
Storm 概念梳理
刚接触storm,梳理了一些概念性的东西,对于 storm 中提到的一些名词做一些解释,重点在于搞清楚 storm 中很多组件设置的并发度,在实际的运行时是怎么体现出来的,另外对于设置 Stream 和 tuple 的 Grouping 方式相对于已有的文档,做了一些补充,这个对于写程序时设置Topology时会有帮助,有理解的不对的地方,欢迎指正。
1. storm
Storm是一个分布式实时计算系统。
全量数据处理一般使用Hadoop,但是Hadoop擅长海量数据批处理,不擅长实时计算,无法实时计算数据,并把结果反馈到系统。所以有很多的实时计算系统冒出来,Storm是其中之一。Jstorm是用Java 重写的Storm。
从应用的角度,JStorm 应用是一种遵守某种编程规范的分布式应用。从系统角度, JStorm一套类似MapReduce的调度系统。 从数据的角度, 是一套基于流水线的消息处理机制。--参考Jstorm 官方文档概叙
2. Stream
Storm中最核心的是Stream的概念:
从数据的角度,Storm是流水线式的,Tuple是基本的数据单元,由于Storm的计算过程是没有终止状态的,所以可以认为Tuple是源源不断的,没有边界的,一连串无边界的Tuple序列就构成了Stream。例如:一个Spout不断的发送tuple,一个Bolt订阅了这些tuple,之间就构成了一个Stream,Bolt处理完这些tuple,还可以把结果放在tuple中发出去,放进一个新的Stream中。
代码示例,如何声明Stream:
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
// 默认Stream
declarer.declare(new Fields("MessageExt"));
// id为directStream的stream
declarer.declareStream("directStream", false, new Fields("MessageExt"));
}
注意
如果声明Stream,或者订阅Stream的时候,没有显示指定Stream 的Id的,那么对应的Stream默认的Id是“default”
下图中的每一条边都代表一个Stream:
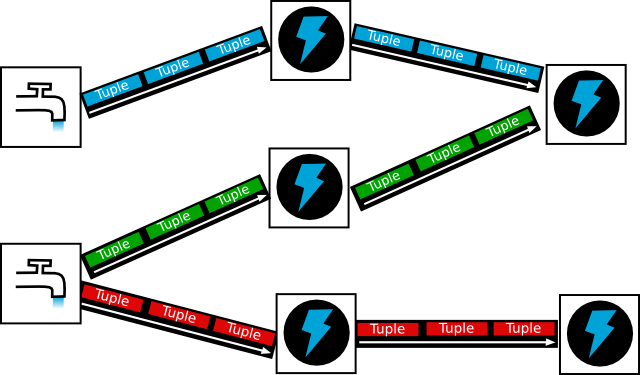
3. Jstorm中构建Topology的一些概念
-
Spot:每个stream都有一个stream源,也就是原始tuple的源头,像水龙头一样,所以将这个源头抽象为spout,tuple最开始是从这个节点发出。 -
Bolt:tuple的中间处理过程抽象为Bolt。只要Bolt订阅了流,上一级的Spot或Bolt一定会把tuple发送给它进行处理。 -
Tuple:发送数据的基本单元。 -
Stream Grouping:规定了tuple的发送方式
如果定义好了Spout和Bolt,以及它们之间的订阅关系,可以构成一个有向无环图,如下:

如果在项目中定义好了Spout、Bolt以及它们的订阅关系,从逻辑上构成了这个有向无环图(在storm/Jstorm中称为一个Topology),可以提交给Jstorm集群执行。
Storm/Jstorm集群的结构大概是这个样子:

Nimbus是master节点,负责分布代码,分发任务,监听失败。Jstorm可以有Nimbus集群,但是同一时刻只有一个有效,这里可以看成只有一个节点。Supervisor是Worker节点,负责执行具体数据处理的任务。Zookeeper集群负责协调整个Jstorm集群。
4. Worker、Executor、Tasks以及并发度
关于Topology在Jstorm具体的机器上的执行情况需要弄清楚Topology、Worker、Executor、Tasks这几个的概念和关系以及为它们设置的并发度:
-
Worker 运行在Supervisor节点上面,被Supervisor守护进程创建的用来干活的进程。每个Worker对应于一个给定topology的全部执行任务的一个子集。就是说,一个Worker里面不会运行属于不同的topology的执行任务。
Config.setNumWorkers(conf, 5);上面的代码相当于在集群中设置了5个Worker进程来执行Topology。
-
Executor可以理解成一个Worker进程中的工作线程(一个Worker进程中可以有一个或多个Executor线程)。一个Executor中只能运行隶属于同一个component(Spout/Bolt)的task。在默认情况下,一个Executor运行一个task。Spout和Bolt设置的并发度默认就是指的Executor的数量。
builder.setSpout("MetaqSpout",// componentID new MetaqSpout(),// Spout 对象 2); // Parallelism hint, 相当于Executor的数量上面的代码相当于设置componentID为
MetaqSpout的Spout的Executor数量为2,相当于起两个线程。 -
Task则是 Spout 和 Bolt 中具体要干的活。一个 Executor 可以负责1个或多个 Task。同时,Task 也是各个节点之间进行grouping的单位。
默认情况,一个Executor对应一个Task,如果这样设置:
topologyBuilder.setBolt("green-bolt", new GreenBolt(), 2) .setNumTasks(4) .shuffleGrouping("blue-spout);相当于设置2个Executor 4个Task,这样会起两个线程,每个执行两个Task。
下图显示了一个拓扑在运行时 Task 在 Worker 中的分配情况。拓扑中有三个 Component:一个Blue Spout,一个Green Bolt一个Yellow Bolt。parallelism_hint分别为2,2,6。

对应的代码中的设置如下:
Config conf = new Config();
conf.setNumWorkers(2);
topologyBuilder.setSpout(“blue-spout”, new BlueSpout(), 2); // set parallelism hint to 2
topologyBuilder.setBolt(“green-bolt”, new GreenBolt(), 2) .setNumTasks(4) .shuffleGrouping(“blue-spout”);
topologyBuilder.setBolt(“yellow-bolt”, new YellowBolt(), 6) .shuffleGrouping(“green-bolt”);
StormSubmitter.submitTopology( “mytopology”, conf, topologyBuilder.createTopology() );
可以看出,并发度是10,总共设置了两个Worker进程,所以每个Worker起5个线程。green-bolt设置了4个Task,并发度是2,所以green-bolt一个线程里要执行两个Task。
更详细的内容见:Storm的基本概念
5. stream 的grouping 方式
一个 Bolt 可以设置为多个 Task 并发执行数据处理任务,假设订阅了一个 Spout 的 Stream,那么应该把 Spout 的数据发送给哪一个具体的Task执行,这个是由grouping的方式决定的。
Jstorm中的Grouping方式如下:
-
Shuffle Grouping:随机分组, 轮询的方式随机派发stream里面的tuple,它尽量保证订阅了数据的下一级的各个Task收到的tuple数量是相等的。Example:
假设有下一级有3个Task,数据源来了6个tuple,它可以保证前3个tuple是分别随机的发到了3个Task上,后3个也随机发到3个Task上。 -
Fields Grouping:类似SQL中的group by, 保证Stream中指定Field(一个或多个)上数据相同的tuple会发送到相同的Task,但是指定Field上数据不同也是有可能会发到一个Task上的。
原理是:对指定的Field上的数据做hash,然后用hash 结果求模得出目标taskId。Example:
假设Spout声明的输出是("Tags", "Message"),指定了按"Tags"分组,tuple是这样的:tuple1:["TagA","Message..."] tuple2:["TagA","Message..."] tuple3:["TagB","Message..."] tuple4:["TagA","Message..."]那么下一级Component的
Task收数据时,所有Tags为TagA的tuple都会被分到同一个Task上去,至于具体是哪一个Task是算出来的,没法手动指定。 -
All Grouping: 广播发送, 对于每一个tuple, 所有订阅了流的Bolts下所有Task都会收到. -
Global Grouping:全局分组,这个tuple被分配到拓扑中订阅了该流的Bolt的其中一个Task.再具体一点就是分配给id值最低的那个Task. -
Non Grouping:真正的随机发送tuple,和Shuffle Grouping不同的是不会尽量保证平均。 -
Direct Grouping:直接分组,这是一种比较特别的分组方法,用这种分组意味着消息的发送者知道由消息接收者的哪个task处理这个消息.如果声明了Direct Grouping的方式发送数据,则必须使用声明为Direct的Stream发送,而且这种消息的tuple必须使用emitDirect方法来发射。Direct的Stream在declareOutputFields(OutputFieldsDeclarer declarer)方法中声明。@Override public void declareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(true, new Fields("MessageExt")); declarer.declareStream("directStream", true, new Fields("MessageExt")); }前一个将默认的Stream声明为
Direct,后一个将另外一个directStreamStream声明为Direct。 -
Custom Grouping:Jstorm新增的一个,没看懂要怎么用^_^ -
localOrShuffleGrouping:本worker优先,如果本worker内有目标component的task,则随机从本worker内部的目标component的task中进行选择,否则就和普通的shuffleGrouping一样。
Grouping的方式是比较多的,所以要用好需要理解用到的Grouping方式的细节,也需要更多的实际项目来积攒经验。



相关推荐
Hadoop Hive HBase Spark Storm概念解释
Storm入门教程 之Storm原理和概念详解,出自Storm流计算从入门到精通之技术篇,Storm入门视频教程用到技术:Storm集群、Zookeeper集群等,涉及项目:网站PV、UV案例实战、其他案例; Storm视频教程亮点: 1、Storm...
Storm核心概念详解.md
storm on yarn概念架构消息机制概述 包括storm job跟mapreduce job对比 storm on yarn架构图 storm关键概念描述 storm消息机制介绍
01、Storm的集群搭建 04-storm部署概念.avi
01-storm简介 02-storm部署-1 03-storm部署-2 04-storm部署概念 05-streamgrouping 06-storm组件生命周期 07-storm可靠性1 08-storm可靠性2
Storm分布式实时计算模式由Apache Storm 项目核心贡献者吉奥兹、奥尼尔亲笔撰 写,融合了作者丰富的Storm实战经验,通过大量示例,全面而系统地讲解使用Storm进行分布式实 时计算的核心概念及应用,并针对不同的应用...
主分支: ##包裹包战 mvn clean package -DskipTests=true -Dwarcp ./target/storm-ui.war $TOMCAT_HOME/webapps/包装罐 mvn clean package -DskipTests=truecp ./target/storm-ui-*.jar $STORM_HOME/external/...
storm概念、基本概念、构建Topology、安装部署、消息的可靠处理
storm的入门,东西很不错!看完就算是基本入门啦!!还等什么?
详细介绍storm的概念 起源 架构 组件 原理已经应用场景描述
《Storm实战:构建大数据实时计算 》是一本系统并且具有实践指导意义的Storm工具书和参考书,对Storm整个技术体系进行了全面的讲解,不仅包括对基本概念、特性的介绍,也涵盖了一些原理说明。 实战性很强,各章节都...
Apache Storm(apache-storm-2.3.0.tar.gz) 是一个免费的开源分布式实时计算系统。Apache Storm 可以轻松可靠地处理无限制的数据流,实时处理就像 Hadoop 进行批处理一样。Apache Storm 很简单,可以与任何编程语言...
Storm Applied is a practical guide to using Apache Storm for the real-world tasks associated with processing and analyzing real-time data streams. This immediately useful book starts by building a ...
Apache Storm(apache-storm-2.3.0-src.tar.gz 源码) 是一个免费的开源分布式实时计算系统。Apache Storm 可以轻松可靠地处理无限制的数据流,实时处理就像 Hadoop 进行批处理一样。Apache Storm 很简单,可以与...
获取到文件名称 : apache-storm-0.9.2-incubating.tar.gz 获取到文件名称 : Learning Storm [eBook].pdf 获取到文件名称 : Storm Blueprints.Patterns.pdf 获取到文件名称 : storm01.rar 获取到文件名称 : storm...
Storm实时数据处理
《大数据技术丛书:Storm实时数据处理》通过丰富的实例,系统讲解Storm的基础知识和实时数据处理的最佳实践方法,内容涵盖Storm本地开发环境搭建、日志流数据处理、Trident、分布式远程过程调用、Topology在不同...
Storm官方网站有段简介 Storm是一个免费并开源的分布式实时计算系统。利用Storm可以很容易做到可靠地处理无限的数据流,像Hadoop批量处理大数据一样,Storm可以实时处理数据。Storm简单,可以使用任何编程语言。