paskaa
- µĄÅĶ¦ł: 306183 µ¼Ī
- µĆ¦Õł½:

- µØźĶć¬: õĖŖµĄĘ
-

µ¢ćń½ĀÕłåń▒╗
ńżŠÕī║ńēłÕØŚ
- µłæńÜäĶĄäĶ«» ( 0)
- µłæńÜäĶ«║ÕØø ( 118)
- µłæńÜäķŚ«ńŁö ( 4)
ÕŁśµĪŻÕłåń▒╗
- 2012-07 ( 3)
- 2012-05 ( 3)
- 2012-04 ( 2)
- µø┤ÕżÜÕŁśµĪŻ...
µ£Ćµ¢░Ķ»äĶ«║
-
di1984HIT’╝Ü
õĖŹķöÖ’╝īõĖŹķöÖŃĆé
Jquery.LazyLoad.jsµÅÆõ╗Čõ┐«µŁŻńēłõĖŗĶĮĮ’╝īÕ«×ńÄ░ÕøŠńēćÕ╗ČĶ┐¤ÕŖĀĶĮĮńē╣µĢł -
fncj’╝Ü
ÕźĮõĖ£Ķź┐’╝ī
freemarkerÕĖĖńö©µŖĆÕʦ -
xwy55555’╝Ü
Ķ»┤ÕŠŚÕŠłµĖģµźÜ
Õż¦Õ×ŗńĮæń½ÖµĪåµ×ČńÜäµ╝öÕÅś -
gxz1989611’╝Ü
Ķ┐ÖõĖ¬õĖ£Ķź┐ÕźĮ’╝īµłæĶĮ¼ĶĮĮõ║å~~
40 õĖ¬ĶĮ╗ķćÅń║¦ JavaScript Õ║ō -
gxz1989611’╝Ü
µü®’╝īĶ┐ÖõĖ¬µĀćķóśń£¤µś»ĶĆāĶÖæÕł░õ║åSEOÕĢŖ’╝ü’╝ü’╝ü
Ķ┐ÖµēŹµś»ń£¤µŁŻńÜäJQuery.ajaxõ╝ĀķĆÆõĖŁµ¢ćÕÅéµĢ░ńÜäĶ¦ŻÕå│µ¢╣µ│Ģ
Õż¦Õ×ŗńĮæń½ÖµĪåµ×ČńÜäµ╝öÕÅś
- ÕŹÜÕ«óÕłåń▒╗’╝Ü
- ń│╗ń╗¤µ×ȵ×ä
õ╣ŗÕēŹõ╣¤µ£ēõĖĆõ║øõ╗ŗń╗ŹÕż¦Õ×ŗńĮæń½Öµ×ȵ×äµ╝öÕÅśńÜäµ¢ćń½Ā’╝īõŠŗÕ”éLiveJournalńÜäŃĆüebayńÜä’╝īķāĮµś»ķØ×ÕĖĖÕĆ╝ÕŠŚÕÅéĶĆāńÜä’╝īõĖŹĶ┐ćµä¤Ķ¦ēõ╗¢õ╗¼Ķ«▓ńÜäµø┤ÕżÜńÜ䵜»µ»Åµ¼Īµ╝öÕÅś
ńÜäń╗ōµ×£’╝īĶĆīµ▓Īµ£ēÕŠłĶ»”ń╗åńÜäĶ«▓õĖ║õ╗Ćõ╣łķ£ĆĶ”üÕüÜĶ┐ÖµĀĘńÜäµ╝öÕÅś’╝īÕåŹÕŖĀõĖŖĶ┐æµØźµä¤Ķ¦ēµ£ēõĖŹÕ░æÕÉīÕŁ”ķāĮÕŠłķÜŠµśÄńÖĮõĖ║õ╗Ćõ╣łõĖĆõĖ¬ńĮæń½Öķ£ĆĶ”üķéŻõ╣łÕżŹµØéńÜäµŖƵ£»’╝īõ║ĵś»µ£ēõ║åÕåÖĶ┐Öń»ćµ¢ćń½ĀńÜäµā│µ│Ģ’╝īÕ£©
Ķ┐Öń»ćµ¢ćń½ĀõĖŁ
Õ░åķśÉĶ┐░õĖĆõĖ¬µÖ«ķĆÜńÜäńĮæń½ÖÕÅæÕ▒ĢµłÉÕż¦Õ×ŗńĮæń½ÖĶ┐ćń©ŗõĖŁńÜäõĖĆń¦ŹĶŠāõĖ║ÕģĖÕ×ŗńÜäµ×ȵ×äµ╝öÕÅśÕÄåń©ŗÕÆīµēĆķ£ĆµÄīµÅĪńÜäń¤źĶ»åõĮōń│╗’╝īÕĖīµ£øĶāĮń╗Öµā│õ╗Äõ║ŗõ║ÆĶüöńĮæĶĪīõĖÜńÜäÕÉīÕŁ”õĖĆńé╣ÕłØµŁźńÜäµ”éÕ┐Ą’╝ī:)’╝īµ¢ć
õĖŁńÜäõĖŹÕ»╣õ╣ŗÕżäõ╣¤Ķ»ĘÕÉäõĮŹÕżÜń╗Öńé╣Õ╗║Ķ««’╝īĶ«®µ£¼µ¢ćń£¤µŁŻĶĄĘÕł░µŖøńĀ¢Õ╝ĢńÄēńÜäµĢłµ×£ŃĆé
µ×ȵ×äµ╝öÕÅśń¼¼õĖƵŁź’╝Üńē®ńÉåÕłåń”╗webserverÕÆīµĢ░µŹ«Õ║ō
µ£ĆÕ╝ĆÕ¦ŗ’╝īńö▒õ║ĵ¤Éõ║øµā│µ│Ģ’╝īõ║ĵś»Õ£©õ║ÆĶüöńĮæõĖŖµÉŁÕ╗║õ║åõĖĆõĖ¬ńĮæń½Ö’╝īĶ┐ÖõĖ¬µŚČÕĆÖńöÜĶć│µ£ēÕÅ»ĶāĮõĖ╗µ£║ķāĮµś»ń¦¤ÕƤńÜä’╝īõĮåńö▒õ║ÄĶ┐Öń»ćµ¢ćń½Āµłæõ╗¼ÕŬÕģ│µ│©µ×ȵ×äńÜäµ╝öÕÅśÕÄåń©ŗ’╝īÕøĀµŁżÕ░▒Õüć
Ķ«ŠĶ┐ÖõĖ¬µŚČÕĆÖ
ÕĘ▓ń╗ŵś»µēśń«Īõ║åõĖĆÕÅ░õĖ╗µ£║’╝īÕ╣ČõĖöµ£ēõĖĆÕ«ÜńÜäÕĖ”Õ«Įõ║å’╝īĶ┐ÖõĖ¬µŚČÕĆÖńö▒õ║ÄńĮæń½ÖÕģĘÕżćõ║åõĖĆÕ«ÜńÜäńē╣Ķē▓’╝īÕÉĖÕ╝Ģõ║åķā©Õłåõ║║Ķ«┐ķŚ«’╝īķĆɵĖÉõĮĀÕÅæńÄ░ń│╗ń╗¤ńÜäÕÄŗÕŖøĶČŖµØźĶČŖķ½ś’╝īÕōŹÕ║öķƤÕ║”ĶČŖµØźĶČŖµģó’╝īĶĆī
Ķ┐ÖõĖ¬µŚČÕĆÖµ»öĶŠāµśÄµśŠńÜ䵜»µĢ░µŹ«Õ║ōÕÆīÕ║öńö©õ║ÆńøĖÕĮ▒ÕōŹ’╝īÕ║öńö©Õć║ķŚ«ķóśõ║å’╝īµĢ░µŹ«Õ║ōõ╣¤ÕŠłÕ«╣µśōÕć║ńÄ░ķŚ«ķóś’╝īĶĆīµĢ░µŹ«Õ║ōÕć║ķŚ«ķóśńÜ䵌ČÕĆÖ’╝īÕ║öńö©õ╣¤Õ«╣µśōÕć║ķŚ«ķóś’╝īõ║ĵś»Ķ┐øÕģźõ║åń¼¼õĖƵŁźµ╝öÕÅśķśČ
µ«Ą’╝ÜÕ░åÕ║öńö©ÕÆīµĢ░µŹ«Õ║ōõ╗Äńē®ńÉåõĖŖÕłåń”╗’╝īÕÅśµłÉõ║åõĖżÕÅ░µ£║ÕÖ©’╝īĶ┐ÖõĖ¬µŚČÕĆÖµŖƵ£»õĖŖµ▓Īµ£ēõ╗Ćõ╣łµ¢░ńÜäĶ”üµ▒é’╝īõĮåõĮĀÕÅæńÄ░ńĪ«Õ«×ĶĄĘÕł░µĢłµ×£õ║å’╝īń│╗ń╗¤ÕÅłµüóÕżŹÕł░õ╗źÕēŹńÜäÕōŹÕ║öķƤÕ║”õ║å’╝īÕ╣ČõĖöµö»µÆæõĮÅ
õ║åµø┤ķ½śńÜ䵥üķćÅ’╝īÕ╣ČõĖöõĖŹõ╝ÜÕøĀõĖ║µĢ░µŹ«Õ║ōÕÆīÕ║öńö©ÕĮóµłÉõ║ÆńøĖńÜäÕĮ▒ÕōŹŃĆé
ń£ŗń£ŗĶ┐ÖõĖƵŁźÕ«īµłÉÕÉÄń│╗ń╗¤ńÜäÕøŠńż║’╝Ü
┬Ā
┬Ā
┬Ā
Ķ┐ÖõĖƵŁźµČēÕÅŖÕł░õ║åĶ┐Öõ║øń¤źĶ»åõĮōń│╗’╝Ü
Ķ┐ÖõĖƵŁźµ×ȵ×äµ╝öÕÅśÕ»╣µŖƵ£»õĖŖńÜäń¤źĶ»åõĮōń│╗Õ¤║µ£¼µ▓Īµ£ēĶ”üµ▒éŃĆé
µ×ȵ×äµ╝öÕÅśń¼¼õ║īµŁź’╝ÜÕó×ÕŖĀķĪĄķØóń╝ōÕŁś
ÕźĮµÖ»õĖŹķĢ┐’╝īķÜÅńØĆĶ«┐ķŚ«ńÜäõ║║ĶČŖµØźĶČŖÕżÜ’╝īõĮĀÕÅæńÄ░ÕōŹÕ║öķƤÕ║”ÕÅłÕ╝ĆÕ¦ŗÕÅśµģóõ║å’╝īµ¤źµēŠÕĤÕøĀ’╝īÕÅæńÄ░µś»Ķ«┐ķŚ«µĢ░µŹ«Õ║ōńÜäµōŹõĮ£Õż¬ÕżÜ’╝īÕ»╝Ķć┤µĢ░µŹ«Ķ┐׵ğń½×õ║ēµ┐Ćńāł’╝īµēĆõ╗źÕōŹÕ║öÕÅśµģó’╝ī
õĮåµĢ░µŹ«Õ║ōĶ┐×
µÄźÕÅłõĖŹĶāĮÕ╝ĆÕż¬ÕżÜ’╝īÕÉ”ÕłÖµĢ░µŹ«Õ║ōµ£║ÕÖ©ÕÄŗÕŖøõ╝ÜÕŠłķ½ś’╝īÕøĀµŁżĶĆāĶÖæķććńö©ń╝ōÕŁśµ£║ÕłČµØźÕćÅÕ░æµĢ░µŹ«Õ║ōĶ┐׵ğĶĄäµ║ÉńÜäń½×õ║ēÕÆīÕ»╣µĢ░µŹ«Õ║ōĶ»╗ńÜäÕÄŗÕŖø’╝īĶ┐ÖõĖ¬µŚČÕĆÖķ”¢Õģłõ╣¤Ķ«Ėõ╝ÜķĆēµŗ®ķććńö©squid
ńŁēń▒╗õ╝╝ńÜäµ£║ÕłČµØźÕ░åń│╗ń╗¤õĖŁńøĖÕ»╣ķØÖµĆüńÜäķĪĄķØó’╝łõŠŗÕ”éõĖĆõĖżÕż®µēŹõ╝ܵ£ēµø┤µ¢░ńÜäķĪĄķØó’╝ēĶ┐øĶĪīń╝ōÕŁś’╝łÕĮōńäČ’╝īõ╣¤ÕÅ»õ╗źķććńö©Õ░åķĪĄķØóķØÖµĆüÕī¢ńÜäµ¢╣µĪł’╝ē’╝īĶ┐ÖµĀĘń©ŗÕ║ÅõĖŖÕÅ»õ╗źõĖŹÕüÜõ┐«µö╣’╝īÕ░▒ĶāĮÕż¤
ÕŠłÕźĮńÜäÕćÅÕ░æÕ»╣webserverńÜäÕÄŗÕŖøõ╗źÕÅŖÕćÅÕ░æµĢ░µŹ«Õ║ōĶ┐׵ğĶĄäµ║ÉńÜäń½×õ║ē’╝īOK’╝īõ║ĵś»Õ╝ĆÕ¦ŗķććńö©squidµØźÕüÜńøĖÕ»╣ķØÖµĆüńÜäķĪĄķØóńÜäń╝ōÕŁśŃĆé
ń£ŗń£ŗĶ┐ÖõĖƵŁźÕ«īµłÉÕÉÄń│╗ń╗¤ńÜäÕøŠńż║’╝Ü

┬Ā
Ķ┐ÖõĖƵŁźµČēÕÅŖÕł░õ║åĶ┐Öõ║øń¤źĶ»åõĮōń│╗’╝Ü
ÕēŹń½»ķĪĄķØóń╝ōÕŁśµŖƵ£»’╝īõŠŗÕ”ésquid’╝īÕ”éµā│ńö©ÕźĮńÜäĶ»ØĶ┐śÕŠŚµĘ▒ÕģźµÄīµÅĪõĖŗsquidńÜäÕ«×ńÄ░µ¢╣Õ╝Åõ╗źÕÅŖń╝ōÕŁśńÜäÕż▒µĢłń«Śµ│ĢńŁēŃĆé
┬Ā
µ×ȵ×äµ╝öÕÅśń¼¼õĖēµŁź’╝ÜÕó×ÕŖĀķĪĄķØóńē浫Ąń╝ōÕŁś
Õó×ÕŖĀõ║åsquidÕüÜń╝ōÕŁśÕÉÄ’╝īµĢ┤õĮōń│╗ń╗¤ńÜäķƤÕ║”ńĪ«Õ«×µś»µÅÉÕŹćõ║å’╝īwebserverńÜäÕÄŗÕŖøõ╣¤Õ╝ĆÕ¦ŗõĖŗķÖŹõ║å’╝īõĮåķÜÅńØĆĶ«┐ķŚ«ķćÅńÜäÕó×ÕŖĀ’╝īÕÅæńÄ░ń│╗ń╗¤ÕÅłÕ╝ĆÕ¦ŗÕÅśńÜäµ£ēõ║ø
µģóõ║å’╝īÕ£©Õ░Ø
Õł░õ║åsquidõ╣ŗń▒╗ńÜäÕŖ©µĆüń╝ōÕŁśÕĖ”µØźńÜäÕźĮÕżäÕÉÄ’╝īÕ╝ĆÕ¦ŗµā│ĶāĮõĖŹĶāĮĶ«®ńÄ░Õ£©ķéŻõ║øÕŖ©µĆüķĪĄķØóķćīńøĖÕ»╣ķØÖµĆüńÜäķā©Õłåõ╣¤ń╝ōÕŁśĶĄĘµØźÕæó’╝īÕøĀµŁżĶĆāĶÖæķććńö©ń▒╗õ╝╝ESIõ╣ŗń▒╗ńÜäķĪĄķØóńē浫Ąń╝ōÕŁśńŁ¢
ńĢź’╝īOK’╝īõ║ĵś»Õ╝ĆÕ¦ŗķććńö©ESIµØźÕüÜÕŖ©µĆüķĪĄķØóõĖŁńøĖÕ»╣ķØÖµĆüńÜäńē浫Ąķā©ÕłåńÜäń╝ōÕŁśŃĆé
ń£ŗń£ŗĶ┐ÖõĖƵŁźÕ«īµłÉÕÉÄń│╗ń╗¤ńÜäÕøŠńż║’╝Ü

┬Ā
Ķ┐ÖõĖƵŁźµČēÕÅŖÕł░õ║åĶ┐Öõ║øń¤źĶ»åõĮōń│╗’╝Ü
ķĪĄķØóńē浫Ąń╝ōÕŁśµŖƵ£»’╝īõŠŗÕ”éESIńŁē’╝īµā│ńö©ÕźĮńÜäĶ»ØÕÉīµĀĘķ£ĆĶ”üµÄīµÅĪESIńÜäÕ«×ńÄ░µ¢╣Õ╝ÅńŁē’╝ø
┬Ā
µ×ȵ×äµ╝öÕÅśń¼¼ÕøøµŁź’╝ܵĢ░µŹ«ń╝ōÕŁś
Õ£©ķććńö©ESIõ╣ŗń▒╗ńÜäµŖƵ£»ÕåŹµ¼ĪµÅÉķ½śõ║åń│╗ń╗¤ńÜäń╝ōÕŁśµĢłµ×£ÕÉÄ’╝īń│╗ń╗¤ńÜäÕÄŗÕŖøńĪ«Õ«×Ķ┐øõĖƵŁźķÖŹõĮÄõ║å’╝īõĮåÕÉīµĀĘ’╝īķÜÅńØĆĶ«┐ķŚ«ķćÅńÜäÕó×ÕŖĀ’╝īń│╗ń╗¤Ķ┐śµś»Õ╝ĆÕ¦ŗÕÅśµģó’╝īń╗ÅĶ┐浤źµēŠ’╝īÕÅ»
ĶāĮõ╝ÜÕÅæńÄ░ń│╗
ń╗¤õĖŁÕŁśÕ£©õĖĆõ║øķćŹÕżŹĶÄĘÕÅ¢µĢ░µŹ«õ┐Īµü»ńÜäÕ£░µ¢╣’╝īÕāÅĶÄĘÕÅ¢ńö©µłĘõ┐Īµü»ńŁē’╝īĶ┐ÖõĖ¬µŚČÕĆÖÕ╝ĆÕ¦ŗĶĆāĶÖæµś»õĖŹµś»ÕÅ»õ╗źÕ░åĶ┐Öõ║øµĢ░µŹ«õ┐Īµü»õ╣¤ń╝ōÕŁśĶĄĘµØźÕæó’╝īõ║ĵś»Õ░åĶ┐Öõ║øµĢ░µŹ«ń╝ōÕŁśÕł░µ£¼Õ£░ÕåģÕŁś’╝īµö╣ÕÅśÕ«ī
µ»ĢÕÉÄ’╝īÕ«īÕģ©ń¼”ÕÉłķóäµ£¤’╝īń│╗ń╗¤ńÜäÕōŹÕ║öķƤÕ║”ÕÅłµüóÕżŹõ║å’╝īµĢ░µŹ«Õ║ōńÜäÕÄŗÕŖøõ╣¤ÕåŹÕ║”ķÖŹõĮÄõ║åõĖŹÕ░æŃĆé
ń£ŗń£ŗĶ┐ÖõĖƵŁźÕ«īµłÉÕÉÄń│╗ń╗¤ńÜäÕøŠńż║’╝Ü

┬Ā
Ķ┐ÖõĖƵŁźµČēÕÅŖÕł░õ║åĶ┐Öõ║øń¤źĶ»åõĮōń│╗’╝Ü
ń╝ōÕŁśµŖƵ£»’╝īÕīģµŗ¼ÕāÅMapµĢ░µŹ«ń╗ōµ×äŃĆüń╝ōÕŁśń«Śµ│ĢŃĆüµēĆķĆēńö©ńÜäµĪåµ×ȵ£¼Ķ║½ńÜäÕ«×ńÄ░µ£║ÕłČńŁēŃĆé
┬Ā
µ×ȵ×äµ╝öÕÅśń¼¼õ║öµŁź’╝Ü Õó×ÕŖĀwebserver
ÕźĮµÖ»õĖŹķĢ┐’╝īÕÅæńÄ░ķÜÅńØĆń│╗ń╗¤Ķ«┐ķŚ«ķćÅńÜäÕåŹÕ║”Õó×ÕŖĀ’╝īwebserverµ£║ÕÖ©ńÜäÕÄŗÕŖøÕ£©ķ½śÕ│░µ£¤õ╝ÜõĖŖÕŹćÕł░µ»öĶŠāķ½ś’╝īĶ┐ÖõĖ¬µŚČÕĆÖÕ╝ĆÕ¦ŗĶĆāĶÖæÕó×ÕŖĀõĖĆÕÅ░
webserver’╝īĶ┐Öõ╣¤µś»õĖ║õ║åÕÉīµŚČĶ¦ŻÕå│ÕÅ»ńö©µĆ¦ńÜäķŚ«ķóś’╝īķü┐ÕģŹÕŹĢÕÅ░ńÜäwebserver
downµ£║ńÜäĶ»ØÕ░▒µ▓Īµ│ĢõĮ┐ńö©õ║å’╝īÕ£©ÕüÜõ║åĶ┐Öõ║øĶĆāĶÖæÕÉÄ’╝īÕå│Õ«ÜÕó×ÕŖĀõĖĆÕÅ░webserver’╝īÕó×ÕŖĀõĖĆÕÅ░webserverµŚČ’╝īõ╝Üńó░Õł░õĖĆõ║øķŚ«ķóś’╝īÕģĖÕ×ŗńÜäµ£ē’╝Ü
1ŃĆüÕ”éõĮĢĶ«®Ķ«┐ķŚ«ÕłåķģŹÕł░Ķ┐ÖõĖżÕÅ░µ£║ÕÖ©õĖŖ’╝īĶ┐ÖõĖ¬µŚČÕĆÖķĆÜÕĖĖõ╝ÜĶĆāĶÖæńÜäµ¢╣µĪłµś»ApacheĶć¬ÕĖ”ńÜäĶ┤¤ĶĮĮÕØćĶĪĪµ¢╣µĪł’╝īµł¢LVSĶ┐Öń▒╗ńÜäĶĮ»õ╗ČĶ┤¤ĶĮĮÕØćĶĪĪµ¢╣µĪł’╝ø
2ŃĆüÕ”éõĮĢõ┐صīüńŖȵĆüõ┐Īµü»ńÜäÕÉīµŁź’╝īõŠŗÕ”éńö©µłĘsessionńŁē’╝īĶ┐ÖõĖ¬µŚČÕĆÖõ╝ÜĶĆāĶÖæńÜäµ¢╣µĪłµ£ēÕåÖÕģźµĢ░µŹ«Õ║ōŃĆüÕåÖÕģźÕŁśÕé©ŃĆücookieµł¢ÕÉīµŁźsessionõ┐Īµü»ńŁēµ£║ÕłČńŁē’╝ø
3ŃĆüÕ”éõĮĢõ┐صīüµĢ░µŹ«ń╝ōÕŁśõ┐Īµü»ńÜäÕÉīµŁź’╝īõŠŗÕ”éõ╣ŗÕēŹń╝ōÕŁśńÜäńö©µłĘµĢ░µŹ«ńŁē’╝īĶ┐ÖõĖ¬µŚČÕĆÖķĆÜÕĖĖõ╝ÜĶĆāĶÖæńÜäµ£║ÕłČµ£ēń╝ōÕŁśÕÉīµŁźµł¢ÕłåÕĖāÕ╝Åń╝ōÕŁś’╝ø
4ŃĆüÕ”éõĮĢĶ«®õĖŖõ╝Āµ¢ćõ╗ČĶ┐Öõ║øń▒╗õ╝╝ńÜäÕŖ¤ĶāĮń╗¦ń╗ŁµŁŻÕĖĖ’╝īĶ┐ÖõĖ¬µŚČÕĆÖķĆÜÕĖĖõ╝ÜĶĆāĶÖæńÜäµ£║ÕłČµś»õĮ┐ńö©Õģ▒õ║½µ¢ćõ╗Čń│╗ń╗¤µł¢ÕŁśÕé©ńŁē’╝ø
Õ£©Ķ¦ŻÕå│õ║åĶ┐Öõ║øķŚ«ķóśÕÉÄ’╝īń╗łõ║ĵś»µŖŖwebserverÕó×ÕŖĀõĖ║õ║åõĖżÕÅ░’╝īń│╗ń╗¤ń╗łõ║ĵś»ÕÅłµüóÕżŹÕł░õ║åõ╗źÕŠĆńÜäķƤÕ║”ŃĆé
1ŃĆüÕ”éõĮĢĶ«®Ķ«┐ķŚ«ÕłåķģŹÕł░Ķ┐ÖõĖżÕÅ░µ£║ÕÖ©õĖŖ’╝īĶ┐ÖõĖ¬µŚČÕĆÖķĆÜÕĖĖõ╝ÜĶĆāĶÖæńÜäµ¢╣µĪłµś»ApacheĶć¬ÕĖ”ńÜäĶ┤¤ĶĮĮÕØćĶĪĪµ¢╣µĪł’╝īµł¢LVSĶ┐Öń▒╗ńÜäĶĮ»õ╗ČĶ┤¤ĶĮĮÕØćĶĪĪµ¢╣µĪł’╝ø
2ŃĆüÕ”éõĮĢõ┐صīüńŖȵĆüõ┐Īµü»ńÜäÕÉīµŁź’╝īõŠŗÕ”éńö©µłĘsessionńŁē’╝īĶ┐ÖõĖ¬µŚČÕĆÖõ╝ÜĶĆāĶÖæńÜäµ¢╣µĪłµ£ēÕåÖÕģźµĢ░µŹ«Õ║ōŃĆüÕåÖÕģźÕŁśÕé©ŃĆücookieµł¢ÕÉīµŁźsessionõ┐Īµü»ńŁēµ£║ÕłČńŁē’╝ø
3ŃĆüÕ”éõĮĢõ┐صīüµĢ░µŹ«ń╝ōÕŁśõ┐Īµü»ńÜäÕÉīµŁź’╝īõŠŗÕ”éõ╣ŗÕēŹń╝ōÕŁśńÜäńö©µłĘµĢ░µŹ«ńŁē’╝īĶ┐ÖõĖ¬µŚČÕĆÖķĆÜÕĖĖõ╝ÜĶĆāĶÖæńÜäµ£║ÕłČµ£ēń╝ōÕŁśÕÉīµŁźµł¢ÕłåÕĖāÕ╝Åń╝ōÕŁś’╝ø
4ŃĆüÕ”éõĮĢĶ«®õĖŖõ╝Āµ¢ćõ╗ČĶ┐Öõ║øń▒╗õ╝╝ńÜäÕŖ¤ĶāĮń╗¦ń╗ŁµŁŻÕĖĖ’╝īĶ┐ÖõĖ¬µŚČÕĆÖķĆÜÕĖĖõ╝ÜĶĆāĶÖæńÜäµ£║ÕłČµś»õĮ┐ńö©Õģ▒õ║½µ¢ćõ╗Čń│╗ń╗¤µł¢ÕŁśÕé©ńŁē’╝ø
Õ£©Ķ¦ŻÕå│õ║åĶ┐Öõ║øķŚ«ķóśÕÉÄ’╝īń╗łõ║ĵś»µŖŖwebserverÕó×ÕŖĀõĖ║õ║åõĖżÕÅ░’╝īń│╗ń╗¤ń╗łõ║ĵś»ÕÅłµüóÕżŹÕł░õ║åõ╗źÕŠĆńÜäķƤÕ║”ŃĆé
ń£ŗń£ŗĶ┐ÖõĖƵŁźÕ«īµłÉÕÉÄń│╗ń╗¤ńÜäÕøŠńż║’╝Ü

┬Ā
Ķ┐ÖõĖƵŁźµČēÕÅŖÕł░õ║åĶ┐Öõ║øń¤źĶ»åõĮōń│╗’╝Ü
Ķ┤¤ĶĮĮÕØćĶĪĪµŖƵ£»’╝łÕīģµŗ¼õĮåõĖŹķÖÉõ║ÄńĪ¼õ╗ČĶ┤¤ĶĮĮÕØćĶĪĪŃĆüĶĮ»õ╗ČĶ┤¤ĶĮĮÕØćĶĪĪŃĆüĶ┤¤ĶĮĮń«Śµ│ĢŃĆülinuxĶĮ¼ÕÅæÕŹÅĶ««ŃĆüµēĆķĆēńö©ńÜäµŖƵ£»ńÜäÕ«×ńÄ░ń╗åĶŖéńŁē’╝ēŃĆüõĖ╗ÕżćµŖƵ£»’╝łÕīģµŗ¼õĮåõĖŹķÖÉõ║Ä
ARPµ¼║ķ¬ŚŃĆülinux
heart-beatńŁē’╝ēŃĆüńŖȵĆüõ┐Īµü»µł¢ń╝ōÕŁśÕÉīµŁźµŖƵ£»’╝łÕīģµŗ¼õĮåõĖŹķÖÉõ║ÄCookieµŖƵ£»ŃĆüUDPÕŹÅĶ««ŃĆüńŖȵĆüõ┐Īµü»Õ╣┐µÆŁŃĆüµēĆķĆēńö©ńÜäń╝ōÕŁśÕÉīµŁźµŖƵ£»ńÜäÕ«×ńÄ░ń╗åĶŖéńŁē’╝ēŃĆüÕģ▒
õ║½µ¢ćõ╗ȵŖƵ£»’╝łÕīģµŗ¼õĮåõĖŹķÖÉõ║ÄNFSńŁē’╝ēŃĆüÕŁśÕ驵ŖƵ£»’╝łÕīģµŗ¼õĮåõĖŹķÖÉõ║ÄÕŁśÕé©Ķ«ŠÕżćńŁē’╝ēŃĆé
┬Ā
µ×ȵ×äµ╝öÕÅśń¼¼ÕģŁµŁź’╝ÜÕłåÕ║ō
õ║½ÕÅŚõ║åõĖƵ«ĄµŚČķŚ┤ńÜäń│╗ń╗¤Ķ«┐ķŚ«ķćÅķ½śķƤÕó×ķĢ┐ńÜäÕ╣Ėń”ÅÕÉÄ’╝īÕÅæńÄ░ń│╗ń╗¤ÕÅłÕ╝ĆÕ¦ŗÕÅśµģóõ║å’╝īĶ┐Öµ¼ĪÕÅłµś»õ╗Ćõ╣łńŖČÕåĄÕæó’╝īń╗ÅĶ┐浤źµēŠ’╝īÕÅæńÄ░µĢ░µŹ«Õ║ōÕåÖÕģźŃĆüµø┤µ¢░ńÜäĶ┐Öõ║øµōŹõĮ£ńÜäķā©ÕłåµĢ░
µŹ«Õ║ōĶ┐׵ğńÜä
ĶĄäµ║Éń½×õ║ēķØ×ÕĖĖµ┐Ćńāł’╝īÕ»╝Ķć┤õ║åń│╗ń╗¤ÕÅśµģó’╝īĶ┐ÖõĖŗµĆÄõ╣łÕŖ×Õæó’╝īµŁżµŚČÕÅ»ķĆēńÜäµ¢╣µĪłµ£ēµĢ░µŹ«Õ║ōķøåńŠżÕÆīÕłåÕ║ōńŁ¢ńĢź’╝īķøåńŠżµ¢╣ķØóÕāŵ£ēõ║øµĢ░µŹ«Õ║ōµö»µīüńÜäÕ╣ČõĖŹµś»ÕŠłÕźĮ’╝īÕøĀµŁżÕłåÕ║ōõ╝ܵłÉõĖ║µ»öĶŠāµÖ«
ķüŹńÜäńŁ¢ńĢź’╝īÕłåÕ║ōõ╣¤Õ░▒µäÅÕæ│ńØĆĶ”üÕ»╣ÕĤµ£ēń©ŗÕ║ÅĶ┐øĶĪīõ┐«µö╣’╝īõĖĆķĆÜõ┐«µö╣Õ«×ńÄ░ÕłåÕ║ōÕÉÄ’╝īõĖŹķöÖ’╝īńø«µĀćĶŠŠÕł░õ║å’╝īń│╗ń╗¤µüóÕżŹńöÜĶć│ķƤÕ║”µ»öõ╗źÕēŹĶ┐śÕ┐½õ║åŃĆé
ń£ŗń£ŗĶ┐ÖõĖƵŁźÕ«īµłÉÕÉÄń│╗ń╗¤ńÜäÕøŠńż║’╝Ü
┬Ā
┬Ā
Ķ┐ÖõĖƵŁźµČēÕÅŖÕł░õ║åĶ┐Öõ║øń¤źĶ»åõĮōń│╗’╝Ü
Ķ┐ÖõĖƵŁźµø┤ÕżÜńÜ䵜»ķ£ĆĶ”üõ╗ÄõĖÜÕŖĪõĖŖÕüÜÕÉłńÉåńÜäÕłÆÕłå’╝īõ╗źÕ«×ńÄ░ÕłåÕ║ō’╝īÕģĘõĮōµŖƵ£»ń╗åĶŖéõĖŖµ▓Īµ£ēÕģČõ╗¢ńÜäĶ”üµ▒é’╝ø
õĮåÕÉīµŚČķÜÅńØƵĢ░µŹ«ķćÅńÜäÕó×Õż¦ÕÆīÕłåÕ║ōńÜäĶ┐øĶĪī’╝īÕ£©µĢ░µŹ«Õ║ōńÜäĶ«ŠĶ«ĪŃĆüĶ░āõ╝śõ╗źÕÅŖń╗┤µŖżõĖŖķ£ĆĶ”üÕüÜńÜäµø┤ÕźĮ’╝īÕøĀµŁżÕ»╣Ķ┐Öõ║øµ¢╣ķØóńÜäµŖƵ£»Ķ┐śµś»µÅÉÕć║õ║åÕŠłķ½śńÜäĶ”üµ▒éńÜäŃĆé
┬Ā
µ×ȵ×äµ╝öÕÅśń¼¼õĖāµŁź’╝ÜÕłåĶĪ©ŃĆüDALÕÆīÕłåÕĖāÕ╝Åń╝ōÕŁś
ķÜÅńØĆń│╗ń╗¤ńÜäõĖŹµ¢ŁĶ┐ÉĶĪī’╝īµĢ░µŹ«ķćÅÕ╝ĆÕ¦ŗÕż¦Õ╣ģÕ║”Õó×ķĢ┐’╝īĶ┐ÖõĖ¬µŚČÕĆÖÕÅæ ńÄ░ÕłåÕ║ōÕÉĵ¤źĶ»óõ╗ŹńäČõ╝ܵ£ēõ║øµģó’╝īõ║ĵś»µīēńģ¦ÕłåÕ║ōńÜäµĆصā│Õ╝ĆÕ¦ŗÕüÜÕłåĶĪ©ńÜäÕĘźõĮ£’╝īÕĮōńäČ’╝īĶ┐ÖõĖŹÕÅ»ķü┐ÕģŹńÜäõ╝Üķ£ĆĶ”üÕ»╣ń©ŗÕ║Å Ķ┐øĶĪīõĖĆõ║øõ┐«µö╣’╝īõ╣¤Ķ«ĖÕ£©Ķ┐ÖõĖ¬µŚČÕĆÖÕ░▒õ╝ÜÕÅæńÄ░Õ║öńö©Ķć¬ÕĘ▒Ķ”üÕģ│Õ┐āÕłåÕ║ōÕłåĶĪ©ńÜäĶ¦äÕłÖńŁē’╝īĶ┐śµś»µ£ēõ║øÕżŹµØéńÜä’╝īõ║ĵś»ĶÉīńö¤ĶāĮÕÉ”Õó×ÕŖĀõĖĆõĖ¬ķĆÜńö©ńÜäµĪåµ×ČµØźÕ«×ńÄ░ÕłåÕ║ōÕłåĶĪ©ńÜäµĢ░µŹ«Ķ«┐ķŚ«’╝īĶ┐ÖõĖ¬ Õ£©ebayńÜäµ×ȵ×äõĖŁÕ»╣Õ║öńÜäÕ░▒µś»DAL’╝īĶ┐ÖõĖ¬µ╝öÕÅśńÜäĶ┐ćń©ŗńøĖÕ»╣ĶĆīĶ©Ćķ£ĆĶ”üĶŖ▒Ķ┤╣ĶŠāķĢ┐ńÜ䵌ČķŚ┤’╝īÕĮōńäČ’╝īõ╣¤µ£ēÕÅ»ĶāĮĶ┐ÖõĖ¬ķĆÜńö©ńÜäµĪåµ×Čõ╝ÜńŁēÕł░ÕłåĶĪ©ÕüÜÕ«īÕÉĵēŹÕ╝ĆÕ¦ŗÕüÜ’╝īÕÉīµŚČ’╝īÕ£©Ķ┐ÖõĖ¬ ķśČµ«ĄÕÅ» ĶāĮõ╝ÜÕÅæńÄ░õ╣ŗÕēŹńÜäń╝ōÕŁśÕÉīµŁźµ¢╣µĪłÕć║ńÄ░ķŚ«ķóś’╝īÕøĀõĖ║µĢ░µŹ«ķćÅÕż¬Õż¦’╝īÕ»╝Ķć┤ńÄ░Õ£©õĖŹÕż¬ÕÅ»ĶāĮÕ░åń╝ōÕŁśÕŁśÕ£©µ£¼Õ£░’╝īńäČÕÉÄÕÉīµŁźńÜäµ¢╣Õ╝Å’╝īķ£ĆĶ”üķććńö©ÕłåÕĖāÕ╝Åń╝ōÕŁśµ¢╣µĪłõ║å’╝īõ║ĵś»’╝īÕÅłµś»õĖĆķĆÜĶĆāÕ»¤ ÕÆīµŖśńŻ©’╝īń╗łõ║ĵś»Õ░åÕż¦ķćÅńÜäµĢ░µŹ«ń╝ōÕŁśĶĮ¼ń¦╗Õł░ÕłåÕĖāÕ╝Åń╝ōÕŁśõĖŖõ║åŃĆé
ķÜÅńØĆń│╗ń╗¤ńÜäõĖŹµ¢ŁĶ┐ÉĶĪī’╝īµĢ░µŹ«ķćÅÕ╝ĆÕ¦ŗÕż¦Õ╣ģÕ║”Õó×ķĢ┐’╝īĶ┐ÖõĖ¬µŚČÕĆÖÕÅæ ńÄ░ÕłåÕ║ōÕÉĵ¤źĶ»óõ╗ŹńäČõ╝ܵ£ēõ║øµģó’╝īõ║ĵś»µīēńģ¦ÕłåÕ║ōńÜäµĆصā│Õ╝ĆÕ¦ŗÕüÜÕłåĶĪ©ńÜäÕĘźõĮ£’╝īÕĮōńäČ’╝īĶ┐ÖõĖŹÕÅ»ķü┐ÕģŹńÜäõ╝Üķ£ĆĶ”üÕ»╣ń©ŗÕ║Å Ķ┐øĶĪīõĖĆõ║øõ┐«µö╣’╝īõ╣¤Ķ«ĖÕ£©Ķ┐ÖõĖ¬µŚČÕĆÖÕ░▒õ╝ÜÕÅæńÄ░Õ║öńö©Ķć¬ÕĘ▒Ķ”üÕģ│Õ┐āÕłåÕ║ōÕłåĶĪ©ńÜäĶ¦äÕłÖńŁē’╝īĶ┐śµś»µ£ēõ║øÕżŹµØéńÜä’╝īõ║ĵś»ĶÉīńö¤ĶāĮÕÉ”Õó×ÕŖĀõĖĆõĖ¬ķĆÜńö©ńÜäµĪåµ×ČµØźÕ«×ńÄ░ÕłåÕ║ōÕłåĶĪ©ńÜäµĢ░µŹ«Ķ«┐ķŚ«’╝īĶ┐ÖõĖ¬ Õ£©ebayńÜäµ×ȵ×äõĖŁÕ»╣Õ║öńÜäÕ░▒µś»DAL’╝īĶ┐ÖõĖ¬µ╝öÕÅśńÜäĶ┐ćń©ŗńøĖÕ»╣ĶĆīĶ©Ćķ£ĆĶ”üĶŖ▒Ķ┤╣ĶŠāķĢ┐ńÜ䵌ČķŚ┤’╝īÕĮōńäČ’╝īõ╣¤µ£ēÕÅ»ĶāĮĶ┐ÖõĖ¬ķĆÜńö©ńÜäµĪåµ×Čõ╝ÜńŁēÕł░ÕłåĶĪ©ÕüÜÕ«īÕÉĵēŹÕ╝ĆÕ¦ŗÕüÜ’╝īÕÉīµŚČ’╝īÕ£©Ķ┐ÖõĖ¬ ķśČµ«ĄÕÅ» ĶāĮõ╝ÜÕÅæńÄ░õ╣ŗÕēŹńÜäń╝ōÕŁśÕÉīµŁźµ¢╣µĪłÕć║ńÄ░ķŚ«ķóś’╝īÕøĀõĖ║µĢ░µŹ«ķćÅÕż¬Õż¦’╝īÕ»╝Ķć┤ńÄ░Õ£©õĖŹÕż¬ÕÅ»ĶāĮÕ░åń╝ōÕŁśÕŁśÕ£©µ£¼Õ£░’╝īńäČÕÉÄÕÉīµŁźńÜäµ¢╣Õ╝Å’╝īķ£ĆĶ”üķććńö©ÕłåÕĖāÕ╝Åń╝ōÕŁśµ¢╣µĪłõ║å’╝īõ║ĵś»’╝īÕÅłµś»õĖĆķĆÜĶĆāÕ»¤ ÕÆīµŖśńŻ©’╝īń╗łõ║ĵś»Õ░åÕż¦ķćÅńÜäµĢ░µŹ«ń╝ōÕŁśĶĮ¼ń¦╗Õł░ÕłåÕĖāÕ╝Åń╝ōÕŁśõĖŖõ║åŃĆé
ń£ŗń£ŗĶ┐ÖõĖƵŁźÕ«īµłÉÕÉÄń│╗ń╗¤ńÜäÕøŠńż║’╝Ü
┬Ā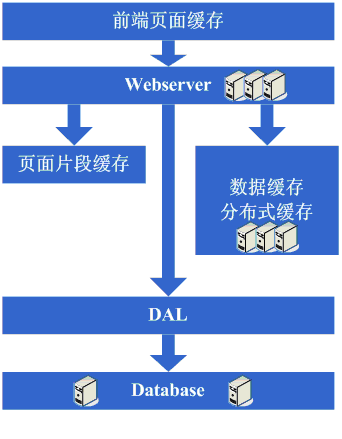
┬Ā
Ķ┐ÖõĖƵŁźµČēÕÅŖÕł░õ║åĶ┐Öõ║øń¤źĶ»åõĮōń│╗’╝Ü
ÕłåĶĪ©µø┤ÕżÜńÜäÕÉīµĀʵś»õĖÜÕŖĪõĖŖńÜäÕłÆÕłå’╝īµŖƵ£»õĖŖµČēÕÅŖÕł░ńÜäõ╝ܵ£ēÕŖ©µĆühashń«Śµ│ĢŃĆüconsistent hashń«Śµ│ĢńŁē’╝ø
DALµČēÕÅŖÕł░µ»öĶŠāÕżÜńÜäÕżŹµØéµŖƵ£»’╝īõŠŗÕ”éµĢ░µŹ«Õ║ōĶ┐׵ğńÜäń«ĪńÉå’╝łĶČģµŚČŃĆüÕ╝éÕĖĖ’╝ēŃĆüµĢ░µŹ«Õ║ōµōŹõĮ£ńÜäµÄ¦ÕłČ’╝łĶČģµŚČŃĆüÕ╝éÕĖĖ’╝ēŃĆüÕłåÕ║ōÕłåĶĪ©Ķ¦äÕłÖńÜäÕ░üĶŻģńŁē’╝ø
┬Ā
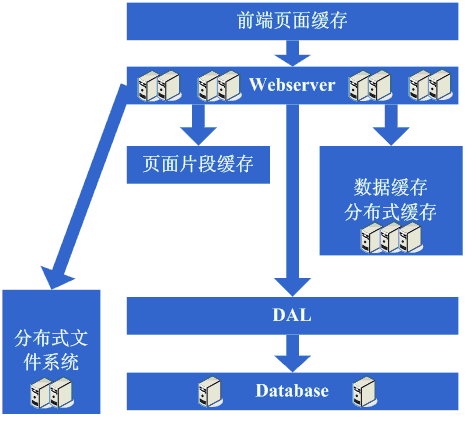
µ×ȵ×äµ╝öÕÅśń¼¼Õģ½µŁź’╝ÜÕó×ÕŖĀµø┤ÕżÜńÜäwebserver
Õ£©ÕüÜÕ«īÕłåÕ║ōÕłåĶĪ©Ķ┐Öõ║øÕĘźõĮ£ÕÉÄ’╝īµĢ░µŹ«Õ║ōõĖŖńÜäÕÄŗÕŖøÕĘ▓ń╗ÅķÖŹÕł░µ»öĶŠāõĮÄõ║å’╝īÕÅłÕ╝ĆÕ¦ŗĶ┐ćńØƵ»ÅÕż®ń£ŗńØĆĶ«┐ķŚ«ķćŵÜ┤Õó×ńÜäÕ╣Ėń”Åńö¤µ┤╗õ║å’╝īń¬üńäȵ£ēõĖĆÕż®’╝īÕÅæńÄ░ń│╗ń╗¤ńÜäĶ«┐ķŚ«ÕÅłÕ╝ĆÕ¦ŗµ£ē
ÕÅśµģóńÜäĶČŗÕŖ┐
õ║å’╝īĶ┐ÖõĖ¬µŚČÕĆÖķ”¢Õģłµ¤źń£ŗµĢ░µŹ«Õ║ō’╝īÕÄŗÕŖøõĖĆÕłćµŁŻÕĖĖ’╝īõ╣ŗÕÉĵ¤źń£ŗwebserver’╝īÕÅæńÄ░apacheķś╗ÕĪ×õ║åÕŠłÕżÜńÜäĶ»Ęµ▒é’╝īĶĆīÕ║öńö©µ£ŹÕŖĪÕÖ©Õ»╣µ»ÅõĖ¬Ķ»Ęµ▒éõ╣¤µś»µ»öĶŠāÕ┐½ńÜä’╝īń£ŗµØź
µś»Ķ»Ęµ▒éµĢ░Õż¬ķ½śÕ»╝Ķć┤ķ£ĆĶ”üµÄÆķś¤ńŁēÕŠģ’╝īÕōŹÕ║öķƤÕ║”ÕÅśµģó’╝īĶ┐ÖĶ┐śÕźĮÕŖ×’╝īõĖĆĶł¼µØźĶ»┤’╝īĶ┐ÖõĖ¬µŚČÕĆÖõ╣¤õ╝ܵ£ēõ║øķÆ▒õ║å’╝īõ║ĵś»µĘ╗ÕŖĀõĖĆõ║øwebserverµ£ŹÕŖĪÕÖ©’╝īÕ£©Ķ┐ÖõĖ¬µĘ╗ÕŖĀ
webserverµ£ŹÕŖĪÕÖ©ńÜäĶ┐ćń©ŗ’╝īµ£ēÕÅ»ĶāĮõ╝ÜÕć║ńÄ░ÕćĀń¦Źµīæµłś’╝Ü
1ŃĆüApacheńÜäĶĮ»Ķ┤¤ĶĮĮµł¢LVSĶĮ»Ķ┤¤ĶĮĮńŁēµŚĀµ│Ģµē┐µŗģÕĘ©Õż¦ńÜäwebĶ«┐ķŚ«ķćÅ’╝łĶ»Ęµ▒éĶ┐׵ğµĢ░ŃĆüńĮæ ń╗£µĄüķćÅńŁē’╝ēńÜäĶ░āÕ║”õ║å’╝īĶ┐ÖõĖ¬µŚČÕĆÖÕ”éµ×£ń╗ÅĶ┤╣ÕģüĶ«ĖńÜäĶ»Ø’╝īõ╝ÜķććÕÅ¢ńÜäµ¢╣µĪłµś»Ķ┤Ł õ╣░ńĪ¼õ╗ČĶ┤¤ĶĮĮ’╝īõŠŗÕ”éF5ŃĆüNetsclarŃĆüAthelonõ╣ŗń▒╗ńÜä’╝īÕ”éń╗ÅĶ┤╣õĖŹÕģüĶ«ĖńÜäĶ»Ø’╝īõ╝ÜķććÕÅ¢ńÜäµ¢╣µĪłµś»Õ░åÕ║öńö©õ╗ÄķĆ╗ĶŠæõĖŖÕüÜõĖĆÕ«ÜńÜäÕłåń▒╗’╝īńäČÕÉÄÕłåµĢŻÕł░õĖŹÕÉīńÜäĶĮ»Ķ┤¤ĶĮĮ ķøåńŠżõĖŁ’╝ø
2ŃĆüÕĤµ£ēńÜäõĖĆõ║øńŖȵĆüõ┐Īµü»ÕÉīµŁźŃĆüµ¢ćõ╗ČÕģ▒õ║½ńŁēµ¢╣µĪłÕÅ»ĶāĮõ╝ÜÕć║ńÄ░ńōČķół’╝īķ£ĆĶ”üĶ┐øĶĪīµö╣Ķ┐ø’╝īõ╣¤Ķ«ĖĶ┐ÖõĖ¬µŚČÕĆÖõ╝ܵĀ╣µŹ«µāģÕåĄń╝¢ÕåÖń¼”ÕÉłńĮæń½ÖõĖÜÕŖĪķ£Ćµ▒éńÜäÕłåÕĖāÕ╝ŵ¢ćõ╗Čń│╗ń╗¤ńŁē’╝ø
Õ£©ÕüÜÕ«īĶ┐Öõ║øÕĘźõĮ£ÕÉÄ’╝īÕ╝ĆÕ¦ŗĶ┐øÕģźõĖĆõĖ¬ń£ŗõ╝╝Õ«īńŠÄńÜ䵌ĀķÖÉõ╝Ėń╝®ńÜ䵌Čõ╗Ż’╝īÕĮōńĮæń½ÖµĄüķćÅÕó×ÕŖĀµŚČ’╝īÕ║öÕ»╣ńÜäĶ¦ŻÕå│µ¢╣µĪłÕ░▒µś»õĖŹµ¢ŁńÜäµĘ╗ÕŖĀwebserverŃĆé
1ŃĆüApacheńÜäĶĮ»Ķ┤¤ĶĮĮµł¢LVSĶĮ»Ķ┤¤ĶĮĮńŁēµŚĀµ│Ģµē┐µŗģÕĘ©Õż¦ńÜäwebĶ«┐ķŚ«ķćÅ’╝łĶ»Ęµ▒éĶ┐׵ğµĢ░ŃĆüńĮæ ń╗£µĄüķćÅńŁē’╝ēńÜäĶ░āÕ║”õ║å’╝īĶ┐ÖõĖ¬µŚČÕĆÖÕ”éµ×£ń╗ÅĶ┤╣ÕģüĶ«ĖńÜäĶ»Ø’╝īõ╝ÜķććÕÅ¢ńÜäµ¢╣µĪłµś»Ķ┤Ł õ╣░ńĪ¼õ╗ČĶ┤¤ĶĮĮ’╝īõŠŗÕ”éF5ŃĆüNetsclarŃĆüAthelonõ╣ŗń▒╗ńÜä’╝īÕ”éń╗ÅĶ┤╣õĖŹÕģüĶ«ĖńÜäĶ»Ø’╝īõ╝ÜķććÕÅ¢ńÜäµ¢╣µĪłµś»Õ░åÕ║öńö©õ╗ÄķĆ╗ĶŠæõĖŖÕüÜõĖĆÕ«ÜńÜäÕłåń▒╗’╝īńäČÕÉÄÕłåµĢŻÕł░õĖŹÕÉīńÜäĶĮ»Ķ┤¤ĶĮĮ ķøåńŠżõĖŁ’╝ø
2ŃĆüÕĤµ£ēńÜäõĖĆõ║øńŖȵĆüõ┐Īµü»ÕÉīµŁźŃĆüµ¢ćõ╗ČÕģ▒õ║½ńŁēµ¢╣µĪłÕÅ»ĶāĮõ╝ÜÕć║ńÄ░ńōČķół’╝īķ£ĆĶ”üĶ┐øĶĪīµö╣Ķ┐ø’╝īõ╣¤Ķ«ĖĶ┐ÖõĖ¬µŚČÕĆÖõ╝ܵĀ╣µŹ«µāģÕåĄń╝¢ÕåÖń¼”ÕÉłńĮæń½ÖõĖÜÕŖĪķ£Ćµ▒éńÜäÕłåÕĖāÕ╝ŵ¢ćõ╗Čń│╗ń╗¤ńŁē’╝ø
Õ£©ÕüÜÕ«īĶ┐Öõ║øÕĘźõĮ£ÕÉÄ’╝īÕ╝ĆÕ¦ŗĶ┐øÕģźõĖĆõĖ¬ń£ŗõ╝╝Õ«īńŠÄńÜ䵌ĀķÖÉõ╝Ėń╝®ńÜ䵌Čõ╗Ż’╝īÕĮōńĮæń½ÖµĄüķćÅÕó×ÕŖĀµŚČ’╝īÕ║öÕ»╣ńÜäĶ¦ŻÕå│µ¢╣µĪłÕ░▒µś»õĖŹµ¢ŁńÜäµĘ╗ÕŖĀwebserverŃĆé
ń£ŗń£ŗĶ┐ÖõĖƵŁźÕ«īµłÉÕÉÄń│╗ń╗¤ńÜäÕøŠńż║’╝Ü
┬Ā
Ķ┐ÖõĖƵŁźµČēÕÅŖÕł░õ║åĶ┐Öõ║øń¤źĶ»åõĮōń│╗’╝Ü
Õł░õ║åĶ┐ÖõĖƵŁź’╝īķÜÅńØƵ£║ÕÖ©µĢ░ńÜäõĖŹµ¢ŁÕó×ķĢ┐ŃĆüµĢ░µŹ«ķćÅńÜäõĖŹµ¢ŁÕó×ķĢ┐ÕÆīÕ»╣ń│╗ń╗¤ÕÅ»ńö©µĆ¦ńÜäĶ”üµ▒éĶČŖµØźĶČŖķ½ś’╝īĶ┐ÖõĖ¬µŚČÕĆÖĶ”üµ▒éÕ»╣µēĆķććńö©ńÜäµŖƵ£»ķāĮĶ”üµ£ēµø┤õĖ║µĘ▒ÕģźńÜäńÉåĶ¦Ż’╝īÕ╣Čķ£ĆĶ”üµĀ╣µŹ«ńĮæń½ÖńÜäķ£Ćµ▒éµØźÕüܵø┤ÕŖĀÕ«ÜÕłČµĆ¦Ķ┤©ńÜäõ║¦ÕōüŃĆé
┬Ā
µ×ȵ×äµ╝öÕÅśń¼¼õ╣صŁź’╝ܵĢ░µŹ«Ķ»╗ÕåÖÕłåń”╗ÕÆīÕ╗ēõ╗ĘÕŁśÕ驵¢╣µĪł
ń¬üńäȵ£ēõĖĆÕż®’╝īÕÅæńÄ░Ķ┐ÖõĖ¬Õ«īńŠÄńÜ䵌Čõ╗Żõ╣¤Ķ”üń╗ōµØ¤õ║å’╝īµĢ░µŹ«Õ║ōńÜäÕÖ®µó”ÕÅłõĖƵ¼ĪÕć║ńÄ░Õ£©ń£╝ÕēŹõ║å’╝īńö▒õ║ĵĘ╗ÕŖĀńÜäwebserverÕż¬ÕżÜõ║å’╝īÕ»╝Ķć┤µĢ░µŹ«Õ║ōĶ┐׵ğńÜäĶĄäµ║ÉĶ┐śµś»
õĖŹÕż¤ńö©’╝īĶĆīĶ┐ÖõĖ¬µŚČÕĆÖÕÅłÕĘ▓ń╗ÅÕłåÕ║ōÕłåĶĪ©õ║å’╝īÕ╝ĆÕ¦ŗÕłåµ×ɵĢ░µŹ«Õ║ōńÜäÕÄŗÕŖøńŖČÕåĄ’╝īÕÅ»ĶāĮõ╝ÜÕÅæńÄ░µĢ░µŹ«Õ║ōńÜäĶ»╗ÕåÖµ»öÕŠłķ½ś’╝īĶ┐ÖõĖ¬µŚČÕĆÖķĆÜÕĖĖõ╝ܵā│Õł░µĢ░µŹ«Ķ»╗ÕåÖÕłåń”╗ńÜäµ¢╣µĪł’╝īÕĮōńäČ’╝īĶ┐ÖõĖ¬µ¢╣µĪł
Ķ”üÕ«×ńÄ░Õ╣ČõĖŹ
Õ«╣µśō’╝īÕÅ”Õż¢’╝īÕÅ»ĶāĮõ╝ÜÕÅæńÄ░õĖĆõ║øµĢ░µŹ«ÕŁśÕé©Õ£©µĢ░µŹ«Õ║ōõĖŖµ£ēõ║øµĄ¬Ķ┤╣’╝īµł¢ĶĆģĶ»┤Ķ┐ćõ║ÄÕŹĀńö©µĢ░µŹ«Õ║ōĶĄäµ║É’╝īÕøĀµŁżÕ£©Ķ┐ÖõĖ¬ķśČµ«ĄÕÅ»ĶāĮõ╝ÜÕĮóµłÉńÜäµ×ȵ×äµ╝öÕÅśµś»Õ«×ńÄ░µĢ░µŹ«Ķ»╗ÕåÖÕłåń”╗’╝īÕÉīµŚČń╝¢ÕåÖõĖĆ
õ║øµø┤õĖ║Õ╗ēõ╗ĘńÜäÕŁśÕ驵¢╣µĪł’╝īõŠŗÕ”éBigTableĶ┐Öń¦ŹŃĆé
ń£ŗń£ŗĶ┐ÖõĖƵŁźÕ«īµłÉÕÉÄń│╗ń╗¤ńÜäÕøŠńż║’╝Ü

┬Ā
Ķ┐ÖõĖƵŁźµČēÕÅŖÕł░õ║åĶ┐Öõ║øń¤źĶ»åõĮōń│╗’╝Ü
µĢ░µŹ«Ķ»╗ÕåÖÕłåń”╗Ķ”üµ▒éÕ»╣µĢ░µŹ«Õ║ōńÜäÕżŹÕłČŃĆüstandbyńŁēńŁ¢ńĢźµ£ēµĘ▒ÕģźńÜäµÄīµÅĪÕÆīńÉåĶ¦Ż’╝īÕÉīµŚČõ╝ÜĶ”üµ▒éÕģĘÕżćĶć¬ĶĪīÕ«×ńÄ░ńÜäµŖƵ£»’╝ø
Õ╗ēõ╗ĘÕŁśÕ驵¢╣µĪłĶ”üµ▒éÕ»╣OSńÜäµ¢ćõ╗ČÕŁśÕ驵£ēµĘ▒ÕģźńÜäµÄīµÅĪÕÆīńÉåĶ¦Ż’╝īÕÉīµŚČĶ”üµ▒éÕ»╣ķććńö©ńÜäĶ»ŁĶ©ĆÕ£©µ¢ćõ╗ČĶ┐ÖÕØŚńÜäÕ«×ńÄ░µ£ēµĘ▒ÕģźńÜäµÄīµÅĪŃĆé
┬Ā
µ×ȵ×äµ╝öÕÅśń¼¼ÕŹüµŁź’╝ÜĶ┐øÕģźÕż¦Õ×ŗÕłåÕĖāÕ╝ÅÕ║öńö©µŚČõ╗ŻÕÆīÕ╗ēõ╗ʵ£ŹÕŖĪÕÖ©ńŠżµó”µā│µŚČõ╗Ż
ń╗ÅĶ┐ćõĖŖķØóĶ┐ÖõĖ¬µ╝½ķĢ┐ĶĆīńŚøĶŗ”ńÜäĶ┐ćń©ŗ’╝īń╗łõ║ĵś»ÕåŹÕ║”Ķ┐ÄµØźõ║åÕ«īńŠÄńÜ䵌Čõ╗Ż’╝īõĖŹµ¢ŁńÜäÕó×ÕŖĀwebserverÕ░▒ÕÅ»õ╗źµö»µÆæĶČŖµØźĶČŖķ½śńÜäĶ«┐ķŚ«ķćÅõ║å’╝īÕ»╣õ║ÄÕż¦Õ×ŗńĮæń½ÖĶĆīĶ©Ć’╝ī
õ║║µ░öńÜäķćŹĶ”üµ»ŗ
Õ║ĖńĮ«ń¢æ’╝īķÜÅńØĆõ║║µ░öńÜäĶČŖµØźĶČŖķ½ś’╝īÕÉäń¦ŹÕÉäµĀĘńÜäÕŖ¤ĶāĮķ£Ćµ▒éõ╣¤Õ╝ĆÕ¦ŗńłåÕÅæµĆ¦ńÜäÕó×ķĢ┐’╝īĶ┐ÖõĖ¬µŚČÕĆÖń¬üńäČÕÅæńÄ░’╝īÕĤµØźķā©ńĮ▓Õ£©webserverõĖŖńÜäķéŻõĖ¬webÕ║öńö©ÕĘ▓ń╗ÅķØ×ÕĖĖÕ║×Õż¦
õ║å’╝īÕĮōÕżÜõĖ¬Õøóķś¤ķāĮÕ╝ĆÕ¦ŗÕ»╣ÕģČĶ┐øĶĪīµö╣ÕŖ©µŚČ’╝īÕÅ»ń£¤µś»ńøĖÕĮōńÜäõĖŹµ¢╣õŠ┐’╝īÕżŹńö©µĆ¦õ╣¤ńøĖÕĮōń│¤ń│Ģ’╝īÕ¤║µ£¼µś»µ»ÅõĖ¬Õøóķś¤ķāĮÕüÜõ║åµł¢ÕżÜµł¢Õ░æķćŹÕżŹńÜäõ║ŗµāģ’╝īĶĆīõĖöķā©ńĮ▓ÕÆīń╗┤µŖżõ╣¤µś»ńøĖÕĮōńÜäķ║╗ńā”’╝ī
ÕøĀõĖ║Õ║×Õż¦ńÜäÕ║öńö©ÕīģÕ£©NÕÅ░µ£║ÕÖ©õĖŖÕżŹÕłČŃĆüÕÉ»ÕŖ©ķāĮķ£ĆĶ”üĶĆŚĶ┤╣õĖŹÕ░æńÜ䵌ČķŚ┤’╝īÕć║ķŚ«ķóśńÜ䵌ČÕĆÖõ╣¤õĖŹµś»ÕŠłÕźĮµ¤ź’╝īÕÅ”Õż¢õĖĆõĖ¬µø┤ń│¤ń│ĢńÜäńŖČÕåĄµś»ÕŠłµ£ēÕÅ»ĶāĮõ╝ÜÕć║ńÄ░µ¤ÉõĖ¬Õ║öńö©õĖŖńÜäbugÕ░▒Õ»╝
Ķć┤õ║åÕģ©ń½ÖķāĮõĖŹÕÅ»ńö©’╝īĶ┐śµ£ēÕģČõ╗¢ńÜäÕāÅĶ░āõ╝śõĖŹÕźĮµōŹõĮ£’╝łÕøĀõĖ║µ£║ÕÖ©õĖŖķā©ńĮ▓ńÜäÕ║öńö©õ╗Ćõ╣łķāĮĶ”üÕüÜ’╝īµĀ╣µ£¼Õ░▒µŚĀµ│ĢĶ┐øĶĪīķÆłÕ»╣µĆ¦ńÜäĶ░āõ╝ś’╝ēńŁēÕøĀń┤Ā’╝īµĀ╣µŹ«Ķ┐ÖµĀĘńÜäÕłåµ×É’╝īÕ╝ĆÕ¦ŗńŚøõĖŗÕå│Õ┐ā’╝īÕ░å
ń│╗ń╗¤µĀ╣µŹ«ĶüīĶ┤ŻĶ┐øĶĪīµŗåÕłå’╝īõ║ĵś»õĖĆõĖ¬Õż¦Õ×ŗńÜäÕłåÕĖāÕ╝ÅÕ║öńö©Õ░▒Ķ»×ńö¤õ║å’╝īķĆÜÕĖĖ’╝īĶ┐ÖõĖ¬µŁźķ¬żķ£ĆĶ”üĶĆŚĶ┤╣ńøĖÕĮōķĢ┐ńÜ䵌ČķŚ┤’╝īÕøĀõĖ║õ╝Üńó░Õł░ÕŠłÕżÜńÜäµīæµłś’╝Ü
1ŃĆüµŗåµłÉÕłåÕĖāÕ╝ÅÕÉÄķ£ĆĶ”üµÅÉõŠøõĖĆõĖ¬ķ½śµĆ¦ĶāĮŃĆüń©│Õ«ÜńÜäķĆÜõ┐ĪµĪåµ×Č’╝īÕ╣ČõĖöķ£ĆĶ”üµö»µīüÕżÜń¦ŹõĖŹÕÉīńÜäķĆÜõ┐ĪÕÆīĶ┐£ń©ŗĶ░āńö©µ¢╣Õ╝Å’╝ø
2ŃĆüÕ░åõĖĆõĖ¬Õ║×Õż¦ńÜäÕ║öńö©µŗåÕłåķ£ĆĶ”üĶĆŚĶ┤╣ÕŠłķĢ┐ńÜ䵌ČķŚ┤’╝īķ£ĆĶ”üĶ┐øĶĪīõĖÜÕŖĪńÜäµĢ┤ńÉåÕÆīń│╗ń╗¤õŠØĶĄ¢Õģ│ń│╗ńÜäµÄ¦ÕłČńŁē’╝ø
3ŃĆüÕ”éõĮĢĶ┐Éń╗┤’╝łõŠØĶĄ¢ń«ĪńÉåŃĆüĶ┐ÉĶĪīńŖČÕåĄń«ĪńÉåŃĆüķöÖĶ»»Ķ┐ĮĶĖ¬ŃĆüĶ░āõ╝śŃĆüńøæµÄ¦ÕÆīµŖźĶŁ”ńŁē’╝ēÕźĮĶ┐ÖõĖ¬Õ║×Õż¦ńÜäÕłåÕĖāÕ╝ÅÕ║öńö©ŃĆé
ń╗ÅĶ┐ćĶ┐ÖõĖƵŁź’╝īÕĘ«õĖŹÕżÜń│╗ń╗¤ńÜäµ×ȵ×äĶ┐øÕģźńøĖÕ»╣ń©│Õ«ÜńÜäķśČµ«Ą’╝īÕÉīµŚČõ╣¤ĶāĮÕ╝ĆÕ¦ŗķććńö©Õż¦ķćÅńÜäÕ╗ēõ╗ʵ£║ÕÖ©µØźµö»µÆæńØĆÕĘ©Õż¦ńÜäĶ«┐ķŚ«ķćÅÕÆīµĢ░µŹ«ķćÅ’╝īń╗ōÕÉłĶ┐ÖÕźŚµ×ȵ×äõ╗źÕÅŖĶ┐Öõ╣łÕżÜµ¼Īµ╝öÕÅśĶ┐ćń©ŗÕÉĖÕÅ¢ńÜäń╗Åķ¬īµØźķććńö©ÕģČõ╗¢ÕÉäń¦ŹÕÉäµĀĘńÜäµ¢╣µ│ĢµØźµö»µÆæńØĆĶČŖµØźĶČŖķ½śńÜäĶ«┐ķŚ«ķćÅŃĆé
1ŃĆüµŗåµłÉÕłåÕĖāÕ╝ÅÕÉÄķ£ĆĶ”üµÅÉõŠøõĖĆõĖ¬ķ½śµĆ¦ĶāĮŃĆüń©│Õ«ÜńÜäķĆÜõ┐ĪµĪåµ×Č’╝īÕ╣ČõĖöķ£ĆĶ”üµö»µīüÕżÜń¦ŹõĖŹÕÉīńÜäķĆÜõ┐ĪÕÆīĶ┐£ń©ŗĶ░āńö©µ¢╣Õ╝Å’╝ø
2ŃĆüÕ░åõĖĆõĖ¬Õ║×Õż¦ńÜäÕ║öńö©µŗåÕłåķ£ĆĶ”üĶĆŚĶ┤╣ÕŠłķĢ┐ńÜ䵌ČķŚ┤’╝īķ£ĆĶ”üĶ┐øĶĪīõĖÜÕŖĪńÜäµĢ┤ńÉåÕÆīń│╗ń╗¤õŠØĶĄ¢Õģ│ń│╗ńÜäµÄ¦ÕłČńŁē’╝ø
3ŃĆüÕ”éõĮĢĶ┐Éń╗┤’╝łõŠØĶĄ¢ń«ĪńÉåŃĆüĶ┐ÉĶĪīńŖČÕåĄń«ĪńÉåŃĆüķöÖĶ»»Ķ┐ĮĶĖ¬ŃĆüĶ░āõ╝śŃĆüńøæµÄ¦ÕÆīµŖźĶŁ”ńŁē’╝ēÕźĮĶ┐ÖõĖ¬Õ║×Õż¦ńÜäÕłåÕĖāÕ╝ÅÕ║öńö©ŃĆé
ń╗ÅĶ┐ćĶ┐ÖõĖƵŁź’╝īÕĘ«õĖŹÕżÜń│╗ń╗¤ńÜäµ×ȵ×äĶ┐øÕģźńøĖÕ»╣ń©│Õ«ÜńÜäķśČµ«Ą’╝īÕÉīµŚČõ╣¤ĶāĮÕ╝ĆÕ¦ŗķććńö©Õż¦ķćÅńÜäÕ╗ēõ╗ʵ£║ÕÖ©µØźµö»µÆæńØĆÕĘ©Õż¦ńÜäĶ«┐ķŚ«ķćÅÕÆīµĢ░µŹ«ķćÅ’╝īń╗ōÕÉłĶ┐ÖÕźŚµ×ȵ×äõ╗źÕÅŖĶ┐Öõ╣łÕżÜµ¼Īµ╝öÕÅśĶ┐ćń©ŗÕÉĖÕÅ¢ńÜäń╗Åķ¬īµØźķććńö©ÕģČõ╗¢ÕÉäń¦ŹÕÉäµĀĘńÜäµ¢╣µ│ĢµØźµö»µÆæńØĆĶČŖµØźĶČŖķ½śńÜäĶ«┐ķŚ«ķćÅŃĆé
ń£ŗń£ŗĶ┐ÖõĖƵŁźÕ«īµłÉÕÉÄń│╗ń╗¤ńÜäÕøŠńż║’╝Ü

┬Ā
Ķ┐ÖõĖƵŁźµČēÕÅŖÕł░õ║åĶ┐Öõ║øń¤źĶ»åõĮōń│╗’╝Ü
Ķ┐ÖõĖƵŁźµČēÕÅŖńÜäń¤źĶ»åõĮōń│╗ķØ×ÕĖĖńÜäÕżÜ’╝īĶ”üµ▒éÕ»╣ķĆÜõ┐ĪŃĆüĶ┐£ń©ŗĶ░āńö©ŃĆüµČłµü»µ£║ÕłČńŁēµ£ēµĘ▒ÕģźńÜäńÉåĶ¦ŻÕÆīµÄīµÅĪ’╝īĶ”üµ▒éńÜäķāĮµś»õ╗ÄńÉåĶ«║ŃĆüńĪ¼õ╗Čń║¦ŃĆüµōŹõĮ£ń│╗ń╗¤ń║¦õ╗źÕÅŖµēĆķććńö©ńÜäĶ»ŁĶ©ĆńÜäÕ«×ńÄ░ķāĮµ£ēµĖģµźÜńÜäńÉåĶ¦ŻŃĆé
Ķ┐Éń╗┤Ķ┐ÖÕØŚµČēÕÅŖńÜäń¤źĶ»åõĮōń│╗õ╣¤ķØ×ÕĖĖńÜäÕżÜ’╝īÕżÜµĢ░µāģÕåĄõĖŗķ£ĆĶ”üµÄīµÅĪÕłåÕĖāÕ╝ÅÕ╣ČĶĪīĶ«Īń«ŚŃĆüµŖźĶĪ©ŃĆüńøæµÄ¦µŖƵ£»õ╗źÕÅŖĶ¦äÕłÖńŁ¢ńĢźńŁēńŁēŃĆé
Ķ»┤ĶĄĘµØźńĪ«Õ«×õĖŹµĆÄõ╣łĶ┤╣ÕŖø’╝īµĢ┤õĖ¬ńĮæń½Öµ×ȵ×äńÜäń╗ÅÕģĖµ╝öÕÅśĶ┐ćń©ŗķāĮÕÆīõĖŖķØóµ»öĶŠāńÜäń▒╗õ╝╝’╝īÕĮōńäČ’╝īµ»ÅµŁźķććÕÅ¢ńÜäµ¢╣µĪł’╝īµ╝öÕÅśńÜ䵣źķ¬żµ£ēÕÅ»ĶāĮµ£ēõĖŹÕÉī’╝īÕÅ”Õż¢’╝īńö▒õ║ÄńĮæń½ÖńÜäõĖÜÕŖĪ
õĖŹÕÉī’╝īõ╝ܵ£ēõĖŹÕÉīńÜäõĖōõĖܵŖƵ£»ńÜäķ£Ćµ▒é’╝īĶ┐Öń»ćblogµø┤ÕżÜńÜ䵜»õ╗ĵ×ȵ×äńÜäĶ¦ÆÕ║”µØźĶ«▓Ķ¦Żµ╝öÕÅśńÜäĶ┐ćń©ŗ’╝īÕĮōńäČ’╝īÕģČõĖŁĶ┐śµ£ēÕŠłÕżÜńÜäµŖƵ£»õ╣¤µ£¬Õ£©µŁżµÅÉÕÅŖ’╝īÕāŵĢ░µŹ«Õ║ōķøåńŠżŃĆüµĢ░µŹ«µī¢µÄśŃĆü
µÉ£ń┤óńŁē’╝īõĮåÕ£©ń£¤Õ«×ńÜäµ╝öÕÅśĶ┐ćń©ŗõĖŁĶ┐śõ╝ÜÕƤÕŖ®ÕāŵÅÉÕŹćńĪ¼õ╗ČķģŹńĮ«ŃĆüńĮæń╗£ńÄ»ÕóāŃĆüµö╣ķĆĀµōŹõĮ£ń│╗ń╗¤ŃĆüCDNķĢ£ÕāÅńŁēµØźµö»µÆæµø┤Õż¦ńÜ䵥üķćÅ’╝īÕøĀµŁżÕ£©ń£¤Õ«×ńÜäÕÅæÕ▒ĢĶ┐ćń©ŗõĖŁĶ┐śõ╝ܵ£ēÕŠłÕżÜńÜäõĖŹ
ÕÉī’╝īÕÅ”Õż¢õĖĆõĖ¬Õż¦Õ×ŗńĮæń½ÖĶ”üÕüÜÕł░ńÜäĶ┐£Ķ┐£õĖŹõ╗ģõ╗ģõĖŖķØóĶ┐Öõ║ø’╝īĶ┐śµ£ēÕāÅÕ«ēÕģ©ŃĆüĶ┐Éń╗┤ŃĆüĶ┐ÉĶÉźŃĆüµ£ŹÕŖĪŃĆüÕŁśÕé©ńŁē’╝īĶ”üÕüÜÕźĮõĖĆõĖ¬Õż¦Õ×ŗńÜäńĮæń½Öń£¤ńÜäÕŠłõĖŹÕ«╣µśō’╝īÕåÖĶ┐Öń»ćµ¢ćń½Āµø┤ÕżÜńÜ䵜»ÕĖīµ£øĶāĮ
Õż¤Õ╝ĢÕć║µø┤ÕżÜÕż¦Õ×ŗńĮæń½Öµ×ȵ×äµ╝öÕÅśńÜäõ╗ŗń╗Ź’╝ī:)ŃĆé
Õłåõ║½Õł░’╝Ü


- 2011-01-07 14:15
- µĄÅĶ¦ł 2146
- Ķ»äĶ«║(3)
- Õłåń▒╗:õ╝üõĖܵ×ȵ×ä
- µ¤źń£ŗµø┤ÕżÜ
Ķ»äĶ«║
3 µź╝
xwy55555
2012-07-07
2 µź╝
nuhsoah
2012-02-21
õ╗ÄĶ┐Öµ¢ćń½ĀÕÅ»õ╗źń£ŗÕć║õĮ£ĶĆģńÜäµĘ▒ÕÄܵ×ȵ×äÕŖ¤Õ║Ģ’╝īķĪČ’╝ü
1 µź╝
nuhsoah
2012-02-02
ÕŠłÕźĮńÜäµ¢ćń½Ā’╝īÕÅŚńøŖÕī¬µĄģ’╝ü
ÕÅæĶĪ©Ķ»äĶ«║

ńøĖÕģ│µÄ©ĶŹÉ
javaÕż¦Õ×ŗńĮæń½ÖµĪåµ×ČńÜäµ╝öÕÅśńÜäµĢ┤õĖ¬Ķ┐ćń©ŗ’╝īµā│Õ╝ĆÕÅæÕż¦Õ×ŗjavańĮæń½ÖńÜäµ£ŗÕÅŗõ╗¼ÕÅ»õ╗źń£ŗń£ŗ
µ£ēõĖĆõ║øõ╗ŗń╗ŹÕż¦Õ×ŗńĮæń½Öµ×ȵ×äµ╝öÕÅśńÜäµ¢ćń½Ā’╝īõŠŗÕ”éLiveJournalńÜäŃĆüebayńÜä’╝īķāĮµś»ķØ×ÕĖĖÕĆ╝ÕŠŚÕÅéĶĆāńÜä’╝īµø┤ÕżÜńÜ䵜»Ķ«▓µ»Åµ¼Īµ╝öÕÅśńÜäń╗ōµ×£’╝īĶĆīµ▓Īµ£ēÕŠłĶ»”ń╗åńÜäĶ«▓õĖ║õ╗Ćõ╣łķ£ĆĶ”üÕüÜĶ┐ÖµĀĘńÜäµ╝öÕÅśŃĆéÕ£©Ķ┐Öń»ćµ¢ćń½ĀõĖŁ Õ░åķśÉĶ┐░õĖĆõĖ¬µÖ«ķĆÜńÜäńĮæń½ÖÕÅæÕ▒ĢµłÉÕż¦Õ×ŗńĮæń½ÖĶ┐ćń©ŗõĖŁ...
Ķ»źõ╣”ńö▒ķś┐ķćīÕĘ┤ÕĘ┤Ķć¬Ķ║½ÕĘźń©ŗÕĖłµøŠÕ«¬µØ░µēĆĶæŚŃĆéķśÉĶ┐░õ║åÕż¦Õ×ŗńĮæń½ÖńÜäµ╝öÕÅśÕÄåÕÅ▓’╝īõ╗źÕÅŖõĖŁķŚ┤õ╗ČÕ£©Õż¦Õ×ŗńĮæń½ÖńÜäĶ«ŠĶ«ĪõĖÄÕ«×ĶĘĄŃĆéõĖ╗Ķ”üÕīģµŗ¼µ£ŹÕŖĪµĪåµ×ČŃĆüµĢ░µŹ«Õ║ōõĖŁķŚ┤õ╗ČŃĆüµČłµü»õĖŁķŚ┤õ╗ČŃĆüĶĮ»Ķ┤¤ĶĮĮõĖŁÕ┐āÕÆīķøåõĖŁķģŹńĮ«õĖŁķŚ┤õ╗ČńŁēŃĆéń╗ØÕ»╣µś»õĖƵ£¼õ╗żõ║║ÕÉ»ÕÅæńÜäÕźĮõ╣”
1.3ŃĆĆÕż¦Õ×ŗĶĮ»õ╗ČŃĆĆ8 1.4ŃĆƵ╝éõ║«’╝īń£¤ńÉåÕÆīõ╝śķøģŃĆĆ9 1.5ŃĆƵø┤ÕźĮńÜ䵌Āń╗¬ŃĆĆ12 ń¼¼2ń½ĀŃĆĆĶ«ŠĶ«ĪAPIńÜäÕŖ©ÕŖøõ╣ŗµ║ÉŃĆĆ14 2.1ŃĆĆÕłåÕĖāÕ╝ÅÕ╝ĆÕÅæŃĆĆ14 2.2ŃĆƵ©ĪÕØŚÕī¢Õ║öńö©ń©ŗÕ║ÅŃĆĆ16 2.3ŃĆĆõ║żµĄüõ║ÆķĆܵēŹµś»õĖĆÕłćŃĆĆ20 2.4ŃĆĆń╗Åķ¬īõĖ╗õ╣ēń╝¢ń©ŗµ¢╣Õ╝ÅŃĆĆ22 2.5ŃĆĆ...
õĖ║µö»µīüõĖÜÕŖĪńÜäÕ┐½ķƤÕÅæÕ▒Ģ’╝īń¦╗ÕŖ©ńĀöÕÅæÕøóķś¤Ķ¦äµ©Īõ╣¤ķĆɵĖÉõ╗Äķøȵś¤ńÜäÕ░ÅõĮ£ÕØŖÕ╝ÅĶ┐ÉĶÉź’╝īµ╝öÕÅśõĖ║ÕŹāõ║║ń║¦ńĀöÕÅæÕåøÕøóÕŹÅÕÉīõĮ£µłśŃĆéÕ£©Õģ¼ÕÅĖĶō¼ÕŗāÕÅæÕ▒ĢńÜäÕż¦ĶāīµÖ»õĖŗ’╝īń¦╗ÕŖ©ķĪ╣ńø«µ×ȵ×äõ╣¤µ£ēõ║åÕģ©µ¢░ńÜäµ╝öĶ┐øµ¢╣ÕÉæ’╝Üķ£ĆĶ”üµö»µīüķ½śµĢłńÜäķøåµłÉńŁ¢ńĢź’╝īµö»µīüńĀöÕÅæµĄüń©ŗĶć¬ÕŖ©Õī¢...
Õż¦Õ×ŗõ╝üõĖÜÕĘ▓ń╝ōµģóĶĆīń©│Õ«ÜÕ£░Ķ┐øÕģźĶ»źķóåÕ¤¤’╝īĶ»źĶĪīõĖܵŁŻÕ£©µ╝öÕÅśõĖ║µ£ēń╗äń╗ćńÜäÕĮóńŖČÕÆīń╗ōµ×äŃĆé Õ░▒µ£¬µØźńÜäÕó×ķĢ┐µĮ£ÕŖøĶĆīĶ©Ć’╝īÕŹ░Õ║”ķøČÕö«õĖÜÕĘ▓Ķó½ÕłŚõĖ║ÕÅæÕ▒ĢõĖŁÕøĮÕ«ČÕĖéÕ£║õĖŁńÜäõĮ╝õĮ╝ĶĆģŃĆé Ķ┐ÖÕ╝ĢĶĄĘõ║åÕģ©ńÉāÕż¦Õ×ŗķøČÕö«õ╝üõĖÜÕ»╣ÕŹ░Õ║”ķøČÕö«õĖÜńÜäÕ╝║ńāłÕģ┤ĶČŻ’╝īõĮåõĖĵŁżÕÉīµŚČ’╝ī...
Õ£©Õż¦Õ×ŗńĮæń½ÖÕÆīÕżŹµØéń│╗ń╗¤ńÜäÕ╝ĆÕÅæõĖŁ’╝īJavaÕģʵ£ēÕż®ńäČńÜäõ╝śÕŖ┐’╝īĶĆīÕ£©JavańÜäWebµĪåµ×ČõĖŁSpring MVCõ╗źÕģČÕ╝║Õż¦ńÜäÕŖ¤ĶāĮõ╗źÕÅŖń«ĆÕŹĢõĖöńüĄµ┤╗ńÜäńö©µ│ĢÕÅŚÕł░ĶČŖµØźĶČŖÕżÜÕ╝ĆÕÅæĶĆģńÜäķØÆńØÉŃĆéµ£¼õ╣”õĖŹõ╗ģĶ»”ń╗åÕ£░Õłåµ×ÉSpring MVCńÜäń╗ōµ×äÕÅŖÕģČÕ«×ńÄ░ń╗åĶŖé’╝īĶĆīõĖöĶ«▓Ķ¦ŻńĮæń½Ö...
Õ£©Õż¦Õ×ŗńĮæń½ÖÕÆīÕżŹµØéń│╗ń╗¤ńÜäÕ╝ĆÕÅæõĖŁ’╝īJavaÕģʵ£ēÕż®ńäČńÜäõ╝śÕŖ┐’╝īĶĆīÕ£©JavańÜäWebµĪåµ×ČõĖŁSpring MVCõ╗źÕģČÕ╝║Õż¦ńÜäÕŖ¤ĶāĮõ╗źÕÅŖń«ĆÕŹĢõĖöńüĄµ┤╗ńÜäńö©µ│ĢÕÅŚÕł░ĶČŖµØźĶČŖÕżÜÕ╝ĆÕÅæĶĆģńÜäķØÆńØÉŃĆéµ£¼õ╣”õĖŹõ╗ģĶ»”ń╗åÕ£░Õłåµ×ÉSpring MVCńÜäń╗ōµ×äÕÅŖÕģČÕ«×ńÄ░ń╗åĶŖé’╝īĶĆīõĖöĶ«▓Ķ¦ŻńĮæń½Ö...
ķĆÜĶ┐ćµĪłõŠŗÕ«īµĢ┤ÕæłńÄ░TomcatńÜäÕ«×ńÄ░’╝īń│╗ń╗¤µĆ╗ń╗ōSpring MVCõ╣ØÕż¦ń╗äõ╗ČńÜäÕżäńÉåõ╗źÕÅŖÕĖĖńö©ńÜäµŖĆÕʦÕÆīÕ«×ĶĘĄ Õ£©Õż¦Õ×ŗńĮæń½ÖÕÆīÕżŹµØéń│╗ń╗¤ńÜäÕ╝ĆÕÅæõĖŁ’╝īJavaÕģʵ£ēÕż®ńäČńÜäõ╝śÕŖ┐’╝īĶĆīÕ£©JavańÜäWebµĪåµ×ČõĖŁSpring MVCõ╗źÕģČÕ╝║Õż¦ńÜäÕŖ¤ĶāĮõ╗źÕÅŖń«ĆÕŹĢõĖöńüĄµ┤╗ńÜäńö©µ│ĢÕÅŚÕł░...
Õ£©ń╗¤õĖĆńÜäÕłåÕī║µĪåµ×ČõĖŁĶ«©Ķ«║õ║åÕ»╣DGLAPÕÆīBFKLµ¢╣ń©ŗńÜäĶāČÕŁÉĶ׏ÕÉłńÜäµĀĪµŁŻŃĆé ńö▒µŁżõ║¦ńö¤ńÜäķØ×ń║┐µĆ¦µ╝öÕī¢µ¢╣ń©ŗµś»ĶæŚÕÉŹńÜäGLRŌĆōMQŌĆōZRSµ¢╣ń©ŗÕÆīõĖĆõĖ¬µ¢░ńÜäµ╝öÕī¢µ¢╣ń©ŗŃĆé õĮ┐ńö©ÕÅ»ńö©ńÜäķź▒ÕÆīÕ║”µ©ĪÕ×ŗõĮ£õĖ║ĶŠōÕģź’╝īµłæõ╗¼ÕÅæńÄ░µ¢░ńÜäµ╝öÕī¢µ¢╣ń©ŗÕģʵ£ēÕ£©µē░ÕŖ©ĶīāÕø┤ÕåģÕģʵ£ē...
Django Evolutionµś»ńĮæń╗£µĪåµ×ČńÜäķÖäÕŖĀń╗äõ╗Č’╝īÕÅ»ÕĖ«ÕŖ®ń«ĪńÉåÕ»╣µĢ░µŹ«Õ║ōµ©ĪÕ╝ÅńÜäµø┤µö╣ŃĆé ŌĆ£õĮåµś»ńŁēńŁē’╝īµłæõĖ║õ╗Ćõ╣łĶ”üĶ┐Öõ╣łÕüÜ’╝¤Djangoµś»ÕÉ”µ▓Īµ£ēÕåģńĮ«ńÜäĶ┐üń¦╗ÕŖ¤ĶāĮ’╝¤Ķ┐ÖõĖŹµś»õĖĆÕø×õ║ŗÕÉŚ’╝¤ŌĆØ µś»ńÜä’╝īµś»ńÜä’╝īĶĆīõĖöÕż¦ÕżÜµĢ░µāģÕåĄµś»Ķ┐ÖµĀĘŃĆé Õ«×ķÖģõĖŖ’╝īDjango ...
Õ»╣ńĮæń╗£µ╝öÕī¢Õ╗║µ©Īµś»µłæõ╗¼ńÉåĶ¦ŻńÄ░õ╗ŻÕż¦Õ×ŗķĆÜõ┐Īń│╗ń╗¤’╝łõŠŗÕ”éõĖćń╗┤ńĮæ’╝ēõ╗źÕÅŖń╗ŵĄÄÕÆīńżŠõ╝ÜńĮæń╗£ńÜäµĀĖÕ┐āŃĆé Õ»╣ńżŠõ╝ÜÕÆīń╗ŵĄÄńĮæń╗£ńÜäńĀöń®Čµś»ń£¤µŁŻńÜäĶĘ©ÕŁ”ń¦æ’╝īÕ╗║µ©ĪńŁ¢ńĢźÕÆīµ”éÕ┐ĄńÜäµĢ░ķćŵś»ÕĘ©Õż¦ńÜäŃĆé Õ£©µ£¼µ¼ĪĶ░āµ¤źõĖŁ’╝īµłæõ╗¼µÅÉÕć║õ║åõĖĆõ║øÕ╗║µ©Īµ¢╣µ│Ģ’╝īµČĄńø¢ń╗ÅÕģĖńÜä...
webÕ║öńö©õ╗ÄÕŹĢńé╣ÕÉæķ½śÕ╣ČÕÅæµ×ȵ×äµ╝öÕÅśµŚČÕŠĆÕŠĆķüćÕł░µ£ĆÕż¦ńÜäķŚ«ķóśÕ░▒µś»µĢ░µŹ«Õ║ōńÜäÕłåÕĖāÕ╝ÅÕŁśÕé©ŃĆéÕøĀõĖ║webÕ║öńö©µ£¼Ķ║½Õ░▒ÕÅ»õ╗źķøåńŠżķā©ńĮ▓’╝īõĮåÕģȵēĆõĮ┐ńö©ńÜäµĢ░µŹ«Õ║ōńĪ«µś»ÕŹĢńé╣ńÜäŃĆéÕ”éµ×£õĖĆõĖ¬webÕ║öńö©Õ╝ĆÕ¦ŗńÜ䵌ČÕĆÖµ▓Īµ£ēĶĆāĶÖæµĢ░µŹ«Õ║ōńÜäÕłåÕĖāÕ╝ŵ×ȵ×ä’╝īķéŻõ╣łńŁēÕł░Ķ”ü...
ÕøĀõĖ║Õ¤║õ║Äń╗äõ╗ČńÜäµĪåµ×Čń╗ōµ×äÕÆīĶ«ŠĶ«Īń▓ŠÕʦńÜäń╝ōÕŁśµö»µīü’╝īYii ńē╣Õł½ķĆéÕÉłÕ╝ĆÕÅæÕż¦Õ×ŗÕ║öńö©’╝īÕ”éķŚ©µłĘńĮæń½ÖŃĆüĶ«║ÕØøŃĆüÕåģÕ«╣ń«ĪńÉåń│╗ń╗¤’╝łCMS’╝ēŃĆüńöĄÕŁÉÕĢåÕŖĪķĪ╣ńø«ÕÆī RESTful Web µ£ŹÕŖĪńŁēŃĆé Yii ńēłµ£¼ Yii ÕĮōÕēŹµ£ēõĖżõĖ¬õĖ╗Ķ”üńēłµ£¼’╝Ü1.1 ÕÆī 2.0ŃĆé 1.1 ńēłµś»...