
FlumeжҳҜClouderaжҸҗдҫӣзҡ„дёҖдёӘй«ҳеҸҜз”Ёзҡ„пјҢй«ҳеҸҜйқ зҡ„пјҢеҲҶеёғејҸзҡ„жө·йҮҸж—Ҙеҝ—йҮҮйӣҶгҖҒиҒҡеҗҲе’Ңдј иҫ“зҡ„зі»з»ҹпјҢFlumeж”ҜжҢҒеңЁж—Ҙеҝ—зі»з»ҹдёӯе®ҡеҲ¶еҗ„зұ»ж•°жҚ®еҸ‘йҖҒж–№пјҢз”ЁдәҺ收йӣҶж•°жҚ®пјӣеҗҢж—¶пјҢFlumeжҸҗдҫӣеҜ№ж•°жҚ®иҝӣиЎҢз®ҖеҚ•еӨ„зҗҶпјҢ并еҶҷеҲ°еҗ„з§Қж•°жҚ®жҺҘеҸ—ж–№пјҲеҸҜе®ҡеҲ¶пјүзҡ„иғҪеҠӣгҖӮ
Flumeдё»иҰҒз”ұ3дёӘйҮҚиҰҒзҡ„组件жһ„жҲҗпјҡ
Source:е®ҢжҲҗеҜ№ж—Ҙеҝ—ж•°жҚ®зҡ„收йӣҶпјҢеҲҶжҲҗtranstion е’Ң event жү“е…ҘеҲ°channelд№ӢдёӯгҖӮ
Channel:дё»иҰҒжҸҗдҫӣдёҖдёӘйҳҹеҲ—зҡ„еҠҹиғҪпјҢеҜ№sourceжҸҗдҫӣдёӯзҡ„ж•°жҚ®иҝӣиЎҢз®ҖеҚ•зҡ„зј“еӯҳгҖӮ
Sink:еҸ–еҮәChannelдёӯзҡ„ж•°жҚ®пјҢиҝӣиЎҢзӣёеә”зҡ„еӯҳеӮЁж–Ү件系з»ҹпјҢж•°жҚ®еә“пјҢжҲ–иҖ…жҸҗдәӨеҲ°иҝңзЁӢжңҚеҠЎеҷЁгҖӮ
FlumeйҖ»иҫ‘дёҠеҲҶдёүеұӮжһ¶жһ„пјҡagentпјҢcollectorпјҢstorage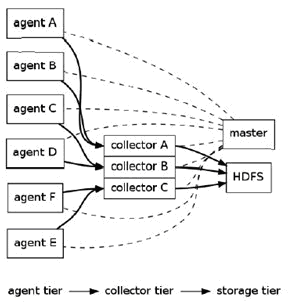
agentз”ЁдәҺйҮҮйӣҶж•°жҚ®пјҢagentжҳҜflumeдёӯдә§з”ҹж•°жҚ®жөҒзҡ„ең°ж–№пјҢеҗҢж—¶пјҢagentдјҡе°Ҷдә§з”ҹзҡ„ж•°жҚ®жөҒдј иҫ“еҲ°collectorгҖӮ
collectorзҡ„дҪңз”ЁжҳҜе°ҶеӨҡдёӘagentзҡ„ж•°жҚ®жұҮжҖ»еҗҺпјҢеҠ иҪҪеҲ°storageдёӯгҖӮ
storageжҳҜеӯҳеӮЁзі»з»ҹпјҢеҸҜд»ҘжҳҜдёҖдёӘжҷ®йҖҡfileпјҢд№ҹеҸҜд»ҘжҳҜHDFSпјҢHIVEпјҢHBaseзӯүгҖӮ
Flumeзҡ„жһ¶жһ„дё»иҰҒжңүдёҖдёӢеҮ дёӘж ёеҝғжҰӮеҝөпјҡ
EventпјҡдёҖдёӘж•°жҚ®еҚ•е…ғпјҢеёҰжңүдёҖдёӘеҸҜйҖүзҡ„ж¶ҲжҒҜеӨҙ
FlowпјҡEventд»ҺжәҗзӮ№еҲ°иҫҫзӣ®зҡ„зӮ№зҡ„иҝҒ移зҡ„жҠҪиұЎ
Clientпјҡж“ҚдҪңдҪҚдәҺжәҗзӮ№еӨ„зҡ„EventпјҢе°Ҷе…¶еҸ‘йҖҒеҲ°Flume Agent
AgentпјҡдёҖдёӘзӢ¬з«Ӣзҡ„FlumeиҝӣзЁӢпјҢеҢ…еҗ«з»„件SourceгҖҒChannelгҖҒSink
Sourceпјҡз”ЁжқҘж¶Ҳиҙ№дј йҖ’еҲ°иҜҘ组件зҡ„Event
ChannelпјҡдёӯиҪ¬Eventзҡ„дёҖдёӘдёҙж—¶еӯҳеӮЁпјҢдҝқеӯҳжңүSourceз»„д»¶дј йҖ’иҝҮжқҘзҡ„Event
Sinkпјҡд»ҺChannelдёӯиҜ»еҸ–并移йҷӨEventпјҢе°ҶEventдј йҖ’еҲ°Flow Pipelineдёӯзҡ„дёӢдёҖдёӘAgentпјҲеҰӮжһңжңүзҡ„иҜқпјү
е…ідәҺFlumeжӣҙеӨҡеҶ…е®№пјҢеҸҜд»ҘеҸӮиҖғзҪ‘з»ңж–ҮзҢ®пјҡFlumeзҡ„еҺҹзҗҶе’ҢдҪҝз”Ё
дёҖпјҡе®үиЈ…flume
flumeдёӢиҪҪең°еқҖпјҡВ flumeдёӢиҪҪе®ҳзҪ‘
1.и§ЈеҺӢе®үиЈ…еҢ…
- sudo tar -zxvf apache-flume-1.7.0-bin.tar.gz -C /usr/local # е°Ҷapache-flume-1.7.0-bin.tar.gzи§ЈеҺӢеҲ°/usr/localзӣ®еҪ•дёӢпјҢиҝҷйҮҢдёҖе®ҡиҰҒеҠ дёҠ-CеҗҰеҲҷдјҡеҮәзҺ°еҪ’жЎЈжүҫдёҚеҲ°зҡ„й”ҷиҜҜ
- sudo mv ./apache-flume-1.7.0-bin ./flume #е°Ҷи§ЈеҺӢзҡ„ж–Ү件дҝ®ж”№еҗҚеӯ—дёәflumeпјҢз®ҖеҢ–ж“ҚдҪң
- sudo chown -R hadoop:hadoop ./flume #жҠҠ/usr/local/flumeзӣ®еҪ•зҡ„жқғйҷҗиөӢдәҲеҪ“еүҚзҷ»еҪ•Linuxзі»з»ҹзҡ„з”ЁжҲ·пјҢиҝҷйҮҢеҒҮи®ҫжҳҜhadoopз”ЁжҲ·
2.й…ҚзҪ®зҺҜеўғеҸҳйҮҸ
- В sudo vim ~/.bashrc
然еҗҺеңЁйҰ–иЎҢеҠ е…ҘеҰӮдёӢд»Јз Ғпјҡ
- export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64;
- export FLUME_HOME=/usr/local/flume
- export FLUME_CONF_DIR=$FLUME_HOME/conf
- export PATH=$PATH:$FLUME_HOME/bin
жіЁж„ҸпјҢ дёҠйқўзҡ„JAVA_HOMEпјҢеҰӮжһңд»ҘеүҚе·Із»ҸеңЁ.bashrcж–Ү件дёӯи®ҫзҪ®иҝҮпјҢе°ұдёҚиҰҒйҮҚеӨҚж·»еҠ дәҶпјҢдҪҝз”Ёд»ҘеүҚзҡ„и®ҫзҪ®еҚіеҸҜгҖӮ
жҜ”еҰӮпјҢд»ҘеүҚи®ҫзҪ®еҫ—JAVA_HOMEеҸҜиғҪжҳҜвҖңexport JAVA_HOME=/usr/lib/jvm/default-javaвҖқпјҢеҲҷдҪҝз”ЁеҺҹжқҘзҡ„и®ҫзҪ®еҚіеҸҜгҖӮ
жҺҘдёӢжқҘдҪҝзҺҜеўғеҸҳйҮҸз”ҹж•Ҳпјҡ
- source ~/.bashrc
дҝ®ж”№ flume-env.sh й…ҚзҪ®ж–Ү件пјҡ
- cd /usr/local/flume/conf
- sudo cp ./flume-env.sh.template ./flume-env.sh
- sudo vim ./flume-env.sh
жү“ејҖflume-env.shж–Ү件д»ҘеҗҺпјҢеңЁж–Ү件зҡ„жңҖејҖе§ӢдҪҚзҪ®еўһеҠ дёҖиЎҢеҶ…е®№пјҢз”ЁдәҺи®ҫзҪ®JAVA_HOMEеҸҳйҮҸпјҡ
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64;
жіЁж„ҸпјҢдҪ зҡ„JAVA_HOMEеҸҜиғҪдёҺдёҠйқўзҡ„и®ҫзҪ®дёҚдёҖиҮҙпјҢдёҖе®ҡиҰҒж №жҚ®дҪ д№ӢеүҚе·Із»Ҹе®үиЈ…зҡ„Javaи·Ҝеҫ„жқҘи®ҫзҪ®пјҢжҜ”еҰӮпјҢжңүзҡ„жңәеҷЁеҸҜиғҪжҳҜпјҡ
export JAVA_HOME=/usr/lib/jvm/default-java
然еҗҺпјҢдҝқеӯҳflume-env.shж–Ү件пјҢ并йҖҖеҮәvimзј–иҫ‘еҷЁгҖӮ
3.жҹҘзңӢflumeзүҲжң¬дҝЎжҒҜ
- cd /usr/local/flume
- ./bin/flume-ng version #жҹҘзңӢflumeзүҲжң¬дҝЎжҒҜпјӣ
еҰӮжһңе®үиЈ…жҲҗеҠҹпјҢеҮәзҺ°еҰӮдёӢеӣҫзүҮ
жіЁж„ҸпјҡеҰӮжһңзі»з»ҹйҮҢе®үиЈ…дәҶhbaseпјҢдјҡеҮәзҺ°й”ҷиҜҜ: жүҫдёҚеҲ°жҲ–ж— жі•еҠ иҪҪдё»зұ» org.apache.flume.tools.GetJavaPropertyгҖӮеҰӮжһңжІЎжңүе®үиЈ…hbaseпјҢиҝҷдёҖжӯҘеҸҜд»Ҙз•ҘиҝҮгҖӮ
- cd /usr/local/hbase/conf
- sudo vim hbase-env.sh
- #1гҖҒе°Ҷhbaseзҡ„hbase.env.shзҡ„иҝҷдёҖиЎҢй…ҚзҪ®жіЁйҮҠжҺү,еҚіеңЁexportеүҚеҠ дёҖдёӘ#
- #export HBASE_CLASSPATH=/home/hadoop/hbase/conf
- #2гҖҒжҲ–иҖ…е°ҶHBASE_CLASSPATHж”№дёәJAVA_CLASSPATH,й…ҚзҪ®еҰӮдёӢ
- export JAVA_CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
- #笔иҖ…з”Ёзҡ„жҳҜ第дёҖз§Қж–№жі•
дәҢпјҡжөӢиҜ•flume
1.жЎҲдҫӢ1пјҡAvro source
гҖҖгҖҖгҖҖгҖҖAvroеҸҜд»ҘеҸ‘йҖҒдёҖдёӘз»ҷе®ҡзҡ„ж–Ү件з»ҷFlumeпјҢAvro жәҗдҪҝз”ЁAVRO RPCжңәеҲ¶гҖӮ
a) еҲӣе»әagentй…ҚзҪ®ж–Ү件
- cd /usr/local/flume
- sudo vim ./conf/avro.conf #еңЁconfзӣ®еҪ•дёӢзј–иҫ‘дёҖдёӘavro.confз©әж–Ү件
然еҗҺпјҢжҲ‘们еңЁavro.confеҶҷе…Ҙд»ҘдёӢеҶ…е®№
- a1.sources = r1
- a1.sinks = k1
- a1.channels = c1
- В
- # Describe/configure the source
- a1.sources.r1.type = avro
- a1.sources.r1.channels = c1
- a1.sources.r1.bind = 0.0.0.0
- a1.sources.r1.port = 4141
- #жіЁж„ҸиҝҷдёӘз«ҜеҸЈеҗҚпјҢеңЁеҗҺйқўзҡ„ж•ҷзЁӢдёӯдјҡз”Ёеҫ—еҲ°
- В
- # Describe the sink
- a1.sinks.k1.type = logger
- В
- # Use a channel which buffers events in memory
- a1.channels.c1.type = memory
- a1.channels.c1.capacity = 1000
- a1.channels.c1.transactionCapacity = 100
- В
- # Bind the source and sink to the channel
- a1.sources.r1.channels = c1
- a1.sinks.k1.channel = c1
дёҠйқўAvro SourceеҸӮж•°иҜҙжҳҺеҰӮдёӢпјҡ
Avro Sourceзҡ„еҲ«еҗҚжҳҜavro,д№ҹеҸҜд»ҘдҪҝз”Ёе®Ңж•ҙзұ»еҲ«еҗҚз§°org.apache.flume.source.AvroSourceпјҢеӣ жӯӨпјҢдёҠйқўжңүдёҖиЎҢи®ҫзҪ®жҳҜa1.sources.r1.type = avroпјҢиЎЁзӨәж•°жҚ®жәҗзҡ„зұ»еһӢжҳҜavroгҖӮ
bindз»‘е®ҡзҡ„ipең°еқҖжҲ–дё»жңәеҗҚпјҢдҪҝз”Ё0.0.0.0иЎЁзӨәз»‘е®ҡжңәеҷЁжүҖжңүзҡ„жҺҘеҸЈгҖӮa1.sources.r1.bind = 0.0.0.0пјҢе°ұиЎЁзӨәз»‘е®ҡжңәеҷЁжүҖжңүзҡ„жҺҘеҸЈгҖӮ
portиЎЁзӨәз»‘е®ҡзҡ„з«ҜеҸЈгҖӮa1.sources.r1.port = 4141пјҢиЎЁзӨәз»‘е®ҡзҡ„з«ҜеҸЈжҳҜ4141гҖӮ
a1.sinks.k1.type = loggerпјҢиЎЁзӨәsinksзҡ„зұ»еһӢжҳҜloggerгҖӮ
b) еҗҜеҠЁflume agent a1
- /usr/local/flume/bin/flume-ng agent -c . -f /usr/local/flume/conf/avro.conf -n a1 -Dflume.root.logger=INFO,console #еҗҜеҠЁж—Ҙеҝ—жҺ§еҲ¶еҸ°
иҝҷйҮҢжҲ‘们жҠҠиҝҷдёӘзӘ—еҸЈз§°дёәagentзӘ—еҸЈгҖӮ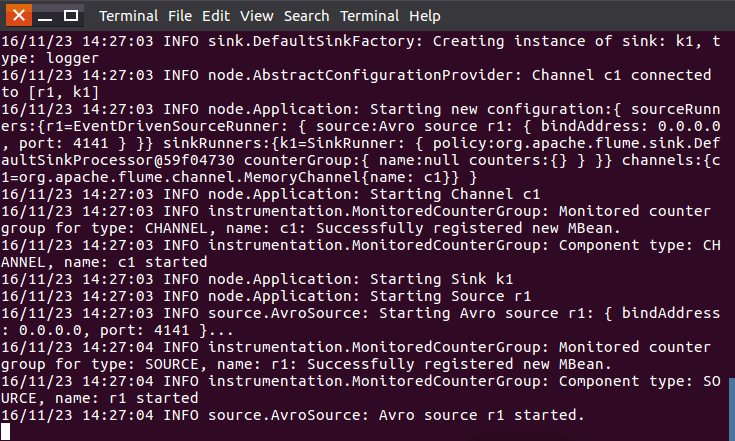
c) еҲӣе»әжҢҮе®ҡж–Ү件
е…Ҳжү“ејҖеҸҰеӨ–дёҖдёӘз»Ҳз«ҜпјҢеңЁ/usr/local/flumeдёӢеҶҷе…ҘдёҖдёӘж–Ү件log.00,еҶ…е®№дёәhello,world:
- cd /usr/local/flume
- sudo sh -c 'echo "hello world" > /usr/local/flume/log.00'
жҲ‘们еҶҚжү“ејҖеҸҰеӨ–дёҖдёӘз»Ҳз«ҜпјҢжү§иЎҢпјҡ
- cd /usr/local/flume
- bin/flume-ng avro-client --conf conf -H localhost -p 4141 -F /usr/local/flume/log.00 #4141жҳҜavro.confж–Ү件йҮҢзҡ„з«ҜеҸЈеҗҚ
жӯӨж—¶жҲ‘们еҸҜд»ҘзңӢеҲ°з¬¬дёҖдёӘз»Ҳз«ҜпјҲagentзӘ—еҸЈпјүдёӢзҡ„жҳҫзӨәпјҢд№ҹе°ұжҳҜеңЁж—Ҙеҝ—жҺ§еҲ¶еҸ°пјҢе°ұдјҡжҠҠlog.00ж–Ү件зҡ„еҶ…е®№жү“еҚ°еҮәжқҘпјҡ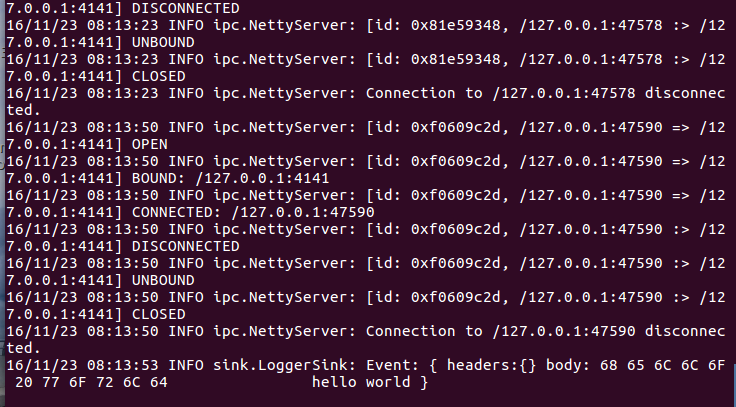
avro sourceжү§иЎҢжҲҗеҠҹпјҒжЎҲдҫӢдёҖoverпјҒ
2.жЎҲдҫӢ2пјҡnetcatsource
a) еҲӣе»әagentй…ҚзҪ®ж–Ү件
- cd /usr/local/flume
- sudo vim ./conf/example.conf #еңЁconfзӣ®еҪ•еҲӣе»әexample.conf
еңЁexample.confйҮҢеҶҷе…Ҙд»ҘдёӢеҶ…е®№пјҡ
- #example.conf: A single-node Flume configuration
- В
- # Name the components on this agent
- a1.sources = r1
- a1.sinks = k1
- a1.channels = c1
- В
- # Describe/configure the source
- a1.sources.r1.type = netcat
- a1.sources.r1.bind = localhost
- a1.sources.r1.port = 44444
- #еҗҢдёҠпјҢи®°дҪҸиҜҘз«ҜеҸЈеҗҚ
- В
- # Describe the sink
- a1.sinks.k1.type = logger
- В
- # Use a channel which buffers events in memory
- a1.channels.c1.type = memory
- a1.channels.c1.capacity = 1000
- a1.channels.c1.transactionCapacity = 100
- В
- # Bind the source and sink to the channel
- a1.sources.r1.channels = c1
- a1.sinks.k1.channel = c1
b)еҗҜеҠЁflume agent (еҚіжү“ејҖж—Ҙеҝ—жҺ§еҲ¶еҸ°)пјҡ
- /usr/local/flume/bin/flume-ng agent --conf ./conf --conf-file ./conf/example.conf --name a1 -Dflume.root.logger=INFO,console
еҰӮеӣҫпјҡ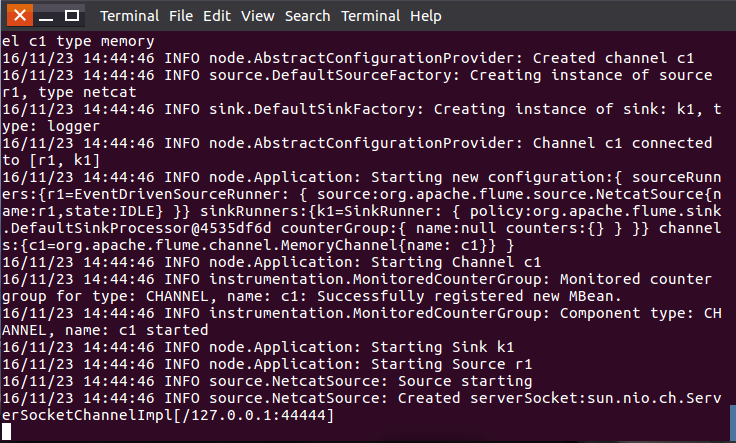
еҶҚжү“ејҖдёҖдёӘз»Ҳз«ҜпјҢиҫ“е…Ҙе‘Ҫд»Ө:telnet localhost 44444
- telnet localhost 44444
- #еүҚйқўзј–иҫ‘confж–Ү件зҡ„з«ҜеҸЈеҗҚ

然еҗҺжҲ‘们еҸҜд»ҘеңЁз»Ҳз«ҜдёӢиҫ“е…Ҙд»»дҪ•еӯ—з¬ҰпјҢ第дёҖдёӘз»Ҳз«Ҝзҡ„ж—Ҙеҝ—жҺ§еҲ¶еҸ°д№ҹдјҡжңүзӣёеә”зҡ„жҳҫзӨәпјҢеҰӮжҲ‘们иҫ“е…ҘвҖқhello,worldвҖқ,еҫ—еҮә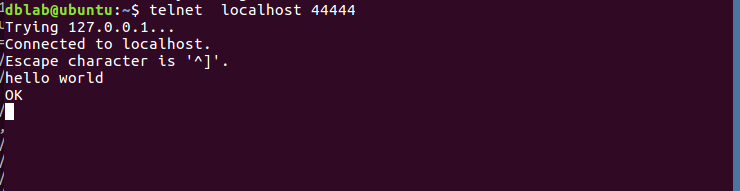
第дёҖдёӘз»Ҳз«Ҝзҡ„ж—Ҙеҝ—жҺ§еҲ¶еҸ°жҳҫзӨәпјҡ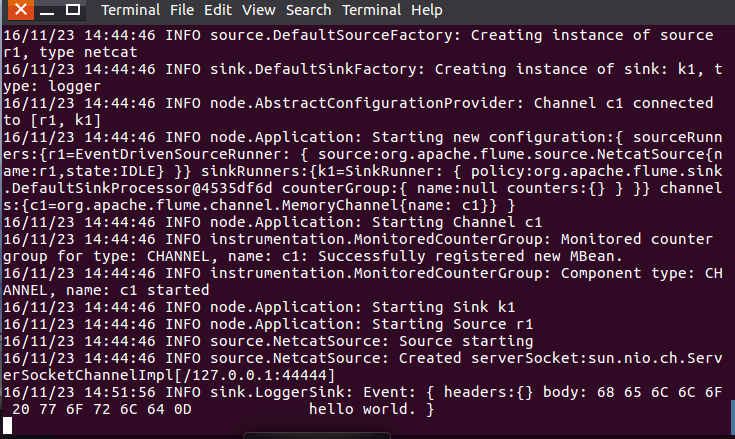
netcatsourceиҝҗиЎҢжҲҗеҠҹпјҒ
иҝҷйҮҢиЎҘе……дёҖзӮ№пјҢflumeеҸӘиғҪдј йҖ’иӢұж–Үе’Ңеӯ—з¬ҰпјҢдёҚиғҪз”Ёдёӯж–ҮпјҢжҲ‘们е…ҲеҸҜд»ҘеңЁз¬¬дәҢдёӘз»Ҳз«Ҝиҫ“е…ҘвҖңдёӯеӣҪвҖқдёӨдёӘеӯ—:
第дёҖдёӘз»Ҳз«Ҝзҡ„ж—Ҙеҝ—жҺ§еҲ¶еҸ°жҳҫзӨәпјҡ



зӣёе…іжҺЁиҚҗ
Flumeзҡ„е®үиЈ…йғЁзҪІ Flumeзҡ„жөӢиҜ•иҝҗиЎҢ Flumeдёӯй…ҚзҪ®дҪҝз”Ёfile channelеҸҠHDFS sink Flumeдёӯй…ҚзҪ®HDFSж–Ү件з”ҹжҲҗеӨ§е°ҸеҸҠж—¶й—ҙеҲҶеҢә Flumeдёӯй…ҚзҪ®Spooling Dirзҡ„дҪҝз”Ё Flumeдёӯй…ҚзҪ®Spooling Dirзҡ„ж–Ү件иҝҮж»Ө Flumeдёӯй…ҚзҪ®жүҮе…Ҙжһ¶жһ„...
гҖҠFlumeпјҡжһ„е»әй«ҳеҸҜз”ЁгҖҒеҸҜжү©еұ•зҡ„жө·йҮҸж—Ҙеҝ—йҮҮйӣҶзі»з»ҹгҖӢд»ҺFlume зҡ„еҹәжң¬жҰӮеҝөе’Ңи®ҫи®ЎеҺҹзҗҶејҖе§Ӣи®Іи§ЈпјҢеҲҶеҲ«д»Ӣз»ҚдәҶдёҚеҗҢз§Қзұ»зҡ„组件гҖҒеҰӮдҪ•й…ҚзҪ®з»„件гҖҒеҰӮдҪ•иҝҗиЎҢFlume Agent зӯүгҖӮеҗҢж—¶пјҢеҲҶеҲ«и®Ёи®әSourceгҖҒChannel е’ҢSink дёүз§Қж ёеҝғ组件пјҢ...
Apache Flume жҳҜдёҖдёӘеҲҶеёғејҸгҖҒй«ҳеҸҜйқ гҖҒй«ҳеҸҜз”Ёзҡ„з”ЁжқҘ收йӣҶгҖҒиҒҡеҗҲгҖҒиҪ¬з§»дёҚеҗҢжқҘжәҗзҡ„еӨ§йҮҸж—Ҙеҝ—ж•°жҚ®еҲ°дёӯеӨ®ж•°жҚ®д»“еә“зҡ„е·Ҙе…· Apache FlumeжҳҜApacheиҪҜ件еҹәйҮ‘дјҡпјҲASFпјүзҡ„йЎ¶зә§йЎ№зӣ® EventжҳҜFlumeе®ҡд№үзҡ„дёҖдёӘж•°жҚ®жөҒдј иҫ“зҡ„жңҖе°ҸеҚ•е…ғгҖӮ...
Flume жҳҜеӨ§ж•°жҚ®з»„件дёӯйҮҚиҰҒзҡ„ж•°жҚ®йҮҮйӣҶе·Ҙе…·пјҢжҲ‘们常еҲ©з”Ё Flume йҮҮйӣҶжҹҗдёӘеҗ„з§Қж•°жҚ®жәҗзҡ„ж•°жҚ®дҫӣ其他组件еҲҶжһҗдҪҝз”ЁгҖӮеңЁж—Ҙеҝ—еҲҶжһҗдёҡеҠЎдёӯпјҢжҲ‘们常йҮҮйӣҶжңҚеҠЎеҷЁж—Ҙеҝ—пјҢд»ҘеҲҶжһҗжңҚеҠЎеҷЁиҝҗиЎҢзҠ¶жҖҒжҳҜеҗҰжӯЈеёёгҖӮеңЁе®һж—¶дёҡеҠЎдёӯпјҢжҲ‘们常е°Ҷж•°жҚ®...
з”ЁдәҺflumeзҡ„е®үиЈ…пјҢzookeeperзҡ„е®үиЈ…пјҢHadoopзҡ„е®үиЈ…пјҢе®үиЈ…mysqlзҡ„дёҖдәӣjarеҢ…гҖӮе®үиЈ…еҘҪflumeпјҢиҰҒе…Ҳе®үиЈ…еҘҪjavaзҺҜеўғ
йҖҡиҝҮjavaжЁЎжӢҹз”ҹдә§зҺҜеўғзҡ„ж—Ҙеҝ—пјҢflumeзӣ‘жҺ§жҢҮе®ҡзӣ®еҪ•пјҢйҮҮйӣҶж—Ҙеҝ—жҺЁйҖҒеҲ°kafkaгҖӮе…·дҪ“еҶ…е®№еҸҜеҸӮиҖғ вҖңеҹәдәҺCDH5зҡ„flume-kafkaеҜ№жҺҘвҖқиҝҷзҜҮ
NULL еҚҡж–Үй“ҫжҺҘпјҡhttps://kavy.iteye.com/blog/2228079
FlumeжҳҜClouderaжҸҗдҫӣзҡ„дёҖдёӘй«ҳеҸҜз”Ёзҡ„пјҢй«ҳеҸҜйқ зҡ„пјҢеҲҶеёғејҸзҡ„жө·йҮҸж—Ҙеҝ—йҮҮйӣҶгҖҒиҒҡеҗҲе’Ңдј иҫ“зҡ„зі»з»ҹ Flumeж”ҜжҢҒеңЁж—Ҙеҝ—зі»з»ҹдёӯе®ҡеҲ¶еҗ„зұ»ж•°жҚ®еҸ‘йҖҒж–№пјҢз”ЁдәҺ收йӣҶж•°жҚ®пјӣ FlumeжҸҗдҫӣеҜ№ж•°жҚ®иҝӣиЎҢз®ҖеҚ•еӨ„зҗҶпјҢ并еҶҷеҲ°еҗ„з§Қж•°жҚ®жҺҘеҸ—ж–№пјҲеҸҜе®ҡеҲ¶пјү...
flumeжҳҜдёҖдёӘй«ҳеҸҜз”Ёзҡ„пјҢй«ҳеҸҜйқ зҡ„пјҢеҲҶеёғејҸзҡ„жө·йҮҸж—Ҙеҝ—йҮҮйӣҶгҖҒиҒҡеҗҲе’Ңдј иҫ“зҡ„зі»з»ҹпјҢFlumeж”ҜжҢҒеңЁж—Ҙеҝ—зі»з»ҹдёӯе®ҡеҲ¶еҗ„зұ»ж•°жҚ®еҸ‘йҖҒж–№пјҢз”ЁдәҺ收йӣҶж•°жҚ®пјӣеҗҢж—¶пјҢFlumeжҸҗдҫӣеҜ№ж•°жҚ®вҖҰ еҗ„йўҶеҹҹж•°жҚ®йӣҶпјҢе·Ҙе…·жәҗз ҒпјҢйҖӮеҗҲжҜ•дёҡи®ҫи®ЎгҖҒиҜҫзЁӢи®ҫи®ЎдҪңдёҡ...
зӣ®еүҚдҪҝз”ЁжңҖе№ҝжіӣзҡ„гҖҒз”ЁдәҺзі»з»ҹж—Ҙеҝ—йҮҮйӣҶзҡ„жө·йҮҸж•°жҚ®йҮҮйӣҶе·Ҙе…·жңү Hadoop зҡ„ ChukwaгҖҒApacheFlumeAFacebook зҡ„ Scribe е’Ң LinkedIn зҡ„ Kafka зӯүгҖӮ д»ҘдёҠе·Ҙе…·еқҮйҮҮз”ЁеҲҶеёғејҸжһ¶жһ„пјҢиғҪж»Ўи¶іжҜҸз§’ж•°зҷҫ MB зҡ„ж—Ҙеҝ—ж•°жҚ®йҮҮйӣҶе’Ңдј иҫ“йңҖжұӮгҖӮ
2 ж•°жҚ®йҮҮйӣҶзҡ„ж–№ејҸж–№жі• 2.1зі»з»ҹж—Ҙеҝ—йҮҮйӣҶж–№жі•гҖӮз»қеӨ§йғЁеҲҶзҡ„дә’иҒ”зҪ‘дјҒдёҡйғҪжӢҘжңүиҮӘе·ұдё“еұһзҡ„жө·йҮҸж•°жҚ®йҮҮйӣҶ е·Ҙе…·пјҢдёҖиҲ¬жҳҜз”ЁдәҺеҜ№зі»з»ҹж—Ҙеҝ—иҝӣиЎҢйҮҮйӣҶпјҢдҫӢеҰӮHadoopзҡ„ChukwaгҖҒFecebookдё“з”Ёзҡ„Scribe д»ҘеҸҠClouderaзҡ„FlumeзӯүзӯүпјҢиҝҷдәӣ...
зҺ°жңүзҡ„ETLе·Ҙе…·Flumeд№ҹеҸҜд»Ҙе®ҢжҲҗж—Ҙеҝ—зҡ„йҮҮйӣҶпјҢдј иҫ“пјҢиҪ¬жҚўе’ҢеӯҳеӮЁпјҢдҪҶжҳҜFlumeе·Ҙе…·д»…иғҪеә”з”ЁеҲ°йҖҡдҝЎиҙЁйҮҸж— йҡңзўҚзҡ„жӣҝд»ЈзҺҜеўғпјҢеңЁе…¬зҪ‘зҺҜеўғдёӢеҸҜиғҪеӣ зҪ‘з»ңејӮеёёзӯүеӣ зҙ еҜјиҮҙиҝһжҺҘиҫғй•ҝзҡ„жңҚеҠЎзҡ„еҸ‘йҖҒеҷЁз»„件еӨұиҙҘпјҢиҖҢжӯӨ时收йӣҶеҷЁз»„件еҸҜиғҪ并дёҚ...
ж—Ҙеҝ—йҮҮйӣҶе·Ҙе…·(logpipe) 1. жҰӮиҝ° еңЁйӣҶзҫӨеҢ–зҺҜеўғйҮҢпјҢж—Ҙеҝ—йҮҮйӣҶжҳҜйҮҚиҰҒеҹәзЎҖи®ҫж–ҪгҖӮ ејҖжәҗдё»жөҒи§ЈеҶіж–№жЎҲжҳҜеҹәдәҺflume-ngпјҢдҪҶеңЁе®һйҷ…дҪҝз”ЁдёӯеҸ‘зҺ°flume-ngеӯҳеңЁиҜёеӨҡй—®йўҳпјҢжҜ”еҰӮflume-ngзҡ„spoolDirйҮҮйӣҶеҷЁеҸӘиғҪеҜ№ж–Ү件еҗҚиҪ¬жЎЈеҗҺзҡ„еӨ§е°ҸдёҚиғҪ...
2.ж №жҚ®е…·дҪ“йңҖжұӮпјҢиҝҗз”ЁFlumeиҝӣиЎҢе®һж—¶йҮҮйӣҶж—Ҙеҝ—дҝЎжҒҜпјҢеӯҳеӮЁеҲ°kafkaж¶ҲжҒҜйҳҹеҲ—дёӯ 3.дҪҝз”ЁSpark StreamingеҜ№ж•°жҚ®иҝӣиЎҢжё…жҙ—гҖҒеҠ е·ҘгҖҒеӨ„зҗҶпјҢеҪўжҲҗжңҖз»ҲиҰҒеұ•зӨәзҡ„жҢҮж ҮпјҢеӯҳе…ҘMySQLпјҢжҸҗдҫӣз»ҷеүҚз«ҜејҖеҸ‘гҖӮ 4.з ”з©¶ж•°жҚ®з»“жһңпјҢеү–жһҗжңүж•ҲдҝЎжҒҜпјҢ...
4.дҪҝз”Ёflumeе®һ时收йӣҶж—Ҙеҝ—дҝЎжҒҜ 5.еҜ№жҺҘе®һж—¶ж•°жҚ®еҲ°kafka并иҫ“еҮәеҲ°жҺ§еҲ¶еҸ° 6.spark streamingеҜ№жҺҘkafkaзҡ„ж•°жҚ®иҝӣиЎҢж¶Ҳиҙ№ ж•°жҚ®йҮҮйӣҶиҜҰжғ…пјҡйЎ№зӣ®е…¶д»–\ж•°жҚ®йҮҮйӣҶ.docx дәҢпјҺж•°жҚ®жё…жҙ—пјҡи§ҒйЎ№зӣ® дҪҝз”Ёspark streamingе®ҢжҲҗж•°жҚ®жё…жҙ—ж“ҚдҪң ...
Flume ж•°жҚ®йҮҮйӣҶе·Ҙе…· Sqoop ж•°жҚ®ETLе·Ҙе…· ElasticSearch жҗңзҙўзі»з»ҹ Logstash ж—Ҙеҝ—йҮҮйӣҶе·Ҙе…· Kibana ж•°жҚ®еұ•зҺ°е·Ҙе…· Ranger йӣҶдёӯе®үе…Ёз®ЎзҗҶе·Ҙе…· Atlas ж•°жҚ®жІ»зҗҶе’Ңе…ғж•°жҚ®з®ЎзҗҶжЎҶжһ¶ kettle ETLе·Ҙе…· mongodb Key-valueж•°жҚ®еә“ ...
Flume ж—Ҙеҝ—йҮҮйӣҶгҖҒиҒҡеҗҲе’Ңдј иҫ“ ж•°жҚ®еӯҳеӮЁзі»з»ҹпјҡ HDFS еҲҶеёғејҸж–Ү件系з»ҹпјӣSwift дә‘еӯҳеӮЁжңҚеҠЎпјӣKafka ж¶ҲжҒҜзі»з»ҹпјҢзұ»дјјдәҺж¶ҲжҒҜйҳҹеҲ— и®Ўз®—еј•ж“Һпјҡ MapReduce жү№йҮҸж•°жҚ®еӨ„зҗҶеј•ж“ҺпјӣStorm жөҒејҸеӨ„зҗҶеј•ж“ҺпјӣGiraph 并иЎҢеӣҫеӨ„зҗҶзі»з»ҹпјӣ Spark...
еҸ‘з”ҹжүҖжңүиҝҷдәӣй—®йўҳзҡ„ж №жәҗеңЁдәҺе…¬зҪ‘дј йҖ’ж•°жҚ®зҡ„дёҚзЁіе®ҡжҖ§жүҖиҮҙпјҢеӣ жӯӨFlumeжҳҜеңЁиҝҷз§Қй—®йўҳиғҢжҷҜзҡ„йңҖжұӮй©ұеҠЁдёӢдә§з”ҹдәҶDataFlowиҝҷж¬ҫдә§е“ҒпјҢDataFlowе®Ңе…ЁжҢүз…§дә§е“Ғзә§ж ҮеҮҶдҪҝз”ЁJAVAиҜӯиЁҖиҝӣиЎҢејҖеҸ‘пјҢе®үиЈ…ж—¶ж— йңҖеҶҚе®үиЈ…еӨ–зҪ®JDKж”ҜжҢҒпјҢи§ЈеҺӢејҖз®ұ...
е®һж—¶ж•°жҚ®еӨ„зҗҶзі»з»ҹйҰ–е…Ҳе°Ҷе®һж—¶ж•°жҚ®д»Ҙж—Ҙеҝ—зҡ„еҪўејҸеӯҳеӮЁеңЁFlumeдёӯ,然еҗҺеҶҚйҖҡиҝҮStromе’ҢSpark Streamingе·Ҙе…·еҜ№е®һж—¶ж•°жҚ®иҝӣиЎҢе®һж—¶еӨ„зҗҶдёҺеҲҶжһҗ,并еҜ№ж•°жҚ®иҝӣиЎҢж ҮзӯҫгҖӮе°Ҷз”ҹжҲҗзҡ„ж ҮзӯҫеӯҳеӮЁеңЁRedisж•°жҚ®еә“дёӯгҖӮе®һж—¶иҗҘй”Җзі»з»ҹзҡ„ж ёеҝғжҳҜйҖҡиҝҮеҲҶжһҗ...
вҖғ 2пјүFlumeпјҡдёҖдёӘй«ҳеҸҜз”Ёзҡ„пјҢй«ҳеҸҜйқ зҡ„пјҢеҲҶеёғејҸзҡ„жө·йҮҸж—Ҙеҝ—йҮҮйӣҶгҖҒиҒҡеҗҲе’Ңдј иҫ“зҡ„зі»з»ҹгҖӮ вҖғ 3пјүHbaseпјҡжҳҜдёҖдёӘеҲҶеёғејҸзҡ„гҖҒйқўеҗ‘еҲ—зҡ„ејҖжәҗж•°жҚ®еә“, еҲ©з”ЁHadoop HDFSдҪңдёәе…¶еӯҳеӮЁзі»з»ҹгҖӮ вҖғ 4пјүHiveпјҡеҹәдәҺHadoopзҡ„дёҖдёӘж•°жҚ®д»“еә“е·Ҙе…·...