
前置条件
已经成功安装配置Hadoop和Mysql数据库服务器,如果将数据导入或从Hbase导出,还应该已经成功安装配置Hbase。
下载sqoop和Mysql的JDBC驱动
sqoop-1.2.0-CDH3B4.tar.gz :http://archive.cloudera.com/cdh/3/sqoop-1.2.0-CDH3B4.tar.gz
mysql-connector-java-5.1.28
安装sqoop
[hadoop@appserver ~]$ tar -zxvf sqoop-1.2.0-CDH3B4.tar.gz
配置环境变量
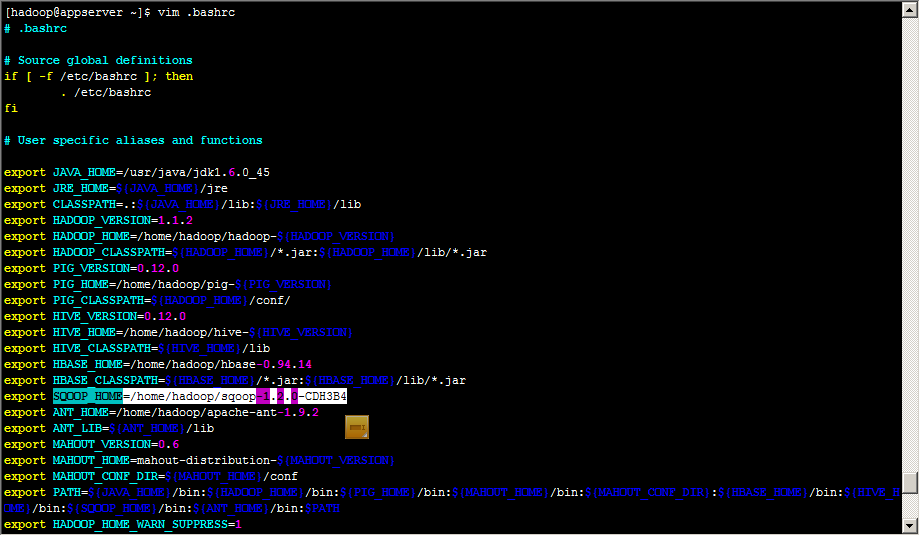
拷贝Hadoop核心包和MYSQL驱动包到sqoop的lib目录
[hadoop@appserver ~]$ cp hadoop-1.1.2/hadoop-core-1.1.2.jar sqoop-1.2.0-CDH3B4/lib/
[hadoop@appserver ~]$ cp mysql-connector-java-5.1.28-bin.jar sqoop-1.2.0-CDH3B4/lib/

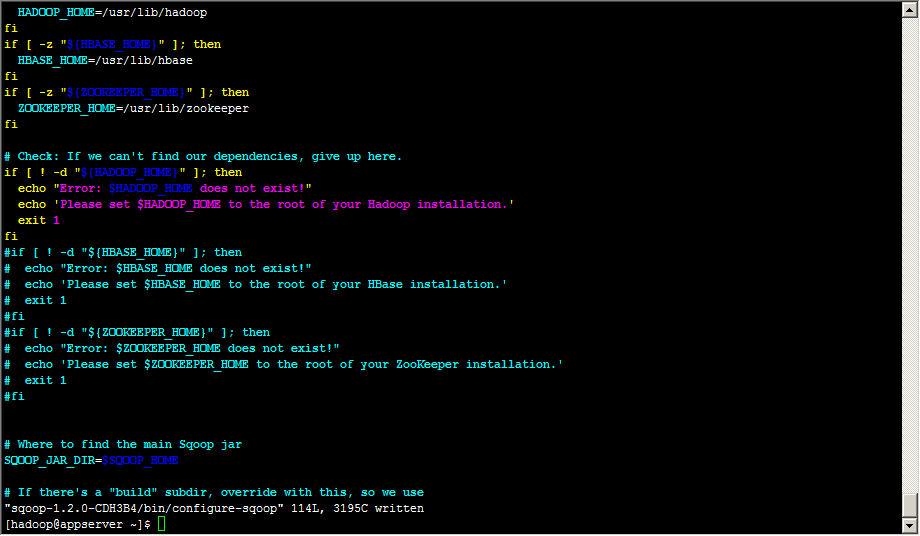
配置sqoop-1.2.0-CDH3B4/bin/configure-sqoop文件
注释掉hbase和zookeeper检查(除非准备使用HABASE等HADOOP组件)
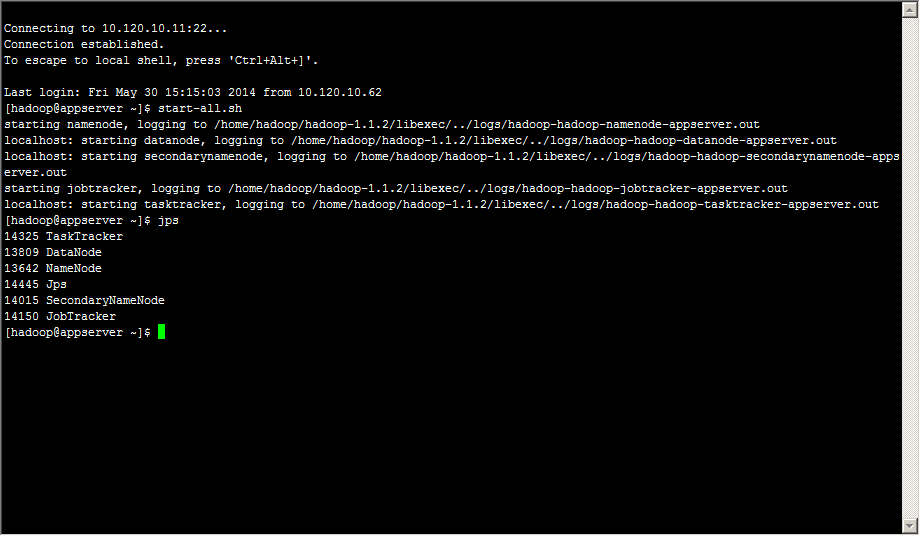
启动hadoop集群
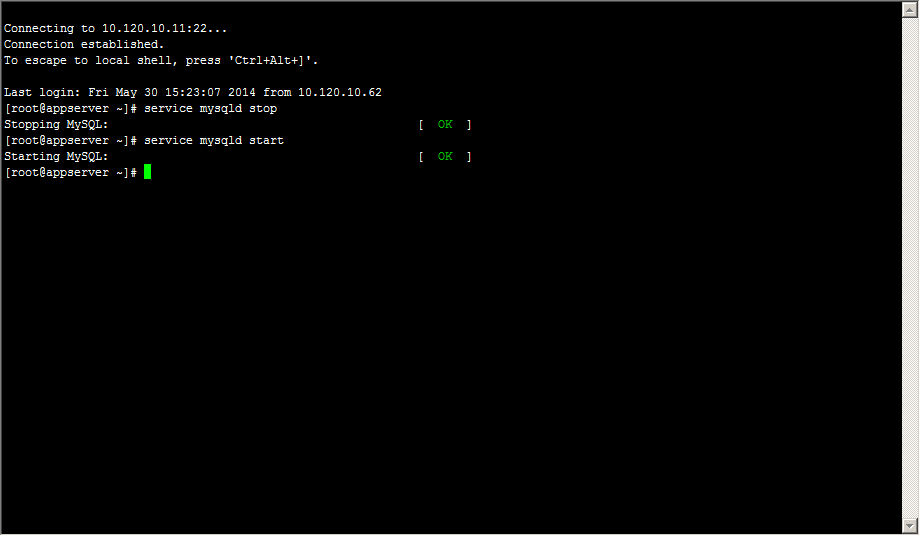
启动mysql
创建sqoop用户
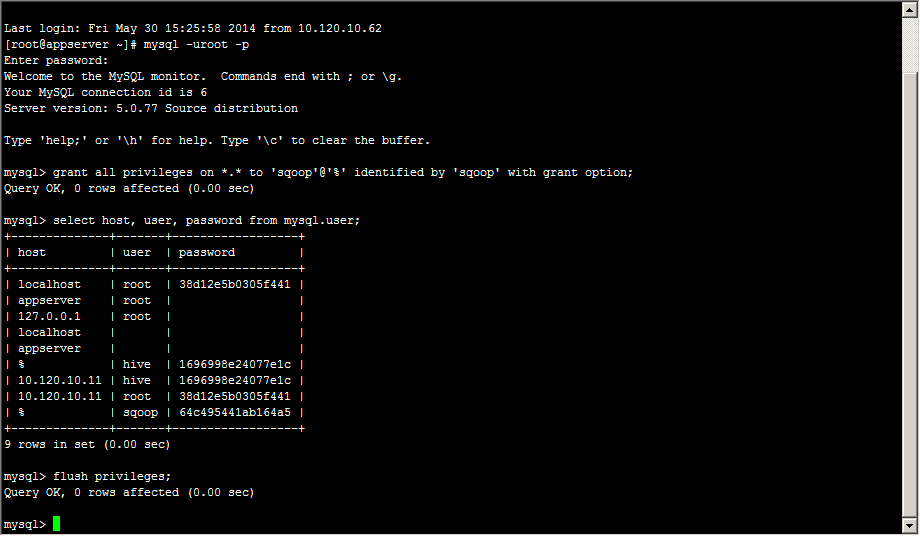
建立sqoop库,test表,并构造测试数据
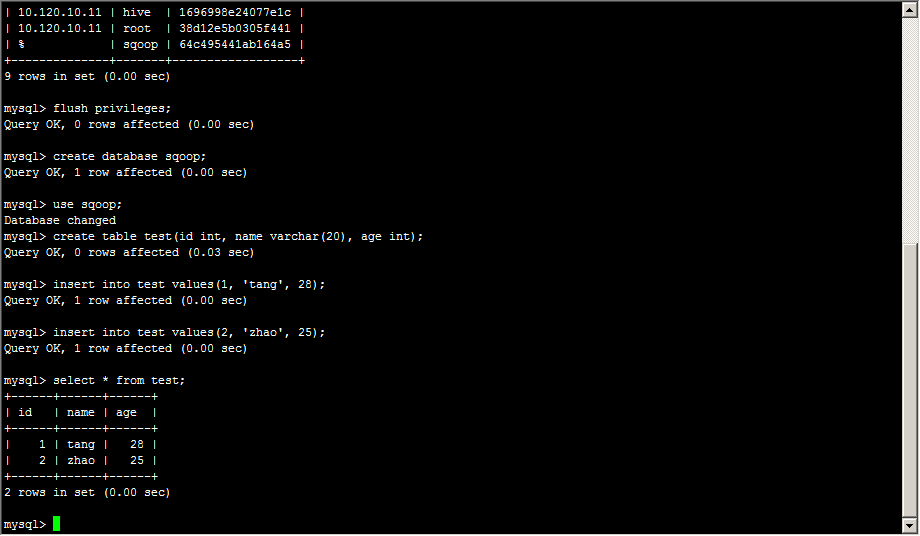
测试sqoop连接
[hadoop@appserver ~]$ sqoop list-databases --connect jdbc:mysql://10.120.10.11:3306/ --username sqoop --password sqoop
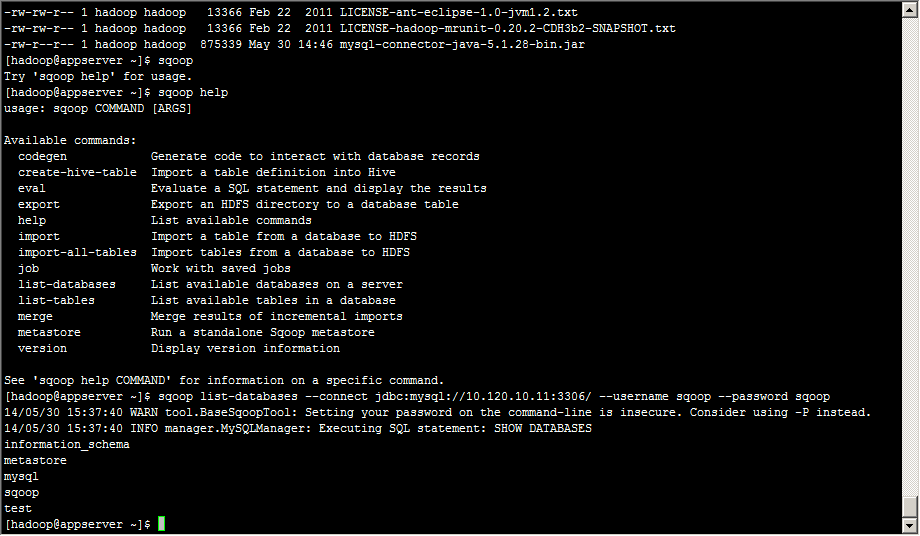
列出mysql中所有数据库的名称
从mysql导入到hdfs中
sqoop ##sqoop命令
import ##表示导入
--connect jdbc:mysql://ip:3306/sqoop ##告诉jdbc,连接mysql的url
--username sqoop ##连接mysql的用户名
--password sqoop ##连接mysql的密码
--table test ##从mysql导出的表名称
--fields-terminated-by '\t' ##指定输出文件中的行的字段分隔符
-m 1 ##复制过程使用1个map作业
[hadoop@appserver ~]$ sqoop import --connect jdbc:mysql://10.120.10.11:3306/sqoop --username sqoop --password sqoop --table test --fields-terminated-by ':' -m 1

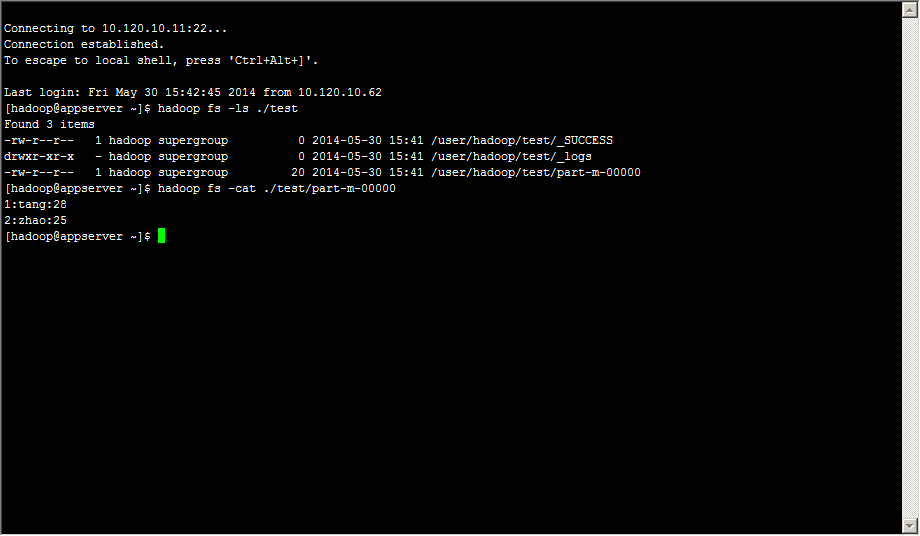
Hadoop中查看导入结果
从hdfs导出到mysql中
sqoop
export ##表示数据从hive复制到mysql中
--connect jdbc:mysql://ip:3306/sqoop
--username sqoop
--password sqoop
--table test ##mysql中的表,即将被导入的表名称
--export-dir '/user/root/aa/part-m-00000' ##hive中被导出的文件
--fields-terminated-by '\t' ##hive中被导出的文件字段的分隔符
[hadoop@appserver ~]$ sqoop export --connect jdbc:mysql://10.120.10.11:3306/sqoop --username sqoop --password sqoop --table test --export-dir '/user/hadoop/test/part-m-00000' --fields-terminated-by ':' -m 1
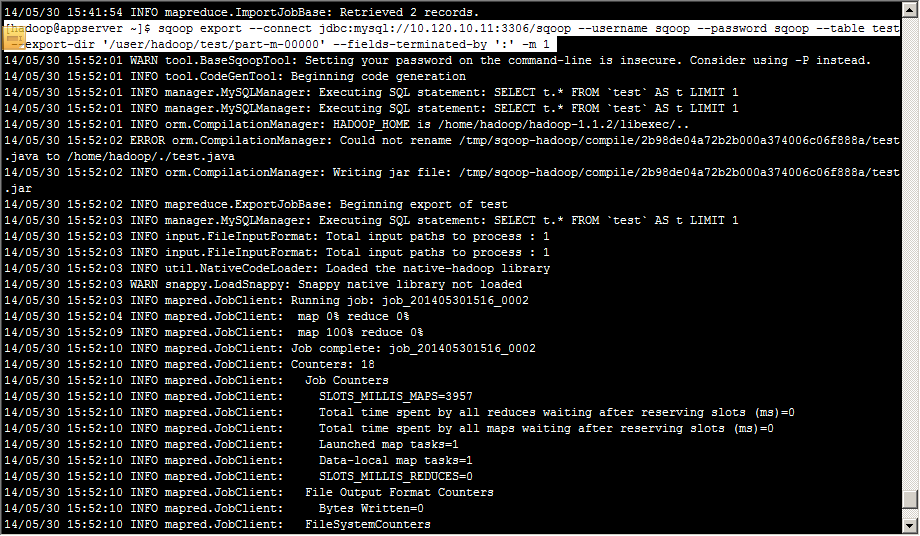
Mysql中查看导出结果

从Mysql导入到Hbase中
参数说明:
Ø hbase_tablename指定要导成hbase的表名
Ø key_col_name指定mysql数据库表中哪一列作为hbase新表的rowkey
Ø col_fam_name是除rowkey之外的所有列的列族名
[hadoop@appserver ~]$ sqoop import --connect jdbc:mysql://10.120.10.11:3306/sqoop --username sqoop --password sqoop --table test --hbase-create-table --hbase-table mysql_sqoop_test --column-family info --hbase-row-key id -m 1
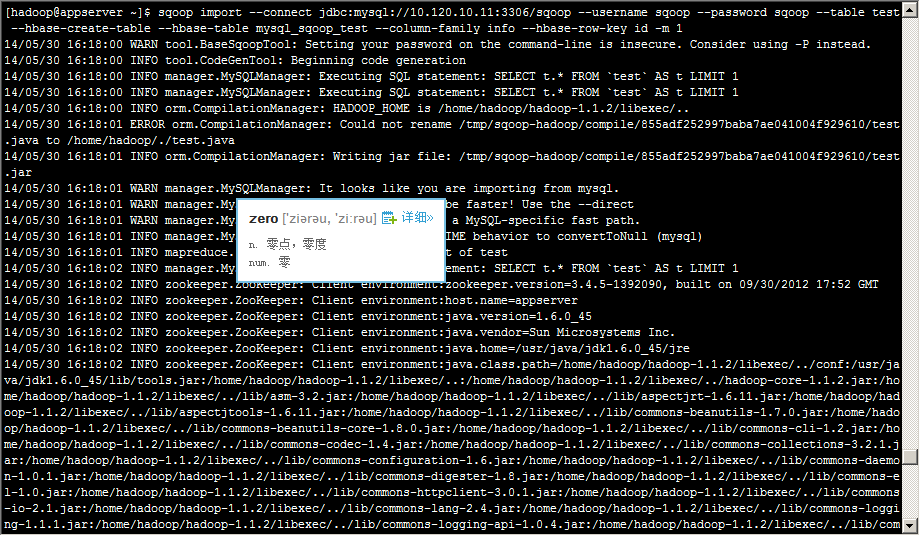
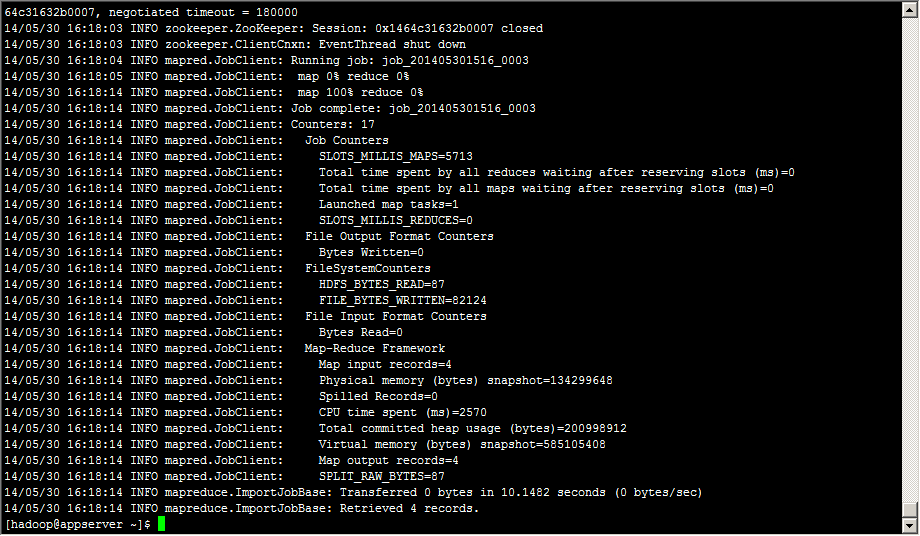
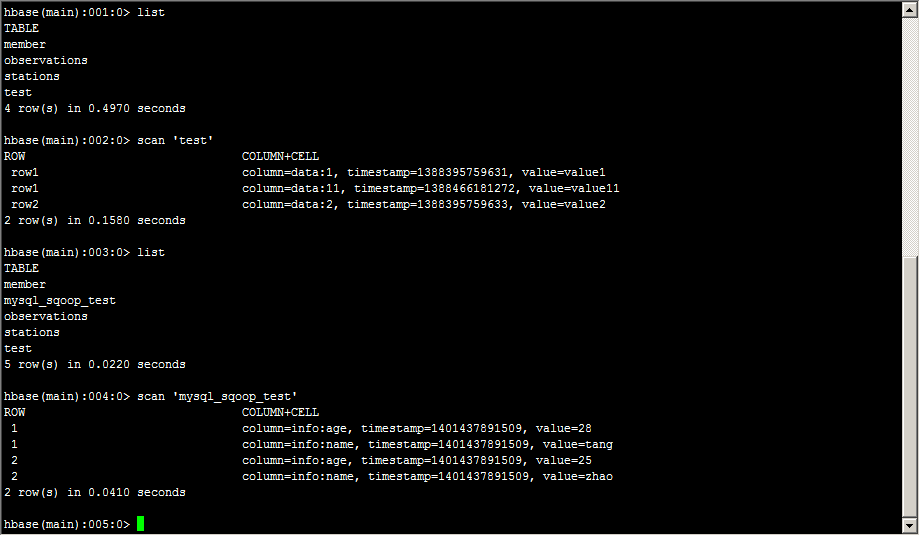
在Hbase中查看结果



相关推荐
1.集群配置,包含三个结点,主节点控制所有的子节点 2.集群已经搭建好了,解压之后...3.包含全套组件:hdfs,hbase,hive,sqoop,mysql,pig,spark等大数据组件 4.如果不知道如何使用,或者需要做Hadoop项目可以私信博主
Ambari已支持大多数Hadoop组件,包括HDFS、MapReduce、Hive、Pig、 Hbase、Zookeeper、Sqoop和Hcatalog等。但是这里的 Hadoop 是广义,指的是 Hadoop 整个生态圈(例如 Hive,Hbase,Sqoop,Zookeeper 等),而并...
Barclamp是实现Crowbar功能的模块组件。 核心气压钳操作撬棒部署机制的基本功能,而其他气压钳则将系统扩展为特定应用。 此barclamp的功能并不孤单,需要Crowbar Framework 关于这个钳子 有关此barclamp的信息,...
包括hadoop,hive,hbase,jdk,mysql,flume,sqoop.xshell等常用组件,组件全部兼容
Hadoop部署平台全套组件,包含hdfs,hive,hbase,sqoop,mysql,flume等,包含大数据处理的全部组件功能! 现成虚拟机,安装好的镜像,下载直接可运行!!!
Sqoop在Hadoop生态系统中占据一席之地,为关系数据库服务器和Hadoop的HDFS之间提供了可行的交互。; Sqoop是一个用于在Hadoop和关系数据库服务器之间传输数据的工具。它用于从关系数据库(如MySQL,Oracle)导入数据...
本实践项目通过一个网站的运营日志,利用hadoop/hive/sqoop/mysql/python等一系列组件联合实践分析挖掘网站运营数据。是不可多得的完整的学习、讲课案例资源。本资源包含ppt、代码、文档及所需数据。
一个完整的hadoop项目实战全流程。是学习、备课不可多得的资源材料。内容包含hadoop/hive/sqoop/mysql等组件的实践。
根据实战安装步骤,详细描述hadoop3.2.1、hive3.1.2(包括mysql5.7)、zookeeper3.6、hbase2.2.4、flume1.90、sqoop1.4.7各组件安装步骤,记录过程中的各种坑,方便各位看官快速安装部署hadoop伪分布集群。
主要介绍Hadoop,Spark,Sqoop,Hbase,kafka等大数据相关组件,以及Apache原生集群以及CDH一键安装方式,最后介绍作者所在公司的应用场景
hadoop 架构图 详细描述 hadoop hive sqoop 等组件
本书主要介绍Hadoop技术的相关知识,不但详细介绍了Hadoop、MapReduce、HDFS、Hive和Sqoop,还深入探讨了Hadoop的运维和调优,并包含了一个具有代表性的完整的基于Hadoop的商业智能系统的设计和实现。, 本书的最大...
基于hadoop的分布式搜索系统的实现代码
最权威的大数据Hadoop学习教程书籍、包含了Hadoop、Hive、HBase、Sqoop、Spark、Storm、Kafka等组件的学习使用。
Hadoop生态圈包含HDFS、MapReduce、HBase、Hive、Pig、Flume、Sqoop、ZooKeeper等诸多组件。对大数据的初学者来说,搭建一个Hadoop大数据基础平台不是一件容易的事;对于企业,如果要部署由成千上万的节点组成的...
资源包括hive-1.2.1、hadoop-2.7.6、hbase-1.4.6、jdk、mysql-5.1.7、redis-3.0.0、sqoop-1.4.7、zookeeper-3.4.6
详细记录基于Hadoop2.5.1的集群的安装过程,集群组件包含:JDK、Hadoop、Hive、ZK、MySql、Sqoop
此外,Hadoop广义上指的是一个更广泛的概念,即Hadoop生态系统,其中还包括了Hive数据仓库工具、HBase非关系型数据库、Zookeeper分布式协调服务、Kafka消息队列、Sqoop数据导入导出等其他组件。 Hadoop的创始人是...
java连接sqoop源码Hadoop 2 学习笔记 来自在线课程的综合说明: 大数据 -从加州大学圣地亚哥分校释放海量数据集中的价值 Randal Scott King学习 Hadoop 2 来自加州大学圣地亚哥分校的Hadoop 平台和应用程序框架 目录...