
本文转载自CSDN博客,纯为技术资料备份!
MapReduce的名字源于函数式编程模型中的两项核心操作:Map和Reduce。也许熟悉Functional Programming(FP)的人见到这两个词会倍感亲切。因为Map和Reduce这两个术语源自Lisp语言和函数式编程。Map是把一组数据一对一的映射为另外的一组数据,其映射的规则由一个函数来指定。Reduce是对一组数据进行归约,这个归约的规则由一个函数指定。Map是一个把数据分开的过程,Reduce则是把分开的数据合并的过程。如Hadoop的wordcount例子:用Map把[one,word,one,dream]进行映射就变成了[{one,1}, {word,1}, {one,1}, {dream,1}],再用Reduce把[{one,1}, {word,1}, {one,1}, {dream,1}]归约变成[{one,2}, {word,1}, {dream,1}]的结果集。
对数组里的每个元素进行相同操作的一段代码:
a = [1, 2, 3];
for (i = 0; i < a.length; i++){
a[i] = a[i] * 2;
}
for (i = 0; i < a.length; i++){
print(a[i]);
}
常常要对数组里的所有元素做同一件事情,因此你可以写个这样的函数:
function map(fn, a){
for (i = 0; i < a.length; i++){
fn(a[i]);
}
}
现在可以把上面的东西改成:
map(function(x) { return x * 2; }, a);
map(print, a);
另一个常见的任务是将数组内的所有元素按照某种方式汇总起来:
function sum(a){
s = 0;
for (i = 0; i < a.length; i++){
s += a[i];
}
return s;
}
function join(a){
s = "";
for (i = 0; i < a.length; i++){
s = s .. a[i]; // ..是字符串连接操作符
}
return s;
}
print(sum([1,2,3]));
print(join(["a","b","c"]));
注意sum和join长得很像,你也许想把它们抽象为一个将数组内的所有元素按某种算法汇总起來的泛型函数:
function reduce(fn, a, init){
s = init;
for (i = 0; i < a.length; i++){
s = fn(s, a[i]);
}
return s;
}
这样sum和join就变成下面的样子了:
function sum(a){
return reduce(function(a, b) { return a + b; }, a, 0 );
}
function join(a){
return reduce(function(a, b) { return a .. b; }, a, "" );
}
让我们看回map函数。当你要对数组内的每个元素做一些事,你很可能不在乎哪个元素先做。无论由第一个元素开始执行,还是是由最后一个元素开始执行,你的结果都是一样的。这样如果你手头上有2个CPU,你可以写段代码,使它们各自处理1/2的元素,于是乎map快了两倍。设想你在全球有千千万万台服务器,恰好你有一个真的很大很大的数组,现在你可以在几千台服务器上同时执行map,让每台服务器都来解决同一个问题的一小部分。
Map的定义:
Map, written by the user, takes an input pair and produces a set of intermediate key/value pairs. The MapReduce library groups together all intermediate values associated with the same intermediate key I and passes them to the Reduce function.
Reduce的定义:
The Reduce function, also written by the user, accepts an intermediate key I and a set of values for that key. It merges together these values to form a possibly smaller set of values. Typically just zero or one output value is produced per Reduce invocation. The intermediate values are supplied to the user’s reduce function via an iterator. This allows us to handle lists of values that are too large to fit in memory.
MapReduce论文中给出了这样一个例子:在一个文档集合中统计每个单词出现的次数。Map操作的输入是每一篇文档,将输入文档中每一个单词的出现输出到中间文件中去。
map(String key, String value):
// key: document name
// value: document contents
for each word w in value:
EmitIntermediate(w, "1");
比如我们有两篇文档,内容分别是
A - "I love programming"
B - "I am a blogger, you are also a blogger"
A文档经过Map运算后输出的中间文件将会是:
I,1
love,1
programming,1
B文档经过Map运算后输出的中间文件将会是:
I,1
am,1
a,1
blogger,1
you,1
are,1
also,1
a,1
blogger,1
Reduce操作的输入是单词和出现次数的序列。用上面的例子来说,就是 (I, [1, 1]), (love, [1]), (programming, [1]), (am, [1]), (a, [1,1]) 等。然后根据每个单词,算出总的出现次数。
reduce(String key, Iterator values):
// key: a word
// values: a list of counts
int result = 0;
for each v in values:
result += ParseInt(v);
Emit(AsString(result));
最终结果是:("I", "2"), ("a", "2"), ……
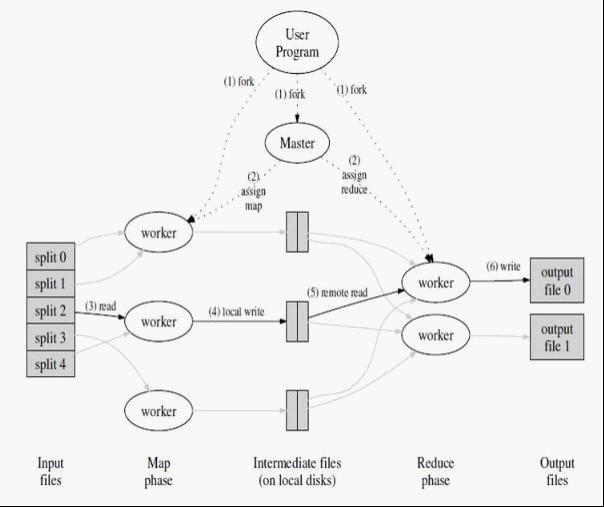
实际的执行顺序是:
MapReduce Library将Input分成M份。这里的Input Splitter也可以是多台机器并行Split。
Master将M份Job分给Idle状态的M个worker来处理;
对于输入中的每一个<key, value> pair 进行Map操作,将中间结果Buffer在Memory里;
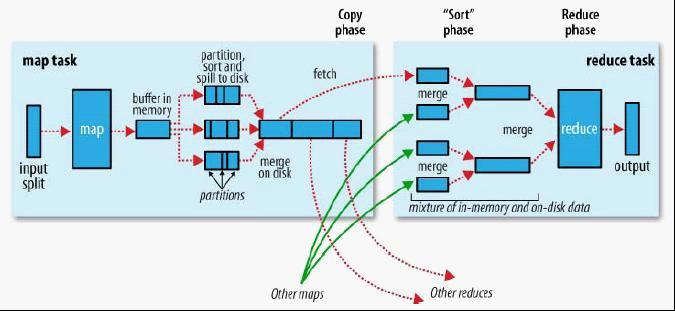
定期的(或者根据内存状态),将Buffer中的中间信息Dump到本地磁盘上,并且把文件信息传回给Master(Master需要把这些信息发送给Reduce worker)。这里最重要的一点是,在写磁盘的时候,需要将中间文件做Partition(比如R个)。拿上面的例子来举例,如果把所有的信息存到一个文件,Reduce worker又会变成瓶颈。我们只需要保证相同Key能出现在同一个Partition里面就可以把这个问题分解。
R个Reduce worker开始工作,从不同的Map worker的Partition那里拿到数据(read the buffered data from the local disks of the map workers),用key进行排序(如果内存中放不下需要用到外部排序 – external sort)。很显然,排序(或者说Group)是Reduce函数之前必须做的一步。 这里面很关键的是,每个Reduce worker会去从很多Map worker那里拿到X(0<X<R) Partition的中间结果,这样,所有属于这个Key的信息已经都在这个worker上了。
Reduce worker遍历中间数据,对每一个唯一Key,执行Reduce函数(参数是这个key以及相对应的一系列Value)。
执行完毕后,唤醒用户程序,返回结果(最后应该有R份Output,每个Reduce Worker一个)。
可见,这里的分(Divide)体现在两步,分别是将输入分成M份,以及将Map的中间结果分成R份。将输入分开通常很简单,Map的中间结果通常用”hash(key) mod R”这个结果作为标准,保证相同的Key出现在同一个Partition里面。当然,使用者也可以指定自己的Partition Function,比如,对于Url Key,如果希望同一个Host的URL出现在同一个Partition,可以用”hash(Hostname(urlkey)) mod R”作为Partition Function。
对于上面的例子来说,每个文档中都可能会出现成千上万的 ("the", 1)这样的中间结果,琐碎的中间文件必然导致传输上的损失。因此,MapReduce还支持用户提供Combiner Function。这个函数通常与Reduce Function有相同的实现,不同点在于Reduce函数的输出是最终结果,而Combiner函数的输出是Reduce函数的某一个输入的中间文件。



相关推荐
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念"Map(映射)"和"Reduce(化简)",和他们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。他极大地方便了编程...
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念"Map(映射)"和"Reduce(归约)",是它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。它极大地方便了编程...
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念"Map(映射)"和"Reduce(归约)",是它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性...
MapReduce将复杂的、运行于大规模集群上的并行计算过程高度地抽象到了两个函数:Map和Reduce,并极大地方便了分布式编程工作,编程人员在不会分布式并行编程的情况下,也可以很容易将自己的程序运行在分布式系统上,...
针对以上问题,紧密结合MapReduce模型提供的高效分布式编程和运行框架,在深入分析H-mine频繁模式挖掘算法的基础上,通过对H-mine算法频繁模式挖掘过程的并行化改进,提出了一种新颖的基于MapReduce模型的H-mine算法...
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念"Map(映射)"和"Reduce(归约)",是它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。它极大地方便了编程...
简单地说,Hadoop是一个实现可靠、可扩展、分布式运算的开源软件平台,它也是Google著名的分布式文件系统Google File System和分布式并行开发框架MapReduce的开源版本。 包含以下资源: Hadoop分布式安装与配置手册...
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念"Map(映射)"和"Reduce(归约)",和它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。它极大地方便了编程人员在...
MapReduce是一个编程模型,也是一个处理和生成超大数据集的算法模型的相关实现。用户首先创建 一个Map函数处理一个基于key/value pair的数据集合,输出中间的基于key/value pair的数据集合;然 后再创建一个Reduce...
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念"Map(映射)"和"Reduce(归约)",是它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。它极大地方便了编程...
Google三大神器 具备海量数据存储和访问的分布式文件系统 GFS 简洁高效的并行计算编程模型 MapReduce 支持海量结构化数据管理的BigTable 大数据分析技术基础教学课件3-大数据处理平台Hadoop全文共27页,当前为第5页...
云计算的核心技术 (1)编程模型 MapReduce是Google开发的java、Python、C++编程模型,它是一种简化的分布式编 程模型和高效的任务调度模型,用于大规模数据集(大于1TB)的并行运算。严格的编程 模型使云计算环境下...
百度百科:MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念"Map(映射)"和"Reduce(归约)",和他们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。它极大地...
MapReduce批处理 MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念"Map(映射)"和"Reduce(归约)",是它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。它...
MapReduce 就是一种简化并行计算的编程模型,降低了开发并行应用的入门门槛。 Hadoop MapReduce 构思体现在如下的三个方面: 如何对付大数据处理:分而治之 对相互间不具有计算依赖关系的大数据,实现并行最...
Spark是专门为大数据处理而设计的一个适合迭代运算的并行计算模型,相比MapReduce具有更高效、充分利用内存、更适合迭代计算和交互式处理的优点。对已有的基于Spark的并行关联规则挖掘算法进行了分类和综述,并总结...
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念"Map(映射)"和"Reduce(归约)",是它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。它极大地方便了编程...
针对以上问题,紧密结合MapReduce模型提供的高效分布式编程和运行框架,在深入分析H-mine频繁模式挖掘算法的基础上,通过对H-mine算法频繁模式挖掘过程的并行化改进,提出了一种新颖的基于MapReduce模型的H-mine算法...
MapReduce是Google开发的java、Python、C++编程模型,它是一种简化的分布式编程模型和高效的任务调度模型,用于大规模数据集(大于1TB)的并行运算。严格的编程模型使云计算环境下的编程十分简单。MapReduce模式的...
MapReduce是Google开发的java、Python、C++编程模型,它是一种简化的分布式编程模型和高效的任务调度模型,用于大规模数据集(大于1TB)的并行运算。严格的编程模型使云计算环境下的编程十分简单。MapReduce模式的...