- 浏览: 73662 次
-

文章分类
最新评论
Step by Step!Kubernetes持续部署指南
本文是作者通过亲身实践,从零基础开始,一步一步总结出来的Kubernetes持续部署工作流程。文章从前期的工具准备开始,到复刻存储库、测试、构建镜像、构建流水线最后进行部署,所有的工作流程都一一展现在文章中,对于想要拥有全自动持续交付流水线的用户将有很大的借鉴意义。

在很久很久以前的一份工作中,我的任务是将老式的LAMP堆栈切换到Kubernetes上。那会儿我的老板总是追逐新技术,认为只需要几天时间就能够完成新旧技术的迭代——鉴于那时我们甚至对容器的工作机制一无所知,所以不得不说老板的想法真的很大胆。
在阅读了官方文档并且搜索了很多信息之后,我们开始感到不知所措——有许多新的概念需要学习:pod、容器以及replica等。对我而言,Kubernetes似乎只是为一群聪明的开发者而设计的。
然后我做了我在这一状况下常做的事:通过实践来学习。通过一个简单的例子可以很好地理解错综复杂的问题,所以我自己一步一步完成了整个部署过程。
最后,我们做到了,虽然远未达到规定的一周时间——我们花了将近一个月的时间来创建三个集群,包括它们的开发、测试和生产。
本文我将详细介绍如何将应用程序部署到Kubernetes。阅读完本文之后,你将拥有一个高效的Kubernetes部署和持续交付工作流程。
持续集成与交付
持续集成是在每次应用程序更新时构建和测试的实践。通过以少量的工作,更早地检测到错误并立即解决。
集成完成并且所有测试都通过之后,我们就能够添加持续交付到自动化发布和部署的流程中。使用CI/CD的项目可以更频繁、更可靠地发布。
我们将使用Semaphore,这是一个快速、强大且易用地持续集成和交付(CI/CD)平台,它能够自动执行所有流程:
1、 安装项目依赖项
2、 运行单元测试
3、 构建一个Docker镜像
4、 Push镜像到Docker Hub
5、 一键Kubernetes部署
对于应用程序,我们有一个Ruby Sinatra微服务,它暴露一些HTTP端点。该项目已包含部署所需的所有内容,但仍需要一些组件。
准备工作
在开始操作之前,你需要登录Github和Semaphore账号。此外,为后续方便拉取或push Docker镜像,你需要登录Docker Hub。
接下来,你需要在计算机上安装一些工具:
-
Git:处理代码
-
curl:网络的“瑞士军刀”
-
kubectl:远程控制你的集群
当然,千万不要忘了Kubernetes。大部分的云供应商都以各种形式提供此服务,选择适合你的需求的即可。最低端的机器配置和集群大小足以运行我们示例的app。我喜欢从3个节点的集群开始,但你可以只用1个节点的集群。
集群准备好之后,从你的供应商中下载kubeconfig文件。有些允许你直接从其web控制台下载,有些则需要帮助程序。我们需要此文件才能连接到集群。
有了这个,我们已经可以开始了。首先要做的是fork存储库。
Fork存储库
在这篇文章中fork我们将使用的演示应用程序。
-
访问semaphore-demo-ruby-kubernetes存储库,并且点击右上方的Fork按钮
-
点击Clone or download按钮并且复制地址
-
复制存储库:$ git clone https://github.com/your_repository_path…
使用Semaphore连接新的存储库
1、 登录到你的Semaphore
2、 点击侧边栏的链接,创建一个新项目
3、 点击你的存储库旁【Add Repository】按钮
使用Semaphore测试
持续集成让测试变得有趣并且高效。一个完善的CI 流水线能够创建一个快速反馈回路以在造成任何损失之前发现错误。我们的项目附带一些现成的测试。
打开位于.semaphore/semaphore.yml的初始流水线文件,并快速查看。这个流水线描述了Semaphore构建和测试应用程序所应遵循的所有步骤。它从版本和名称开始。
version: v1.0
name: CI
接下来是agent,它是为job提供动力的虚拟机。我们可以从3种类型中选择:
agent:
machine:
type: e1-standard-2
os_image: ubuntu1804
Block(块)、任务以及job定义了在流水线的每个步骤中要执行的操作。在Semaphore,block按照顺序运行,与此同时,在block中的job也会并行运行。流水线包含2个block,一个是用于库安装,一个用于运行测试。
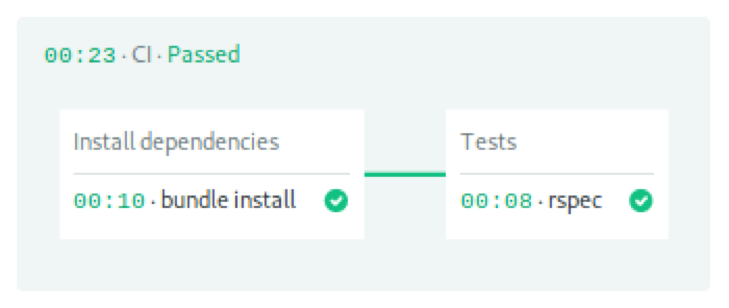
第一个block下载并安装了Ruby gems。
- name: Install dependencies
task:
jobs:
- name: bundle install
commands:
- checkout
- cache restore gems-$SEMAPHORE_GIT_BRANCH-$(checksum Gemfile.lock),gems-$SEMAPHORE_GIT_BRANCH,gems-master
- bundle install --deployment --path .bundle
- cache store gems-$SEMAPHORE_GIT_BRANCH-$(checksum Gemfile.lock) .bundle
Checkout复制了Github里的代码。既然每个job都在完全隔离的机器里运行,那么我们必须依赖缓存(cache)来在job运行之间存储和检索文件。
blocks:
- name: Install dependencies
task:
jobs:
- name: bundle install
commands:
- checkout
- cache restore gems-$SEMAPHORE_GIT_BRANCH-$(checksum Gemfile.lock),gems-$SEMAPHORE_GIT_BRANCH,gems-master
- bundle install --deployment --path .bundle
- cache store gems-$SEMAPHORE_GIT_BRANCH-$(checksum Gemfile.lock) .bundle
第二个block进行测试。请注意我们重复使用了checkout和cache的代码以将初始文件放入job中。最后一个命令用于启动RSpec测试套件。
- name: Tests
task:
jobs:
- name: rspec
commands:
- checkout
- cache restore gems-$SEMAPHORE_GIT_BRANCH-$(checksum Gemfile.lock),gems-$SEMAPHORE_GIT_BRANCH,gems-master
- bundle install --deployment --path .bundle
- bundle exec rspec
最后一个部分我们来看看Promotion。Promotion能够在一定条件下连接流水线以创建复杂的工作流程。所有job完成之后,我们使用 auto_promote_on来启动下一个流水线。
promotions:
- name: Dockerize
pipeline_file: docker-build.yml
auto_promote_on:
- result: passed
工作流程继续执行下一个流水线。
构建Docker镜像
我们可以在Kubernetes上运行任何东西,只要它打包在Docker镜像中。在这一部分,我们将学习如何构建镜像。
我们的Docker镜像将包含应用程序的代码、Ruby以及所有的库。让我们先来看一下Dockerfile:
FROM ruby:2.5
RUN apt-get update -qq && apt-get install -y build-essential
ENV APP_HOME /app
RUN mkdir $APP_HOME
WORKDIR $APP_HOME
ADD Gemfile* $APP_HOME/
RUN bundle install --without development test
ADD . $APP_HOME
EXPOSE 4567
CMD ["bundle", "exec", "rackup", "--host", "0.0.0.0", "-p", "4567"]
Dockerfile就像一个详细的菜谱,包含所有构建容器镜像所需要的步骤和命令:
1、 从预构建的ruby镜像开始
2、 使用apt-get安装构建工具
3、 复制Gemfile,因为它具有所有的依赖项
4、 用bundle安装它们
5、 复制app的源代码
6、 定义监听端口和启动命令
我们将在Semaphore环境中bake我们的生产镜像。然而,如果你想要在计算机上进行一个快速的测试,那么请输入:
$ docker build . -t test-image
使用Docker运行和暴露内部端口4567以在本地启动服务器:
$ docker run -p 4567:4567 test-image
你现在可以测试一个可用的HTTP端点:
$ curl -w "\n" localhost:4567
hello world :))
添加Docker Hub账户到Semaphore
Semaphore有一个安全的机制以存储敏感信息,如密码、令牌或密钥等。为了能够push镜像到你的Docker Hub镜像仓库中,你需要使用你的用户名和密码来创建一个Secret:
-
打开你的Semaphore
-
在左侧导航栏中,点击【Secret】
-
点击【Creat New Secret】
-
Secret的名字应该是Dockerhub,键入登录信息(如下图所示),并保存。
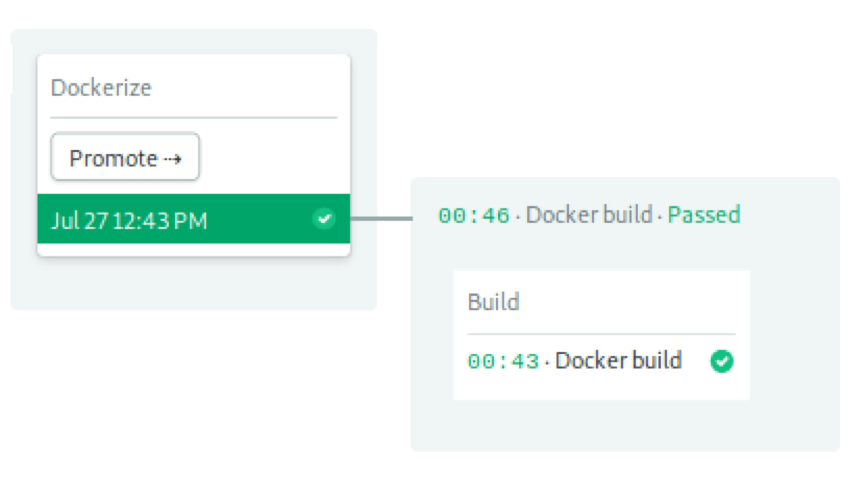
构建Docker流水线
这个流水线开始构建并且push镜像到Docker Hub,它仅仅有1个block和1个job:

这次,我们需要使用更好的性能,因为Docker往往更加耗费资源。我们选择具有四个CPU,8GB RAM和35GB磁盘空间的中端机器e1-standard-4:
version: v1.0
name: Docker build
agent:
machine:
type: e1-standard-4
os_image: ubuntu1804
构建block通过登录到Docker Hub启动,用户名和密码可以从我们刚创建的secret导入。登录之后,Docker可以直接访问镜像仓库。
下一个命令是docker pull,它试图拉取最新镜像。如果找到镜像,那么Docker可能能够重新使用其中的一些层,以加速构建过程。如果没有最新镜像,也无需担心,只是需要花费长一点的时间来构建。
最后,我们push新的镜像。注意,这里我们使用SEMAPHORE_WORKFLOW_ID 变量来标记镜像。
blocks:
- name: Build
task:
secrets:
- name: dockerhub
jobs:
- name: Docker build
commands:
- echo "${DOCKER_PASSWORD}" | docker login -u "${DOCKER_USERNAME}" --password-stdin
- checkout
- docker pull "${DOCKER_USERNAME}"/semaphore-demo-ruby-kubernetes:latest || true
- docker build --cache-from "${DOCKER_USERNAME}"/semaphore-demo-ruby-kubernetes:latest -t "${DOCKER_USERNAME}"/semaphore-demo-ruby-kubernetes:$SEMAPHORE_WORKFLOW_ID .
- docker images
- docker push "${DOCKER_USERNAME}"/semaphore-demo-ruby-kubernetes:$SEMAPHORE_WORKFLOW_ID
当镜像准备完毕,我们进入项目的交付阶段。我们将用手动promotion来扩展我们的Semaphore 流水线。
promotions:
- name: Deploy to Kubernetes
pipeline_file: deploy-k8s.yml
要进行第一次自动构建,请进行push:
$ touch test-build
$ git add test-build
$ git commit -m "initial run on Semaphore“
$ git push origin master
镜像准备完成之后,我们就可以进入部署阶段。
部署到Kubernetes
自动部署是Kubernetes的强项。我们所需要做的就是告诉集群我们最终的期望状态,剩下的将由它来负责。
然而,在部署之前,你必须将kubeconfig文件上传到Semaphore。
上传Kubeconfig到Semaphore
我们需要第二个secret:集群的kubeconfig。这个文件授予可以对它的管理访问权限。因此,我们不希望将文件签入存储库。
创建一个名为do-k8s的secret并且将kubeconfig文件上传到/home/semaphore/.kube/dok8s.yaml中:
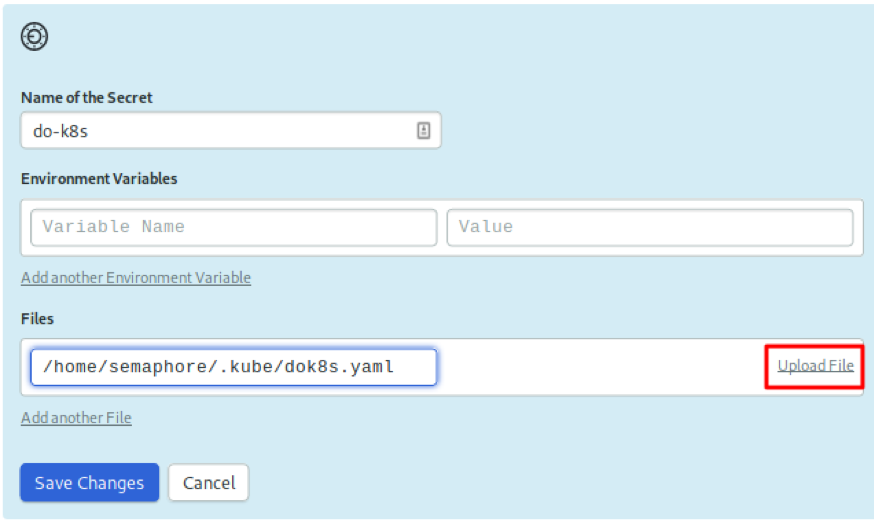
部署清单
尽管Kubernetes已经是容器编排平台,但是我们不直接管理容器。实际上,部署的最小单元是pod。一个pod就好像一群形影不离的朋友,总是一起去同一个地方。因此要保证在pod中的容器运行在同一个节点上并且有相同的IP。它们可以同步启动和停止,并且由于它们在同一台机器上运行,因此它们可以共享资源。
pod的问题在于它们可以随时启动和停止,我们没办法确定它们会被分配到的pod IP。要把用户的http流量转发,还需要提供一个公共IP和一个负载均衡器,它负责跟踪pod和转发客户端的流量。
打开位于deploymente.yml的文件。这是一个部署我们应用程序的清单,它被3个dash分离成两个资源。第一个,部署资源:
apiVersion: apps/v1
kind: Deployment
metadata:
name: semaphore-demo-ruby-kubernetes
spec:
replicas: 1
selector:
matchLabels:
app: semaphore-demo-ruby-kubernetes
template:
metadata:
labels:
app: semaphore-demo-ruby-kubernetes
spec:
containers:
- name: semaphore-demo-ruby-kubernetes
image: $DOCKER_USERNAME/semaphore-demo-ruby-kubernetes:$SEMAPHORE_WORKFLOW_ID
这里有几个概念需要厘清:
-
资源都有一个名称和几个标签,以便组织
-
Spec定义了最终期望的状态,template是用于创建Pod的模型。
-
Replica设置要创建的pod的副本数。我们经常将其设置为集群中的节点数。既然我们使用了3个节点,我将这一命令行更改为replicas:3
第二个资源是服务。它绑定到端口80并且将HTTP流量转发到部署中的pod:
---
apiVersion: v1
kind: Service
metadata:
name: semaphore-demo-ruby-kubernetes-lb
spec:
selector:
app: semaphore-demo-ruby-kubernetes
type: LoadBalancer
ports:
- port: 80
targetPort: 4567
Kubernetes将selector与标签相匹配以便将服务与pod连接起来。因此,我们在同一个集群中有许多服务和部署并且根据需要连接他们。
部署流水线
我们现在进入CI/CD配置的最后一个阶段。这时,我们有一个定义在semaphore.yml的CI流水线,以及定义在docker-build.yml的Docker流水线。在这一步中,我们将部署到Kubernetes。
打开位于.semaphore/deploy-k8s.yml的部署流水线:
version: v1.0
name: Deploy to Kubernetes
agent:
machine:
type: e1-standard-2
os_image: ubuntu1804
两个job组成最后的流水线:
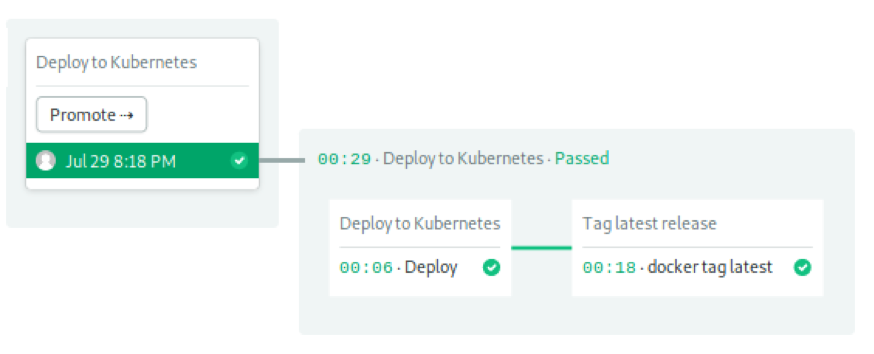
Job 1开始部署。导入kubeconfig文件之后,envsubst将deployment.yaml中的占位符变量替换为其实际值。然后,kubectl apply将清单发送到集群。
blocks:
- name: Deploy to Kubernetes
task:
secrets:
- name: do-k8s
- name: dockerhub
env_vars:
- name: KUBECONFIG
value: /home/semaphore/.kube/dok8s.yaml
jobs:
- name: Deploy
commands:
- checkout
- kubectl get nodes
- kubectl get pods
- envsubst < deployment.yml | tee deployment.yml
- kubectl apply -f deployment.yml
Job 2将镜像标记为最新,以让我们能够在下一次运行中将其作为缓存使用。
- name: Tag latest release
task:
secrets:
- name: dockerhub
jobs:
- name: docker tag latest
commands:
- echo "${DOCKER_PASSWORD}" | docker login -u "${DOCKER_USERNAME}" --password-stdin
- docker pull "${DOCKER_USERNAME}"/semaphore-demo-ruby-kubernetes:$SEMAPHORE_WORKFLOW_ID
- docker tag "${DOCKER_USERNAME}"/semaphore-demo-ruby-kubernetes:$SEMAPHORE_WORKFLOW_ID "${DOCKER_USERNAME}"/semaphore-demo-ruby-kubernetes:latest
- docker push "${DOCKER_USERNAME}"/semaphore-demo-ruby-kubernetes:latest
这是工作流程的最后一步了。
部署应用程序
让我们教我们的Sinatra应用程序唱歌。在app.rb中的App类中添加以下代码:
get "/sing" do
"And now, the end is near
And so I face the final curtain..."
end
推送修改的文件到Github:
$ git add .semaphore/*
$ git add deployment.yml
$ git add app.rb
$ git commit -m "test deployment”
$ git push origin master
等到docker构建流水线完成,你可以查看Semaphore的进度:

是时候进行部署了,点击Promote按钮,看它是否工作:
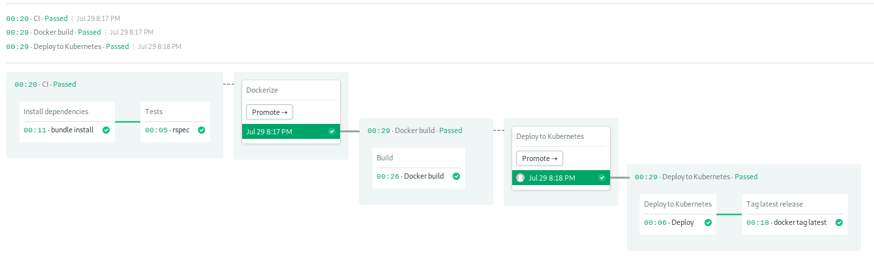
我们已经有了一个好的开始,现在就看Kubernetes的了。我们可以使用kubectl检查部署状态,初始状态是三个所需的pod并且零可用:
$ kubectl get deployments
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
semaphore-demo-ruby-kubernetes 3 0 0 0 15m
几秒之后,pod已经启动,reconciliation已经完成:
$ kubectl get deployments
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
semaphore-demo-ruby-kubernetes 3 3 3 3 15m
使用get all获得集群的通用状态,它显示了pod、服务、部署以及replica:
$ kubectl get all
NAME READY STATUS RESTARTS AGE
pod/semaphore-demo-ruby-kubernetes-7d985f8b7c-454dh 1/1 Running 0 2m
pod/semaphore-demo-ruby-kubernetes-7d985f8b7c-4pdqp 1/1 Running 0 119s
pod/semaphore-demo-ruby-kubernetes-7d985f8b7c-9wsgk 1/1 Running 0 2m34s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes ClusterIP 10.12.0.1 443/TCP 24m
service/semaphore-demo-ruby-kubernetes-lb LoadBalancer 10.12.15.50 35.232.70.45 80:31354/TCP 17m
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
deployment.apps/semaphore-demo-ruby-kubernetes 3 3 3 3 17m
NAME DESIRED CURRENT READY AGE
replicaset.apps/semaphore-demo-ruby-kubernetes-7d985f8b7c 3 3 3 2m3
Service IP在pod之后展示。对于我来说,负载均衡器被分配到外部IP 35.232.70.45。需要将其更改为你的提供商分配给你的那个,然后我们来试试新的服务器。
$ curl -w "\n" http://YOUR_EXTERNAL_IP/sing
现在,离结束已经不远了。
胜利近在咫尺
当你使用了正确的CI/CD解决方案之后,部署到Kubernetes并不是那么困难。你现在拥有一个Kubernetes的完全自动的持续交付流水线啦。
这里有几个建议可以让你在Kubernetes上随意fork并玩转semaphore-demo-ruby-kubernetes:
-
创建一个staging集群
-
构建一个部署容器并且在里面运行测试
-
使用更多微服务扩展项目
转载于:https://my.oschina.net/u/3330830/blog/3101722


发表评论

相关推荐
在本指南中,您将逐步了解DevOps的核心理念,包括持续集成(Continuous Integration, CI)、持续交付(Continuous Delivery, CD)和持续部署(Continuous Deployment)。这些概念是DevOps实践中不可或缺的部分,它们...
通过这个名为"spring-cloud-stream-step-by-step-master"的项目,你将全面了解如何使用Kotlin构建Spring Cloud Stream应用,从创建源、处理器到配置Binder,以及如何进行测试和部署。这个逐步指南将帮助你掌握消息...
This example demonstrates step by step to create, run, deploy and consume a gRPC service in .NetCore 3.0. Whole process is has been categorized in 3 main section **Create, Test and Deploy**. 每个步骤...
10. **云原生技术**:掌握容器化技术(Docker)、编排工具(Kubernetes)、Serverless架构,以及如何利用这些技术进行弹性伸缩和自动化部署。 通过这门课程,你将能够掌握系统设计的全局视角,从需求分析到架构设计...
3 Android SqliteManager 源码.zip
内容概要:本文详细介绍了基于S7-200 PLC的煤矿排水系统智能控制方案,重点讨论了三台水泵(两台工作水泵和一台备用水泵)的联动与备援策略。系统通过超声波液位传感器实时监测水位,根据不同水位情况自动控制水泵的启停。具体而言,水位低时不启动水泵,水位介于中水位和高水位之间时启动1号水泵,水位超过高水位则启动1号和2号水泵共同工作。若1号或2号水泵出现故障,系统会自动启用3号备用水泵。此外,MCGS6.2组态画面用于实时监控水位和水泵状态,帮助操作员及时应对异常情况,确保矿井安全。 适合人群:从事煤矿自动化控制领域的技术人员、矿业工程管理人员及相关研究人员。 使用场景及目标:适用于需要提高煤矿排水系统自动化水平的场合,旨在提升矿井排水效率和安全性,减少人工干预,确保矿井生产安全。 其他说明:文中提到的技术方案不仅提高了排水系统的可靠性,还为未来的智能化矿山建设提供了有益借鉴。
scratch少儿编程逻辑思维游戏源码-灌篮之王.zip
scratch少儿编程逻辑思维游戏源码-飞翔马里奥(2).zip
scratch少儿编程逻辑思维游戏源码-火柴人大战 中世纪战争.zip
scratch少儿编程逻辑思维游戏源码-几何冲刺(2).zip
南京证券-低轨卫星互联网启动,天地一体通信迈向6G
nginx-1.20.1
sshpass-1.06-8.ky10.aarch
少儿编程scratch项目源代码文件案例素材-我的世界2D(更新北极).zip
通信行业专题研究:车载全息数字人——AI+Agent新场景,全息投影新方向-20231121-国盛证券-13页
内容概要:本文详细介绍了利用西门子S7-200 PLC和组态王软件构建的邮件分拣系统的具体设计方案和技术细节。首先,文中阐述了硬件部分的设计,包括光电传感器、传送带电机以及分拣机械臂的连接方式,特别是旋转编码器用于精确测量包裹位移的技术要点。接着,展示了PLC编程中的关键代码段,如初始化分拣计数器、读取编码器数据并进行位置跟踪等。然后,描述了组态王作为上位机软件的作用,它不仅提供了直观的人机交互界面,还允许通过简单的下拉菜单选择不同的分拣规则(按省份、按重量或加急件)。此外,针对可能出现的通信问题提出了有效的解决方案,比如采用心跳包机制确保稳定的数据传输,并解决了因电磁干扰导致的问题。最后,分享了一些现场调试的经验教训,例如为减少编码器安装误差对分拣精度的影响而引入的位移补偿算法。 适合人群:从事自动化控制领域的工程师或者对此感兴趣的初学者。 使用场景及目标:适用于需要提高邮件或其他物品自动分拣效率的企业或机构,旨在降低人工成本、提升工作效率和准确性。 其他说明:文中提到的实际案例表明,经过优化后的系统能够显著改善分拣性能,将分拣错误率大幅降至0.3%,并且日均处理量可达2万件包裹。
scratch少儿编程逻辑思维游戏源码-机械汽车.zip
内容概要:本文详细探讨了在连续介质中利用束缚态驱动设计并实现具有最大和可调谐手征光学响应的平面手征超表面的方法。文中首先介绍了comsol三次谐波和本征手性BIC(束缚态诱导的透明)两种重要光学现象,随后阐述了具体的手征超表面结构设计,包括远场偏振图、手性透射曲线、二维能带图、Q因子图和电场图的分析。最后,通过大子刊nc复现实验验证了设计方案的有效性,并对未来的研究方向进行了展望。 适合人群:从事光学研究的专业人士、高校物理系师生、对光与物质相互作用感兴趣的科研工作者。 使用场景及目标:适用于希望深入了解手征超表面设计原理及其光学响应机制的研究人员,旨在推动新型光学器件的研发和技术进步。 其他说明:本文不仅展示了理论分析和模拟计算,还通过实验证明了设计方法的可行性,为后续研究奠定了坚实的基础。
少儿编程scratch项目源代码文件案例素材-位图冒险.zip
少儿编程scratch项目源代码文件案例素材-校园困境2.zip