- жµПиІИ: 166293 жђ°
- жАІеИЂ:

- жЭ•иЗ™: дЄКжµЈ
-

жЦЗзЂ†еИЖз±ї
з§ЊеМЇзЙИеЭЧ
- жИСзЪДиµДиЃѓ ( 0)
- жИСзЪДиЃЇеЭЫ ( 0)
- жИСзЪДйЧЃз≠Ф ( 0)
е≠Шж°£еИЖз±ї
- 2017-07 ( 1)
- 2014-12 ( 1)
- 2014-08 ( 2)
- жЫіе§Ъе≠Шж°£...
жЬАжЦ∞иѓДиЃЇ
-
jiangyeqtпЉЪ
е•ље•љзЪДжЄ©дє†дЇЖдЄАйБНпЉМиЃ≤зЪДйЭЮеЄЄзЪДеИ∞дљН
SessionзЪДеОЯзРЖ -
JAVAйЭЩйЭЩпЉЪ
ињЩжШѓдїАдєИеХКпЉЯжЬЙж≤°жЬЙжЇРз†БпЉЯзЬЛдЄНжЗВиѓґпЉБ
еЉАжЇРж°ЖжЮґPushletеЕ•йЧ® -
colinzhyпЉЪ
иЃ≤зЪДеЊИжЈ±еИїпЉМе≠¶дє†дЇЖ
SessionзЪДеОЯзРЖ -
жШФйЫ™дЉЉиК±пЉЪ
...
Map-iterator -
дЄНзЫЄдњ°зЬЉж≥™пЉЪ
жБ©пЉМеЊИе•љпЉМе§Ъи∞Ґ
.sccжЦЗдїґжШѓеБЪдїАдєИзФ®зЪДпЉЯ
SessionзЪДеОЯзРЖ
- еНЪеЃҐеИЖз±їпЉЪ
- tomcat/weblogic/jboss
 
еЉХи®А
¬†¬†¬† еЬ®webеЉАеПСдЄ≠пЉМsessionжШѓдЄ™йЭЮеЄЄйЗНи¶БзЪДж¶ВењµгАВеЬ®иЃЄе§ЪеК®жАБзљСзЂЩзЪДеЉАеПСиАЕзЬЛжЭ•пЉМsessionе∞±жШѓдЄАдЄ™еПШйЗПпЉМиАМдЄФеЕґи°®зО∞еГПдЄ™йїСжіЮпЉМдїЦеП™йЬАи¶Бе∞ЖдЄЬи•њеЬ®еРИйАВзЪДжЧґжЬЇжФЊињЫињЩдЄ™жіЮйЗМпЉМз≠ЙйЬАи¶БзЪДжЧґеАЩеЖНжККдЄЬи•њеПЦеЗЇжЭ•гАВињЩжШѓеЉАеПСиАЕеѓєsessionжЬАзЫіиІВзЪДжДЯеПЧпЉМдљЖжШѓйїСжіЮйЗМзЪДжЩѓи±°жИЦиАЕиѓіsessionеЖЕйГ®еИ∞еЇХжШѓжАОдєИеЈ•дљЬзЪДеСҐпЉЯељУзђФиАЕеРСиЇЂиЊєзЪДдЄАдЇЫеРМдЇЛжИЦжЬЛеПЛйЧЃеПКзЫЄеЕ≥зЪДжЫіињЫдЄАж≠•зЪДзїЖиКВжЧґпЉМеЊИе§ЪдЇЇеЊАеЊАи¶БдєИеРЂз≥КеЕґиЊЮи¶БдєИдЄїиІВиЗЖжЦ≠пЉМжЙАи∞УзЯ•еЕґзДґиАМдЄНзЯ•еЕґжЙАдї•зДґгАВ
зђФиАЕзФ±ж≠§жГ≥еИ∞еЊИе§ЪеЉАеПСиАЕпЉМеМЕжЛђжИСиЗ™еЈ±пЉМжѓПжѓПйГљжШѓзЇ†зЉ†дЇОж°ЖжЮґзФЪиЗ≥дЇМжђ°еЉАеПСеє≥еП∞дєЛдЄКпЉМиАМеѓєдЇОеЕґдЄЛзЪДж†ЄењГеТМеЯЇз°АзЯ•дєЛзФЪе∞СпЉМжИЦиАЕжЬЙењГжЧ†еКЫзФЪиЗ≥жѓЂдЄНеЕ≥ењГпЉМе∞СдЇЖйАРжЬђжЇѓжЇРзЪДз≤Њз•ЮпЉМжѓПењЖеПКж≠§пЉМжЧ†дЄНжГ≠жДІгАВжЫЊзїПеЃЮзО∞ињЗдЄАдЄ™зЃАеНХзЪДHttpServerпЉМдљЖељУжЧґзФ±дЇОзЯ•иѓЖеВ®е§ЗеТМжЧґйЧізЪДйЧЃйҐШпЉМж≤°жЬЙиАГиЩСеИ∞sessionињЩеЭЧпЉМдЄНињЗињСжЬЯеЬ®еЈ•дљЬдєЛдљЩзњїзЬЛдЇЖдЄАдЇЫиµДжЦЩпЉМеєґињЫи°МдЇЖзЫЄеЕ≥еЃЮиЈµпЉМе∞ПжЬЙжЙАеЊЧпЉМжЬђзЭАеИЖдЇЂзЪДз≤Њз•ЮпЉМжИСе∞ЖеЬ®жЬђжЦЗдЄ≠е∞љеПѓиГљеЕ®йЭҐеЬ∞е∞ЖдЄ™дЇЇеѓєдЇОsessionзЪДзРЖиІ£е±ХзО∞зїЩиѓїиАЕпЉМеРМжЧґе∞љжИСжЙАиГљеЬ∞иЃЇеПКдЄАдЇЫзЫЄеЕ≥зЪДзЯ•иѓЖпЉМдї•жЬЯиѓїиАЕеЬ®еѓєsessionжЬЙжЙАдЇЖиІ£зЪДеРМжЧґдєЯиГљеП¶жЬЙжЙАжВЯпЉМж≠£жЙАи∞УжОИдЇЇдї•жЄФгАВ
SessionжШѓдїАдєИ
¬†¬†¬† SessionдЄАиИђиѓСдљЬдЉЪиѓЭпЉМзЙЫжі•иѓНеЕЄеѓєеЕґзЪДиІ£йЗКжШѓињЫи°МжЯРжіїеК®ињЮзї≠зЪДдЄАжЃµжЧґйЧігАВдїОдЄНеРМзЪДе±ВйЭҐзЬЛеЊЕsessionпЉМеЃГжЬЙзЭАз±їдЉЉдљЖдЄНеЕ®зДґзЫЄеРМзЪДеРЂдєЙгАВжѓФе¶ВпЉМеЬ®webеЇФзФ®зЪДзФ®жИЈзЬЛжЭ•пЉМдїЦжЙУеЉАжµПиІИеЩ®иЃњйЧЃдЄАдЄ™зФµе≠РеХЖеК°зљСзЂЩпЉМзЩїељХгАБеєґеЃМжИРиі≠зЙ©зЫіеИ∞еЕ≥йЧ≠жµПиІИеЩ®пЉМињЩжШѓдЄАдЄ™дЉЪиѓЭгАВиАМеЬ®webеЇФзФ®зЪДеЉАеПСиАЕеЉАжЭ•пЉМзФ®жИЈзЩїељХжЧґжИСйЬАи¶БеИЫеїЇдЄАдЄ™жХ∞жНЃзїУжЮДдї•е≠ШеВ®зФ®жИЈзЪДзЩїељХдњ°жБѓпЉМињЩдЄ™зїУжЮДдєЯеПЂеБЪsessionгАВеЫ†ж≠§еЬ®и∞ИиЃЇsessionзЪДжЧґеАЩи¶Бж≥®жДПдЄКдЄЛжЦЗзОѓеҐГгАВиАМжЬђжЦЗи∞ИиЃЇзЪДжШѓдЄАзІНеЯЇдЇОHTTPеНПиЃЃзЪДзФ®дї•еҐЮеЉЇwebеЇФзФ®иГљеКЫзЪДжЬЇеИґжИЦиАЕиѓідЄАзІНжЦєж°ИпЉМеЃГдЄНжШѓеНХжМЗжЯРзІНзЙєеЃЪзЪДеК®жАБй°µйЭҐжКАжЬѓпЉМиАМињЩзІНиГљеКЫе∞±жШѓдњЭжМБзКґжАБпЉМдєЯеПѓдї•зІ∞дљЬдњЭжМБдЉЪиѓЭгАВ
дЄЇдїАдєИйЬАи¶Бsession
¬†¬†¬† и∞ИеПКsessionдЄАиИђжШѓеЬ®webеЇФзФ®зЪДиГМжЩѓдєЛдЄЛпЉМжИСдїђзЯ•йБУwebеЇФзФ®жШѓеЯЇдЇОHTTPеНПиЃЃзЪДпЉМиАМHTTPеНПиЃЃжБ∞жБ∞жШѓдЄАзІНжЧ†зКґжАБеНПиЃЃгАВдєЯе∞±жШѓиѓіпЉМзФ®жИЈдїОAй°µйЭҐиЈ≥иљђеИ∞Bй°µйЭҐдЉЪйЗНжЦ∞еПСйАБдЄАжђ°HTTPиѓЈж±ВпЉМиАМжЬНеК°зЂѓеЬ®ињФеЫЮеУНеЇФзЪДжЧґеАЩжШѓжЧ†ж≥ХиОЈзЯ•иѓ•зФ®жИЈеЬ®иѓЈж±ВBй°µйЭҐдєЛеЙНеБЪдЇЖдїАдєИзЪДгАВ
¬†¬†¬† еѓєдЇОHTTPзЪДжЧ†зКґжАБжАІзЪДеОЯеЫ†пЉМзЫЄеЕ≥RFCйЗМеєґж≤°жЬЙиІ£йЗКпЉМдљЖиБФз≥їеИ∞HTTPзЪДеОЖеП≤дї•еПКеЇФзФ®еЬЇжЩѓпЉМжИСдїђеПѓдї•жО®жµЛеЗЇдЄАдЇЫзРЖзФ±пЉЪ
1.¬†¬† иЃЊиЃ°HTTPжЬАеИЭзЪДзЫЃзЪДжШѓдЄЇдЇЖжПРдЊЫдЄАзІНеПСеЄГеТМжО•жФґHTMLй°µйЭҐзЪДжЦєж≥ХгАВйВ£дЄ™жЧґеАЩж≤°жЬЙеК®жАБй°µйЭҐжКАжЬѓпЉМеП™жЬЙзЇѓз≤єзЪДйЭЩжАБHTMLй°µйЭҐпЉМеЫ†ж≠§ж†єжЬђдЄНйЬАи¶БеНПиЃЃиГљдњЭжМБзКґжАБпЉЫ
2.¬†¬† зФ®жИЈеЬ®жФґеИ∞еУНеЇФжЧґпЉМеЊАеЊАи¶БиК±дЄАдЇЫжЧґйЧіжЭ•йШЕиѓїй°µйЭҐпЉМеЫ†ж≠§е¶ВжЮЬдњЭжМБеЃҐжИЈзЂѓеТМжЬНеК°зЂѓдєЛйЧізЪДињЮжО•пЉМйВ£дєИињЩдЄ™ињЮжО•еЬ®е§Іе§ЪжХ∞зЪДжЧґйЧійЗМйГље∞ЖжШѓз©ЇйЧ≤зЪДпЉМињЩжШѓдЄАзІНиµДжЇРзЪДжЧ†зЂѓжµ™иієгАВжЙАдї•HTTPеОЯеІЛзЪДиЃЊиЃ°жШѓйїШиЃ§зЯ≠ињЮжО•пЉМеН≥еЃҐжИЈзЂѓеТМжЬНеК°зЂѓеЃМжИРдЄАжђ°иѓЈж±ВеТМеУНеЇФдєЛеРОе∞±жЦ≠еЉАTCPињЮжО•пЉМжЬНеК°еЩ®еЫ†ж≠§жЧ†ж≥ХйҐДзЯ•еЃҐжИЈзЂѓзЪДдЄЛдЄАдЄ™еК®дљЬпЉМеЃГзФЪиЗ≥йГљдЄНзЯ•йБУињЩдЄ™зФ®жИЈдЉЪдЄНдЉЪеЖНжђ°иЃњйЧЃпЉМеЫ†ж≠§иЃ©HTTPеНПиЃЃжЭ•зїіжК§зФ®жИЈзЪДиЃњйЧЃзКґжАБдєЯеЕ®зДґж≤°жЬЙењЕи¶БпЉЫ
3.¬†¬† е∞ЖдЄАйГ®еИЖе§НжЭВжАІиљђеЂБеИ∞дї•HTTPеНПиЃЃдЄЇеЯЇз°АзЪДжКАжЬѓдєЛдЄКеПѓдї•дљњеЊЧHTTPеЬ®еНПиЃЃињЩдЄ™е±ВйЭҐдЄКжШЊеЊЧзЫЄеѓєзЃАеНХпЉМиАМињЩзІНзЃАеНХдєЯиµЛдЇИдЇЖHTTPжЫіеЉЇзЪДжЙ©е±ХиГљеКЫгАВдЇЛеЃЮдЄКпЉМsessionжКАжЬѓдїОжЬђиі®дЄКжЭ•иЃ≤дєЯжШѓеѓєHTTPеНПиЃЃзЪДдЄАзІНжЙ©е±ХгАВ
жАїиАМи®АдєЛпЉМHTTPзЪДжЧ†зКґжАБжШѓзФ±еЕґеОЖеП≤дљњеСљиАМеЖ≥еЃЪзЪДгАВдљЖйЪПзЭАзљСзїЬжКАжЬѓзЪДиУђеЛГеПСе±ХпЉМдЇЇдїђеЖНдєЯдЄНжї°иґ≥дЇОж≠їжЭњдєПеС≥зЪДйЭЩжАБHTMLпЉМдїЦдїђеЄМжЬЫwebеЇФзФ®иГљеК®иµЈжЭ•пЉМдЇОжШѓеЃҐжИЈзЂѓеЗЇзО∞дЇЖиДЪжЬђеТМDOMжКАжЬѓпЉМHTMLйЗМеҐЮеК†дЇЖи°®еНХпЉМиАМжЬНеК°зЂѓеЗЇзО∞дЇЖCGIз≠Йз≠ЙеК®жАБжКАжЬѓгАВ
иАМж≠£жШѓињЩзІНwebеК®жАБеМЦзЪДйЬАж±ВпЉМзїЩHTTPеНПиЃЃжПРеЗЇдЇЖдЄАдЄ™йЪЊйҐШпЉЪдЄАдЄ™жЧ†зКґжАБзЪДеНПиЃЃжАОж†ЈжЙНиГљеЕ≥иБФдЄ§жђ°ињЮзї≠зЪДиѓЈж±ВеСҐпЉЯдєЯе∞±жШѓиѓіжЧ†зКґжАБзЪДеНПиЃЃжАОж†ЈжЙНиГљжї°иґ≥жЬЙзКґжАБзЪДйЬАж±ВеСҐпЉЯ
ж≠§жЧґжЬЙзКґжАБжШѓењЕзДґиґЛеКњиАМеНПиЃЃзЪДжЧ†зКґжАБжАІдєЯжШѓжЬ®еЈ≤жИРиИЯпЉМеЫ†ж≠§жИСдїђйЬАи¶БдЄАдЇЫжЦєж°ИжЭ•иІ£еЖ≥ињЩдЄ™зЯЫзЫЊпЉМжЭ•дњЭжМБHTTPињЮжО•зКґжАБпЉМдЇОжШѓеЗЇзО∞дЇЖcookieеТМsessionгАВ
еѓєдЇОж≠§йГ®еИЖеЖЕеЃєпЉМиѓїиАЕжИЦиЃЄдЉЪжЬЙдЄАдЇЫзЦСйЧЃпЉМзђФиАЕеЬ®ж≠§еЕИи∞ИдЄ§зВєпЉЪ
1.¬†¬† жЧ†зКґжАБжАІеТМйХњињЮжО•
еПѓиГљжЬЙдЇЇдЉЪйЧЃпЉМзО∞еܮ襀府ж≥ЫдљњзФ®зЪДHTTP1.1йїШиЃ§дљњзФ®йХњињЮжО•пЉМеЃГињШжШѓжЧ†зКґжАБзЪДеРЧпЉЯ
ињЮжО•жЦєеЉПеТМжЬЙжЧ†зКґжАБжШѓеЃМеЕ®ж≤°жЬЙеЕ≥з≥їзЪДдЄ§еЫЮдЇЛгАВеЫ†дЄЇзКґжАБдїОжЯРзІНжДПдєЙдЄКжЭ•иЃ≤е∞±жШѓжХ∞жНЃпЉМиАМињЮжО•жЦєеЉПеП™жШѓеЖ≥еЃЪдЇЖжХ∞жНЃзЪДдЉ†иЊУжЦєеЉПпЉМиАМдЄНиГљеЖ≥еЃЪжХ∞жНЃгАВйХњињЮжО•жШѓйЪПзЭАиЃ°зЃЧжЬЇжАІиГљзЪДжПРйЂШеТМзљСзїЬзОѓеҐГзЪДжФєеЦДжЙАйЗЗеПЦзЪДдЄАзІНеРИзРЖзЪДжАІиГљдЄКзЪДдЉШеМЦпЉМдЄАиИђжГЕеЖµдЄЛпЉМwebжЬНеК°еЩ®дЉЪеѓєйХњињЮжО•зЪДжХ∞йЗПињЫи°МйЩРеИґпЉМдї•еЕНиµДжЇРзЪДињЗеЇ¶жґИиАЧгАВ
2.¬†¬† жЧ†зКґжАБжАІеТМsession
¬†¬†¬† ¬†¬†¬† SessionжШѓжЬЙзКґжАБзЪДпЉМиАМHTTPеНПиЃЃжШѓжЧ†зКґжАБзЪДпЉМдЇМиАЕжШѓеР¶зЯЫзЫЊеСҐпЉЯ
¬†¬†¬† SessionеТМHTTPеНПиЃЃе±ЮдЇОдЄНеРМе±ВйЭҐзЪДдЇЛзЙ©пЉМеРОиАЕе±ЮдЇОISOдЄГе±Вж®°еЮЛзЪДжЬАйЂШе±ВеЇФзФ®е±ВпЉМеЙНиАЕдЄНе±ЮдЇОеРОиАЕпЉМеЙНиАЕжШѓеЕЈдљУзЪДеК®жАБй°µйЭҐжКАжЬѓжЭ•еЃЮзО∞зЪДпЉМдљЖеРМжЧґеЃГеПИжШѓеЯЇдЇОеРОиАЕзЪДгАВеЬ®дЄЛжЦЗдЄ≠зђФиАЕдЉЪеИЖжЮРServlet/JspжКАжЬѓдЄ≠зЪДsessionжЬЇеИґпЉМињЩдЉЪдљњдљ†еѓєж≠§жЬЙжЫіжЈ±еИїзЪДзРЖиІ£гАВ
CookieеТМSession
¬†¬†¬† дЄКйЭҐжПРеИ∞иІ£еЖ≥HTTPеНПиЃЃиЗ™иЇЂжЧ†зКґжАБзЪДжЦєеЉПжЬЙcookieеТМsessionгАВдЇМиАЕйГљиГљиЃ∞ељХзКґжАБпЉМеЙНиАЕжШѓе∞ЖзКґжАБжХ∞жНЃдњЭе≠ШеЬ®еЃҐжИЈзЂѓпЉМеРОиАЕеИЩдњЭе≠ШеЬ®жЬНеК°зЂѓгАВ
¬†¬†¬† й¶ЦеЕИзЬЛдЄАдЄЛcookieзЪДеЈ•дљЬеОЯзРЖпЉМињЩйЬАи¶БжЬЙеЯЇжЬђзЪДHTTPеНПиЃЃеЯЇз°АгАВ
cookieжШѓеЬ®RFC2109пЉИеЈ≤еЇЯеЉГпЉМ襀RFC2965еПЦдї£пЉЙйЗМеИЭ搰襀жППињ∞зЪДпЉМжѓПдЄ™еЃҐжИЈзЂѓжЬАе§ЪдњЭжМБдЄЙзЩЊдЄ™cookieпЉМжѓПдЄ™еЯЯеРНдЄЛжЬАе§Ъ20дЄ™CookieпЉИеЃЮйЩЕдЄКдЄАиИђжµПиІИеЩ®зО∞еЬ®йГљжѓФињЩдЄ™е§ЪпЉМе¶ВFirefoxжШѓ50дЄ™пЉЙпЉМиАМжѓПдЄ™cookieзЪДе§Іе∞ПдЄЇжЬАе§Ъ4KпЉМдЄНињЗдЄНеРМзЪДжµПиІИеЩ®йГљжЬЙеРДиЗ™зЪДеЃЮзО∞гАВеѓєдЇОcookieзЪДдљњзФ®пЉМжЬАйЗНи¶БзЪДе∞±жШѓи¶БжОІеИґcookieзЪДе§Іе∞ПпЉМдЄНи¶БжФЊеЕ•жЧ†зФ®зЪДдњ°жБѓпЉМдєЯдЄНи¶БжФЊеЕ•ињЗе§Ъдњ°жБѓгАВ
¬†¬†¬† жЧ†иЃЇдљњзФ®дљХзІНжЬНеК°зЂѓжКАжЬѓпЉМеП™и¶БеПСйАБеЫЮзЪДHTTPеУНеЇФдЄ≠еМЕеРЂе¶ВдЄЛ嚥еЉПзЪДе§іпЉМеИЩиІЖдЄЇжЬНеК°еЩ®и¶Бж±ВиЃЊзљЃдЄАдЄ™cookieпЉЪ
Set-cookie:name=name;expires=date;path=path;domain=domain
¬†¬†¬† жФѓжМБcookieзЪДжµПиІИеЩ®йГљдЉЪеѓєж≠§дљЬеЗЇеПНеЇФпЉМеН≥еИЫеїЇcookieжЦЗдїґеєґдњЭе≠ШпЉИдєЯеПѓиГљжШѓеЖЕе≠ШcookieпЉЙпЉМзФ®жИЈдї•еРОеЬ®жѓПжђ°еПСеЗЇиѓЈж±ВжЧґпЉМжµПиІИеЩ®йГљи¶БеИ§жЦ≠ељУеЙНжЙАжЬЙзЪДcookieдЄ≠жЬЙж≤°жЬЙж≤°е§±жХИпЉИж†єжНЃexpiresе±ЮжАІеИ§жЦ≠пЉЙеєґдЄФеМєйЕНдЇЖpathе±ЮжАІзЪДcookieдњ°жБѓпЉМе¶ВжЮЬжЬЙзЪДиѓЭпЉМдЉЪдї•дЄЛйЭҐзЪД嚥еЉПеК†еЕ•еИ∞иѓЈж±Ве§ідЄ≠еПСеЫЮжЬНеК°зЂѓпЉЪ
    Cookie: name="zj"; Path="/linkage"
¬†¬†¬† жЬНеК°зЂѓзЪДеК®жАБиДЪжЬђдЉЪеѓєеЕґињЫи°МеИЖжЮРпЉМеєґеБЪеЗЇзЫЄеЇФзЪДе§ДзРЖпЉМељУзДґдєЯеПѓдї•йАЙжЛ©зЫіжО•ењљзХ•гАВ
¬†¬†¬† ињЩйЗМзЙµжЙѓеИ∞дЄАдЄ™иІДиМГпЉИжИЦеНПиЃЃпЉЙдЄОеЃЮзО∞зЪДйЧЃйҐШпЉМзЃАеНХжЭ•иЃ≤е∞±жШѓиІДиМГиІДеЃЪдЇЖеБЪжИРдїАдєИж†Је≠РпЉМйВ£дєИеЃЮзО∞е∞±ењЕй°їдЊЭжНЃиІДиМГжЭ•еБЪпЉМињЩж†ЈжЙНиГљдЇТзЫЄеЕЉеЃєпЉМдљЖжШѓеРДдЄ™еЃЮзО∞жЙАдљњзФ®зЪДжЦєеЉПеНідЄНеПЧзЇ¶жЭЯпЉМдєЯеПѓдї•еЬ®еЃЮзО∞дЇЖиІДиМГзЪДеЯЇз°АдЄКиґЕеЗЇиІДиМГпЉМињЩе∞±зІ∞дєЛдЄЇжЙ©е±ХдЇЖгАВжЧ†иЃЇеУ™зІНжµПиІИеЩ®пЉМеП™и¶БжГ≥жПРдЊЫcookieзЪДеКЯиГљпЉМйВ£е∞±ењЕй°їдЊЭзЕІзЫЄеЇФзЪДRFCиІДиМГжЭ•еЃЮзО∞гАВжЙАдї•ињЩйЗМжЬНеК°еЩ®еП™зЃ°еПСSet-cookieе§іеЯЯпЉМињЩдєЯжШѓHTTPеНПиЃЃжЧ†зКґжАБжАІзЪДдЄАзІНдљУзО∞гАВ
йЬАи¶Бж≥®жДПзЪДжШѓпЉМеЗЇдЇОеЃЙеЕ®жАІзЪДиАГиЩСпЉМcookieеσ俕襀жµПиІИеЩ®з¶БзФ®гАВ
¬†¬†¬† еЖНзЬЛдЄАдЄЛsessionзЪДеОЯзРЖпЉЪ
¬†¬†¬† зђФиАЕж≤°жЬЙжЙЊеИ∞зЫЄеЕ≥зЪДRFCпЉМеЫ†дЄЇsessionжЬђе∞±дЄНжШѓеНПиЃЃе±ВйЭҐзЪДдЇЛзЙ©гАВеЃГзЪДеЯЇжЬђеОЯзРЖжШѓжЬНеК°зЂѓдЄЇжѓПдЄАдЄ™sessionзїіжК§дЄАдїљдЉЪиѓЭдњ°жБѓжХ∞жНЃпЉМиАМеЃҐжИЈзЂѓеТМжЬНеК°зЂѓдЊЭйЭ†дЄАдЄ™еЕ®е±АеФѓдЄАзЪДж†ЗиѓЖжЭ•иЃњйЧЃдЉЪиѓЭдњ°жБѓжХ∞жНЃгАВзФ®жИЈиЃњйЧЃwebеЇФзФ®жЧґпЉМжЬНеК°зЂѓз®ЛеЇПеЖ≥еЃЪдљХжЧґеИЫеїЇsessionпЉМеИЫеїЇsessionеПѓдї•ж¶ВжЛђдЄЇдЄЙдЄ™ж≠•й™§пЉЪ
1.¬†¬† зФЯжИРеЕ®е±АеФѓдЄАж†ЗиѓЖзђ¶пЉИsessionidпЉЙпЉЫ
2.¬†¬† еЉАиЊЯжХ∞жНЃе≠ШеВ®з©ЇйЧігАВдЄАиИђдЉЪеЬ®еЖЕе≠ШдЄ≠еИЫеїЇзЫЄеЇФзЪДжХ∞жНЃзїУжЮДпЉМдљЖињЩзІНжГЕеЖµдЄЛпЉМз≥їзїЯдЄАжЧ¶жОЙзФµпЉМжЙАжЬЙзЪДдЉЪиѓЭжХ∞жНЃе∞±дЉЪ䪥姱пЉМе¶ВжЮЬжШѓзФµе≠РеХЖеК°зљСзЂЩпЉМињЩзІНдЇЛжХЕдЉЪйА†жИРдЄ•йЗНзЪДеРОжЮЬгАВдЄНињЗдєЯеПѓдї•еЖЩеИ∞жЦЗдїґйЗМзФЪиЗ≥е≠ШеВ®еЬ®жХ∞жНЃеЇУдЄ≠пЉМињЩж†ЈиЩљзДґдЉЪеҐЮеК†I/OеЉАйФАпЉМдљЖsessionеПѓдї•еЃЮзО∞жЯРзІНз®ЛеЇ¶зЪДжМБдєЕеМЦпЉМиАМдЄФжЫіжЬЙеИ©дЇОsessionзЪДеЕ±дЇЂпЉЫ
3.¬†¬† е∞ЖsessionзЪДеЕ®е±АеФѓдЄАж†Зз§Їзђ¶еПСйАБзїЩеЃҐжИЈзЂѓгАВ
йЧЃйҐШзЪДеЕ≥йФЃе∞±еЬ®жЬНеК°зЂѓе¶ВдљХеПСйАБињЩдЄ™sessionзЪДеФѓдЄАж†ЗиѓЖдЄКгАВиБФз≥їеИ∞HTTPеНПиЃЃпЉМжХ∞жНЃжЧ†йЭЮеПѓдї•жФЊеИ∞иѓЈж±Ви°МгАБе§іеЯЯжИЦBodyйЗМпЉМеЯЇдЇОж≠§пЉМдЄАиИђжЭ•иѓідЉЪжЬЙдЄ§зІНеЄЄзФ®зЪДжЦєеЉПпЉЪcookieеТМURLйЗНеЖЩгАВ
1.   Cookie
иѓїиАЕеЇФиѓ•жГ≥еИ∞дЇЖпЉМеѓєпЉМжЬНеК°зЂѓеП™и¶БиЃЊзљЃSet-cookieе§іе∞±еПѓдї•е∞ЖsessionзЪДж†ЗиѓЖзђ¶дЉ†йАБеИ∞еЃҐжИЈзЂѓпЉМиАМеЃҐжИЈзЂѓж≠§еРОзЪДжѓПдЄАжђ°иѓЈж±ВйГљдЉЪеЄ¶дЄКињЩдЄ™ж†ЗиѓЖзђ¶пЉМзФ±дЇОcookieеσ俕职皁姱жХИжЧґйЧіпЉМжЙАдї•дЄАиИђеМЕеРЂsessionдњ°жБѓзЪДcookieдЉЪ职皁姱жХИжЧґйЧідЄЇ0пЉМеН≥жµПиІИеЩ®ињЫз®ЛжЬЙжХИжЧґйЧігАВиЗ≥дЇОжµПиІИеЩ®жАОдєИе§ДзРЖињЩдЄ™0пЉМжѓПдЄ™жµПиІИеЩ®йГљжЬЙиЗ™еЈ±зЪДжЦєж°ИпЉМдљЖеЈЃеИЂйГљдЄНдЉЪ姙姲пЉИдЄАиИђдљУзО∞еЬ®жЦ∞еїЇжµПиІИеЩ®з™ЧеП£зЪДжЧґеАЩпЉЙпЉЫ
2.¬†¬† URLйЗНеЖЩ
жЙАи∞УURLйЗНеЖЩпЉМй°ЊеРНжАЭдєЙе∞±жШѓйЗНеЖЩURLгАВиѓХжГ≥пЉМеЬ®ињФеЫЮзФ®жИЈиѓЈж±ВзЪДй°µйЭҐдєЛеЙНпЉМе∞Жй°µйЭҐеЖЕжЙАжЬЙзЪДURLеРОйЭҐеЕ®йГ®дї•getеПВжХ∞зЪДжЦєеЉПеК†дЄКsessionж†ЗиѓЖзђ¶пЉИжИЦиАЕеК†еЬ®path infoйГ®еИЖз≠Йз≠ЙпЉЙпЉМињЩж†ЈзФ®жИЈеЬ®жФґеИ∞еУНеЇФдєЛеРОпЉМжЧ†иЃЇзВєеЗїеУ™дЄ™йУЊжО•жИЦжПРдЇ§и°®еНХпЉМйГљдЉЪеЬ®еЖНеЄ¶дЄКsessionзЪДж†ЗиѓЖзђ¶пЉМдїОиАМе∞±еЃЮзО∞дЇЖдЉЪиѓЭзЪДдњЭжМБгАВиѓїиАЕеПѓиГљдЉЪиІЙеЊЧињЩзІНеБЪж≥ХжѓФиЊГйЇїзГ¶пЉМз°ЃеЃЮжШѓињЩж†ЈпЉМдљЖжШѓпЉМе¶ВжЮЬеЃҐжИЈзЂѓз¶БзФ®дЇЖcookieзЪДиѓЭпЉМURLйЗНеЖЩе∞ЖдЉЪжШѓй¶ЦйАЙгАВ
¬†¬†¬† еИ∞ињЩйЗМпЉМиѓїиАЕеЇФиѓ•жШОзЩљжИСеЙНйЭҐдЄЇдїАдєИиѓіsessionдєЯзЃЧдљЬжШѓеѓєHTTPзЪДдЄАзІНжЙ©е±ХдЇЖеРІгАВе¶ВдЄЛдЄ§еєЕеЫЊжШѓзђФиАЕеЬ®FirefoxзЪДFirebugжПТдїґдЄ≠зЪДжИ™еЫЊпЉМеПѓдї•зЬЛеИ∞пЉМељУжИСзђђдЄАжђ°иЃњйЧЃindex.jspжЧґпЉМеУНеЇФе§ійЗМеМЕеРЂдЇЖSet-cookieе§іпЉМиАМиѓЈж±Ве§ідЄ≠ж≤°жЬЙгАВељУжИСеЖНжђ°еИЈжЦ∞й°µйЭҐжЧґпЉМеЫЊдЇМжШЊз§ЇеЬ®еУНеЇФдЄ≠дЄНеЬ®жЬЙSet-cookieе§іпЉМиАМеЬ®иѓЈж±Ве§ідЄ≠еНіжЬЙдЇЖCookieе§ігАВж≥®жДПдЄАдЄЛCookieзЪДеРНе≠ЧпЉЪjsessionidпЉМй°ЊеРНжАЭдєЙпЉМе∞±жШѓsessionзЪДж†ЗиѓЖзђ¶пЉМеП¶е§ЦеПѓдї•зЬЛеИ∞дЄ§еєЕеЫЊдЄ≠зЪДjsessionidзЪДеАЉжШѓзЫЄеРМзЪДпЉМеОЯеЫ†зђФиАЕе∞±дЄНеЖНе§ЪиІ£йЗКдЇЖгАВеП¶е§ЦиѓїиАЕеПѓиГљеЬ®дЄАдЇЫзљСзЂЩдЄКиІБињЗеЬ®жЬАеРОйЩДеК†дЇЖдЄА恵嚥е¶Вjsessionid=xxxзЪДURLпЉМињЩе∞±жШѓйЗЗзФ®URLйЗНеЖЩжЭ•еЃЮзО∞зЪДsessionгАВ

пЉИеЫЊдЄАпЉМй¶Цжђ°иѓЈж±Вindex.jspпЉЙ

пЉИеЫЊдЇМпЉМеЖНжђ°иѓЈж±Вindex.jspпЉЙ
CookieеТМsessionзФ±дЇОеЃЮзО∞жЙЛжЃµдЄНеРМпЉМеЫ†ж≠§дєЯеРДжЬЙдЉШзЉЇзВєеТМеРДиЗ™зЪДеЇФзФ®еЬЇжЩѓпЉЪ
1.¬†¬† еЇФзФ®еЬЇжЩѓ
CookieзЪДеЕЄеЮЛеЇФзФ®еЬЇжЩѓжШѓRemember MeжЬНеК°пЉМеН≥зФ®жИЈзЪДиі¶жИЈдњ°жБѓйАЪињЗcookieзЪД嚥еЉПдњЭе≠ШеЬ®еЃҐжИЈзЂѓпЉМељУзФ®жИЈеЖНжђ°иѓЈж±ВеМєйЕНзЪДURLзЪДжЧґеАЩпЉМиі¶жИЈдњ°жБѓдЉЪ襀䊆йАБеИ∞жЬНеК°зЂѓпЉМдЇ§зФ±зЫЄеЇФзЪДз®ЛеЇПеЃМжИРиЗ™еК®зЩїељХз≠ЙеКЯиГљгАВељУзДґдєЯеПѓдї•дњЭе≠ШдЄАдЇЫеЃҐжИЈзЂѓдњ°жБѓпЉМжѓФе¶Вй°µйЭҐеЄГе±Адї•еПКжРЬ糥еОЖеП≤з≠Йз≠ЙгАВ
SessionзЪДеЕЄеЮЛеЇФзФ®еЬЇжЩѓжШѓзФ®жИЈзЩїељХжЯРзљСзЂЩдєЛеРОпЉМе∞ЖеЕґзЩїељХдњ°жБѓжФЊеЕ•sessionпЉМеЬ®дї•еРОзЪДжѓПжђ°иѓЈж±ВдЄ≠жߕ胥зЫЄеЇФзЪДзЩїељХдњ°жБѓдї•з°ЃдњЭиѓ•зФ®жИЈеРИж≥ХгАВељУзДґињШжШѓжЬЙиі≠зЙ©иљ¶з≠Йз≠ЙзїПеЕЄеЬЇжЩѓпЉЫ
2.¬†¬† еЃЙеЕ®жАІ
cookieе∞Ждњ°жБѓдњЭе≠ШеЬ®еЃҐжИЈзЂѓпЉМе¶ВжЮЬдЄНињЫи°МеК†еѓЖзЪДиѓЭпЉМжЧ†зЦСдЉЪжЪійЬ≤дЄАдЇЫйЪРзІБдњ°жБѓпЉМеЃЙеЕ®жАІеЊИеЈЃпЉМдЄАиИђжГЕеЖµдЄЛжХПжДЯдњ°жБѓжШѓзїПињЗеК†еѓЖеРОе≠ШеВ®еЬ®cookieдЄ≠пЉМдљЖеЊИеЃєжШУе∞±дЉЪ襀з™ГеПЦгАВиАМsessionеП™дЉЪе∞Ждњ°жБѓе≠ШеВ®еЬ®жЬНеК°зЂѓпЉМе¶ВжЮЬе≠ШеВ®еЬ®жЦЗдїґжИЦжХ∞жНЃеЇУдЄ≠пЉМдєЯжЬЙ襀з™ГеПЦзЪДеПѓиГљпЉМеП™жШѓеПѓиГљжАІжѓФcookieе∞ПдЇЖ姙е§ЪгАВ
SessionеЃЙеЕ®жАІжЦєйЭҐжѓФиЊГз™БеЗЇзЪДжШѓе≠ШеЬ®дЉЪиѓЭеКЂжМБзЪДйЧЃйҐШпЉМињЩжШѓдЄАзІНеЃЙеЕ®е®БиГБпЉМињЩеЬ®дЄЛжЦЗдЉЪињЫи°МжЫіиѓ¶зїЖзЪДиѓіжШОгАВжАїдљУжЭ•иЃ≤пЉМsessionзЪДеЃЙеЕ®жАІи¶БйЂШдЇОcookieпЉЫ
3.¬†¬† жАІиГљ
Cookieе≠ШеВ®еЬ®еЃҐжИЈзЂѓпЉМжґИиАЧзЪДжШѓеЃҐжИЈзЂѓзЪДI/OеТМеЖЕе≠ШпЉМиАМsessionе≠ШеВ®еЬ®жЬНеК°зЂѓпЉМжґИиАЧзЪДжШѓжЬНеК°зЂѓзЪДиµДжЇРгАВдљЖжШѓsessionеѓєжЬНеК°еЩ®йА†жИРзЪДеОЛеКЫжѓФиЊГйЫЖдЄ≠пЉМиАМcookieеЊИе•љеЬ∞еИЖжХ£дЇЖиµДжЇРжґИиАЧпЉМе∞±ињЩзВєжЭ•иѓіпЉМcookieжШѓи¶БдЉШдЇОsessionзЪДпЉЫ
4.¬†¬† жЧґжХИжАІ
CookieеПѓдї•йАЪињЗиЃЊзљЃжЬЙжХИжЬЯдљњеЕґиЊГйХњжЧґйЧіеЖЕе≠ШеЬ®дЇОеЃҐжИЈзЂѓпЉМиАМsessionдЄАиИђеП™жЬЙжѓФиЊГзЯ≠зЪДжЬЙжХИжЬЯпЉИзФ®жИЈдЄїеК®йФАжѓБsessionжИЦеЕ≥йЧ≠жµПиІИеЩ®еРОеЉХеПСиґЕжЧґпЉЙпЉЫ
5.¬†¬† еЕґдїЦ
CookieзЪДе§ДзРЖеЬ®еЉАеПСдЄ≠ж≤°жЬЙsessionжЦєдЊњгАВиАМдЄФcookieеЬ®еЃҐжИЈзЂѓжШѓжЬЙжХ∞йЗПеТМе§Іе∞ПзЪДйЩРеИґзЪДпЉМиАМsessionзЪДе§Іе∞ПеНіеП™дї•з°ђдїґдЄЇйЩРеИґпЉМиГље≠ШеВ®зЪДжХ∞жНЃжЧ†зЦСе§ІдЇЖ姙е§ЪгАВ
Servlet/JSPдЄ≠зЪДSession
¬†¬†¬† йАЪињЗдЄКињ∞зЪДиЃ≤иІ£пЉМиѓїиАЕеЇФиѓ•еѓєsessionжЬЙдЇЖдЄАдЄ™е§ІдљУзЪДиЃ§иѓЖпЉМдљЖжШѓеЕЈдљУеИ∞жЯРзІНеК®жАБй°µйЭҐжКАжЬѓпЉМеПИжШѓжАОдєИеЃЮзО∞sessionзЪДеСҐпЉЯдЄЛйЭҐзђФиАЕе∞ЖзїУеРИsessionзЪДзФЯеСљеС®жЬЯпЉИlifecycleпЉЙпЉМдїОжЇРдї£з†БзЪДе±Вжђ°жЭ•еЕЈдљУеИЖжЮРдЄАдЄЛеЬ®servlet/jspжКАжЬѓдЄ≠пЉМsessionжШѓжАОдєИеЃЮзО∞зЪДгАВдї£з†БйГ®еИЖдї•tomcat6.0.20дљЬдЄЇеПВиАГгАВ
еИЫеїЇ
еЬ®жИСйЧЃињЗзЪДдЄАдЇЫдїОдЇЛjava webеЉАеПСзЪДдЇЇдЄ≠пЉМеѓєдЇОsessionзЪДеИЫеїЇжЧґжЬЇе§ІйГљињЩдєИеЫЮз≠ФпЉЪељУжИСиѓЈж±ВжЯРдЄ™й°µйЭҐзЪДжЧґеАЩпЉМsessionе∞±иҐЂеИЫеїЇдЇЖгАВињЩеП•иѓЭеЕґеЃЮеЊИеРЂз≥КпЉМеЫ†дЄЇи¶БеИЫеїЇsessionиѓЈж±ВзЪДеПСйАБжШѓењЕдЄНеПѓе∞СзЪДпЉМдљЖжШѓжЧ†иЃЇдљХзІНиѓЈж±ВйГљдЉЪеИЫеїЇsessionеРЧпЉЯйФЩгАВжИСдїђжЭ•зЬЛдЄАдЄ™дЊЛе≠РгАВ
дЉЧжЙАеС®зЯ•пЉМjspжКАжЬѓжШѓservletжКАжЬѓзЪДеПНиљђпЉМеЬ®еЉАеПСйШґжЃµпЉМжИСдїђзЬЛеИ∞зЪДжШѓjspй°µйЭҐпЉМдљЖзЬЯж≠£еИ∞ињРи°МжЧґйШґжЃµпЉМjspй°µйЭҐжШѓдЉЪ襀вАЬзњїиѓСвАЭдЄЇservletз±їжЭ•жЙІи°МзЪДпЉМдЊЛе¶ВжИСдїђжЬЙе¶ВдЄЛjspй°µйЭҐпЉЪ
|
<%@ page language="java" pageEncoding="ISO-8859-1" session="true"%> <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"> <html>     <head>         <title>index.jsp</title>     </head>     <body>         This is index.jsp page.         <br>     </body> </html> |
¬†¬†¬† еЬ®жИСдїђеИЭжђ°иѓЈж±Виѓ•й°µйЭҐеРОпЉМеЬ®еѓєеЇФзЪДworkзЫЃељХеПѓдї•жЙЊеИ∞иѓ•й°µйЭҐеѓєеЇФзЪДjavaз±їпЉМиАГиЩСеИ∞зѓЗеєЕзЪДеОЯеЫ†пЉМеЬ®ж≠§еП™жСШељХжѓФиЊГйЗНи¶БзЪДдЄАйГ®еИЖпЉМжЬЙеЕіиґ£зЪДиѓїиАЕеПѓдї•дЇ≤иЗ™иѓХдЄАдЄЛпЉЪ
|
...... response.setContentType("text/html;charset=ISO-8859-1"); pageContext = _jspxFactory.getPageContext(this, request, response,             null, true, 8192, true); _jspx_page_context = pageContext; application = pageContext.getServletContext(); config = pageContext.getServletConfig(); session = pageContext.getSession(); out = pageContext.getOut(); _jspx_out = out;   out.write("\r\n"); out.write("<!DOCTYPE HTML PUBLIC \"-//W3C//DTD HTML 4.01 Transitional//EN\">\r\n"); out.write("<html>\r\n"); ...... |
¬†¬†¬† еПѓдї•зЬЛеИ∞жЬЙдЄАеП•жШЊеЉПеИЫеїЇsessionзЪДиѓ≠еП•пЉМеЃГжШѓжАОдєИжЭ•зЪДеСҐпЉЯжИСдїђеЖНзЬЛдЄАдЄЛеѓєеЇФзЪДjspй°µйЭҐпЉМеЬ®jspзЪДpageжМЗдї§дЄ≠еК†еЕ•дЇЖsession="true"пЉМжДПжАЭжШѓеЬ®иѓ•й°µйЭҐеРѓзФ®sessionпЉМеЕґеЃЮдљЬдЄЇеК®жАБжКАжЬѓпЉМињЩдЄ™еПВжХ∞жШѓйїШиЃ§дЄЇtrueзЪДпЉМињЩеЊИеРИзРЖпЉМеЬ®ж≠§жШЊз§ЇеЖЩеЗЇжЭ•еП™жШѓеБЪдЄАдЄЛеЉЇи∞ГгАВеЊИжШЊзДґдЇМиАЕжЬЙзЭАењЕзДґзЪДиБФз≥їгАВзђФиАЕеЬ®jsp/servletзЪДзњїиѓСеЩ®пЉИorg.apache.jasper.compilerпЉЙзЪДжЇРз†БдЄ≠жЙЊеИ∞дЇЖзЫЄеЕ≥иѓБжНЃпЉЪ
|
...... if (pageInfo.isSession())     out.printil("session = pageContext.getSession();"); out.printil("out = pageContext.getOut();"); out.printil("_jspx_out = out;"); ...... |
¬†¬†¬† дЄКйЭҐзЪДдї£з†БзЙЗжЃµзЪДжДПжАЭжШѓе¶ВжЮЬй°µйЭҐдЄ≠еЃЪдєЙдЇЖsession="true"пЉМе∞±еЬ®зФЯжИРзЪДservletжЇРз†БдЄ≠еК†еЕ•sessionзЪДиОЈеПЦиѓ≠еП•гАВињЩеП™иГље§ЯиѓіжШОsessionеИЫеїЇзЪДжЭ°дїґпЉМжШЊзДґињШдЄНиГљиѓіжШОsessionжШѓе¶ВдљХеИЫеїЇзЪДпЉМжЬђзЭАйАРжЬђжЇѓжЇРзЪДз≤Њз•ЮпЉМжИСдїђзїІзї≠еЊАдЄЛжΥ糥гАВ
¬†¬†¬† жЬЙињЗservletеЉАеПСзїПй™МзЪДеЇФиѓ•иЃ∞еЊЧжИСдїђжШѓйАЪињЗHttpServletRequestзЪДgetSessionжЦєж≥ХжЭ•иОЈеПЦељУеЙНзЪДsessionеѓєи±°зЪДпЉЪ
|
public HttpSession getSession(boolean create); public HttpSession getSession(); |
¬†¬†¬† дЇМиАЕзЪДеМЇеИЂеП™жШѓжЧ†еПВзЪДgetSessionе∞ЖcreateйїШиЃ§иЃЊзљЃдЄЇtrueиАМеЈ≤гАВеН≥пЉЪ
|
public HttpSession getSession() {     return (getSession(true)); } |
¬†¬†¬† йВ£дєИињЩдЄ™еПВжХ∞еИ∞еЇХжДПеС≥зЭАдїАдєИеСҐпЉЯйАЪињЗе±Ве±ВиЈЯиЄ™пЉМзђФиАЕзїИдЇОзРЖжЄЕдЇЖеЕґдЄ≠зЪДиДЙзїЬпЉМзФ±дЇОеЗљжХ∞дєЛйЧізЪДеЕ≥з≥їжѓФиЊГе§НжЭВпЉМе¶ВжЮЬжГ≥жЫіиѓ¶зїЖеЬ∞дЇЖиІ£еЖЕйГ®жЬЇеИґпЉМеїЇиЃЃеОїзЛђзЂЛйШЕиѓїtomcatзЫЄеЕ≥йГ®еИЖзЪДжЇРдї£з†БгАВињЩйЗМжИСе∞ЖеЕґдЄ≠зЪДе§ІиЗіжµБз®ЛеПЩињ∞дЄАдЄЛпЉЪ
1.¬†¬† зФ®жИЈиѓЈж±ВжЯРjspй°µйЭҐпЉМиѓ•й°µйЭҐиЃЊзљЃдЇЖsession="true"пЉЫ
2.¬†¬† Servlet/jspеЃєеЩ®е∞ЖеЕґзњїиѓСдЄЇservletпЉМеєґеК†иљљгАБжЙІи°Миѓ•servletпЉЫ
3.¬†¬† Servlet/jspеЃєеЩ®еЬ®е∞Би£ЕHttpServletRequestеѓєи±°жЧґж†єжНЃcookieжИЦиАЕurlдЄ≠жШѓеР¶е≠ШеЬ®jsessionidжЭ•еЖ≥еЃЪжШѓзїСеЃЪељУеЙНзЪДsessionеИ∞HttpRequestињШжШѓеИЫеїЇжЦ∞зЪДsessionеѓєи±°пЉИеЬ®иѓЈж±ВиІ£жЮРйШґжЃµеПСзО∞еєґиЃ∞ељХjsessionidпЉМеЬ®Requestеѓєи±°еИЫеїЇйШґжЃµе∞ЖsessionзїСеЃЪпЉЙпЉЫ
4.¬†¬† з®ЛеЇПжМЙйЬАжУНдљЬsessionпЉМе≠ШеПЦжХ∞жНЃпЉЫ
5.¬†¬† е¶ВжЮЬжШѓжЦ∞еИЫеїЇзЪДsessionпЉМеЬ®зїУжЮЬеУНеЇФжЧґпЉМеЃєеЩ®дЉЪеК†еЕ•Set-cookieе§іпЉМдї•жПРйЖТжµПиІИеЩ®и¶БдњЭжМБиѓ•дЉЪиѓЭпЉИжИЦиАЕйЗЗзФ®URLйЗНеЖЩжЦєеЉПе∞ЖжЦ∞зЪДйУЊжО•еСИзО∞зїЩзФ®жИЈпЉЙгАВ
йАЪињЗдЄКйЭҐзЪДеПЩињ∞иѓїиАЕеЇФиѓ•дЇЖиІ£дЇЖsessionжШѓдљХжЧґеИЫеїЇзЪДпЉМињЩйЗМеЖНдїОservletињЩдЄ™е±ВйЭҐжАїзїУдЄАдЄЛпЉЪељУзФ®жИЈиѓЈж±ВзЪДservletи∞ГзФ®дЇЖgetSessionжЦєж≥ХжЧґпЉМйГљдЉЪиОЈеПЦsessionпЉМиЗ≥дЇОжШѓеР¶еИЫеїЇжЦ∞зЪДsessionеПЦеЖ≥дЇОељУеЙНrequestжШѓеР¶еЈ≤зїСеЃЪsessionгАВељУеЃҐжИЈзЂѓеЬ®иѓЈж±ВдЄ≠еК†еЕ•дЇЖjsessionidж†ЗиѓЖиАМservletеЃєеЩ®ж†єжНЃж≠§ж†ЗиѓЖжЯ•жЙЊеИ∞дЇЖеѓєеЇФзЪДsessionеѓєи±°жЧґпЉМдЉЪе∞Жж≠§sessionзїСеЃЪеИ∞ж≠§жђ°иѓЈж±ВзЪДrequestеѓєи±°пЉМеЃҐжИЈзЂѓиѓЈж±ВдЄ≠дЄНеЄ¶jsessionidжИЦиАЕж≠§jsessionidеѓєеЇФзЪДsessionеЈ≤ињЗжЬЯ姱жХИжЧґпЉМsessionзЪДзїСеЃЪжЧ†ж≥ХеЃМжИРпЉМж≠§жЧґењЕй°їеИЫеїЇжЦ∞зЪДsessionгАВеРМжЧґеПСйАБSet-cookieе§ійАЪзЯ•еЃҐжИЈзЂѓеЉАеІЛдњЭжМБжЦ∞зЪДдЉЪиѓЭгАВ
дњЭжМБ
¬†¬†¬† зРЖиІ£дЇЖsessionзЪДеИЫеїЇпЉМе∞±еЊИе•љзРЖиІ£дЉЪиѓЭжШѓе¶ВдљХеЬ®еЃҐжИЈзЂѓеТМжЬНеК°зЂѓдєЛйЧідњЭжМБзЪДдЇЖгАВељУй¶Цжђ°еИЫеїЇдЇЖsessionеРОпЉМеЃҐжИЈзЂѓдЉЪеЬ®еРОзї≠зЪДиѓЈж±ВдЄ≠е∞ЖsessionзЪДж†ЗиѓЖзђ¶еЄ¶еИ∞жЬНеК°зЂѓпЉМжЬНеК°зЂѓз®ЛеЇПеП™и¶БеЬ®йЬАи¶БsessionзЪДжЧґеАЩи∞ГзФ®getSessionпЉМжЬНеК°зЂѓе∞±еПѓдї•е∞ЖеѓєеЇФзЪДsessionзїСеЃЪеИ∞ељУеЙНиѓЈж±ВпЉМдїОиАМеЃЮзО∞зКґжАБзЪДдњЭжМБгАВељУзДґињЩйЬАи¶БеЃҐжИЈзЂѓзЪДжФѓжМБпЉМе¶ВжЮЬз¶БзФ®дЇЖcookieиАМеПИдЄНйЗЗзФ®urlйЗНеЖЩзЪДиѓЭпЉМsessionжШѓжЧ†ж≥ХдњЭжМБзЪДгАВ
¬†¬†¬† е¶ВжЮЬеЗ†жђ°иѓЈж±ВдєЛйЧіжЬЙдЄАдЄ™servletжЬ™и∞ГзФ®getSessionпЉИжИЦиАЕеє≤иДЖиѓЈж±ВдЄАдЄ™йЭЩжАБй°µйЭҐпЉЙдЉЪдЄНдЉЪдљњеЊЧдЉЪиѓЭдЄ≠жЦ≠еСҐпЉЯињЩдЄ™дЄНдЉЪеПСзФЯзЪДпЉМеЫ†дЄЇеЃҐжИЈзЂѓеП™дЉЪе∞ЖеРИж≥ХзЪДcookieеАЉдЉ†йАБзїЩжЬНеК°зЂѓпЉМиЗ≥дЇОжЬНеК°зЂѓжЛњcookieеБЪдїАдєИдЇЛеЃГжШѓдЄНдЉЪеЕ≥ењГзЪДпЉМељУзДґдєЯжЧ†ж≥ХеЕ≥ењГгАВSessionеїЇзЂЛдєЛеРОпЉМеЃҐжИЈзЂѓдЉЪдЄАзЫіе∞ЖsessionзЪДж†ЗиѓЖзђ¶дЉ†йАБеИ∞жЬНеК°еЩ®пЉМжЧ†иЃЇиѓЈж±ВзЪДй°µйЭҐжШѓеК®жАБзЪДгАБйЭЩжАБзЪДпЉМзФЪиЗ≥жШѓдЄАеЙѓеЫЊзЙЗгАВ
йФАжѓБ
¬†¬†¬† ж≠§е§Ди∞ИеИ∞зЪДйФАжѓБжШѓжМЗдЉЪиѓЭзЪДеЇЯеЉГпЉМиЗ≥дЇОе≠ШеВ®дЉЪиѓЭдњ°жБѓзЪДжХ∞жНЃзїУжЮДжШѓеЫЮжԴ襀йЗНзФ®ињШжШѓзЫіжО•йЗКжФЊеЖЕе≠ШжИСдїђеєґдЄНеЕ≥ењГгАВSessionзЪДйФАжѓБжЬЙдЄ§зІНжГЕеЖµпЉЪиґЕжЧґеТМжЙЛеК®йФАжѓБгАВ
¬†¬†¬† зФ±дЇОHTTPеНПиЃЃзЪДжЧ†зКґжАБжАІпЉМжЬНеК°зЂѓжЧ†ж≥ХеЊЧзЯ•дЄАдЄ™sessionеѓєи±°дљХжЧґе∞ЖеЖН搰襀䚜зФ®пЉМеПѓиГљзФ®жИЈеЉАеРѓдЇЖдЄАдЄ™sessionдєЛеРОеЖНдєЯж≤°жЬЙеРОзї≠зЪДиЃњйЧЃпЉМиАМдЄФsessionзЪДдњЭжМБжШѓйЬАи¶БжґИиАЧдЄАеЃЪзЪДжЬНеК°зЂѓеЉАйФАзЪДпЉМеЫ†ж≠§дЄНеПѓиГљдЄАеС≥еЬ∞еИЫеїЇsessionиАМдЄНеОїеЫЮжФґжЧ†зФ®зЪДsessionгАВињЩйЗМе∞±еЉХеЕ•дЇЖдЄАдЄ™иґЕжЧґжЬЇеИґгАВTomcatдЄ≠зЪДиґЕжЧґеЬ®web.xmlйЗМеБЪе¶ВдЄЛйЕНзљЃпЉЪ
|
<session-config> <session-timeout>30</session-timeout> </session-config> |
¬†¬†¬† дЄКињ∞йЕНзљЃжШѓжМЗsessionеЬ®30еИЖйТЯж≤°жЬЙ襀еЖНжђ°дљњзФ®е∞±е∞ЖеЕґйФАжѓБгАВTomcatжШѓжАОдєИиЃ°зЃЧињЩдЄ™30еИЖйТЯзЪДеСҐпЉЯеОЯжЭ•еЬ®getSessionдєЛеРОпЉМйГљи¶Би∞ГзФ®еЃГзЪДaccessжЦєж≥ХпЉМдњЃжФєlastAccessedTimeпЉМеЬ®йФАжѓБsessionзЪДжЧґеАЩе∞±жШѓеИ§жЦ≠ељУеЙНжЧґйЧіеТМињЩдЄ™lastAccessedTimeзЪДеЈЃеАЉгАВ
¬†¬†¬† жЙЛеК®йФАжѓБжШѓжМЗзЫіжО•и∞ГзФ®еЕґinvalidateжЦєж≥ХпЉМж≠§жЦєж≥ХеЃЮйЩЕдЄКжШѓи∞ГзФ®expireжЦєж≥ХжЭ•жЙЛеК®е∞ЖеЕґиЃЊзљЃдЄЇиґЕжЧґгАВ
¬†¬†¬† ељУзФ®жИЈжЙЛеК®иѓЈж±ВдЇЖsessionзЪДйФАжѓБжЧґпЉМеЃҐжИЈзЂѓжШѓжЧ†ж≥ХзЯ•йБУжЬНеК°зЂѓзЪДsessionеЈ≤зїП襀йФАжѓБзЪДпЉМеЃГдЊЭзДґдЉЪеПСйАБеЕИеЙНзЪДsessionж†ЗиѓЖзђ¶еИ∞жЬНеК°зЂѓгАВиАМж≠§жЧґе¶ВжЮЬеЖНжђ°иѓЈж±ВдЇЖжЯРдЄ™и∞ГзФ®дЇЖgetSessionзЪДservletпЉМжЬНеК°зЂѓжШѓжЧ†ж≥Хж†єжНЃеЕИеЙНзЪДsessionж†ЗиѓЖзђ¶жЙЊеИ∞зЫЄеЇФзЪДsessionеѓєи±°зЪДпЉМињЩжШѓеПИи¶БйЗНжЦ∞еИЫеїЇжЦ∞зЪДsessionпЉМеИЖйЕНжЦ∞зЪДж†ЗиѓЖзђ¶пЉМеєґеСКзЯ•жЬНеК°зЂѓжЫіжЦ∞sessionж†ЗиѓЖзђ¶еЉАеІЛдњЭжМБжЦ∞зЪДдЉЪиѓЭгАВ
SessionзЪДжХ∞жНЃзїУжЮД
¬†¬†¬† еЬ®servlet/jspдЄ≠пЉМеЃєеЩ®жШѓзФ®дљХзІНжХ∞жНЃзїУжЮДжЭ•е≠ШеВ®sessionзЫЄеЕ≥зЪДеПШйЗПзЪДеСҐпЉЯжИСдїђзМЬжµЛдЄАдЄЛпЉМй¶ЦеЕИеЃГењЕ鰿襀еРМж≠•жУНдљЬпЉМеЫ†дЄЇеЬ®е§ЪзЇњз®ЛзОѓеҐГдЄЛsessionжШѓзЇњз®ЛйЧіеЕ±дЇЂзЪДпЉМиАМwebжЬНеК°еЩ®дЄАиИђжГЕеЖµдЄЛйГљжШѓе§ЪзЇњз®ЛзЪДпЉИдЄЇдЇЖжПРйЂШжАІиГљињШдЉЪзФ®еИ∞汆жКАжЬѓпЉЙпЉЫеЕґжђ°пЉМињЩдЄ™жХ∞жНЃзїУжЮДењЕй°їеЃєжШУжУНдљЬпЉМжЬАе•љжШѓдЉ†зїЯзЪДйФЃеАЉеѓєзЪДе≠ШеПЦжЦєеЉПгАВ
¬†¬†¬† йВ£дєИжИСдїђеЕИеЕЈдљУеИ∞еНХдЄ™sessionеѓєи±°пЉМеЃГйЩ§дЇЖе≠ШеВ®иЗ™иЇЂзЪДзЫЄеЕ≥дњ°жБѓпЉМжѓФе¶ВidдєЛе§ЦпЉМtomcatзЪДsessionињШжПРдЊЫзїЩз®ЛеЇПеСШдЄАдЄ™зФ®дї•е≠ШеВ®еЕґдїЦдњ°жБѓзЪДжО•еП£пЉИеЬ®з±їorg.apache.catalina.session. StandardSessionйЗМпЉЙпЉЪ
|
public void setAttribute(String name, Object value, boolean notify) |
¬†¬†¬† еЬ®ињЩйЗМеПѓдї•ињљиЄ™еИ∞еЃГеИ∞еЇХдљњзФ®дЇЖдљХзІНжХ∞жНЃпЉЪ
|
protected Map attributes = new ConcurrentHashMap(); |
¬†¬†¬† ињЩе∞±еЊИжШОз°ЃдЇЖпЉМеОЯжЭ•tomcatдљњзФ®дЇЖдЄАдЄ™ConcurrentHashMapеѓєи±°е≠ШеВ®жХ∞жНЃпЉМињЩжШѓjavaзЪДconcurrentеМЕйЗМзЪДдЄАдЄ™з±їгАВеЃГеИЪе•љжї°иґ≥дЇЖжИСдїђжЙАзМЬжµЛзЪДдЄ§зВєйЬАж±ВпЉЪеРМж≠•дЄОжШУжУНдљЬжАІгАВ
¬†¬†¬† йВ£дєИtomcatеПИжШѓзФ®дїАдєИжХ∞жНЃзїУжЮДжЭ•е≠ШеВ®жЙАжЬЙзЪДsessionеѓєи±°еСҐпЉЯжЮЬзДґињШжШѓConcurrentHashMapпЉИеЬ®зЃ°зРЖsessionзЪДorg.apache.catalina.session. ManagerBaseз±їйЗМпЉЙпЉЪ
|
protected Map<String, Session> sessions = new ConcurrentHashMap<String, Session>(); |
¬†¬†¬† еЕЈдљУеОЯеЫ†е∞±дЄНењЕе§ЪиѓідЇЖгАВиЗ≥дЇОеЕґдїЦwebжЬНеК°еЩ®зЪДеЕЈдљУеЃЮзО∞дєЯеЇФиѓ•иАГиЩСеИ∞ињЩдЄ§зВєгАВ
Session Hijack
¬†¬†¬† Session hijackеН≥дЉЪиѓЭеКЂжМБжШѓдЄАзІНжѓФиЊГдЄ•йЗНзЪДеЃЙеЕ®е®БиГБпЉМдєЯжШѓдЄАзІНеєњж≥Ые≠ШеЬ®зЪДе®БиГБпЉМеЬ®sessionжКАжЬѓдЄ≠пЉМеЃҐжИЈзЂѓеТМжЬНеК°зЂѓйАЪињЗдЉ†йАБsessionзЪДж†ЗиѓЖзђ¶жЭ•зїіжК§дЉЪиѓЭпЉМдљЖињЩдЄ™ж†ЗиѓЖзђ¶еЊИеЃєжШУе∞±иÚ襀еЧЕжОҐеИ∞пЉМдїОиАМ襀еЕґдїЦдЇЇеИ©зФ®пЉМињЩе±ЮдЇОдЄАзІНдЄ≠йЧідЇЇжФїеЗїгАВ
жЬђйГ®еИЖйАЪињЗдЄАдЄ™еЃЮдЊЛжЭ•иѓіжШОдљХдЄЇдЉЪиѓЭеКЂжМБпЉМйАЪињЗињЩдЄ™еЃЮдЊЛпЉМиѓїиАЕеЕґеЃЮжЫіиГљзРЖиІ£sessionзЪДжЬђиі®гАВ
й¶ЦеЕИпЉМжИСзЉЦеЖЩдЇЖе¶ВдЄЛй°µйЭҐпЉЪ
|
<%@ page language="java" pageEncoding="ISO-8859-1" session="true"%> <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"> <html>     <head>        <title>index.jsp</title>     </head>     <body>        This is index.jsp page.        <br>        <%            Object o = session.getAttribute("counter");            if (o == null) {               session.setAttribute("counter", 1);            } else {               Integer i = Integer.parseInt(o.toString());               session.setAttribute("counter", i + 1);            }            out.println(session.getAttribute("counter"));        %>        <a href="<%=response.encodeRedirectURL("index.jsp")%>">index</a>     </body> </html> |
¬†¬†¬† й°µйЭҐзЪДеКЯиГљжШѓеЬ®sessionдЄ≠жФЊзљЃдЄАдЄ™иЃ°жХ∞еЩ®пЉМзђђдЄАжђ°иЃњйЧЃиѓ•й°µйЭҐпЉМињЩдЄ™иЃ°жХ∞еЩ®зЪДеАЉеИЭеІЛеМЦдЄЇ1пЉМдї•еРОжѓПдЄАжђ°иЃњйЧЃињЩдЄ™й°µйЭҐиЃ°жХ∞еЩ®йГљеК†1гАВиЃ°жХ∞еЩ®зЪДеАЉдЉЪ襀жЙУеН∞еИ∞й°µйЭҐгАВеП¶е§ЦпЉМдЄЇдЇЖжѓФиЊГзЃАеНХеЬ∞ж®°жЛЯпЉМзђФиАЕз¶БзФ®дЇЖеЃҐжИЈзЂѓпЉИйЗЗзФ®firefox3.0пЉЙзЪДcookieпЉМиљђиАМжФєзФ®URLйЗНеЖЩжЦєеЉПпЉМеЫ†дЄЇзЫіжО•е§НеИґйУЊжО•и¶БжѓФдЉ™йА†cookieжЦєдЊње§ЪдЇЖгАВ
¬†¬†¬† дЄЛйЭҐпЉМжЙУеЉАfirefoxиЃњйЧЃиѓ•й°µйЭҐпЉМжИСдїђзЬЛеИ∞дЇЖиЃ°жХ∞еЩ®зЪДеАЉдЄЇ1пЉЪ

пЉИеЫЊдЄЙпЉЙ
¬†¬†¬† зДґеРОзВєеЗїindexйУЊжО•жЭ•еИЈжЦ∞иЃ°жХ∞еЩ®пЉМж≥®жДПдЄНи¶БеИЈжЦ∞ељУеЙНй°µпЉМеЫ†дЄЇжИСдїђж≤°зФ®йЗЗзФ®cookieзЪДжЦєеЉПпЉМеП™иГљеЬ®urlеРОйЭҐеЄ¶дЄКjsessionidпЉМиАМж≠§жЧґеЬ∞еЭАж†ПйЗМзЪДurlжШѓжЧ†ж≥ХеЄ¶дЄКjsessionidзЪДгАВе¶ВеЫЊеЫЫпЉМжИСжККиЃ°жХ∞еЩ®еИЈжЦ∞еИ∞дЇЖ20гАВ
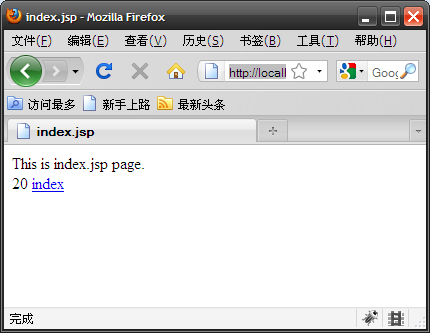
пЉИеЫЊеЫЫпЉЙ
¬†¬†¬† дЄЛйЭҐжШѓжЬАеЕ≥йФЃзЪДпЉМе§НеИґfirefoxеЬ∞еЭАж†ПйЗМзЪДеЬ∞еЭАпЉИзђФиАЕзЬЛеИ∞зЪДжШѓhttp://localhost:8080/sessio
n/index.jsp;jsessionid=1380D9F60BCE9C30C3A7CBF59454D0A5пЉЙпЉМзДґеРОжЙУеЉАеП¶дЄАдЄ™жµПиІИеЩ®пЉМж≠§е§ДдЄНењЕе∞ЖеЕґcookieз¶БзФ®гАВињЩйЗМжИСжЙУеЉАдЇЖиЛєжЮЬзЪДsafari3жµПиІИеЩ®пЉМзДґеРОе∞ЖеЬ∞еЭАз≤ШиііеИ∞еЕґеЬ∞еЭАж†ПйЗМпЉМеЫЮиљ¶еРОе¶ВдЄЛеЫЊпЉЪ

пЉИеЫЊдЇФпЉЙ
¬†¬†¬† еЊИе•ЗжА™еРІпЉМиЃ°жХ∞еЩ®зЫіжО•еИ∞дЇЖ21гАВињЩдЄ™дЊЛе≠РзђФиАЕжШѓеЬ®еРМдЄАеП∞иЃ°зЃЧжЬЇдЄКеБЪзЪДпЉМдЄНињЗеН≥дљњжНҐзФ®дЄ§еП∞жЭ•еБЪпЉМеЕґзїУжЮЬдєЯжШѓдЄАж†ЈзЪДгАВж≠§жЧґе¶ВжЮЬдЇ§жЫњзВєеЗїдЄ§дЄ™жµПиІИеЩ®йЗМзЪДindexйУЊжО•дљ†дЉЪеПСзО∞дїЦдїђеЕґеЃЮжУНзЇµзЪДжШѓеРМдЄАдЄ™иЃ°жХ∞еЩ®гАВеЕґеЃЮдЄНењЕжГКиЃґпЉМж≠§е§ДsafariзЫЧзФ®дЇЖfirefoxеТМtomcatдєЛйЧізЪДзїіжМБдЉЪиѓЭзЪДйТ•еМЩпЉМеН≥jsessionidпЉМињЩе±ЮдЇОsession hijackзЪДдЄАзІНгАВеЬ®tomcatзЬЛжЭ•пЉМsafariдЇ§зїЩдЇЖеЃГдЄАдЄ™jsessionidпЉМзФ±дЇОHTTPеНПиЃЃзЪДжЧ†зКґжАБжАІпЉМеЃГжЧ†ж≥ХеЊЧзЯ•ињЩдЄ™jsessionidжШѓдїОfirefoxйВ£йЗМвАЬеКЂжМБвАЭжЭ•зЪДпЉМеЃГдЊЭзДґдЉЪеОїжЯ•жЙЊеѓєеЇФзЪДsessionпЉМеєґжЙІи°МзЫЄеЕ≥иЃ°зЃЧгАВиАМж≠§жЧґfirefoxдєЯжЧ†ж≥ХеЊЧзЯ•иЗ™еЈ±зЪДдњЭжМБдЉЪиѓЭеЈ≤зїП襀вАЬеКЂжМБвАЭгАВ
зїУиѓ≠
¬†¬†¬† еИ∞ињЩйЗМпЉМиѓїиАЕеЇФиѓ•еѓєsessionжЬЙдЇЖжЫіе§ЪзЪДжЫіжЈ±е±Вжђ°зЪДдЇЖиІ£пЉМдЄНињЗзФ±дЇОзђФиАЕзЪДж∞іеє≥дї•еПКиІЖйЗОжЬЙйЩРпЉМжЦЗдЄ≠дєЯдЄНдєПи°®ињ∞搆嶕дєЛе§ДпЉМйАЪзѓЗжЫіе§ЪеЬ∞жППињ∞дЇЖеЬ®servlet/jspдЄ≠зЪДsessionжЬЇеИґпЉМдљЖеЕґдїЦеЉАеПСеє≥еП∞зЪДжЬЇеИґдєЯйГљдЄЗеПШдЄНз¶їеЕґеЃЧгАВеП™и¶БиЃ§зЬЯжАЭиАГпЉМдљ†дЉЪеПСзО∞еЕґеЃЮињЩйЗМжЮЧжЮЧжАїжАїдєЛйЧіпЉМжАїжЬЙдЄАдЇЫеЫ†жЮЬеЕ≥з≥їе≠ШеЬ®гАВеЬ®иљѓдїґиІДж®°жЧ•зЫКеҐЮе§ІзЪДиГМжЩѓдЄЛпЉМжИСдїђжЫіе§ЪзЪДжЧґеАЩжО•иІ¶еИ∞зЪДжШѓж°ЖжЮґгАБзїДдїґпЉМз®ЛеЇПеСШзЪДеПМз܊襀иТЩиФљдЇЖпЉМеЬ®ињЩдЇЫж°ЖжЮґгАБзїДдїґдЄНжЦ≠дЇІзФЯдї•еПКзЙИжЬђзЪДдЄНжЦ≠жЫіжЦ∞дЄ≠пЉМеЕґеЃЮжЬЙеЊИе§ЪзЫЄеѓєдЄНеПШзЪДдЄЬи•њпЉМйВ£е∞±жШѓиІДиМГгАБеНПиЃЃгАБж®°еЉПгАБзЃЧж≥Хз≠Йз≠ЙпЉМзЬЯж≠£дї§дЄАдЄ™дЇЇеЊЧеИ∞жПРйЂШзЪДињШжШѓйВ£дЇЫеЇХе±ВзЪДжФѓжТСжКАжЬѓгАВеє≥жЧґе§Ъе§ЪжАЭиАГзЪДиѓЭпЉМдљ†е∞±иГљжККз±їдЉЉзЪДжΥ糥蚐еМЦдЄЇеН∞иѓБгАВеБЪжКАжЬѓзКєе¶ВиІ£зЙЫпЉМзЯ•ж†єзЯ•еЇХжЦєиГљжЄЄеИГжЬЙдљЩгАВ
иљђиљљиѓЈдњЭзХЩеЗЇе§Д:shoru.cnblogs.com жЩЛеУ•еУ•зЪДзІБжИњйТ±


- 2010-02-20 12:48
- жµПиІИ 18237
- иѓДиЃЇ(2)
- жЯ•зЬЛжЫіе§Ъ
иѓДиЃЇ
еПСи°®иѓДиЃЇ

-
TomcatзЪДеЉВеЄЄ дєЛ java.lang.IllegalArgumentException: Document base
2009-10-29 17:10 977жШОжШОеЈ≤зїПе∞ЖжЯРдЄ™webеЇФзФ®дїОtomcatдЄЛзЪДwebappsдЄЛзІїйЩ§ ... -
configuration/ConfigurationFactoryзФ®ж≥Х(pache.commonsеМЕдЄЛ)
2009-11-04 17:14 1408иѓїеПЦйЕНзљЃжЦЗдїґжЬЙеЊИе§ЪзІНжЦєж≥ХпЉМзО∞е∞±жЬАеЄЄзФ®зЪДжЦєж≥ХдљЬдї•дЄЛжАїзїУпЉЪпЉИеЕґдїЦдЉЪ ... -
TomcatйЕНзљЃжЦЗдїґдњЃжФє
2009-11-29 21:23 805Tomcat йЕНзљЃжЦЗдїґдњЃжФє дњЃжФєserver.xml < ... -
йЕНзљЃtomcatзЪДињЮжΕ汆
2009-11-29 21:27 736йЕНзљЃtomcatзЪДињЮжΕ汆 дњЃжФєcontext.xml < ... -
tomcat-жЄЕйЩ§зЉУе≠Ш
2010-02-28 15:22 840жЦєж≥ХдЄАпЉЪ ¬†conf/server.xmlжЦЗдїґ ¬†Contex ... -
иІ£еЖ≥java.lang.OutOfMemoryError: PermGen space(иљђеЄЦ)
2010-04-22 10:18 847¬†PermGen spaceзЪДеЕ®зІ∞жШѓPermanent Gen ... -
TomcatиЃЊзљЃ404йФЩиѓѓй°µжЧ†ж≥Хж≠£з°ЃеЃЪеРС
2010-06-24 10:19 1230еЬ®еЉАеІЛеК®жЙЛдєЛеЙН,жИСдЄАиИђдє†жГѓжХідљУзЫШзЃЧдЄАйБН,ињЩж†ЈжДЯиІЙдЄЛиµЈжЙЛжЭ•,жѓФиЊГ ...
зЫЄеЕ≥жО®иНР
еЖЕеЃєж¶Ви¶БпЉЪжЬђжЦЗиѓ¶зїЖдїЛзїНдЇЖе¶ВдљХдљњзФ®C#еЉАеПСдЄАдЄ™SMTиіізЙЗжЬЇзЪДиљ®ињєеѓЉеЕ•з®ЛеЇПпЉМиѓ•з®ЛеЇПиГље§ЯиІ£жЮРCADиЃЊиЃ°зЪДDXFжЦЗдїґеєґе∞ЖеЕґдЄ≠зЪДиљ®ињєиљђжНҐдЄЇйАВзФ®дЇОSMTиЃЊе§ЗзЪДGдї£з†БгАВдЄїи¶БеЖЕеЃєжґµзЫЦDXFжЦЗдїґзЪДиѓїеПЦдЄОиІ£жЮРгАБLWPOLYLINEзЪДжПРеПЦгАБеЭРж†ЗиљђжНҐгАБGдї£з†БзФЯжИРдї•еПКдњЭе≠ШгАВж≠§е§ЦпЉМжЦЗдЄ≠ињШжОҐиЃ®дЇЖдЄАдЇЫеЃЮйЩЕеЇФзФ®дЄ≠зЪДж≥®жДПдЇЛй°єпЉМе¶ВеЭРж†Зз≥їиљђжНҐгАБжПТи°•зЃЧж≥ХзЪДйАЙжЛ©еТМйФЩиѓѓе§ДзРЖжЦєж≥ХгАВйАЪињЗеЕЈдљУзЪДдї£з†Бз§ЇдЊЛе±Хз§ЇдЇЖе¶ВдљХеИ©зФ®netDxfеЇУзЃАеМЦDXFжЦЗдїґзЪДжУНдљЬпЉМеєґжПРдЊЫдЇЖиЈѓеЊДдЉШеМЦеТМZиљіжОІеИґзЪДеЕЈдљУеЃЮзО∞гАВ йАВеРИдЇЇзЊ§пЉЪдїОдЇЛSMTи°МдЄЪжИЦзЫЄеЕ≥йҐЖеЯЯзЪДеЈ•з®ЛеЄИеТМжКАжЬѓдЇЇеСШпЉМе∞§еЕґжШѓжЬЙдЄАеЃЪC#зЉЦз®ЛеЯЇз°АеєґеѓєжХ∞жОІзЉЦз®ЛжДЯеЕіиґ£зЪДеЉАеПСиАЕгАВ дљњзФ®еЬЇжЩѓеПКзЫЃж†ЗпЉЪвС†е∞ЖCADиЃЊиЃ°зЪДDXFжЦЗдїґйЂШжХИиљђеМЦдЄЇSMTиЃЊе§ЗжЙАйЬАзЪДGдї£з†БпЉЫвС°з°ЃдњЭзФЯжИРзЪДGдї£з†БиГље§ЯеЬ®еЃЮйЩЕиЃЊе§ЗдЄКж≠£з°ЃжЙІи°МпЉМжПРйЂШзФЯдЇІжХИзОЗеТМеЗЖз°ЃжАІпЉЫвСҐиІ£еЖ≥еЭРж†Зз≥їиљђжНҐгАБжПТи°•зЃЧж≥ХйАЙжЛ©з≠ЙйЧЃйҐШпЉМеҐЮеЉЇз®ЛеЇПзЪДй≤Бж£ТжАІеТМеЃЮзФ®жАІгАВ еЕґдїЦиѓіжШОпЉЪеїЇиЃЃеЬ®зЬЯеЃЮиЃЊе§ЗињРи°МеЙНеЕИзФ®CAMиљѓдїґињЫи°МдїњзЬЯжµЛиѓХпЉМеРМжЧґж≥®жДПе§ДзРЖе•љжЦЗдїґиѓїеПЦеТМжХ∞еАЉиљђжНҐдЄ≠зЪДеЉВеЄЄжГЕеЖµгАВ
еЖЕеЃєж¶Ви¶БпЉЪжЬђжЦЗиѓ¶зїЖдїЛзїНдЇЖеЯЇдЇОи•њйЧ®е≠РS7-1200 PLCзЪДзЙ©жµБдїУеВ®иЗ™еК®еМЦз≥їзїЯпЉМжґµзЫЦдЇЖз°ђдїґжЮґжЮДгАБйАЪдњ°е§ДзРЖгАБињРеК®жОІеИґзЃЧж≥ХгАБиІ¶жСЄе±ПдЇ§дЇТз≠Йе§ЪдЄ™жЦєйЭҐзЪДеЖЕеЃєгАВз°ђдїґдЄКпЉМйЗЗзФ®S7-1217Cе§ДзРЖеЩ®гАБG120еПШйҐСеЩ®гАБET200SињЬз®ЛзЂЩеТМжњАеЕЙжµЛиЈЭдЉ†жДЯеЩ®жЮДеїЇдЇЖдЄАдЄ™з≤ЊеѓЖзЪДз©ЇйЧіеЭРж†ЗеЃЪдљНдљУз≥їгАВйАЪдњ°йГ®еИЖеИ©зФ®ProfinetеТМRS485ињЫи°МжХ∞жНЃдЉ†иЊУпЉМеєґйАЪињЗSCLеТМSTLзЉЦеЖЩдЇЖе§ЪзІНеЃЮзФ®зЪДеКЯиГљеЭЧпЉМе¶ВжА•еБЬе§ДзРЖгАБжЄ©жЉВи°•еБњгАБиЈѓеЊДдЉШеМЦз≠ЙгАВињРеК®жОІеИґжЦєйЭҐпЉМйАЪињЗйАЯ寶楃嚥еЫЊдЄОSеЮЛжЫ≤зЇњзїУеРИзЪДжЦєеЉПеЃЮзО∞йЂШз≤ЊеЇ¶еЃЪдљНгАВиІ¶жСЄе±ПзХМйЭҐеИЩйАЪињЗWinCC AdvancedеЃЮзО∞жК•и≠¶иЃ∞ељХеТМиіІдљНзКґжАБжШЊз§Їз≠ЙеКЯиГљгАВ йАВеРИдЇЇзЊ§пЉЪдїОдЇЛзЙ©жµБдїУеВ®иЗ™еК®еМЦз≥їзїЯиЃЊиЃ°гАБеЉАеПСеТМзїіжК§зЪДжКАжЬѓдЇЇеСШпЉМе∞§еЕґжШѓзЖЯжВЙи•њйЧ®е≠РPLCзЉЦз®ЛзЪДеЈ•з®ЛеЄИгАВ дљњзФ®еЬЇжЩѓеПКзЫЃж†ЗпЉЪйАВзФ®дЇОйЬАи¶БйЂШз≤ЊеЇ¶гАБйЂШеПѓйЭ†жАІзЪДзЙ©жµБдїУеВ®иЗ™еК®еМЦй°єзЫЃзЪДеЉАеПСеТМи∞ГиѓХгАВдЄїи¶БзЫЃж†ЗжШѓжПРйЂШз≥їзїЯзЪДеУНеЇФйАЯеЇ¶гАБеЃЪдљНз≤ЊеЇ¶еТМз®≥еЃЪжАІпЉМз°ЃдњЭиЃЊе§ЗиГље§ЯйХњжЧґйЧіз®≥еЃЪињРи°МгАВ еЕґдїЦиѓіжШОпЉЪжЦЗдЄ≠жПРдЊЫдЇЖе§ІйЗПеЃЮйЩЕдї£з†БзЙЗжЃµеТМжКАжЬѓзїЖиКВпЉМеЄЃеК©иѓїиАЕжЫіе•љеЬ∞зРЖиІ£еТМеЇФзФ®зЫЄеЕ≥жКАжЬѓгАВж≠§е§ЦпЉМињШеИЖдЇЂдЇЖдЄАдЇЫзО∞еЬЇи∞ГиѓХзЪДзїПй™МеТМжКАеЈІпЉМе¶ВжЄ©жЉВи°•еБњгАБйАЪдњ°дЉШеМЦз≠ЙгАВ
жЦ∞5
еЖЕеЃєж¶Ви¶БпЉЪжЬђжЦЗиѓ¶зїЖдїЛзїНдЇЖе¶ВдљХеИ©зФ®MATLABзЪДFuzzyеЈ•еЕЈзЃ±еЃЮзО∞й©Њй©ґеСШеИґеК®жДПеЫЊзЪДиѓЖеИЂгАВжЦЗдЄ≠й¶ЦеЕИиІ£йЗКдЇЖж®°з≥КжОІеИґзЪДеЯЇжЬђж¶ВењµеПКеЕґеЬ®е§ДзРЖдЄНз°ЃеЃЪжАІеТМж®°з≥КжАІжЦєйЭҐзЪДдЉШеКњгАВйЪПеРОпЉМйАЪињЗеЕЈдљУзЪДMATLABдї£з†Бз§ЇдЊЛе±Хз§ЇдЇЖе¶ВдљХжЮДеїЇж®°з≥КжО®зРЖз≥їзїЯпЉИFISпЉЙпЉМеМЕжЛђеЃЪдєЙиЊУеЕ•иЊУеЗЇеПШйЗПгАБйЪґе±ЮеЗљжХ∞дї•еПКиІДеИЩеЇУгАВж≠§е§ЦпЉМињШиЃ®иЃЇдЇЖеЃЮйЩЕеЇФзФ®дЄ≠зЪДдЉШеМЦжО™жЦљпЉМе¶Ви∞ГжХійЪґе±ЮеЗљжХ∞еПВжХ∞еТМеЉХеЕ•е§ЪиЊУеЕ•еПШйЗПдї•жПРйЂШз≥їзїЯзЪДй≤Бж£ТжАІеТМеЗЖз°ЃжАІгАВжЬАеРОпЉМйАЪињЗеѓєжѓФеЃЮй™Мй™МиѓБдЇЖж®°з≥КжОІеИґзЫЄжѓФдЉ†зїЯжЦєж≥ХеЬ®еУНеЇФжЧґйЧіеТМиѓЖеИЂз≤ЊеЇ¶дЄКзЪДдЉШиґКжАІгАВ йАВеРИдЇЇзЊ§пЉЪдїОдЇЛиЗ™еК®й©Њй©ґжИЦжЩЇиГљиЊЕеК©й©Њй©ґз≥їзїЯз†Фз©ґзЪДжКАжЬѓдЇЇеСШпЉМе∞§еЕґжШѓеѓєж®°з≥КжОІеИґзЃЧж≥ХжДЯеЕіиґ£зЪДеЉАеПСиАЕгАВ дљњзФ®еЬЇжЩѓеПКзЫЃж†ЗпЉЪйАВзФ®дЇОйЬАи¶Бз≤Њз°ЃиѓЖеИЂй©Њй©ґеСШеИґеК®жДПеЫЊзЪДеЇФзФ®еЬЇеРИпЉМе¶ВйЂШзЇІй©Њй©ґиЊЕеК©з≥їзїЯпЉИADASпЉЙгАБиЗ™еК®й©Њй©ґиљ¶иЊЖзЪДеЃЙеЕ®жОІеИґж®°еЭЧз≠ЙгАВдЄїи¶БзЫЃж†ЗжШѓжПРйЂШз≥їзїЯзЪДжЩЇиГљеМЦж∞іеє≥пЉМеҐЮеЉЇи°Миљ¶еЃЙеЕ®жАІгАВ еЕґдїЦиѓіжШОпЉЪжЦЗдЄ≠жПРдЊЫзЪДдї£з†БзЙЗжЃµеТМеЃЮй™МжХ∞жНЃжЬЙеК©дЇОиѓїиАЕжЈ±еЕ•зРЖиІ£ж®°з≥КжОІеИґзЪДеЈ•дљЬжЬЇеИґпЉМеєґдЄЇеЃЮйЩЕй°єзЫЃеЉАеПСжПРдЊЫеПВиАГгАВеРМжЧґпЉМеЉЇи∞ГдЇЖеПВжХ∞и∞ГжХізЪДйЗНи¶БжАІпЉМжМЗеЗЇж®°з≥КжОІеИґеєґйЭЮдЄЗиГљиІ£еЖ≥жЦєж°ИпЉМйЬАзїУеРИеЕЈдљУеЇФзФ®еЬЇжЩѓињЫи°МдЉШеМЦгАВ
еЖЕеЃєж¶Ви¶БпЉЪжЬђжЦЗиѓ¶зїЖдїЛзїНдЇЖдЄЙиП±PLC QD75ж®°еЭЧFBеКЯиГљеЭЧеЬ®дЉЇжЬНзФµжЬЇжОІеИґдЄ≠зЪДеЇФзФ®гАВй¶ЦеЕИйШРињ∞дЇЖйАЙжЛ©FBеКЯиГљеЭЧзЪДеОЯеЫ†пЉМеН≥зЉЦз®ЛжЦєеЉПжЄЕжЩ∞жШОдЇЖпЉМдЊњдЇОзїіжК§еТМдњЃжФєгАВжО•зЭАе±Хз§ЇдЇЖеЕ≥йФЃдї£з†БеПКеЕґеИЖжЮРпЉМеМЕжЛђиЊУеЕ•иЊУеЗЇеПШйЗПгАБдЄ≠йЧіеПШйЗПгАБеИЭеІЛеМЦгАБињРеК®еПВжХ∞иЃЊзљЃгАБељУеЙНдљНзљЃзЫСжОІгАБзЫЃж†ЗдљНзљЃеИ§жЦ≠дї•еПКйФЩиѓѓе§ДзРЖз≠ЙжЦєйЭҐзЪДеЖЕеЃєгАВжЦЗдЄ≠ињШжПРдЊЫдЇЖе§ЪдЄ™еЃЮзФ®жКАеЈІпЉМе¶ВйАЯеЇ¶еИЗжНҐеИ§жЦ≠гАБзКґжАБзЫСжОІгАБйФЩиѓѓе§ДзРЖгАБи∞ГиѓХжЦєж≥Хз≠ЙгАВж≠§е§ЦпЉМжЦЗзЂ†еЉЇи∞ГдЇЖињЩе•Чз®ЛеЇПзЪДйАВзФ®иМГеЫіеТМеАЯйЙіжДПдєЙпЉМе∞§еЕґйАВеРИеИЭе≠¶иАЕдљЬдЄЇж®°жЭњињЫи°Мй°єзЫЃзЇІеЉАеПСгАВ йАВеРИдЇЇзЊ§пЉЪеЕЈе§ЗдЄАеЃЪPLCзЉЦз®ЛеЯЇз°АпЉМе∞§еЕґжШѓдЄЙиП±PLCеИЭе≠¶иАЕеТМй°єзЫЃзЇІеЉАеПСиАЕгАВ дљњзФ®еЬЇжЩѓеПКзЫЃж†ЗпЉЪвС†еЄЃеК©иѓїиАЕзРЖиІ£дЄЙиП±PLC QD75ж®°еЭЧFBеКЯиГљеЭЧзЪДеЈ•дљЬеОЯзРЖпЉЫвС°жПРдЊЫдЄАдЄ™жИРзЖЯзЪДдЉЇжЬНзФµжЬЇжОІеИґз®ЛеЇПж®°жЭњпЉМдЊЫиѓїиАЕеЬ®еЃЮйЩЕй°єзЫЃдЄ≠еПВиАГеТМжФєињЫпЉЫвСҐжПРйЂШз®ЛеЇПзЪДеПѓзїіжК§жАІеТМеПѓйЭ†жАІгАВ еЕґдїЦиѓіжШОпЉЪжЦЗзЂ†дЄНдїЕжПРдЊЫдЇЖиѓ¶зїЖзЪДдї£з†Бз§ЇдЊЛеТМж≥®йЗКпЉМињШеИЖдЇЂдЇЖиЃЄе§ЪеЃЮйЩЕеЇФзФ®дЄ≠зЪДзїПй™МеТМжКАеЈІпЉМжЬЙеК©дЇОиѓїиАЕжЫіе•љеЬ∞зРЖиІ£еТМеЇФзФ®ињЩдЇЫзЯ•иѓЖгАВ
е∞СеДњзЉЦз®Лscratchй°єзЫЃжЇРдї£з†БжЦЗдїґж°ИдЊЛзі†жЭР-жБґй≠ФзЪДеЖТйЩ© Level Devil.zip
е∞СеДњзЉЦз®Лscratchй°єзЫЃжЇРдї£з†БжЦЗдїґж°ИдЊЛзі†жЭР-йђЉељ±жЦ©.zip
Node-Webkit Javascript (NW.js)
еЖЕеЃєж¶Ви¶БпЉЪжЬђжЦЗиѓ¶зїЖдїЛзїНдЇЖеЯЇдЇОUDSпЉИUnified Diagnostic ServicesпЉЙеНПиЃЃзЪДBootloaderзЪДиЃЊиЃ°дЄОеЃЮзО∞пЉМжґµзЫЦеЕґе§ЪеНПиЃЃжФѓжМБпЉИXCPгАБCCPгАБUDSпЉЙгАБAUTOSARеЕЉеЃєжАІгАБе§ЪзЙИжЬђйАЙжЛ©пЉИILLDеТМMCALпЉЙгАБеєњж≥Ыз°ђдїґеє≥еП∞жФѓжМБпЉИе¶ВTCз≥їеИЧиКѓзЙЗпЉЙдї•еПКCAN FDзЪДжФѓжМБгАВжЦЗдЄ≠дЄНдїЕжПРдЊЫдЇЖдЄКдљНжЬЇеТМдЄЛдљНжЬЇзЪДдї£з†Бз§ЇдЊЛпЉМињШе±Хз§ЇдЇЖеЕЈдљУзЪДжµЛиѓХзФ®дЊЛпЉМз°ЃдњЭBootloaderзЪДеКЯиГљж≠£з°ЃжАІеТМз®≥еЃЪжАІгАВж≠§е§ЦпЉМжЦЗзЂ†жОҐиЃ®дЇЖBootloaderеЬ®ж±љиљ¶зФµе≠РеТМеЈ•дЄЪжОІеИґз≥їзїЯдЄ≠зЪДеЇФзФ®еЬЇжЩѓпЉМеЉЇи∞ГдЇЖеЕґйЗНи¶БжАІеТМзБµжіїжАІгАВ йАВеРИдЇЇзЊ§пЉЪдїОдЇЛж±љиљ¶зФµе≠РгАБеµМеЕ•еЉПз≥їзїЯеЉАеПСзЪДжКАжЬѓдЇЇеСШпЉМе∞§еЕґжШѓйВ£дЇЫйЬАи¶БжЈ±еЕ•дЇЖиІ£BootloaderеЈ•дљЬжЬЇеИґеТМеЃЮзО∞зїЖиКВзЪДдЇЇзЊ§гАВ дљњзФ®еЬЇжЩѓеПКзЫЃж†ЗпЉЪйАВзФ®дЇОйЬАи¶БеЉАеПСжИЦзїіжК§ж±љиљ¶зФµе≠РжОІеИґеНХеЕГпЉИECUпЉЙзЪДеЫҐйШЯпЉМжЧ®еЬ®жПРйЂШз≥їзїЯзЪДеПѓйЭ†жАІеТМжАІиГљгАВзЫЃж†ЗеМЕжЛђдљЖдЄНйЩРдЇОпЉЪеЃЮзО∞йЂШжХИзЪДжХ∞жНЃдЉ†иЊУгАБз°ЃдњЭиѓКжЦ≠жЬНеК°зЪДеЗЖз°ЃжАІгАБдЉШеМЦеИЈеЖЩйАЯеЇ¶гАБеҐЮеЉЇз≥їзїЯзЪДеЃЙеЕ®жАІз≠ЙгАВ еЕґдїЦиѓіжШОпЉЪжЦЗзЂ†жПРдЊЫдЇЖдЄ∞еѓМзЪДдї£з†Бз§ЇдЊЛеТМжКАжЬѓзїЖиКВпЉМеЄЃеК©иѓїиАЕжЫіе•љеЬ∞зРЖиІ£еТМеЇФзФ®еЯЇдЇОUDSзЪДBootloaderгАВеРМжЧґпЉМйТИеѓєдЄНеРМз°ђдїґеє≥еП∞еТМеЇФзФ®еЬЇжЩѓпЉМзїЩеЗЇдЇЖеЕЈдљУзЪДйЕНзљЃеїЇиЃЃеТМж≥®жДПдЇЛй°єгАВ
esp32дЄ≤еП£жО•жФґtcpеПСйАБдї£з†Б
е∞СеДњзЉЦз®Лscratchй°єзЫЃжЇРдї£з†БжЦЗдїґж°ИдЊЛзі†жЭР-иЭЧиЩЂзЊ§жА™ Boss жИШ.zip
е∞СеДњзЉЦз®Лscratchй°єзЫЃжЇРдї£з†БжЦЗдїґж°ИдЊЛзі†жЭР-жФЊе∞ДжАІеНЧзУЬзФ∞.zip
е∞СеДњзЉЦз®Лscratchй°єзЫЃжЇРдї£з†БжЦЗдїґж°ИдЊЛзі†жЭР-ж†ЉжЮЧе•З Boss е§ІжИШ.zip
жЦЗж°£жФѓжМБзЫЃељХзЂ†иКВиЈ≥иљђеРМжЧґињШжФѓжМБйШЕиѓїеЩ®еЈ¶дЊІе§ІзЇ≤жШЊз§ЇеТМзЂ†иКВењЂйАЯеЃЪдљНпЉМжЦЗж°£еЖЕеЃєеЃМжХігАБжЭ°зРЖжЄЕжЩ∞гАВжЦЗж°£еЖЕжЙАжЬЙжЦЗе≠ЧгАБеЫЊи°®гАБеЗљжХ∞гАБзЫЃељХз≠ЙеЕГзі†еЭЗжШЊз§Їж≠£еЄЄпЉМжЧ†дїїдљХеЉВеЄЄжГЕеЖµпЉМжХђиѓЈжВ®жФЊењГжЯ•йШЕдЄОдљњзФ®гАВжЦЗж°£дїЕдЊЫе≠¶дє†еПВиАГпЉМиѓЈеЛњзФ®дљЬеХЖдЄЪзФ®йАФгАВ Rust дї•еЖЕе≠ШеЃЙеЕ®гАБйЫґжИРжЬђжКљи±°еТМеєґеПСйЂШжХИзЪДзЙєжАІпЉМйЗНе°СзЉЦз®ЛдљУй™МгАВжЧ†йЬАеЮГеЬЊеЫЮжФґпЉМеНіиГљйАЪињЗжЙАжЬЙжЭГдЄОеАЯзФ®ж£АжЯ•жЬЇеИґжЭЬзїЭз©ЇжМЗйТИгАБжХ∞жНЃзЂЮдЇЙз≠ЙйЪРжВ£гАВдїОеЇХе±Вз≥їзїЯеЉАеПСеИ∞ Web жЬНеК°жЮДеїЇпЉМдїОзЙ©иБФзљСиЃЊе§ЗеИ∞йЂШжАІиГљеМЇеЭЧйУЊпЉМеЃГеЗ≠еАЯеЗЇиЙ≤зЪДжАІиГљеТМеПѓйЭ†жАІпЉМжИРдЄЇеЉАеПСиАЕзЪДеЕ®иГљеИ©еЩ®гАВжЛ•жК± RustпЉМиІ£йФБйЂШжХИгАБеЃЙеЕ®зЉЦз®ЛжЦ∞еҐГзХМпЉБ
еЖЕеЃєж¶Ви¶БпЉЪжЬђжЦЗиѓ¶зїЖдїЛзїНдЇЖдљњзФ®MATLABињЫи°МQPSKи∞ГеИґдњ°еПЈйАЪињЗAWGNдњ°йБУзЪДиѓѓзђ¶еПЈзОЗпЉИSERпЉЙеТМиѓѓжѓФзЙєзОЗпЉИBERпЉЙжАІиГљеИЖжЮРзЪДжЦєж≥ХгАВдЄїи¶БеЖЕеЃєеМЕжЛђеПВжХ∞иЃЊзљЃгАБйЪПжЬЇжѓФзЙєжµБзФЯжИРгАБGrayзЉЦз†БжШ†е∞ДгАБAWGNдњ°йБУеїЇж®°гАБеЩ™е£∞еКЯзОЗиЃ°зЃЧгАБиІ£и∞ГињЗз®Лдї•еПКиѓѓз†БзОЗзїЯиЃ°гАВжЦЗдЄ≠ињШиЃ®иЃЇдЇЖдЄАдЇЫеЄЄиІБзЪДеЃЮзО∞йЩЈйШ±еТМжКАжЬѓзїЖиКВпЉМе¶ВGrayзЉЦз†БзЪДж≠£з°ЃеЃЮзО∞гАБеЩ™е£∞жЦєеЈЃзЪДиЃ°зЃЧжЦєж≥ХгАБдњ°еЩ™жѓФиљђжНҐз≠ЙгАВйАЪињЗдїњзЬЯдЄОзРЖиЃЇеАЉеѓєжѓФпЉМе±Хз§ЇдЇЖQPSKи∞ГеИґеЬ®дЄНеРМдњ°еЩ™жѓФдЄЛзЪДжАІиГљи°®зО∞гАВ йАВеРИдЇЇзЊ§пЉЪйАЪдњ°еЈ•з®ЛдЄУдЄЪе≠¶зФЯгАБйАЪдњ°з≥їзїЯеЉАеПСиАЕгАБMATLABзИ±е•љиАЕгАВ дљњзФ®еЬЇжЩѓеПКзЫЃж†ЗпЉЪйАВзФ®дЇОеЄМжЬЫжЈ±еЕ•дЇЖиІ£QPSKи∞ГеИґеОЯзРЖеПКеЕґеЬ®AWGNдњ°йБУдЄЛзЪДжАІиГљеИЖжЮРзЪДз†Фз©ґдЇЇеСШеТМеЈ•з®ЛеЄИгАВйАЪињЗеК®жЙЛеЃЮиЈµпЉМеПѓдї•жОМжП°QPSKи∞ГеИґзЪДеЯЇжЬђеОЯзРЖгАБMATLABзЉЦз®ЛжКАеЈІдї•еПКйАЪдњ°з≥їзїЯзЪДжАІиГљиѓДдЉ∞жЦєж≥ХгАВ еЕґдїЦиѓіжШОпЉЪжЦЗдЄ≠жПРдЊЫдЇЖиѓ¶зїЖзЪДMATLABдї£з†БзЙЗжЃµпЉМеЄЃеК©иѓїиАЕжЫіе•љеЬ∞зРЖиІ£еТМеЃЮзО∞QPSKи∞ГеИґзЪДжАІиГљеИЖжЮРгАВж≠§е§ЦпЉМињШжПРеИ∞дЇЖдЄАдЇЫдЉШеМЦеїЇиЃЃпЉМе¶ВеҐЮеК†дїњзЬЯжђ°жХ∞дї•жПРйЂШдљОдњ°еЩ™жѓФеМЇеЯЯзЪДз≤ЊеЇ¶гАВ
еЖЕеЃєж¶Ви¶БпЉЪжЬђжЦЗиѓ¶зїЖдїЛзїНдЇЖеЕ≠иљіEtherCATжАїзЇњдЉЇжЬНжґВеЄГжФґеНЈжЬЇз®ЛеЇПзЪДеЃЮзО∞ињЗз®ЛгАВиѓ•з≥їзїЯйАЪињЗеЕ≠дЄ™дЉЇжЬНзФµжЬЇгАБеПШйҐСеЩ®еТМзЉЦз†БеЩ®зЪДйЕНеРИпЉМеЃЮзО∞дЇЖеК®жАБжµЛйЗПйҐСзОЗгАБиљђйАЯиЃ°зЃЧгАБйҐСзОЗжНҐзЃЧдЄОйАЯеЇ¶еРМж≠•дї•еПКйАЪиЃѓжОІеИґз≠ЙеКЯиГљгАВжЦЗдЄ≠жПРдЊЫдЇЖеЕЈдљУзЪДдї£з†Бз§ЇдЊЛпЉМе¶ВPythonгАБC/C++еТМSTиѓ≠и®Адї£з†БзЙЗжЃµпЉМзФ®дЇОиІ£йЗКе¶ВдљХињЫи°МйҐСзОЗжµЛйЗПгАБиљђйАЯжНҐзЃЧгАБеПШйҐСеЩ®йҐСзОЗиЃЊзљЃеТМEtherCATйАЪиЃѓжОІеИґгАВж≠§е§ЦпЉМињШиЃ®иЃЇдЇЖеЃЮйЩЕеЇФзФ®дЄ≠зЪДеЄЄиІБйЧЃйҐШеПКеЕґиІ£еЖ≥жЦєж°ИпЉМе¶ВйАЪиЃѓеїґињЯе§ДзРЖгАБеЉВеЄЄе§ДзРЖеТМеПВжХ∞йЕНзљЃз≠ЙгАВ йАВеРИдЇЇзЊ§пЉЪдїОдЇЛеЈ•дЄЪиЗ™еК®еМЦжОІеИґйҐЖеЯЯзЪДеЈ•з®ЛеЄИеТМжКАжЬѓдЇЇеСШпЉМе∞§еЕґжШѓеѓєEtherCATжАїзЇњжКАжЬѓеТМдЉЇжЬНжОІеИґз≥їзїЯжЬЙдЄАеЃЪдЇЖиІ£зЪДдЇЇзЊ§гАВ дљњзФ®еЬЇжЩѓеПКзЫЃж†ЗпЉЪйАВзФ®дЇОйЬАи¶БйЂШз≤ЊеЇ¶еРМж≠•жОІеИґзЪДеЈ•дЄЪеЇФзФ®еЬЇжЩѓпЉМе¶ВжґВеЄГеЈ•иЙЇеТМжФґеНЈзОѓиКВгАВзЫЃж†ЗжШѓеЄЃеК©иѓїиАЕзРЖиІ£еТМеЃЮзО∞еЕ≠иљіEtherCATжАїзЇњдЉЇжЬНжґВеЄГжФґеНЈжЬЇз≥їзїЯзЪДеНПеРМеЈ•дљЬпЉМжПРйЂШзФЯдЇІжХИзОЗеТМз®≥еЃЪжАІгАВ еЕґдїЦиѓіжШОпЉЪжЦЗзЂ†дЄНдїЕжПРдЊЫдЇЖиѓ¶зїЖзЪДдї£з†БеЃЮзО∞пЉМињШеИЖдЇЂдЇЖиЃЄе§ЪеЃЮйЩЕи∞ГиѓХзїПй™МеТМжКАеЈІпЉМжЬЙеК©дЇОиѓїиАЕжЫіе•љеЬ∞еЇФеѓєеЃЮйЩЕеЈ•з®ЛдЄ≠зЪДжМСжИШгАВ
еЖЕеЃєж¶Ви¶БпЉЪжЬђжЦЗиѓ¶зїЖдїЛзїНдЇЖе¶ВдљХеИ©зФ®COMSOLиљѓдїґдЄ≠зЪДж∞іеє≥йЫЖжЦєж≥ХињЫи°МжњАеЕЙжЙУе≠ФзЪДж®°жЛЯгАВй¶ЦеЕИпЉМжЮДеїЇдЇЖеЗ†дљХж®°еЮЛеєґиЃЊзљЃдЇЖжЭРжЦЩеПВжХ∞пЉМеМЕжЛђжЄ©еЇ¶дЊЭиµЦзЪДеѓЉзГ≠з≥їжХ∞гАБеѓЖеЇ¶еТМжѓФзГ≠еЃєз≠ЙгАВжО•зЭАпЉМеЃЪдєЙдЇЖйЂШжЦѓеИЖеЄГзЪДжњАеЕЙзГ≠жЇРпЉМеєґеЉХеЕ•дЇЖж∞іеє≥йЫЖжЦєз®ЛжЭ•ињљиЄ™зЖФ汆зХМйЭҐзЪДеПШеМЦгАВжЦЗдЄ≠еЉЇи∞ГдЇЖзљСж†ЉеИТеИЖгАБжЧґйЧіж≠•йХњиЃЊзљЃдї•еПКе§ЪзЙ©зРЖеЬЇиА¶еРИзЪДйЗНи¶БжАІпЉМзЙєеИЂжШѓеЬ®е§ДзРЖз≠Йз¶їе≠РдљУе±ПиФљжХИеЇФжЧґгАВжЬАеРОпЉМиЃ®иЃЇдЇЖеРОе§ДзРЖж≠•й™§пЉМе¶ВеѓЉеЗЇеИЗеЙ≤зЇњжХ∞жНЃгАБй™МиѓБзљСж†ЉзЛђзЂЛжАІеТМдЄОеЃЮй™МжХ∞жНЃеѓєжѓФз≠ЙгАВ йАВеРИдЇЇзЊ§пЉЪдїОдЇЛз≤ЊеѓЖеК†еЈ•йҐЖеЯЯзЪДз†Фз©ґдЇЇеСШеТМжКАжЬѓдЇЇеСШпЉМе∞§еЕґжШѓйВ£дЇЫзЖЯжВЙCOMSOLиљѓдїґеєґеѓєжњАеЕЙжЙУе≠ФжДЯеЕіиґ£зЪДзФ®жИЈгАВ дљњзФ®еЬЇжЩѓеПКзЫЃж†ЗпЉЪйАВзФ®дЇОеЄМжЬЫжЈ±еЕ•дЇЖиІ£жњАеЕЙжЙУе≠ФињЗз®ЛдЄ≠жґЙеПКзЪДеРДзІНзЙ©зРЖзО∞и±°зЪДз†Фз©ґдЇЇеСШпЉМеЄЃеК©дїЦдїђдЉШеМЦеЈ•иЙЇеПВжХ∞пЉМжПРйЂШеК†еЈ•з≤ЊеЇ¶гАВеРМжЧґпЉМдєЯдЄЇжХЩе≠¶жПРдЊЫдЇЖдЄАдЄ™еЊИе•љзЪДж°ИдЊЛпЉМдљње≠¶зФЯиГље§ЯжОМжП°е§НжЭВзЪДе§ЪзЙ©зРЖеЬЇиА¶еРИдїњзЬЯжКАжЬѓгАВ еЕґдїЦиѓіжШОпЉЪжЦЗдЄ≠жПРдЊЫдЇЖе§ІйЗПеЕЈдљУзЪДMATLABдї£з†БзЙЗжЃµпЉМдЊњдЇОиѓїиАЕзРЖиІ£еТМеЃЮиЈµгАВж≠§е§ЦпЉМдљЬиАЕињШеИЖдЇЂдЇЖдЄАдЇЫеЃЮзФ®зЪДе∞ПжКАеЈІпЉМе¶Ве¶ВдљХйБњеЕНжХ∞еАЉйЬЗиН°гАБйАЙжЛ©еРИйАВзЪДеИЭеІЛеПВжХ∞з≠ЙгАВ
APKеМЕеРНз±їеРНжЯ•зЬЛеЈ•еЕЈ
жЦЗж°£жФѓжМБзЫЃељХзЂ†иКВиЈ≥иљђеРМжЧґињШжФѓжМБйШЕиѓїеЩ®еЈ¶дЊІе§ІзЇ≤жШЊз§ЇеТМзЂ†иКВењЂйАЯеЃЪдљНпЉМжЦЗж°£еЖЕеЃєеЃМжХігАБжЭ°зРЖжЄЕжЩ∞гАВжЦЗж°£еЖЕжЙАжЬЙжЦЗе≠ЧгАБеЫЊи°®гАБеЗљжХ∞гАБзЫЃељХз≠ЙеЕГзі†еЭЗжШЊз§Їж≠£еЄЄпЉМжЧ†дїїдљХеЉВеЄЄжГЕеЖµпЉМжХђиѓЈжВ®жФЊењГжЯ•йШЕдЄОдљњзФ®гАВжЦЗж°£дїЕдЊЫе≠¶дє†еПВиАГпЉМиѓЈеЛњзФ®дљЬеХЖдЄЪзФ®йАФгАВ Rust дї•еЖЕе≠ШеЃЙеЕ®гАБйЫґжИРжЬђжКљи±°еТМеєґеПСйЂШжХИзЪДзЙєжАІпЉМйЗНе°СзЉЦз®ЛдљУй™МгАВжЧ†йЬАеЮГеЬЊеЫЮжФґпЉМеНіиГљйАЪињЗжЙАжЬЙжЭГдЄОеАЯзФ®ж£АжЯ•жЬЇеИґжЭЬзїЭз©ЇжМЗйТИгАБжХ∞жНЃзЂЮдЇЙз≠ЙйЪРжВ£гАВдїОеЇХе±Вз≥їзїЯеЉАеПСеИ∞ Web жЬНеК°жЮДеїЇпЉМдїОзЙ©иБФзљСиЃЊе§ЗеИ∞йЂШжАІиГљеМЇеЭЧйУЊпЉМеЃГеЗ≠еАЯеЗЇиЙ≤зЪДжАІиГљеТМеПѓйЭ†жАІпЉМжИРдЄЇеЉАеПСиАЕзЪДеЕ®иГљеИ©еЩ®гАВжЛ•жК± RustпЉМиІ£йФБйЂШжХИгАБеЃЙеЕ®зЉЦз®ЛжЦ∞еҐГзХМпЉБ
еЖЕеЃєж¶Ви¶БпЉЪжЬђжЦЗиѓ¶зїЖдїЛзїНдЇЖеЗЄжЮБж∞Єз£БеРМж≠•зФµжЬЇйЗЗзФ®йЂШйҐСжЦєж≥Ґж≥®еЕ•жКАжЬѓеТМиљђе≠РйФБзЫЄзОѓпЉИPLLпЉЙињЫи°МжЧ†дљНзљЃдЉ†жДЯеЩ®жОІеИґзЪДжЦєж≥ХгАВй¶ЦеЕИиІ£йЗКдЇЖйЂШйҐСжЦєж≥Ґж≥®еЕ•зЪДеЯЇжЬђеОЯзРЖеПКеЕґзЫЄеѓєдЇОж≠£еЉ¶ж≥ҐзЪДдЉШеКњпЉМзДґеРОе±Хз§ЇдЇЖеЕЈдљУзЪДMATLAB/SimulinkеЃЮзО∞дї£з†БпЉМеМЕжЛђдњ°еПЈзФЯжИРгАБеЭРж†ЗеПШжНҐгАБеЄ¶йАЪжї§ж≥ҐгАБиІ£и∞Гдї•еПКPLLзЪДеЕЈдљУеЃЮзО∞гАВжЦЗдЄ≠ињШиЃ®иЃЇдЇЖеЄЄиІБйЧЃйҐШзЪДиІ£еЖ≥жЦєж°ИпЉМе¶ВйЂШйҐСеЩ™е£∞еЉХиµЈзЪДжКЦеК®гАБеК®жАБеУНеЇФињЯжїЮз≠ЙпЉМеєґжПРдЊЫдЇЖдЉШеМЦеїЇиЃЃгАВж≠§е§ЦпЉМдљЬиАЕеИЖдЇЂдЇЖдЄАдЇЫеЃЮзФ®зЪДи∞ГиѓХжКАеЈІпЉМе¶ВйАЪињЗжЭОиР®е¶Веی嚥еИ§жЦ≠йФБзЫЄзКґжАБпЉМдї•еПКе¶ВдљХйАЙжЛ©еРИйАВзЪДжї§ж≥ҐеЩ®еПВжХ∞гАВжЬАеРОпЉМжО®иНРдЇЖеЗ†зѓЗйЗНи¶БзЪДеПВиАГжЦЗзМЃпЉМеЄЃеК©иѓїиАЕжЈ±еЕ•зРЖиІ£зЫЄеЕ≥зРЖиЃЇеТМжКАжЬѓгАВ йАВеРИдЇЇзЊ§пЉЪдїОдЇЛзФµжЬЇжОІеИґз≥їзїЯз†Фз©ґеТМеЉАеПСзЪДжКАжЬѓдЇЇеСШпЉМе∞§еЕґжШѓеѓєж∞Єз£БеРМж≠•зФµжЬЇжЧ†дљНзљЃдЉ†жДЯеЩ®жОІеИґжДЯеЕіиґ£зЪДеЈ•з®ЛеЄИеТМз†Фз©ґдЇЇеСШгАВ дљњзФ®еЬЇжЩѓеПКзЫЃж†ЗпЉЪйАВзФ®дЇОйЬАи¶Бз≤Њз°ЃиОЈеПЦзФµжЬЇиљђе≠РдљНзљЃзЪДеЇФзФ®еЬЇеРИпЉМе¶ВеЈ•дЄЪиЗ™еК®еМЦгАБзФµеК®ж±љиљ¶з≠ЙйҐЖеЯЯгАВдЄїи¶БзЫЃж†ЗжШѓжПРйЂШз≥їзїЯзЪДй≤Бж£ТжАІеТМз≤ЊеЇ¶пЉМе∞§еЕґжШѓеЬ®дљОйАЯжИЦйЭЩжАБжЭ°дїґдЄЛгАВ еЕґдїЦиѓіжШОпЉЪжЦЗдЄ≠дЄНдїЕжПРдЊЫдЇЖзРЖиЃЇеИЖжЮРпЉМињШеМЕжЛђдЇЖе§ІйЗПзЪДеЃЮиЈµзїПй™МеИЖдЇЂеТМдї£з†Бз§ЇдЊЛпЉМжЬЙеК©дЇОиѓїиАЕењЂйАЯжОМжП°йЂШйҐСжЦєж≥Ґж≥®еЕ•еТМPLLзЪДеЃЮйЩЕеЇФзФ®гАВеРМжЧґпЉМеЉЇи∞ГдЇЖдЄОеЕґдїЦжОІеИґжЦєж≥ХпЉИе¶ВйЊЩдЉѓж†ЉиІВжµЛеЩ®пЉЙзїУеРИдљњзФ®зЪДењЕи¶БжАІпЉМдї•еЃЮзО∞еЕ®йАЯеЯЯзЪДжЬЙжХИжОІеИґгАВ