
使用默认的Kafka参数配置你就能够从零搭建起一个Kafka集群环境用于开发及测试之用,但默认配置通常都不匹配你的生产环境,因此必须要做某种程度的调优。毕竟不同的使用场景有着不同的使用需求和性能指标。而Kafka提供的各种参数就是为了优化这些需求和指标的。Kafka提供了很多配置供用户设置以确保搭建起来的Kafka环境是能够满足需求目标的,因此详细地去调研这些参数的含义以及针对不同参数值进行测试是非常重要的。所有这些工作都应该在Kafka正式上生产环境前就做好,并且各种参数的配置要考虑未来集群规模的扩展。
执行优化的流程如下图所示:

- 明确调优目标
- 有针对性地配置Kafka server端和clients端参数
- 执行性能测试,监控各个指标以确定是否满足需求以及是否有进一步调优的可能
一、确立目标
第一步就是要明确性能调优目标,主要从4个方面考虑:吞吐量(throughput)、延时(latency)、持久性(durability)和可用性(availability)。根据实际的使用场景来确定要达到这4个中的哪个(或哪几个)目标。有时候我们可能很难确定自己到底想要什么,那么此时可以尝试采用这样的方法:让你的团队坐下来讨论一下原本的业务使用场景然后看看主要的业务目标是什么。确立目标的原因主要有两点:
- “鱼和熊掌不可兼得”——你没有办法最大化所有目标。这4者之间必然存在着权衡(tradeoff)。常见的tradeoff包括:吞吐量和延时权衡、持久性和可用性之间权衡。但是当我们考虑整个系统时通常都不能孤立地只考虑其中的某一个方面,而是需要全盘考量。虽然它们之间不是互斥的,但使所有目标同时达到最优几乎肯定是不可能的
- 我们需要不断调整Kafka配置参数以实现这些目标,并确保我们对Kafka的优化是满足用户实际使用场景的需要
下面的这些问题可以帮助你确立目标:
- 是否期望着Kafka实现高吞吐量(TPS,即producer生产速度和consumer消费速度),比如几百万的TPS?由于Kafka自身良好的设计,生产超大数量的消息并不是什么难事。比起传统的数据库或KV存储而言,Kafka要快得多,而且使用普通的硬件就能够做到这点
- 是否期望着Kafka实现低延时(即消息从被写入到被读取之间的时间间隔越小越好)? 低延时的一个实际应用场景就是平时的聊天程序,接收到某一条消息越快越好。其他的例子还包括交互性网站中用户期望实时看到好友动态以及物联网中的实时流处理等
- 是否期望着Kafka实现高持久性,即被成功提交的消息永远不能丢失?比如事件驱动的微服务数据管道使用Kafka作为底层数据存储,那么就要求Kafka不能丢失事件。再比如streaming框架读取持久化存储时一定要确保关键的业务事件不能遗漏等
- 是否期望着Kafka实现高可用?即使出现崩溃也不能出现服务的整体宕机。Kafka本身是分布式系统,天然就是能够对抗崩溃的。如果高可用是你的主要目标,配置特定的参数确保Kafka可以及时从崩溃中恢复就显得至关重要了
二、配置参数
下面我们将分别讨论这四个目标的优化以及对应的参数设置。这些参数涵盖了producer端、broker端和consumer端的不同配置。如前所述,很多配置都提现了某种程度的tradeoff,在使用时一定要弄清楚这些配置的真正含义,做到有的放矢。
producer端
- batch.size
- linger.ms
- compression.type
- acks
- retries
- max.in.flight.requests.per.connection
- buffer.memory
Broker端
- default.replication.factor
- num.replica.fetchers
- auto.create.topics.enable
- min.insync.replicas
- unclean.leader.election.enable
- broker.rack
- log.flush.interval.messages
- log.flush.interval.ms
- unclean.leader.election.enable
- min.insync.replicas
- num.recovery.threads.per.data.dir
Consumer端
- fetch.min.bytes
- auto.commit.enable
- session.timeout.ms
1 调优吞吐量
Producer端
- batch.size = 100000 - 200000(默认是16384,通常都太小了)
- linger.ms = 10 - 100 (默认是0)
- compression.type = lz4
- acks = 1
- retries = 0
- buffer.memory:如果分区数很多则适当增加 (默认是32MB)
Consumer端
- fetch.min.bytes = 10 ~ 100000 (默认是1)
2 调优延时
Producer端
- linger.ms = 0
- compression.type = none
- acks = 1
Broker端
- num.replica.fetchers:如果发生ISR频繁进出的情况或follower无法追上leader的情况则适当增加该值,但通常不要超过CPU核数+1
Consumer端
- fetch.min.bytes = 1
3 调优持久性
Producer端
- replication.factor = 3
- acks = all
- retries = 相对较大的值,比如5 ~ 10
- max.in.flight.requests.per.connection = 1 (防止乱序)
Broker端
- default.replication.factor = 3
- auto.create.topics.enable = false
- min.insync.replicas = 2,即设置为replication factor - 1
- unclean.leader.election.enable = false
- broker.rack: 如果有机架信息,则最好设置该值,保证数据在多个rack间的分布性以达到高持久化
- log.flush.interval.messages和log.flush.interval.ms: 如果是特别重要的topic并且TPS本身也不高,则推荐设置成比较低的值,比如1
Consumer端
- auto.commit.enable = false 自己控制位移
4 调优高可用
Broker端
- unclean.leader.election.enable = true
- min.insync.replicas = 1
- num.recovery.threads.per.data.dir = log.dirs中配置的目录数
Consumer端
- session.timeout.ms:尽可能地低
三、指标监控
1 操作系统级指标
- 内存使用率
- 磁盘占用率
- CPU使用率
- 打开的文件句柄数
- 磁盘IO使用率
- 带宽IO使用率
2 Kafka常规JMX监控
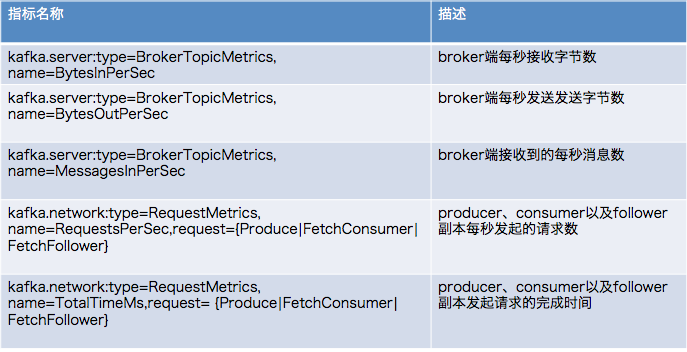
3 易发现瓶颈的JMX监控

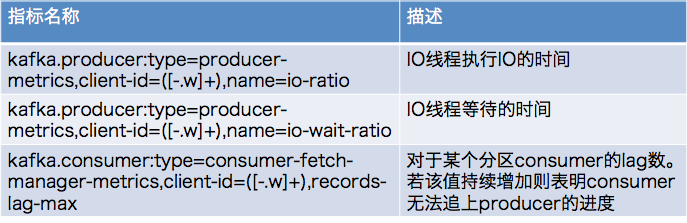
4 clients端常用JMX监控
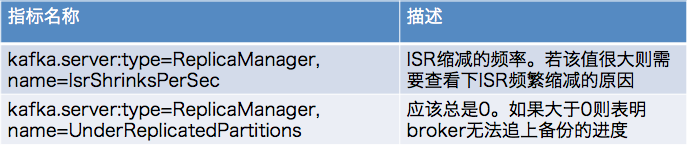
5 broker端ISR相关的JMX监控
rel:https://www.cnblogs.com/huxi2b/p/6936348.html
rel:https://www.confluent.io/blog/optimizing-apache-kafka-deployment/



相关推荐
Apache Kafka实战.pdf..
Apache Kafka源码剖析 PDF较大,分5份上传!一起解压即可。
课程内容包括了Kafka java Consumer实战,Kafka集成框架,Kafka分布式集群架构,Kafka性能测试实战,Kafka集群监控实战,Kafka用户行为画像,Kafka性能存储优化及如何提高Kafka吞吐量等企业级技术。 视频大小:1.5G
Spring for Apache Kafka API。 Spring for Apache Kafka 开发文档。
This book is here to help you get familiar with Apache Kafka and to solve your challenges related to the consumption of millions of messages in publisher-subscriber architectures. It is aimed at ...
Apache Kafka is a popular distributed streaming platform that acts as a messaging queue or an enterprise messaging system. It lets you publish and subscribe to a stream of records and process them in ...
本文不讲kafka集群原理,只谈部署步骤。 默认读者已对kafka有最基本的认知,纯粹作为部署笔记,方便回忆。 另外本文是基于Windows部署的,Linux的步骤是基本相同的(只是启动脚本位置不同)。 kafka集群类型: ...
KCenter(之前项目名称为KafkaCenter)是Apache Kafka 集群管理和维护,生产/消费监控,生态组件使用的统一一站式平台
zookeeper集群部署,kafka集群部署,kafka介绍,topic创建、删除、kafka监控
Building Data Streaming Applications with Apache Kafka 英文azw3 本资源转载自网络,如有侵权,请联系上传者或csdn删除 本资源转载自网络,如有侵权,请联系上传者或csdn删除
Apache Kafka Apache Kafka Apache Kafka Apache Kafka
docker容器中搭建kafka集群环境,kafka集群配置注意事项与优化
Kafka是一个对于像Hadoop的一样的日志数据和离线... 1.Kafka集群包含一个或多个服务器,这种服务器被称为broker 2.Partition是物理上的概念,每个Topic包含一个或多个Partition. 3.负责发布消息到Kafka broker ……
Streaming Architecture New Designs Using Apache Kafka and MapR Streams
搭建基于sasl的安全认证的kafka集群,并配置acl,使用户能分权分域接受发送消息
kafka集群部署文档及kafka详解,包括kafka常用命令,详细部署说明,如何运维以及一些FAQ,下载app注册免费获取:http://m3w.cn/jcsh
网上Kafka集群搭建的教程很多了,但真正能用的不多,本文提供了详细的步骤说明,绝对可用
《Apache Kafka实战》是涵盖Apache Kafka各方面的具有实践指导意义的工具书和参考书。...第7~9章以实例的方式讲解了Kafka集群的管理、监控与调优;第10章介绍了Kafka新引入的流式处理组件。 《Apache Kafk...
apache kafka技术内幕 和 apacke kafka源码分析2本PDF 电子书 网盘下载