2、shedule条件
把并行循环中的计算指定给线程这种方式称为循环队列(loop’s schedule)。对于并行循环中并形体计算量接近的情况,使用默认的队列方式是最优的。但也存在并行循环中每个并行计算量大小不一致的情况,如果计算量大小差距很大,并行程序的执行时间是以最后完成的那个线程为结束标记的,所以如果还采用相同的队列方式,计算量小的线程会先执行完,然后等计算量大的线程执行完,最后才结束并行。在这种情况下,队列分布的不均将会影响整个并行的运行效率,因此,需要去设置其队列选项来控制队列的分布。
schedule条件的格式如下:
schedule(type[,chunk])
其中type有static,dynamic,guided和auto四种,chunk是表示一个并行块的大小。如果需要对1000个循环进行并行,可以将它分成8个并行块(chunk),每个并行块就包括125个循环,则并行块的大小就是125,即chunk size。线程执行的具体对象就是这些并行块chunk。static表示静态分割并行块,在整个并行计算过程中并行块的大小都一样。dynamic则表示动态分割,默认其并行块尺寸为1。guided表示向导性的分割,指定第一个并行块的大小,后面每个并行块的尺寸都会递减,直到最小的并行块尺寸。采用auto或runtime时,不需要设置chunk参数,此时队列类型将由环境变量omp_schedule来控制。
循环结构并行队列过程以及在CPU中执行队列过程如下图所示:
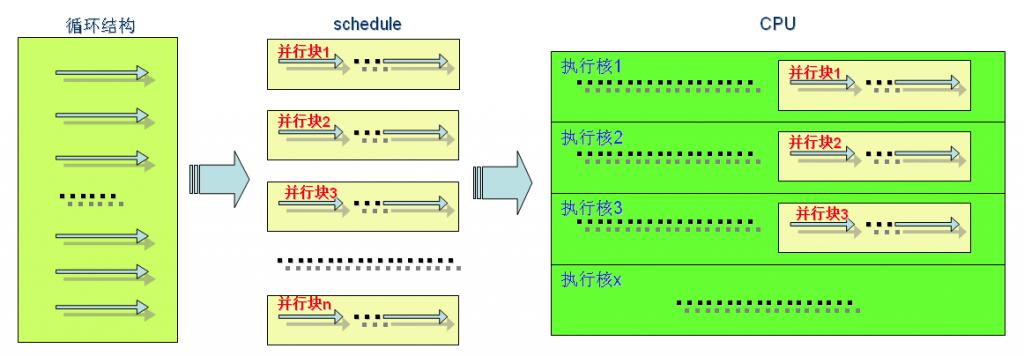
若循环结构中循环次数为100次,通过schedule队列指定每块尺寸为20(即20个循环),则有5个并行块,每个并行块中并形体(一个循环)仍然按串行方式排列。每个并行块对应一个新的线程。若计算机CPU具有4个执行核或4线程,那么每一时刻最多只能执行4个线程,而现在有5个并行块,所以最多只能执行4个并行块,剩下一个并行块就只有在后面,并行计算所耗时间是由最慢的那个线程(并行块)来决定的,所以尽量让这些并行块数目是计算机CPU核心的倍数(1倍或其它整数倍),以充分利用计算机CPU资源。
下面通过一个程序动态设置并行块大小来测试对计算效率的影响,代码如下:
// File: ScheduleTest.cpp
#include "stdafx.h"
#include<omp.h>
#include<iostream>
using namespace std;
//private测试
int ScheduleTest()
{
cout<<"ScheduleTest输出:\n";
inti=0,j,chunkSize = 1;
doublestarttime,endtime;
cout<<"请输入并行块的大小(-200):\n";
cin>>chunkSize;
starttime=omp_get_wtime();
#pragmaomp parallel for private(j)schedule(static,chunkSize)
for(i=0;i<200;i++)
{
for(j=0;j<100000000;j++);
}
endtime=omp_get_wtime();
cout<<"计算耗时为:"<<endtime-starttime<<"s\n";
return0;
}
分别设置并行块大小为1、2等,分别测试其计算耗时,结果如下表所示:
|
并行块大小
|
计算耗时(s)
|
并行块数目
|
每核平均执行并行块数目
|
空闲线程数
|
并行块大小
|
计算耗时(s)
|
并行块数目
|
每核平均执行并行块数目
|
空闲线程数
|
|
1
|
7.08998
|
200
|
25.0
|
0
|
24
|
8.57893
|
9
|
1.0
|
7
|
|
2
|
7.2503
|
100
|
12.5
|
4
|
25
|
7.05088
|
8
|
1.0
|
0
|
|
3
|
7.44965
|
67
|
8.3
|
5
|
26
|
7.25465
|
8
|
1.0
|
0
|
|
4
|
7.67307
|
50
|
6.3
|
6
|
27
|
7.45207
|
8
|
0.9
|
0
|
|
5
|
7.09083
|
40
|
5.0
|
0
|
28
|
7.87446
|
8
|
0.9
|
0
|
|
6
|
8.1865
|
34
|
4.2
|
6
|
29
|
8.4484
|
7
|
0.9
|
1
|
|
7
|
7.69326
|
29
|
3.6
|
3
|
30
|
8.17421
|
7
|
0.8
|
1
|
|
8
|
8.57003
|
25
|
3.1
|
7
|
31
|
8.41376
|
7
|
0.8
|
1
|
|
9
|
7.36662
|
23
|
2.8
|
1
|
32
|
8.62639
|
7
|
0.8
|
1
|
|
10
|
8.30294
|
20
|
2.5
|
4
|
33
|
9.14871
|
7
|
0.8
|
1
|
|
11
|
9.01532
|
19
|
2.3
|
5
|
34
|
9.09194
|
6
|
0.7
|
2
|
|
12
|
8.58991
|
17
|
2.1
|
7
|
35
|
9.32059
|
6
|
0.7
|
2
|
|
13
|
7.27074
|
16
|
1.9
|
0
|
36
|
9.5623
|
6
|
0.7
|
2
|
|
14
|
7.70015
|
15
|
1.8
|
1
|
37
|
10.0546
|
6
|
0.7
|
2
|
|
15
|
8.26512
|
14
|
1.7
|
2
|
38
|
10.1078
|
6
|
0.7
|
2
|
|
16
|
8.72735
|
13
|
1.6
|
3
|
39
|
10.248
|
6
|
0.6
|
2
|
|
17
|
9.05444
|
12
|
1.5
|
4
|
40
|
10.472
|
5
|
0.6
|
3
|
|
18
|
9.52952
|
12
|
1.4
|
4
|
50
|
12.572
|
4
|
0.5
|
4
|
|
19
|
10.0843
|
11
|
1.3
|
5
|
80
|
20.2732
|
3
|
0.3
|
5
|
|
20
|
10.5465
|
10
|
1.3
|
6
|
100
|
24.5377
|
2
|
0.3
|
6
|
|
21
|
10.9686
|
10
|
1.2
|
6
|
150
|
36.5224
|
2
|
0.2
|
6
|
|
22
|
11.4323
|
10
|
1.1
|
6
|
200
|
48.5702
|
1
|
0.1
|
7
|
|
23
|
10.2983
|
9
|
1.1
|
7
|
|
|
|
|
|
注:空闲线程指每队列中并行块数目没有填满CPU中总线程,所剩下的空闲线程(实际上这些线程不是空闲的,它可能用于其它程序,在此只是假定空闲以便于比较)。
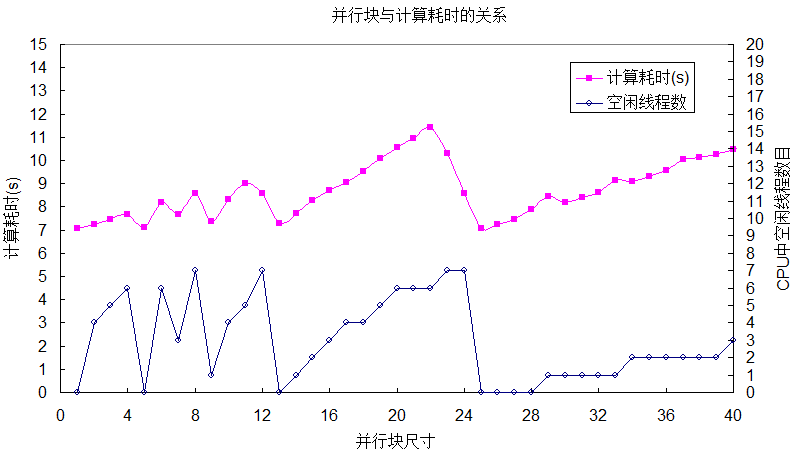
从上图以及测试结果可以得知:在每核平均执行并行块数目大于或等于1.0时,并行块数目对计算效率的影响呈锯齿状形态;当每核平均执行并行块数目小于1.0时,计算效率急剧下降;空闲线程数目越多,计算效率越低。当每核平均执行并行块数目为1,且每个并行块中尺寸均匀相等时,计算效率会提供到极大值,上例中即并行块尺寸为25时。若每个循环的计算量相差不大,建议采用static设置每个并行块尺寸一样。
相关程序源码下载地址:
http://download.csdn.net/detail/xwebsite/3843187
分享到:




相关推荐
- **并行循环**:LabVIEW支持并行编程,你可以使用并行循环结构(如Parfor Loop)来加速计算密集型任务,尤其是当你的系统拥有多个处理器核心时。 - **优化技巧**:理解何时使用循环结构的优化选项,如预分配数组和...
在这个“labview事件结构控制多个并行循环运行示例LV8.6版”中,我们将探讨如何利用LabVIEW的事件结构来实现多个并行循环的高效控制。 事件结构是LabVIEW中的核心编程机制之一,它允许程序对多个不相关的事件做出...
* 通过优化循环结构,例如使用缓存、减少循环次数、使用并行处理等,可以提高循环结构的效率。 * 通过优化循环结构,可以提高程序的执行效率和可读性。 本章节通过循环结构的基本概念、应用、python3实现、实践例题...
并行多核体系结构基础_课后习题 本资源摘要信息涵盖了并行多核体系结构基础的课后习题,涉及到工艺技术升级、设计权衡、功率管理和Amdahl定律等多...此外,还需要使用共享编程模型对算法中的“for i”循环进行并行化。
1. **并行编程语言和库**:如OpenMP、CUDA、OpenCL等,它们的语法、并行区域的定义以及并行循环的处理。 2. **错误处理和调试**:在并行环境中,数据竞争、死锁和竞态条件等问题的识别和解决方法。 3. **性能优化...
4. **自动并行化系统实现**:该方法已集成到一个自动并行化系统中,这意味着它可以自动识别适合并行化的循环结构,并自动进行相应的优化,减轻了程序员的工作负担。 5. **实际应用效果**:在实际应用中,该方法展示...
微机原理与接口技术实验题目及其答案,汇编程序源码,汇编语言分支和循环结构,8255并行接口实验,使用8255完成流水灯实验,8254定时/计数器应用实验,8254 典型应用电路的接法,8259 中断控制器的工作原理, 8259 ...
循环性能优化策略包括减少循环次数、避免重复计算、选择合适的循环结构,还可以利用并行循环、循环展开和循环向量化技术。 **循环与递归**的区别在于,循环通过迭代实现重复,适合已知迭代次数的情况;递归则是函数...
我们将我们的方法与pthread par allelization进行比较,表明(1)我们的并行执行是确定性的,(2)我们的线程管理缺陷,(3)我们的并行性是隐式的,(4)我们的方法并行化函数和循环。隐式并行性使并行代码易于编写...
循环级并行性则与迭代循环操作相关,是并行机或向量计算机上运行的最优程序结构;子任务级、任务级和作业级的并行性则对应不同的任务粒度和处理规模。 并行处理技术的发展,对于提高计算机系统的并行性至关重要。...
循环结构是计算机编程中的基础控制流之一,用于重复执行一段代码直到满足特定条件为止。常见的循环结构有for循环、while循环和do-while循环。在本例中,我们使用for循环来计算第200位三角数。for循环由三个部分组成...
文章主要探讨了C语言程序中循环结构的性能优化,内容涉及C语言、循环结构优化、缓存和并行等多个领域。首先,循环结构是C语言程序的基本结构之一,程序运行时,循环中的时间开销往往占据了总时间开销的大部分。因此...
- `parfor`:用于并行循环,类似于普通的`for`循环,但可以并行执行循环体。 - `spmd`:同步并行多指令多数据(SPMD)结构,允许在所有工作节点上执行相同的代码段。 - `parfeval`:并行函数评估,可以在后台工作...
在快速排序的过程中,可以使用OpenMP的并行for循环来并行化“划分”和“递归”步骤。当划分完成后,可以并行地对子数组进行排序,这样就避免了频繁的消息传递,更适合于共享内存系统。 并行快速排序的挑战包括负载...
实验报告“51单片机并行端口实验报告”主要...总的来说,这个实验报告涵盖了51单片机的并行端口编程、中断系统、循环结构、汇编语言以及硬件连接等多个关键知识点,对于学习单片机的初学者来说是一次全面且实用的实践。
第2章为利用parfor对for循环进行并行;第3章为SPMD并行结构;第4章为其他Matlab并行结构;第5章为Matlab并行计算数据类型;第6章为Matlab通用并行程序设计;第7章为MDCE配置;第8章为创建多线程MEX文件;第9章为在...
在编程语言中,循环结构是控制程序流程的重要组成部分,它允许我们重复执行一段代码,直到满足特定条件为止。C#作为.NET框架的核心编程语言,提供了多种循环结构供开发者使用。以下将详细介绍C#中的几种主要循环结构...