还在为传统 DBMS 的性能问题而烦恼?想借助 ODPS 的分布计算能力?但是你又不想学习官方的 SDK ?如果你恰好在老项目中用了 JDBC 访问 Oracle 或 MySQL?那么你可能对这篇文章感兴趣。
本文将结合几种常见的使用场景(数据查询、数据导入、第三方客户端工具)来介绍 odps-jdbc ,并附有代码示例级别的入门教程(比较长,所以放在了最后,并不建议看 :D)。
什么是 odps-jdbc?odps-jdbc 是 ODPS 官方提供的 JDBC 驱动,它向 Java 程序提供了一套执行 SQL 任务的接口。还记得吗? 当年 Java 红遍大江南北靠的就是一句“编写一次,处处运行”,JDBC 也是这种思潮下产物。
目前 hive-jdbc 支持的功能 odps-jdbc 都能够支持,hive-jdbc 不支持的一些功能,例如滚动游标的 ResultSet,也支持了。 我们的目标是使 ODPS 更加开放、灵活和易用。项目托管在 github。欢迎各位开源热心人士积极反馈,贡献代码。
场景1:数据查询
用 JDBC API 执行查询语句(Select)是最常见的场景。对于 ODPS 的 SQL 任务,我们只要通过几个简单的 API,就可以拿到带有类型信息的数据。
具体来说,就是调用 Statement 对象的 execute() 方法,Statement 对象可以通过 conn 对象的来创建(conn 是 JDBC 连接对象,后面的入门教程会具体描述它是如何创建的)。Statement 对象可以重复地使用来执行不同的 SQL。
Statement stmt = conn.createStatement();
ResultSet rs = stmt.execute("SELECT foo FROM bar");
Select 语句执行完成会返回一个 ResultSet 对象,它的用法类似一个迭代器,你可以在一个 while 循环中访问结果中每一行的数据。是不是很简单?
while (rs.next()) {
...
}
假设查询到的结果只有两列数据,第一列为整型,第二列为字符串,把所有行打印出来的代码应该长这样:
while (rs.next()) {
System.out.printf("col1:%d, col2:%s", rs.getInt(1), rs.getString(2));
}
更多 API 的使用可以查看 JDBC 的文档。
场景2:批量数据导入
JDBC 接口定义了批处理(batch)操作,结合 PreparedStatement 使用,odps-jdbc 就可以实现数据批量导入 ODPS 的功能。
具体地,只要把带有类型信息的数据先添加到 batch 中,当累计到一定数量(batchSize),就调用一次批量执行方法,这样就能批量地将你的数据上传到 odps。省去了额外序列化反序列化的麻烦,尤其适合从传统数据库导到 ODPS 的场景。
还是直接看代码吧:
String sql = "insert into employee (name, city, phone) values (?, ?, ?)";
PreparedStatement ps = conn.prepareStatement(sql);
final int batchSize = 1000;
int count = 0;
for (Employee employee: employees) {
ps.setString(1, employee.getName());
ps.setString(2, employee.getCity());
ps.setString(3, employee.getPhone());
ps.addBatch();
if(++count % batchSize == 0) {
ps.executeBatch();
}
}
ps.executeBatch(); // insert remaining records
其中 PreparedStatement 通过一个 sql 语句的模板来创建,它可以让我们在一条 sql 语句中注入带有类型信息的数据。
我们将 batch 的大小设为 1000,用一个 count 来触发批量执行的操作(executeBatch())。
场景3:第三方客户端工具
你甚至不一定需要通过代码的方式来接入 JDBC。兼容 JDBC,也就意味着 ODPS 可以兼容所有 JDBC 兼容的第三方工具,例如:
- Pentahao 报表工具
- Squirrel SQL 客户端工具
- SQL Workbench/J 客户端工具
- TalentD ETL 工具
- ...
也就是说如果你是以上这些软件的用户,都可以毫无成本地迁移到 ODPS 平台上工作。下面就简单介绍一下 SQL Workbench/J 的使用。笔者曾经试用过很多利用 JDBC 连接数据库的客户端软件,大多都因为操作实在不方便,不得不放弃,直到遇见了 SQL Workbench/J,好像突然遇到了老朋友,非常推荐!
SQL Workbench/J 下载地址
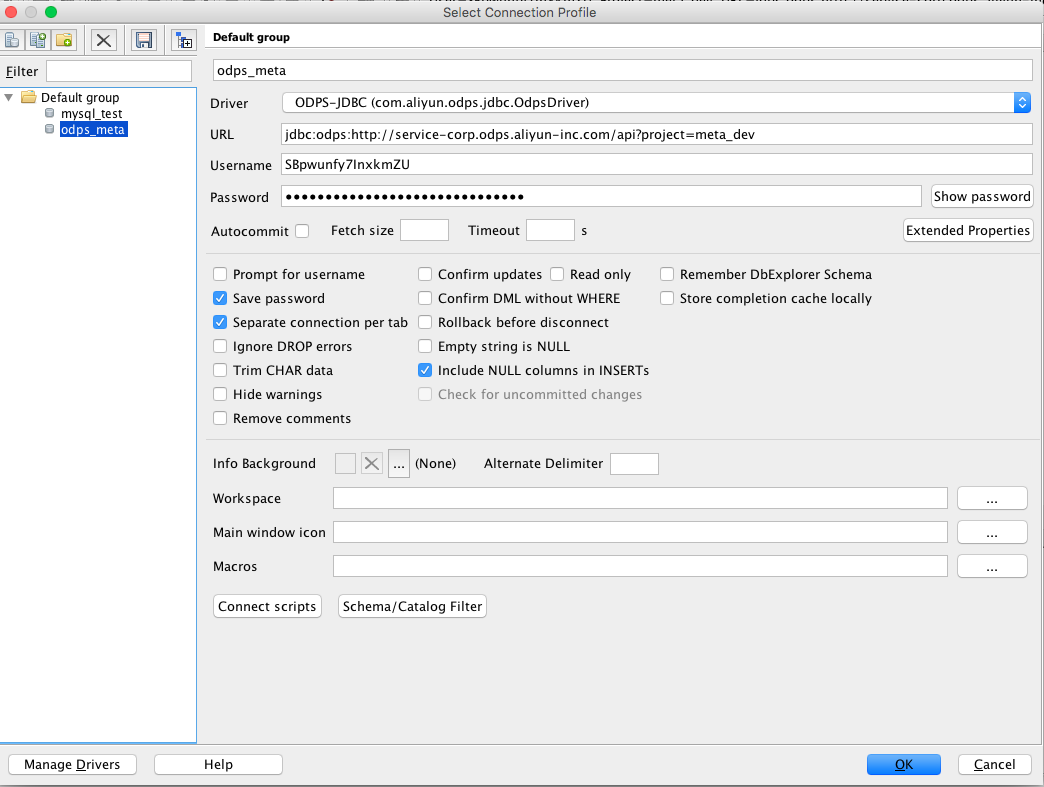
首先你需要加载我们的 jdbc 驱动,点开 Manager Driver 加载我们的独立 jar 包(下载地址会在后面的入门教程中介绍),然后正确输入 Classname。
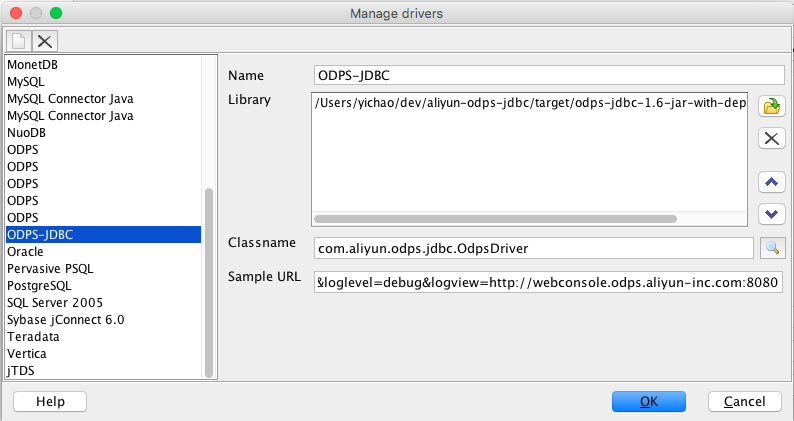
其次新建一个 Connection Profile,在 Driver 下拉框中选择我们刚才添加的驱动,然后填入 url(详细定义见入门教程),username 和 password 分别为你的阿里云账号和钥匙。
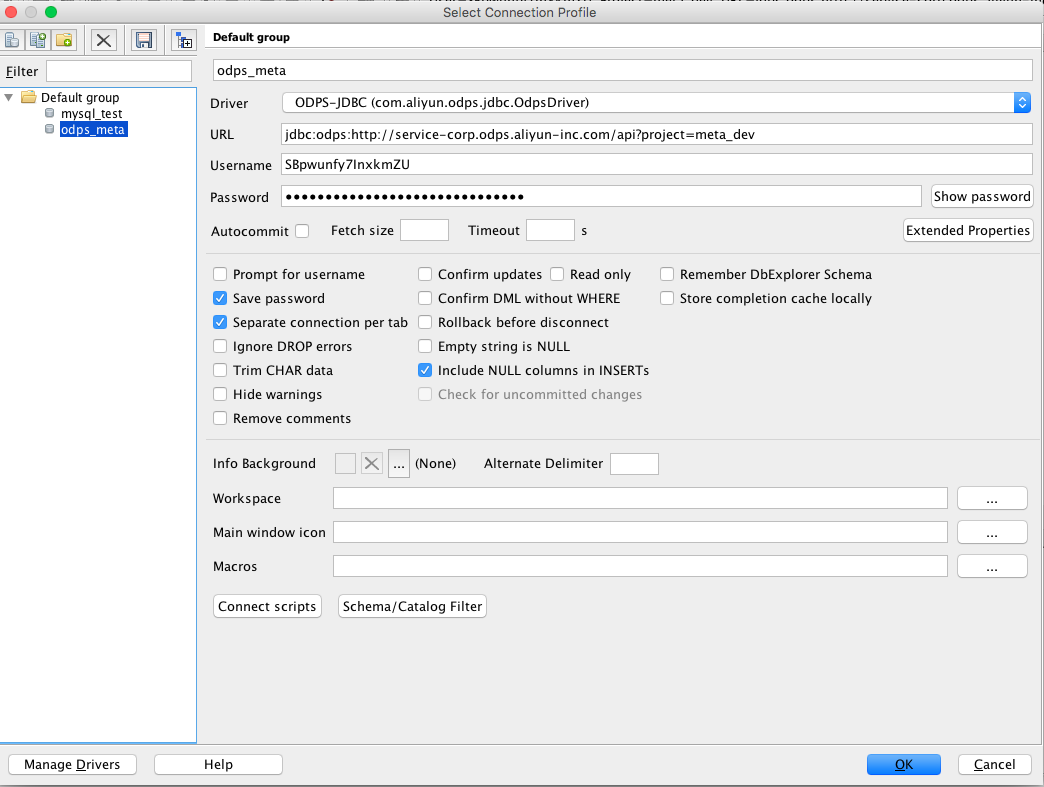
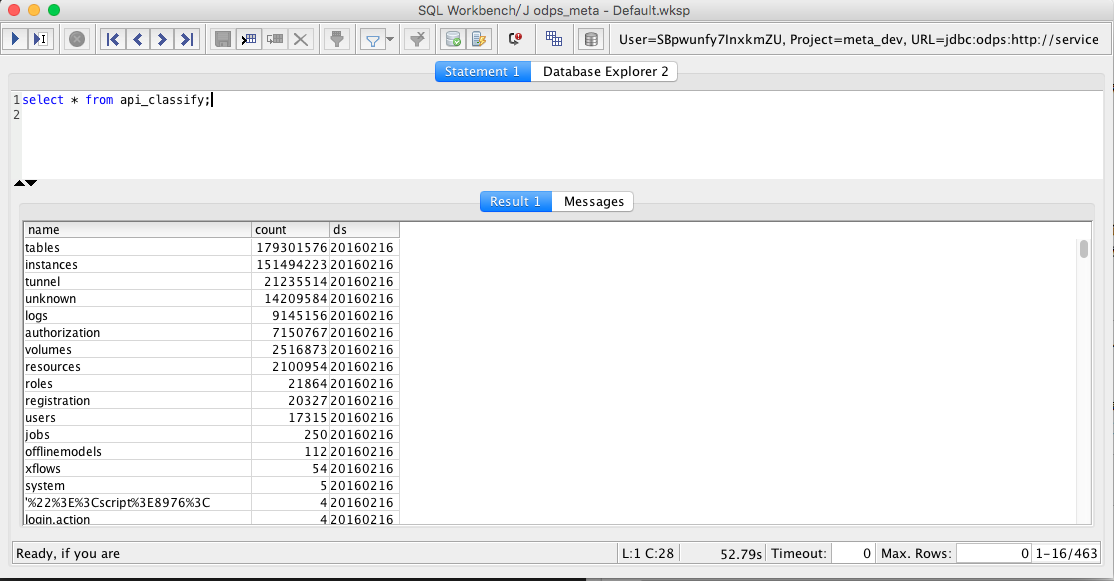
点击确认,这个时候你会发现数据库已经连接好了。于是你就可以在输入框中敲入查询语句、DDL 语句,并在下面的结果栏中查看结果。
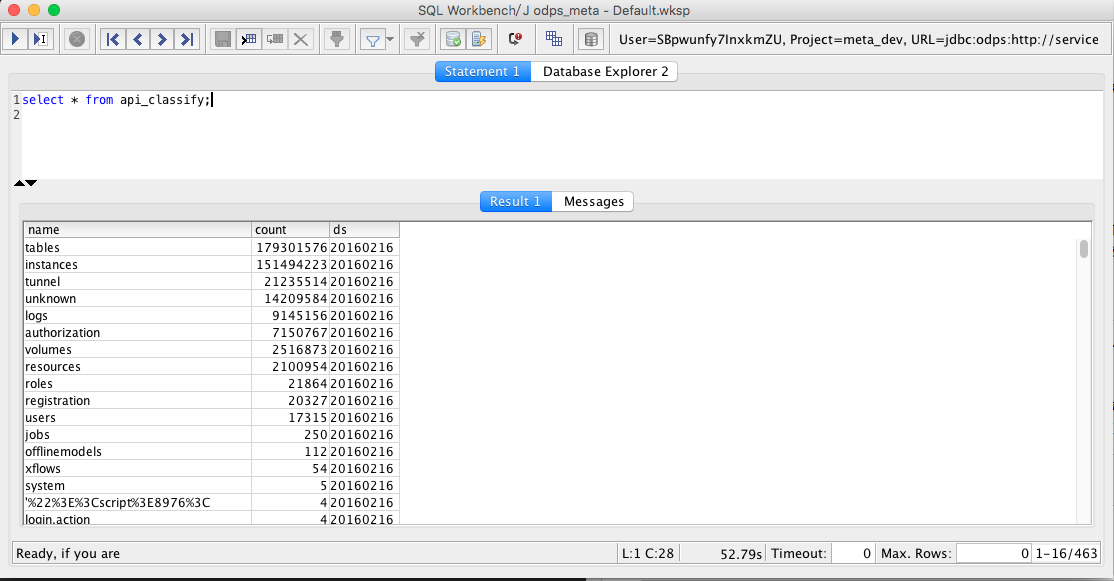
现在你已经大概了解了 odps-jdbc 能用来处理哪些场景,如果你真的需要开始使用它,可以继续阅读以下内容。
入门教程(TL;DR)
使用前的准备工作
1.你可以通过以下两种方式来安装 JDBC 驱动
<dependency>
<groupId>com.aliyun.odps</groupId>
<artifactId>odps-jdbc</artifactId>
<version>x.y</version>
</dependency>
2.手动在代码中将 JDBC 驱动加载到 JVM
Class.forName("com.aliyun.odps.jdbc.OdpsDriver");
3.通过下面这条语句可以定义一个 JDBC 连接
Connection conn = DriverManager.getConnection(url, accessId, accessKey);
其中 url 是 JDBC 的资源定位符,用过 JDBC 的人一定知道,JDBC 就是利用它来找到数据库的入口,并且进行一些初始化的配置。一个完整的 url 就长下面这个样子,它将使用名为 jdbc_test 的 ODPS 项目,并使用 UTF-8 编码:
"jdbc:odps:https://service.odps.aliyun.com/api?project=jdbc_test&charset=UTF-8"
accessId 和 accessKey 分别对应了阿里云账号和钥匙。
首先你要有一个阿里云的账号 :)
4.如果配置参数太多,也可以先添加到 Properties 中,然后通过它来创建
Properties config = new Properties();
config.put("access_id", "...");
config.put("access_key", "...");
config.put("project_name", "...");
config.put("charset", "...");
Connection conn = DriverManager.getConnection("jdbc:odps:<endpoint>", config);
一个完整的例子
下面的代码展示 JDBC 中的常见操作,包含了删表、建表、获取表 meta、执行 insert、执行 select 以及遍历结果集:
import java.sql.Connection;
import java.sql.DatabaseMetaData;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.Properties;
public class Main {
private static String driverName = "com.aliyun.odps.jdbc.OdpsDriver";
public static void main(String[] args) throws SQLException {
try {
Class.forName(driverName);
} catch (ClassNotFoundException e) {
e.printStackTrace();
System.exit(1);
}
Properties config = new Properties();
config.put("access_id", "your_access_id");
config.put("access_key", "your_access_key");
config.put("project_name", "your_project");
config.put("charset", "utf-8");
Connection
conn = DriverManager.getConnection("jdbc:odps:https://service.odps.aliyun.com/api", config);
ResultSet rs;
// create a table
Statement stmt = conn.createStatement();
String tableName = "jdbc_test";
stmt.execute("drop table if exists " + tableName);
stmt.execute("create table " + tableName + " (key int, value string)");
// get meta data
DatabaseMetaData metaData = conn.getMetaData();
System.out.println("product = " + metaData.getDatabaseProductName());
System.out.println("jdbc version = " + metaData.getDriverMajorVersion() + ", "
+ metaData.getDriverMinorVersion());
rs = metaData.getTables(null, null, tableName, null);
while (rs.next()) {
String name = rs.getString(3);
System.out.println("inspecting table: " + name);
ResultSet rs2 = metaData.getColumns(null, null, name, null);
while (rs2.next()) {
System.out.println(rs2.getString("COLUMN_NAME") + "\t"
+ rs2.getString("TYPE_NAME") + "(" + rs2.getInt("DATA_TYPE") + ")");
}
}
// run sql
String sql;
// insert a record
sql = String.format("insert into table %s select 24 key, 'hours' value from (select count(1) from %s) a", tableName, tableName);
System.out.println("Running: " + sql);
int count = stmt.executeUpdate(sql);
System.out.println("updated records: " + count);
// select * query
sql = "select * from " + tableName;
System.out.println("Running: " + sql);
rs = stmt.executeQuery(sql);
while (rs.next()) {
System.out.println(String.valueOf(rs.getInt(1)) + "\t" + rs.getString(2));
}
}
运行可以获得类似如下结果:
product = ODPS JDBC
jdbc version = 1, 0
inspecting table: jdbc_test
key BIGINT(-5)
value STRING(12)
Running: insert into table jdbc_test select 24 key, 'hours' value from (select count(1) from jdbc_test) a
updated records: 1
Running: select * from jdbc_test
24 hours
FAQ
1.如何获取 ODPS SQL 的 logview?
JDBC 驱动默认会以日志的形式将 LOGVIEW 打印在程序的 stderr 中。
2.如何调试 JDBC 驱动?
在连接串中将 loglevel 设置为 DEBUG,例如:
"jdbc:odps:<endpoint>?project=jdbc_test&loglevel=DEBUG"




相关推荐
odps-jdbc-3.2.9-jar-with-dependencies.jar 是阿里云 MaxCompute(开放数据处理服务,ODPS)平台的 JDBC 驱动程序,专为大数据处理和分析而设计。此版本的驱动程序包含所有必要的依赖库,简化了开发人员在 Java ...
aliyun-odps-jdbc-3.2.29jar包 是阿里云为其大数据平台 MaxCompute(也称为 ODPS:开放数据处理服务)提供的 JDBC 驱动程序。通过该驱动,开发者可以在 Java 应用程序中使用标准的 JDBC API 与 MaxCompute 平台进行...
>odps-jdbc</ artifactId > < version >VERSION</ version > </ dependency > 入门 使用 ODPS JDBC 驱动程序就像使用其他 JDBC 驱动程序一样。 它包含以下几个步骤: 1. 使用Class.forName()显式加载 ...
java采用jdbc连接neo4j所需要jar
而"odps-eclipse-plugin-bundle-0.16.0.zip"则是一个针对ODPS开发的Eclipse集成开发环境(IDE)插件,版本为0.16.0,方便开发者在Eclipse环境中进行ODPS相关的项目开发和管理。 该插件的安装和使用是其核心知识点之...
kettle使用maxcompute相关插件,aliyun-kettle-odps-plugin-1.0.0.tar.gz
aliyun-kettle-odps-plugin-1.0.0包以及安装操作文件,适合在使用maxcompute时用kettle将数据导出,方便实用
odps-sdk-impl/odps-common-local/src/test/resources/test.conf odps-sdk-impl/odps-mapred-local/src/test/resources/test.conf odps-sdk-impl/odps-graph-local/src/test/resources/test.conf odps-sdk/odps-sdk...
odps-flume-plugin-2.0.4.jar
#aliyun-odps-php-sdk ##CI ##Preconditoins Since some data types(such as Bigint, Datetime) in ODPS depends on 64bit integer (long in java), and php32 build doesn't include this type, so we have to use ...
ODPS Python SDK和数据分析框架 ----------------- 轻松访问ODPS API的方式。 安装 快速方法: pip install pyodps[full] 与整合: pip install pyodps#egg=pyodps[mars] 如果您不需要使用Jupyter,只需键入 pip ...
在Java代码中,首先需要创建一个ODPS实例,这需要提供ODPS的接入点(Endpoint)、项目名(Project Name)以及访问凭证(Access ID和Access Key)。这些信息可以在阿里云控制台上获取。 ```java Odps odps = new ...
文件->新建->项目..-> ODPS-> ODPS项目 Mapper / Reducer / MapReducer驱动程序/ UDF / UDTF模板 文件->新建->其他..-> ODPS-> ..template 运行ODPS项目 本地调试Mapreduce程序 右键单击类WordCount(或类Resource)...
odps-jbbc for kettle
#### 一、ODPS-SQL基础用法 ##### 1. 使用CASE语句 ODPS中的CASE语句用于根据不同的条件返回不同的结果。例如,在创建新表`train_1`时,可以根据`tab`字段的不同值来决定`weight`字段的值: ```sql DROP TABLE IF...
2. **ODPS SQL**:ODPS SQL是ODPS提供的一种强大工具,允许用户使用SQL语法对存储在ODPS中的大数据进行查询和分析。SQL支持包括但不限于:SELECT、INSERT、UPDATE、DELETE等基本操作,以及JOIN、GROUP BY、HAVING、...
第1章“ODPS概述”首先从引言开始,探讨了大数据分析的重要性以及面临的挑战。1.2节介绍了ODPS产生的背景和原因,指出在面对海量数据时,传统数据库系统的局限性促使了ODPS的诞生。1.2.1至1.2.4小节分别解释了为何...
这些库文件使得开发者可以在本地开发环境中编写和运行ODPS相关的Java程序,或者使用ODPS命令行工具(odpscmd)进行数据操作。包含了ODPS的数据处理API,如SQL执行引擎、数据导入导出工具等。 3. **plugins**: 这...
从/向 ODPS 读/写数据帧。 将一些 R 模型转换为 SQL 命令。 大数据集可以使用分布式算法进行处理。 小数据集可以直接在R中处理。 要求 Java:推荐 Java 8(Java 9 或更高版本可能会遇到 JAXB 问题) R:最新版本...
用户可以通过学习提供的内容,了解如何配置和使用这两个服务,实现大数据环境下的实时数据接入与离线处理的无缝对接。同时,这也暗示了在大数据处理中,选择合适的工具和平台,以及实现良好的集成,对于提升工作效率...