
Hive 的元数据信息通常存储在关系型数据库中,常用MySQL数据库作为元数据库管理。
1. 版本表
i) VERSION -- 查询版本信息
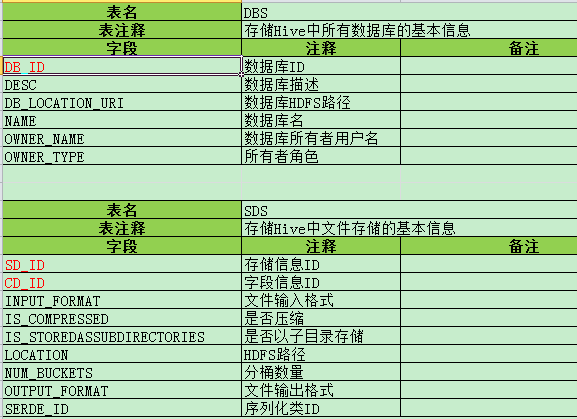
2. 数据库、文件存储相关
i) DBS -- 存储Hive中所有数据库的基本信息
ii) SDS -- 存储Hive中文件存储的基本信息
3. 表、视图相关
i) TBLS -- 存储Hive表、视图、索引表的基本信息
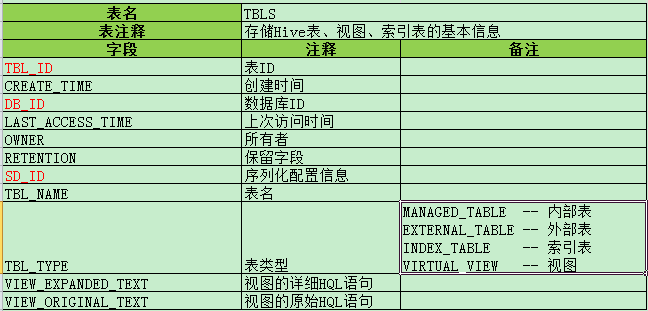
简要说明:1. 内部表与外部表的区别, 外部表 drop table 后,只删除元数据信息,数据文件还在。但是内部表 drop table 后,元数据和数据文件都会删除。
2. INDEX_TABLE : 创建索引后,Hive会单独生成一个物理表,存储索引信息和数据。
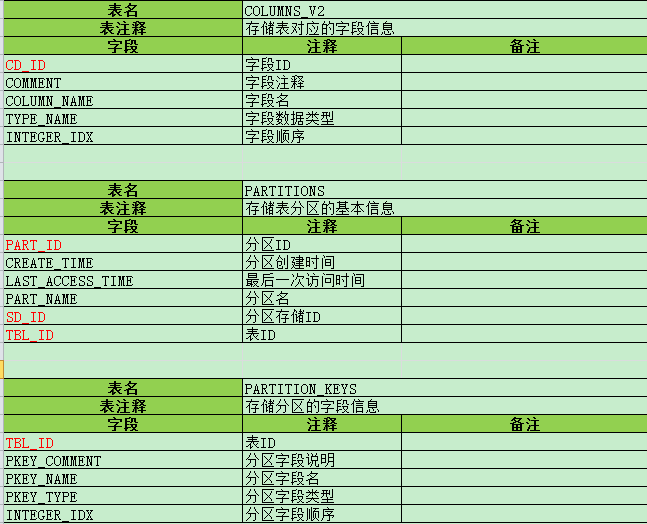
4. 列、分区相关
i) COLUMNS_V2 -- 存储表对应的字段信息
ii) PARTITIONS -- 存储表分区的基本信息
iii) PARTITION_KEYS -- 存储分区的字段信息
-- 收集统计信息
---====================
Impala 仅仅能部分利用Hive的统计信息, 要想得到好的执行效率, impala需要收集统计信息.
1. 检查统计信息
show table stats table_name; --显示表和分区级别的统计信息.
如果返回第一列 #Rows 值-1, 表名还没有收集过统计信息.
show column stats table_name ; --显示列级别的统计信息.
2. 收集统计信息
Impala 的compute stats 一条命令同时采集表和字段两种信息, 使用起来非常方便.
它增量和全量两种写法, 在从未收集过统计信息的前提下, 并且数量一致的情况下, 使用COMPUTE STATS命令要比COMPUTE INCREMENTAL STATS速度更快. 所以对于非分区表, 推荐使用COMPUTE STATS.
COMPUTE STATS table_name ; -- 对于非分区表, 推荐使用COMPUTE STATS, 速度更快
COMPUTE INCREMENTAL STATS table_name ;--对于分区表, 推荐使用COMPUTE INCREMENTAL STATS, 速度更快一些.
如果table通过Hive增加了分区, 需要先进行refresh, 然后增量收集统计信息.
REFRESH table_name;
COMPUTE INCREMENTAL STATS table_name;
3. 删除统计信息
DROP STATS table_name
DROP INCREMENTAL STATS table_name PARTITION (key_col1=val1 [, key_col2=val2...])]
hive里如何快速查看表中有多少记录数
直接从Mysql里查询
mysql> use hive
select * from TBLS where TBL_NAME='call_center';
mysql> select a.TBL_ID, a.TBL_NAME, b.PARAM_KEY, b.PARAM_VALUE from TBLS as a join TABLE_PARAMS as b where a.TBL_ID = b.TBL_ID and TBL_NAME="web_sales" and PARAM_KEY="numRows";
+--------+-----------+-----------+-------------+
| TBL_ID | TBL_NAME | PARAM_KEY | PARAM_VALUE |
+--------+-----------+-----------+-------------+
| 382 | web_sales | numRows | -1 |
| 406 | web_sales | numRows | 144002668 |
+--------+-----------+-----------+-------------+



相关推荐
Hive运维中通常会用到操作元数据,这里提供了常用的sql语句
Hive4——HIVE元数据库.pdf 学习资料 复习资料 教学资源
Hive4--HIVE元数据库.pdf 学习资料 复习资料 教学资源
可以从hive元数据生成建表语句的资源。包括表结构、分区等信息
apache-hive-1.2.1-bin.tar.gz mysql-connector-java-5.1.6-bin 用于安装Hive并使用MySQL作为元数据库
查数据库单个表大小 查数据库所有表大小
jdbc连接hive数据库的jar包.整理可用合集.
Idea连接Hive,Idea连接Hive,Idea连接Hive,Idea连接Hive,Idea连接Hive
可能对于很多编程员来说注册表HIVE数据库都是个头痛的难题,这篇源代码或许有所帮助
使用dbeaver或者其他数据库管理工具连接hive时使用到的驱动
通过shell脚本,批量把一个库下面的表结构全部导出,在开发环境执行过。
环境启动 hadoop hive2元数据库 sql导入 导入hivesql脚本,修改application.yml 启动主程序 HadoopApplication 基于Hadoop Hive健身馆可视化分析平台项目源码+数据库文件.zip启动方式 环境启动 hadoop hive2元数据库...
SpagoBI集成Hive数据库:此文档主要介绍集成步骤,不包含Hive数据库部分。在做集成时Hive数据库老是不稳定,导致报表出问题。针对这种情况小伙伴可以写个简单的JDBC连接 循环测试一下。
hive1.2.1用mysql作为元数据库搭建DT-大数据 大数据学习可以了解一下
本资源包含Hive数据库连接所需要的驱动,为了方便我们在用第三方工具链接Hive数据库的时候,解决驱动的问题,而自己在下载的时候,资源又不是很好找,所以在这里打包分享给大家。不过大家在下载使用的时候,还需要...
该配置文件用于Hive数据库的部署,涵盖了嵌入、本地和远程部署的配置信息。包括Hive的基本配置、元数据存储、Hive服务器等方面的设置,以满足不同部署场景的需求。 适用人群: 数据工程师、数据科学家和数据库管理员 ...
只需要一个jar包,不需要大量的hadoop相关jar包
由于公司要把oracle 数据库迁移到hive ,hbase 环境,特建议使用kettle做数据迁移,调试3个小时,终于调试成功,顺手写了个配置文档。
连接hive数据库的驱动