
SQLиҜӯеҸҘзҡ„жү§иЎҢйЎәеәҸжүҚиғҪ继з»ӯпјҢдёҠзҪ‘дёҠжҹҘдәҶдёҖдёӢзӣёе…ізҡ„иө„ж–ҷпјҢзҺ°ж•ҙзҗҶеҰӮдёӢпјҡ
дёҖгҖҒsqlиҜӯеҸҘзҡ„жү§иЎҢжӯҘйӘӨпјҡ
В 1пјүиҜӯжі•еҲҶжһҗпјҢеҲҶжһҗиҜӯеҸҘзҡ„иҜӯжі•жҳҜеҗҰз¬ҰеҗҲ规иҢғпјҢиЎЎйҮҸиҜӯеҸҘдёӯеҗ„иЎЁиҫҫејҸзҡ„ж„Ҹд№үгҖӮ
2пјү иҜӯд№үеҲҶжһҗпјҢжЈҖжҹҘиҜӯеҸҘдёӯж¶үеҸҠзҡ„жүҖжңүж•°жҚ®еә“еҜ№иұЎжҳҜеҗҰеӯҳеңЁпјҢдё”з”ЁжҲ·жңүзӣёеә”зҡ„жқғйҷҗгҖӮ
3пјүи§ҶеӣҫиҪ¬жҚўпјҢе°Ҷж¶үеҸҠи§Ҷеӣҫзҡ„жҹҘиҜўиҜӯеҸҘиҪ¬жҚўдёәзӣёеә”зҡ„еҜ№еҹәиЎЁжҹҘиҜўиҜӯеҸҘгҖӮ
4пјүиЎЁиҫҫејҸиҪ¬жҚўпјҢ е°ҶеӨҚжқӮзҡ„ SQL иЎЁиҫҫејҸиҪ¬жҚўдёәиҫғз®ҖеҚ•зҡ„зӯүж•ҲиҝһжҺҘиЎЁиҫҫејҸгҖӮ
В 5пјүйҖүжӢ©дјҳеҢ–еҷЁпјҢдёҚеҗҢзҡ„дјҳеҢ–еҷЁдёҖиҲ¬дә§з”ҹдёҚеҗҢзҡ„вҖңжү§иЎҢи®ЎеҲ’вҖқ
6пјүйҖүжӢ©иҝһжҺҘж–№ејҸпјҢ ORACLE жңүдёүз§ҚиҝһжҺҘж–№ејҸпјҢеҜ№еӨҡиЎЁиҝһжҺҘ ORACLE еҸҜйҖүжӢ©йҖӮеҪ“зҡ„иҝһжҺҘж–№ејҸгҖӮ
7пјүйҖүжӢ©иҝһжҺҘйЎәеәҸпјҢ еҜ№еӨҡиЎЁиҝһжҺҘ ORACLE йҖүжӢ©е“ӘдёҖеҜ№иЎЁе…ҲиҝһжҺҘпјҢйҖүжӢ©иҝҷдёӨиЎЁдёӯе“ӘдёӘиЎЁеҒҡдёәжәҗж•°жҚ®иЎЁгҖӮ
8пјүйҖүжӢ©ж•°жҚ®зҡ„жҗңзҙўи·Ҝеҫ„пјҢж №жҚ®д»ҘдёҠжқЎд»¶йҖүжӢ©еҗҲйҖӮзҡ„ж•°жҚ®жҗңзҙўи·Ҝеҫ„пјҢеҰӮжҳҜйҖүз”Ёе…ЁиЎЁжҗңзҙўиҝҳжҳҜеҲ©з”Ёзҙўеј•жҲ–жҳҜе…¶д»–зҡ„ж–№ејҸгҖӮ
9пјүиҝҗиЎҢвҖңжү§иЎҢи®ЎеҲ’вҖқ
дәҢгҖҒoracle е…ұдә«еҺҹзҗҶпјҡ
В В В В В В В ORACLEе°Ҷжү§иЎҢиҝҮзҡ„SQLиҜӯеҸҘеӯҳж”ҫеңЁеҶ…еӯҳзҡ„е…ұдә«жұ (shared buffer pool)дёӯпјҢеҸҜд»Ҙиў«жүҖжңүзҡ„ж•°жҚ®еә“з”ЁжҲ·е…ұдә« еҪ“дҪ жү§иЎҢдёҖдёӘSQLиҜӯеҸҘ(жңүж—¶иў«з§°дёәдёҖдёӘжёёж Ү)ж—¶,еҰӮжһңе®ғе’Ңд№ӢеүҚзҡ„жү§иЎҢиҝҮзҡ„иҜӯеҸҘе®Ңе…ЁзӣёеҗҢ, ORACLEе°ұиғҪеҫҲеҝ«иҺ·еҫ—е·Із»Ҹиў«и§Јжһҗзҡ„иҜӯеҸҘд»ҘеҸҠжңҖеҘҪзҡ„ жү§иЎҢи·Ҝеҫ„. иҝҷдёӘеҠҹиғҪеӨ§еӨ§ең°жҸҗй«ҳдәҶSQLзҡ„жү§иЎҢжҖ§иғҪ并иҠӮзңҒдәҶеҶ…еӯҳзҡ„дҪҝз”Ё
дёүгҖҒoracle иҜӯеҸҘжҸҗй«ҳжҹҘиҜўж•ҲзҺҮзҡ„ж–№жі•пјҡ1пјҡ where column in(select * from ... where ...); 2пјҡ... where exists (select 'X' from ...where ...); 第дәҢз§Қж јејҸиҰҒиҝңжҜ”第дёҖз§Қж јејҸзҡ„ж•ҲзҺҮй«ҳгҖӮеңЁOracleдёӯеҸҜд»ҘеҮ д№Һе°ҶжүҖжңүзҡ„INж“ҚдҪңз¬ҰеӯҗжҹҘиҜўж”№еҶҷдёәдҪҝз”ЁEXISTSзҡ„еӯҗжҹҘиҜў дҪҝз”ЁEXISTпјҢOracleзі»з»ҹдјҡйҰ–е…ҲжЈҖжҹҘдё»жҹҘиҜўпјҢ然еҗҺиҝҗиЎҢеӯҗжҹҘиҜўзӣҙеҲ°е®ғжүҫеҲ°з¬¬дёҖдёӘеҢ№й…ҚйЎ№пјҢиҝҷе°ұиҠӮзңҒдәҶж—¶й—ҙ Oracleзі»з»ҹеңЁжү§иЎҢINеӯҗжҹҘиҜўж—¶пјҢйҰ–е…Ҳжү§иЎҢеӯҗжҹҘиҜўпјҢ并е°ҶиҺ·еҫ—зҡ„з»“жһңеҲ—иЎЁеӯҳж”ҫеңЁеңЁдёҖдёӘеҠ дәҶзҙўеј•зҡ„дёҙж—¶иЎЁдёӯ йҒҝе…ҚдҪҝз”Ёhavingеӯ—еҸҘ йҒҝе…ҚдҪҝз”ЁHAVINGеӯҗеҸҘ, HAVING еҸӘдјҡеңЁжЈҖзҙўеҮәжүҖжңүи®°еҪ•д№ӢеҗҺжүҚеҜ№з»“жһңйӣҶиҝӣиЎҢиҝҮж»Ө. иҝҷдёӘеӨ„зҗҶйңҖиҰҒжҺ’еәҸ,жҖ»и®Ўзӯүж“ҚдҪң. еҰӮжһңиғҪйҖҡиҝҮWHEREеӯҗеҸҘйҷҗеҲ¶и®°еҪ•зҡ„ж•°зӣ®,йӮЈе°ұиғҪеҮҸе°‘иҝҷж–№йқўзҡ„ејҖй”Җ
SQL SelectиҜӯеҸҘе®Ңж•ҙзҡ„жү§иЎҢйЎәеәҸпјҡВ
1гҖҒfromеӯҗеҸҘз»„иЈ…жқҘиҮӘдёҚеҗҢж•°жҚ®жәҗзҡ„ж•°жҚ®пјӣ
В 2гҖҒwhereеӯҗеҸҘеҹәдәҺжҢҮе®ҡзҡ„жқЎд»¶еҜ№и®°еҪ•иЎҢиҝӣиЎҢзӯӣйҖүпјӣ
3гҖҒgroup byеӯҗеҸҘе°Ҷж•°жҚ®еҲ’еҲҶдёәеӨҡдёӘеҲҶз»„пјӣ
4гҖҒдҪҝз”ЁиҒҡйӣҶеҮҪж•°иҝӣиЎҢи®Ўз®—пјӣ
5гҖҒдҪҝз”ЁhavingеӯҗеҸҘзӯӣйҖүеҲҶз»„пјӣ
6гҖҒеӨ„зҗҶselectеҲ—иЎЁпјӣ
7гҖҒdistinctе°ҶйҮҚеӨҚзҡ„иЎҢеү”йҷӨпјӣ
8гҖҒдҪҝз”Ёorder byеҜ№з»“жһңйӣҶиҝӣиЎҢжҺ’еәҸпјӣ
9гҖҒtopйҖүжӢ©жҢҮе®ҡж•°йҮҸжҲ–жҜ”дҫӢзҡ„иЎҢгҖӮ
В
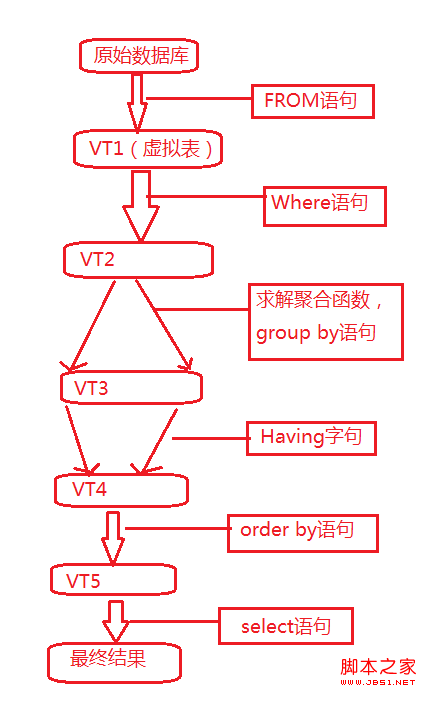
В
жү§иЎҢйЎәеәҸе’Ңж•°жҚ®еә“жңүе…іпјҢдёҚеҗҢзҡ„ж•°жҚ®еә“жңүдёҚеҗҢзҡ„и§ЈжһҗйЎәеәҸгҖӮ
ORACLEжҳҜд»ҺеҗҺеҫҖеүҚи§Јжһҗзҡ„,д№ҹе°ұжҳҜе…Ҳи§Јжһҗwhere жқЎд»¶andеҗҺйқўзҡ„гҖӮ
дҪҶжҳҜеңЁи°ғдјҳдёҠпјҢORACLEзүҲжң¬жҳҜеҹәдәҺCBO规еҲҷзҡ„пјҲжҜ”еҰӮ10Gпјүе°ұеҸҜд»ҘдёҚиҖғиҷ‘andзҡ„е…ҲеҗҺйЎәеәҸи°ғдјҳпјҢеҰӮжһңжҳҜеҹәдәҺRBO规еҲҷпјҲжҜ”еҰӮ8iпјүпјҢи°ғж•ҙANdзҡ„е…ҲеҗҺйЎәеәҸеҸҜд»ҘиҫҫеҲ°дјҳеҢ–зҡ„ж•ҲжһңгҖӮ
В
еҸӮиҖғhttp://www.linuxidc.com/Linux/2011-12/50226.htm



зӣёе…іжҺЁиҚҗ
SqlиҜӯеҸҘжү§иЎҢйЎәеәҸSqlиҜӯеҸҘжү§иЎҢйЎәеәҸSqlиҜӯеҸҘжү§иЎҢйЎәеәҸSqlиҜӯеҸҘжү§иЎҢйЎәеәҸSqlиҜӯеҸҘжү§иЎҢйЎәеәҸSqlиҜӯеҸҘжү§иЎҢйЎәеәҸSqlиҜӯеҸҘжү§иЎҢйЎәеәҸ
е…ідәҺSQLиҜӯеҸҘеңЁиҝӣе…Ҙoracleеә“зј“еӯҳд№ӢеҗҺзҡ„жү§иЎҢйЎәеәҸзҡ„з®Җжһҗ~пјҒ
жң¬ж–Үе°ҶиҜҰз»Ҷд»Ӣз»Қж•°жҚ®еә“жҖ»з»“--SQLиҜӯеҸҘжү§иЎҢйЎәеәҸпјҢйңҖиҰҒдәҶи§ЈжӣҙеӨҡзҡ„жңӢеҸӢеҸҜд»ҘеҸӮиҖғдёӢ
жң¬ж–Үз»ҷеӨ§е®¶д»Ӣз»ҚSQLиҜӯеҸҘжү§иЎҢйЎәеәҸиҜҰи§ЈпјҢж¶үеҸҠеҲ°sqlиҜӯеҸҘжү§иЎҢйЎәеәҸзӣёе…ізҹҘиҜҶпјҢеҜ№sqlиҜӯеҸҘжү§иЎҢйЎәеәҸж„ҹе…ҙи¶Јзҡ„жңӢеҸӢдёҖиө·зңӢзңӢеҗ§
T-SQLиҜӯеҸҘжү§иЎҢзҡ„йЎәеәҸ
SQLиҜӯеҸҘзҡ„жү§иЎҢеҺҹзҗҶеҸҠйЎәеәҸпјҢеҘҪеҘҪеӯҰд№ еҗ§пјҒе“Ҳе“ҲпјҒ
SQLиҜӯеҸҘдёӯSELECTиҜӯеҸҘзҡ„жү§иЎҢйЎәеәҸпјӣ иҜҰз»Ҷзҡ„и®Іиҝ°дәҶSQLзҡ„SELECTиҜӯеҸҘзҡ„еҗ„дёӘеӯҗеҸҘдёҖиө·дҪҝз”Ёж—¶зҡ„жү§иЎҢдјҳе…Ҳзә§й—®йўҳпјӣ
SQL Select2008иҜӯеҸҘе®Ңж•ҙзҡ„жү§иЎҢйЎәеәҸ
гҖҖе…ідәҺOracleпјҢжҲ‘们йғҪе·Із»ҸеӯҰд№ дәҶSQLиҜӯеҸҘпјҢйӮЈд№ҲOracleе…¶е®һе·Із»ҸеӯҰд№ дәҶдёҖеӨ§еҚҠпјҢжҺҘдёӢжқҘиҮӘе·ұеӯҰд№ Oracleдё»иҰҒжҳҜзңӢдёҖдёӢд»–зҡ„жҰӮеҝөпјҢOracleе’ҢSQL ServerиҝҳжҳҜжңүеҫҲеӨ§дёҚеҗҢзҡ„пјҢзҶҹжӮүд»–зҡ„иЎЁз©әй—ҙиҝҷдәӣжҰӮеҝөпјҢдәҶи§Јд»–зҡ„еӣҫеҪўз•ҢйқўпјҢе’ҢеӨҮд»Ҫ...
жң¬ж–Үе°Ҷд»ҺMySQLжҖ»дҪ“жһ¶жһ„вҖ”>жҹҘиҜўжү§иЎҢжөҒзЁӢвҖ”>иҜӯеҸҘжү§иЎҢйЎәеәҸжқҘжҺўи®ЁдёҖдёӢе…¶дёӯзҡ„зҹҘиҜҶгҖӮ дёҖгҖҒMySQLжһ¶жһ„жҖ»и§Ҳпјҡ жһ¶жһ„жңҖеҘҪзңӢеӣҫпјҢеҶҚй…ҚдёҠеҝ…иҰҒзҡ„иҜҙжҳҺж–Үеӯ—гҖӮ дёӢеӣҫж №жҚ®еҸӮиҖғд№ҰзұҚдёӯдёҖеӣҫдёәеҺҹжң¬пјҢеҶҚеңЁе…¶дёҠж·»еҠ дёҠдәҶиҮӘе·ұзҡ„зҗҶи§ЈгҖӮ В д»Һ...
жү§иЎҢи®ЎеҲ’иЎЁзӨәдәҶSQLиҜӯеҸҘжү§иЎҢйЎәеәҸдёҺж–№жі•гҖӮ жү§иЎҢи®ЎеҲ’зҡ„еӯҳеӮЁж–№ејҸпјҡ дёҖдҪҶдә§з”ҹжү§иЎҢи®ЎеҲ’гҖӮиҝҷдёӘи®ЎеҲ’е°ұдјҡе’ҢsqlиҜӯеҸҘдёҖиө·еӯҳеӮЁеңЁlibrary cacheдёӯгҖӮsqlиҜӯеҸҘжҢүз…§hashзҡ„з®—жі•пјҢдә§з”ҹhash еҖјпјҢиҝҷйҮҢпјҢжҲ‘们еҸҜд»ҘжҠҠhashеҖјеҪ“еҒҡдёҖдёӘPKеҖјпјҢ...
ansi sqlдёӯSELECTиҜӯеҸҘзҡ„жү§иЎҢйЎәеәҸпјҢеҫҲжңүз”Ёзҡ„е“Ұ
еӣ жӯӨпјҢжҲ‘们еҲӣж–°жҖ§зҡ„жҸҗеҮәдәҶжҢүз…§SQLиҜӯеҸҘжү§иЎҢйЎәеәҸжқҘе®һзҺ°SQLеҲ°иҮӘ然иҜӯиЁҖзҡ„зҝ» иҜ‘гҖӮжң¬ж–Үдё»иҰҒеҒҡзҡ„е·ҘдҪңеҰӮдёӢпјҡ(1) и®ҫи®ЎдәҶSQLиҜӯиЁҖзҡ„иҜҚ法规еҲҷгҖҒиҜӯ法规еҲҷпјҢ然еҗҺеҲ©з”Ё ANTLRе·Ҙе…·з”ҹжҲҗSQLиҜӯеҸҘеҜ№еә”зҡ„жҠҪиұЎиҜӯжі•ж ‘гҖӮ(2) и®ҫи®ЎдәҶSQLеҜ№еә”зҡ„...
SQL иҜӯеҸҘзҡ„жү§иЎҢйЎәеәҸи·ҹе…¶иҜӯеҸҘзҡ„иҜӯжі•йЎәеәҸ并дёҚдёҖиҮҙ дёҖиҲ¬иҖҢиЁҖ SQL иҜӯеҸҘзҡ„иҜӯжі•йЎәеәҸжҳҜпјҡ SELECT[DISTINCT] FROM WHERE GROUP BY HAVING UNION ORDER BY е…¶жү§иЎҢйЎәеәҸдёәпјҡ FROM WHERE GROUP BY HAVING SELECT DISTINCT UNION...
1 :жҷ®йҖҡSQLиҜӯеҸҘеҸҜд»Ҙз”ЁExecжү§иЎҢ дҫӢ: Select * from tableName Exec('select * from tableName') Exec sp_executesql N'select * from tableName' -- иҜ·жіЁж„Ҹеӯ—з¬ҰдёІеүҚдёҖе®ҡиҰҒеҠ N 2:еӯ—ж®өеҗҚпјҢиЎЁеҗҚпјҢж•°жҚ®еә“еҗҚд№Ӣзұ»...
SqlжҹҘиҜўиҜӯеҸҘзҡ„зҡ„жү§иЎҢйЎәеәҸ.xmind
жү§иЎҢйЎәеәҸе‘ўпјҹеңЁеӣһзӯ”иҝҷдёӘй—®йўҳеүҚпјҢжҲ‘们е…ҲжқҘеӣһйЎҫдёҖдёӢпјҡеңЁORACLEж•°жҚ®еә“жһ¶жһ„дёӢпјҢSQLиҜӯеҸҘз”ұз”ЁжҲ·иҝӣзЁӢдә§з”ҹпјҢ然еҗҺдј еҲ°зӣёеҜ№еә”зҡ„жңҚеҠЎз«ҜиҝӣзЁӢпјҢд№ӢеҗҺз”ұжңҚеҠЎеҷЁиҝӣзЁӢжү§иЎҢиҜҘSQLиҜӯеҸҘпјҢеҰӮжһңжҳҜSELECTиҜӯеҸҘпјҢжңҚеҠЎеҷЁиҝӣзЁӢиҝҳйңҖиҰҒе°Ҷжү§иЎҢз»“жһңеӣһдј ...
жң¬ж–Үе°ұsqlе’Ңmysqlзҡ„иҜӯеҸҘжү§иЎҢйЎәеәҸй—®йўҳеҗ‘еӨ§е®¶дҪңдәҶиҜҰз»Ҷд»Ӣз»ҚпјҢе°Ҹзј–и§үеҫ—жҢәдёҚй”ҷзҡ„пјҢиҝҷйҮҢеҲҶдә«дёӢпјҢдҫӣеӨ§е®¶еҸӮиҖғгҖӮ