥Ó Í¯ÝÒÑÓÙÓÍÓÿ¥ÒÍÎÌÌÍÙÓ˜Îͤӯ̘À̯ð§ð¡¤ÌÕÓÒ₤ÿ¥Ì̘ͧð¡Ùͤӯ̘À̯ÌÍÊÓÍÙÓ˜ÎͯÝÒ¨ÍÓ¥ˋÌð¤ÍƒÓÙÓÓ¥Ó Ð
ô
//todo



Ó¡Í °Ì´Ò
̯ÍÙÎÍ£¤Ì´À30ð¡ˆÍ¡¡Ó´ÓÛÌ°ÿ¥Pythonÿ¥Ì¯ÍÙÎÍ£¤Ì´À30ð¡ˆÍ¡¡Ó´ÓÛÌ°ÿ¥Pythonÿ¥Ì¯ÍÙÎÍ£¤Ì´À30ð¡ˆÍ¡¡Ó´ÓÛÌ°ÿ¥Pythonÿ¥Ì¯ÍÙÎÍ£¤Ì´À30ð¡ˆÍ¡¡Ó´ÓÛÌ°ÿ¥Pythonÿ¥Ì¯ÍÙÎÍ£¤Ì´À30ð¡ˆÍ¡¡Ó´ÓÛÌ°ÿ¥Pythonÿ¥Ì¯ÍÙÎÍ£¤Ì´À30ð¡ˆÍ¡¡Ó´ÓÛÌ°ÿ¥Pythonÿ¥Ì¯ÍÙÎÍ£¤Ì´À30ð¡ˆÍ¡¡Ó´ÓÛÌ°...
Ì´ÀÍÓÛÌ°ÍÊÏÍ ´ÿ¥20+ÓÏÍ¡¡Ó´ÓÛÌ°Ì´ÀÍ+ð£ÈÓ ÍÛÓ¯ÿ¥Ì´ÀÍÓÛÌ°ÍÊÏÍ ´ÿ¥20+ÓÏÍ¡¡Ó´ÓÛÌ°Ì´ÀÍ+ð£ÈÓ ÍÛÓ¯ÿ¥Ì´ÀÍÓÛÌ°ÍÊÏÍ ´ÿ¥20+ÓÏÍ¡¡Ó´ÓÛÌ°Ì´ÀÍ+ð£ÈÓ ÍÛÓ¯ÿ¥Ì´ÀÍÓÛÌ°ÍÊÏÍ ´ÿ¥20+ÓÏÍ¡¡Ó´ÓÛÌ°Ì´ÀÍ+ð£ÈÓ ÍÛÓ¯ÿ¥Ì´ÀÍÓÛÌ°ÍÊÏÍ ´ÿ¥20+ÓÏÍ¡¡Ó´ÓÛÌ°Ì´ÀÍ+...
Í¡¡Ó´ÓÛÌ° Í¡¡Ó´ÓÛÌ° Í¡¡Ó´ÓÛÌ° Í¡¡Ó´ÓÛÌ° Í¡¡Ó´ÓÛÌ°
ÍçÍ ËÍ¥Ó°£Ó£Ò§₤ð£ÑÒÛƒÒÛÀð¡ÙÓÍ¡¡Ó´ÓÛÌ°ÐÓ˜˜1Ó¨ ð£Ó£Í¡¡Ó´Ó¤¢ÌÏÌ¿Ó´Ó£ÌÝÒÏÈÓÛÌ°; Ó˜˜2Ó¨ ð£Ó£Í¡¡Ó´ð£È̯ÌÍ¥ÍÌýÓ¤¢ÌÍÓÛÌ°; Ó˜˜3Ó¨ ð£Ó£Í¡¡Ó´Ì¯Í¥ÓÏ₤ÍÓÛÌ°; Íð¤˜ÒˆÓˋ¤ÒˆÍÊˋÍÊÏÍÙÎͤÓÓʃӘ˜4Ó¨ ð£Ó£Í¡¡Ó´Ò§Ò¯ÝÍÊÓÓÛÌ°; Ó˜˜5Ó¨ ð£Ó£Í¡¡Ó´Ì¯ÍÙÌ£ÊÌ°Â...
CÍ¡¡Ó´ÓṴ̂ӴͤÕCÍ¡¡Ó´ÓṴ̂ӴͤÕCÍ¡¡Ó´ÓṴ̂ӴͤÕCÍ¡¡Ó´ÓṴ̂ӴͤÕ
ÒÛÀÓṲ̂͡¡Ó´ÓÛÌ° ÒÛÀÓṲ̂͡¡Ó´ÓÛÌ° ÒÛÀÓṲ̂͡¡Ó´ÓÛÌ°ÒÛÀÓṲ̂͡¡Ó´ÓÛÌ° ÒÛÀÓṲ̂͡¡Ó´ÓÛÌ° ÒÛÀÓṲ̂͡¡Ó´ÓÛÌ°
ÍçÍ ËÍ¥Ó°£Ó£Ò§₤ð£ÑÒÛƒÒÛÀð¡ÙÓÍ¡¡Ó´ÓÛÌ°(ÍÛÌÇÓ)
ð¡Ó₤ð¡¤ÓṴ̂ӴͤÓ₤ÿ¥ ð¡£ÒÎÒÛýÒ¢¯ð£Ëð¡Ì¿ÕÂÍ¡¡Ó´ÓÛÌ°Ó MATLAB ÍÛÓ¯ÿ¥Í ̘ÌÍ¥Ð̯ͧեҢÐÓˋÕçӿ̓ͥÒÛÀÓÛÐ̯ͥ̓ÛÍÐ̯ͥÓÏ₤ÍÐÌ¿Ó´ÌÝÌ ¿ÐÕÓ¤¢ÌÏÌ¿Ó´Ó£ÌÝÒÏÈÐÒÏÈÓ¤¢ÌÏÌ¿Ó´Ó£ÓÓÇÌËÌ°ÐÒÏÈÓ¤¢ÌÏÌ¿Ó´Ó£ÓÒ¢Ùð£ÈÌ°ÐÕ̤̯ÓÌÐ...
Òç̤ÍÓϯÿ¥JavaÍ¡¡Ó´ÓÛÌ°ÌÍÍ ÍÛ¿ÓÛð£ÿ¥Ó¯ð£ÈÓÒÛƒÒÛÀð££ÍÀÍÊÏÍÊÕÒ¢ÒÛÀÓṲ̂ӥӴÌËÍÛÌÿ¥ÒÓÛÌ°Òçñͯð¤Ò°Í °ÕÒÎÓð§Ó´ÐÍ₤ð£ËÌ₤¨ð¡ÍÊ¡Í¥ ͯÒ₤Çÿ¥ÓÛÌ°Ì₤ð¡ÍӴͤÒÛƒÒÛÀÓÓçÕÙÍͤÓÀÐÕÌˋÍÓÓÓÛÌ°ÿ¥Í₤ð£ËÒçñͯð¤ÍÍÍÓÌÌÐÐÒçç...
VBÍ¡¡Ó´ÓÛÌ°ÍÊÏÍ ´ÿ¥VBÍ¡¡Ó´ÓÛÌ°ÍÊÏÍ ´VBÍ¡¡Ó´ÓÛÌ°ÍÊÏÍ ´ÿ¥VBÍ¡¡Ó´ÓÛÌ°ÍÊÏÍ ´
Ì´Í Ì ÒÛÀÓṲ̂͡¡Ó´ÓÛÌ°ð¡Ó´Í¤ÒÛƒÒÛÀÌÓ´Ì´Í Ì ÒÛÀÓṲ̂͡¡Ó´ÓÛÌ°ð¡Ó´Í¤ÒÛƒÒÛÀÌÓ´Ì´Í Ì ÒÛÀÓṲ̂͡¡Ó´ÓÛÌ°ð¡Ó´Í¤ÒÛƒÒÛÀÌÓ´Ì´Í Ì ÒÛÀÓṲ̂͡¡Ó´ÓÛÌ°ð¡Ó´Í¤ÒÛƒÒÛÀÌÓ´
Í¡¡Ó´ÓÛÌ°ÍðƒÕÂÍ¡¡Ó´ÓÛÌ°ÍðƒÕÂÍ¡¡Ó´ÓÛÌ°ÍðƒÕÂ
VBÍ¡¡Ó´ÓÛÌ°ÍÊÏÍ ´ VBÍ¡¡Ó´ÓÛÌ°ÍÊÏÍ ´ VBÍ¡¡Ó´ÓÛÌ°ÍÊÏÍ ´
C++Í¡¡Ó´ÓÛÌ°Í °ð¤Ì¯ÌÛÍÙÍ´Ó£Í ¡Ó¥Ó´ÓÛÌ°ÍÛðƒ
MatlabÍ¡¡Ó´ÓÛÌ°ÍÊÏÕÍÿ¥ FloydÓÛÌ°.rar Í Ó¨ÓÛÌ°.rar ÍÌý£ÓÛÌ°.rar Í´ÌÒÏÍ.rar ̓ÒÛ¤.rar ÍÙÎð¿ Òñ₤Ó¤¢.png ÌÓÇÂÓÛÌ°.rar ÌÎÓÓÛÌ°.rar Ì´ÀÌÕÓ¨ÓÛÌ°.rar Ó¯ÒýÕÂÌç.rar Óˋñð¡ƒÌ°ÌÝÒÏÈ0-1ÌÇ̯ÒÏÍÓmatlabӴͤ.rar ÓÝ£Ì₤Ì°....
Í¡¡Ó´ÓṴ̂ӴͤÕÓ˜˜6Ó
CÍ¡¡Ó´ÓṴ̂ӴͤÕÿ¥ÍƒÍȨÒ₤Òÿ¥Ó˜˜6Ó¨ ÿ¥Í ̘cÌð£ÑÍdatÌð£Ñ
CÍ¡¡Ó´ÓÛÌ°Õ(Õ§Ì₤Ì₤ÒƒÓ£Í ¡ÓÓÛÌ° chm)
Í¡¡Ó´ÓṴ̂ӴͤÕ-̓ÍȨÒ₤ Í¡¡Ó´ÓṴ̂ӴͤÕ-̓ÍȨÒ₤ Í¡¡Ó´ÓṴ̂ӴͤÕ-̓ÍȨÒ₤ Í¡¡Ó´ÓṴ̂ӴͤÕ-̓ÍȨÒ₤ Í¡¡Ó´ÓṴ̂ӴͤÕ-̓ÍȨÒ₤