
ŠŚÂŔç│ń╗ŐŠŚą´╝îzookeeperňťĘňłćňŞâň╝ĆšÜäň║öšöĘňť║ŠÖ»ňĚ▓š╗ĆňĄÜŔÂŐŠŁąŔÂŐňĄÜń║ć´╝î Š»öňŽéŔžúňć│hbasešÜähmasterňŹĽšé╣ÚŚ«Úóś´╝îňłćňŞâň╝ĆÚöü´╝îňłćňŞâň╝ĆÚśčňłŚ´╝îÚŤćšżĄŠť║ňÖĘšŤĹŠÄžšşëšşëŃÇézookeeperŠĆÉńżŤšÜäňŐčŔâŻňîůŠőČ´╝ÜÚůŹšŻ«š╗┤ŠŐĄŃÇüňÉŹňşŚŠťŹňŐíŃÇüňłćňŞâň╝Ć ňÉąŃÇüš╗䊝ŹňŐíšşëŃÇéŔÇîňťĘň╝ĽŠôÄňÉÄňĆ░ŠĽ░ŠŹ«ňĄäšÉćš│╗š╗čÚçîŠÇÄń╣łńŻ┐šöĘzookeeperšÜäňĹó´╝čń╗ąňĆŐňťĘńŻ┐šöĘŔ┐çšĘőńŞşÚüçňł░Úéúń║ŤÚŚ«ÚóśňĹó´╝č ÚŽľňůł´╝îń╗őš╗ŹńŞÇńŞőzookeeper
-
zookeeperš«Çń╗ő
┬á ┬á ┬á ┬á┬á ┬á 1´╝ëWhy zookeeper?
┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á 2´╝ëWhat┬á Is Zookeeper ?
ň«âŠś»ApacheHadoopšÜäńŞÇńެňşÉÚí╣šŤ«´╝îň«âńŞ╗ŔŽüšöĘŠŁąŔžúňć│ňłćňŞâň╝ĆÚŤćšżĄńŞşň║öšöĘš│╗š╗čšÜäńŞÇŔç┤ŠÇžÚŚ«Úóś´╝îŠĆÉńżŤňč║ń║Äš▒╗ń╝╝ń║ÄŠľçń╗š│╗š╗čšÜ䚍«ňŻĽŔŐéšé╣ŠáĹŠľ╣ň╝ĆšÜ䊼░ŠŹ«ňşśňéĘŃÇéÚÖĄń║押░ŠŹ«ňşśňéĘ´╝îň«âŔ┐śňĆ»ń╗ąšöĘŠŁąš╗┤ŠŐĄňĺŊĞńŻáňşśňéĘšÜ䊼░ŠŹ«šÜäšŐŠÇüňĆśňîľŃÇéń╗ÄŔ«żŔ«íŠĘíň╝ĆŔžĺň║ŽŠŁąň«âŔ⯚ťő´╝îZookeeperŠś»ńŞÇńެňč║ń║ÄŔžéň»čŔÇůŠĘíň╝ĆŔ«żŔ«íšÜäňłćňŞâň╝ĆŠťŹňŐíš«íšÉćŠíćŠ×´╝îň«âŔ┤čŔ┤úňşśňéĘňĺîš«íšÉćňĄžň«ÂÚâŻňů│ň┐âšÜ䊼░ŠŹ«´╝îšäÂňÉÄŠÄąňĆŚŔžéň»čŔÇůšÜäŠ│Ęňćî´╝îńŞÇŠŚŽŔ┐Öń║ŤŠĽ░ŠŹ«šÜäšŐŠÇüňĆĹšöčňĆśňîľ´╝îZookeeperň░▒ň░ćŔ┤čŔ┤úÚÇÜščąÚéúń║ŤňĚ▓š╗ĆŠ│ĘňćîšÜäŔžéň»čŔÇůňüÜňç║šŤŞň║öšÜäňĆŹň║öŃÇé
┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á 3´╝ëWhat zk looks like?
ńŞŐÚŁóŔ»┤Ŕ┐ç´╝îš▒╗ń╝╝ń║ÄŠľçń╗š│╗š╗č´╝î Šś»Šľçń╗š│╗š╗čŠĘíň×őŃÇé ňŽéňŤż´╝Ü
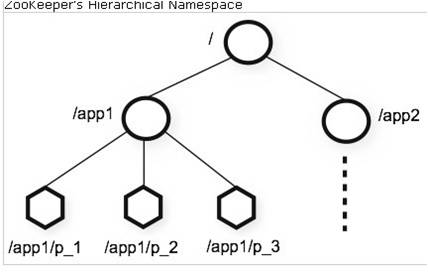
Š│Ę´╝ÜšŤ«ňŻĽŔŐéšé╣ňĆ»ń╗ąňşśň░ĹÚçĆŠĽ░ŠŹ«´╝ł<1M´╝ëŃÇé
           4) How ZK Work?
zookeeperňŽéńŻĽŔžúňć│ňĚąńŻť´╝îňŽéńŻĽŔžúňć│ńŞÇŔç┤ŠÇžÚŚ«ÚóśšÜäňĹó´╝čzookeeperÚŤćšżĄňÉ»ňŐĘŠŚÂ´╝îń╝ÜÚÇëńŞżňç║ńŞÇńެleader server´╝î ňůÂń╗ľserverňč║ŠťČň░▒Šś»followerń║ćŃÇé ŠëÇŠťëšÜäserverÚâŻń┐Łňşśň«îŠĽ┤ńŞÇń╗ŻŠĽ░ŠŹ«´╝î ŠëÇŠťëšÜäserver´╝łňÉźleader´╝ëÚâŻŔâŻň»╣ňĄľŠťŹňŐíŃÇé ňŻôŠťëňćÖŔ»ĚŠ▒銌´╝îÚÇÜŔ┐çÚÇëńŞżš«ŚŠ│ĽŔÄĚňżŚleaderšÜäňÉîŠäĆŠëŹŔ⯚ö芼ł´╝Ť ňŻôŠťëŔ»╗Ŕ»ĚŠ▒銌´╝îňĄäšÉćŔ»ąŔ»ĚŠ▒éšÜäserveršŤ┤ŠÄąŔÄĚňĆľŠťČňť░ŠĽ░ŠŹ«Ŕ┐öňŤ×š╗Öclientšź»ŃÇé

-
zookeeperňťĘšŽ╗š║┐ŠĽ░ŠŹ«ňĄäšÉćšÜäńŻ┐šöĘ
ŔÖŻšäÂzookeeperŔâŻŔžúňć│ňżłňĄÜňłćňŞâň╝ĆńŞŐšÜäÚŚ«Úóś´╝╗š║┐ŠĽ░ŠŹ«ňĄäšÉćňťĘńŻ┐šöĘńŞŐŔ┐śŠś»Úüçňł░ńŞÇń║ŤzookeeperńŞŹŠ╗íŔÂ│š│╗š╗čڝNJ▒éšÜäňť░Šľ╣´╝Ü
1´╝ë zookeeperš╗ÖšöĘŠłĚŠĆÉńżŤš╗ÖšöĘŠłĚńŻ┐šöĘňĚąňůĚŠťë´╝Üjava/c/pythonšÜäšşëň«óŠłĚšź»´╝îňÉÄňĆ░ňĹŻń╗ĄŔíîňĚąňůĚŠťëzkCli.sh´╝îzkServer.shšşë´╝î Ŕ┐śŠťëňŤŤňşŚňĹŻń╗Ą´╝łŠťëruok´╝îstat´╝îmntr´╝îconf´╝îconsšşë´╝îŔ┐Öń║ŤňĹŻń╗Ąň»╣ń║ÄŔ┐Éš╗┤ňŹüňłćÚçŹŔŽü´╝îňů│ń║ÄňŤŤňşŚńŻ┐šöĘňĆéŔÇâ http://zookeeper.apache.org/doc/trunk/zookeeperAdmin.html#sc_zkCommands´╝ë šşëŃÇé ┬á ńŻćŠś»ň╣Š▓튝ëŠĆÉńżŤwebÚíÁÚŁóŠľ╣ńż┐ńżŤšöĘŠłĚŠčąšťőzookeeperńŞŐšÜäŔŐéšé╣ŠĽ░ŠŹ«ŃÇéňŽéŠ×ťŠ»ĆŠČíÚâŻńŻ┐šöĘňĹŻń╗ĄŔíîňĚąňůĚňÄ╗ŠčąšťőŔŐéšé╣ŠĽ░ŠŹ«´╝îňĚąńŻťŠĽłšÄçńŻÄńŞőŃÇé
2´╝ëňŻôňĄÜńެšöĘŠłĚňů▒ňÉîńŻ┐šöĘńŞÇńެzookeeperÚŤćšżĄ´╝îň╣ÂńŞöŠ»ĆňĄęŠľ░ňó×ńŞÇń║ŤŠľ░šÜäzookeeperŔŐéšé╣ňĺ░ŠŹ«ŠŚÂ´╝ÂÚŚ┤ÚĽ┐ń║ćň░▒ŔŽüŔžúňć│ńŞÇńŞ¬ÚŚ«Úóś´╝ÜZookeeperńŞŐŔ┐犝čńŞŹšöĘšÜäŔŐéšé╣ňĺ░ŠŹ«ÚťÇŔŽüňŤ×ŠöÂŃÇé
3´╝ëzookeeperńŞŐŔŐéšé╣Šś»ńŞŹňłćŠĽ░ŠŹ«ŔŐéšé╣ňĺ«ňŻĽŔŐéšé╣šÜäŃÇéŔ┐Öšé╣ŔĚčń╝áš╗čšÜälinuxŠľçń╗š│╗š╗čńŞŹňÉîŃÇéňŽéŠ×ťň║öšöĘňť║ŠÖ»ň»╣ŔŐéšé╣ÚťÇŔŽüňłćš▒╗ŠŚÂ´╝îň║öšöĘšĘőň║ĆŔç¬ŔíîŔžúňć│ŃÇé
Úĺł ň»╣ń╗ąńŞŐ3šé╣šÜäńŞŹńż┐´╝î šŽ╗š║┐ňĄäšÉćš│╗š╗čň»╣zookeeper┬áclientňüÜń║ćńŞÇň▒éň░üŔúů´╝îň░üŔúůňÉÄšÜäzookeeper clientňĆźňüÜresource┬ázookeeper´╝îš«Çšž░reskeeperŃÇéreskeeperňłćňłźň«×šÄ░ń║ćň»╣zookeeperšÜä java´╝îc´╝îpythonšÜäň░üŔúůŃÇéšÄ░ňťĘŠő┐reskeeperšÜäjava clientŔ»┤ŠśÄreskeeperšÜäŠ×Š×äŃÇé

ňťĘreskeeperÚçî´╝îzookeeperŠ»ĆńŞÇńެnodeň░▒Šś»ńŞÇńެResource´╝îŔóźňłćńŞ║3ńެš▒╗ň×ő´╝Ü
1´╝ëinfo,┬ášöĘŠŁąňşśňéĘÚçŹŔŽüń┐íŠü»šÜä´╝îňůÂnodeňĆ»ňşśňéĘšÜädataŠś»Mapš╗ôŠ×äšÜäŃÇé
2´╝ëuri´╝îńŞôÚŚĘšöĘŠŁąňşśurlšÜä
3´╝ëdir´╝îńŞÄlinuxš│╗š╗čšÜ䚍«ňŻĽŠś»ńŞÇńެŠŽéň┐ÁŃÇé
ňůÂńŞşResourceŠťëńެÚçŹŔŽüň▒׊Ǟetime´╝îŔíĘšĄ║Ŕ┐ÖńެnodešÜäŔ┐犝芌ÂÚŚ┤´╝îš▒╗ń╝╝ń║ÄhbasešÜättl´╝ëňůÂń╗ľšĘőň║ĆńŞôÚŚĘňłáÚÖĄzookeeperńŞŐŔ┐犝čšÜänodeŃÇéńŞ║ń║抾╣ńż┐ňťĘwebńŞŐň«×šÄ░´╝îŔ┐Öń║ŤResourceŠëÇň»╣ň║ödataňşśňůąŠś»jsonŠá╝ň╝ĆšÜäŃÇé
ň»╣ň║öšÜäwebŠś»ÚíÁÚŁóšÜäŠáĚňşÉńŞ║´╝Ü

ŠÇ╗ńŻôńŞŐŔ«▓´╝╗š║┐ŠĽ░ŠŹ«ňĄäšÉćš│╗š╗čň»╣zookeeperšÜäň║öšöĘšÜäňť║ŠÖ»Šťë´╝Ü
1´╝뚎╗š║┐ŠĽ░ŠŹ«ňĄäšÉćš│╗š╗čňůĘÚçĆňĺîňó×ÚçĆšÜäňŹĆŔ░⊜»ÚÇÜŔ┐çzookeeperŠŁąň«×šÄ░šÜäŃÇéńżőňŽéňŻôňůĘÚçĆšÜäjobŔÁĚŠŁąŠŚÂ´╝┤Šľ░zkńŞŐÔÇŽ/statusšÜ䊼░ŠŹ«ńŞ║ suspendŃÇé ňó×ÚçĆšÜäjobŠś»24ň░ĆŠŚÂň╝ÇňÉ»šÜä´╝îńŻćŠ»ĆŠČíňó×ÚçĆšÜäjobňÉ»ňŐĘŠŚÂ´╝îń╝ÜňÄ╗ŠúÇŠÁőÔÇŽ/statusšÜ䊼░ŠŹ«´╝îňŽéŠ×ťňĆĹšÄ░ňůĘÚçĆjobŠşúňťĘŔ┐ÉŔíî´╝îň░▒ÚÇÇňç║ŠŁąŃÇé
2´╝ëńŞÄň╝ĽŠôÄšŽ╗š║┐buildŠĘíňŁŚŠĽ░ŠŹ«ń║Ąń║ĺšÜäňĚąńŻťń╣芜»ÚÇÜŔ┐çzookeeperŠŁąňŹĆŔ░âšÜäŃÇ銻öňŽéń╗ŐňĄęšÜäňůĘÚçĆxmlŠľçń╗šö芳ÉňąŻń║ć´╝îń╝ÜňťĘzkšöč ŠłÉÔÇŽ/product/20130910_233949´╝îŔ»ąŔŐéšé╣ńŞ║uriš▒╗ň×ő´╝î ňÇ╝ńŞ║´╝Ühdfs://namenode:9000ÔÇŽ/product_20130910_233949
3´╝ëÚçŹŔŽüń┐íŠü»ňşśňůązookeeper´╝îŔ┐Öš▒╗ń┐íŠü»šÜäšë╣šé╣Šś»ňşśňéĘšÜäňćůň«╣Š»öŔżâň░ĹŃÇéńżőňŽé´╝ĆňĄęš▓żňŹźń╗╗ňŐíŔžúŠ×ÉŠĽ░ŠŹ«ň║ôšÜäbinlogšÜ䊌ÂÚŚ┤Šł│ń╝Üń┐ŁňşśňťĘzookeeperńŞŐ´╝îń╗ąńżŤň╝ĽŠôÄńŻťňŤ×Š║»šöĘŃÇé
4´╝ëňłćňŞâÚöüŃÇéňĄÜńެmapreducešÜätaskňů▒šöĘšź×ń║ëÚöü´╝îŔÄĚňżŚÚöüňÉÄňĆ»ń╗ąňĄäšÉćŠčÉńŞÇšë╣ň«ÜšÜäń╗╗ňŐíŃÇé
-
Úüçňł░šÜäÚŚ«Úóś´╝îŔŞęŔ┐çšÜäňŁĹ
Ŕç¬ń╗Ä2011ň╣┤ńŻ┐šöĘzookeeperń╗ąŠŁą´╝îš║┐ńŞŐń╣čÚüçňł░ńŞÇń║ŤÚŚ«Úóś´╝Ü
ńŞÇ´╝ë┬ázookeeperńŞÄhbasešÜäregion serverŔ┐ŤšĘőňů▒ňÉîńŻ┐šöĘńŞÇňĆ░Šť║ňÖĘŃÇéŔ┐ÖŠś»ňťĘňłÜńŻ┐šöĘzookeeperŠŚÂň«╣ŠśôňĆĹšöčšÜäÚŚ«Úóś´╝îń╗ąńŞ║zookeeperňŹášöĘŔÁäŠ║Éň░Ĺ´╝îňĆ»ń╗ąňĺîňůÂń╗ľšĘőň║ĆńŞÇŔÁĚŔ┐ÉŔíîňťĘňÉîńŞÇňĆ░Šť║ňÖĘńŞŐŃÇéŔ┐ÖÚçĹń╗Čňç║šÄ░Ŕ┐çńŞąÚ珚ÜäÚŚ«Úóś´╝îhbaseÚŤćšżĄšÜäregion serverŠîéń║ćńŞÇňĄžšëç´╝îÚŤćšżĄňč║ŠťČńŞŹňĆ»šöĘŃÇé ňŻôhbaseÚŤćšżĄŠťëŔżâňĄžňÄőňŐŤŠŚÂ´╝îRSŔ┐׊ĹzookeeperŔÂůŠŚÂ´╝îŔ«ĄńŞ║Ŕç¬ňĚ▒Šś»ŠŚáŠĽłšÜäRSń║ćŃÇé Ŕ┐Öńެš«ŚŠś»ňŞŞŔžüšÜäÚŚ«Úóśń║ć´╝îšťőńŞÇŔłČzookeeperńŻ┐šöĘš╗ĆÚ¬î´╝îÚâŻň╗║Ŕ««šőČšźőšÜäzk server´╝îňô¬ŠÇĽŠť║ňÖĘňĚ«ńŞÇšé╣ŃÇé
ń║î´╝ëňů│ń║ÄzookeeperňłŁňžőŔ┐׊ĹšÜäÚŚ«ÚóśŃÇéÚôżŠÄązookeeperňĄ▒Ŕ┤ą´╝îÚöÖŔ»»ń┐íŠü»ňŽéńŞő´╝Ü
13/04/08 10:41:40 INFO zookeeper.ClientCnxn: Opening socket connection to server dump002010.cm6.tbsite.net/10.246.2.10:2181
13/04/08┬á10:41:41┬áWARN┬ázookeeper.ClientCnxn:┬áSession┬á0├Ś0┬áfor┬áserver┬ánull,┬áunexpected┬áerror,┬áclosing┬ásocket┬áconnection┬áand┬áattempting┬áreconnect
java.net.ConnectException: Connection refused
ÚöÖŔ»»ń╗úšáüňŽéńŞő´╝Ü
try {
zk = new ZooKeeper(ParseArgs.fullScanConf.hc.HbaseQuorum, 10000000,  new NullWatcher());
zdata = zk.getData(ParseArgs.fullScanConf.hc.HbaseZKNode+ParseArgs.HTABLE, false, null);┬á ÔÇŽÔÇŽ
new Zookeeperň»╣Ŕ▒íňÉÄň░▒šźőňł╗ńŻ┐šöĘzkň»╣Ŕ▒íňÄ╗Ŕ»╗ňĆľŠĽ░ŠŹ«´╝îŔ┐ÖÚçîzkň»╣Ŕ▒íŔ┐׊ĹserverŠś»ň╝銺ąšÜä´╝îń╣čŠ▓튝ëňÄ╗ŠúÇŠčązkň»╣Ŕ▒íšÜäšŐŠÇüŠşúňŞŞňÉŽ´╝łňĆ»ń╗ąÚÇÜŔ┐ç getStateŠľ╣Š│ĽŔÄĚňĆľ´╝ë´╝îň░▒šźőňł╗Ŕ░âšöĘgetData´╝îŠŐąÚöÖConnectExceptionŔÇîÚÇÇňç║šÜäňĆ»Ŕ⯊Ǟڣ×ňŞŞňĄžŃÇ銳Ĺń╗ČšÜäńŞĄńެŔžúňć│Šľ╣ŠíłŠŚÂŠś»´╝Ü
1´╝ëÚÇÜŔ┐çzkň»╣Ŕ▒íšÜägetStateŠľ╣Š│Ľ´╝îšťőStatusŠś»ňÉŽńŞ║ÔÇÖCONNECTEDÔÇś´╝îňŽéŠ×ťńŞŹŠś»ňż¬šÄ»šşëňżůšŤ┤ňł░statusňĆśńŞ║ÔÇÖCONNECTEDÔÇśŃÇé
2´╝ëňťĘnew Zookeeperň»╣Ŕ▒튌Âń╝áňůąňĆ銼░Watcherň»╣Ŕ▒í´╝îňĆ»ń╗ąÚÇÜŔ┐çWatcherň»╣Ŕ▒íŠčąšťőWatcherš▒╗šÜäprocessň篊Ľ░ŠťëŔ󟊺úší«ŠëžŔíîŔ┐çń╣ł´╝芺úňŞŞŠâůňćÁ ńŞő´╝îŔ┐׊Ĺzk serverňÉÄWatcheršÜäprocessň篊Ľ░ń╝ÜŔóźŠëžŔíîńŞÇŠČíšÜäŃÇé
ńŞë´╝ë┬áOut┬áof memoryÚŚ«ÚóśŃÇé┬ášÄ░Ŕ▒튜»zkšÜäŔ┐ŤšĘőÚâŻňťĘ´╝î ň░▒Šś»ńŞŹŠÄąňĆŚŠľ░šÜäŔ»ĚŠ▒é´╝îŠčąšťőlogŠŐąÚöÖňŽéńŞő´╝Ü
at java.net.PlainSocketImpl.socketConnect(Native Method)
at java.net.PlainSocketImpl.doConnect(PlainSocketImpl.java:333)
at java.net.PlainSocketImpl.connectToAddress(PlainSocketImpl.java:195)
ňŻôŠŚÂšťőzk serveršÜäŔ┐ŤšĘőšÜägcŠâůňćÁňŽéńŞő´╝Ü

ŠśÄŠśżŠś»šö▒ń║Äzk nodeňĺîdatašÜäňó×ňŐá´╝îňŹášöĘňĄ¬ňĄÜšÜäzk┬á serverŔ┐ŤšĘőšÜäňćůňşś´╝îň»╝Ŕç┤OOMŃÇéŠÇÄń╣łŔžúňć│Ŕ┐ÖńŞ¬ÚŚ«Úóś?ńŞŹňĆ»Ŕ⯊ŐŐzk nodeŠŞůšÉćńŞÇń║ŤšÜä´╝îŔ┐ÖňĆ»Šś»š║┐ńŞŐšÜäň║öšöĘ´╝ëňĄ¬ňĄÜšÜäÚçŹŔŽüń┐íŠü»ŃÇéňƬŔâŻňó×ňŐázk┬á serverŔ┐ŤšĘőjvmšÜäňćůňşśňĄžň░ĆŃÇé ňůĚńŻôňüÜŠ│ĽňĆ»ń╗ąňĆéšůž´╝Ühttp://blog.csdn.net/yioadgjn/article/details/8209154ŃÇé┬áňÉšŁúń┐âň║öšöĘŠŐŐńŞŹ ÚťÇŔŽüšÜäŔ┐犝čšÜäzk nodeňłáÚÖĄŠÄëŃÇé
ňŤŤ´╝ëtoo open filesÚŚ«ÚóśŃÇé┬ášÄ░Ŕ▒튜»ŔĚčńŞŐÚŁóšÜäŠâůňćÁňĚ«ńŞŹňĄÜ´╝îlogÚçîŠŐąÚöÖŠś»Ŕ»┤too open filesŃÇéńŞ║ń╗Çń╣łń╝ÜŠŐąŔ┐ÖńެÚöÖňĹó´╝čňÄčňŤáŠś»ň«óŠłĚšź»ŔÂŐŠŁąŔÂŐňĄÜ´╝îsocketń╣čńŞŹňĄčšöĘń║ćŃÇéšöĘulimit -ańŞÇšťő´╝îopen filesńŞ║10240´╝î Š▓튝ëŔ░âňł░ŠťÇňĄžňÇ╝65535ŃÇéÚÇÜŔ┐çń┐«Šö╣linuxš│╗š╗čňĆ銼░´╝îÚçŹňÉ»zk Ŕ┐ŤšĘőŔžúňć│ń║ć ŃÇé
ŠÇ╗ń╣ő´╝îzookeeperšŤŞň»╣hadoopňĺîhbaseŠŁąŔ»┤´╝»ŠŤ┤šĘ│ň«ÜšÜäš│╗š╗čŃÇézookeeperń╗úšáüŠ»öŔżâš«ÇŠ┤üŠśôŠçé´╝îÚÇéňÉłň»╣ňłćňŞâň╝ĆŠäčňů┤ŔÂúšÜäňłŁňşŽŔÇůšáöŔ»╗ŃÇé
ňĆéŔÇ⊾çšî«´╝Ü
http://zookeeper.apache.org/doc/trunk/
https://cwiki.apache.org/confluence/display/ZOOKEEPER/Index
 
ŔŻČŔ笊̜ň«Ł´╝Ühttp://www.searchtb.com/2014/03/zookeeper-in-offline-computing.html
 



šŤŞňů│ŠÄĘŔŹÉ
eclipseň«ëŔúůzookeeperŠĆĺń╗ÂňĄ▒Ŕ┤ąšÜä´╝îňĆ»ň░ŁŔ»Ľń╗ąŠşĄŠľ╣ň╝ĆšŽ╗š║┐ň«ëŔúůzookeeperŠĆĺń╗ÂŃÇé´╝łŔë»ň┐âŠĆÉšĄ║´╝ÜšöĘŠŤ┤ÚźśšëłŠťČšÜäeclipseň░▒ňąŻń║ć´╝ë
ŠťČŠľ╣ŠíłÚççšöĘš╗čń┐í UOS ŠôŹńŻťš│╗š╗č+Storm+Zookeeper š╗ôňÉłŔ┐ŤŔíîŔ«żŔ«í´╝îń╗ą Storm ńŞ║ňč║šíÇšÜäňłćňŞâň╝ĆÚŤćšżĄš│╗š╗č´╝îŠÉşÚůŹ Apache ň╝ÇŠ║Éš│╗š╗čńŞşšÜäň║öšöĘšĘőň║ĆňŹĆŔ░⊝ŹňŐí Zookeeper šÜäňłćňŞâň╝Ćň«×ŠŚÂňĄžŠĽ░ŠŹ«ňĄäšÉćŠíćŠ×ÂŃÇé ńŻ┐šöĘ UOS š╗čń┐튝ŹňŐíňÖĘŠôŹńŻťš│╗š╗čńŞ║...
ZooKeeper Šť¬ŠÄłŠŁâŔ«┐ÚŚ«Š╝ĆŠ┤×ňĄäšÉ抾╣Š│ĽňĺîÚçŹŔ«żsetAcl,ÚťÇŔŽüŔ«żšŻ«ŔÂůš║žš«íšÉćň»ćšáüňÉÄ´╝╣ňĆ»ń┐«Šö╣
ÚÇÜŔ┐çňłćŠ×ÉZABňŹĆŔ««šÜäńŞĄňĄžŠáŞň┐âňŐčŔ⯴╝ÜŠÂłŠü»ň╣┐Šĺşňĺîň┤ęŠ║âŠüóňĄŹ´╝ȊľçŠĆşšĄ║ń║ćZookeeperňťĘňĄäšÉćÚŤćšżĄŠĽ░ŠŹ«ńŞÇŔç┤ŠÇžÚŚ«Ú󜊌šÜäňćůÚâĘŠť║ňłÂŃÇéšë╣ňłźňť░´╝皟áŔ┐śŠĚ▒ňůąŠÄóŔ«Ęń║ćZABňŹĆŔ««ńŞşšÜäń║őňŐíňĄäšÉ抾╣ň╝ĆŃÇüLeaderňĺîFolloweršÜäń║Ąń║ĺŠÁüšĘő´╝îń╗ąňĆŐňťĘÚŁóň»╣š│╗š╗č...
zookeeper-3.4.9 aarch64 ňťĘlinuxńŞşšÜäň«ëŔúůňîůŃÇé
zookeeperšÜämyeclipse2014ŠĆĺń╗Â
Šö╣ń╗úšáüńŞ╗ŔŽüňŐčŔâŻŔ⯊ś»ň«îŠłÉÚÇÜŔ┐çzookeeperňÉąmysqlŠĽ░ŠŹ«´╝îňůĚńŻôšÜäń╗őš╗ŹňĆ»ń╗ąňĆéŔÇâňŹÜŠľçzookeeperMasterÚÇëńŞżń╗ąňĆŐŠĽ░ŠŹ«ňÉą
LinuxńŞőZookeeperÚŤćšżĄšÜäň«ëŔúů
1.Ŕç¬ňŐĘňÉĹzookeeperŠ│ĘňćȊť║ń┐íŠü»´╝îňÉąŔ┤čŔŻŻšŐŠÇü 2.Ŕç¬ňŐĘń╗ÄzookeeperňÉąńŞŐŠŞŞŠťŹňŐíňÖĘń┐íŠü» 3.ŔÄĚňĆľŠťČŠť║š│╗š╗čń┐íŠü»,cpuńŻ┐šöĘšÄç´╝îňćůňşśńŻ┐šöĘšÄç´╝înginxŔ┐׊ĹŠĽ░ňÉąňł░zookeeper csdn´╝Ühttp://blog.csdn.net/rushroom
Úí╣šŤ«ŠáŞň┐âÚççšöĘSparkŔ┐ŤŔíîŠë╣ňĄäšÉćńŞÄŠÁüňĄäšÉć´╝┤ňÉłń║ćZooKeeperňĺîKafkań╗ąňó×ň╝║ňłćňŞâň╝ĆŔ«íš«Śňĺ░ŠŹ«ŠÁüš«íšÉćŔâŻňŐŤŃÇ銾çń╗š▒╗ň×őňĄÜŠáĚ´╝îňîůŠőČ175ńެclassŠľçń╗´╝î109ńެcrcŠáíڬçń╗´╝î82ńެParquetŠĽ░ŠŹ«Šľçń╗´╝îń╗ąňĆŐ67ńެScalaŠ║ÉšáüŠľçń╗šşëŃÇé Úí╣šŤ«...
eclipseڍ抳ÉZooKeeperŠĆĺń╗ÂŃÇüŃÇüŃÇüŃÇüŃÇüŃÇüń║▓ŠÁőňąŻšöĘŃÇéŃÇéŃÇéŃÇéŃÇéŃÇéŃÇéŃÇé
NULL ňŹÜŠľçÚôżŠÄą´╝Ühttps://xly1981.iteye.com/blog/2295918
ňĆ»ń╗ąŠîçň«Üzk nodeŔ┐ŤŔíîňĄçń╗ŻńŞÄŠüóňĄŹ´╝╣ńż┐ńŻ┐šöĘ
šČČňŤŤÚâĘňłć´╝łšČČ7šźá´╝ëň»╣ZooKeeperšÜäŠ×Š×äŔ«żŔ«íňĺîň«×šÄ░ňÄčšÉćŔ┐ŤŔíîń║ćŠĚ▒ňůąňłćŠ×É´╝îňîůňÉźš│╗š╗čŠĘíň×őŃÇüLeaderÚÇëńŞżŃÇüň«óŠłĚšź»ńŞÄŠťŹňŐíšź»šÜäňĚąńŻťňÄčšÉćŃÇüŔ»ĚŠ▒éňĄäšÉć´╝îń╗ąňĆŐŠťŹňŐíňÖĘŔžĺŔë▓šÜäňĚąńŻťŠÁüšĘőňĺ░ŠŹ«ňşśňéĘšşë´╝ŤšČČń║öÚâĘňłć´╝łšČČ8šźá´╝ëń╗őš╗Źń║ćZooKeeperšÜä...
java zookeeper kafka ŠŚąň┐ŚňĄäšÉć´╝îňşśňéĘmysqlŠĽ░ŠŹ«ň║ô
apache-zookeeper-3.7.1 apache-zookeeper-3.7.1 apache-zookeeper-3.7.1 apache-zookeeper-3.7.1 apache-zookeeper-3.7.1 apache-zookeeper-3.7.1 apache-zookeeper-3.7.1 apache-zookeeper-3.7.1 apache-zookeeper...
zookeeperŠĽ░ŠŹ«Ŕ┐üšž╗ń╗ÄňŹĽńżőňł░ÚŤćšżĄlinuxňĹŻń╗ĄŔ┐çšĘő
ZookeeperňťĘwindowsŠÉşň╗║ń╝¬ÚŤćšżĄ ZookeeperňťĘwindowsŠÉşň╗║ń╝¬ÚŤćšżĄ
zookeeperŔŐéšé╣ŠĽ░ŠŹ«šÜ䚍ĹňÉČńŞÄŔ»╗ňćÖŠôŹńŻť
zookeeper 3.6.3 Š║Éšáü