
Kafka Streams
初识流式处理
什么是数据流
数据流(也叫事件流)是无边界数据集的抽象表示。无边界意味着无限和持续增长。无边界数据集之所以是无限的,是因为随着时间的推移,新记录会不断加入进来。数据流除了无边界还有以下特性:
-
数据流是有序的。事件的发生总是有先后顺序的,如先下单再发货
-
数据记录不可变。事件一旦发生,就不能被改变,如下单后,想要取消只会新产生一个事件
-
数据流是可重播的。
什么是流式处理
持续的从一个无边界的数据集读取数据,然后对它们进行处理并生成结果,就是流式处理。
流式处理是一种编程范式,就像请求和响应范式、批处理范式那样,下面是三种范式的比较:
-
请求和响应,这种范式的特点是延迟最小
-
批处理,这种范式的特点是高延迟和高吞吐量
-
流式处理,这种范式介于上面两种之间
什么是Kafka Streams
Kafka Streams是一个用于构建流式处理应用程序的客户端库,其中输入和输出数据是存储在Kafka集群中的。一个用Kakfa Streams搭建的流处理程序,它的架构如下图:

Kafka Streams的优点:
-
简单轻量级的客户端库,可以轻松嵌入到任何Java应用程序中;除了Kafka之外没有其他外部的依赖。所有可以轻松的整合到自己的应用中,也不需要为流式处理需求额外的的部署一个应用集群。
-
使用Kafka作为内部消息通讯存储介质,不需要重新加入其它外部组件来做消息通讯。值得注意的是,它使用Kafka的分区模型来水平扩展处理,同时保持强大的排序保证。
-
支持本地状态容错,可实现非常快速有效的有状态操作,如窗口连接和聚合。本地状态被保存在Kafka中,在机器故障的时候,其他机器可以自动恢复这些状态继续处理。
-
可以保证每个记录只处理一次,即使在处理过程中Streams客户端或Kafka代理发生故障时也只处理一次。
-
采用一条记录一次处理以实现毫秒处理延迟,并支持基于事件时间的窗口操作以及记录的延迟到达。
-
提供丰富的流式处理API,包括高级的Streams DSL和低级的Processor API。
核心概念
时间
时间在流式处理中非常的重要,因为大部分的流式处理都是基于时间窗的,如计算5分钟内用户的访问量,那么对于五分钟前的数据就不应该参与计算。
-
事件时间
事件时间是指事件的发生时间或事件的创建时间,如商品的出售时间,用户的访问时间。在Kakfa 0.10之后的版本,生产者会自动在记录中添加创建时间,如果与业务的事件时间不一致,那就需要手动设置这个时间。
-
日志追加时间
日志追加时间是指时间保存到kafka broker上的时间。
-
处理时间
处理时间是指我们的应用在收到事件后对其处理的时间。同一个事件的处理时间可能不同,这取决于不同的应用何时读取这个时间
状态
如果只是单独的处理每一个事件,那么这个流式处理就很简单,如从数据流中过滤出交易金额大于10000的数据,然后给这些交易人发个优惠券,这种需求我们用kafka的消费者客户端就完全能满足,但通常情况下我们的操作中会包含多个事件,如统计总数、平均数、最大值等。事件与事件之间的信息被称为状态。如我们卖了1双鞋,然后又买了2双鞋,经过这两个事件后,在现在这个时间,我们鞋数量的状态就是一双。
流表的二元性
在业务系统中,有时我们关注变化的过程,有时我们关注结果。流是一系列事件,每个事件就是一个变更;表包含了当前的状态,是多个变更所产生的结果。将流转换为表,叫做流的物化。我们捕获到表所发生的变更(insert、update、delete)事件,这些事件就组成了流。
窗口
在流处理中,我们的数据处理大部分都是基于窗操作的,如我们在分析股价的走势时,我们需要统计出的每天或者每个小时的内股价的平均价格,然后查看价格的一个走势,而不是直接统计从股票发行到现在的平均价,这个是没多大意义的,这里的每天或每个小时就是一个时间窗。
在Kafka streams中窗口有两种,时间窗口和会话窗口(其实会话窗口也是基于时间窗的)。
时间窗有两个重要的属性:窗口大小和步长(移动间隔)。
-
滚动窗口:步长等于窗口大小,滚动窗口是没有没有记录的重叠。

-
跳跃窗口:步长不等于窗口大小

-
滑动窗口:窗口随着每一条记录移动,滑动窗口不与时间对齐,而是与数据记录时间戳对齐。
-
会话窗口:会话窗口与时间窗最大的不同是,他的大小是不确定的(因为它的大小是由数据本身决定的)
看下图,这是一个时间间隔为5分钟的session窗口 ,先忽略图中迟到的两个记录,假设他们没迟到。

Processing Topology(拓扑)和Stream processor(流处理器)
在kakfa streams中,计算逻辑被定义为拓扑,它是一个操作和变换的集合,每个事件从输入到输出都会流经它。每个流式处理的应用至少会有一个拓扑。
流处理器是处理拓扑中的各个节点,代表拓扑中的每个处理步骤,用来完成数据转换功能,如过滤、映射、分组、聚合等。一个流处理器同一时间从上游接收一条输入数据,产生一个或多个输出记录到下个流式处理器。
一个拓扑中有两种特殊的的处理器:
-
Source Processor,没有上游处理器,从一个或多个Kafka topic为拓扑生成输入流。
-
Slink Processor,没有下游处理器,将从上游处理器接收的记录发送到指定的Kafka主题。

从三个示例来了解Kafka Streams 的应用
单词统计
将数据按空格拆分成单个单词,过滤掉不需要的单词,统计每个单词出现的次数
// 配置信息
Properties props = new Properties();
//Streams应用Id
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "wordCount");
//Kafka集群地址
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.195.88:9092");
//指定序列化和反序列化类型
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
//创建一个topology构建器,在kakfa中计算逻辑被定义为连接的处理器节点的拓扑。
StreamsBuilder builder = new StreamsBuilder();
//使用topology构建器创建一个源流,指定源topic
KStream<String, String> source = builder.stream("wordCountInput");
// 构建topology
KStream<String, Long> wordCounts = source
//把数据按空格拆分成单个单词
.flatMapValues(textLine -> Arrays.asList(textLine.toLowerCase().split("\\W+")))
//过滤掉the这个单词,不统计这个单词
.filter((key, value) -> (!value.equals("the")))
//分组
.groupBy((key, word) -> word)
//计数,其中'countsStore'是状态存储的名字
.count(Materialized.<String, Long, KeyValueStore<Bytes, byte[]>>as("countsStore"))
.toStream();
//将stream写回到Kafka的topic
wordCounts.to("wordCountOutput", Produced.with(Serdes.String(), Serdes.String()));
//创建Streams客户端
KafkaStreams streams = new KafkaStreams(builder.build(), props);
//启动Streams客户端
streams.start();
股价统计
统计5秒钟内股票交易的最高价、最低价、交易次数及平均价格,统计信息每隔一秒钟更新一次。这是一个典型的时间窗的应用。
StreamsBuilder builder = new StreamsBuilder();
KStream<String, Trade> source = builder.stream("stockStatsInput");
KStream<Windowed<String>, TradeStats> stats =
// 按key分组,这里的key是股票代码
source.groupByKey()
// 创建一个跳跃时间窗,窗口大小5s,步长1s
.windowedBy(TimeWindows.of(Duration.ofSeconds(5)).advanceBy(Duration.ofSeconds(1)))
// 进行聚合操作,用TradeStats对象存储每个窗口的统计信息——最高价、最低价、交易次数及总交易额
.aggregate(TradeStats :: new, (k, v, tradeStats) -> tradeStats.add(v),
Materialized.<String, TradeStats,
WindowStore<Bytes, byte[]>>as("tradeAggregates").withValueSerde(new TradeStatsSerde()))
.toStream()
//计算平均股价
.mapValues(TradeStats :: computeAvgPrice);
//将stream写回到Kafka
stats.to("stockStatsOutput", Produced.keySerde(WindowedSerdes.timeWindowedSerdeFrom(String.class)));
KafkaStreams streams = new KafkaStreams(builder.build(), props);
streams.start();
网站点击事件分析
根据用户的搜索信息、点击信息、及个人信息,把这些信息连接在一起,动态的分析出用户行为。如一个用户搜索了"奶粉",并在一分钟内点击了“贝因美”,个人信息是年龄20-30岁之间的女性,我们把这些事件流连接起来后,就可以得到一条用户分析的数据,以后贝因美的奶粉搞活动了就可以直接向该用户推荐。这个例子主要演示了数据流间的连接。
// 搜索事件
KStream<Integer, Search> searches =builder.stream(Constants.SEARCH_TOPIC,
Consumed.with(Serdes.Integer(), new SearchSerde()));
// 点击事件
KStream<Integer, PageView> views = builder.stream(Constants.PAGE_VIEW_TOPIC,
Consumed.with(Serdes.Integer(), new PageViewSerde()));
// 用户信息
KTable<Integer, UserProfile> profiles = builder.table(Constants.USER_PROFILE_TOPIC,
Consumed.with(Serdes.Integer(), new ProfileSerde()), Materialized.as("profileStore"));
//将点击事件与用户信息连接,用UserActivity对象来存储状态
KStream<Integer, UserActivity> viewsWithProfile = views.leftJoin(profiles,
(page, profile) -> {
if (profile != null){
return new UserActivity(profile.getUserId(), profile.getUserName(),
profile.getPhone(), "", page.getPage());
}else {
return new UserActivity(-1, "", "", "", page.getPage());
}
});
//将用户点击事件与搜索信息连接
KStream<Integer, UserActivity> userActivityKStream = viewsWithProfile.leftJoin(searches,
(userActivity, search) -> {
if (search != null) {
userActivity.updateSearch(search.getSearchTerms());
}else {
userActivity.updateSearch("");
}
return userActivity;
},
// 搜索过后的10s秒钟内的数据才被认为是相关联的
JoinWindows.of(Duration.ofSeconds(10)),
Joined.with(Serdes.Integer(), new UserActivitySerde(), new SearchSerde()));
userActivityKStream.to(Constants.USER_ACTIVITY_TOPIC,
Produced.with(Serdes.Integer(), new UserActivitySerde()) );
KafkaStreams streams = new KafkaStreams(builder.build(), props);
streams.start();
Kafka Streams常见的API
Kafka Streams的API有两种,Kafka Streams DSL和Processor API。
-
Kafka Streams DSL是高级API,它提供最常见的数据转换操作,诸如map,filter,join等。
-
Processor API一种低级API,允许您添加和连接处理器以及直接与状态存储进行交互,Processor API为您提供比DSL更多的灵活性,但代价是需要在应用程序开发人员方面进行更多的手动工作(例如,更多行代码)。因此接下来所有的工作都是基于DSL。
重要的抽象
-
KStream:数据流抽象。创建方法如下:
StreamsBuilder builder = new StreamsBuilder(); KStream<String, Long> wordCounts = builder.stream( "word-counts-input-topic", // 输入的topic Consumed.with(Serdes.String(), Serdes.Long()) //key和value的序列化方式 ); -
KTable:数据表抽象。创建方法如下:
KStream<String, Long> wordCounts = builder.table( "word-counts-input-topic", // 输入的topic Consumed.with(Serdes.String(), Serdes.Long(), //key和value的序列化方式 Materialized.as("word-counts-store") // 状态存储名 ); -
GlobalKTable:同KTable,只不过是全局的,KTable是读取的当前分区的数据,而GlobalKTable是读取的全部分区的数据,这在进行join操作时是非常有用的。比较类似关系型数据库在分库分表后join的问题。
如何理解kStream和KTable的区别:
我们可以这样看,我们从topic先后读取了两条数据,("苹果", 1) --> ("苹果", 3),对于KStream来说,表示有一个苹果,然后我又有3个苹果,结果是我就有了4个苹果 ;但是对于KTable来说,表示我现在有1苹果,我现在有3个苹果,结果是我有3个苹果。因为对于KTable来说,第二条记录是第一条记录的更新。
所以官网对它们区别描述的非常好,KStream对于流中的记录始终解释为insert,而KTable对流中的记录解释为upsert。
无状态的转换
只需要数据流过一遍就可以,不依赖前后的状态。
-
branch:将一个Kstream分成多个
KStream<String, Long>[] branches = stream.branch( (key, value) -> key.startsWith("A"), //branches[0]中只包含key以“A”开头的所有记录 (key, value) -> key.startsWith("B"), //branches[1]中只包含key以“B”开头的所有记录 (key, value) -> true //branches[2]中包含其他记录 ); -
filter:过滤操作
// 过滤掉value不大于0的记录 KStream<String, Long> onlyPositives = stream.filter((key, value) -> value > 0); -
filterNot:反向过滤,与filter相反
-
flatMap:将一条记录转换成0条、1条或多条记录
// 把一条记录转换成了两条记录。如: (345L, "Hello") -> ("HELLO", 1000), ("hello", 9000) KStream<String, Integer> transformed = stream.flatMap((key, value) -> { List<KeyValue<String, Integer>> result = new LinkedList<>(); result.add(KeyValue.pair(value.toUpperCase(), 1000)); result.add(KeyValue.pair(value.toLowerCase(), 9000)); return result; }); -
flatMapValues:作用和flatMap相同,但是只是对value操作,转换后记录的key同原来的key
// 通过空格拆分成单个单词 KStream<byte[], String> words = sentences.flatMapValues(value -> Arrays.asList(value.split("\\s+"))); -
foreach:循环
// 循环打印出每条记录 stream.foreach((key, value) -> System.out.println(key + " => " + value)); -
groupByKey:根据key分组
KGroupedStream<byte[], String> groupedStream = stream.groupByKey(); -
GroupBy: 分组
// 分组,并修改了key和value的类型 KGroupedStream<String, String> groupedStream = stream.groupBy( (key, value) -> value, Serialized.with(Serdes.String(), Serdes.String()) ); // 分组,并生成新的key,并且修改了key和value的类型 KGroupedTable<String, Integer> groupedTable = table.groupBy( (key, value) -> KeyValue.pair(value, value.length()), Serialized.with(Serdes.String(), Serdes.Integer()) ); -
map:将一条记录转换成另一条记录
KStream<String, Integer> transformed = stream.map(key, value) -> KeyValue.pair(value.toLowerCase(), value.length())); -
mapValues:作用同map,但是只是对value操作,转换后记录的key同原来的key
KStream<byte[], String> uppercased = stream.mapValues(value -> value.toUpperCase()); -
merge:合并两个流
KStream<byte[], String> merged = stream1.merge(stream2); -
peek:对每条记录执行无状态操作,并返回未更改的流,也就是说peek中的任何操作,返回的都是以前的流,可以用来调试
KStream<byte[], String> unmodifiedStream = stream.peek((key, value) -> System.out.println("key=" + key + ", value=" + value)); -
print:打印流,可以用来调试
stream.print(); -
SelectKey:重新构建key
//将key值改为value的第一个单词 KStream<String, String> rekeyed = stream.selectKey((key, value) -> value.split(" ")[0]) -
toStream:将KTable转换成KStream
KStream<byte[], String> stream = table.toStream();
有状态的转换
有状态的转换包括:Aggregating、Joining、Windowing。他们间的关系如下图:

Aggregating(聚合)
通过groupByKey或groupBy分组后,返回KGroupedStream或KGroupedTable数据类型,它们可以进行聚合的操作。聚合是基于key操作的。这里有个注意点,kafka streams要求同一个连接操作所涉及的topic必须要有相同数量的分区,并且连接所用的key必须就是分区的key,至于为什么可以想一想分库分表后的join问题。
常用API
-
aggregate
滚动聚合,按分组键进行聚合。
聚合分组流时,必须提供初始值设定项(例如,aggValue = 0)和“加法”聚合器(例如,aggValue + curValue)。
聚合分组表时,必须提供“减法”聚合器(例如:aggValue - oldValue)。
KGroupedStream<byte[], String> groupedStream = ; KGroupedTable<byte[], String> groupedTable = ; // 聚合分组流 (注意值类型如何从String更改为Long) KTable<byte[], Long> aggregatedStream = groupedStream.aggregate( () -> 0L, // 初始值 (aggKey, newValue, aggValue) -> aggValue + newValue.length(), Materialized.as("aggregated-stream-store") // 本地状态名称 .withValueSerde(Serdes.Long()); // 聚合分组表 KTable<byte[], Long> aggregatedTable = groupedTable.aggregate( () -> 0L, (aggKey, newValue, aggValue) -> aggValue + newValue.length(), (aggKey, oldValue, aggValue) -> aggValue - oldValue.length(), Materialized.as("aggregated-table-store") .withValueSerde(Serdes.Long())KGroupedStream:
-
key为null的记录会被忽略。
-
第一次收到记录key时,将调用初始化(并在加法器之前调用)。
-
只要记录的值为非null时,就会调用加法器。
KGroupedTable:
- key为null的记录会被忽略。
- 第一次收到记录key时,将调用初始化(并在加法器和减法器之前调用)。
- 当一个key的第一个非null的值被接收,只调用加法器。
- 当接收到key的后续非空值(例如,UPDATE)时,则(1)使用存储在表中的旧值调用减法器,以及(2)使用输入记录的新值调用加法器。那是刚收到的。未定义减法器和加法器的执行顺序。
- 当为一个key(例如,DELETE)接收到逻辑删除记录(即具有空值的记录)时,则仅调用减法器。请注意,只要减法器本身返回空值,就会从生成的KTable中删除相应的键。如果发生这种情况,该key的任何下一个输入记录将再次触发初始化程序。
-
-
aggregate (windowed)
窗口聚合,按分组键聚合每个窗口的记录值。
KGroupedStream<String, Long> groupedStream = ...; // 与基于时间的窗口进行聚合(此处:使用5分钟的翻滚窗口) KTable<Windowed<String>, Long> timeWindowedAggregatedStream = groupedStream.windowedBy(Duration.ofMinutes(5)) .aggregate( () -> 0L, (aggKey, newValue, aggValue) -> aggValue + newValue, Materialized.<String, Long, WindowStore<Bytes, byte[]>>as("time-windowed-aggregated-stream-store").withValueSerde(Serdes.Long())); // 使用基于会话的窗口进行聚合(此处:不活动间隔为5分钟) KTable<Windowed<String>, Long> sessionizedAggregatedStream = groupedStream.windowedBy(SessionWindows.with(Duration.ofMinutes(5)) .aggregate( () -> 0L, (aggKey, newValue, aggValue) -> aggValue + newValue, (aggKey, leftAggValue, rightAggValue) -> leftAggValue + rightAggValue, Materialized.<String, Long, SessionStore<Bytes, byte[]>>as("sessionized-aggregated-stream-store").withValueSerde(Serdes.Long())); -
count
滚动聚合,按分组键统计记录数。
// Counting a KGroupedStream KTable<String, Long> aggregatedStream = groupedStream.count(); // Counting a KGroupedTable KTable<String, Long> aggregatedTable = groupedTable.count();对于KGroupedStream,会忽略具有空键或空值的记录。
对于KGroupedTable,会忽略具有空键的输入记录,具有空值的记录,会从table中删除该键。
-
count(windowed)
窗口聚合。按分组键统计每个窗口的记录数,它会忽略具有空键或空值的记录。
KTable<Windowed<String>, Long> aggregatedStream = groupedStream.windowedBy( TimeWindows.of(Duration.ofMinutes(5))) // 基于时间的窗口 .count(); KTable<Windowed<String>, Long> aggregatedStream = groupedStream.windowedBy( SessionWindows.with(Duration.ofMinutes(5))) // session窗口 .count(); -
Reduce
滚动聚合,通过分组键组合(非窗口)记录的值。当前记录值与最后一个减少的值组合,并返回一个新的减少值。与聚合不同,结果值类型不能更改。
KGroupedStream<String, Long> groupedStream = ...; KGroupedTable<String, Long> groupedTable = ...; KTable<String, Long> aggregatedStream = groupedStream.reduce( (aggValue, newValue) -> aggValue + newValue ); KTable<String, Long> aggregatedTable = groupedTable.reduce( (aggValue, newValue) -> aggValue + newValue, (aggValue, oldValue) -> aggValue - oldValue ); -
Reduce (windowed)
窗口聚合。通过分组键将每个窗口的记录值组合在一起。当前记录值与最后一个减少的值组合,并返回一个新的减少值。使用null键或值的记录将被忽略。与聚合不同,结果值类型不能更改。
KGroupedStream<String, Long> groupedStream = ...; KTable<Windowed<String>, Long> timeWindowedAggregatedStream = groupedStream.windowedBy( TimeWindows.of(Duration.ofMinutes(5))) .reduce((aggValue, newValue) -> aggValue + newValue ); KTable<Windowed<String>, Long> sessionzedAggregatedStream = groupedStream.windowedBy( SessionWindows.with(Duration.ofMinutes(5))) .reduce((aggValue, newValue) -> aggValue + newValue );
聚合过程详细分析
分组流的聚合:
KStream<String, Integer> wordCounts = ...;
KGroupedStream<String, Integer> groupedStream = wordCounts
.groupByKey(Grouped.with(Serdes.String(), Serdes.Integer()));
KTable<String, Integer> aggregated = groupedStream.aggregate(
() -> 0,
(aggKey, newValue, aggValue) -> aggValue + newValue,
Materialized.<String, Long, KeyValueStore<Bytes, byte[]>as("aggregated-stream-store" )
.withKeySerde(Serdes.String()).withValueSerde(Serdes.Integer());
这段段代码运行后,聚合会如下图所示随着时间的变化:
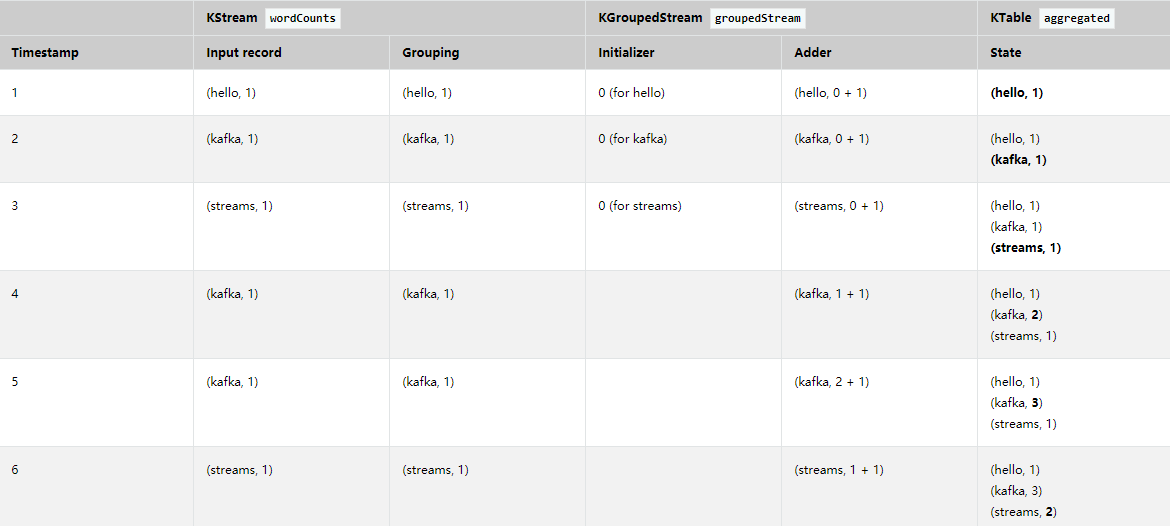
分组表的聚合:
KTable<String, String> userProfiles = ...;
KGroupedTable<String, Integer> groupedTable = userProfiles
.groupBy((user, region) ->KeyValue.pair(region, user.length()), Serdes.String(), Serdes.Integer());
KTable<String, Integer> aggregated = groupedTable.aggregate(
() -> 0,
(aggKey, newValue, aggValue) -> aggValue + newValue,
(aggKey, oldValue, aggValue) -> aggValue - oldValue,
Materialized.<String, Long, KeyValueStore<Bytes, byte[]>as("aggregated-table-store" )
.withKeySerde(Serdes.String()).withValueSerde(Serdes.Integer());
这段段代码运行后,聚合会如下图所示随着时间的变化:
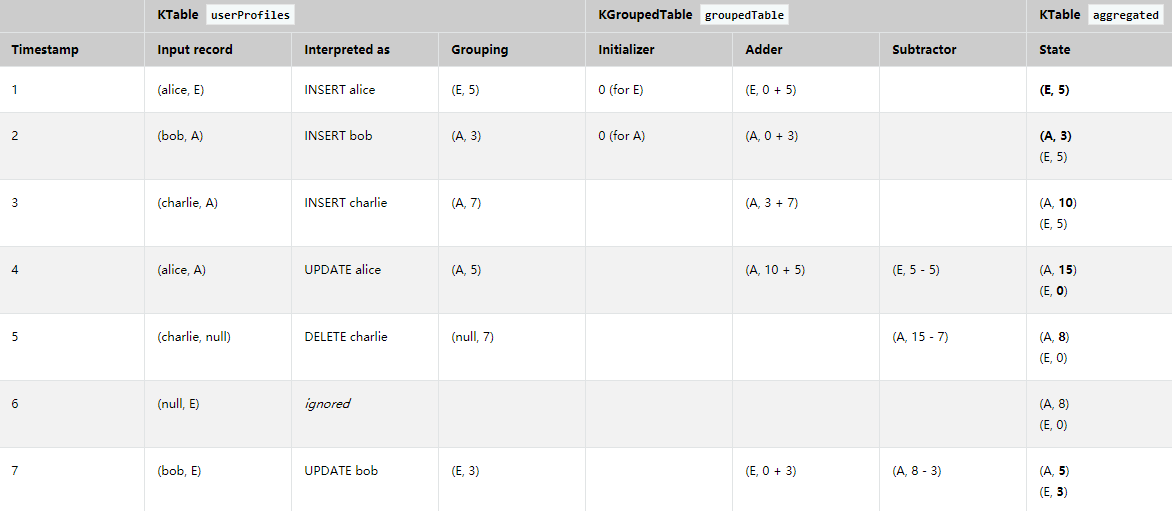
Joining
所谓连接,就是将两条记录按照一定的规则连接为一条记录,其实和sql中的连接是一样的作用。在Kafka stream中,join都是基于Key的,join的方式有三种:innerJoin、leftJoin和outerJoin。
-
join
KStream<String, Long> left = ...; KStream<String, Double> right = ...; KStream<String, String> joined = left.join(right, (leftValue, rightValue) -> "left=" + leftValue + ", right=" + rightValue, JoinWindows.of(Duration.ofMinutes(5)), Joined.with(Serdes.String(), Serdes.Long(), Serdes.Double()) ); -
leftJoin
KStream<String, Long> left = ...; KStream<String, Double> right = ...; KStream<String, String> joined = left.leftJoin(right, (leftValue, rightValue) -> "left=" + leftValue + ", right=" + rightValue, JoinWindows.of(Duration.ofMinutes(5)), Joined.with(Serdes.String(), Serdes.Long(), Serdes.Double()) ); -
outerJoin
KStream<String, Long> left = ...; KStream<String, Double> right = ...; KStream<String, String> joined = left.outerJoin(right, (leftValue, rightValue) -> "left=" + leftValue + ", right=" + rightValue, /* ValueJoiner */ JoinWindows.of(Duration.ofMinutes(5)), Joined.with( Serdes.String(), Serdes.Long(), Serdes.Double()) );
KStream-KStream的join总是基于windowed的。空键或空值的输入记录将被忽略,并且不会触发连接
KTable-KTable的join都是不基于windowed的。空键的输入记录将被忽略,并且不会触发连接
KStream-KTable的join都是不基于windowed的。只有左侧(流)的输入记录才会触发连接。右侧(表)的输入记录仅更新内部右侧连接状态。空键或空值的输入记录将被忽略,并且不会触发连接。
KStream-GlobalKTable的join都是不基于windowed的。只有左侧(流)的输入记录才会触发连接。右侧(表)的输入记录仅更新内部右侧连接状态。空键或空值的输入记录将被忽略,并且不会触发连接。
为什么只有流与流的连接必须是基于窗口的呢?因为流的数据是无限的,所以流和流的连接是不能完成的。
Windowing
窗口化使您可以控制如何将具有相同键的记录分组,以进行有状态操作,例如聚合或连接到所谓的窗口。根据记录密钥跟踪Windows。
// 创建一个时间窗口:窗口大小5s,步长1s
TimeWindows.of(Duration.ofSeconds(5)).advanceBy(Duration.ofSeconds(1));
// 创建一个会话窗口:窗口大小5分钟
SessionWindows.with(Duration.ofMinutes(5));
在实际情况中,我们不能保证,每条记录都能准时的到达,所以就不能保证窗口的结果一定是正确的。例如,我们要统计每一个小时的每种产品的的销售量,然后筛选出销量大于3的产品,但是有一条销售记录的确是在这个小时内产生的,由于某种原因,在这个时间窗关闭的以后才到达,这样的话我们这个时间窗的统计数据实际上是不准确的,解决这个问题,可以用如下的方法:那就是,时间窗在到时间时,先不着急关闭,等待一段时间。
KGroupedStream<UserId, Event> grouped = ...;
//允许时间窗接受迟到10分钟内的记录
grouped.windowedBy(TimeWindows.of(Duration.ofHours(1)).grace(ofMinutes(10)))
.count()
//控制在窗口关闭前,下游接受不到任何记录
.suppress(Suppressed.untilWindowCloses(unbounded()))
.filter((windowedUserId, count) -> count < 3)
.toStream();
自定义API
可以继承Process和Transform来达到我们自定义的目的。
Kafka Streams常见的配置
| application.id | 无 | kafka集群地址,必须参数 |
| bootstrap.servers | 无 | 应用id,必须参数,同一应用的所有实例的都应该一直。 |
| commit.interval.ms | 30000 ms | 提交任务位置的频率 |
| replication.factor | 1 | 应用程序创建的更改日志主题和重新分区主题的复制因子 |
| state.dir | /tmp/kafka-streams | 状态存储的物理位置,注意这个是保存的本地的 |
还有很多配置,等以后用到了再慢慢更新。详细请参考官方的配置介绍
分布式下的Kafka Streams
既然我们选择了kafka做应用,那么只用单线程或单实例的处理我们的业务那基本上是不太可能的,如果已经使用过kafka,我们知道kafka的扩展能力那是非常出色的,对使用者也是非常的简单,如kafka集群自身的扩展,我们仅仅需要集群的配置文件复制到新节点中,修改一下broker id就行了。对于Kafka Streams的应用来说,通过启动多个实例组建集群来提高吞掉量,那也是非常的容易,因为kafka会自动帮我们做好这些事情。
kafka能自动的根据我们的实例数量和每个实例的线程数量,将任务进行拆分,当然和topic的分区数也是直接相关的。和我们的消费者客户端一样,kafka会自动的协调工作,为每个任务分配属于任务自己的分区,这样每个任务独自处理自己的分区,并维护与聚合相关的本地状态。
如果我们需要处理来自多个分区的结果,即对多个任务结果再进行处理,这时我们就可以根据新的key进行重新分区后写入到重分区主题上,并启动新的任务从新主题上读取和处理事件。
容错
Kafka Streams对故障的处理有非常好的支持,如果应用出现故障需要重启,可以自动的从Kafka上找到上一处理的位置,从该位置继续开始处理。如果本地状态丢失(如宕机),应用可以自动从保存到kafka上的变更日志新建本地状态,因为本地状态的所有数据都保存到了kafka中。如果集群中的一个任务失败,只要还有其他任务实例可用,就可以用其他实例来继续这个任务,因为Kafka有消费者的重平衡机制。
与Spring Cloud Stream整合
依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream-binder-kafka-streams</artifactId>
</dependency>
流处理类:
@EnableBinding(KafkaStreamsProcessor.class)
public class WordCountProcessor {
@StreamListener("input")
@SendTo("output")
public KStream<?, WordCountDto> process(KStream<Object, String> input) {
return input
.flatMapValues(value -> Arrays.asList(value.toLowerCase().split("\\W+")))
.map((key, value) -> new KeyValue<>(value, value))
.groupByKey(Serialized.with(Serdes.String(), Serdes.String()))
.windowedBy(TimeWindows.of(30000))
.count(Materialized.as("WordCounts-1"))
.toStream()
.map((key, value) -> new KeyValue<>(null, new WordCountDto(key.key(), value, new Date(key.window().start()), new Date(key.window().end()))));
}
}
配置文件:
spring.cloud.stream.kafka.streams.binder:
brokers: 192.168.195.88
applicationId: word-count
configuration:
default.key.serde: org.apache.kafka.common.serialization.Serdes$StringSerde
default.value.serde: org.apache.kafka.common.serialization.Serdes$StringSerde
commit.interval.ms: 1000
serdeError: logAndFail
spring.cloud.stream.bindings.output:
destination: wordCountOutput
spring.cloud.stream.bindings.input:
destination: wordCountInput


相关推荐
本文介绍了KafkaStream的架构和并发模型,同时分析了KafkaStream如何解决流式计算的关键问题。一般流式计算会与批量计算相比较在流式计算模型中,输入是持续的,在时间上是无界的。这也就意味着,永远拿不到全量数据...
flink搭配kafka,构建流式采集框架,提供了docker部署方式脚本和k8s多副本方式部署脚本
01. Kafka基础回顾 02. Kafka的两种模式 03. Kafka的序列化 04. Kafka Connector 05. Kafka常用指令 06. Kafka监控 07. Kafka流式处理
推出 KSQL 是为了降低流式处理的门槛,为处理 Kafka 数据提供简单而完整的可交互式 SQL 接口。KSQL 目前可以支持多种流式操作,包括聚合(aggregate)、连接(join)、时间窗口(window)、会话(session),等等。
Kafka是一个分布式流处理平台,被广泛用于构建实时数据管道,允许你流式地处理数据。 Kafka的主要特性包括: 1.分布式:Kafka是分布式的,可以跨多台机器同时存储和处理数据。 2.提供消息系统:Kafka可以作为消息中间件...
在示例代码中 `kafkaParams` 封装了 Kafka 消费者的属性,这些属性和 Spark Streaming 无关,是 Kafka 原生 API 中就有定义的。其中服务器地址、键序列化器和值序列化器是必选的,其他配置是可选的。 Spark ...
本套代码是2019年大数据实时交易监控系统,包括技术有flume+spark streaming+kafka流式处理数据等一线互联网大数据分析平台核心内容,欢迎收藏!
Kafka Streams是Kafka提供的一个用于构建流式处理程序的Java库,它与Storm、Spark等流式处理框架不同,是一个仅依赖于Kafka的Java库,而不是一个流式处理框架。除Kafka之外,Kafka Streams不需要额外的流式处理集群...
KSQL是一个用于Apache kafka的流式SQL引擎,KSQL降低了进入流处理的门槛,提供了一个简单的、完全交互式的SQL接口,用于处理Kafka的数据,可以让我们在流数据上持续执行 SQL 查询,KSQL支持广泛的强大的流处理操作,...
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。...此外,Kafka可以通过Kafka Connect连接到外部系统(用于数据输入/输出),并提供了Kafka Streams——一个Java流式处理库 (计算机)。
本书以Apache Kafka和MapRStreams为例,重点讲解如何确定使用流数据的时机、如何为多用户系统设计流式架构、为什么要求消息传递层具备某些特定功能,以及为什么需要微服务,并且描述了目前最符合流式设计需求的消息...
本资源中的源码都是经过本地编译过可运行的,下载后按照文档配置好环境就可以运行。资源项目的难度比较适中,内容都是经过助教老师审定过的,应该能够满足学习、使用需求,如果有需要的话可以放心下载使用。...
Kafka是最初由Linkedin公司开发,是一个分布式、支持分区的(partition)、多副本的(replica),基于zookeeper协调的分布式消息系统,它的最大的特性就是可以实时的处理大量数据以满足各种场景需求:比如基于hadoop...
同时,本书还对Kafka的设计原理及其流式处理组件进行了较深入的探讨,并给出了翔实的案例。 《Apache Kafka实战》共分为10章:第1章全面介绍消息引擎系统以及Kafka的基本概念与特性,快速带领读者走进Kafka的世界;...
Apache Kafka是一个开源的流处理平台,设计用于构建实时数据管道和流式应用。它允许发布和订阅记录流,类似于消息队列或企业消息系统。然而,Kafka被设计为一个分布式系统,具有高度的可扩展性、容错性和持久性,...
Apache Kafka是一个分布式发布 - 订阅消息系统和一个强大的队列,可以处理大量的数据,并使您能够将消息从一个端点传递到另一个端点。 Kafka适合离线和在线消息消费。 Kafka消息保留在磁盘上,并在群集内复制以防止...
这些数据通常被用于实时分析、日志收集、监控和流式处理等场景。 Kafka的核心概念 Producer:生产者,即向Kafka topic发布消息的客户端。 Consumer:消费者,即从Kafka topic订阅并消费消息的客户端。 Topic:主题...
项目开发 系统设计 Spark 机器学习 大数据 算法 源码 项目开发 系统设计 Spark 机器学习 大数据 算法 源码 项目开发 系统设计 Spark 机器学习 大数据 算法 源码 项目开发 系统设计 Spark 机器学习 大数据 算法 源码 ...