摘自:
http://www.blogjava.net/zhenandaci/archive/2009/03/24/261701.html
前文提到过,除了开方检验(CHI)以外,信息增益(IG,Information Gain)也是很有效的特征选择方法。但凡是特征选择,总是在将特征的重要程度量化之后再进行选择,而如何量化特征的重要性,就成了各种方法间最大的不同。开方检验中使用特征与类别间的关联性来进行这个量化,关联性越强,特征得分越高,该特征越应该被保留。
Âú®‰ø°ÊÅØ¢ûÁõä‰∏≠ÔºåÈáç˶ÅÊÄßÁöÑË°°ÈáèÊÝáÂáÜÂ∞±ÊòØÁúãÁâπÂæÅËÉΩ§ü‰∏∫ÂàÜÁ±ªÁ≥ªÁªüÂ∏¶Êù•Â§öÂ∞ë‰ø°ÊÅØÔºåÂ∏¶Êù•Áöщø°ÊÅØË∂ä§öÔºåËØ•ÁâπÂæÅË∂äÈáç˶ńÄÇ
ÂõÝÊ≠§ÂÖàÂõûÂø܉∏ĉ∏ã‰ø°ÊÅØËÆ∫‰∏≠ÊúâÂÖ≥‰ø°ÊÅØÈáèÔºàÂ∞±ÊòØ‚ÄúÁܵ‚ÄùÔºâÁöÑÂÆö‰πâ„ÄÇËØ¥ÊúâËøô‰πà‰∏ĉ∏™ÂèòÈáèXÔºåÂÆÉÂèØËÉΩÁöÑÂèñÂĺÊúân§öÁßçÔºåÂàÜÂà´ÊòØx1Ôºåx2Ôºå‚Ķ‚ĶԺåxnÔºåÊØè‰∏ÄÁßçÂèñÂà∞ÁöÑʶÇÁéáÂàÜÂà´ÊòØP1ÔºåP2Ôºå‚Ķ‚ĶԺåPnÔºåÈÇ£‰πàXÁöÑÁܵÂ∞±ÂÆö‰πâ‰∏∫Ôºö
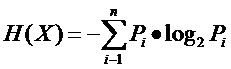
ÊÑèÊÄùÂ∞±Êò؉∏ĉ∏™ÂèòÈáèÂèØËÉΩÁöÑÂèòÂåñË∂ä§öÔºàÂèçËÄåË∑üÂèòÈáèÂÖ∑‰ΩìÁöÑÂèñÂĺÊ≤°Êú≪ª‰ΩïÂÖ≥Á≥ªÔºåÂè™ÂíåÂĺÁöÑÁßçÁ±ªÂ§öÂ∞뉪•ÂèäÂèëÁîüʶÇÁéáÊúâÂÖ≥ÔºâÔºåÂÆÉÊê∫Â∏¶Áöщø°ÊÅØÈáèÂ∞±Ë∂ä§ßÔºàÂõÝÊ≠§Êàë‰∏ÄÁõ¥ËßâÂæóÊà뉪¨ÁöÑÊîøÁ≠ñÊ≥ïËßщø°ÊÅØÈáèÈùûÂ∏∏§ßÔºåÂõ݉∏∫ÂÆÉÂèòÂåñÂæà§öÔºåÂü∫Êú¨Êúù‰ª§Â§ïÊîπÔºåÁ¨ëÔºâ„ÄÇ
ÂØπÂàÜÁ±ªÁ≥ªÁªüÊù•ËØ¥ÔºåÁ±ªÂà´CÊòØÂèòÈáèÔºåÂÆÉÂèØËÉΩÁöÑÂèñÂĺÊòØC1ÔºåC2Ôºå‚Ķ‚ĶԺåCnÔºåËÄåÊØè‰∏ĉ∏™Á±ªÂà´Âá∫Áé∞ÁöÑʶÇÁéáÊòØP(C1)ÔºåP(C2)Ôºå‚Ķ‚ĶԺåP(Cn)ÔºåÂõÝÊ≠§nÂ∞±ÊòØÁ±ªÂà´ÁöÑÊĪÊï∞„ÄÇÊ≠§Êó∂ÂàÜÁ±ªÁ≥ªÁªüÁöÑÁܵÂ∞±Âè؉ª•Ë°®Á§∫‰∏∫Ôºö
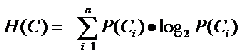
ÊúâÂêåÂ≠¶ËØ¥‰∏ç•ΩÁêÜËߣÂëÄÔºåËøôÊÝ∑ÊÉ≥Â∞±Â•Ω‰∫ÜÔºåÊñáÊú¨ÂàÜÁ±ªÁ≥ªÁªüÁöщΩúÁî®Â∞±ÊòØËæìÂá∫‰∏ĉ∏™Ë°®Á§∫ÊñáÊú¨Â±û‰∫éÂ왉∏™Á±ªÂà´ÁöÑÂĺԺåËÄåËøô‰∏™ÂĺÂèØËÉΩÊòØC1ÔºåC2Ôºå‚Ķ‚ĶԺåCnÔºåÂõÝÊ≠§Ëøô‰∏™ÂĺÊâÄÊê∫Â∏¶Áöщø°ÊÅØÈáèÂ∞±Êò؉∏äºè‰∏≠ÁöÑËøô‰πà§ö„ÄÇ
信息增益是针对一个一个的特征而言的,就是看一个特征t,系统有它和没它的时候信息量各是多少,两者的差值就是这个特征给系统带来的信息量,即增益。系统含有特征t的时候信息量很好计算,就是刚才的式子,它表示的是包含所有特征时系统的信息量。
ÈóÆÈ¢òÊòØÂΩìÁ≥ªÁªü‰∏çÂåÖÂê´tÊó∂Ôºå‰ø°ÊÅØÈáè¶ljΩïËÆ°ÁÆóÔºüÊà뉪¨Ê碉∏™ËßíÂ∫¶ÊÉ≥ÈóÆÈ¢òÔºåÊääÁ≥ªÁªü˶ÅÂÅöÁöщ∫ãÊÉÖÊÉ≥˱°ÊàêËøôÊÝ∑ÔºöËØ¥ÊïôÂƧÈáåÊúâÂæà§öÂ∫߉ΩçÔºåÂ≠¶Áîü‰ª¨ÊØèʨ°‰∏äËØæËøõÊù•ÁöÑÊó∂ÂÄôÂè؉ª•Èöè‰æøÂùêÔºåÂõÝËÄåÂèòÂåñÊòØÂæà§ßÁöÑÔºàÊóÝÊï∞ÁßçÂèØËÉΩÁöÑÂ∫ßʨ°ÊÉÖÂܵԺâÔºõ‰ΩÜÊòØÁé∞Âú®Êúâ‰∏ĉ∏™Â∫߉ΩçÔºåÁúãȪëÊùøÂæàÊ∏ÖÊ•öÔºåÂê¨ËÄÅÂ∏àËÆ≤‰πüÂæàÊ∏ÖÊ•öÔºå‰∫éÊòØÊÝ°ÈïøÁöÑÂ∞èËàÖÂ≠êÁöÑÂßêÂßêÁöÑ•≥ÂÑøÊâòÂÖ≥Á≥ªÔºàÁúüËæóËΩ¨ÂïäÔºâÔºåÊääËøô‰∏™Â∫߉ΩçÂÆö‰∏ãÊù•‰∫ÜÔºåÊØèʨ°Âè™ËÉΩÁªô•πÂùêÔºåÂà´‰∫∫‰∏çË°åÔºåÊ≠§Êó∂ÊÉÖÂܵÊÄéÊÝ∑ÔºüÂØπ‰∫éÂ∫ßʨ°ÁöÑÂèØËÉΩÊÉÖÂܵÊù•ËØ¥ÔºåÊà뉪¨ÂæàÂÆπÊòìÁúãÂá∫‰ª•‰∏ã‰∏§ÁßçÊÉÖÂܵÊòØÁ≠≪∑ÁöÑÔºöÔºà1ÔºâÊïôÂƧÈáåÊ≤°ÊúâËøô‰∏™Â∫߉ΩçÔºõÔºà2ÔºâÊïôÂƧÈáåËôΩÁÑ∂ÊúâËøô‰∏™Â∫߉ΩçÔºå‰ΩÜÂÖ∂‰ªñ‰∫∫‰∏çËÉΩÂùêÔºàÂõ݉∏∫ÂèçÊ≠£ÂÆɉπü‰∏çËÉΩÂèlj∏éÂà∞ÂèòÂåñ‰∏≠Êù•ÔºåÂÆÉÊò؉∏çÂèòÁöÑÔºâ„ÄÇ
对应到我们的系统中,就是下面的等价:(1)系统不包含特征t;(2)系统虽然包含特征t,但是t已经固定了,不能变化。
我们计算分类系统不包含特征t的时候,就使用情况(2)来代替,就是计算当一个特征t不能变化时,系统的信息量是多少。这个信息量其实也有专门的名称,就叫做“条件熵”,条件嘛,自然就是指“t已经固定“这个条件。
‰ΩÜÊòØÈóÆÈ¢òÊé•Ë∏µËÄåËá≥Ôºå‰æã¶lj∏ĉ∏™ÁâπÂæÅXÔºåÂÆÉÂèØËÉΩÁöÑÂèñÂĺÊúân§öÁßçÔºàx1Ôºåx2Ôºå‚Ķ‚ĶԺåxnÔºâÔºåÂΩìËÆ°ÁÆóÊù°‰ª∂ÁܵËÄåÈúÄ˶ÅÊääÂÆÉÂõ∫ÂÆöÁöÑÊó∂ÂÄôÔºå˶ÅÊääÂÆÉÂõ∫ÂÆöÂú®Â왉∏ĉ∏™Âĺ‰∏äÂë¢ÔºüÁ≠îÊ°àÊòØÊØè‰∏ÄÁßçÂèØËÉΩÈÉΩ˶ÅÂõ∫ÂÆö‰∏ĉ∏ãÔºåËÆ°ÁÆón‰∏™ÂĺԺåÁÑ∂ÂêéÂèñÂùáÂĺÊâçÊòØÊù°‰ª∂Áܵ„ÄÇËÄåÂèñÂùáÂĺ‰πü‰∏çÊòØÁÆÄÂçïÁöÑÂä݉∏ÄÂäÝÁÑ∂ÂêéÈô§‰ª•nÔºåËÄåÊòØ˶ÅÁî®ÊØè‰∏™ÂĺÂá∫Áé∞ÁöÑʶÇÁéáÊù•ÁÆóÂπ≥ÂùáÔºàÁÆÄÂçïÁêÜËߣԺåÂ∞±Êò؉∏ĉ∏™ÂĺÂá∫Áé∞ÁöÑÂèØËÉΩÊÄßÊØîËæɧßÔºåÂõ∫ÂÆöÂú®ÂÆɉ∏äÈù¢Êó∂ÁÆóÂá∫Êù•Áöщø°ÊÅØÈáèÂçÝÁöÑÊØîÈáçÂ∞±Ë¶Å§ö‰∏ĉ∫õÔºâ„ÄÇ
ÂõÝÊ≠§ÊúâËøôÊÝ∑‰∏§‰∏™Êù°‰ª∂ÁܵÁöÑË°®ËææºèÔºö
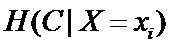
这是指特征X被固定为值xi时的条件熵,
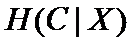
这是指特征X被固定时的条件熵,注意与上式在意义上的区别。从刚才计算均值的讨论可以看出来,第二个式子与第一个式子的关系就是:
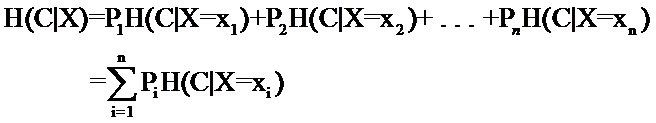
ÂÖ∑‰ΩìÂà∞Êà뉪¨ÊñáÊú¨ÂàÜÁ±ªÁ≥ªÁªü‰∏≠ÁöÑÁâπÂæÅtÔºåtÊúâÂá݉∏™ÂèØËÉΩÁöÑÂĺÂë¢ÔºüÊ≥®ÊÑètÊòØÊåá‰∏ĉ∏™Âõ∫ÂÆöÁöÑÁâπÂæÅÔºåÊØî¶ljªñÂ∞±ÊòØÊåáÂÖ≥ÈîÆËØç‚ÄúÁªèʵé‚ÄùÊàñËÄÖ‚Äú‰ΩìËÇ≤‚ÄùÔºåÂΩìÊà뉪¨ËØ¥ÁâπÂæÅ‚ÄúÁªèʵé‚ÄùÂèØËÉΩÁöÑÂèñÂĺÊó∂ÔºåÂÆûÈôÖ‰∏äÂè™Êúâ‰∏§‰∏™Ôºå‚ÄúÁªèʵé‚Äù˶ʼnπàÂá∫Áé∞Ôºå˶ʼnπà‰∏çÂá∫Áé∞„Älj∏ÄËà¨ÁöÑÔºåtÁöÑÂèñÂĺÂè™ÊúâtÔºà‰ª£Ë°®tÂá∫Áé∞ÔºâÂíåÔºà‰ª£Ë°®t‰∏çÂá∫Áé∞ÔºâÔºåÊ≥®ÊÑèÁ≥ªÁªüÂåÖÂê´t‰ΩÜt ‰∏çÂá∫Áé∞‰∏éÁ≥ªÁªüÊÝπÊú¨‰∏çÂåÖÂê´tÂèØÊò؉∏§Âõû‰∫ã„ÄÇ
ÂõÝÊ≠§Âõ∫ÂÆötÊó∂Á≥ªÁªüÁöÑÊù°‰ª∂ÁܵÂ∞±Êúâ‰∫ÜÔºå‰∏∫‰∫ÜÂå∫Âà´tÂá∫Áé∞Êó∂ÁöÑÁ¨¶Âè∑‰∏éÁâπÂæÅtÊú¨Ë∫´ÁöÑÁ¨¶Âè∑ÔºåÊà뉪¨Áî®T‰ª£Ë°®ÁâπÂæÅÔºåËÄåÁî®t‰ª£Ë°®TÂá∫Áé∞ÔºåÈÇ£‰πàÔºö
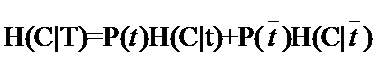
与刚才的式子对照一下,含义很清楚对吧,P(t)就是T出现的概率,就是T不出现的概率。这个式子可以进一步展开,其中的
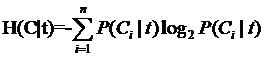
另一半就可以展开为:
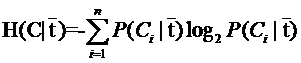
ÂõÝÊ≠§ÁâπÂæÅTÁªôÁ≥ªÁªüÂ∏¶Êù•Áöщø°ÊÅØ¢ûÁõäÂ∞±Âè؉ª•ÂÜôÊàêÁ≥ªÁªüÂéüÊú¨ÁöÑÁܵ‰∏éÂõ∫ÂÆöÁâπÂæÅTÂêéÁöÑÊù°‰ª∂Áܵ‰πãÂ∑ÆÔºö
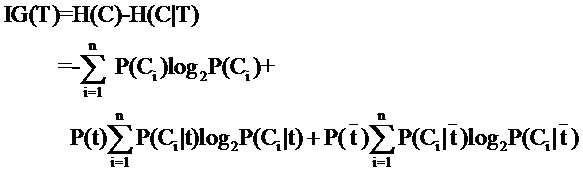
Â֨ºè‰∏≠Áöщ∏úË•øÁúã‰∏äÂéªÂæà§öÔºåÂÖ∂ÂÆû‰πüÈÉΩÂæà•ΩËÆ°ÁÆó„ÄÇÊØî¶ÇP(Ci)ÔºåË°®Á§∫Á±ªÂà´CiÂá∫Áé∞ÁöÑʶÇÁéáÔºåÂÖ∂ÂÆûÂè™Ë¶ÅÁî®1Èô§‰ª•Á±ªÂà´ÊĪÊï∞Â∞±ÂæóÂà∞‰∫ÜÔºàËøôÊòØËØ¥‰ΩÝÂπ≥Á≠âÁöÑÁúãÂæÖÊØè‰∏™Á±ªÂà´ËÄåÂøΩÁï•ÂÆɉª¨ÁöѧßÂ∞èÊó∂ËøôÊÝ∑ÁÆóÔºå¶ÇÊûúËÄÉËôë‰∫ܧßÂ∞èÂ∞±Ë¶ÅÊää§ßÂ∞èÁöÑÂΩ±ÂìçÂäÝËøõÂéªÔºâ„ÄÇÂÜçÊØî¶ÇP(t)ÔºåÂ∞±ÊòØÁâπÂæÅTÂá∫Áé∞ÁöÑʶÇÁéáÔºåÂè™Ë¶ÅÁî®Âá∫Áé∞ËøáTÁöÑÊñáÊ°£Êï∞Èô§‰ª•ÊĪÊñáÊ°£Êï∞Â∞±Âè؉ª•‰∫ÜÔºåÂÜçÊØî¶ÇP(Ci|t)Ë°®Á§∫Âá∫Áé∞TÁöÑÊó∂ÂÄôÔºåÁ±ªÂà´CiÂá∫Áé∞ÁöÑʶÇÁéáÔºåÂè™Ë¶ÅÁî®Âá∫Áé∞‰∫ÜTÂπ∂‰∏î±û‰∫éÁ±ªÂà´CiÁöÑÊñáÊ°£Êï∞Èô§‰ª•Âá∫Áé∞‰∫ÜTÁöÑÊñáÊ°£Êï∞Â∞±Âè؉ª•‰∫Ü„ÄÇ
‰ªé‰ª•‰∏äËÆ®ËÆ∫‰∏≠Âè؉ª•ÁúãÂá∫Ôºå‰ø°ÊÅØ¢ûÁõä‰πüÊòØËÄÉËôë‰∫ÜÁâπÂæÅÂá∫Áé∞Âíå‰∏çÂá∫Áé∞‰∏§ÁßçÊÉÖÂܵԺå‰∏éºÄÊñπÊ£ÄÈ™å‰∏ÄÊÝ∑ÔºåÊòØÊØîËæÉÂÖ®Èù¢ÁöÑÔºåÂõÝËÄåÊïàÊûú‰∏çÈîô„ÄljΩ܉ø°ÊÅØ¢ûÁõäÊúħßÁöÑÈóÆÈ¢òËøòÂú®‰∫éÂÆÉÂè™ËÉΩËÄÉÂØüÁâπÂæÅÂØπÊ雷∏™Á≥ªÁªüÁöÑË¥°ÁåÆÔºåËÄå‰∏çËÉΩÂÖ∑‰ΩìÂà∞Êüê‰∏™Á±ªÂà´‰∏äÔºåËøôÂ∞±‰ΩøÂæóÂÆÉÂè™ÈÄÇÂêàÁî®Êù•ÂÅöÊâÄË∞ì‚ÄúÂ֮±ĂÄùÁöÑÁâπÂæÅÈÄâÊã©ÔºàÊåáÊâÄÊúâÁöÑÁ±ªÈÉΩ‰ΩøÁî®Áõ∏ÂêåÁöÑÁâπÂæÅÈõÜÂêàÔºâÔºåËÄåÊóÝÊ≥ïÂÅö‚ÄúÊú¨Âú∞‚ÄùÁöÑÁâπÂæÅÈÄâÊã©ÔºàÊØè‰∏™Á±ªÂà´ÊúâËá™Â∑±ÁöÑÁâπÂæÅÈõÜÂêàÔºåÂõ݉∏∫ÊúâÁöÑËØçÔºåÂØπËøô‰∏™Á±ªÂà´ÂæàÊúâÂå∫ÂàÜÂ∫¶ÔºåÂØπÂ趉∏ĉ∏™Á±ªÂà´ÂàôÊóÝË∂≥ËΩªÈáçÔºâ„ÄÇ
看看,导出的过程其实很简单,没有什么神秘的对不对。可有的学术论文里就喜欢把这种本来很直白的东西写得很晦涩,仿佛只有读者看不懂才是作者的真正成功。
咱们是新一代的学者,咱们没有知识不怕被别人看出来,咱们有知识也不怕教给别人。所以咱都把事情说简单点,说明白点,大家好,才是真的好。
分享到:





相关推荐
ÈíàÂØπ‰ºÝÁªü‰ø°ÊÅØ¢ûÁõäÔºàIGÔºâÁâπÂæÅÈÄâÊã©ÊñπÊ≥ïÊ≤°ÊúâÂæà•ΩÁªÑÂêàÊ≠£Áõ∏ÂÖ≥ÁâπÂæÅÂíåË¥üÁõ∏ÂÖ≥ÁâπÂæÅÁöÑÈóÆÈ¢òÔºåºïÂÖ•ÊØî‰æãÂõÝÂ≠êÊù•Âπ≥Ë°°ÁâπÂæÅÂá∫Áé∞Âíå‰∏çÂá∫Áé∞Êó∂Áöщø°ÊÅØÈáèÔºåÈôç‰ΩéÂú®‰∏çÂπ≥Ë°°ËØ≠ÊñôÈõ܉∏äË¥üÁõ∏ÂÖ≥ÁâπÂæÅÁöÑÊØî‰æãÔºåÊèêÈ´òÂàÜÁ±ªÊïàÊûú„ÄÇÈÄöËøáÂÆûÈ™åËØÅÊòé‰∫ÜÊîπËøõÁöщø°ÊÅØ...
ÈíàÂØπËÇøÁò§Âü∫ÂõÝÊï∞ÊçÆÂõÝÁª¥Â∫¶È´òÂíåÂÜó‰ΩôÂü∫ÂõÝËæɧöËÄåÂغËá¥ÂàÜÁ±ªÁ≤æÂ∫¶‰ΩéÁöÑÈóÆÈ¢ò,ÊèêÂá∫‰∏ÄÁßçÂü∫‰∫éPCAÂíå‰ø°ÊÅØ¢ûÁõäÁöÑËÇøÁò§ÁâπÂæÅÂü∫ÂõÝÈÄâÊã©ÊñπÊ≥ï.ËØ•ÊñπÊ≥ïȶñÂÖà‰ΩøÁî®PCAÁÆóÊ≥ïÂâîÈô§ÂÜó‰ΩôÂü∫ÂõÝ,Ëé∑ÂæóÈ¢ÑÈÄâÁâπÂæÅÂü∫ÂõÝÂ≠êÈõÜ;ÁÑ∂ÂêéÂà©Áø°ÊÅØ¢ûÁõäÁÆóÊ≥ïÂØπÈ¢ÑÈÄâÁâπÂæÅÂü∫ÂõÝÂ≠ê...
现有的特征选择函数主要有文档频率(DF),信息增益(IG),互信息(MI)等。基于特征的基本约束条件以及高性能特征选择方法的设计步骤,提出了一种改进的特征选择方法SIG。该特征选择方法在保证分类效果的同时,...
针对上述问题,提出了信息增益(IG)与主成分分析(PCA)相结合的特征选择方法。通过实验比较分析了不同特征选择方法与特征维度对分类性能的影响,证明了该特征选择方法在基于神经网络的中文文本分类中的优越性,并得出...
对四种特征选择方法: 互信息、信息增益、x 2 统计和期望交叉熵作了简要的介绍, 并 且结合 K NN分类算法 , 使用查全率、查准率、宏平均和微平均对四种特征选择方法分别进行评 估 , 提出并讨论了互信息修正的两种方法...
介绍文本分类中特征提取方法的比较与分析,信息增益、卡方等方法
考察了文档频率DF、信息增益IG、互信息MI、V2 分布CHI 四种不同的特征选取方法。采用支持向量机(SVM) 和KNN 两种不同的分类器以考察不同抽取方法的有效性。实验结果表明, 在英文文本分类中表现良好的特征抽取方法( ...
比较了常用的CHI选择、互信息(MI)、信息增益(IG)和SVM 特征选择算法在垃圾邮件过滤中的效果,针对这些方法只排序而未消除特征间冗余的缺点,提出了利用特征词间条件概率和分类区分度消除冗余的混合邮件特征选择...
是关于文本特征提取的新方法,很不错,在信息增益\积比率的基础上,做了改善
Âú®‰ºÝÁªüÁöÑk-gramÊñπÊ≥ïÊèêÂèñÁöÑÁâπÂæÅÁöÑÂü∫Á°Ä‰∏äÔºå‰∏∫‰∫ÜÈÄâÂá∫Êõ¥ÂäÝÊúâÊïàÁöÑÁâπÂæÅÔºåÊèêÂá∫‰∫܉∏ÄÁßçÊñ∞ÁöÑÁâπÂæÅÈÄâÊã©ÊñπÊ≥ï‚Äî‚Äî‰ø°ÊÅØ¢ûÁõä„ÄÇÁ∫éÈíàÂØπ‰ø°ÊÅØ¢ûÁõäÊñπÊ≥ï‰∏≠Êú™ÂØπÁâπÂæÅÁ¢éÁâáÁöÑËØçÈ¢ëÁªô‰∫àË∂≥§üÈáçËßÜԺ剪éËÄåÂغËá¥ÁâπÂæÅÂàÜÂ∏ɉ∏çÂùáÁöÑÈóÆÈ¢òÔºåÂ∞ÜÁâπÂæÅÈ¢ëÁéáÂ∫îÁ∫é...
文档频率(DF)、信息增益(IG)和互信息(MI)等特征选择方法在文本分类中广泛应用。已有的实验结果表明,IG是最有效的特征选择算法之一,该方法基于申农提出的信息论。本文基于粗糙集理论,提出了一种新的特征选择方法(KG...
Âú®ÁÝîÁ©∂ÊñáÊú¨ÂàÜÁ±ªÁâπÂæÅÈÄâÊã©ÊñπÊ≥ïÁöÑÂü∫Á°Ä‰∏äÔºåÂàÜÊûê‰∫܉ø°ÊÅØ¢ûÁõäÊñπÊ≥ïÁöщ∏çË∂≥ÔºåÂ∞ÜÈ¢ëÂ∫¶„ÄÅÈõ܉∏≠Â∫¶„ÄÅÂàÜÊï£Â∫¶Â∫îÁî®Âà∞‰ø°ÊÅØ¢ûÁõäÊñπÊ≥ï‰∏äÔºåÊèêÂá∫‰∫܉∏ÄÁßçÂü∫‰∫é‰ø°ÊÅØ¢ûÁõäÁöÑÁâπÂæʼnºòÂåñÈÄâÊã©ÊñπÊ≥ï„ÄÇÂÆûÈ™åË°®ÊòéÔºåËØ•ÊñπÊ≥ïÂú®ÂàÜÁ±ªÊïàÊûú‰∏éÊÄßËÉΩ‰∏äÈÉΩ‰ºò‰∫鉺ÝÁªüÊñπÊ≥ï„ÄÇ
基于信息增益与CHI卡方统计的情感文本特征选择.pdf
ÂÆûÁé∞ÁöÑÂäüËÉΩ ‰∏Ä„ÄÅËØ≠ÊñôÂ∫ì§ÑÁêÜ ËØçÈ¢ëÁéáÔºàTFÔºâÔºåÊñáÊ°£È¢ëÁéáÔºàDFÔºâÁöÑÁªüËÆ°„ÄÇ...‰ø°ÊÅØ¢ûÁõäIGÊñπÊ≥ïÔºöË°°ÈáèÁâπÂæÅËÉΩ§ü‰∏∫ÂàÜÁ±ªÁ≥ªÁªüÂ∏¶Êù•Â§öÂ∞ë‰ø°ÊÅØÔºåË∑üÂÖ∑‰ΩìÁ±ªÂà´ÊóÝÂÖ≥„ÄÇ ‰∏â„ÄÅÊñáÊú¨ÂàÜÁ±ª„ÄÇ ÂàÜÁ±ªÂø´ÈÄü„ÄÇ ËÉΩÂØπÂçï‰∏™Êñቪ∂„ÄÅÁõÆÂΩï„ÄÅÊñቪ∂ÂàóË°®ËøõË°åÂàÜÁ±ª„ÄÇ
‰∏∫‰∫ÜËé∑ÂæóÊõ¥Â•ΩÁöÑÊñáÊú¨ÂàÜÁ±ªÂáÜÁ°ÆÁéáÂíåÊõ¥Âø´ÁöÑÊâßË°åÊïàÁéá, ÁÝîÁ©∂‰∫ܧöÁßçWebÊñáÊú¨ÁöÑÁâπÂæÅÊèêÂèñÊñπÊ≥ï, ÈÄöËøáÂØπ‰∫í‰ø°ÊÅØ(MI)„ÄÅÊñáÊ°£È¢ëÁéá(DF)„Äʼnø°ÊÅØ¢ûÁõä(IG)Âíåœá2ÁªüËÆ°ÔºàCHIÔºâÁÆóÊ≥ïÁöÑÁÝîÁ©∂, Âà©Áî®ÂÖ∂ÂêÑËá™ÁöщºòÂäø‰∫íË°•, ÊèêÂá∫‰∏ÄÁßçÂü∫‰∫é‰∏ªÊàêÂàÜÂàÜÊûê(PCA)...
Áø°ËÆæ§á-‰∏ÄÁßçÂü∫‰∫é‰ø°ÊÅØ¢ûÁõäÁéáÁöѱûÊÄßÂäÝÊùÉÊñπÊ≥ïÂèäÊñáÊú¨ÂàÜÁ±ªÊñπÊ≥ï.zip
matlab版的信息增益算法实现
提出了结合情感词典的改进信息增益特征选择方法。首先,针对现有的信息增益特征选择存在注重特征词的文档频率而忽视语料均衡等问题,提出了改进方法。其次,考虑情感词对文本分类的影响,提出了基于情感词典的特征...
ÈíàÂØπÁΩëÁªúÂÖ•‰æµÊ£ÄʵãÊâħÑÁêÜÊï∞ÊçÆÁâπÂæÅÁª¥Êï∞È´ò„ÄÅÂÖ•‰æµÊ£ÄʵãÁ≥ªÁªüË¥üËç∑§߄ÄÅÊ£ÄʵãÈÄüÂ∫¶ÊÖ¢Á≠âÈóÆÈ¢ò,ÊèêÂá∫‰∫܉∏ÄÁßçÂ∞ÜËá™ÈÄÇÂ∫îÈÅó‰ºÝÁÆóÊ≥ï‰∏é‰ø°ÊÅØ¢ûÁõäÁõ∏ÁªìÂêàÁöÑÁâπÂæÅÈÄâÊã©ÊñπÊ≥ï,Âπ∂ÈááÁî®Âü∫‰∫éÊîØÊåÅÂêëÈáèÊú∫ÁöÑÂàÜÁ±ªÂô®‰Ωú‰∏∫Ëá™ÈÄÇÂ∫îÈÅó‰ºÝÁÆóÊ≥ï‰∏≠ÈÄÇÂ∫îÂ∫¶ÂáΩÊï∞ÁöÑËÆ°ÁÆó‰∏é...
ÈÄöËøáÂàÜÊûêÁâπÂæÅËØç‰∏éÁ±ªÂà´Èó¥ÁöÑÁõ∏ÂÖ≥ÊÄß, Âú®ÂéüÊúâÂç°ÊñπÁâπÂæÅÈÄâÊã©Âíå‰ø°ÊÅØ¢ûÁõäÁâπÂæÅÈÄâÊã©ÁöÑÂü∫Á°Ä‰∏äÊèêÂá∫‰∫܉∏§‰∏™ÂèÇÊï∞, ‰ΩøÂæóÈÄâÂá∫...ÈÄöËøáÂÆûÈ™åÂØπÊØÝÁªüÁöÑÂç°ÊñπÁâπÂæÅÈÄâÊã©„Äʼnø°ÊÅØ¢ûÁõäÂíåCCIFÊñπÊ≥ï, CCIFÊñπÊ≥ï‰ΩøÂæóÁÆóÊ≥ïÁöÑÂæÆÂπ≥ÂùáÊü•ÂáÜÁéáÂæóÂà∞‰∫ÜÊòéÊòæÁöÑÊèêÈ´ò„ÄÇ