作者: jillzhang
联系方式:jillzhang@126.com
C语言和C#语言中,对于浮点类型的数据采用单精度类型(float)和双精度类型(double)来存储,float数据占用32bit,double数据占用64bit,我们在声明一个变量float f= 2.25f的时候,是如何分配内存的呢?如果胡乱分配,那世界岂不是乱套了么,其实不论是float还是double在存储方式上都是遵从IEEE的规范的,float遵从的是IEEE R32.24 ,而double 遵从的是R64.53。
无论是单精度还是双精度在存储中都分为三个部分:
- 符号位(Sign) : 0代表正,1代表为负
- 指数位(Exponent):用于存储科学计数法中的指数数据,并且采用移位存储
- 尾数部分(Mantissa):尾数部分
其中float的存储方式如下图所示:
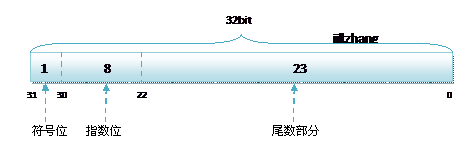
1 8 23
符号位 指数位 尾数部分
而双精度的存储方式为:

1 11 52
符号位 指数位 尾数部分
R32.24和R64.53的存储方式都是用科学计数法来存储数据的,比如8.25用十进制的科学计数法表示就为:8.25*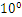 ,而120.5可以表示为:1.205*
,而120.5可以表示为:1.205* ,这些小学的知识就不用多说了吧。而我们傻蛋计算机根本不认识十进制的数据,他只认识0,1,所以在计算机存储中,首先要将上面的数更改为二进制的科学计数法表示,8.25用二进制表示可表示为1000.01,我靠,不会连这都不会转换吧?那我估计要没辙了。120.5用二进制表示为:1110110.1用二进制的科学计数法表示1000.01可以表示为1.00001*
,这些小学的知识就不用多说了吧。而我们傻蛋计算机根本不认识十进制的数据,他只认识0,1,所以在计算机存储中,首先要将上面的数更改为二进制的科学计数法表示,8.25用二进制表示可表示为1000.01,我靠,不会连这都不会转换吧?那我估计要没辙了。120.5用二进制表示为:1110110.1用二进制的科学计数法表示1000.01可以表示为1.00001*![clip_image002[2]](http://images.cnblogs.com/cnblogs_com/jillzhang/WindowsLiveWriter/float_A919/clip_image002%5B2%5D_thumb_1.gif) ,1110110.1可以表示为1.1101101*
,1110110.1可以表示为1.1101101*![clip_image002[3]](http://images.cnblogs.com/cnblogs_com/jillzhang/WindowsLiveWriter/float_A919/clip_image002%5B3%5D_thumb_1.gif) ,任何一个数都的科学计数法表示都为1.xxx*
,任何一个数都的科学计数法表示都为1.xxx*![clip_image002[1]](http://images.cnblogs.com/cnblogs_com/jillzhang/WindowsLiveWriter/float_A919/clip_image002%5B1%5D_thumb_1.gif) ,尾数部分就可以表示为xxxx,第一位都是1嘛,干嘛还要表示呀?可以将小数点前面的1省略,所以23bit的尾数部分,可以表示的精度却变成了24bit,道理就是在这里,那24bit能精确到小数点后几位呢,我们知道9的二进制表示为1001,所以4bit能精确十进制中的1位小数点,24bit就能使float能精确到小数点后6位,而对于指数部分,因为指数可正可负,8位的指数位能表示的指数范围就应该为:-127-128了,所以指数部分的存储采用移位存储,存储的数据为元数据 127,下面就看看8.25和120.5在内存中真正的存储方式。
,尾数部分就可以表示为xxxx,第一位都是1嘛,干嘛还要表示呀?可以将小数点前面的1省略,所以23bit的尾数部分,可以表示的精度却变成了24bit,道理就是在这里,那24bit能精确到小数点后几位呢,我们知道9的二进制表示为1001,所以4bit能精确十进制中的1位小数点,24bit就能使float能精确到小数点后6位,而对于指数部分,因为指数可正可负,8位的指数位能表示的指数范围就应该为:-127-128了,所以指数部分的存储采用移位存储,存储的数据为元数据 127,下面就看看8.25和120.5在内存中真正的存储方式。
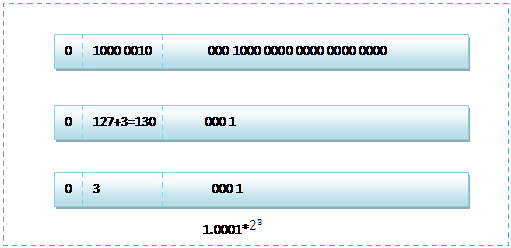
首先看下8.25,用二进制的科学计数法表示为:1.00001*
按照上面的存储方式,符号位为:0,表示为正,指数位为:3 127=130 ,位数部分为,故8.25的存储方式如下图所示:
而单精度浮点数120.5的存储方式如下图所示:
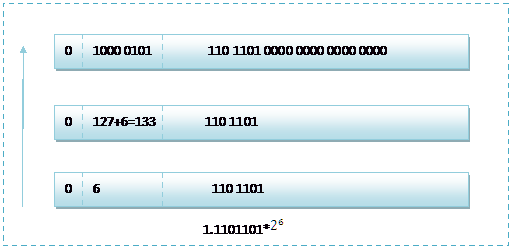
那么如果给出内存中一段数据,并且告诉你是单精度存储的话,你如何知道该数据的十进制数值呢?其实就是对上面的反推过程,比如给出如下内存数据:0100001011101101000000000000,首先我们现将该数据分段,0 10000 0101 110 1101 0000 0000 0000 0000,在内存中的存储就为下图所示:

根据我们的计算方式,可以计算出,这样一组数据表示为:1.1101101*=120.5
而双精度浮点数的存储和单精度的存储大同小异,不同的是指数部分和尾数部分的位数。所以这里不再详细的介绍双精度的存储方式了,只将120.5的最后存储方式图给出,大家可以仔细想想为何是这样子的

下面我就这个基础知识点来解决一个我们的一个疑惑,请看下面一段程序,注意观察输出结果
float f = 2.2f;
double d = (double)f;
Console.WriteLine(d.ToString("0.0000000000000"));
f = 2.25f;
d = (double)f;
Console.WriteLine(d.ToString("0.0000000000000"));
可能输出的结果让大家疑惑不解,单精度的2.2转换为双精度后,精确到小数点后13位后变为了2.2000000476837,而单精度的2.25转换为双精度后,变为了2.2500000000000,为何2.2在转换后的数值更改了而2.25却没有更改呢?很奇怪吧?其实通过上面关于两种存储结果的介绍,我们已经大概能找到答案。首先我们看看2.25的单精度存储方式,很简单 0 1000 0001 001 0000 0000 0000 0000 0000,而2.25的双精度表示为:0 100 0000 0001 0010 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000,这样2.25在进行强制转换的时候,数值是不会变的,而我们再看看2.2呢,2.2用科学计数法表示应该为:将十进制的小数转换为二进制的小数的方法为将小数*2,取整数部分,所以0.282=0.4,所以二进制小数第一位为0.4的整数部分0,0.4×2=0.8,第二位为0,0.8*2=1.6,第三位为1,0.6×2 = 1.2,第四位为1,0.2*2=0.4,第五位为0,这样永远也不可能乘到=1.0,得到的二进制是一个无限循环的排列 00110011001100110011... ,对于单精度数据来说,尾数只能表示24bit的精度,所以2.2的float存储为:

但是这样存储方式,换算成十进制的值,却不会是2.2的,应为十进制在转换为二进制的时候可能会不准确,如2.2,而double类型的数据也存在同样的问题,所以在浮点数表示中会产生些许的误差,在单精度转换为双精度的时候,也会存在误差的问题,对于能够用二进制表示的十进制数据,如2.25,这个误差就会不存在,所以会出现上面比较奇怪的输出结果。
本文属作者原创,只发布在博客园,希望大家在转载的时候,注明出处和作者,谢谢。





相关推荐
浮点数在内存中的存储机制和整型数不同,其有舍入误差,在计算机中用近似表示任意某个实数。具体的说,这个实数由一个整数或定点数(即尾数)乘以某个基数(计算机中通常是2)的整数次幂得到,这种表示方法类似于...
将32bit的float型数据 转换为 64bit的double类型存储在内存中,跨平台可用。解决C51等平台double类型为32bit存储的问题。
其区别在于,float,double等非标准类型,在DB中保存的是近似值,而Decimal则以字符串的形式保存数值。 float,double类型是可以存浮点数(即小数类型),但是float有个坏处,当你给定的数据是整数的时候,那么它就...
double与8位16进制互转;float与4位16进制互转。处理发送的消息,或者收到的消息很方便。
结合图释详细介绍浮点数的计算机存储结构。解释了IEEE有关浮点数的标准。
C语言和C#语言中,对于浮点类型的数据采用单精度类型(float)和双精度类型(double)来存储,float数据占用32bit, double数据占用64bit
NULL 博文链接:https://canlynet.iteye.com/blog/1796889
STM32Flash闪存存储参考,支持多种类型操作(double,float等),已封装,便于移植
c语言中的float , double 等数据类型的存储,如何计算 , 如何用vc vs查看内存
C语言和C#语言中,对于浮点类型的数据采用单精度类型(float)和双精度类型(double)来存储,float数据占用32bit,double数据占用64bit,我们在声明一个变量float f= 2.25f的时候,是如何分配内存的呢?如果胡乱分配,...
奇怪输出结果:首先我们看看2.25的单精度存储方式,2.25 --> 10.01 --> 1.001*21符号位0,指数部分1+127 --> 10000000
在计算机中,用float或double来存储小数有时不能得到精确值,若要精确表达一个浮点数的计算结果, 最好用分数来表示小数,有限小数或无限循环小数都可以转化为分数,无限循环小数的循环节用括号标记出来。如: 0.9 =...
浮点类型:float、double 字符类型:char 布尔类型:boolean 这些基本数据类型在Java中用于存储不同类型的数据值,它们分别占用不同的内存空间,并具有不同的取值范围。在Java中,基本数据类型是直接存储在栈内存中...
如果在以上声明中不使用后缀,则会因为您尝试将一个 double值存储到 float 变量中而发生编译错误。 float的取值范围 float占用4个字节,和int是一样,也就是32bit. 1bit(符号位) 8bits(指数位) 23bits(尾数位) ...
float存储格式及FPU float存储格式及FPU 浮点数用科学计数法的形式存储, 即分成符号位, 底数位和指数位 如 10.0 的二进制表示为 1010.0, 科学表示法表示为: 1.01exp110, 即 (1+0*1/2+1*1/4)*2^3. 小数点每左移一位...
在JAVA中,通常使⽤的浮点数的类型为 FLoat和Double,他们的区别在于⼤⼩与储存⽅式不同 public class App { public static void main(String[] args) { System.out.println("Float:"+Float.SIZE); System.out....
问题4:FLOAT和DOUBLE的区别是什么? FLOAT类型数据可以存储至多8位十进制数,并在内存中占4字节。 DOUBLE类型数据可以存储至多18位十进制数,并在内存中占8字节。 问题5:如何在MySQL种获取当前...
C语言和C#语言中,对于浮点类型的数据采用单精度类型(float)和双精度类型(double)来存储,float数据占用32bit, double数据占用64bit,我们在声明一个变量float f= 2.25f的时候,是如何分配内存的呢?如果胡乱分配,...
分别定义float,double类型的变量各一个,并依次输出它们的存储空间大小(单位:字节)。 【输入】 (无) 【输出】 一行,两个整数,分别是两个变量的存储空间大小,用一个空格隔开。 【输入样例】 (无) 【输出...
C语言和C#语言中,对于浮点类型的数据采用单精度类型(float)和双精度类型(double)来存储,float数据占用32bit,double数据占用64bit,我们在声明一个变量float f= 2.25f的时候,是如何分配内存的呢?如果胡乱分配,...