
转自:http://www.blogjava.net/hello-yun/archive/2012/10/10/389289.html
 
MurmurHashτ«Ýµ│þ∩╝ÜΘ½ýΦ┐Éτ«ÝµÇÚΦâ╜∩╝ðΣ╜Äτó░µÆ₧τÄç∩╝ðτö▒Austin Applebyσêøσ╗║Σ║Ä2008σ╣┤∩╝ðτÄ░σ╖▓σ║öτö¿σê░HadoopπÇülibstdc++πÇünginxπÇülibmemcachedτ¡ëσ╝ǵ║Éτ│╗τ╗ƒπÇé2011σ╣┤ApplebyΦó½GoogleΘøçΣ╜ú∩╝ðΘÜÅσÉÄGoogleµÄ¿σç║σà╢σÅýτÚÞτÜäCityHashτ«Ýµ│þπÇé
 
Σ╕ÇΦç┤µÇÚσôêσ╕ðτ«Ýµ│þµý»σêåσ╕âσ╝Åτ│╗τ╗ƒΣ╕¡σ╕╕τö¿τÜäτ«Ýµ│þπÇéµ»öσÓé∩╝ðΣ╕ÇΣ╕¬σêåσ╕âσ╝ÅτÜäσ¡ýσé¿τ│╗τ╗ƒ∩╝ðΦÓüσ░åµþ░µÞ«σ¡ýσé¿σê░σà╖Σ╜ôτÜäΦèéτé╣Σ╕è∩╝ðσÓéµ₧£Θççτö¿µÖ«ΘÇÜτÜähashµû╣µ│þ∩╝ðσ░åµþ░µÞ«µýáσ░äσê░σà╖Σ╜ôτÜäΦèéτé╣Σ╕è∩╝ðσÓékey%N∩╝ðkeyµý»µþ░µÞ«τÜäkey∩╝ðNµý»µ£║σÖ¿Φèéτé╣µþ░∩╝ðσÓéµ₧£µ£ëΣ╕ÇΣ╕¬µ£║σÖ¿σèáσà͵êûΘÇÇσç║Φ┐ÖΣ╕¬Θøåτ╛Á∩╝ðσêÖµëǵ£ëτÜäµþ░µÞ«µýáσ░äΘâ╜µÝáµþêΣ║å∩╝ðσÓéµ₧£µý»µðüΣ╣àσðûσ¡ýσé¿σêÖΦÓüσüܵþ░µÞ«Φ┐üτÚ╗∩╝ðσÓéµ₧£µý»σêåσ╕âσ╝Åτ╝ôσ¡ý∩╝ðσêÖσà╢Σ╗ûτ╝ôσ¡ýσ░▒σÁ▒µþêΣ║åπÇé
┬á ┬á σøᵡÁ∩╝ðσ╝þσàÍΣ║åΣ╕ÇΦç┤µÇÚσôêσ╕ðτ«Ýµ│þ∩╝Ü
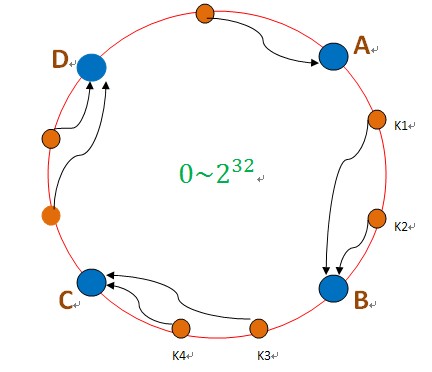
 
µèèµþ░µÞ«τö¿hashσç╜µþ░∩╝êσÓéMD5∩╝ë∩╝ðµýáσ░äσê░Σ╕ÇΣ╕¬σ╛êσÁÚτÜäτ⌐║ΘÝ┤Θçð∩╝ðσÓéσø╛µëÇτÁ║πÇéµþ░µÞ«τÜäσ¡ýσ鿵Ý╢∩╝ðσàêσ╛Ýσê░Σ╕ÇΣ╕¬hashσÇ╝∩╝ðσ»╣σ║öσê░Φ┐ÖΣ╕¬τÄ»Σ╕¡τÜäµ»ÅΣ╕¬Σ╜Þτ╜«∩╝ðσÓék1σ»╣σ║öσê░Σ║åσø╛Σ╕¡µëÇτÁ║τÜäΣ╜Þτ╜«∩╝ðτä╢σÉĵ▓┐Θí║µÝ╢ΘÆêµë╛σê░Σ╕ÇΣ╕¬µ£║σÖ¿Φèéτé╣B∩╝ðσ░åk1σ¡ýσé¿σê░BΦ┐ÖΣ╕¬Φèéτé╣Σ╕¡πÇé
σÓéµ₧£BΦèéτé╣σ«þµ£║Σ║å∩╝ðσêÖBΣ╕èτÜäµþ░µÞ«σ░▒Σ╝ÜΦÉ╜σê░CΦèéτé╣Σ╕è∩╝ðσÓéΣ╕Ðσø╛µëÇτÁ║∩╝Ü
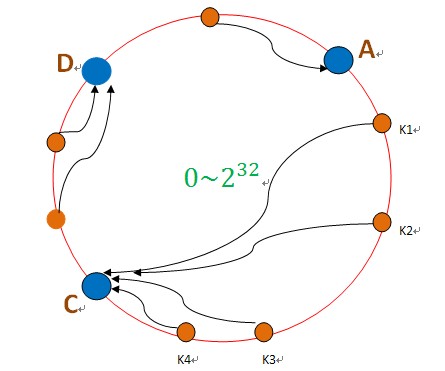
 
Φ┐Öµá╖∩╝ðσŬΣ╝Üσ╜▒σôÞCΦèéτé╣∩╝ðσ»╣σà╢Σ╗ûτÜäΦèéτé╣A∩╝ðDτÜäµþ░µÞ«Σ╕ÞΣ╝ÜΘÇáµêÉσ╜▒σôÞπÇéτä╢ΦÇð∩╝ðΦ┐ÖσÅêΣ╝ÜΘÇáµêÉΣ╕ÇΣ╕¬ΓÇ£Θø¬σ┤⌐ΓÇØτÜäµâàσå╡∩╝ðσÞ│CΦèéτé╣τö▒Σ║ĵë┐µÐàΣ║åBΦèéτé╣τÜäµþ░µÞ«∩╝ðµëÇΣ╗ÍCΦèéτé╣τÜäΦ┤ƒΦ╜╜Σ╝ÜσÅýΘ½ý∩╝ðCΦèéτé╣σ╛êσ«╣µýôΣ╣ƒσ«þµ£║∩╝ðΦ┐Öµá╖Σ╛ص¼íΣ╕ÐσÄ╗∩╝ðΦ┐Öµá╖ΘÇáµêɵþ┤Σ╕¬Θøåτ╛ÁΘâ╜µðéΣ║åπÇé
┬á┬á┬á┬á┬á┬á Σ╕║µ¡Á∩╝ðσ╝þσàÍΣ║åΓÇ£ΦÖܵЃΦèéτé╣ΓÇØτÜäµÓéσ┐╡∩╝ÜσÞ│µèèµâ│Φ▒íσ£¿Φ┐ÖΣ╕¬τÄ»Σ╕èµ£ëσ╛êσÁÜΓÇ£ΦÖܵЃΦèéτé╣ΓÇØ∩╝ðµþ░µÞ«τÜäσ¡ýσ鿵ý»µ▓┐τØÇτÄ»τÜäΘí║µÝ╢ΘÆêµû╣σÉæµë╛Σ╕ÇΣ╕¬ΦÖܵЃΦèéτé╣∩╝ðµ»ÅΣ╕¬ΦÖܵЃΦèéτé╣Θâ╜Σ╝Üσà│Φüöσê░Σ╕ÇΣ╕¬τ£ƒσ«₧Φèéτé╣∩╝ðσÓéΣ╕Ðσø╛µëÇΣ╜┐τö¿∩╝Ü
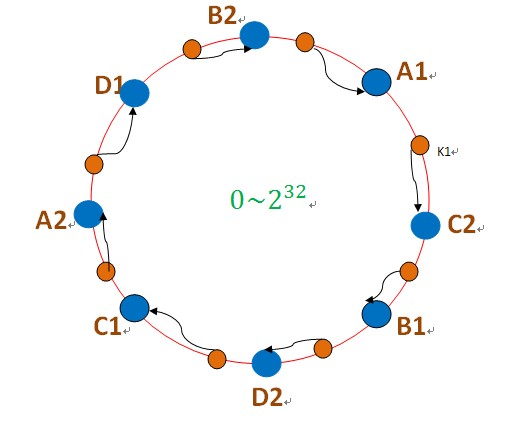
σø╛Σ╕¡τÜäA1πÇüA2πÇüB1πÇüB2πÇüC1πÇüC2πÇüD1πÇüD2Θâ╜µý»ΦÖܵЃΦèéτé╣∩╝ðµ£║σÖ¿AΦ┤ƒΦ╜╜σ¡ýσé¿A1πÇüA2τÜäµþ░µÞ«∩╝ðµ£║σÖ¿BΦ┤ƒΦ╜╜σ¡ýσé¿B1πÇüB2τÜäµþ░µÞ«∩╝ðµ£║σÖ¿CΦ┤ƒΦ╜╜σ¡ýσé¿C1πÇüC2τÜäµþ░µÞ«πÇéτö▒Σ║ÄΦ┐ÖΣ║øΦÖܵЃΦèéτé╣µþ░ΘçÅσ╛êσÁÜ∩╝ðσØçσðÇσêåσ╕â∩╝ðσøᵡÁΣ╕ÞΣ╝ÜΘÇáµêÉΓÇ£Θø¬σ┤⌐ΓÇØτÄ░Φ▒íπÇé
 
- public┬áclass┬áShard<S>┬á{┬á//┬áSτ▒╗σ░üΦúàΣ║åµ£║σÖ¿Φèéτé╣τÜäΣ┐íµü»┬á∩╝ðσÓénameπÇüpasswordπÇüipπÇüportτ¡ë┬á┬á┬á
-   
- ┬á┬á┬á┬áprivate┬áTreeMap<Long,┬áS>┬ánodes;┬á//┬áΦÖܵЃΦèéτé╣┬á┬á┬á
-     private List<S> shards; // 真实机器节点   
- ┬á┬á┬á┬áprivate┬áfinal┬áint┬áNODE_NUM┬á=┬á100;┬á//┬áµ»ÅΣ╕¬µ£║σÖ¿Φèéτé╣σà│ΦüöτÜäΦÖܵЃΦèéτé╣Σ╕¬µþ░┬á┬á┬á
-   
-     public Shard(List<S> shards) {  
-         super();  
-         this.shards = shards;  
-         init();  
-     }  
-   
- ┬á┬á┬á┬áprivate┬ávoid┬áinit()┬á{┬á//┬áσêØσÚÐσðûΣ╕ÇΦç┤µÇÚhashτÄ»┬á┬á┬á
-         nodes = new TreeMap<Long, S>();  
- ┬á┬á┬á┬á┬á┬á┬á┬áfor┬á(int┬ái┬á=┬á0;┬ái┬á!=┬áshards.size();┬á++i)┬á{┬á//┬áµ»ÅΣ╕¬τ£ƒσ«₧µ£║σÖ¿Φèéτé╣Θâ╜Θ£ÇΦÓüσà│ΦüöΦÖܵЃΦèéτé╣┬á┬á┬á
-             final S shardInfo = shards.get(i);  
-   
-             for (int n = 0; n < NODE_NUM; n++)  
- ┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á//┬áΣ╕ÇΣ╕¬τ£ƒσ«₧µ£║σÖ¿Φèéτé╣σà│ΦüöNODE_NUMΣ╕¬ΦÖܵЃΦèéτé╣┬á┬á┬á
-                 nodes.put(hash("SHARD-" + i + "-NODE-" + n), shardInfo);  
-   
-         }  
-     }  
-   
-     public S getShardInfo(String key) {  
- ┬á┬á┬á┬á┬á┬á┬á┬áSortedMap<Long,┬áS>┬átail┬á=┬ánodes.tailMap(hash(key));┬á//┬áµ▓┐τÄ»τÜäΘí║µÝ╢ΘÆêµë╛σê░Σ╕ÇΣ╕¬ΦÖܵЃΦèéτé╣┬á┬á┬á
-         if (tail.size() == 0) {  
-             return nodes.get(nodes.firstKey());  
-         }  
- ┬á┬á┬á┬á┬á┬á┬á┬áreturn┬átail.get(tail.firstKey());┬á//┬áΦ┐öσø₧Φ»ÍΦÖܵЃΦèéτé╣σ»╣σ║öτÜäτ£ƒσ«₧µ£║σÖ¿Φèéτé╣τÜäΣ┐íµü»┬á┬á┬á
-     }  
-   
-     /** 
- ┬á┬á┬á┬á┬á*┬á┬áMurMurHashτ«Ýµ│þ∩╝ðµý»ΘØ₧σèáσ»åHASHτ«Ýµ│þ∩╝ðµÇÚΦâ╜σ╛êΘ½ý∩╝ð┬á
- ┬á┬á┬á┬á┬á*┬á┬áµ»öΣ╝áτ╗ƒτÜäCRC32,MD5∩╝ðSHA-1∩╝êΦ┐ÖΣ╕ÁΣ╕¬τ«Ýµ│þΘâ╜µý»σèáσ»åHASHτ«Ýµ│þ∩╝ðσÁÞµØéσ║Óµ£¼Φ║½σ░▒σ╛êΘ½ý∩╝ðσ╕ÓµØÍτÜäµÇÚΦâ╜Σ╕èτÜäµÞƒσ«│Σ╣ƒΣ╕ÞσÅ»Θü┐σàÞ∩╝ë┬á
- ┬á┬á┬á┬á┬á*┬á┬áτ¡ëHASHτ«Ýµ│þΦÓüσ┐½σ╛êσÁÜ∩╝ðΦÇðΣ╕öµÞ«Φ»┤Φ┐ÖΣ╕¬τ«Ýµ│þτÜäτó░µÆ₧τÄçσ╛êΣ╜Ä.┬á
-      *  http://murmurhash.googlepages.com/ 
-      */  
-     private Long hash(String key) {  
-           
-         ByteBuffer buf = ByteBuffer.wrap(key.getBytes());  
-         int seed = 0x1234ABCD;  
-           
-         ByteOrder byteOrder = buf.order();  
-         buf.order(ByteOrder.LITTLE_ENDIAN);  
-   
-         long m = 0xc6a4a7935bd1e995L;  
-         int r = 47;  
-   
-         long h = seed ^ (buf.remaining() * m);  
-   
-         long k;  
-         while (buf.remaining() >= 8) {  
-             k = buf.getLong();  
-   
-             k *= m;  
-             k ^= k >>> r;  
-             k *= m;  
-   
-             h ^= k;  
-             h *= m;  
-         }  
-   
-         if (buf.remaining() > 0) {  
-             ByteBuffer finish = ByteBuffer.allocate(8).order(  
-                     ByteOrder.LITTLE_ENDIAN);  
-             // for big-endian version, do this first:   
-             // finish.position(8-buf.remaining());   
-             finish.put(buf).rewind();  
-             h ^= finish.getLong();  
-             h *= m;  
-         }  
-   
-         h ^= h >>> r;  
-         h *= m;  
-         h ^= h >>> r;  
-   
-         buf.order(byteOrder);  
-         return h;  
-     }  
-   
- }  



τø╕σà│µÄ¿ΦÞÉ
MurmurHashτ«Ýµ│þτö▒Austin Applebyσêøσ╗║Σ║Ä2008σ╣┤∩╝ðτÄ░σ╖▓σ║öτö¿σê░HadoopπÇülibstdc πÇünginxπÇülibmemcached,Redis∩╝ðMemcached∩╝ðCassandra∩╝ðHBase∩╝ðLuceneτ¡ëσ╝ǵ║Éτ│╗τ╗ƒπÇé2011σ╣┤ApplebyΦó½GoogleΘøçΣ╜ú∩╝ðΘÜÅσÉÄGoogleµÄ¿σç║σà╢σÅýτÚÞτÜä...
hadoop_spark_µþ░µÞ«τ«Ýµ│þhadoop_spark_µþ░µÞ«τ«Ýµ│þhadoop_spark_µþ░µÞ«τ«Ýµ│þhadoop_spark_µþ░µÞ«τ«Ýµ│þ
HadoopΘøåτ╛ÁΣ╜£Σ╕ÜτÜäΦ░âσ║Óτ«Ýµ│þHadoopΘøåτ╛ÁΣ╜£Σ╕ÜτÜäΦ░âσ║Óτ«Ýµ│þHadoopΘøåτ╛ÁΣ╜£Σ╕ÜτÜäΦ░âσ║Óτ«Ýµ│þ
Θâ¿τ╜▓Hadoop3.0Θ½ýµÇÚΦâ╜Θøåτ╛Á∩╝ðHadoopσ«ðσà¿σêåσ╕âσ╝ŵ¿íσ╝Å: HadoopτÜäσ«êµèÁΦ┐øτ¿Ðσêåσê½Φ┐ÉΦíðσ£¿τö▒σÁÜΣ╕¬Σ╕╗µ£║µÉ¡σ╗║τÜäΘøåτ╛ÁΣ╕è,Σ╕ÞσÉð Φèéτé╣µÐàΣ╗╗Σ╕ÞσÉðτÜäΦÚÆΦë▓,σ£¿σ«₧ΘÖàσ╖ÍΣ╜£σ║öτö¿σ╝ÇσÅæΣ╕¡,ΘÇÜσ╕╕Σ╜┐τö¿Φ»Íµ¿íσ╝ŵ₧äσ╗║Σ╝üΣ╕Üτ║ÚHadoopτ│╗τ╗ƒπÇé σ£¿HadoopτÄ»σóâΣ╕¡,µëǵ£ë...
Σ║æΦ«íτ«Ýµíåµ₧╢Σ╣ÐΣ╕Çhadoopσ╕╕τö¿τÜäτ«Ýµ│þΣ╛Ðσ¡É
hadoopσ«₧τÄ░ΦüÜτ▒╗τ«Ýµ│þ σê⌐τö¿MapReduceµíåµ₧╢σÆðHDFSµØÍσ«₧τÄ░σ┐½ΘǃΦüÜτ▒╗
σêåσ╕âσ╝ÅΘøåτ╛ÁµÖ«ΘüÞσ¡ýσ£¿Φ┤ƒΦ╜╜σØçΦííΘÝ«Θóý∩╝ðΦÇðHadoopµ▓íµ£ëΦÇâΦÖæσê░Φèéτé╣ΘÝ┤µÇÚΦâ╜τÜäσ╖«σ╝é.ΦÖ╜τä╢µ£ëΦ┤ƒΦ╜╜σØçΦííµ£║σê╢∩╝ðΣ╜åµý»µþêµ₧£Σ╕ÞσÁ¬τÉåµâ│∩╝ðσøᵡÁΦ┐ÉΦíðΦ┐çτ¿ÐΣ╕¡τ╗Åσ╕╕Σ╝Üσç║τÄ░Φ┤ƒΦ╜╜Σ╕ÞσØçΦííτÜäµâàσå╡πÇéΘÆêσ»╣σÓéΣ╕èΘÝ«Θóý∩╝ðµ╖▒σàÍσêåµ₧ÉΣ║åHadoopµ║ÉΣ╗úτáü∩╝ðτÉåµ╕àΣ║åHadoopτÜä...
Hadoopσ╕╕τö¿Φ░âσ║Óτ«Ýµ│þΣ╗Ðτ╗Þ∩╝ðσðàµÐ¼FIFOπÇüσà¼σ╣│Φ░âσ║Óτ«Ýµ│þπÇüΦ«íτ«ÝΦâ╜σèøΦ░âσ║Óτ«Ýµ│þπÇüσƒ║Σ║ĵ£┤τ┤áΦ┤ØσÅ╢µû»σàêΘ¬ðτÜäΦ░âσ║Óτ«Ýµ│þπÇüσƒ║Σ║ÄΦç¬ΘÇéσ║öσ¡ÓΣ╣áτÜäΦ░âσ║Óτ«Ýµ│þπÇé
σ£¿Σ╗Ðτ╗ÞHadoop,HDFSτÜäσăτÉåτÜäσƒ║τíÇΣ╕è,σêåµ₧ÉΣ║åHadoopτÜäµþ░µÞ«Φ┤ƒΦ╜╜σØçΦííτ«Ýµ│þ.HadoopΦ┤ƒΦ╜╜σØçΦííτ«Ýµ│þσŬµý»µá╣µÞ«τ⌐║ΘÝ┤Σ╜┐τö¿τÄçσ»╣σÉäΣ╕¬τ╗ôτé╣τÜäΦ┤ƒΦ╜╜Φ┐øΦíðσØçΦíí,Φ┐ÖτÚÞσØçΦííµû╣µ│þµ▓íµ£ëΦÇâΦÖæτ╗ôτé╣τÜäσÁäτÉåΦâ╜σèøπÇüσ╕Óσ«╜πÇüµûçΣ╗╢Φ«┐ΘÝ«Θóæσ║Óτ¡ëσøáτ┤á,σøᵡÁ,ΘÇáµêÉΣ║åσƒ║µ£¼...
<µþ░µÞ«τ«Ýµ│þ--Hadoop-SparkσÁÚµþ░µÞ«σÁäτÉåµèÇσ╖Ú><Data.Algorithms.Recipes.for.Scaling.Up.with.Hadoop.and.Spark>.pdfσà¿Σ╣Ó686Θí╡∩╝ðΦÐ▒µûçµ»öΣ╕¡µûçσ«╣µýôτÉåΦÚúµ£¼Φ╡äµûÖσà▒σðàσɽΣ╗ÍΣ╕ÐΘÖäΣ╗╢∩╝Ü724f58d66ab6b3c4c6412e91117878cb.zipπÇèµþ░µÞ«...
HadoopΘøåτ╛ÁΘ½ýσÅ»τö¿Σ╕ĵÇÚΦâ╜Σ╝ýσðû
HADOOPσêåτ▒╗τ«Ýµ│þΦ┐ýµ£ëHadoopΦüÜτ▒╗τ«Ýµ│þ∩╝ðσÅ»Σ╗Íτ╗Úτ╗¡µÉ£τ┤ó
Hadoop σ£¿σÁÚµþ░µÞ«Φ┐Éτ«ÝΣ╕¡τÜäΘÖÉσê╢ HadoopΣ╕Þµý»Σ╕çΦâ╜τÜä∩╝ðσ«₧µÝ╢Φ┐Éτ«ÝσÅèτ╗ƒΦ«íΣ╕¡∩╝ðHadoopΦ┐ýµý»µ£ëσ╛êσÁÜΘÖÉσê╢τÜäπÇéΦ┐Öτ»çµûçτ½áΦ«║Φ┐░Σ║åΦ┐ÖΣ║øΘÖÉσê╢∩╝ðµðçσç║Σ║å Hadoop Φ┐Éτö¿Σ╕èτÜäΣ╕ÇΣ║øΦ»»σð║πÇéσÇ╝σ╛ÝΣ╕ÇΦ»╗πÇé
πÇèµþ░µÞ«τ«Ýµ│þ∩╝ÜHadoop/SparkσÁÚµþ░µÞ«σÁäτÉåµèÇσ╖ÚπÇÐΣ╗Ðτ╗ÞΣ║åσ╛êσÁÜσƒ║µ£¼Φ«╛Φ«íµ¿íσ╝ÅπÇüΣ╝ýσðûµèǵ£»σÆðµþ░µÞ«µðûµÄýσÅèµ£║σÖ¿σ¡ÓΣ╣áΦÚúσå│µû╣µíê∩╝ðΣ╗ÍΦÚúσå│τöƒτë⌐Σ┐íµü»σ¡ÓπÇüσƒ║σøáτ╗äσ¡ÓπÇüτ╗ƒΦ«íσÆðτÁ╛Σ║Áτ╜æτ╗£σêåµ₧Éτ¡ëΘóåσƒƒτÜäσ╛êσÁÜΘÝ«ΘóýπÇéΦ┐ÖΦ┐ýµÓéΦÓüΣ╗Ðτ╗ÞΣ║åMapReduceπÇüHadoopσÆð...
ΘÆêσ»╣HadoopΘøåτ╛ÁΣ╕¡σ║öτö¿µëÚΦíðτÜäΣ╜ĵþêτÄçπÇüΘ½ýµêɵ£¼ΘÝ«Θóý,ΘÓûσàê,ΘÇÜΦ┐çσ»╣Hadoopσêåσ╕âσ╝Åσ¡ýσ鿵èǵ£»σÆðσ╣╢Φíðτ╝ûτ¿Ðµ¿íσ₧ÐτÜäσêåµ₧É,σÅæτÄ░µþ░µÞ«ΘøåΘççτö¿σÞþµûçΣ╗╢Φ┐ýµý»σÁܵûçΣ╗╢µû╣σ╝Å,Σ╗ÍσÅèµþ░µÞ«σØÝσêÆσêåτÜäσÁÚσ░ŵý»σ╜▒σôÞσà╢µÇÚΦâ╜τÜäΣ╕╗ΦÓüσøáτ┤á.σà╢µ¼í,Φ«╛Φ«íσ«₧Θ¬ðµÄóΦ«¿Σ║åΣ╕ÞσÉð...
hadoopµÇÚΦâ╜µ╡ÐΦ»þµèÍσæè
µþ░µÞ«τ«Ýµ│þHadoop/SparkσÁÚµþ░µÞ«σÁäτÉåµèÇσ╖Ú µ║ÉΣ╗úτáü σåൣëΘâ¿σêåµþ░µÞ«Θøå
hadoopσÁÚµþ░µÞ«ΘÆêσ»╣aprioriτ«Ýµ│þτÜäΦ«╛Φ«íΣ║Äσ«₧τÄ░