浏览 429 次
|
锁定老帖子 主题:MYSQL 使用技巧总结,超全总结
精华帖 (0) :: 良好帖 (0) :: 新手帖 (0) :: 隐藏帖 (0)
|
|
|---|---|
| 作者 | 正文 |
|
发表时间:2021-12-17
最近给新来的开发做一次数据库基础培训,特意写了这篇文章。
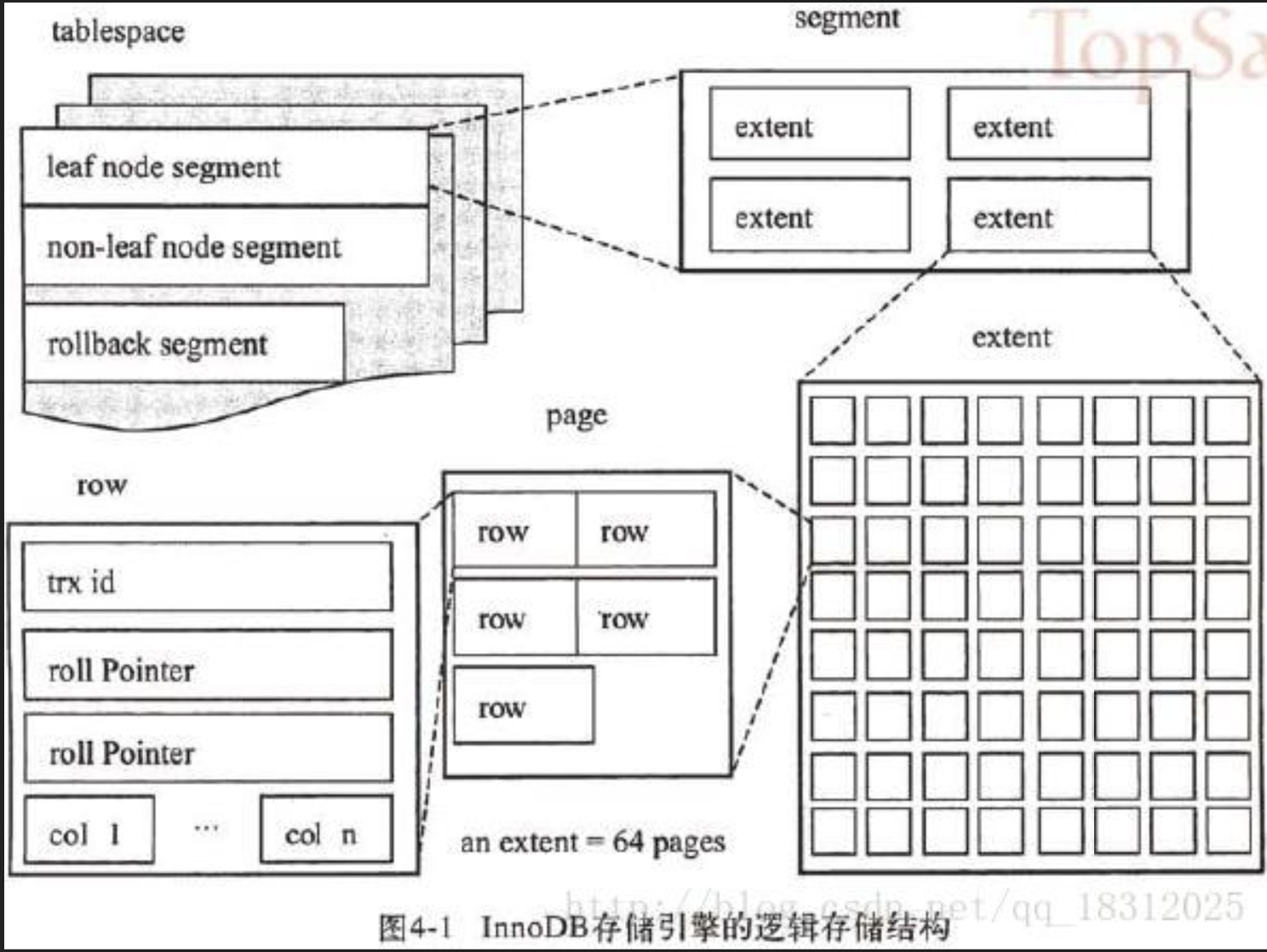
有些内容也参考了其它一些大神的举例。大多都是自己对Mysql使用时的一些心得,总结出来后感觉也应该分享给更多人,因此贴了过来 正文:MYSQL 使用技巧总结 1. 索引使用小技巧 1、联合索引最左原则,例如(联合索引:a, b, c): where a = 3, 使用a where a = 3, b = 5 使用a, b where a = 3, b = 4, c = 5 使用a, b, c where a = 3, c = 4 使用a where a = 3, b > 4, c = 5 使用a, b(c不能使用在范围条件之后) 反例: KEY \`idx_test\` (\`user_id\`,\`batch_id\`,\`coupon_code\`) USING BTREE SELECT * FROM coup_coupon WHERE user_id = 122121 and batch_id > 10017 and coupon_code = 'vmKnC61y1ns260Gc94o09Q36JV02O50t'; 结果:不管有没有第三个条件,扫描行都是169行 再创建一个索引:KEY \`idx_coup_code\` (\`coupon_code\`),此时会走\`idx_coup_code\`,引擎会自动选择最优方式 2、数据量小的情况(< 2000条数据) InnoDB必定会有一个聚簇索引,且一个表的数据是一个独立文件 所以:2000条数据是连续的,虽然是全表扫描。但实际上磁头只需要一个回合就能读出所有数据 1、单表查询走全表扫描反而比索引更快 2、如果是关联查询,左右条件字段还是要走索引快 3、前缀索引:索引创建不能过大,大字段或者text字段要指定索引长度 根据实际情况获取占比,一般情况“选择性”在0.6到0.7都可以接受。值越高越好,要结合索引取长进行综合判断 选择性:“索引列”取前几位、再去重后的总量占比 创建:ALTER TABLE shop_wechat_config ADD KEY idx_app_secret(app_secret(8)); 占比测试: SELECT 1.0*count(distinct left(coupon_code, 4))/count(*) FROM coup_coupon; -> 0.46524 SELECT 1.0*count(distinct left(coupon_code, 5))/count(*) FROM coup_coupon; -> 0.95477 结果:取4位时“选择性”只有0.46,但是取5位达到了0.954,所以这个表的索引其实可以直接使用5位前缀索引 占比测试2: SELECT 1.0*count(distinct left(open_id, 9))/count(*) FROM crm_user_third_0; -- 0.13915 SELECT 1.0*count(distinct left(open_id, 10))/count(*) FROM crm_user_third_0; -- 0.82227 SELECT 1.0*count(distinct left(open_id, 11))/count(*) FROM crm_user_third_0; -- 0.99124 缺点:MySQL不能在 ORDER BY 或 GROUP BY 中使用前缀索引,也不能把它们用作覆盖索引(Covering Index) 4、使用“覆盖索引” 定义:如果查询的列恰好是索引列的一部分,那查询只需要找到索引文件后直接返回,不需要回行到磁盘再找数据 比如:SELECT batch_id, batch_name, coupon_id, third_code, redeem_code FROM coup_coupon WHERE batch_id = 10086; 索引:batch_id,batch_name 此时,查询的字段为都包含在“索引文件”中,就不会“回表”把整条数据查出来再取name,而是直接返回“索引文件” 5、减少索引量: 1、使用联合索引,根据大多数使用场景,有些索引可以合并成联合索引 2、底频次的索引,可以考虑替代方案(代码中处理、全表扫描) 6、联合索引 - 前后顺序 规则1:因为有最左原则,从单个的使用场景上考虑,有的单个使用频次比较高的,我们放最前端 规则2:不考虑单个使用,把过滤数据越多的,越靠前放 反例: KEY \`idx_status_batch_id\` (\`status\`,\`batch_id\`) USING BTREE 基本永远也用不到,也不知道谁创建的 说明:MySql发现命中率大于30%时,就会优化成全表扫描 7、索引自动优化 索引默认命中率大于30%时、或者磁盘来回扫描多次,会认为性能比全表扫描还慢 PS:机械硬盘中,按索引搜索,索引的最小单位是页,而根据索引的长久使用(索引分裂、索引合并),会导致页的顺序分散在磁盘的不同位置。 比如:走索引会对整个盘扫描1000次,而全表扫描 反例: SELECT * FROM coup_coupon WHERE coupon_code != '4400A940h'; 命中率 > 99.99% SELECT * FROM coup_coupon_use WHERE status = 3(已使用); 命中率 > 80% PS:索引类型在某些场景下,也会自动优化。比如:使用B-Tree,但是数据重复率非常底,Mysql可能会选择重建索引,自动改为Hash索引 8、避免冗余索引 会增加索引负担 比如:KEY1 \`idx_batch_id_user_id_coup_code\`,KEY2 \`idx_batch_id\`,KEY2完全是冗余的 9、Order By - 使用问题: Order By子句的顺序完全一致,并且所有列的排序方向都一样时,MySQL才能够使用索引来对结果做排序。如果查询需要关联多张表,则只有当ORDER BY 子句引用的字段全部为第一个表时,才能使用索引做排序。ORDER BY子句和查找型查找的限制是一样的:需要满足索引的最左前缀的要求,否则无法利用索引排序。 10、Select * 问题 性能:从性能上来讲,并无区别。 主要区别: 1、磁盘IO:如果只需要其中的部分数据,则指定字段查询是最快的,减少磁盘读取量(虽然不多) 2、网络IO:如果有无用数据,增加内部系统的网络(真实发生过的问题,大表的一条数据就有1K,结果查询几万条数据,传输量达到了几十上百兆) 3、回表查询:如果需要的数据刚好都有索引,则可以直接返回索引文件内容,磁盘不会再根据索引地扯进行扫描 4、扩展性:如果使用Select *,增加、删除列时,会影响到代码 2. 函数失效 1、查询字段中使用,不会失效,但是消耗CPU和内存 SELECT coupon_id, IFNULL(update_time, 0), (batch_id * 10) bid2, CONCAT(user_id, "_", "a") FROM coup_coupon WHERE batch_id = 142; 2、查询条件中使用函数索引失效 反例1 - 函数: SELECT * FROM coup_coupon WHERE batch_id + 1 = 22 反例2 - 运算符号: SELECT * FROM coup_coupon WHERE batch_id + 1 = 22 SELECT * FROM coup_coupon WHERE batch_id * 2 = 22 SELECT * FROM coup_coupon WHERE batch_id = (plat + 132); 3. 查询条件中使用关键词 1:OR 条件 条件里只要有一个OR的条件没加索引,索引就会失效 2:LIKE 条件 只能从左往右模糊匹配,不支持左边模糊 反例:LIKE '%ABC' 正例:LIKE 'ABC%' 3:IN 条件, 4:NOT IN 条件, 5:!= 条件 普通索引:SELECT * FROM app WHERE name != "duan"; -- 不会走索引 主键索引:SELECT * FROM app WHERE app_id != 18; -- 会走索引,前提命中率 < 30% 6:>或< 条件 如果是聚集索引或普通索引是整数类型,是会走索引的。反之则会失效 创建聚集索引 - InnoDB表必定有聚簇索引: 1、手动定义(主键索引) 2、自动:找出所有的唯一索引,根据创建顺序往下取。 然后此索引列为非null。否则找下一个,如果一直找不到,则会隐式定义一个主键来作为聚簇索引 PS:聚集索引尽量使用有顺序的生成方案,避免索引页的分裂 4. 设置非空Null - 索引 1、Count函数会漏掉null值 例如: # 总共:41242行 SELECT count(update_time) FROM coup_coupon; # 41160行 SELECT count(update_time) FROM coup_coupon WHERE update_time is null; # 0行 SELECT * FROM coup_coupon WHERE update_time is null; # 82行 2、对null做算术运算的结果都是null 3、不要使用is not null,索引失效 4、null 比空字符串需要更多的存储空间 5、排序(排序无法走到索引) 6、5.6之后,null值也可以走索引(不过应该是mysql做了特殊处理,这样消耗CPU和内存) 为什么索引列无法存储Null值? 索引是有序的。NULL值进入索引时,无法确定其应该放在哪里() 数据“页”:有上一页、下一页,Null值是**不确定**的一个数据,根本不知道放到哪个位置(页->叶子节点)合适。 PS:新版的5.7引擎好像是做了特殊处理,null值搜索可以走索引,不过是有代价的 5. 一定要定义主键,且使用自增ID 在InnoDB中,使用自增ID可以避免页分裂问题 如果没手动指定聚簇索引,自动找了一个UUID的唯一索引来当聚簇索引,那很容易就引起页分裂 页分裂: 1、表字段大小是已知的,所以一页能放多少条数据,也是固定的 2、比如,页5、6、7全部都存满了,此时插入新数据,根据主键索引分配到页6,然后6满了,顺序放入页7,7也满了,此时会进行分裂。生成一个新的页,再把5、7页的数据重新安排 代价: 1、相邻两页的数据列重新记录位置 2、数据列分散(严重) 解决办法: 1、如果有删除的数据,则有可能在页合并的时候挪回去(数据库动处理) 2、用OPTIMIZE重新整理表(极慢),比如:OPTIMIZE TABLE bs_brand; PS: 每个表有一个ibd文件 文件组成说明:表 -> 段(关联索引) -> 区(1024KB) -> 页(16KB)-> 行(>=2,根据数据大小自动判断)-> 4簇 磁盘:1簇 = 8扇区 = 4KB,1扇区 = 512B InnoDB要求页至少要有两个行,因此可以算出行的大小最多为8KB 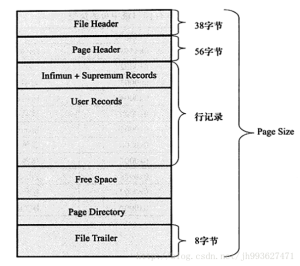
6. InnoDB的主键ID不能被修改 千万不要改主键ID:很容易就页分裂 7. 尽量不要物理删除数据 页合并: 当页中删除的记录达到MERGE_THRESHOLD(默认页体积的50%,1%-50%)(空洞率)时,InnoDB会开始寻找最靠近的页(前或后)看看是否可以将两个页合并以优化空间使用 如果能合成一个,就会合并到前一页上去,后一页空出来给新插入的数据使用(主键的排序就乱了,顺序取数时代价更大) MERGE_THRESHOLD(合并阈值): 1、表上使用: ALTER TABLE coup_coupon COMMENT='MERGE_THRESHOLD=40'; 2、索引上使用: CREATE INDEX id_index ON coup_coupon (coupon_id) COMMENT 'MERGE_THRESHOLD=40'; 例如:A/B/C分别有10条数据,先把A/C删除4条,再把B删除9条,此时会进行页合并,页B合并后就是空 如果是自增的表,页B就会独立出来,用于存放最新的数据(它是物理磁盘) 如果有删除:则需要“重建表”(随机主键、删除操作) 方式1: 命令:optimize table coup_coupon 说明:被删除的记录被保持在链接清单中,后续的INSERT操作会重新使用旧的记录位置 优点:速度快 缺点1:对于自增ID来说,新数据使用原来的位置,聚集索引不是连续的,有可能查询两条数据时,会进行磁盘的来回扫描。 缺点2:不支持InnoDB(会提示:Table does not support optimize, doing recreate + analyze instead -> 也就是方案3) 方案2: 命令1:alter table coup_coupon engine = InnoDB(重建表,解决空洞) 命令2:analyze table coup_coupon(对表的索引信息做重新统计,会加MDL读锁) 方案3: shell脚本 查看碎片: SELECT t.TABLE_SCHEMA, t.TABLE_NAME, t.TABLE_ROWS, t.DATA_LENGTH, t.INDEX_LENGTH, concat(round(t.DATA_FREE / 1024 / 1024, 2), 'M') AS datafree FROM information_schema.tables t WHERE t.TABLE_SCHEMA = 'test' AND table_name like 'coup_coupon%'; 8. 类型转换 举例1 - 普通索引(varchar): 走索引:SELECT * FROM coup_coupon WHERE coupon_code = '999988888'; 不走索引:SELECT * FROM coup_coupon WHERE coupon_code = 999988888; 执行计划:1 SIMPLE coup_coupon ALL idx_coup_code 40891 10.00 Using where 举例2 - 主键索引(int): 走索引:SELECT * FROM coup_coupon WHERE coupon_id = 112673; 走索引:SELECT * FROM coup_coupon WHERE coupon_id = '112673'; 举例3 - 普通索引(int) 走索引:SELECT * FROM coup_coupon WHERE batch_id = 99998; 走索引:SELECT * FROM coup_coupon WHERE batch_id = '99998'; 举例4 - 时间 走索引:SELECT * FROM coup_coupon WHERE create_time = '2020-08-02 00:00:00'; 走索引:SELECT * FROM coup_coupon WHERE create_time = '2020-08-02'; 9.字符集 当多个表关联查询时: 两个表的字符集不一至,索引失效(varchar类型)。导致笛卡尔集 解决办法: 1、重新创建表,都使用同样的字符集 2、在查询语句中进行类型转换 ON CONVERT (act.batch_name USING UTF8) = coup.batch_name 反例: SELECT * FROM test.coup_coupon c left join test.coup_batch b on b.batch_name = c.batch_name WHERE c.coupon_id = 112695; 10. 能用代码解决的,就不要在数据库中处理 1、排序: 1、消耗CPU 2、没用好可能会导致索引失效 正例:根据主键排序 反例:排序顺序不对、排序中有非索引字段 2、运算: MySql函数能不用就不用,任何函数都能在Java代码中实现 如: 函数计算:count,SUM等等 运算符:+-*/ 3、合并、组装:关联查询,内部查询,零时表 4、减少IO 磁盘IO: 减少回表查询:只查有用的,如果索引文件已经包含了需要的数据,就不要查询多余的数据导致回表 索引文件优化(索引本身不能太大、太多,不然失去了索引的意义) 定期整理表(让数据可以连续,时间久了数据太分散),类似碎片整理 网络IO: 减少查询返回的数据总条数 不必要的字段不查询(SELECT *) 反例: 同时消耗CPU(函数、+-运算符),内存(零时表)、IO SELECT *,@rownum:=@rownum+1 AS rownum,@pa pa1, IF(@pa=ff.userid,@rank:=@rank+1,@rank:=1) AS rank, @pa:=ff.userid pa2 FROM ( SELECT loanid, userid, realName, investCount, investOrder FROM push_server_loan_investor ORDER BY userid ASC, investTime DESC ) ff, ( SELECT @rank:=0,@rownum:=0,@pa=NULL ) tt; 13. 其它 执行计划: 1、Extra = Using temporary 查询有使用临时表,一般出现于排序,分组和多表 join 的情况,查询效率不高,建议优化 2、Extra = Using filesort 表示 MySQL 需额外的排序操作, 不能通过索引顺序达到排序效果,非常消耗CPU 声明:ITeye文章版权属于作者,受法律保护。没有作者书面许可不得转载。
推荐链接
|
| 返回顶楼 | |
