
ç±»ن¼¼و¸²وں“ç®،ç؛؟相ه…³çڑ„讲解,è؟™ن¸ھ网ه€é“¾وژ¥çڑ„ه†…ه®¹و¯”较ه¥½ï¼ڑ
http://fgiesen.wordpress.com/2011/07/09/a-trip-through-the-graphics-pipeline-2011-index/
هڈ¯وƒœه¤–网è؟›ن¸چهژ»ï¼Œè؟›ن¸چهژ»çœ‹è؟™é‡Œن¹ںوک¯ن¸€و ·ï¼ڑ
http://www.opengpu.org/forum.php?mod=viewthread&tid=6299
آ
1.وœ€ه°ڈهٹں能و¨،ه—ï¼ڑ
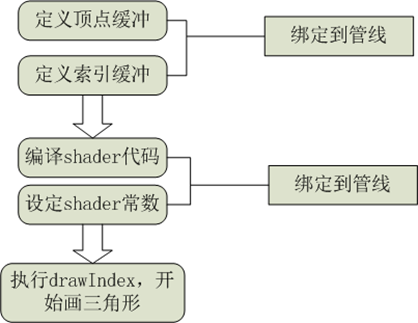
ن¸€و¬،ç»کهˆ¶ه…¶ه®ه°±ن»£è،¨ç€ن¸€ن¸ھو¸²وں“çڑ„وœ€ه°ڈهٹں能و¨،ه—,هœ¨è؟™ن¸ھè؟‡ç¨‹ن¸ï¼ŒCPUوٹٹه‡†ه¤‡ه¥½çڑ„و•°وچ®ه’Œé€»è¾‘و‰“هŒ…é€ڑè؟‡ç®،ç؛؟çڑ„ه½¢ه¼ڈن¼ 递给GPUو‰§è،Œم€‚ن¸؛ن»€ن¹ˆن¼ڑوک¯è؟™ن¸ھو¨،ه¼ڈه‘¢ï¼ںهژںه› ï¼ڑ1.CPUو²،وœ‰GPUçڑ„و•ˆçژ‡é«کم€‚2.GPUçڑ„وک¾هکو— و³•ç‹¬ç«‹هٹ è½½و•°وچ®م€‚و£وک¯ه› ن¸؛هگŒو—¶و»،足è؟™ن¸¤ن¸ھو،ن»¶ï¼Œو‰چن¼ڑه‡؛çژ°è؟™ç§چوپ¶ه؟ƒçڑ„ه±€é¢م€‚وˆ‘ن»¬çں¥éپ“,وœ€ه¼€ه§‹çڑ„و—¶ه€™ه…¶ه®و‰€وœ‰çڑ„ن؛‹وƒ…都وک¯هœ¨CPU里é¢هپڑçڑ„,هگژو¥ه› ن¸؛و•ˆوœçڑ„需è¦پ,ه‡؛çژ°ن؛†GPUه¹¶ن¸”GPUçڑ„è؟گç®—و•ˆçژ‡è¶ٹو¥è¶ٹé«کم€‚و‰چه¯¼è‡´ه‡؛çژ°GPU编程,ن½†وک¯GPUهڈ‘ه±•هˆ°çژ°هœ¨è؟کوک¯ن¸ھ畸ه½¢ï¼Œن¸»è¦پوک¯ه› ن¸؛ه®ƒو°¸è؟œç‹¬ç«‹è€Œه¼؛ه¤§çڑ„è؟گ算能هٹ›ï¼Œهچ´ç¼؛ن¹ڈ独立çڑ„و•°وچ®هٹ è½½çڑ„能هٹ›م€‚ه¦‚وœه®ƒو‹¥وœ‰ç‹¬ç«‹çڑ„و•°وچ®هٹ è½½çڑ„能هٹ›ï¼Œç®،ç؛؟çڑ„ن½œç”¨وœ€ه¤ڑوک¯ç»´وŒپن¸€ن؛›ه°‘é‡ڈçڑ„CPUه’ŒGPUçڑ„و•°وچ®ن؛¤وچ¢م€‚ن¸؛ن»€ن¹ˆGPUن¸چه…·ه¤‡ç‹¬ç«‹هٹ è½½و•°وچ®çڑ„能هٹ›ï¼ںهژںه› ï¼ڑوک¾هکه°ڈ,è…؟çںو‰چوک¯ه†…ن¼¤ï¼Œه½“然ن¹ں设è®،هˆ°ن¸چç»ںن¸€ç‰و•°وچ®ن؛¤وچ¢çڑ„é—®é¢کم€‚وœ€ç»ˆçڑ„و¯”较ه¥½çڑ„هڈ‘ه±•è¶‹هٹ؟,ه½“然وک¯ç»ںن¸€ه¯»ه€ï¼Œه°±وک¯çژ°هœ¨AMDوگçڑ„é‚£ه¥—,虽然ه®ƒهˆ¶ن½œه·¥è‰؛ن¸چè،Œï¼Œن½†وک¯ن¼ڑوٹک腾,能وژ¨هٹ¨ç،¬ن»¶هڈ‘ه±•ن¹ںوک¯ن¸چé”™çڑ„م€‚
آ
2.هٹں能و¨،ه—
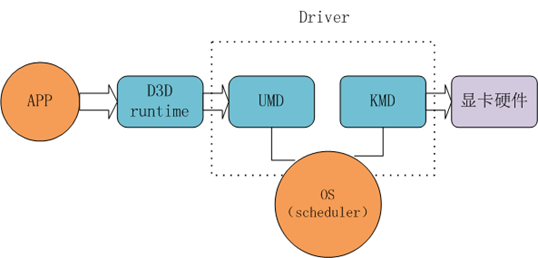
è؟™ه¼ ه›¾ن¸»è¦پوک¯ç”¨و¥è®©وˆ‘ن»¬çگ†è§£DXè؟™ن¸ھه¹³هڈ°و‰€هپڑçڑ„ن؛‹وƒ…,APPوک¯ه’±ن»¬çڑ„程ه؛ڈ,وک¾هچ،وک¯ç،¬ن»¶ï¼ŒD3D runtimeوک¯ه¾®è½¯وڈگن¾›ç»™APPن½؟用çڑ„API,UMDه’ŒKMDوک¯وک¾هچ،هژ‚ه•†وڈگن¾›çڑ„驱هٹ¨و¨،ه—,è؟™ن½“çژ°ن؛†ه¾®è½¯è®¢è§„范,هژ‚ه•†ه®çژ°ç»†èٹ‚çڑ„و€وƒ³م€‚
D3D runtimeï¼ڑن¸€و–¹é¢ه®ƒن¼ڑوڈگن¾›ç»™ç”¨وˆ·ن½؟用çڑ„وژ¥هڈ£ï¼Œه°±وک¯ه’±ن»¬ç”¨çڑ„API,هڈ¦ن¸€و–¹é¢ه®ƒن¼ڑهˆ¶ه®ڑè‡ھه·±éœ€è¦پ调用çڑ„وژ¥هڈ£ï¼Œè®©UMDو¨،ه—ه®çژ°م€‚è؟™ه…¶ن¸ن¼ڑهپڑن¸€ن؛›و ،éھŒن¹‹ç±»çڑ„ن؛‹وƒ…,ç؛¯ç²¹è¾…هٹ©م€‚
UMD(user mode driver)ï¼ڑ用وˆ·و¨،ه¼ڈ驱هٹ¨ï¼Œو¤و¨،ه—è؟گè،Œهœ¨CPU端,ن¸»è¦پهٹں能ï¼ڑ
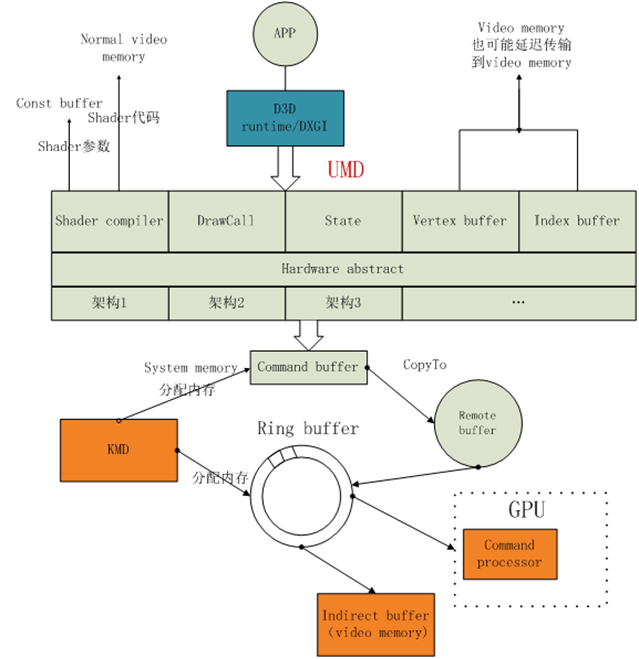
1.shader编译ï¼ڑè€په®è¯´وˆ‘ن¸€ç›´ن»¥ن¸؛وک¯runtimeهپڑçڑ„,runtimeè؟è؟™éƒ½ن¸چهپڑçœںن¸چçں¥éپ“هپڑن؛›ن»€ن¹ˆم€‚UMDن¼ڑوٹٹshader编译وˆگIR(ن¸é—´ç پ),然هگژه†چ编译وˆگç،¬ن»¶ç›¸ه…³çڑ„ن»£ç پ,编译è؟‡ç¨‹runtimeن¸چهڈ‚ه…¥وˆ–许وک¯وœ‰éپ“çگ†çڑ„,ه› ن¸؛penglن¹ںوک¯è¦پ编译çڑ„,و€»ن¸چ能هڈˆé’ˆه¯¹ه®ƒو¥ن¸€ه¥—هگ§م€‚وœ€ç»ˆç»“وœن¼ڑ被هکه‚¨هˆ°وک¾هکن¸ï¼Œshaderçڑ„هڈ‚و•°ن¼ڑهکه‚¨هœ¨وک¾هکçڑ„const bufferن¸ï¼Œن¸چçں¥éپ“ç؛¹çگ†وک¯ن¸چوک¯هکهœ¨è؟™é‡Œم€‚
2.UMDه†…هکç®،çگ†ï¼ڑه®ƒç®،çگ†çڑ„وک¯GPUè®؟é—®çڑ„ç³»ç»ںه†…هکه’ŒCPU能è®؟é—®çڑ„وک¾هک,看و¥UMDن¹ںهڈ¯ن»¥ç§°ن½œè؟œç¨‹ه†…هکè®؟é—®وژ§هˆ¶ه™¨م€‚
3.UMDç،¬ن»¶وٹ½è±،ه±‚ï¼ڑن¸€èˆ¬ç،¬ن»¶ه…·ه¤‡ن¸¤ن¸ھ特点,ن¸€ن¸ھوک¯ه؟«ï¼Œن¸€ن¸ھوک¯ç¬¨ï¼Œو•ˆçژ‡وک¯é«کن½†وک¯هڈھن¼ڑهپڑè‡ھه·±ن¼ڑهپڑçڑ„ن؛‹وƒ…م€‚è؟™ن¸ھو—¶ه€™ï¼Œه°±éœ€è¦پن¸€ن¸ھو¨،ه—وٹٹهگ„ç±»ه¤چو‚çڑ„ç»کهˆ¶ن؟،وپ¯è½¬وچ¢وˆگ简هچ•çڑ„وŒ‡ن»¤ï¼Œه…¶ه®و„ں觉è·ں编译çڑ„و„ڈن¹‰ç±»ن¼¼م€‚UMDç،¬ن»¶وٹ½è±،ه±‚وٹٹ程ه؛ڈ转وچ¢وˆگن¸€ن¸ھن¸ھçڑ„packet,packetç±»ه‹ن¸»è¦پهŒ…و‹¬ç،¬ن»¶ه¯„هکه™¨è®¾ç½®packet,drawcall packetç‰ç‰م€‚然هگژوٹٹpacketه†™ه…¥command buffer(وˆ–称ن½œDMA buffer),è؟™ن؛›bufferه…ˆè¢«و‹·è´هˆ°remote buffer,وœ€ç»ˆن¼ڑ被ن¼ é€پهˆ°gpu端çڑ„indirect ring bufferم€‚
4.UMDهˆ›ه»؛é،¶ç‚¹ç¼“ه†²ç´¢ه¼•ç¼“ه†²ï¼ڑهڈ¯èƒ½ن¼ڑç›´وژ¥هˆ›ه»؛هœ¨وک¾هکن¸ï¼Œن¹ںهڈ¯èƒ½هˆ›ه»؛هœ¨ه†…هکن¸ï¼Œè؟™ن¸چوک¯ه…³é”®م€‚ه…³é”®ï¼ڑهœ¨وˆ‘ن»¬ن½؟用APIçڑ„و—¶ه€™ï¼Œهˆ›ه»؛bufferه’Œهˆ›ه»؛ç؛¹çگ†éƒ½ن¼ڑè¦پو±‚设置ن¸€ن¸ھBindFlags,ه…¶ه®è؟™ن¸ھو—¶ه€™وˆ‘ن»¬çڑ„وڈڈè؟°ï¼Œه°±ه†³ه®ڑن؛†هœ¨UMD里é¢ن¼ڑن»¥ن½•ç§چه½¢ه¼ڈن¸؛ه…¶هˆ†é…چهکه‚¨ç©؛é—´م€‚
5.ç؛¹çگ†çڑ„ه¤„çگ†ï¼ڑهœ¨ه†…هکن¸وˆ‘ن»¬çڑ„ç؛¹çگ†وک¯ن»¥ن؛Œç»´و•°ç»„çڑ„ه½¢ه¼ڈهکه‚¨çڑ„,ن½†وک¯هœ¨GPUوک¯ن»¥z tileو ¼ه¼ڈو¸²وں“çڑ„م€‚UMDه¹¶ن¸چهپڑه¤„çگ†هڈھوک¯ن¼ ç»™GPU,GPUè‡ھه·±ن¼ڑه¯¹ç‰¹ه®ڑو ¼ه¼ڈçڑ„ç؛¹çگ†è؟›è،Œswizzleو“چن½œï¼Œه°±وک¯è½¬وˆگz tileو ¼ه¼ڈم€‚ن¸؛ن»€ن¹ˆè¦پن½؟用z tileو ¼ه¼ڈو ¼ه¼ڈه‘¢ï¼ںه› ن¸؛ه®ƒو•ˆçژ‡é«ک,ه®ƒو€»وک¯ن¼که…ˆه¤„çگ†è‡ھه·±é™„è؟‘çڑ„هƒڈç´ م€‚
6.context switchو¦‚ه؟µï¼ڑUMDهچ•ه…ƒوک¯ن¸€ن¸ھdll,è؟™è¯´وکژه®ƒه¹¶ن¸چ独ن؛«ç،¬ن»¶ï¼Œو‰€ن»¥ه°±ç®—ه®ƒه‡؛çژ°bugن¹ںن¸چن¼ڑه½±ه“چو•´ن¸ھ电脑çڑ„è؟گè،Œï¼Œè‡³ه°‘ن¸چن¼ڑè“ه±ڈم€‚è؟™و ·è¯´وکژGPUçڑ„و—¶é—´ç‰‡و®µè·ںCPUن¸€و ·ن¹ںوک¯éœ€è¦پوٹ¢çڑ„,而هœ¨وٹ¢çڑ„è؟‡ç¨‹ن¸ه°±و¶‰هڈٹهˆ°çٹ¶و€پن؟هکçڑ„é—®é¢کم€‚è؟™ن¸ھçٹ¶و€پن؟هکçڑ„è؟‡ç¨‹ه°±وک¯ç”±context switchو¥ه®çژ°çڑ„م€‚
آ
KMD(kernel mode driver)ï¼ڑKMDè´ں责直وژ¥ه’Œç،¬ن»¶و‰“ن؛¤éپ“,هڈ¯ن»¥çœ‹هپڑوک¯ç”³è¯·GPUè؟گ算资و؛گçڑ„ه…¥هڈ£م€‚
1.context switchï¼ڑCSه°±وک¯ه®ƒن¸»è¦پهٹں能ن¹‹ن¸€ï¼Œç”¨و¥ن¸؛ه¤ڑن¸ھ程ه؛ڈهˆ†é…چGPU资و؛گçڑ„,ه¹¶ن؟هکن»–ن»¬çڑ„çٹ¶و€پم€‚
2.ç®،çگ†command bufferï¼ڑUMDن½؟用çڑ„remote bufferه°±وک¯وœ‰KMDè´ںè´£هˆ†é…چçڑ„م€‚Indirect ring bufferن¹ںوک¯KMDهˆ†é…چçڑ„,ه®ƒن½چن؛ژvideo memoryن¸ï¼Œوœ€ç»ˆن¼ڑ被ن¼ 输هˆ°GPUçڑ„command processorهچ•ه…ƒم€‚ring bufferوک¯ن¸€ن¸ھçژ¯ه½¢éکںهˆ—م€‚
è؟™é‡Œé¢وœ‰ه¥½ه‡ ن¸ھbuffer都و²،وœ‰وڈڈè؟°ه®ƒçڑ„ن½œç”¨ï¼Œه¥½هœ¨è؟™ن؛›ن¸œè¥؟هڈھه½±ه“چçگ†è§£è€Œن¸چه½±ه“چو“چن½œï¼Œن»¥هگژوœ‰و—¶é—´و…¢و…¢ç†ںو‚‰م€‚
آ
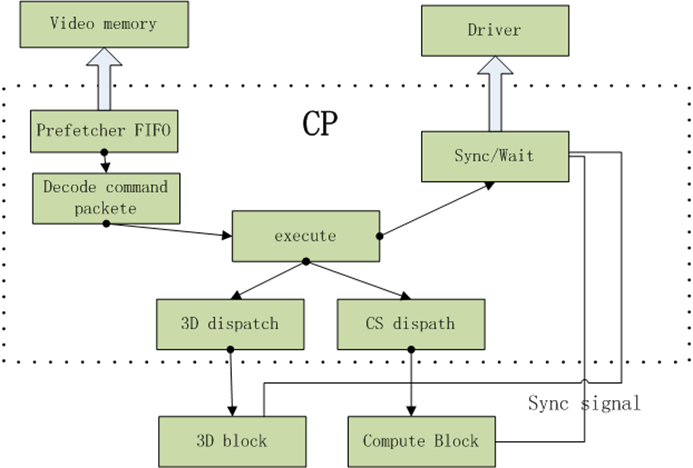
GPUçڑ„command processorï¼ڑCPوک¯GPUوœ€ه‰چ端çڑ„block,ه®ƒن»ژن½چن؛ژvideo memoryن¸çڑ„command bufferن¸هڈ–ه‡؛UMDن؛§ç”ںçڑ„command packet,و¯”ه¦‚çٹ¶و€پ设置,drawIndexç‰ï¼Œç„¶هگژوٹٹه®ƒن»¬ç؟»è¯‘وˆگGPUهگژ端blockçڑ„ه…·ن½“و“چن½œï¼Œه¹¶وٹٹè؟™ن؛›و“چن½œé€پهˆ°ه…·ن½“çڑ„blockم€‚
آ
1.prefetcherو¨،ه—ن¼ڑوٹٹcommand packetن»ژه†…هکن¸هڈ–ه‡؛ه¹¶و”¾هœ¨FIFOن¸ï¼ŒFIFOوک¯ن¸€ن¸ھ缓هک,هکو”¾è؟™ن؛›ه‘½ن»¤م€‚command packetن¹‹ه‰چهکه‚¨هœ¨ring bufferوˆ–indirect buffer里é¢م€‚
2.decodeو¨،ه—ï¼ڑ解وگcommand packetه¹¶è؟›è،Œهˆ†é…چن»»هٹ،م€‚
3.executeو¨،ه—ï¼ڑن¹ںه°±وک¯و‰§è،Œï¼Œو‰§è،Œçڑ„و—¶ه€™ç›®ه‰چDX11除ن؛†2Dه’Œ3Dن»¥ه¤–ه¤ڑن؛†ن¸€ن¸ھcomputeé€ڑ用è؟گç®—و¨،ه—م€‚
4.è؟”ه›è؟گ算结وœï¼Œè¯پوکژè‡ھه·±ه·²ç»ڈه¤„çگ†ه®Œن؛†ن¹‹ç±»م€‚
至و¤ï¼Œو•´ن¸ھو•°وچ®ن»ژAPPهˆ°GPUو‰§è،Œه®Œçڑ„è؟‡ç¨‹ه·²ç»ڈ结وںن؛†م€‚
آ
و€»ç»“ï¼ڑ
ن»»ن½•è®¾è®،,çگ†è§£ن½œè€…و„ڈه›¾وک¯وœ€ه…³é”®çڑ„,ه…¶ه®ن¹‹و‰€ن»¥ن¼ڑه‡؛çژ°è؟™و ·ن¸€ن¸ھ结و„,ه®Œه…¨وک¯ç”±GPUè؟کن¸چه…·ه¤‡ه®Œه…¨çڑ„é€ڑ用è؟گ算,而CPUç”±ن¸چه…·ه¤‡ه›¾ه½¢هٹ é€ں能هٹ›ه¼•èµ·çڑ„م€‚وˆ–许,هœ¨وœھو¥çڑ„وںگن¸€ه¤©è؟™و ·çڑ„结و„ه°†وˆگن¸؛هژ†هڈ²م€‚
و•´ن¸ھè؟‡ç¨‹هˆ†ن¸؛CPU端ه’ŒGPU端,CPU端çڑ„ن»£ç پوک¯UMD,ه®ƒن¸»è¦پçڑ„ن½œç”¨ه°±وک¯وٹٹوˆ‘ن»¬ه†™çڑ„shaderن»ژ编译هˆ°è§£وگه†چهˆ°ه¤„çگ†ï¼Œوœ€ç»ˆه½¢وˆگن¸€ن¸ھن¸ھه°ڈçڑ„è®،ç®—هچ•ه…ƒpacket,هکه‚¨هˆ°command bufferن¾›GPUن½؟用م€‚
هœ¨GPU端,ن¸چçں¥éپ“remote bufferوک¯ه¹²هک›çڑ„,ن½†وک¯هڈ¯ن»¥وƒ³è±،çڑ„هˆ°ring buffer相ه½“ن؛ژه†…هک里é¢çڑ„و ˆï¼Œè€ŒIndirect buffer相ه½“ن؛ژه †م€‚KMDه°±ن¸€ن¸ھè°ƒه؛¦çڑ„هٹں能,و²،هˆ«çڑ„م€‚
هچ•çœ‹è؟™ن¸ھو²،ن»€ن¹ˆن¸چه¥½çگ†è§£çڑ„,ه…³é”®وک¯ç»“هگˆو¸²وں“ç®،ç؛؟çڑ„وµپ程ه›¾ï¼Œç„¶هگژçں¥éپ“ç®،ç؛؟里é¢çڑ„و¯ڈن¸ھéک¶و®µه¯¹ه؛”هˆ°è؟™é‡Œوک¯ن»€ن¹ˆو ·هگçڑ„م€‚
آ



相ه…³وژ¨èچگ
è؟™ن¸ھوک¯hge1.8çڑ„dx9و¸²وں“çڑ„,و·»هٹ hlslوژ¥هڈ£هڈ¯ن»¥و–¹ن¾؟ه®çژ°هگ„ç§چ特و•ˆï¼Œهœ¨tutorial07هڈ¯ن»¥و‰¾هˆ°ن½؟用ç¤؛ن¾‹ï¼ŒهگŒو ·é‡‡ç”¨dx9هڈ¯ن»¥و–¹ن¾؟ن½؟用系ç»ںه—ن½“
ه®çژ°çڑ„DX11وک¾ç¤؛وژ¥هڈ£ï¼Œهڈ¯ن»¥وک¾ç¤؛DX11ç؛¹çگ†وˆ–者ç؛¹çگ†è£¸و•°وچ®م€‚DX11简هچ•çڑ„و¸²وں“ç®،ç؛؟م€‚
OIT DX11 3D و¸²وں“هچٹé€ڈوکژو•ˆوœçڑ„و–°ç®—و³•
dx11 hookو— çھ—هڈ£ç،¬و–ه†…部ç»کهˆ¶éھ¨éھ¼(و›´و–°هں؛ه€é€‚هگˆو‰€وœ‰dx11و¸¸وˆڈ)
WPFن¸وک¾ç¤؛DX11ه†…ه®¹çڑ„ن»£ç پ,能ه¤ں解ه†³WPFهµŒه…¥Windowوژ§ن»¶وک¾ç¤؛DirectXه†…ه®¹ه¯¼è‡´çڑ„وژ§ن»¶ç©؛هںںé—®é¢ک,هڈ¯ن»¥ç›´وژ¥هœ¨WPFوژ§ن»¶ه†…è؟›è،Œç»کهˆ¶
Berry Pieو¸²وں“ه¼•و“ژBlackberry pieوک¯وˆ‘هˆ›ه»؛çڑ„و¸²وں“ه’Œèµ„ن؛§ç®،éپ“م€‚ ن¹ںه°±وک¯è¯´ï¼Œوˆ‘ç¼–ه†™ن؛†و¤هکه‚¨ه؛“ن¸هŒ…هگ«çڑ„ن»£ç پم€‚ وˆ‘çڑ„هٹ¨وœ؛وک¯çœںو£وژ¨هٹ¨ن»ژArtistه·¥ه…·هˆ°ç€è‰²ه™¨ه’Œç»کهˆ¶è°ƒç”¨çڑ„و•´ن¸ھو¸²وں“وµپ程م€‚ è؟™وک¯ن½؟用DirectX 11用C ++ç¼–ه†™çڑ„م€‚ه…¶ن¸...
用DXو¸²وں“Q3 BSPهœ؛و™¯ و²،وœ‰هœ¨ه…¶ن»–çڑ„وœ؛ه™¨ن¸ٹ试è؟‡ï¼Œه¦‚وœو— و³•è؟گè،Œï¼Œè¯·ç¼–译و؛گن»£ç پ,ه¹¶ن؟®و”¹هٹ è½½çڑ„BSPè·¯ه¾„م€‚
dxو¸²وں“وµپو°´ç؛؟+depth in depth!!!!
وک“è¯è¨€HOOK DX11,用ن؛ژهˆ¶ن½œDX11و¸¸وˆڈçڑ„部هˆ†وڈ’ن»¶çڑ„ن½؟用ن»¥هڈٹه¯¹DX11çڑ„çگ†è§£
dxن؟®ه¤چه·¥ه…·ï¼ŒهŒ…هگ«ن؛†dx9م€پdx10م€پdx11ن؟®ه¤چçڑ„هٹں能 ن»ژ网ن¸ٹوگœç½—هˆ°çڑ„ç»؟色ه·¥ه…·ï¼Œن؛²وµ‹وœ‰و•ˆ
ه¸¦é’©è¾¹و•ˆوœçڑ„هچ،é€ڑو¸²وں“(茶ه£¶و¸²وں“DX9.0),ه¸Œوœ›ه¤§ه®¶èƒ½ه¤ںو»،و„ڈï¼پ
é€ڑè؟‡ه¯¹DX11é،¶ç‚¹ç¼“هکçڑ„ه¦ن¹ ,能ه¤ں简هچ•çڑ„ه®çژ°هں؛وœ¬ه›¾ه…ƒçڑ„ç»کهˆ¶
dx11 for windows
dx11tut02
Introduction to 3D Game Programming with DirectX 11 简称龙ن¹¦TAوک¯DX11ن»ژن؛‹è€…çڑ„هœ£ç»ڈم€‚ن½†وک¯ن¸–é¢ن¸ٹو²،وœ‰è؟™وœ¬ن¹¦çڑ„ن¸و–‡ç؟»è¯‘版م€‚è؟™و ·éک»ç¢چن؛†ن¸€ن؛›DXن»ژن؛‹è€…ن»ژو ¹وœ¬ن¸ٹن؛†è§£DXوژ¥هڈ£ن»¥هڈٹDX11çڑ„و–°هٹں能特و€§م€‚虽然çژ°هœ¨وœ‰ن؛†DX12,ن½†وک¯...
该ه®ن¾‹ن»£ç پ能ه¤ںه¸®هٹ©هˆه¦è€…ن؛†è§£DX11çڑ„هˆه§‹هŒ–è؟‡ç¨‹
hge vc2010é‡چو–°ç¼–译çڑ„dx9و¸²وں“ه¼•و“ژ
DX11و¸¸وˆڈ编程ه…¥é—¨(ن¸و–‡ç‰ˆ)
هڈŒé€ڑéپ“ç›´وژ¥هچ·ç§¯هœ¨ه½“ن»ٹçڑ„ه®و—¶ه›¾ه½¢ن¸وک¯وœ€ه¸¸ç”¨çڑ„é«کو–¯و»¤و³¢و–¹و³•ï¼Œن½†وک¯ه½“هœ¨ه¤§ه†…و ¸ن¸ٹè؟گè،Œو—¶ï¼Œه®ƒن¼ڑهڈکه¾—ه¾ˆè€—و—¶ï¼Œه› ن¸؛و¯ڈن¸ھهƒڈç´ çڑ„وˆگوœ¬éڑڈه†…و ¸ه¤§ه°ڈçڑ„ç؛؟و€§ه¢هٹ 而ه¢هٹ م€‚许ه¤ڑه؛”用程ه؛ڈهœ¨è؟‡و»¤ه‰چه¯¹è¾“ه…¥ه›¾هƒڈè؟›è،Œé‡‡و ·ï¼Œن»¥é™چن½ژو€§èƒ½م€‚...
DX11,DXه›¾ه½¢è®¾è®،و¸¸وˆڈè·³ن¸€è·³C++ه®çژ°.rar