
-
όοΓϋ┐░
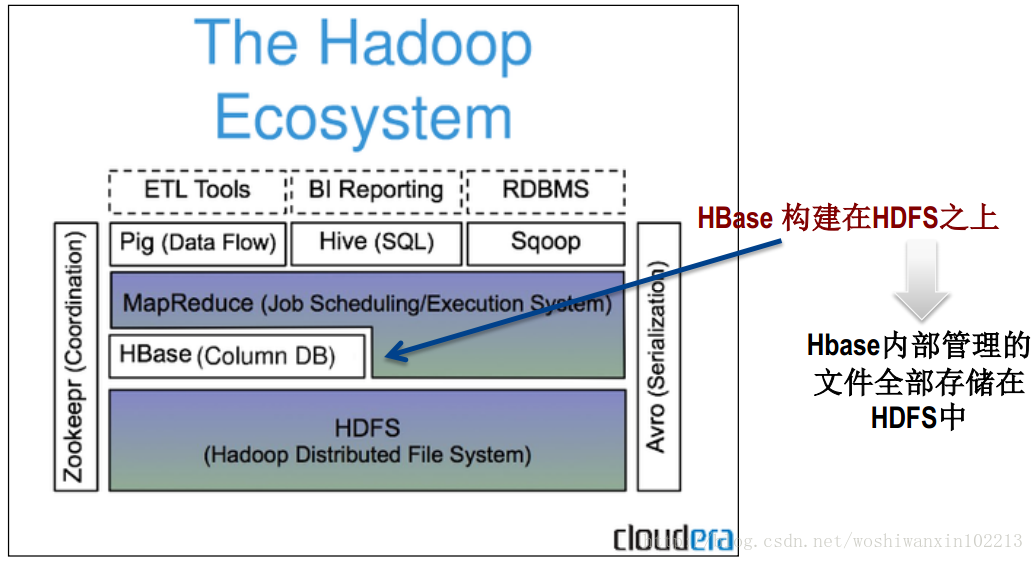
HBaseόαψϊ╕Αϊ╕ςόηΕί╗║ίερHDFSϊ╕ΛύγΕίΙΗί╕Δί╝ΠίΙΩίφαίΓρύ│╗ύ╗θΎ╝δ
HBaseόαψίθ║ϊ║ΟGoogle BigTableόρκίηΜί╝ΑίΠΣύγΕΎ╝ΝίΖ╕ίηΜύγΕkey/valueύ│╗ύ╗θΎ╝δ
HBaseόαψApache HadoopύΦθόΑΒύ│╗ύ╗θϊ╕φύγΕώΘΞϋοΒϊ╕ΑίΣαΎ╝Νϊ╕╗ϋοΒύΦρϊ║Οό╡╖ώΘΠύ╗ΥόηΕίΝΨόΧ░όΞχίφαίΓρΎ╝δ
ϊ╗ΟώΑ╗ϋ╛Σϊ╕Λϋχ▓Ύ╝ΝHBaseί░ΗόΧ░όΞχόΝΚύΖπϋκρήΑΒϋκΝίΤΝίΙΩϋ┐δϋκΝίφαίΓρήΑΓ
ϊ╕Οhadoopϊ╕Αόι╖Ύ╝ΝHbaseύδχόιΘϊ╕╗ϋοΒϊ╛ζώζιόρςίΡΣόΚσί▒ΧΎ╝ΝώΑγϋ┐Θϊ╕ΞόΨφίληίΛιί╗Κϊ╗╖ύγΕίΧΗύΦρόεΞίΛκίβρΎ╝ΝόζξίληίΛιϋχκύχΩίΤΝίφαίΓρϋΔ╜ίΛδήΑΓ
HbaseϋκρύγΕύΚ╣ύΓ╣
ίνπΎ╝γϊ╕Αϊ╕ςϋκρίΠψϊ╗ξόεΚόΧ░ίΞΒϊ║┐ϋκΝΎ╝Νϊ╕Λύβ╛ϊ╕ΘίΙΩΎ╝δ
όΩιόρκί╝ΠΎ╝γόψΠϋκΝώΔ╜όεΚϊ╕Αϊ╕ςίΠψόΟΤί║ΠύγΕϊ╕╗ώΦχίΤΝϊ╗╗όΕΠίνγύγΕίΙΩΎ╝ΝίΙΩίΠψϊ╗ξόι╣όΞχώεΑϋοΒίΛρόΑΒύγΕίληίΛιΎ╝ΝίΡΝϊ╕Αί╝ιϋκρϊ╕φϊ╕ΞίΡΝύγΕϋκΝίΠψϊ╗ξόεΚόΙςύΕ╢ϊ╕ΞίΡΝύγΕίΙΩΎ╝δ
ώζλίΡΣίΙΩΎ╝γώζλίΡΣίΙΩΎ╝ΙόΩΠΎ╝ΚύγΕίφαίΓρίΤΝόζΔώβΡόΟπίΙ╢Ύ╝ΝίΙΩΎ╝ΙόΩΠΎ╝ΚύΜυύτΜόμΑύ┤λΎ╝δ
ύρΑύΨΠΎ╝γύσ║Ύ╝ΙnullΎ╝ΚίΙΩί╣╢ϊ╕ΞίΞιύΦρίφαίΓρύσ║ώΩ┤Ύ╝ΝϋκρίΠψϊ╗ξϋχ╛ϋχκύγΕώζηί╕╕ύρΑύΨΠΎ╝δ
όΧ░όΞχίνγύΚΙόευΎ╝γόψΠϊ╕ςίΞΧίΖΔϊ╕φύγΕόΧ░όΞχίΠψϊ╗ξόεΚίνγϊ╕ςύΚΙόευΎ╝Νώ╗αϋχνόΔΖίΗ╡ϊ╕ΜύΚΙόευίΠ╖ϋΘςίΛρίΙΗώΖΞΎ╝ΝόαψίΞΧίΖΔόι╝όΠΤίΖξόΩ╢ύγΕόΩ╢ώΩ┤όΙ│Ύ╝δ
όΧ░όΞχύ▒╗ίηΜίΞΧϊ╕ΑΎ╝γHbaseϊ╕φύγΕόΧ░όΞχώΔ╜όαψίφΩύυοϊ╕▓Ύ╝Νό▓κόεΚύ▒╗ίηΜήΑΓ
-
HbaseόΧ░όΞχόρκίηΜ
HbaseώΑ╗ϋ╛ΣϋπΗίδ╛
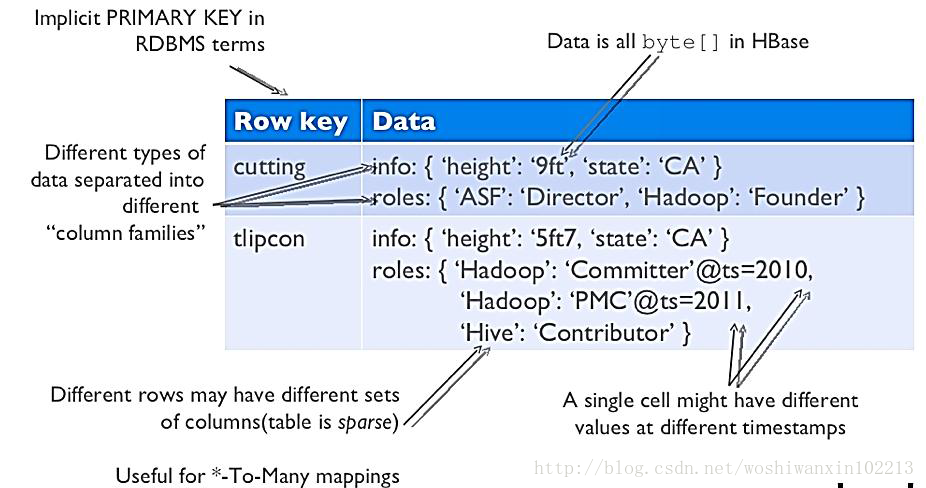
ό│ρόΕΠϊ╕Λίδ╛ϊ╕φύγΕϋΜ▒όΨΘϋψ┤όαΟ
Hbaseίθ║όευόοΓί┐╡
RowKeyΎ╝γόαψByte arrayΎ╝Νόαψϋκρϊ╕φόψΠόζκϋχ░ί╜ΧύγΕέΑεϊ╕╗ώΦχέΑζΎ╝ΝόΨ╣ϊ╛┐ί┐τώΑθόθξόΚ╛Ύ╝ΝRowkeyύγΕϋχ╛ϋχκώζηί╕╕ώΘΞϋοΒήΑΓ
Column FamilyΎ╝γίΙΩόΩΠΎ╝ΝόΜξόεΚϊ╕Αϊ╕ςίΡΞύπ░(string)Ύ╝ΝίΝΖίΡτϊ╕Αϊ╕ςόΙΨϋΑΖίνγϊ╕ςύδ╕ίΖ│ίΙΩ
ColumnΎ╝γί▒ηϊ║ΟόθΡϊ╕Αϊ╕ςcolumnfamilyΎ╝ΝfamilyName:columnNameΎ╝ΝόψΠόζκϋχ░ί╜ΧίΠψίΛρόΑΒό╖╗ίΛι
Version NumberΎ╝γύ▒╗ίηΜϊ╕║LongΎ╝Νώ╗αϋχνίΑ╝όαψύ│╗ύ╗θόΩ╢ώΩ┤όΙ│Ύ╝ΝίΠψύΦ▒ύΦρόΙ╖ϋΘςίχγϊ╣Κ
Value(Cell)Ύ╝γByte array
-
HbaseύΚσύΡΗόρκίηΜ
όψΠϊ╕ςcolumn familyίφαίΓρίερHDFSϊ╕ΛύγΕϊ╕Αϊ╕ςίΞΧύΜυόΨΘϊ╗╢ϊ╕φΎ╝Νύσ║ίΑ╝ϊ╕Ξϊ╝γϋλτϊ┐ζίφαήΑΓ
Key ίΤΝ Version numberίερόψΠϊ╕ς column familyϊ╕φίζΘόεΚϊ╕Αϊ╗╜Ύ╝δ
HBase ϊ╕║όψΠϊ╕ςίΑ╝ύ╗┤όΛνϊ║Ηίνγύ║πύ┤λί╝ΧΎ╝ΝίΞ│Ύ╝γ<key, column family, column name, timestamp>
ύΚσύΡΗίφαίΓρ:
1ήΑΒTableϊ╕φόΚΑόεΚϋκΝώΔ╜όΝΚύΖπrow keyύγΕίφΩίΖ╕ί║ΠόΟΤίΙΩΎ╝δ
2ήΑΒTableίερϋκΝύγΕόΨ╣ίΡΣϊ╕ΛίΙΗίΚ▓ϊ╕║ίνγϊ╕ςRegionΎ╝δ
3ήΑΒRegionόΝΚίνπί░ΠίΙΗίΚ▓ύγΕΎ╝ΝόψΠϊ╕ςϋκρί╝ΑίπΜίΠςόεΚϊ╕Αϊ╕ςregionΎ╝ΝώγΠύζΑόΧ░όΞχίληίνγΎ╝Νregionϊ╕ΞόΨφίληίνπΎ╝Νί╜ΥίληίνπίΙ░ϊ╕Αϊ╕ςώαΑίΑ╝ύγΕόΩ╢ίΑβΎ╝Νregionί░▒ϊ╝γύφΚίΙΗϊ╝γϊ╕νϊ╕ςόΨ░ύγΕregionΎ╝Νϊ╣ΜίΡΟϊ╝γόεΚϋ╢Λόζξϋ╢ΛίνγύγΕregionΎ╝δ
4ήΑΒRegionόαψHbaseϊ╕φίΙΗί╕Δί╝ΠίφαίΓρίΤΝϋ┤θϋ╜╜ίζΘϋκκύγΕόεΑί░ΠίΞΧίΖΔΎ╝Νϊ╕ΞίΡΝRegionίΙΗί╕ΔίΙ░ϊ╕ΞίΡΝRegionServerϊ╕ΛήΑΓ

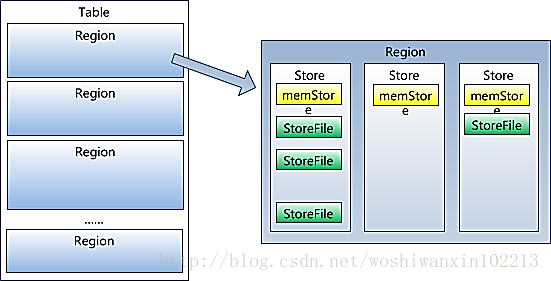
5ήΑΒ Regionϋβ╜ύΕ╢όαψίΙΗί╕Δί╝ΠίφαίΓρύγΕόεΑί░ΠίΞΧίΖΔΎ╝Νϊ╜Ηί╣╢ϊ╕ΞόαψίφαίΓρύγΕόεΑί░ΠίΞΧίΖΔήΑΓRegionύΦ▒ϊ╕Αϊ╕ςόΙΨϋΑΖίνγϊ╕ςStoreύ╗ΕόΙΡΎ╝ΝόψΠϊ╕ςstoreϊ┐ζίφαϊ╕Αϊ╕ςcolumns familyΎ╝δόψΠϊ╕ςStroreίΠΙύΦ▒ϊ╕Αϊ╕ςmemStoreίΤΝ0ϋΘ│ίνγϊ╕ςStoreFileύ╗ΕόΙΡΎ╝ΝStoreFileίΝΖίΡτHFileΎ╝δmemStoreίφαίΓρίερ ίΗΖίφαϊ╕φΎ╝ΝStoreFileίφαίΓρίερHDFSϊ╕ΛήΑΓ
┬ι
-
HBaseόη╢όηΕίΠΛίθ║όευύ╗Εϊ╗╢

Hbaseίθ║όευύ╗Εϊ╗╢ϋψ┤όαΟΎ╝γ
Client
ΎΔ╝ίΝΖίΡτϋχ┐ώΩχHBaseύγΕόΟξίΠμΎ╝Νί╣╢ύ╗┤όΛνcacheόζξίΛιί┐τίψ╣HBaseύγΕϋχ┐ώΩχΎ╝ΝόψΦίοΓregionύγΕϊ╜Ξύ╜χϊ┐κόΒψ
Master
ΎΔ╝ϊ╕║Region serverίΙΗώΖΞregion
ΎΔ╝ϋ┤θϋ┤μRegion serverύγΕϋ┤θϋ╜╜ίζΘϋκκ
ΎΔ╝ίΠΣύΟ░ίν▒όΧΙύγΕRegion serverί╣╢ώΘΞόΨ░ίΙΗώΖΞίΖ╢ϊ╕ΛύγΕregion
ΎΔ╝ύχκύΡΗύΦρόΙ╖ίψ╣tableύγΕίληίΙιόΦ╣όθξόΥΞϊ╜ε
Region Server
ΎΔ╝Regionserverύ╗┤όΛνregionΎ╝ΝίνΕύΡΗίψ╣ϋ┐βϊ║δregionύγΕIOϋψ╖ό▒Γ
ΎΔ╝Regionserverϋ┤θϋ┤μίΙΘίΙΗίερϋ┐ΡϋκΝϋ┐ΘύρΜϊ╕φίΠαί╛Ωϋ┐ΘίνπύγΕregion
Zookeeperϊ╜εύΦρ
ΎΔ╝ώΑγϋ┐ΘώΑΚϊ╕╛Ύ╝Νϊ┐ζϋψΒϊ╗╗ϊ╜ΧόΩ╢ίΑβΎ╝ΝώδΗύ╛νϊ╕φίΠςόεΚϊ╕Αϊ╕ςmasterΎ╝ΝMasterϊ╕ΟRegionServers ίΡψίΛρόΩ╢ϊ╝γίΡΣZooKeeperό│ρίΗΝ
ΎΔ╝ίφαϋ┤χόΚΑόεΚRegionύγΕίψ╗ίζΑίΖξίΠμ
ΎΔ╝ίχηόΩ╢ύδΣόΟπRegion serverύγΕϊ╕Λύ║┐ίΤΝϊ╕Μύ║┐ϊ┐κόΒψήΑΓί╣╢ίχηόΩ╢ώΑγύθξύ╗βMaster
ΎΔ╝ίφαίΓρHBaseύγΕschemaίΤΝtableίΖΔόΧ░όΞχ
ΎΔ╝ώ╗αϋχνόΔΖίΗ╡ϊ╕ΜΎ╝ΝHBase ύχκύΡΗZooKeeper ίχηϊ╛ΜΎ╝ΝόψΦίοΓΎ╝Ν ίΡψίΛρόΙΨϋΑΖίΒεόφλZooKeeper
ΎΔ╝ZookeeperύγΕί╝ΧίΖξϊ╜┐ί╛ΩMasterϊ╕ΞίΗΞόαψίΞΧύΓ╣όΧΖώγε

┬ι
Write-Ahead-LogΎ╝ΙWALΎ╝Κ
┬ι
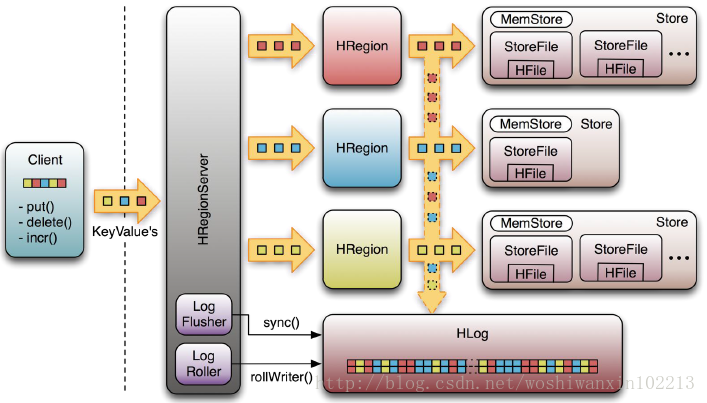
ϋψξόε║ίΙ╢ύΦρϊ║ΟόΧ░όΞχύγΕίχ╣ώΦβίΤΝόΒλίνΞΎ╝γ
όψΠ ϊ╕ςHRegionServerϊ╕φώΔ╜όεΚϊ╕Αϊ╕ςHLogίψ╣ϋ▒κΎ╝ΝHLogόαψϊ╕Αϊ╕ςίχηύΟ░Write Ahead LogύγΕύ▒╗Ύ╝ΝίερόψΠόυκύΦρόΙ╖όΥΞϊ╜είΗβίΖξMemStoreύγΕίΡΝόΩ╢Ύ╝Νϊ╣θϊ╝γίΗβϊ╕Αϊ╗╜όΧ░όΞχίΙ░HLogόΨΘϊ╗╢ϊ╕φΎ╝ΙHLogόΨΘϊ╗╢όι╝ί╝ΠϋπΒίΡΟύ╗φΎ╝ΚΎ╝ΝHLogόΨΘϊ╗╢ίχγόεθϊ╝γό╗γίΛρίΘ║όΨ░ύγΕΎ╝Νί╣╢ ίΙιώβνόΩπύγΕόΨΘϊ╗╢Ύ╝Ιί╖▓όΝΒϊ╣ΖίΝΨίΙ░StoreFileϊ╕φύγΕόΧ░όΞχΎ╝ΚήΑΓί╜ΥHRegionServerόΕΠίνΨύ╗ΙόφλίΡΟΎ╝ΝHMasterϊ╝γώΑγϋ┐ΘZookeeperόΕθύθξ ίΙ░Ύ╝ΝHMasterώοΨίΖΙϊ╝γίνΕύΡΗώΒΩύΧβύγΕ HLogόΨΘϊ╗╢Ύ╝Νί░ΗίΖ╢ϊ╕φϊ╕ΞίΡΝRegionύγΕLogόΧ░όΞχϋ┐δϋκΝόΜΗίΙΗΎ╝ΝίΙΗίΙτόΦ╛ίΙ░ύδ╕ί║ΦregionύγΕύδχί╜Χϊ╕ΜΎ╝ΝύΕ╢ίΡΟίΗΞί░Ηίν▒όΧΙύγΕregionώΘΞόΨ░ίΙΗώΖΞΎ╝ΝώλΗίΠΨ ίΙ░ϋ┐βϊ║δregionύγΕHRegionServerίερLoad RegionύγΕϋ┐ΘύρΜϊ╕φΎ╝Νϊ╝γίΠΣύΟ░όεΚίΟΗίΠ▓HLogώεΑϋοΒίνΕύΡΗΎ╝Νίδιόφνϊ╝γReplay HLogϊ╕φύγΕόΧ░όΞχίΙ░MemStoreϊ╕φΎ╝ΝύΕ╢ίΡΟflushίΙ░StoreFilesΎ╝ΝίχΝόΙΡόΧ░όΞχόΒλίνΞ
┬ι
HBaseίχ╣ώΦβόΑπ
Masterίχ╣ώΦβΎ╝γZookeeperώΘΞόΨ░ώΑΚόΜσϊ╕Αϊ╕ςόΨ░ύγΕMaster
ΎΔ╝όΩιMasterϋ┐ΘύρΜϊ╕φΎ╝ΝόΧ░όΞχϋψ╗ίΠΨϊ╗ΞύΖπί╕╕ϋ┐δϋκΝΎ╝δ
ΎΔ╝όΩιmasterϋ┐ΘύρΜϊ╕φΎ╝ΝregionίΙΘίΙΗήΑΒϋ┤θϋ╜╜ίζΘϋκκύφΚόΩιό│Χϋ┐δϋκΝΎ╝δ
RegionServerίχ╣ώΦβΎ╝γίχγόΩ╢ίΡΣZookeeperό▒ΘόΛξί┐Δϋ╖│Ύ╝ΝίοΓόηεϊ╕ΑόΩοόΩ╢ώΩ┤ίΗΖόεςίΘ║ύΟ░ί┐Δϋ╖│Ύ╝ΝMasterί░ΗϋψξRegionServerϊ╕ΛύγΕRegionώΘΞόΨ░ίΙΗώΖΞίΙ░ίΖ╢ϊ╗ΨRegionServerϊ╕ΛΎ╝Νίν▒όΧΙόεΞίΛκίβρϊ╕ΛέΑεώλΕίΗβέΑζόΩξί┐ΩύΦ▒ϊ╕╗όεΞίΛκίβρϋ┐δϋκΝίΙΗίΚ▓ί╣╢ό┤╛ώΑΒύ╗βόΨ░ύγΕRegionServer
Zookeeperίχ╣ώΦβΎ╝γZookeeperόαψϊ╕Αϊ╕ςίΠψώζιίε░όεΞίΛκΎ╝Νϊ╕ΑϋΙυώΖΞύ╜χ3όΙΨ5ϊ╕ςZookeeperίχηϊ╛Μ
Regionίχγϊ╜Ξό╡ΒύρΜΎ╝γ
ίψ╗όΚ╛RegionServer
ZooKeeper-->┬ι-ROOT-(ίΞΧRegion)-->┬ι.META.-->┬ιύΦρόΙ╖ϋκρ
-ROOT-
ΎΔ╝ϋκρίΝΖίΡτ.META.ϋκρόΚΑίερύγΕregionίΙΩϋκρΎ╝ΝϋψξϋκρίΠςϊ╝γόεΚϊ╕Αϊ╕ςRegionΎ╝δ
ΎΔ╝Zookeeperϊ╕φϋχ░ί╜Χϊ║Η-ROOT-ϋκρύγΕlocationήΑΓ
.META.
ΎΔ╝ϋκρίΝΖίΡτόΚΑόεΚύγΕύΦρόΙ╖ύσ║ώΩ┤regionίΙΩϋκρΎ╝Νϊ╗ξίΠΛRegionServerύγΕόεΞίΛκίβρίε░ίζΑήΑΓ
-
Hbaseϊ╜┐ύΦρίε║όβψ
storing large amounts ┬ιof data(100s of TBs)
need high write throughput
need efficient random access(key lookups) within large data sets
need to scale gracefully with data
for structured and semi-structured data
don't need fullRDMS capabilities(cross row/cross table transaction, joins,etc.)
ίνπόΧ░όΞχώΘΠίφαίΓρΎ╝ΝίνπόΧ░όΞχώΘΠώταί╣╢ίΠΣόΥΞϊ╜ε
ώεΑϋοΒίψ╣όΧ░όΞχώγΠόε║ϋψ╗ίΗβόΥΞϊ╜ε
ϋψ╗ίΗβϋχ┐ώΩχίζΘόαψώζηί╕╕ύχΑίΞΧύγΕόΥΞϊ╜ε
-
Hbaseϊ╕ΟHDFSίψ╣όψΦ
ϊ╕νϋΑΖώΔ╜ίΖ╖όεΚϋΚψίξ╜ύγΕίχ╣ώΦβόΑπίΤΝόΚσί▒ΧόΑπΎ╝ΝώΔ╜ίΠψϊ╗ξόΚσί▒ΧίΙ░όΙΡύβ╛ϊ╕ΛίΞΔϊ╕ςϋΛΓύΓ╣Ύ╝δ
HDFSώΑΓίΡΙόΚ╣ίνΕύΡΗίε║όβψ
ϊ╕ΞόΦψόΝΒόΧ░όΞχώγΠόε║όθξόΚ╛
ϊ╕ΞώΑΓίΡΙίληώΘΠόΧ░όΞχίνΕύΡΗ
ϊ╕ΞόΦψόΝΒόΧ░όΞχόδ┤όΨ░

┬ι
┬ι
http://my.oschina.net/u/923508/blog/393766



ύδ╕ίΖ│όΟρϋΞΡ
ώΑγϋ┐ΘώαΖϋψ╗ήΑΛHbaseόη╢όηΕϋχ╛ϋχκήΑΜϋ┐βόευϊ╣οΎ╝Νϋψ╗ϋΑΖϊ╕Ξϊ╗ΖίΠψϊ╗ξόΟΝόΠκHbaseύγΕίθ║όευόοΓί┐╡ίΤΝόΛΑόεψύ╗ΗϋΛΓΎ╝Νϋ┐αϋΔ╜ίφοϊ╣ιίΙ░ίοΓϊ╜ΧίερίχηώβΖώκ╣ύδχϊ╕φόεΚόΧΙίε░ί║ΦύΦρίΤΝϊ╝αίΝΨHbaseΎ╝Νϊ╗ΟϋΑΝίερίνπόΧ░όΞχίνΕύΡΗώλΗίθθί╗║ύτΜϋ╡╖ίζγίχηύγΕHbaseόΛΑόεψίθ║ύκΑήΑΓϊ╣οϊ╕φύγΕήΑΛHBaseί║ΦύΦρόη╢όηΕ.pdfήΑΜ...
ϋ┐βϊ╗╜"40ώκ╡ύγΕHBaseί║ΦύΦρίε║όβψίΟθύΡΗϊ╕Οίθ║όευόη╢όηΕ"όΨΘόκμΎ╝Νί╛ΙίΠψϋΔ╜όαψίψ╣HBaseύγΕό╖▒ί║οϋπμόηΡΎ╝ΝίΝΖόΜυίΖ╢όι╕ί┐ΔόοΓί┐╡ήΑΒί╖ξϊ╜είΟθύΡΗήΑΒίχηώβΖί║ΦύΦρόκΙϊ╛Μϊ╗ξίΠΛίοΓϊ╜ΧόηΕί╗║ίΤΝόΚσί▒ΧHBaseώδΗύ╛νήΑΓ ώοΨίΖΙΎ╝ΝHBaseύγΕίθ║όευόη╢όηΕύΦ▒Region ServerήΑΒMaster ServerήΑΒ...
### HBaseίΟθύΡΗϊ╕Οϋχ╛ϋχκ #### ϊ╕ΑήΑΒHBaseόοΓϋ┐░ HBaseόαψϊ╕Αϊ╕ςί╝Αό║ΡύγΕήΑΒώταόΑπϋΔ╜ύγΕίΙΗί╕Δί╝ΠίφαίΓρύ│╗ύ╗θΎ╝Νίθ║ϊ║ΟHadoopϊ╣Μϊ╕ΛόηΕί╗║ήΑΓίχΔόΠΡϊ╛δϊ║Ηϊ╕Αϊ╕ςώταί║οίΠψώζιήΑΒώζλίΡΣίΙΩύγΕίφαίΓρόΨ╣όκΙΎ╝ΝώΑΓύΦρϊ║ΟίνΕύΡΗίνπϋπΕόρκύγΕόΧ░όΞχώδΗήΑΓHBaseύγΕϋχ╛ϋχκύΚ╣ύΓ╣ίΝΖόΜυΎ╝γ 1. **ώτα...
ίερό╖▒ίΖξϊ║ΗϋπμHBaseϊ╣ΜίΚΞΎ╝ΝόΙΣϊ╗υίΖΙόζξύΡΗϋπμϊ╕Αϊ╕ΜίχΔύγΕίθ║όευόοΓί┐╡ήΑΓ HBaseόαψόηΕί╗║ίερHadoopόΨΘϊ╗╢ύ│╗ύ╗θΎ╝ΙHDFSΎ╝Κϊ╣Μϊ╕ΛύγΕΎ╝ΝίχΔίΙσύΦρϊ║ΗHadoopύγΕίΙΗί╕Δί╝ΠίφαίΓρϋΔ╜ίΛδήΑΓϋ┐βόΕΠίΣ│ύζΑHBaseύγΕόΧ░όΞχόαψϋ╖ρίνγίΠ░όεΞίΛκίβρίΙΗί╕Δί╝ΠίφαίΓρύγΕΎ╝ΝόΠΡϊ╛δϊ║ΗώταίΠψύΦρόΑπίΤΝίχ╣ώΦβόΑπήΑΓ...
ήΑΛHBaseί║ΦύΦρόη╢όηΕήΑΜϋ┐βόευϊ╣οϊ╝γϋψού╗Ηϋχ▓ϋπμϋ┐βϊ║δόοΓί┐╡Ύ╝Νί╣╢όΠΡϊ╛δίχηϋ╖╡όκΙϊ╛ΜΎ╝Νί╕χίΛσϋψ╗ϋΑΖό╖▒ίΖξύΡΗϋπμίοΓϊ╜Χϋχ╛ϋχκίΤΝύχκύΡΗHBaseώδΗύ╛νΎ╝Νϊ╗ξίΠΛίοΓϊ╜ΧϋπμίΗ│ίχηώβΖώΒΘίΙ░ύγΕώΩχώλαήΑΓώΑγϋ┐ΘώαΖϋψ╗ϋ┐βόευϊ╣οΎ╝Νϋψ╗ϋΑΖίΠψϊ╗ξόΟΝόΠκHBaseύγΕόι╕ί┐ΔίΟθύΡΗίΤΝόεΑϊ╜│ίχηϋ╖╡Ύ╝Νϊ╗ΟϋΑΝίερίνπόΧ░όΞχίνΕύΡΗ...
- **ύυυ1ύτιΎ╝γϊ╗Μύ╗ΞHBase**Ύ╝γόευύτιϊ╗Μύ╗Ξϊ║ΗHBaseύγΕόοΓί┐╡ήΑΒόη╢όηΕϊ╗ξίΠΛϊ╕ΟίΖ╢ϊ╗ΨNoSQLόΧ░όΞχί║ΥύγΕόψΦϋ╛ΔήΑΓόφνίνΨΎ╝Νϋ┐αϋχρϋχ║ϊ║ΗHBaseύγΕόι╕ί┐Δύ╗Εϊ╗╢ίΠΛίΖ╢ίερHadoopύΦθόΑΒύ│╗ύ╗θϊ╕φύγΕϊ╜Ξύ╜χήΑΓ - **ύυυ2ύτιΎ╝γίΖξώΩρόΝΘίΞΩ**Ύ╝γώΑγϋ┐Θϊ╕Αϊ╕ςύχΑίΞΧύγΕϊ╛ΜίφΡόζξί▒Χύν║ίοΓϊ╜ΧίχΚϋμΖ...
ϋ┐βόευϊ╣οό╖▒ίΖξό╡ΖίΘ║ίε░ϊ╗Μύ╗Ξϊ║ΗίΙΗί╕Δί╝ΠόΧ░όΞχί║ΥHBaseύγΕόι╕ί┐ΔόοΓί┐╡ήΑΒϋχ╛ϋχκίΟθύΡΗϊ╗ξίΠΛίχηώβΖί║ΦύΦρΎ╝ΝόΩρίερί╕χίΛσϋψ╗ϋΑΖί┐τώΑθόΟΝόΠκϋ┐βϊ╕Αί╝║ίνπύγΕίνπόΧ░όΞχίφαίΓρύ│╗ύ╗θήΑΓ HBaseΎ╝ΝίΖρύπ░ϊ╕║Apache HBaseΎ╝ΝόαψόηΕί╗║ίερHadoopόΨΘϊ╗╢ύ│╗ύ╗θΎ╝ΙHDFSΎ╝Κϊ╣Μϊ╕ΛύγΕίΙΗί╕Δί╝ΠήΑΒύΚΙόευίΝΨήΑΒ...
HBaseίχαόΨ╣ϊ╕φόΨΘόΨΘόκμόοΓϋ┐░ϊ║ΗApache HBase TMύγΕίθ║όευόοΓί┐╡ήΑΒώΖΞύ╜χόΨ╣ό│ΧήΑΒίΞΘύ║πύφΨύΧξήΑΒshellϊ╜┐ύΦρήΑΒόΧ░όΞχόρκίηΜήΑΒόη╢όηΕϋχ╛ϋχκήΑΒίχΚίΖρόε║ίΙ╢ήΑΒAPIόΟξίΠμήΑΒόΑπϋΔ╜ϋ░Δϊ╝αϊ╗ξίΠΛόΧΖώγεόΟΤώβνύφΚίνγόΨ╣ώζλύγΕύθξϋψΗήΑΓHBaseόαψϊ╕Αϊ╕ςί╝Αό║ΡύγΕώζηίΖ│ύ│╗ίηΜίΙΗί╕Δί╝ΠόΧ░όΞχί║ΥΎ╝ΙNoSQL...
1. HBaseύγΕίθ║όευόοΓί┐╡ίΤΝόη╢όηΕΎ╝γϊ║ΗϋπμHBaseύγΕίΙΗί╕Δί╝ΠίφαίΓρόρκίηΜΎ╝ΝύΡΗϋπμRegionήΑΒRegionServerήΑΒMasterϋΛΓύΓ╣ίΤΝZookeeperύγΕϊ╜εύΦρήΑΓ 2. όΧ░όΞχόρκίηΜΎ╝γύΡΗϋπμϋκΝώΦχήΑΒίΙΩόΩΠήΑΒόΩ╢ώΩ┤όΙ│ίΤΝύΚΙόευύγΕόοΓί┐╡Ύ╝Νίφοϊ╣ιίοΓϊ╜Χϋχ╛ϋχκώταόΧΙύγΕόΧ░όΞχόρκίηΜήΑΓ 3. HBaseόΥΞϊ╜ε...
ϋ┐βόευϊ╣οόΩρίερί╕χίΛσϋψ╗ϋΑΖό╖▒ίΖξύΡΗϋπμHBaseύγΕίΟθύΡΗήΑΒόη╢όηΕϊ╗ξίΠΛίχηώβΖί║ΦύΦρήΑΓ ίερίνπόΧ░όΞχώλΗίθθΎ╝ΝHBaseίδιίΖ╢ώταόΧΙύγΕόΧ░όΞχίνΕύΡΗϋΔ╜ίΛδίΤΝί╝║ίνπύγΕόΚσί▒ΧόΑπϋΑΝίνΘίΠΩώζΤύζΡήΑΓίχΔόΠΡϊ╛δϊ║ΗίχηόΩ╢ϋψ╗ίΗβήΑΒό░┤ί╣│όΚσί▒Χϊ╗ξίΠΛί╝║ϊ╕ΑϋΘ┤όΑπύγΕύΚ╣όΑπΎ╝Νϋ┐βϊ╜┐ί╛ΩHBaseόΙΡϊ╕║ίνΕύΡΗPBύ║πίΙτ...
2. **όη╢όηΕ**Ύ╝γϋψού╗ΗϋπμώΘΛϊ║ΗHBaseύγΕίΙΗί╕Δί╝Πόη╢όηΕΎ╝ΝίΝΖόΜυMasterϋΛΓύΓ╣ήΑΒRegionServerήΑΒRegionήΑΒColumn FamilyύφΚόοΓί┐╡ήΑΓ 3. **όΧ░όΞχόρκίηΜ**Ύ╝γίΙΩόΩΠί╝ΠόΧ░όΞχί║ΥύγΕόΧ░όΞχόρκίηΜϊ╕Οϊ╝ιύ╗θύγΕίΖ│ύ│╗ίηΜόΧ░όΞχί║Υϊ╕ΞίΡΝΎ╝ΝόΨΘόκμϊ╝γϋχ▓ϋπμHBaseύγΕϋκΝήΑΒίΙΩόΩΠήΑΒίΙΩήΑΒ...
ώοΨίΖΙΎ╝ΝόΙΣϊ╗υϊ╗ΟHBaseύγΕίθ║όευόοΓί┐╡ίΤΝίΛθϋΔ╜ίΖξόΚΜήΑΓ HBaseόαψϊ╕Αϊ╕ςίΙΗί╕Δί╝ΠήΑΒίΙΩί╝ΠίφαίΓρύγΕNoSQLόΧ░όΞχί║ΥΎ╝Νίθ║ϊ║ΟGoogleύγΕBigtableϋχ╛ϋχκόΑζόΔ│ί╝ΑίΠΣΎ╝Νϋ┐ΡϋκΝϊ║ΟHadoopϊ╣Μϊ╕ΛήΑΓίχΔόΠΡϊ╛δώταίΠψώζιόΑπήΑΒώταόΑπϋΔ╜ήΑΒίχηόΩ╢ύγΕόΧ░όΞχίφαίΓρίΤΝϋχ┐ώΩχϋΔ╜ίΛδΎ╝ΝύΚ╣ίΙτώΑΓίΡΙίνΕύΡΗ...
ί░νίΖ╢ίψ╣ϊ║ΟίΙζίφοϋΑΖϋΑΝϋρΑΎ╝ΝόΟΝόΠκHBaseύγΕίθ║όευόοΓί┐╡ήΑΒόΥΞϊ╜εϊ╕Οί║ΦύΦρόαψϋΘ│ίΖ│ώΘΞϋοΒύγΕήΑΓόευόΨΘί░Ηϊ╛ζόΞχέΑεhbaseόΧβύρΜέΑζϋ┐βϊ╕Αϊ╕╗ώλαΎ╝Νό╖▒ίΖξό╡ΖίΘ║ίε░ϊ╗Μύ╗ΞHBaseύγΕόι╕ί┐ΔύθξϋψΗΎ╝Νί╕χίΛσίΙζίφοϋΑΖί┐τώΑθίΖξώΩρήΑΓ 1. **HBaseόοΓϋ┐░** HBaseόαψόηΕί╗║ίερHadoopϊ╣Μϊ╕ΛύγΕί╝Αό║Ρ...
1. **HBaseόοΓϋ┐░**Ύ╝γϊ╗Μύ╗ΞHBaseύγΕίθ║όευόοΓί┐╡Ύ╝ΝίοΓίΖ╢ίΙΗί╕Δί╝ΠίφαίΓρόρκίηΜήΑΒϋκρόι╝ύ╗ΥόηΕήΑΒϋκΝώΦχϊ╕ΟίΙΩόΩΠύφΚήΑΓ 2. **όη╢όηΕϋψοϋπμ**Ύ╝γϋψοϋ┐░HRegionServerήΑΒMasterϋΛΓύΓ╣ήΑΒZookeeperύγΕϋπΤϋΚ▓ίΠΛίΖ╢ϊ║νϊ║Τόε║ίΙ╢ήΑΓ 3. **όΧ░όΞχόρκίηΜ**Ύ╝γϋχ▓ϋπμHBaseίοΓϊ╜ΧώΑγϋ┐ΘKey-...
ύΦ▒Shashwat ShriparvόΤ░ίΗβΎ╝Νί╣╢ύΦ▒ίΣρί╜οϊ╝θήΑΒίρΕί╕ΖήΑΒϋΤ▓ϋΒςύ┐╗ϋψΣόΙΡϊ╕φόΨΘΎ╝Νόφνϊ╣οόΩρίερί╕χίΛσϋψ╗ϋΑΖύΡΗϋπμίΤΝόΟΝόΠκHBaseύγΕόι╕ί┐ΔόοΓί┐╡ήΑΒϋχ╛ϋχκίΟθύΡΗϊ╗ξίΠΛίχηώβΖί║ΦύΦρήΑΓ HBaseόαψϊ╕ΑύπΞώζηίΖ│ύ│╗ίηΜόΧ░όΞχί║ΥΎ╝ΙNoSQLΎ╝ΚΎ╝Νίθ║ϊ║ΟGoogleύγΕBigtableόρκίηΜόηΕί╗║Ύ╝ΝίΖ╖ίνΘώτα...
ίερϋ┐βϊ╕ςέΑεhbase_ί╕╕ύΦρώΖΞύ╜χίΠΓόΧ░_ϊ╗ξίΠΛίφοϊ╣ιύυΦϋχ░ϋχ▓ϋπμ_ϊ╗ξίΠΛίΡΕύπΞίΟθύΡΗίδ╛.zipέΑζίΟΜύ╝σίΝΖϊ╕φΎ╝ΝίΝΖίΡτϊ║Ηϊ╕Αύ│╗ίΙΩίΖ│ϊ║ΟHBaseίΖ│ώΦχόοΓί┐╡ήΑΒώΖΞύ╜χίΠΓόΧ░ίΤΝίΟθύΡΗύγΕϋ╡ΕόΨβΎ╝ΝώΑγϋ┐Θϊ╗ξϊ╕ΜίΘιώΔρίΙΗόζξϋψού╗Ηϊ╗Μύ╗Ξϋ┐βϊ║δίΗΖίχ╣Ύ╝γ 1. **HBaseόη╢όηΕίΟθύΡΗ**Ύ╝γ HBaseώΘΘύΦρίΙΩί╝Π...
όευϊ╣οί░Ηί╕οϊ╜ιόΟλύ┤λHBaseύγΕόι╕ί┐ΔόοΓί┐╡ήΑΒόη╢όηΕϊ╗ξίΠΛίερίχηώβΖίε║όβψϊ╕φύγΕί║ΦύΦρήΑΓ ώοΨίΖΙΎ╝ΝόΙΣϊ╗υϊ╗Οίθ║ύκΑί╝ΑίπΜΎ╝Νϊ║ΗϋπμHBaseύγΕίθ║όευόοΓί┐╡ήΑΓHBaseίθ║ϊ║ΟGoogleύγΕBigtableόρκίηΜΎ╝Νϊ╗ξϋκΝίΤΝίΙΩόΩΠϊ╕║όΧ░όΞχύ╗Εύ╗ΘόΨ╣ί╝ΠΎ╝ΝόΠΡϊ╛δϊ║ΗίχηόΩ╢ϋψ╗ίΗβϋΔ╜ίΛδήΑΓίχΔόαψϊ╕Αϊ╕ςώταί║οίΠψόΚσί▒Χ...
ίΖρώζλόΠΠϋ┐░ίνπόΧ░όΞχίΙΩί╝ΠίφαίΓρHBaseύθξϋψΗΎ╝Νό╢╡ύδΨόοΓί┐╡ήΑΒόη╢όηΕήΑΒί╖ξϊ╜είΟθύΡΗήΑΒHbaseϊ╝αίΝΨήΑΒϋψ╗ίΗβό╡ΒύρΜήΑΒύ│╗ύ╗θϊ╝αίΝΨύφΚόΨ╣ώζλήΑΓόευόΑζύ╗┤ίψ╝ίδ╛ίΗΖίχ╣ίΖρώζλΎ╝ΝίΡΝόΩ╢ίψ╣FlushήΑΒcompactionί╖ξϊ╜είΟθύΡΗϋ┐δϋκΝό╖▒ί║οόΑ╗ύ╗ΥήΑΓόαψϊ╕ςώζηί╕╕ϊ╕ΞώΦβύγΕϋ╡Εό║ΡΎ╝Β
ήΑΛϋΩΠύ╗ΠώαΒ-HBaseίθ║όευύθξϋψΗϊ╗Μύ╗ΞίΠΛίΖ╕ίηΜόκΙϊ╛ΜίΙΗόηΡήΑΜόαψϊ╕Αϊ╗╜ό╖▒ίΖξόΟλϋχρHBaseόΛΑόεψύγΕόΨΘόκμΎ╝ΝύΦ▒ώα┐ώΘΝϊ║ΣύγΕίΡ┤ώα│ί╣│Ύ╝ΙόαΟόΔιΎ╝ΚΎ╝Νϊ╕Αϊ╜Ξϋ╡Εό╖▒ύγΕHBaseϊ╕γίΛκόη╢όηΕί╕Ιύ╝ΨόΤ░ήΑΓϋψξόΨΘόκμϊ╕╗ϋοΒό╢╡ύδΨϊ║Ηϊ║Φϊ╕ςόι╕ί┐ΔώΔρίΙΗΎ╝ΝόΩρίερί╕χίΛσϋψ╗ϋΑΖύΡΗϋπμHBaseύγΕίθ║όευύθξϋψΗήΑΒϋψ╗ίΗβ...