1.3 准备Hadoop源代码
在Hadoop的官方网站(http://hadoop.apache.org/)中,可以找到Hadoop项目相关的信息,如图1-14所示。
1.3.1 下载Hadoop
前面在介绍Hadoop生态系统的时候,已经了解到Hadoop发展初期的系统中包括Common(开始使用的名称是Core)、HDFS和MapReduce三部分,现在这些子系统都已经独立,成为Apache的子项目。但在Hadoop 1.0的发行包中,Common、HDFS和MapReduce还是打包在一起,我们只需要下载一个hadoop-1.0.0.tar.gz包即可。注意,Hadoop官方也提供Subversion(SVN)方式的代码下载,SVN地址为http://svn.apache.org/repos/asf/hadoop/common/tags/release-0.1.0/。
熟悉Subversion的读者,也可以通过该地址下载Hadoop1.0版本代码,该Tag也包含了上述三部分的代码。
Apache提供了大量镜像网站,供大家下载它的软件和源码,上面提到的hadoop-1.0.0.tar.gz的一个下载地址为http://apache.etoak.com/hadoop/common/hadoop-1.0.0,如图1-15所示。
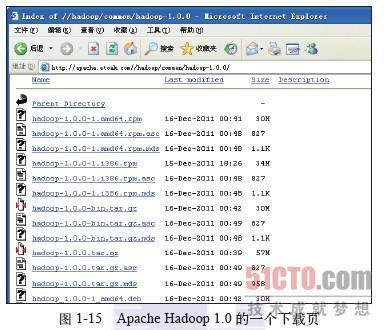
该地址包含了Hadoop 1.0的多种发行方式,如64位系统上的hadoop-1.0.0-1.adm64.rpm、不包含源代码的发行包hadoop-1.0.0.bin.tar.gz等。下载的hadoop-1.0.0.tar.gz是包括源代码的Hadoop发行包。
1.3.2 创建Eclipse项目
解压下载的hadoop-1.0.0.tar.gz包,假设解压后Hadoop的根目录是E:\hadoop-1.0.0,启动Cygwin,进入项目的根目录,我们开始将代码导入Eclipse。Hadoop的Ant配置文件build.xml中提供了eclipse任务,该任务可以为Hadoop代码生成Eclipse项目文件,免去创建Eclipse项目所需的大量配置工作。只需在Cygwin下简单地执行“ant eclipse”命令即可,如图1-16所示。

在Ubutu环境下注意安装:ant、libtool。

注意 该过程需要使用UNIX的在线编辑器sed,所以一定要在Cygwin环境里执行上述命令,否则会出错。
命令运行结束后,就可以在Eclipse中创建项目了。打开Eclipse的File→New→Java Project,创建一个新的Java项目,选择项目的位置为Hadoop的根目录,即E:\hadoop-1.0.0,然后单击“Finish”按钮,就完成了Eclipse项目的创建,如图1-17所示。

完成上述工作以后,Eclipse提示一个错误:“Unbound classpath variable: 'ANT_HOME/lib/ant.jar' in project 'hadoop-1.0.0'”。
显然,我们需要设置系统的ANT_HOME变量,让Eclipse能够找到编译源码需要的Ant库,选中项目,然后打开Eclipse的Project→Properties→Java Build Path,在Libraries页编辑(单击“Edit”按钮)出错的项:ANT_HOME/lib/ant.jar,创建变量ANT_HOME(在接下来第一个对话框里单击“Varliable”,第二个对话框里单击“New”按钮),其值为Ant的安装目录,如图1-18所示。
由于本书只分析Common和HDFS两个模块,在Project→Properties→Java Build Path的Source页只保留两个目录,分别是core和hdfs,如图1-19所示。
完成上述操作以后,创建Eclipse项目的任务就完成了。

1.3.3 Hadoop源代码组织
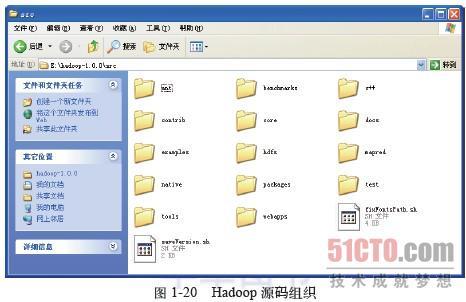
打开已经解压的Hadoop 1.0源代码,进入src目录,该目录包含了Hadoop中所有的代码,如图1-20所示。
前面已经提到过,Hadoop 1.0的发行包中,Common、HDFS和MapReduce三个模块还是打包在一起的,它们的实现分别位于core、hdfs和mapred子目录下。源代码目录src下还有若干值得关注的子目录,具体如下。
tools:包含Hadoop的一些实用工具的实现,如存档文件har、分布式拷贝工具distcp、MapReduce执行情况分析工具rumen等。
benchmarks:包含对Hadoop进行性能测试的两个工具gridmix和gridmix2,通过这些工具,可以测试Hadoop集群的一些性能指标。
c++:需要提及的是libhdfs,它通过Java的C语言库界面,实现了一套访问HDFS的C接口。
examples:为开发人员提供了一些使用Hadoop的例子,不过这些例子只涉及MapReduce的API,本书中不会讨论这部分内容。
contrib:是contribution的缩写,包含大量Hadoop辅助模块的实现,如在亚马逊弹性计算云上部署、运行Hadoop所需的脚本就在contrib\ec2目录下。
test:包含项目的单元测试用例,在该目录中能找到Common、HDFS和MapReduce等模块的单元测试代码。
分享到:




相关推荐
本文件内包含spark1.3与hadoop2.6的环境配置 包括yarn等模式,服务器上测试稳定。只需要更改自己的hostname即可使用
Hadoop源代码分析完整版.pdf Hadoop源代码分析 hadoop mapreduce
深入云计算:Hadoop源代码分析(修订版)
Hadoop源代码分析(完整版).pdf
Hadoop的源代码分析
Hadoop 源代码分析 完整版
Hadoop源代码分析 分析了hadoop的一些包,一些类 ,需要对hadoop深入了解的可以看看
Hadoop源代码分析完整版.pdf
hadoop源代码存档
进军Hadoop源代码,进军Hadoop源代码,进军Hadoop源代码,进军Hadoop源代码
大数据处理系统:Hadoop源代码情景分析(采用Hadoop 2.6)
Hadoop源代码eclipse编译指南 Hadoop源代码eclipse编译指南
Hadoop源代码eclipse编译教程
包mapreduce.lib.map的Hadoop源代码分析
hadoop源代码归档
NULL 博文链接:https://xinyu4856.iteye.com/blog/2023886
资源名称:大数据处理系统:Hadoop源代码情景分析内容简介:Hadoop是目前重要的一种开源的大数据处理平台,读懂Hadoop的源代码,深入理解其各种机理,对于掌握大数据处理的技术有着显而易见的重要性。 本书从大数据...