
Case Study: Automatic Reduce Parallelism
Motivation
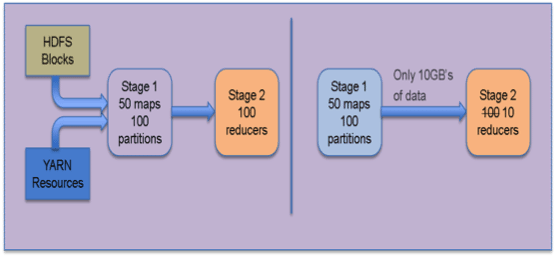 Distributed data processing is dynamic by nature and it is extremely difficult to statically determine optimal concurrency and data movement methods a priori. More information is available during runtime, like data samples and sizes, which may help optimize the execution plan further. We also recognize that Tez by itself cannot always have the smarts to perform these dynamic optimizations. The design of Tez includes support for pluggable vertex management modules to collect relevant information from tasks and change the dataflow graph at runtime to optimize for performance and resource usage. The diagram shows how we can determine an appropriate number of reducers in a MapReduce like job by observing the actual data output produced and the desired load per reduce task.
Distributed data processing is dynamic by nature and it is extremely difficult to statically determine optimal concurrency and data movement methods a priori. More information is available during runtime, like data samples and sizes, which may help optimize the execution plan further. We also recognize that Tez by itself cannot always have the smarts to perform these dynamic optimizations. The design of Tez includes support for pluggable vertex management modules to collect relevant information from tasks and change the dataflow graph at runtime to optimize for performance and resource usage. The diagram shows how we can determine an appropriate number of reducers in a MapReduce like job by observing the actual data output produced and the desired load per reduce task.
Performance & Efficiency via Dynamic Graph Reconfiguration
Tez envisions running computation by the most resource efficient and high-performance means possible given the runtime conditions in the cluster and the results of the previous steps of the computation. This functionality is constructed using a couple of basic building blocks
- Pluggable Vertex Management Modules: The control flow architecture of Tez incorporates a per-vertex pluggable module for user logic that deeply understands the data and computation. The vertex state machine invokes this user module at significant transitions of the state machine such as vertex start, source task completion etc. At these points the user logic can examine the runtime state and provide hints to the main Tez execution engine on attributes like vertex task parallelism.
- Event Flow Architecture: Tez defines a set of events by which different components like vertices, tasks etc. can pass information to each other. These events are routed from source to destination components based on a well-defined routing logic in the Tez control plane. One such event is the VertexManager event that can be used to send any kind of user-defined payload to the VertexManager of a given vertex.
Case Study: Reduce task parallelism and Reduce Slow-start
Determining the correct number of reduce tasks has been a long standing issue for Map Reduce jobs. The output produced by the map tasks is not known a priori and thus determining that number before job execution is hard. This becomes even more difficult when there are several stages of computation and the reduce parallelism needs to be determined for each stage. We take that as a case study to demonstrate the graph reconfiguration capabilities of Tez.
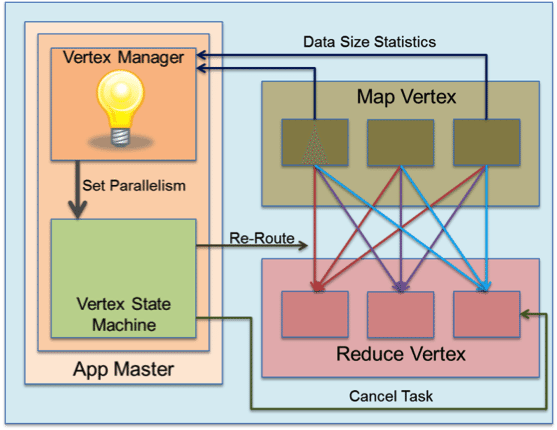 Reduce Task Parallelism: Tez has a ShuffleVertexManager that understands the semantics of hash based partitioning performed over a shuffle transport layer that is used in MapReduce. Tez defines a VertexManager event that can be used to send an arbitrary user payload to the vertex manager of a given vertex. The partitioning tasks (say the Map tasks) use this event to send statistics such as the size of the output partitions produced to the ShuffleVertexManager for the reduce vertex. The manager receives these events and tries to model the final output statistics that would be produced by the all the tasks. It can then advise the vertex state machine of the Reduce vertex to decrease the parallelism of the vertex if needed. The idea being to first over-partition and then determine the correct number at runtime. The vertex controller can cancel extra tasks and proceed as usual.
Reduce Task Parallelism: Tez has a ShuffleVertexManager that understands the semantics of hash based partitioning performed over a shuffle transport layer that is used in MapReduce. Tez defines a VertexManager event that can be used to send an arbitrary user payload to the vertex manager of a given vertex. The partitioning tasks (say the Map tasks) use this event to send statistics such as the size of the output partitions produced to the ShuffleVertexManager for the reduce vertex. The manager receives these events and tries to model the final output statistics that would be produced by the all the tasks. It can then advise the vertex state machine of the Reduce vertex to decrease the parallelism of the vertex if needed. The idea being to first over-partition and then determine the correct number at runtime. The vertex controller can cancel extra tasks and proceed as usual.
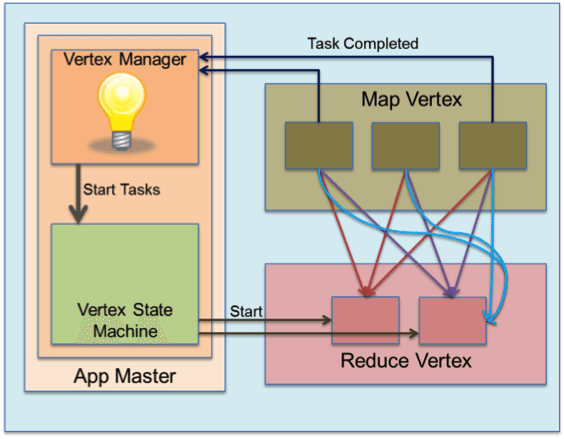 Reduce Slow-start/Pre-launch: Slow-start is a MapReduce feature where-in the reduce tasks are launched before all the map tasks complete. The hypothesis being that reduce tasks can start fetching the completed map outputs while the remaining map tasks complete. Determining when to pre-launch the reduce tasks is tricky because it depends on output data produced by the map tasks. It would be inefficient to run reduce tasks so early that they finish fetching the data and sit idle while the remaining maps are still running. In Tez, the slow-start logic is embedded in the ShuffleVertexManager. The vertex state controller informs the manager whenever a source task (here the Map task) completes. The manager uses this information to determine when to pre-launch the reduce tasks and how many to pre-launch. It then advises the vertex controller.
Reduce Slow-start/Pre-launch: Slow-start is a MapReduce feature where-in the reduce tasks are launched before all the map tasks complete. The hypothesis being that reduce tasks can start fetching the completed map outputs while the remaining map tasks complete. Determining when to pre-launch the reduce tasks is tricky because it depends on output data produced by the map tasks. It would be inefficient to run reduce tasks so early that they finish fetching the data and sit idle while the remaining maps are still running. In Tez, the slow-start logic is embedded in the ShuffleVertexManager. The vertex state controller informs the manager whenever a source task (here the Map task) completes. The manager uses this information to determine when to pre-launch the reduce tasks and how many to pre-launch. It then advises the vertex controller.
Its easy to see how the above can be extended to determine the correct parallelism for range-partitioning scenarios. The data samples could be sent via the VertexManager events to the vertex manager that can create the key-range histogram and determine the correct number of partitions. It can then assign the appropriate key-ranges to each partition. Thus, in Tez, this operation could be achieved without the overhead of a separate sampling job.
orginal doc: http://hortonworks.com/blog/apache-tez-dynamic-graph-reconfiguration/



相关推荐
tez:训练pytorch模型fastrrrr ....... tez:训练pytorch模型fastrrrr .......注意:当前,我们不接受任何拉取请求! 所有公共关系将被关闭。 如果您需要某个功能或某些功能不起作用,请创建一个问题。 意思是“锐利...
Tez:简单的pytorch培训师 注意:当前,我们不接受任何拉取请求! 所有公共关系将被关闭。 如果您需要某个功能或某些功能不起作用,请创建一个问题。 意思是“锐利,快速,活跃”。 这是一个简单的要点库,使您的...
阿帕奇·特兹(Apache Tez) Apache Tez是一个通用的数据处理管道引擎,被设想为用于更高抽象的低级引擎,例如Apache Hadoop Map-Reduce,Apache Pig,Apache Hive等。 从本质上讲,tez非常简单,只有两个组成部分...
在 Tez 上运行 Apache Hive 的 Docker 镜像此存储库包含一个 docker 文件,用于构建 docker 映像以在 Tez 上运行 Apache Hive。 这个 docker 文件依赖于我的其他包含和 基础镜像的存储库。当前版本Apache Hive(主干...
Storm-tez 使用TEZ在纱线POC上进行风暴
audioholic.tez 建立在Tezos区块链上的音乐流/购买平台。
阿托斯 (ATOS)数字式位置控制器Z-RI-TEZpdf,阿托斯 (ATOS)数字式位置控制器Z-RI-TEZ:数字式,与阀集成,适用于轴运动控制
包括pom修改的每个截图和配置,该文档从有道云笔记到处略加修改,其中pom内容格式需要你手动调整一下. 富含 大量截图帮助定位和配置. 含hive on tez 常见报错的解决方法. tez比spark更省心. spark容易出现内存问题.
1)Failing because I am unlikely to write too. 2)Caused by: java.lang.OutOfMemoryError: Java heap space ...5)hive on tez 最终insert的表如果使用到union all 时会导致直接查询结果表数据为空的
源码使用的是apache-tez-0.8.3,对应的hadoop版本2.7.3,源码包中的nodejs的版本是v0.12.3,很难编译通过,最后把nodejs改成了v4.0.0才编译通过tez-ui2模块。
Apache TEZ 部署手册 的各个步骤,包括打包等步骤说明
源码使用的是apache-tez-0.8.3,对应的hadoop版本2.8.3,源码包中的nodejs的版本是v0.12.3,很难编译通过,最后把nodejs改成了v4.0.0才编译通过tez-ui2模块。
最新版本tez-ui war包,可以解决tez编译问题出现tez-ui编译不进去的问题,现在可以吧这个拿出来自己配置到hadoop和tez上
apache tez 安装
学习大数据的小白用得到的apache tez源码,通过源码可以感受大牛们的代码风格和思维逻辑
基于github tez最新版本编译,编译日期为2021-03-22,压缩包带有tar包和tez-ui的war包
Tez是Apache开源的支持DAG作业的计算框架,它直接源于MapReduce框架,核心思想是将Map和Reduce两个操作进一步拆分,即Map被拆分成Input、Processor、Sort、Merge和Output, Reduce被拆分成Input、Shuffle、Sort、...
tez-0.9.1.tar.gz(CDH6.3.2编译版)已安装测试
基于hadoop 3.2.1和 TEZ 0.9.2 最新版本比编译的tar包 ,欢迎下载,欢迎使用,希望好用